R语言在分子流行病学中的应用
2023-12-04宋花玲
吴 娜,宋花玲
上海中医药大学公共健康学院(上海 201203)
分子流行病学作为医学院校公共卫生与预防医学专业研究生的公共基础课,不仅可以帮助医学研究生探索疾病传播和控制的科学意义及环境对人类健康的影响,还能从分子标记的角度了解饮食和营养影响人类健康的内在生物学机制。目前,大数据在识别和干预人口健康决定因素方面具有革命性意义,被认为是未来科学的革命性发展。为积极应对大数据时代的挑战,公共卫生尤其流行病学相关专业的研究生不仅需要掌握传统流行病学的方法,还应该熟知分子流行病学相关知识,尤其是通过R 语言编程处理大数据,通过大数据确定人口健康的干预目标。为培养相关大数据人才适应社会发展需求,医学院校教师有必要在传统流行病学的基础上,指导研究生掌握新兴技术和大数据分析方法,将R 语言应用于分子流行病学研究,推动分子流行病学领域的发展。
1 分子流行病学概述
1.1 分子流行病学的定义和应用
分子流行病学是一种将先进的生物学实验方法纳入传统流行病学,以确定疾病病因并提出相应预防和干预措施的科学[1-2]。它越来越多地被作为一种了解外部环境暴露与遗传及其他易感因素间相互作用的工具,从而确定易感人群,被广泛应用于遗传及代谢性疾病。
1973 年,Kilbourne 在“流感的分子流行病学”一文中首次引入了分子流行病学的概念[3]。随着第一本关于分子流行病学的书籍《分子流行病学:原理与实践》的出版,这个术语变得更加正式[1]。分子流行病学主要研究遗传和环境因素在分子或细胞阶段的作用及其相互作用。2003 年人类基因组计划完成DNA 全测序工作是该领域的一个突破。随着基因分型和高通量测序技术的发展,研究人员可以全方位评估人类的DNA、RNA、蛋白质或代谢组分,为更全面地检测与疾病风险因素和途径相关的潜在生物学变异奠定了基础。另外,高通量技术丰富了研究人员对疾病表型-基因型关联的理解,有助于寻找疾病的生物标志物,并利用其识别易感人群,从而帮助临床医生为患者制定个性化的治疗方案。分子流行病学通过各种工具研究疾病的生物标志物,如DNA 甲基化谱、蛋白质谱、代谢物或新基因,有助于发现疾病的病因和决定因素,进而预防疾病以达到改善公众健康的目的。
1.2 分子流行病学在医学院校研究生教育中的作用
