基于深度强化学习的无人机集群协同作战决策方法
2023-11-29赵琳吕科郭靖宏晨向贤财薛健王泳
赵琳,吕科,郭靖,宏晨,向贤财,薛健,王泳
基于深度强化学习的无人机集群协同作战决策方法
赵琳1,吕科1,郭靖2,宏晨3,向贤财1,薛健1,王泳4*
(1.中国科学院大学 工程科学学院,北京 100049; 2.沈阳航空航天大学 电子信息工程学院,沈阳 110136; 3.北京联合大学 机器人学院,北京 100101; 4.中国科学院大学 人工智能学院,北京 100049)( ∗ 通信作者电子邮箱wangyong@ucas.ac.cn)
在无人机(UAV)集群攻击地面目标时,UAV集群将分为两个编队:主攻目标的打击型UAV集群和牵制敌方的辅助型UAV集群。当辅助型UAV集群选择激进进攻或保存实力这两种动作策略时,任务场景类似于公共物品博弈,此时合作者的收益小于背叛者。基于此,提出一种基于深度强化学习的UAV集群协同作战决策方法。首先,通过建立基于公共物品博弈的UAV集群作战模型,模拟智能化UAV集群在合作中个体与集体间的利益冲突问题;其次,利用多智能体深度确定性策略梯度(MADDPG)算法求解辅助UAV集群最合理的作战决策,从而以最小的损耗代价实现集群胜利。在不同数量UAV情况下进行训练并展开实验,实验结果表明,与IDQN(Independent Deep Q-Network)和ID3QN(Imitative Dueling Double Deep Q-Network)这两种算法的训练效果相比,所提算法的收敛性最好,且在4架辅助型UAV情况下胜率可达100%,在其他UAV数情况下也明显优于对比算法。
无人机;多集群;公共物品博弈;多智能体深度确定性策略梯度;协同作战决策方法
0 引言
智能化的无人机(Unmanned Aerial Vehicle,UAV)适合应用在高速、复杂和多变的现代军事行动当中,智能UAV集群具备更高的自主性,可以在复杂的对抗博弈中找到最优的决策[1]。将UAV投入战场既降低了作战成本又大幅减少了人员伤亡,具有明显的作战优势。多集群UAV协同作战的攻击模式能够应对更复杂的作战任务,同时完成多目标打击。因此在任务中提高多UAV集群间的配合,以及平衡多UAV之间的利益博弈,成为提高作战效率、降低损耗的关键研究[2]。
UAV的自主机动决策能力直接影响了它在智能战争中的胜率。但空战中的决策问题研究具有多智能体、动作空间大、维度高、视野长等特点,因此求解困难。通常采用智能算法求最优解[3],或引入博弈论求均衡解[4]。近些年随着强化学习的发展,强化学习算法在解决UAV空战决策问题中起到了越来越重要的作用。
UAV及集群对抗中的决策问题研究主要分为两类:一类是研究UAV在空战中姿态、位置与速度的决策占优问题,另一类是研究集群中UAV决策比例问题。其中,第一类研究成果相对丰富,如利用深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法[5]处理UAV连续空间动作问题:文献[6-7]中利用DDPG算法建立UAV空战中的决策模型,提高了机动决策的自主控制精度;文献[8]中为提高DDPG算法效率,利用最大熵逆强化学习算法构造奖励结构,解决空战决策稀疏奖励问题,同时将正则化引入策略网络,加强了决策模型在不完全信息环境中的鲁棒性。以上研究成果为UAV空战中的一对一智能决策模型,DDPG算法在处理多智能体问题时会变得不稳定,基于它改进的多智能体深度确定性策略梯度(Multi-Agent DDPG, MADDPG)算法[9]则更适合解决UAV集群决策问题。文献[10]中在战前只掌握敌方部分火力信息的前提下,基于MADDPG算法构造了动态UAV集群任务决策模型,验证了MADDPG算法在处理多机决策问题时的稳定性更强。
