基于HHO-CNN-LSTM的CMAQ修正模型及其在上海市空气质量预报中的应用
2023-12-02郑鑫楠林开颜王孜竞宋远博路函悦张亚雷
郑鑫楠, 林开颜, 王孜竞, 宋远博,师 洋, 路函悦, 张亚雷 , 3, 沈 峥, *
(1. 同济大学 电子与信息工程学院, 上海 201804;2. 同济大学 新农村发展研究院, 上海 201804;3. 同济大学 环境科学与工程学院, 上海 200092)
0 引 言
大气环境污染物一般是由二氧化硫(SO2)、氮氧化物(NOx)、臭氧(O3)、一氧化碳(CO)等工业生产废物,以及PM10、PM2.5等固体粒子组成。这种污染物会引发肿瘤等各种病症,严重危害人们健康。随着中国经济社会发展和人民生活水平的提升,大气环境污染已成为我国目前存在的主要大气环境问题之一。因此,建立空气质量模型预测污染物的浓度对人类健康和环境管理具有重要意义。
目前传统的空气质量模型以区域多尺度空气质量模型(CMAQ)为代表,用数学方程模拟污染物传播时的物理化学反应机制,充分考虑了实际环境中污染物相互之间的变化与影响,因此得到广泛的应用。例如,ZHENG等[1]用非均相化学更新的CMAQ模型研究中国北方次生无机气溶胶的形成;ZHE等[2]使用CMAQ模型分析2013年严重雾霾期间河北源部地区和其他地区PM2.5的排放量;HU等[3]使用WRF-CMAQ模型,对2013年中国的臭氧和颗粒物进行了模拟;NAPELENOK等[4]使用CMAQ-ISAM模型研究十余种生物质燃烧对美国东南部PM2.5浓度的影响;KOO等[5]使用WRF-CMAQ模型预测了韩国首尔地区的PM10污染事件发生的时间和污染物的传输路径;WANG等[6]利用WRF-CMAQ模型模拟了香港地区O3在不同海拔地区的分布浓度以及其形成、扩散的物理化学过程。
CMAQ模型的预报需要将污染源排放清单作为数据输入,由于污染源种类繁多、分布面广和变化复杂,所以排放清单的编制工作需要较长的时间以及较多的人力,其制作过程决定了排放清单无法满足实时更新的要求;另外,CAMQ模型是基于“一个大气”的核心概念建立的,而人们对于大气这个异常复杂的系统的了解十分有限,无法对其中所有的大气传输、污染物扩散和化学反应等过程进行量化处理;污染源位置和高度、大气稳定度以及人口、燃料构成等对大气质量的影响和作用往往是非线性的[7],在应用偏微分方程来描述这些非线性作用时,又使用了大量的近似方法来简化求解过程。这些都是CMAQ模型的预测结果存在偏差的主要原因。为提高CMAQ模型预报能力,利用监测数据对模型预报结果进行统计修正的方法应用也较为普遍。