传统流行病学是研究人群中疾病与健康状况的分布及其影响因素,以及防治疾病及促进健康的策略和措施的科学[4]。分子流行病学作为传统流行病学与分子生物学的交叉学科,强调通过先进的技术检测生物学标志的分布情况,借助传统流行病学的研究方法,从更深层次即分子或基因水平阐明疾病的病因及其致病过程[5]。分子流行病学是由传统流行病学学科发展的需求,以及分子生物学理论和技术的巨大成就相结合的产物,是近十几年迅速发展的一门流行病学新分支[6]。
分子流行病学课程在医学院校研究生教育中起着至关重要的作用[7]:①疾病诊断和预防。研究生能够了解不同疾病的分子机制,如遗传变异、突变和表达模式,这些知识对于疾病诊断、预后评估和预防是必不可少的。通过学习如何利用分子工具和技术识别病原体,研究疾病病因,有助于制定个性化医疗和预防策略。②药物开发和治疗研究。分子流行病学是药物开发和治疗研究的工具。通过掌握分子技术评估药物的有效性和安全性,可以获得有关药物代谢、药物靶标相互作用和药物作用机制的知识,这些知识对于研究和开发新的治疗方法和个性化药物至关重要。③流行病学研究的设计和分析。通过学习设计和开展分子流行病学研究,掌握分析大规模分子数据的统计和生物信息学方法,对于研究疾病的遗传和环境风险因素、建立疾病预测模型和评估干预措施的有效性具有指导意义。④研究技能和科学素养的培养。分子流行病学教育不仅注重传授理论知识,而且注重培养研究技能和科学素养,包括学习文献综述,制定研究假设,设计实验方案,收集和分析数据等。
2 R语言与SPSS软件的比较
2.1 R语言的特点
R 是一种用于统计计算和图形绘制的编程语言,由统计学家Ross Ihaka 和Robert Gentleman创建,核心R 语言由大量包含可重复使用的代码和文档的扩展包组成[8-9]。在过去的三十年里,R 语言在统计学和生物信息学领域发挥了重要作用,目前已产生了数以万计的扩展包,涉及范围从机器学习(如支持向量机、随机森林、人工神经网络等)到单核苷酸多态性(single nucleotide polymorphisms, SNPs)数据、转录组数据和DNA甲基化数据分析等[10-12]。