在实际作战中,决策的优劣也体现在控制己方资源及损耗上。UAV执行的任务未必是单一的,可能是连续的多段任务。此外,由于UAV在执行任务中很难补充资源,分配过多资源给其中一项任务将导致个体生存能力的降低,这也是第二类UAV空战决策研究的目的及关键。
目前公共物品博弈在社会性研究之中比较广泛,理性个体倾向于在单次任务中保持自身实力。为了将UAV更加智能化,将博弈思想引入UAV集群执行任务,此时个体UAV对集体的贡献低,自身损耗小,但是对UAV集群完成任务会产生消极影响。UAV个体利益与集群利益产生冲突,个体的奖励与损失模型可以视为公共物品博弈模型。由于UAV作战场景的特殊性,目前的相关研究还较少,其中禹明刚等[11]基于多元公共品演化博弈求解UAV集群对抗中个体选择为集体贡献者的比例。受该研究的启发,为了提高UAV决策中的智能性,本文提出一种基于深度强化学习的UAV集群协同作战决策方法。该方法设计了一种异构UAV集群协同对地攻击决策模型,根据集群中UAV的价值和载荷,为UAV分配不同的作战攻击任务,实现两编队UAV集群协同打击目标,分别是主攻目标的打击型UAV集群和牵制敌方的辅助型UAV集群;同时,辅助型UAV集群制定决策时面临着公共物品博弈,在能检测敌方火力信息的前提下,利用MADDPG算法求解辅助型UAV集群动态最优的作战决策。
1 UAV集群合作对地攻击模型
UAV集群合作对地攻击模型的场景如图1所示,我方作为攻击方为蓝方,拥有由携带炮弹的UAV集群组成空中力量;敌方作为防御方为红方,拥有对UAV能产生有效打击的地面防空力量。蓝方目标为打击红方碉堡,红方采取防御反击。蓝方由两编队UAV集群共同组成:一队为执行打击目标(碉堡)任务的打击型UAV集群,另一队为牵制红方火力的辅助型UAV集群。假定红方没有特殊武器和空中拦截能力,主要的防空力量组成为坦克部队(RT)、防空导弹部队(RD)和碉堡(R)的自身防御系统。
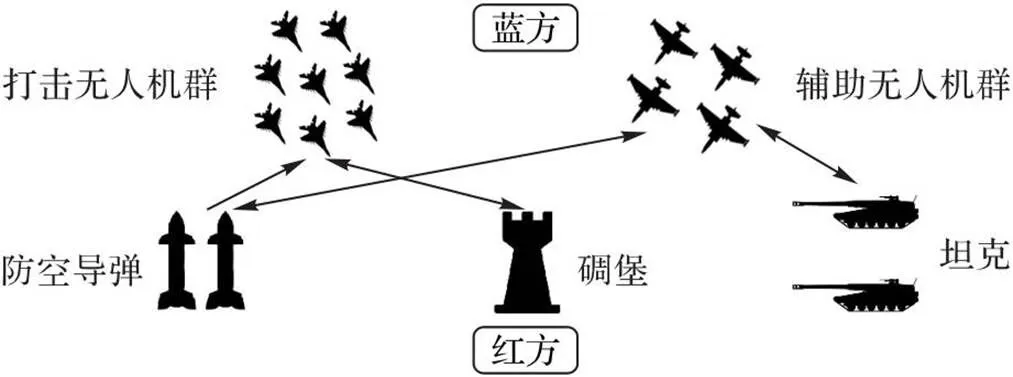
图1 UAV集群协同对地攻击模型
蓝方在完成自身任务的同时,为降低自身损耗,保证任务结束之后仍有更好的战斗力,会派出两支载荷不同的UAV队伍:负责打击目标的UAV集群自身价值较低,但是携带可以有效攻击碉堡的弹药;协同辅助的UAV集群自身价值较高,除携带弹药外还携带干扰弹。文献[12]中提到UAV释放干扰弹可以诱骗敌方红外制导武器脱离真目标,因此本文中假设UAV可以通过释放干扰弹的方法避免受到敌方攻击伤害。
1.1 辅助型UAV集群决策模型


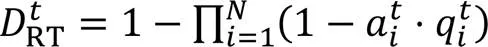
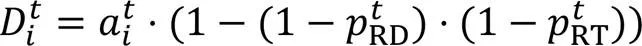

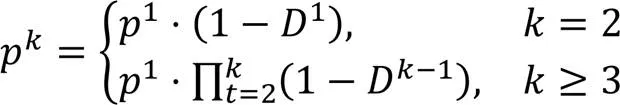
1.2 打击型UAV集群攻击模型
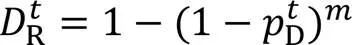

1.3 公共物品博弈模型