谢敏等[8]尝试将监测数据直接作为预报初始值,结合CMAQ模型预报的增减量建立修正方法;王茜等[9]利用线性回归方法建立预测数据与监测数据之间的关系,降低了由于污染源不确定性产生的预报偏差;芦华等[10]使用多元线性回归方法对CMAQ模型的预报结果进行滚动订正,有效提高了模型的预报效果。SAYEED等[11]利用深度卷积神经网络(DCNN)对CMAQ模型进行修正和扩展,提高了模型在颗粒物浓度预测上的准确性。
近年来,由于人工智能的应用,不少深度学习算法也逐渐发展,如深度信念网络(DBN)、卷积神经网络(CNN)和循环神经网络(RNN)等。相比于传统的统计方法,深度学习算法能够处理更多非线性、非结构化的数据,具有更好的性能。一些研究人员已将其应用于空气质量研究,YI等[12]提出了一种基于深度神经网络的PM2.5浓度预测模型,使用卷积神经网络和循环神经网络进行特征提取和序列建模,并引入了注意力机制和残差连接以增强模型的表达能力;XAYASOUK等[13]提出了一种基于深度自编码器(DAE)和长短期记忆网络(LSTM)的空气污染物浓度预测方法,使用DAE对输入特征进行降维和特征提取,然后利用LSTM对时间序列数据进行预测;PAK等[14]提出了一种基于卷积神经网络和长短期记忆神经网络的混合模型(CNN-LSTM)用于预测臭氧浓度,并证实具有良好的精度。LI等[15]使用CNN-LSTM模型预测北京未来24小时PM2.5浓度,并通过比较得出CNN-LSTM模型具有误差小、训练时间短的优点。DU等[16]提出了由多个一维卷积神经网络和一个双向长短期记忆神经网络组成的混合CNN-BiLSTM模型,多个一维卷积神经网络用于提取多个监测站的空间相关性特征,双向长短期记忆神经网络可以学习时间序列数据过去和未来的特征,从而进行更有效的预测。
上述研究表明,CNN-LSTM模型在大气污染物浓度预测方面具有较好的性能。在此基础上,利用哈里斯鹰优化算法(HHO)寻找CNN-LSTM模型的最优超参数,可以使模型拥有更好的预测效果。本文将会在CMAQ模型对上海市污染物浓度进行预测的基础上,使用深度学习方法构建基于HHO-CNN-LSTM的修正模型。将CMAQ模型的预报数据以及影响污染物浓度的气象数据和污染物浓度实测数据作为HHO-CNN-LSTM模型的输入,进行污染物浓度再预测,从而实现对CMAQ模型预报结果的修正。
1 方 法
1.1 卷积神经网络