R 语言具有以下特点[13]:①开源性,可以免费下载,并提供复杂的数据分析功能,同时还有一个活跃的在线用户社区,使用者们可以在其中寻求帮助。②跨平台的编程语言,其代码可以在多个操作系统上运行,程序员只需编写一次程序。③可以进行各种机器学习操作,如分类、回归以及开发人工神经网络的各种扩展包。④可以绘制高质量图片,通过ggplot2 和plotly 等R 包制作精美图片。⑤在CRAN 存储库中存有超过10 000 个扩展包,可以执行各种数据分析功能。⑥既能使数据可视化,又能连接外部数据库如基因表达综合数据库(Gene Expression Omnibus,GEO)、京都基因与基因组百科全书数据库(Kyoto Encyclopedia of Genes and Genomes, KEGG)等以执行高级生物统计功能。⑦作为一种不断发展的编程语言,每当添加任何新功能时,R 都会提供更新服务,便于广大用户使用。
2.2 SPSS软件的特点
SPSS(statistical product and service solutions)是一种数据统计分析软件,由SPSS 有限公司于1968 年推出,2009 年被国际商业机器公司(International Business Machines Corporation, IBM)收购。由于SPSS 简单易操作,常被用于数据处理、市场调查等。
SPSS 具有以下特点:①不需要编程,简单易上手;②不适用于大数据分析,如分子流行病学中有关SNPs、转录组学及DNA 甲基化等大数据;③作为一款商业软件包,正版软件需要付费才可以使用。
2.3 R语言与SPSS软件的比较
分子流行病学是一门探究疾病病因相关分子生物标记的学科,SNPs 数据、转录组学数据及DNA 甲基化数据等分子生物标记均属于大数据集,越来越多的研究人员选择使用R 语言中的各种扩展包进行分析,而SPSS 更适合分析样本量较少的人类测量学数据及血液学指标,见表1。分子流行病学的教学目的之一是培养研究生掌握大数据处理与分析的能力以适应和满足社会需求。研究者可根据自身需要选择合适的统计软件,考虑到R 语言在大数据处理上的优势,在分子流行病学研究中更推荐使用R 语言。

表1 R语言与SPSS软件的比较Table 1. Comparison between R language and SPSS software
3 R语言在分子流行病学中的应用
分子流行病学侧重研究生物标记物在疾病病因、风险评估和预防研究中的应用。通过选择和验证不同种类的生物标记物,采用不同的研究设计和R 语言数据分析方法[14]。本研究通过案例介绍R 语言在分子流行病学生物标记物SNPs 和DNA 甲基化修饰数据分析中的应用。