传统的公共物品博弈是指向公共池中投入资源,参与者可共享投资结果的博弈方式,研究成本与收益之间的关系,带阈值的公共物品博弈设置了取得回报的门槛,符合作战中为UAV集群对敌方打击设置成功条件。智能性提高了集体中个体的自私性,在对抗中,UAV的搭便车行为虽然会带来更高的收益,但利用合适的奖惩机制,它的选择将受到最终合作效果的约束。UAV作战博弈中涉及的参与者数量多、对抗过程较长,传统的博弈论求解方法很难直接在此应用。因此本文利用MADDPG算法[9]求解此问题,构建了合适的奖励函数,既满足UAV智能化要求,又避免集体发生“公地悲剧”。
2 基于MADDPG算法的UAV集群协同作战决策模型
2.1 基于MADDPG算法的模型
本文利用MADDPG算法[9]训练UAV集群协同作战决策,MADDPG算法可以视为DDPG算法[5]的多智能体版本变体。DDPG算法由DQN(Deep Q-Network)与确定性策略梯度(Deterministic Policy Gradient, DPG)组合得到。DPG是Actor-Critic算法的变体,DPG结构上具有两个神经网络:策略网络(Actor)与价值网络(Critic)。DPG改进Actor,使它输出确定行为,在此基础上引入DQN后增加了经验回放与双网络,使Actor与Critic分别增加了一个目标网络,提高了价值网络的稳定性。在复杂的动态多UAV场景下,多个UAV同时与环境交互,每架UAV的决策在训练中变化也会成为造成环境的变化从而影响其他UAV决策。不稳定的环境会影响DDPG算法收敛,而采用集中训练和分散执行框架的MADDPG算法可以使每架UAV所处的环境仍然可以被视为稳定。MADDPG算法的主要改进点是利用可观察全局信息的Critic指导Actor进行个体训练。

图2 基于MADDPG算法的模型结构
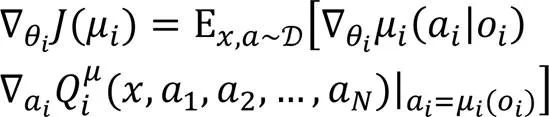

2.2 奖励函数设计
在深度强化学习模型中,影响UAV行为的主要因素是奖励结构。参照文献[14],如果相互合作的奖励大于个体的奖励最大化,则个体倾向于学习寻求协作解决任务的策略。本文模型的特征可以近似为公共物品博弈模型,理性UAV想要保留实力拒绝贡献,但集群为了完成任务需要UAV贡献。为了平衡理性个体利益与集体利益间的冲突,本文设计了引导UAV“搭便车”行为的奖励函数,UAV输出动作后,环境依据奖励函数返回对应奖励。
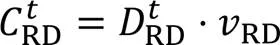
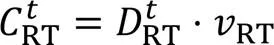


同样按照图3可以对右侧底板进行分析(图4),得出巷道左侧的极限破坏深度y′1和沿滑动面KJ的有效滑动力T′1为
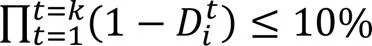
5)在每步攻击后,判断碉堡情况,根据表1中的条件判断打击碉堡任务是否完成。

表1 判断 k 步攻击后任务成败的条件
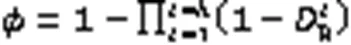
3 实验与结果分析
3.1 实验环境及参数设计
本文使用TensorFlow框架构建训练网络,训练时硬件环境:AMD Ryzen 9 5950X CPU,Nvidia RTX3090显卡,内存64 GB。


表2 作战单位给对方造成的初始毁伤概率
3.2 实验结果及分析
为验证本文算法的有效性,另外建立了基于IDQN(Independent DQN)[15]与ID3QN(Imitative Dueling Double DQN)[16]这两种算法的模型与本文算法进行对比,使用的超参数与本文一致。