卷积神经网络(CNN)是一种包含卷积结构的深度前馈网络,由于其强大的特征提取能力,卷积神经网络已被广泛用于时间序列数据分析[17]。卷积神经网络可以提取空间结构中多维时间序列数据之间的关系,它由输入层、卷积层、池化层、全连接层和输出层组成。其中,卷积层的特征提取主要是通过卷积核进行的,它可以捕捉污染物数据中存在的时间依赖性[18];池化层主要用于特征降维,减少参数的数量,防止过拟合。经过卷积层和池化层作用后的特征进入全连接层后进行再整合,最终转化成一维向量。在本研究中,可以将模型的输入数据样本看作一个二维矩阵,其中横轴表示时间维度,纵轴表示特征维度。卷积核在时间维度上进行滑动,对每个时间点附近的特征进行卷积操作。通过多层不同大小的卷积核的叠加,卷积神经网络可以不断提取时间维度上的更高级别特征,从而获得更好的预测效果。
1.2 长短期记忆神经网络
长短期记忆神经网络(LSTM)是一种改进的循环神经网络。通过引入门结构(Gate),用门结构决定序列上信息的去留,记住需要长时间记忆的信息,过滤不重要的信息,解决了循环神经网络的长期依赖问题[19]。它被提出后也进行了改良,增加了额外的遗忘门。改良后的长短期记忆神经网络解决了模型训练中“梯度消失”的问题,可以学习时间序列长短期依赖信息,是目前最成功的循环神经网络架构,应用于许多场景中。在本研究中,大气污染物浓度数据和气象数据属于时间序列数据,当前时刻的状态通常与过去时刻的状态有关。通过长短期记忆神经网络的“遗忘门”“输入门”和“输出门”等机制,学习并记忆过往时刻的状态信息,可以有效地对时间序列数据进行预测。
1.3 哈里斯鹰优化算法
神经网络模型包含许多超参数,如神经网络层数、学习率、神经元数量等,选取最优的超参数能显著提高模型的精度和拟合度。传统的超参数选取往往依赖于研究者的个人经验或者每个超参数组合的效果[20],这种做法需要耗费大量的时间。优化算法的应用可以减少超参数搜索的时间,增强模型的预测效果[21]。近年来,基于种群的元启发式算法——群智能优化算法开始应用于神经网络的超参数优化[22-24]。
哈里斯鹰优化算法(HHO)是Heidari在2019年提出的一种群智能优化算法,具有参数少、搜索精度高和简单易行的优点[25]。该算法由哈里斯鹰对猎物的追捕行为演化而来,其具体流程如图1所示。根据猎物能量E和捕获概率r的变化,哈里斯鹰会执行不同的追逐策略。其中,哈里斯鹰为候选解,猎物为最优解,哈里斯鹰捕捉猎物的过程即为候选解向最优解迭代的过程。
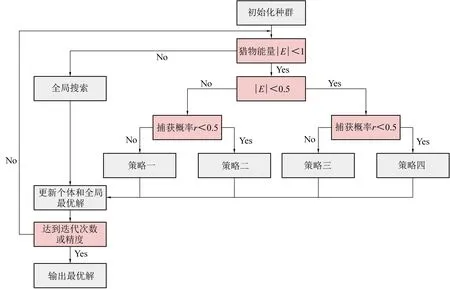
图1 哈里斯鹰优化算法流程示意图Fig. 1 Flowchart of Harris Hawks Optimization algorithm
1.4 基于HHO优化的CNN-LSTM模型