3.1 R语言应用于非酒精性脂肪肝的SNPs位点筛选
易感基因的SNPs 位点是分子流行病学重点关注的一类生物标记物,也是分子流行病学课程教学的重要内容。利用R 语言中的SNPassoc 包的association 函数分析非酒精性脂肪肝(non-alcoholic fatty liver disease, NAFLD)的易感基因SNPs 在五种遗传模型下的基因型频率,操作简单,结果展示清晰明了。具体代码如下:
> setwd
> library(openxlsx)
> File<- read.xlsx("NAFLD.xlsx",5)
> File[File=="0 0"]<-NA
> File[File=="NA"]<-NA
> File[File==""]<-NA
> File<-as.data.frame(File)
> write.csv(File, file = "NAFLD_1.csv")
> library(SNPassoc)
> names(File)
> File.1<- setupSNP(File,colSNPs=2,sep="")
> zlassoc<- WGassociation(NAFLD~1,data=File.1)
> zlassoc
> dev.new()
> plot(zlassoc,ylim = c(-0,-2))
> write.csv(zlassoc,"NAFLD_5model.csv")
> asso<- association(NAFLD~rs1260326,data=File.1)
> asso
> write.csv(asso,"rs1260326_result.csv")
表2 展示了rs1260326 在五种遗传模型下基因型的频率,NAFLD 的葡萄糖调节蛋白基因(glucokinase regulator, GCKR)的rs1260326 位点在显性模型(P=0.038)和超显性模型(P=0.040)下具有统计学意义。
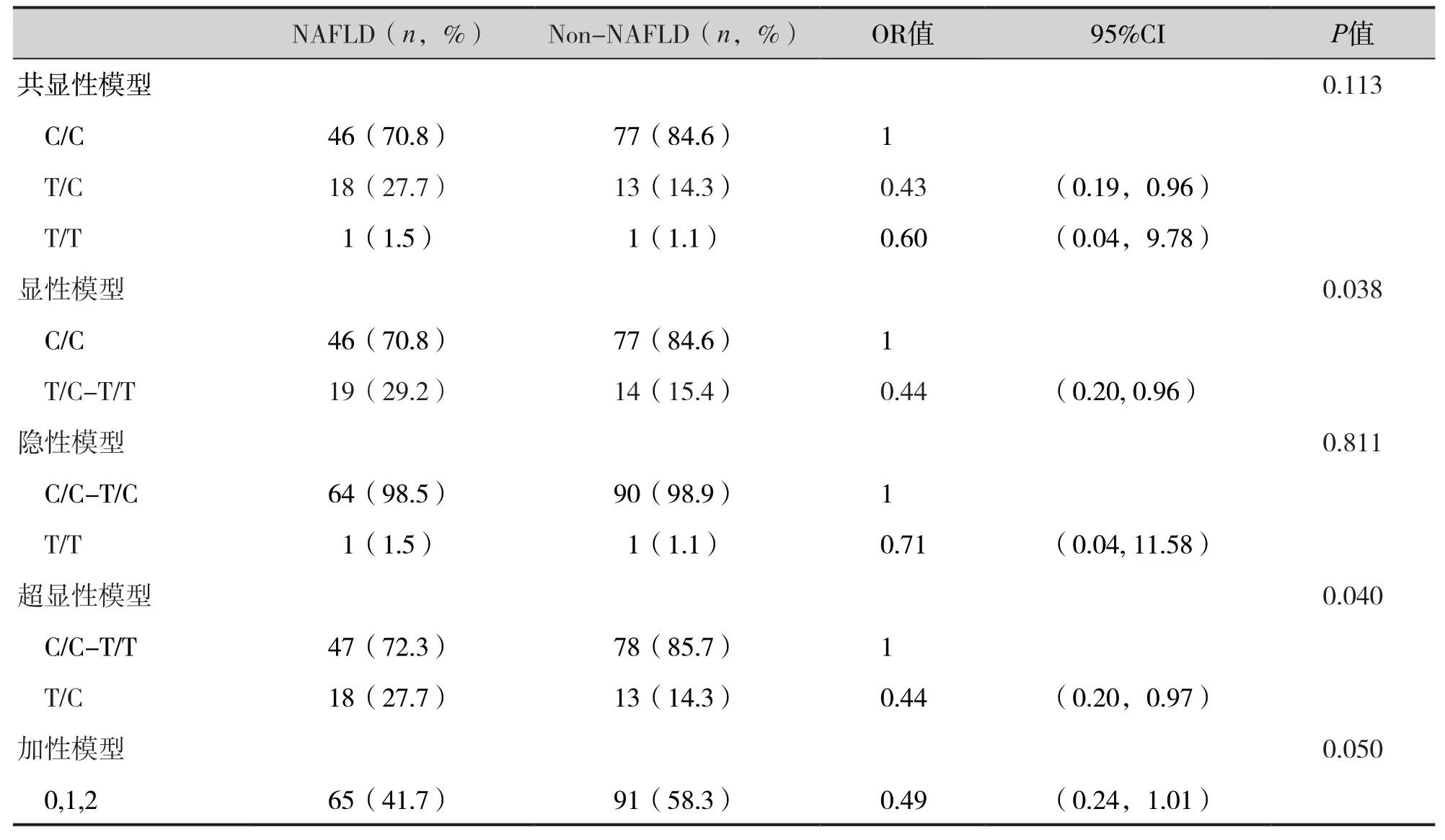
表2 SNPs位点在五种遗传模型下的基因型频率分布Table 2. Genotype frequency distribution of SNPs loci under five genetic models
