废水中鸟粪石回收的机器学习预测和优化
2023-12-02蒋绍坚康冰艳冷立健李海龙
佟 颖, 蒋绍坚, 康冰艳, 冷立健, 李海龙
(中南大学 能源科学与工程学院, 湖南 长沙 410083)
0 引 言
磷(P)是一种不可再生的基本资源,对生命和农业生产的发展至关重要[1]。鉴于P对环境的不利影响、储量有限、全球需求增加和单边依赖,P的可持续利用和管理日益重要。迄今为止,国内外已经开发了许多P重复利用和回收的工艺,如利用聚磷菌或反硝化聚磷菌等强化生物除磷[2-3]、向富磷溶液中添加试剂生成鸟粪石或磷酸钙沉淀[4-6]和选用合适的固体吸附材料对磷溶液进行选择性吸附[7]等方法。在氮(N)和P共存的情况下,采用鸟粪石回收磷的方式是最常用的技术[9]。该方法只需调节废水的pH和投加适当镁源即可进行磷回收。含有高浓度N和P的废水(如城市废水、工业废水和尿液等)是生成鸟粪石的可靠来源。
鸟粪石(磷酸铵镁,MgNH4PO4·6H2O)是一种富含镁(Mg)、铵和磷酸盐的磷酸盐矿物和缓释肥料,具有吸磷量大、浸出率低、养分释放缓慢等优点,可用于农业生产,也用于河流的营养强化[8]。使用鸟粪石结晶技术回收磷可以有效缓解矿物磷的资源匮乏问题,并且在减少当地的环境污染方面显现出巨大潜力。近年来,全球范围内已有近多个鸟粪石工厂从污水中回收营养物质。例如,在比利时的一个污水处理厂中,鸟粪石用于回收磷的沉淀和缓释肥料已经商业化,并被应用在OSTARA PEARL、AirPrex®技术和NuReSys®技术等流化床反应器中[11]。美国某污水处理厂对现有的鸟粪石处理工艺进行了质量平衡的建模分析,结果显示,在符合美国基础设施典型设计参数的情况下,可以回收约71%至96%的潜在损失磷[12]。此外,LI等[13]对鸟粪石结晶的基础研究进展进行了总结,其中pH、温度、Mg∶P、搅拌速率和晶种等因素被证明对除磷效率和产品纯度具有重要影响。然而,废水在不同回收工艺参数下的鸟粪石回收难以预测和操作,生产优质鸟粪石所需的条件尚未得到充分研究。
随着人工智能的飞速发展,机器学习(ML,Machine Learning)作为一种新兴的技术,可以用来解决复杂的非线性问题,例如鸟粪石沉淀/结晶过程中化学反应系统的建立。基于影响目标的输入变量与目标本身之间的联系,所构建的ML模型可以准确计算理论目标值或预测目标值。利用优化算法对构建的ML模型进行求解,可以优化输入变量,以指导实验研究。据知,目前还没有利用ML模型研究鸟粪石回收的相关研究。
因此,本文中采用了随机森林(RF)和极限梯度提升算法(XGBoost)两种基于ML算法的经典预测模型,用于辅助从模型废水中回收鸟粪石的预测和优化。本研究的主要目的是通过ML提供一种省时省力的工艺设计和操作方案,以及相关的预测模型,从而促进鸟粪石的回收利用。基于机器学习技术的应用,本研究可以更好地指导设计和优化鸟粪石回收工艺,为相关领域提供必要的信息和预测模型。