训练中得到的辅助UAV集群在每一回合累计奖励变化如图3所示。每种算法各训练3次,图3中线条代表3次实验均值,阴影代表3次实验标准差,可以看出,本文算法收敛效果稳定。随着训练次数的增加,使用本文算法训练辅助UAV集群在5 000回合训练后即可学习到最大奖励,在训练回合数达到2万回合后,累计奖励曲线趋于平缓,总体呈收敛趋势,最优决策下获得的累计奖励为515.132;而另外两种算法训练效果较差,IDQN无法在探索到的最大奖励处收敛,而ID3QN趋向收敛至负奖励。
辅助UAV集群基于三种算法训练得到的攻击决策,使打击碉堡任务成功的比率如图4所示。利用本文算法训练UAV的获胜比率为100%,在经过6 000回合训练呈收敛趋势。结合图3可以看出,只有基于本文算法训练的辅助UAV集群在最大奖励处收敛得到的决策方法,可保证打击碉堡任务得以完成。

图3 采用3种算法得到的累计奖励收敛曲线
由于本文算法将辅助型UAV的最优决策作为训练目标,因此通过修改辅助型UAV数这一参数,并调整奖励函数,对比三种算法下的多智能体强化学习模型,验证辅助型UAV数对模型结果的影响,实验结果如图5所示。从图5可以看出,修改UAV数对实验结果的影响显著。在不改变打击型UAV数的前提下,三种算法都无法让3架辅助UAV完成任务。与4架辅助UAV的情况相比,增加辅助UAV数导致结果不稳定,但相较于其他两种对比算法,本文算法的优势更明显。

图4 3种算法训练UAV的获胜比率
通过分析以上实验结果可知:一方面,在多UAV混合关系的强化学习环境中,辅助型UAV之间既存在合作关系也包含了竞争关系,增加UAV数的同时会增加混合关系复杂性,难以预知将给实验结果带来消极或积极的影响;另一方面,本文实验也验证了在构建的多UAV集群公共物品博弈的环境下,MADDPG算法是针对多智能体环境进行设计的,具有针对集中训练、分散执行的特点,能适用于不稳定的多智能体环境问题。MADDPG算法假定每个智能体都拥有自己的奖励函数,使智能体在混合关系模型中能够自适应地调整策略,增强稳定性,更适用于解决个体与集体收益冲突的实际问题。
4 结语
在公共物品博弈中,理性个体在合作中会产生“搭便车”的行为,虽然这种行为可以帮助个体节约成本、减小损失,但是会对集体产生威胁。本文通过设置奖励函数构建了公共物品博弈框架,利用MADDPG算法训练UAV集群学习到最好的作战决策。通过实验验证,当UAV集群在对敌时自身力量超过敌方力量时,UAV可以利用MADDPG算法在个体利益与集体利益的博弈中学习,选择最优决策,有效避免发生“公地悲剧”。
本文除了基于MADDPG算法训练外,同时与IDQN与ID3QN这两种算法进行对比实验,从累计奖励曲线和任务成功率曲线可以验证本文算法在多智能体中应用的有效性。
本文为不同价值的UAV主观分配了作战任务,但为了更好地适应实际战斗时变性,在未来的研究里UAV应根据价值与载荷不同自主分配作战任务。同时在下一步研究中,将结合UAV性能及作战特点,在对抗中添加更多随机的影响因素,构造自主机动生成UAV对战决策方法,更广泛适用于复杂的真实战场环境。
[1] AYAMGA M, AKABA S, NYAABA A A. Multifaceted applicability of drones: a review[J]. Technological Forecasting and Social Change, 2021, 167: No.120677.