由于卷积神经网络具有较好的特征提取能力,长短期记忆神经网络在处理时间序列问题上有较大的优势,同时也能避免梯度消失的问题,因此本研究选择将卷积神经网络与长短期记忆神经网络相结合构建模型,具体结构如图2所示。模型的前半部分是卷积神经网络,用于特征提取,提取的信息经过最大池化层(Max-Pool)和Dropout层处理后,可有效防止其过拟合;模型的后半部分是长短期记忆神经网络,用于时间序列数据的预测,LSTM层的输出结果经过全连接层(FC)的展平操作后,最终变为一维的预测数据进行输出。
CNN-LSTM混合神经网络有卷积层卷积核大小、卷积核数量、LSTM层神经元数量、批次大小等超参数,这些超参数的选取会显著影响模型的性能。因此本文使用哈里斯鹰优化算法对CNN-LSTM模型进行优化,寻找到最优的超参数,提高模型的预测精度。
哈里斯鹰算法优化CNN-LSTM模型的具体步骤如图3所示。每个哈里斯鹰个体代表一组超参数,通过计算适应度值对个体进行排序,选取表现最好的一部分个体,作为新一轮迭代的种群,重复迭代直到达到最大迭代次数或找到满意的超参数组合为止。
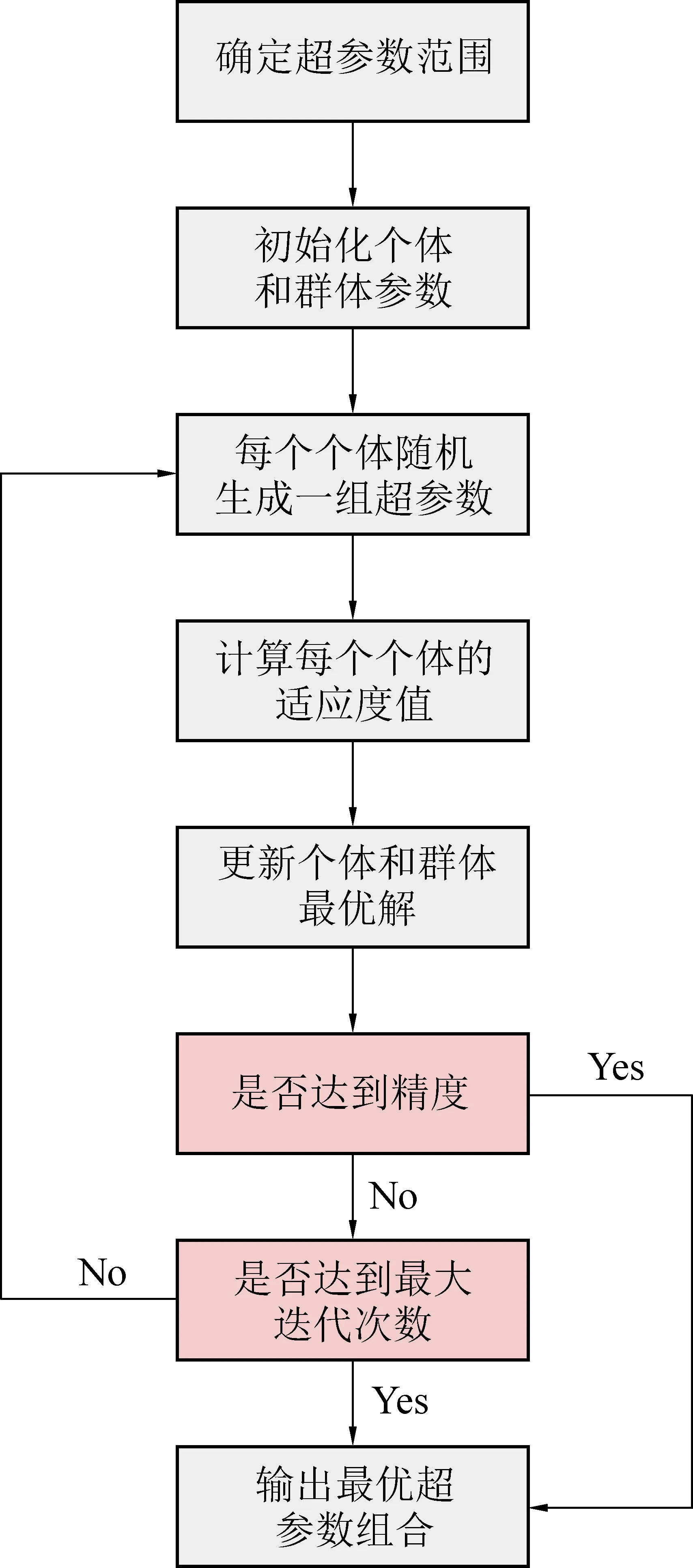
图3 HHO优化CNN-LSTM模型流程示意图Fig. 3 Flowchart of HHO-optimized CNN-LSTM model
2 实 验
2.1 实验数据
本文研究使用2022年12月1日至2022年12月31日上海市徐汇区上海师范大学空气质量监测站的大气污染物浓度数据和徐家汇气象站的气象数据。大气污染物数据来自中国环境监测总站,包括二氧化硫(SO2)、二氧化氮(NO2)、可吸入颗粒物(PM10)、细颗粒物(PM2.5)、一氧化碳(CO)和臭氧(O3)的逐小时监测数据。我们将其作为实测数据,后续用于修正模型的训练和比较。气象数据来自国家气象信息中心,包括温度、湿度、气压、风速和风向的逐小时监测数据,后续作为影响污染物浓度的气象因子用于修正模型的训练。
2.2 基于CMAQ模型的污染物浓度预测
CMAQ模型是美国环保署(EPA)开发的第三代空气质量预报模型。通过输入气象数据和排放源清单,CMAQ模型使用数学算法和反应动力学模型对大气中各种污染物的传输、化学反应、扩散等过程进行建模和模拟,从而预测不同时间和空间范围内污染物的浓度分布情况。化学传输模块是CMAQ模型的核心,包括扩散模块、平流模块、气象化学模块、气溶胶模块等,用于模拟和预测污染物的化学反应、输送和扩散过程。