1 研究方法
1.1 数据收集与预处理
1.1.1 建立数据集
在学术数据库(如Web of Science、Scopus和中国知网等)中搜索模拟废水、磷回收、鸟粪石等关键词。在25篇文献中,整理了598条有效数据[14-38],数据集#1的输入变量为搅拌速率(stir)、反应时间(t)、反应温度(T)、pH、氮磷比(N∶P)、镁磷比(Mg∶P)和P初始浓度(P_initial),目标变量为P回收率(P_recovery);数据集#2来自于数据集#1中的422条数据,其中输入变量将Mg∶P替换成Mg∶N,输出变量为N回收率(N_recovery);数据集#3来自于数据集#1中的422条数据,输出变量为N回收率和P回收率。
1.1.2 数据处理
为了使输入和输出参数服从正态分布并且比例适当,在训练ML模型之前,基于式(1)对收集的数据集进行了标准化:
(1)
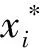
1.1.3 变量分析
根据式(2)所得的皮尔逊相关系数(PCC)计算两个变量之间的线性相关性:
(2)
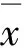
1.1.4 数据集划分
在进行ML建模之前,使用Python编程将整理好的数据集拆分为训练集和测试集。随机选取80%的数据点作为训练集,每个数据集中剩余20%的数据点(测试集)用于对训练后超参数最优的ML模型进行最终评估[40]。
1.2 机器学习建模
1.2.1 机器学习模型与超参数调优
本文选用RF和XGBoost两种算法探究模拟废水中鸟粪石的回收性能与搅拌速率、反应时间、反应温度、pH、N∶P、Mg∶P和P初始浓度之间的关系,预测N回收率和P回收率。RF采用集成学习的思想,包含多个决策回归树,每个回归树都尽可能多地增长,通过对原始训练集进行装袋和自举集成来解决回归问题[41]。RF模型的最终结果将是上述所有决策树的预测结果的平均值。在RF模型中,决策树的数量(n_estimators)和树的最大深度(max_depth)是两个关键的超参数,其他超参数是默认值。XGBoost算法是基于决策树的集成学习算法,采用梯度提升框架。它使用梯度提升技术以及几个串联开发的决策树,每个后续决策树都从前一个树的错误中学习和成长。当后续决策树足够深或前一树中不再有任何错误模式时,XGBoost学习将停止[42]。学习率(learning_rate)、n_estimators以及max_depth是模型训练过程中需要调整的基本超参数。这两种ML模型具有可解释性强、泛化能力强、训练时收敛速度快、对多特征数据适应性强等优势。