[2] 马子玉,何明,刘祖均,等. 无人机协同控制研究综述[J]. 计算机应用, 2021, 41(5):1477-1483.(MA Z Y, HE M, LIU Z J, et al. Survey of unmanned aerial vehicle cooperative control[J]. Journal of Computer Applications, 2021, 41(5): 1477-1483.)
[3] 黄长强,赵克新,韩邦杰,等. 一种近似动态规划的无人机机动决策方法[J]. 电子与信息学报, 2018, 40(10): 2447-2452.(HUANG C Q, ZHAO K X, HAN B J, et al. Maneuvering decision-making method of UAV based on approximate dynamic programming[J]. Journal of Electronics Information Technology, 2018, 40(10): 2447-2452.)
[4] 李世豪,丁勇,高振龙. 基于直觉模糊博弈的无人机空战机动决策[J]. 系统工程与电子技术, 2019, 41(5): 1063-1070.(LI S H, DING Y, GAO Z L. UAV air combat maneuvering decision based on intuitionistic fuzzy game theory[J]. Systems Engineering and Electronics, 2019, 41(5): 1063-1070.)
[5] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-05) [2023-03-27].https://arxiv.org/pdf/1509.02971.pdf.
[6] YANG Q, ZHU Y, ZHANG J, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm[C]// Proceedings of the IEEE 15th International Conference on Control and Automation. Piscataway: IEEE, 2019: 37-42.
[7] LI Y, HAN W, WANG Y. Deep reinforcement learning with application to air confrontation intelligent decision-making of manned/unmanned aerial vehicle cooperative system[J]. IEEE Access, 2020, 8: 67887-67898.
[8] KONG W, ZHOU D, YANG Z, et al. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning[J]. Electronics, 2020, 9(7): No.1211.
[9] LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]// Proceedings of the 31st Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6382-6393.
[10] 李波,越凯强,甘志刚,等. 基于MADDPG的多无人机协同任务决策[J]. 宇航学报, 2021, 42(6): 757-765.(LI B, YUE K Q, GAN Z G, et al. Multi-UAV cooperative autonomous navigation based on multi-agent deep deterministic policy gradient[J]. Journal of Astronautics, 2021, 42(6): 757-765.)
[11] 禹明刚,何明,张东戈,等. 基于多元公共品演化博弈的无人作战集群策略占优条件[J]. 系统工程与电子技术, 2021, 43(9): 2553-2561.(YU M G, HE M, ZHANG D G, et al. Strategy dominance condition of unmanned combat cluster based on multi-player public goods evolutionary game[J]. Systems Engineering and Electronics, 2021, 43(9): 2553-2561.)
[12] 邢炳楠,杜忠华,杜成鑫. 采用弹道修正技术的红外干扰弹性能优化[J]. 国防科技大学学报, 2022, 44(2): 141-149.(XING B N, DU Z H, DU C X. Performance optimization of infrared interference decoy based on trajectory correction technique[J]. Journal of National University of Defense Technology, 2022, 44(2): 141-149.)
[13] 黄捷,陈谋,姜长生. 无人机空对地多目标攻击的满意分配决策技术[J]. 电光与控制, 2014, 21(7): 10-13, 30.(HUANG J, CHEN M, JIANG C S. Satisficing decision-making on task allocation for UAVs in air-to-ground attacking[J]. Electronics Optics and Control, 2014, 21(7): 10-13, 30.)
[14] GRONAUER S, DIEPOLD K. Multi-agent deep reinforcement learning: a survey[J]. Artificial Intelligence Review, 2022, 55(2): 895-943.
[15] TAMPUU A, MATIISEN T, KODELJA D, et al. Multiagent cooperation and competition with deep reinforcement learning[J]. PLoS ONE, 2020, 12(4): No.e0172395.