本研究使用CMAQ模型对上海市2022年12月1日至2022年12月30日的空气污染物浓度进行逐时预报。空气质量预报模型模拟区域采用Lambert投影坐标系,坐标中心点为31°N、121°E,设置两层嵌套网格,第一层网格水平分辨率为27公里,网格数为100×100;第二层网格水平分辨率为9公里,网格数为103×103。CMAQ模型自2022年12月1日开始,每日0时起报,预报未来72小时的污染物浓度。将相同时间点的预报数据进行均值化处理,得到了上海市2022年12月1日至2022年12月30日的空气污染物(SO2、NO2、PM10、PM2.5、O3、CO)浓度逐小时预报数据。将其作为CMAQ预报数据后续用于修正模型的训练和比较。
2.3 修正模型的训练
本研究使用哈里斯鹰算法优化的CNN-LSTM模型作为污染物浓度的修正模型,对CMAQ模型的预报结果进行修正。考虑到污染物浓度与气象条件紧密相关,同时污染物之间存在复杂的化学反应[26],修正模型的输入特征包括气象因子(温度、湿度、气压、风速、风向)和除自身外其他5项污染物浓度的实测数据以及该项污染物的CMAQ预报数据,共计11个特征,输出数据为该项污染物浓度的实测数据。实验数据的时间范围为2022年12月1日0时至2022年12月30日23时,时间步长为1小时,共计720条数据。对实验数据进行划分,设置训练集、验证集和测试集的比例为7∶2∶1并进行归一化处理。
将处理好的数据输入模型后,开始使用哈里斯鹰算法对CNN-LSTM的超参数进行寻优迭代。需要优化的超参数包括卷积核大小、卷积核数量、批次大小、第一层LSTM神经元个数、第二层LSTM神经元个数、最大迭代数和学习率。确定每个超参数的寻优范围,通过HHO迭代找到最优的超参数。将最优的超参数组合应用于CNN-LSTM模型,当模型完成训练之后便可得到新的污染物浓度预测值,从而实现对CMAQ模型预报结果的修正。
3 结果与讨论
3.1 污染物浓度修正结果
基于HHO优化的CNN-LSTM大气污染物浓度修正模型对CMAQ预测数据的修正结果如图4所示。选择均方根误差(RMSE)、平均绝对误差(MAE)和一致性指数(IOA)作为评价指标来评价模型的预测效果。均方根误差和平均绝对误差反映预测值与实测值的数值偏差,一致性指数反映预测值与实测值的一致性。三个评价指标的计算公式如下:

图4 污染物浓度修正结果Fig. 4 Correction results of pollutant concentration
(1)
(2)

(3)


表1 修正前后的评价指标结果