交叉验证是提高模型性能和避免过度拟合的常见策略。本文采用5倍交叉验证的方法对RF模型和XGBoost模型的超参数进行优化,将训练集随机分为五个部分。其中四部分用于模型训练查找ML模型的最佳超参数,其余一部分将用于评估性能。此过程迭代了五次,以确保五个部分对于模型都是可行的。然后使用五次验证的平均性能来确定ML模型的最佳超参数。超参数调优后,利用训练集对超参数最优的模型进行再训练,得到最优ML模型。在调优过程中,n_estimators和max_depth从2、4、8、16、32、64、128调优到150。此外,XGBoost模型的超参数学习率值得注意,通过学习率可缩小每棵树的贡献。学习率太小会减慢收敛率,而学习率太高会导致梯度在最小值附近振动,甚至无法收敛。
1.2.2 模型评估
使用决定系数(R2)、平均绝对误差(MAE)和平均均方根误差(RMSE)来评估ML模型在训练和测试过程中的预测性能。R2越大,MAE和RMSE越小,表示训练后的ML模型预测越准确,性能越好。R2、RMSE和MAE的计算方法如下:
(3)
(4)
(5)
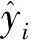
1.2.3 特征重要性分析
成功建立具有最优超参数的ML模型后,通过特征分析和部分依赖分析(PDP)对预测模型进行解释。用偏依赖图表示必要输入对输出的具体平均影响。基于合作博弈论策略的加性解释模型(SHapley Additive exPlanations,简称SHAP)[43]被用于ML模型的特征分析。具体而言,根据构建的ML模型计算SHAP值,以评估输入对预测输出的相对贡献和影响。
1.3 正向优化
基于最优的多目标ML模型进行优化,以获得在初始P浓度为10 mg/L和1 000 mg/L的情况下最高P回收率和N回收率所对应的最佳工艺参数。在进行优化之前,先利用Origin软件画出数据集中各输入变量的箱线图,根据图表剔除变量中的异常值,确定各变量的范围。在模型内按指定步长对各变量进行迭代,得到大量解,筛选出多目标ML模型中P回收率和N回收率权重各占0.5时的最优解。例如,在P回收率和N回收率多目标优化过程中,N∶P从0.4到1.5,步长为0.1;pH从8到10,步长为0.1;Mg∶P从0.4到2,步长为0.1;t从0到90,步长为20;搅拌速率从40到420,步长为50;初始P浓度为10 mg/L和1 000 mg/L;温度为25 ℃。通过整改项优化筛选出最佳参数后进行氮磷回收实验。
1.4 实验验证
1.4.1 储备液的配制
称取13.6 g的KH2PO4溶解于100 mL的去离子水中作为含P储备液,此储备液中P的浓度为1 mol/L。同时称取5.3 g的NH4Cl和9.5 g的MgCl2分别溶解于100 mL的去离子水中,配制1 mol/L的含N储备液和含Mg储备液。实验中所用到的药剂均为分析纯。