3.2 R语言应用于非酒精性脂肪肝的DNA甲基化修饰标记筛选
在后基因组时代,随着高通量技术成本的降低,海量组学数据与研究结果展现了生命现象的复杂性。目前,分子流行病学研究越来越倾向于从多组学的角度出发,从遗传和表观遗传到转录和代谢,从机制到表型,进行整合研究以得到全局结果。DNA 甲基化是表观遗传学中研究最多的一种修饰,是将甲基基团(CH3)转移至DNA,从而使基因活性发生改变的修饰方式。
在当前的科研需求下,Illumina 的甲基化芯片Infinium Methylation EPIC BeadChip(简称850k 芯片)可以检测超过853 000 个CpG 位点,全面覆盖CpG 岛、启动子、编码区、开放染色质和增强子,提供了性能优越且经济可靠的解决方案。R 语言中CHAMP 包的CpG.GUI 函数可以分析CpG 位点在染色体、CpG 岛、转录起始区域(transcription star site, TSS)的分布情况,见图1。
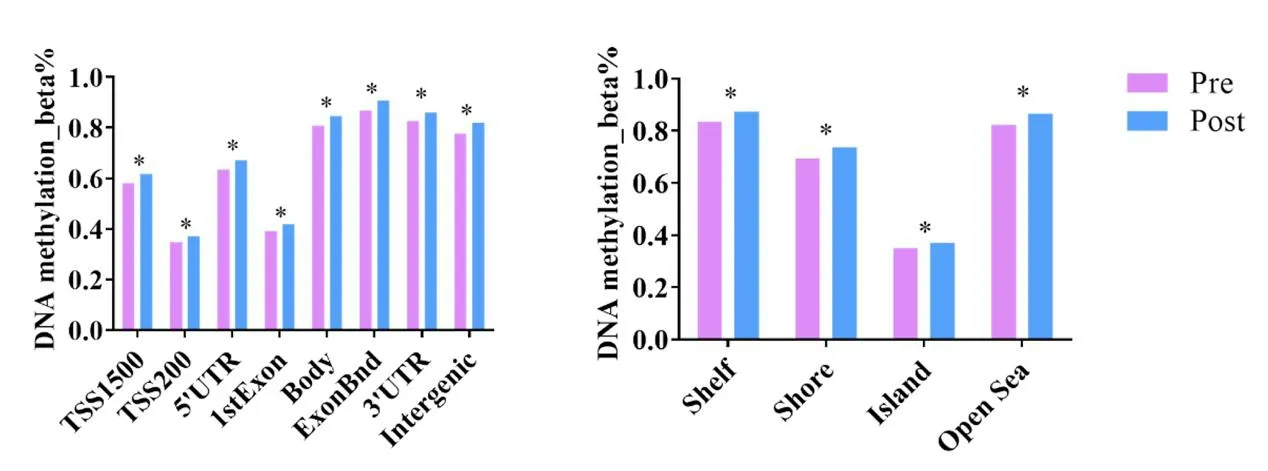
图1 NAFLD患者与健康人群DNA甲基化的分布情况Figure 1. Distribution of DNA methylation between NAFLD patients and healthy people
差异甲基化位点的筛选是数据分析过程的主要环节,R 语言中CHAMP 包的champ.DMP()函数可以计算差异甲基化,使用ggplot2 包可以绘制火山图,以展示NAFLD 患者相比于健康人群的差异甲基化位点,见图2。
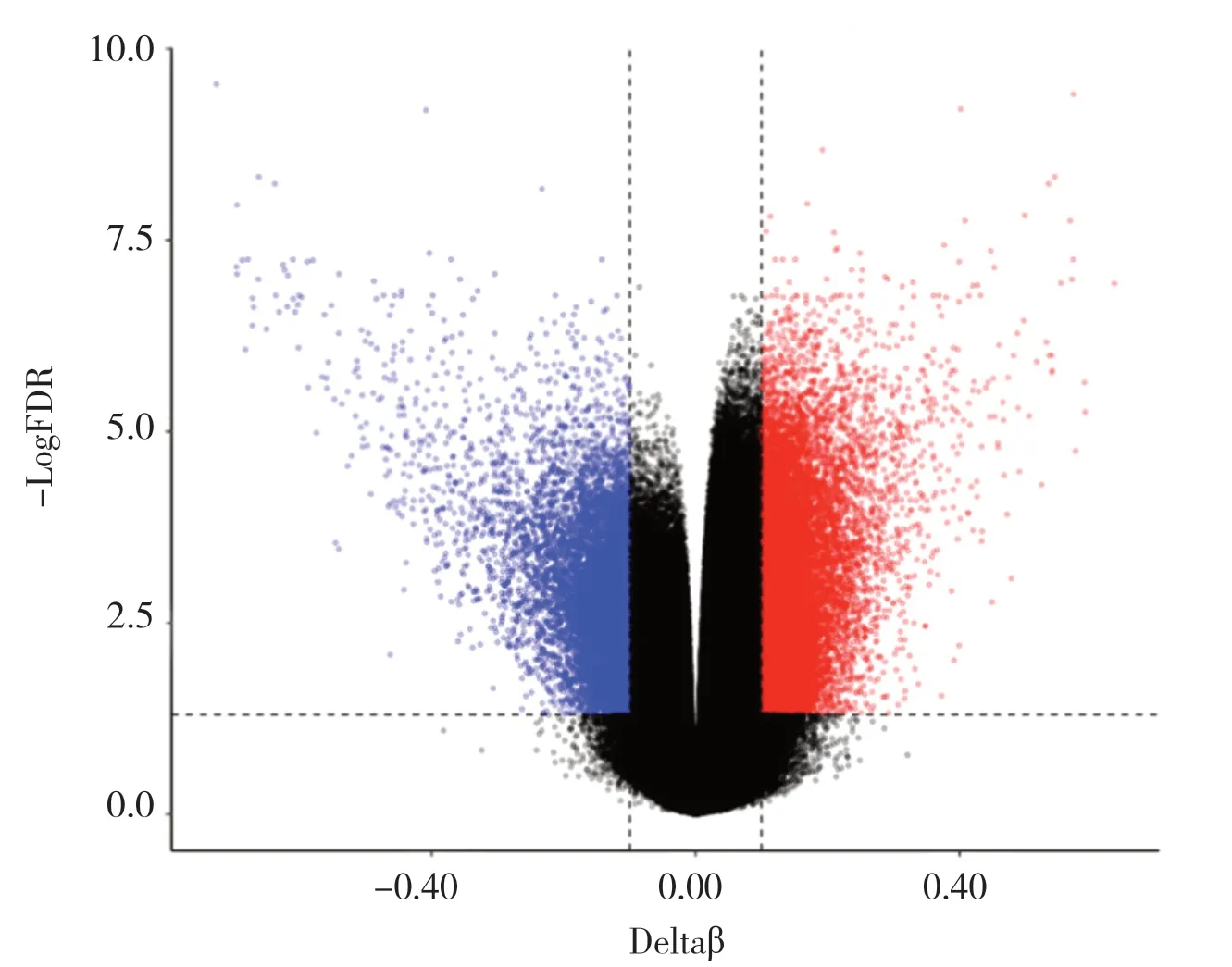
图2 NAFLD的差异DNA甲基化位点Figure 2. Differential DNA methylation sites in NAFLD
4 结语
本文通过比较R 语言和SPSS 软件的特点,重点探讨了R 语言在分子流行病学中的应用,R语言具有强大的绘图及数据分析能力,在大数据处理与分析上更具优势。医学类高等院校教师应根据时代要求和现实需要,培养研究生掌握应用R 语言处理和分析大数据的能力,进一步满足分子流行病学领域的研究需求。