[16] 相晓嘉,闫超,王菖,等. 基于深度强化学习的固定翼无人机编队协调控制方法[J]. 航空学报, 2021, 42(4): No.524009.(XIANG X J, YAN C, WANG C, et al. Coordination control method for fixed-wing UAV formation through deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(4): No.524009.)
UAV cluster cooperative combat decision-making method based on deep reinforcement learning
ZHAO Lin1, LYU Ke1, GUO Jing2, HONG Chen3, XIANG Xiancai1, XUE Jian1, WANG Yong4*
(1,,100049,;2,,110136,;3,,100101,;4,,100049,)
When the Unmanned Aerial Vehicle (UAV) cluster attacks ground targets, it will be divided into two formations: a strike UAV cluster that attacks the targets and a auxiliary UAV cluster that pins down the enemy. When auxiliary UAVs choose the action strategy of aggressive attack or saving strength, the mission scenario is similar to a public goods game where the benefits to the cooperator are less than those to the betrayer. Based on this, a decision method for cooperative combat of UAV clusters based on deep reinforcement learning was proposed. First, by building a public goods game based UAV cluster combat model, the interest conflict problem between individual and group in cooperation of intelligent UAV clusters was simulated. Then, Muti-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm was used to solve the most reasonable combat decision of the auxiliary UAV cluster to achieve cluster victory with minimum loss cost. Training and experiments were performed under conditions of different numbers of UAV. The results show that compared to the training effects of two algorithms — IDQN (Independent Deep Q-Network) and ID3QN (Imitative Dueling Double Deep Q-Network), the proposed algorithm has the best convergence, its winning rate can reach 100% with four auxiliary UAVs, and it also significantly outperforms the comparison algorithms with other UAV numbers.
Unmanned Aerial Vehicle (UAV); multi-cluster; public goods game; Multi-Agent Deep Deterministic Policy Gradient (MADDPG); cooperative combat decision-making method
1001-9081(2023)11-3641-06
10.11772/j.issn.1001-9081.2022101511
2022⁃10⁃13;
2023⁃04⁃19;
国家重点研发计划项目(2018AAA0100804)。
赵琳(1998—),女,辽宁盘锦人,博士研究生,主要研究方向:深度强化学习、无人机集群控制、博弈论; 吕科(1971—),男,宁夏西吉人,教授,博士,CCF会员,主要研究方向:人工智能、计算机视觉; 郭靖(1997—),男,陕西咸阳人,硕士,主要研究方向:深度强化学习、无人机集群控制; 宏晨(1974—),男,宁夏青铜峡人,副教授,博士,主要研究方向:无人机集群控制; 向贤财(1997—),男,湖北施恩人,硕士研究生,主要研究方向:深度强化学习、多智能体系统控制; 薛健(1979—),男,江苏宜兴人,教授,博士,CCF会员,主要研究方向:多智能体系统控制、图像处理; 王泳(1975—),男,山东济南人,研究员,博士,主要研究方向:复杂系统建模与优化、模式识别、数据挖掘。
V279+.2
A
2023⁃04⁃21。
This work is partially supported by National Key Research and Development Program of China (2018AAA0100804).
ZHAO Lin, born in 1998, Ph. D. candidate. Her research interests include deep reinforcement learning, unmanned aerial vehicle cluster control, game theory.
LYU Ke, born in 1971, Ph. D., professor. His research interests include artificial intelligence, computer vision.
GUO Jing, born in 1997, M. S. His research interests include deep reinforcement learning, unmanned aerial vehicle cluster control.
HONG Chen, born in 1974, Ph. D., associate professor. His research interests include unmanned aerial vehicle cluster control.
XIANG Xiancai, born in 1997, M. S. candidate, His research interests include deep reinforcement learning, multi-agent system control.
XUE Jian, born in 1979, Ph. D., professor. His research interests include multi-agent system control, image processing.
WANG Yong, born in 1975, Ph. D., research fellow. His research interests include modeling and optimization of complex systems, pattern recognition, data mining.