1.4.2 实验过程
使用移液枪将定量的KH2PO4溶液和NH4Cl溶液依次移入100 mL的去离子水中,用NaOH(2 mol/L)和稀盐酸(2 mol/L)调节溶液的pH到实验的设定值,之后根据指定的Mg∶P比立即加入定量MgCl2溶液,放到设定好参数的磁力搅拌器上搅拌。沉淀完成后,静置后使用0.45 μm过滤器对上清液进行过滤,采用钼酸铵分光光度法分析滤液中P的含量,计算P回收率并与最佳ML模型的预测值比较。
2 结果与讨论
2.1 数据集统计分析
表1显示了数据集的参数分布情况。由表可知,数据集#1中P回收率在35%~100%之间,由于数据集#2和数据集#3中的可用数据比数据集#1的数据要少,相较于数据集#1大多数变量的范围有所缩小。P回收率在58%~100%之间,而N回收率在5%~99%之间。差异是由7个输入变量的取值造成的。建立和优化以下模型,是识别和调节具有良好回收性能的鸟粪石的重要因素。

表1 数据集的参数分布
2.2 皮尔逊相关系数
为了评估输入变量是否可以为ML模型开发提供有价值的信息,本研究进行了皮尔逊相关系数(PCC)分析,分析结果如图1所示。

图1 皮尔逊相关性矩阵(PCC, **:显著性水平 p <0.01,*:显著性水平 p <0.05)Fig. 1 Pearson correlation matrix (PCC, **: significance level p<0.01, *: significance level p<0.05)
PCC的大小表示一个参数对另一个参数的影响程度,系数越大输入与输出的相关性越高,负值表示负相关。
如图1(a)所示,数据集#1的PCC中输入变量搅拌速率、P初始浓度、pH和N∶P与P回收率的相关性非常显著(p<0.01),搅拌速率和N∶P呈负相关;Mg∶P与P回收率的相关性显著(p<0.05),呈正相关。如图1(b)所示,数据集#2输入变量中搅拌速率、t、N∶P和P初始浓度与N回收率的相关性非常显著(p<0.01),其中P初始浓度呈正相关且最为关键;Mg∶N与N回收率呈显著相关(p<0.05)。如图1(c)所示,数据集#3中只有搅拌速率、T、N∶P和P初始浓度与P回收率显著相关(p<0.01)。图1(a)和(c)之间P回收率和其他变量的相关性差异主要是数据集大小和数据差异造成的,例如数据集#1和#3分别为598和422个数据点。
2.3 机器学习预测和模型解释
2.3.1 超参数调整