由图4可以明显看出经过深度学习算法修正后的CMAQ预报数据(CMAQ-DL)相比修正前(CMAQ)更贴近实测值。根据表1可知,修正后的模型预测结果在均方根误差、平均绝对误差,和一致性指数三项评价指标上均表现得更加优异。六项污染物浓度的预测误差都大幅降低,RMSE减少了73.11%~91.31%,MAE减少了67.19%~89.25%。各项污染物浓度的预测值与实际值的一致性也都有显著提升,IOA提升了35.34%~108.29%。相比之前学者采用的线性回归方法(IOA从0.564提升至0.721)[9],HHO-CNN-LSTM模型对CMAQ预报结果的修正效果更好。这是因为本研究考虑了更多维度的影响因素,且神经网络方法在处理高维度和非线性数据上具有较大的优势。
其中CO的IOA虽有很大提升,但相比于其他污染物,CO的IOA仍然较低,一方面可能是因为CMAQ模型对CO的预测精度较低,从而影响了神经网络的训练;另一方面可能是因为HHO-CNN-LSTM模型性能上的问题,接下来将对修正模型的性能进行检验。
3.2 模型比较
为了检验HHO-CNN-LSTM模型的性能,本文将其与CNN-LSTM、LSTM、支持向量机(SVM)三个模型进行比较。选取2022年12月的实测数据与CMAQ预报数据,使用上述四个模型对CMAQ预报结果进行修正,同样选择均方根误差、平均绝对误差和一致性指数作为评价指标,结果见表2。

表2 模型比较
比较表1和表2可以看出,四个模型修正后的预测值均更加接近实际值。其中,CNN-LSTM模型对六项污染物浓度的预测效果均好于LSTM模型,可见卷积层在特征提取方面的优势。HHO-CNN-LSTM模型在SO2、NO2、PM10、PM2.5、O3这五种污染物浓度的修正效果上优于其他三个模型,相比于CNN-LSTM模型,HHO-CNN-LSTM模型预测值的RMSE减少了6.30%~18.80%,MAE减少了2.91%~22.82%,IOA提升了1.10%~5.73%,这是因为哈里斯鹰算法在训练过程中为混合神经网络找到了最优的超参数,提高了模型的预测性能。然而,在CO浓度的预测中,HHO-CNN-LSTM模型的结果并不理想,在三项评价指标的表现上不如其他三个模型,这可能是因为哈里斯鹰算法在超参数迭代过程中陷入了局部最优[27],本文将针对这个问题对哈里斯鹰算法进行改进。
3.3 改进的哈里斯鹰优化算法及其表现
针对哈里斯鹰算法可能在对模型进行优化的过程中陷入了局部最优而导致对CO浓度预测效果不佳的问题,本文在算法迭代寻优过程中加入了高斯随机游走策略来对算法进行改进。利用优势种群的平均值来判断算法是否陷入停滞,当优势种群的平均值在连续两次迭代过程中没有变化,则认为算法陷入停滞。此时利用高斯随机游走策略生成新个体进而帮助哈里斯鹰算法跳出局部最优。高斯随机游走策略的公式如下:
X(t+1)=Gaussian(X(t),σ)
(4)
(5)
式(4~5)中σ为随机游走的步长,X为从优势种群中随机选择的一个个体,t和T分别为当前迭代次数和最大迭代次数。通过余弦函数在迭代前期施加较大扰动,迭代后期扰动迅速减小,进而平衡了算法的寻优能力。