图2描述了在RF和XGBoost两种算法下超参数n_estimators和max_depth的变化对模型预测效果的影响。模型基于训练集数据对超参数进行调优,其中以R2作为评估标准。当n_estimators高于20而max_depth高于10时,XGBoost模型显示出令人满意的结果。模型的最佳n_estimators和max_depth参数分别为150、128、64和4、8、8。对于RF模型,当max_depth大于8时,随着n_estimators的增加,R2没有明显变化。因此,选择相对较小的max_depth可以避免预测模型的过度拟合。
根据上述超参数优化过程,将RF和XGBoost这两种模型预测结果最好时的超参数和模型性能结果汇总见表2。由此可知,XGBoost模型在单目标和多目标预测中表现出优于RF的性能,因此本文根据XGBoost模型对数据进行特征重要性分析。
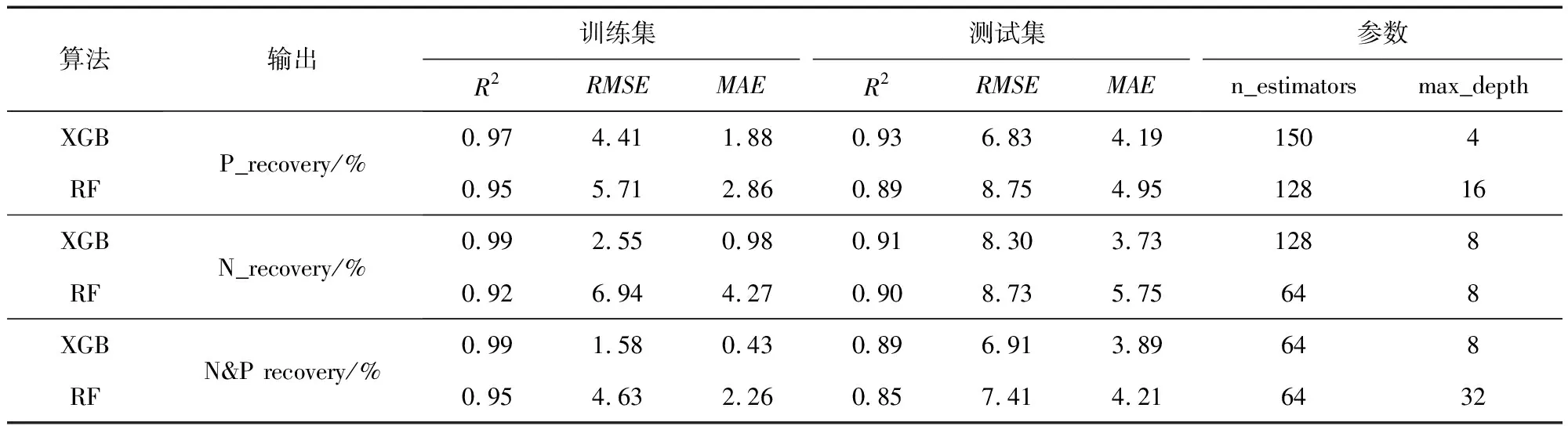
表2 超参数调优和模型性能结果汇总
2.3.2 P回收率单目标预测
利用整个训练集对具有最佳超参数的XGBoost模型进行再次训练,使用测试集进行测试,结果如图3(a)所示。模型XGBoost的最佳参数所对应的测试集R2、RMSE和MAE分别为0.93、6.83和4.19。图中平分虚线(y=x)表示预测值与实际值相等,点越靠近虚线表示预测性能越好。本次测试几乎所有的预测和实际训练点都集中在平分虚线上。由于ML模型的固有属性,ML模型对训练数据集的预测性能总是优于测试数据集[44],所以图中测试数据点的密度分布不如训练数据点紧密。

图3 P回收率单目标预测的预测性能(a)特征重要性分析(b)和部分依赖图(c~f)Fig. 3 Prediction performance (a), feature importance analysis (b),and partial dependence graph (c~f) of P recovery single-target prediction

2.3.3 N回收率单目标预测
由表2和图4(a)可知,模型XGBoost最佳超参数所对应的测试集R2、RMSE和MAE分别为0.91、8.30和3.73。图4(b)中特征重要性分析表明,Mg∶N是影响N回收率最显著的变量,其次是P初始浓度和N∶P。P初始浓度、Mg∶N以及N∶P决定了Mg和P对结晶的有效性,因此从图4(c~e)中可以看出Mg∶N<1.0时,Mg∶N的增加可以提高Mg对鸟粪石形成的有效性。高P初始浓度值和低N∶P值可以增强N回收率。同样的,图4(f)中pH对N回收率的影响趋势与图3(f)中pH对P回收率的影响趋势相同,pH在9.5左右的N回收率最高,由此可看出P的回收与N的回收主要以鸟粪石结晶沉淀实现。
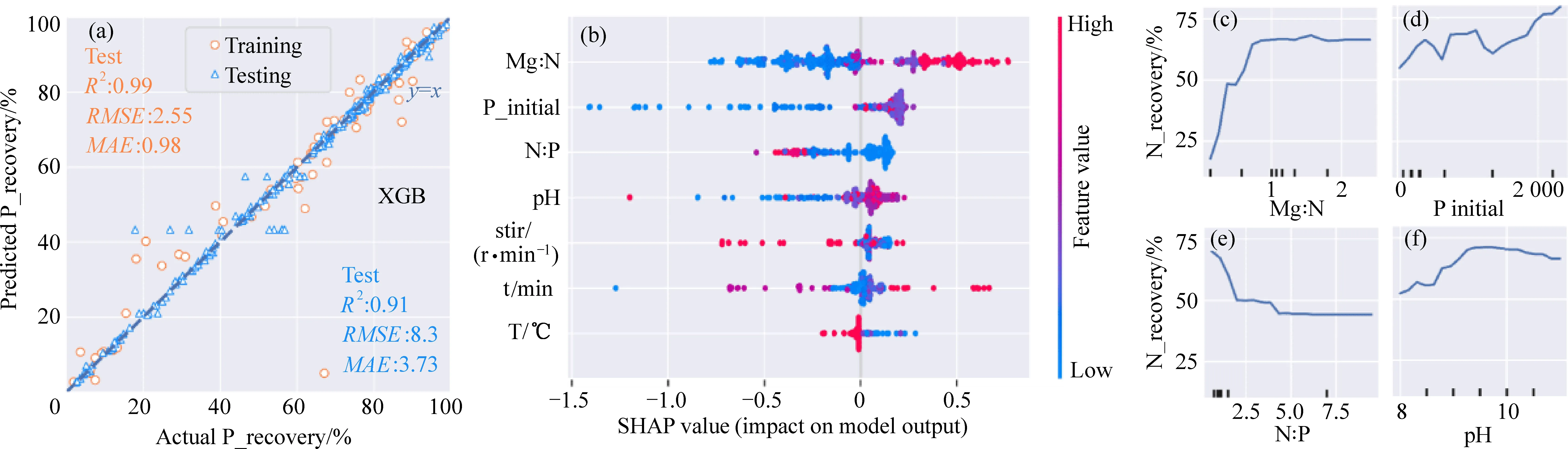