将使用高斯随机游走策略改进后的哈里斯鹰算法应用于修正模型进行CO浓度的预测,结果如图5所示。由图5可知,基于改进的HHO优化的CNN-LSTM模型(GHHO-CNN-LSTM模型)在CO浓度的预测效果上有了很大提升,预测值比其他模型更接近实际值。此外,将改进前后的修正模型进行比较(见表3),发现两者在SO2、NO2、PM10、PM2.5、O3五种污染物浓度上的预测效果相差无几,可见两个模型都在算法的优化下找到了最优的超参数组合。而在CO浓度的预测上,相比于改进前的HHO-CNN-LSTM模型,GHHO-CNN-LSTM模型在三项指标的表现上均有了显著提升,RMSE减少了39.55%,MAE减少了45.93%,IOA提高了32.43%。可见加入了高斯随机游走策略的哈里斯鹰算法有效解决了传统哈里斯鹰算法在寻优迭代过程中易陷入局部最优的问题,提高了修正模型在CO浓度上的预测精度。
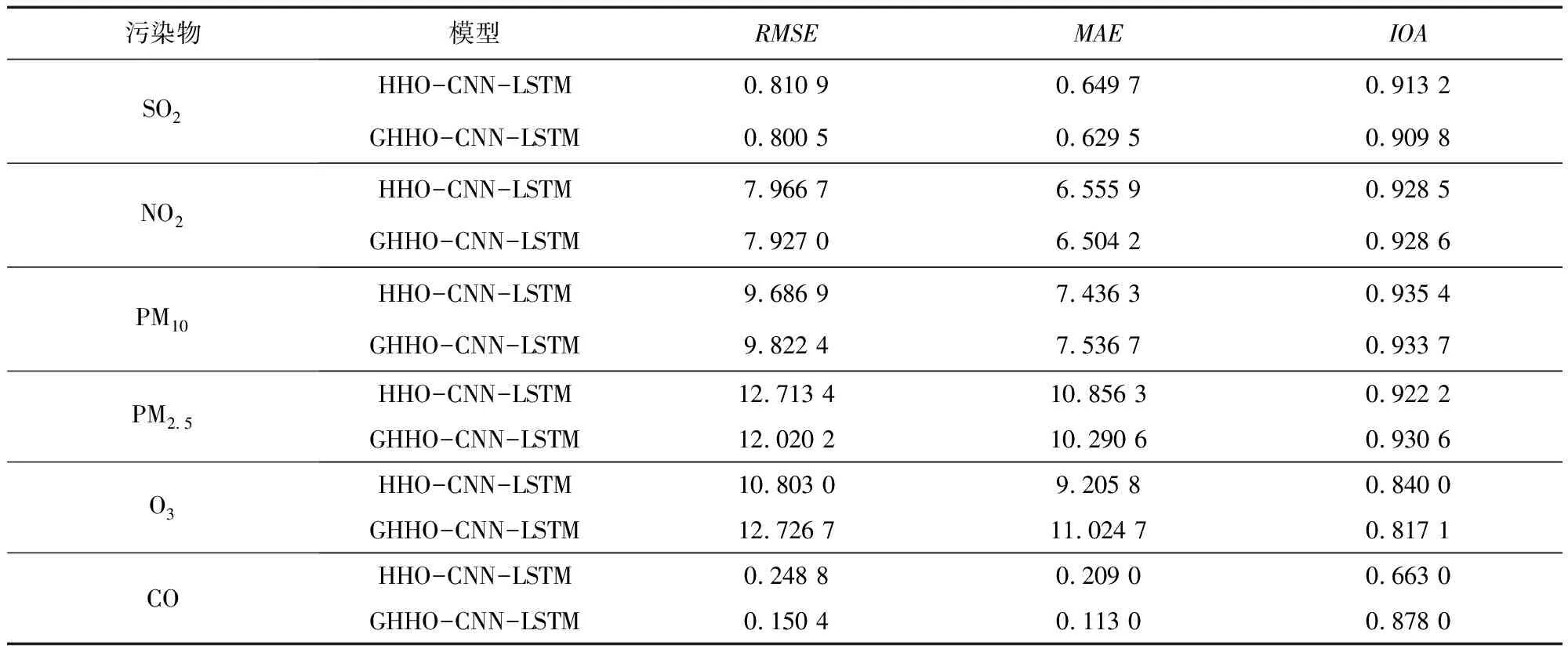
表3 改进前后的模型评价指标结果

图5 CO浓度预测结果Fig. 5 Prediction results of CO concentration
4 总 结
在日益加剧的空气污染严重影响人们身体健康和社会经济发展的背景下,建立空气质量模型预测污染物浓度具有重要意义。然而传统的空气质量模型CMAQ对污染物浓度的预报精度并不理想。基于此,本文在使用CMAQ模型对上海市2022年12月六种大气污染物(SO2、NO2、PM10、PM2.5、O3、CO)浓度进行预测的基础上,建立HHO-CNN-LSTM模型对预报结果进行修正,显著提高了预测精度,RMSE减少了73.11%~91.31%,MAE减少了67.19%~89.25%,IOA提升了35.34%~108.29%。并针对HHO算法陷入局部最优而导致对CO浓度修正效果不佳的问题,使用高斯随机游走策略对算法进行改进,提高了修正模型在CO浓度上的预测精度。与改进前相比,RMSE减少了39.55%,MAE减少了45.93%,IOA提高了32.43%。本文的工作为人工智能技术与传统空气质量模型的结合提供了思路,为大气污染物的防治作出了贡献。
然而,基于深度学习的预测方法也存在其局限性。例如,在中长期预测中可能会出现显著误差以及面临“缺乏可解释性”和“对极端天气条件的不准确预测”等挑战。因此,在未来的研究中,可以用更大时间尺度上的数据训练该模型,并将反映基础物理机制的数学方程式纳入神经网络架构中,以此建立一个具有更强的普适性和可解释性的空气质量预测模型。