图4 N回收率单目标预测的预测性能(a)、特征重要性分析(b)和部分依赖图(c~f)Fig. 4 Prediction performance (a), feature importance analysis (b),and partial dependence plot (c~f) of N recovery single-target prediction
2.3.4 N、P回收率多目标预测
使用单目标预测模型超参数的调优方法对多目标预测模型的超参数进行调整。对P回收率和N回收率同时预测,XGBoost模型的最优超参数所对应的测试集R2、RMSE和MAE值分别为0.89、6.91和3.89,如图5(a)所示。多目标的预测结果逊色于单目标预测。但由于多目标预测数据集的变量范围较窄,泛化能力更好。
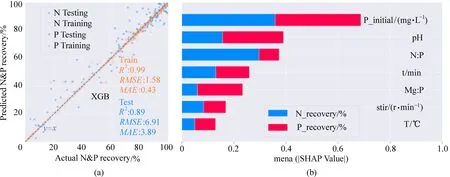
图5 N回收率和P回收率多目标预测的预测性能(a)和特征重要性分析(b)Fig. 5 Prediction performance (a) and feature importance analysis (b)of multi-objective prediction of N recovery rate and P recovery rate
特征重要性分析(图5(b))表明,P初始浓度是影响N、P回收率两个目标最显著的变量,其次是pH、N∶P、t和Mg∶P,搅拌速率和T的影响最不显著。
2.4 优化与验证
根据多目标预测的XGBoost模型筛选模型迭代得到的结果,可对N回收率和P回收率两个目标进行正向优化。在鸟粪石回收过程中,Mg含量是最需要考虑的因素,因此根据图5(b)中各参数的SHAP图,选出除Mg∶P以外的其他参数最优值。根据Mg∶P的比值从0.4到2,步长为0.1,对迭代结果进行筛选,P回收率和N回收率输出的和为优化目标,找到最优解。对最优解进行后续的实验验证,最优方案见表3。
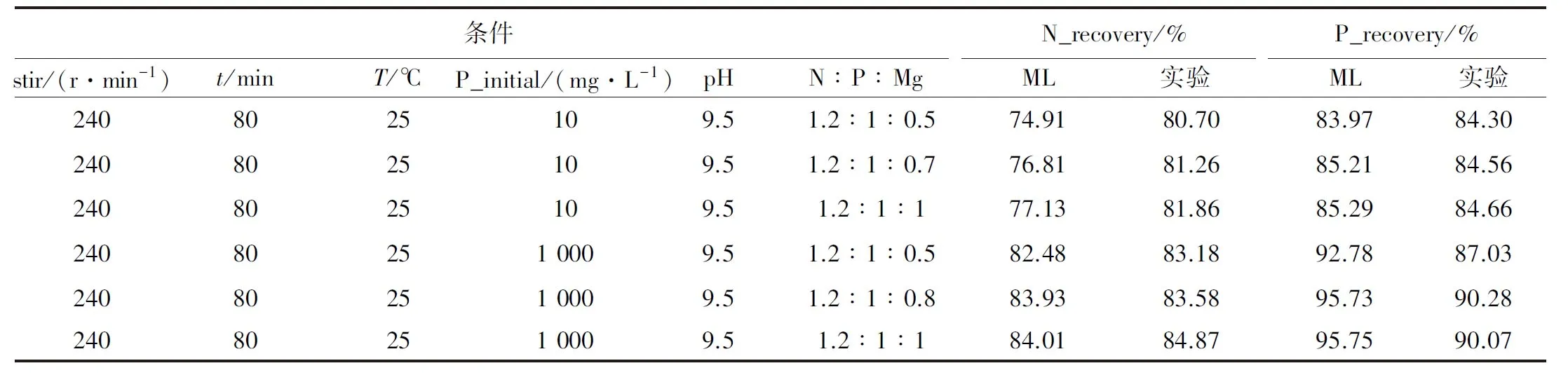
表3 基于ML模型的多目标正向优化最优方案
由表3可知,实验验证得到的结果与ML模型由表3可知,实验验证得到的结果与ML模型预测的最优解相差不大,这意味着本文所建立的机器学习模型具有良好的应用前景。
3 结 论
本文基于机器学习,对从模拟废水中回收鸟粪石这一问题进行了预测与优化。通过XGBoost和RF模型实现了P回收率和N回收率的单目标和多目标预测,其预测的R2分别为0.89~0.93和0.85~0.90。特征重要性分析表明,P初始浓度、N∶P、pH和Mg∶P对P回收率和N回收率有显著影响。利用XGBoost多目标模型成功预测和优化了鸟粪石结晶的最佳条件,并进行了实验验证。本研究证明了ML建模和实验验证相结合是一种促进鸟粪石结晶研究的有前景的方法。
