基于多尺度阶梯时频Conformer GAN的语音增强算法
2023-11-29金玉堂王以松王丽会赵鹏利
金玉堂,王以松*,王丽会,赵鹏利
基于多尺度阶梯时频Conformer GAN的语音增强算法
金玉堂1,王以松1*,王丽会1,赵鹏利2
(1.公共大数据国家重点实验室(贵州大学),贵阳,550025; 2.许昌电气职业学院,河南 许昌 461000)( ∗ 通信作者电子邮箱yswang@gzu.edu.cn)
针对频率域语音增强算法中因相位混乱产生人工伪影,导致去噪性能受限、语音质量不高的问题,提出一种基于多尺度阶梯型时频Conformer生成对抗网络(MSLTF-CMGAN)的语音增强算法。将语音语谱图的实部、虚部和振幅谱作为输入,生成器首先在多个尺度上利用时间-频率Conformer学习时域和频域的全局及局部特征依赖;其次,利用Mask Decoder分支学习振幅掩码,而Complex Decoder分支则直接学习干净的语谱图,融合这两个Decoder分支的输出可得到重建后的语音;最后,利用指标判别器判别语音的评价指标得分,通过极大极小训练使生成器生成高质量的语音。采用主观评价平均意见得分(MOS)和客观评价指标在公开数据集VoiceBank+Demand上与各类语音增强模型进行对比,结果显示,所提算法的MOS信号失真(CSIG)和MOS噪声失真(CBAK)比目前最先进的方法CMGAN(基于Conformer的指标生成对抗网络语音增强模型)分别提高了0.04和0.07,尽管它的MOS整体语音质量(COVL)和语音质量的感知评估(PESQ)略低于CMGAN,但与其他对比模型相比在多项主客观语音质量评估方面的评分均处于领先水平。
语音增强;多尺度;Conformer;生成对抗网络;指标判别器;深度学习
0 引言
语音增强是去除环境噪声、共振噪声、电磁噪声等干扰的重要手段,是语音分析和识别的关键技术[1],旨在通过去除音频中的混合噪声以恢复高质量和高可懂度的语音。
传统语音增强方法包括谱减法[2]、维纳滤波[3]、基于统计模型的方法[4]和子空间算法[5]等,基本思想是假定加性噪声和短时平稳的语音信号相互独立的条件下,从带噪语音中去除噪声;但这类方法只能处理平稳噪声,在处理非平稳噪声和低信噪比信号时性能大幅降低。随着深度学习的出现,基于数据驱动的语音增强技术成为主要的研究趋势。自20世纪80年代起就有将神经网络用于语音增强的方法[6],随后也出现了基于深度神经网络(Deep Neural Network, DNN)、循环神经网络(Recurrent Neural Network, RNN)、卷积神经网络(Convolutional Neural Network, CNN)和生成对抗网络(Generative Adversarial Network, GAN)的方法。
早期基于深度学习的语音增强方法通过短时傅里叶变换(Short Time Fourier Transform, STFT)将一维的语音信号转换为二维的频率域语谱进行去噪,但由于相位混乱且缺乏时间和结构上的规律性,会对语音增强带来巨大干扰,因此许多方法主要关注重建振幅特征而忽略了相位分量。如Wang等[7-8]最早将深度学习应用到语音增强任务,使用DNN学习理想二值掩蔽值(Ideal Binary Mask, IBM),直接将有噪语音信号映射到干净语音信号,但DNN存在参数量大、难以提取上下文特征等问题。随后,Weninger等[9]利用RNN对语音上下文特征信息进行建模,又进一步采用长短期记忆(Long Short-Term Memory, LSTM)神经网络对语音信号进行去噪重建[10];但RNN存在训练时间长、网络规模大、难以并行化处理等缺点。Park等[11]提出了基于CNN的编码-解码器网络RCED,通过输入前几帧的带噪振幅谱预测当前干净的振幅谱。与RNN相比,这种基于CNN的模型有更小的参数量、训练时间更短,但存在感受野受限、提取上下文特征能力弱等问题。为了缓解传统CNN的问题,张天骐等[12]采用门控机制和扩张卷积神经网络,在扩大感受野的基础上,门控机制可以较好地提取上下文特征。
然而越来越多的研究表明,当同时对语谱的振幅和相位分量进行优化时,语音的主客观感知质量会大幅提升,尤其是在低信噪比的情况下[13]。为了同时涵盖振幅和相位信息、避免相位混乱问题,有研究工作将语音的频率域语谱转换至笛卡尔坐标系得到复数域频谱,对复数域特征进行增强的同时也隐含地增强了振幅和相位分量。如Tan等[14]结合CNN和RNN,提出了一种门机制卷积循环神经网络(Gated Convolutional Recurrent Network, GCRN),在增加感受野的同时,门控循环神经网络能较好地提取上下文特征信息,重建干净的复数域频谱。此外也有研究直接对原始一维语音信号进行增强,如Parveen等[15]提出了Wave‑U‑Net模型,采用一维U‑Net架构通过有监督的方式学习有噪声频到干净语音的映射,利用扩张卷积扩大对语音信号的感受野,同时还能保持少量参数。为了提高重建语音的真实性和可懂度,有研究利用GAN进行语音增强。如Pascual等[16]提出语音增强生成对抗网络(Speech Enhancement Generative Adversarial Network, SEGAN),利用基于CNN的生成器对原始的一维音频信号进行特征提取,直接映射到干净的一维语音信号,来自判别器的对抗损失也间接提升了重建语音的质量,但由于判别器未学习对应语音质量判别标准,该方法的效果相较于传统方法提升不明显。为了解决这一问题,Fu等[17]提出了指标生成对抗网络语音增强模型MetricGAN,利用判别器学习评价指标函数,使之能代替评价指标预测音频质量,解决评价指标不可微分的问题,同时优化生成器生成信号的评价指标分数,从而重建出具有更高语音感知质量和可懂度的语音。
近年来,Transformer[18]因可并行、能处理长时间依赖的优势在语音识别、自然语言处理和图像分割等领域取得了成功,也有研究将它应用于语音增强。如Kim等[19]在Transformer模型中引入高斯加权矩阵,提出了带有高斯加权的注意力机制,通过网络学习振幅谱的掩码,将该掩码与带噪语音信号振幅谱相乘得到干净语音振幅的估计,然后结合原始带噪语音信号的相位逆短时傅里叶变换(Inverse Short Time Fourier Transform, ISTFT)重构干净语音信号。为了更好地捕获音频信号中的局部特征和全局依赖,Gulati等[20]提出了结合CNN和Transformer的模型Conformer,在语音识别领域取得了显著的成果。Cao等[21]提出了一种基于Conformer的MetricGAN——CMGAN,用于在振幅谱和复数域频谱上进行语音增强。CMGAN的生成器包含基于时频的两级Conformer模块,能捕获时间域和频率域的长距离依赖和局部特征,它采用的指标判别器作用与MetricGAN相同,有助于提高生成语音的质量,同时不会对其他指标产生不利影响。
本文针对频率域语音增强中因相位混乱产生人工伪影、去噪性能受限、语音质量不高的问题,提出一种多尺度阶梯型时频Conformer生成对抗网络(Multi-Scale Ladder-type Time-Frequency CMGAN, MSLTF-CMGAN)算法用于单通道语音增强。MSLTF-CMGAN由一个生成器和一个指标判别器组成:生成器采用编码-解码器结构,包含一个编码器、一个多尺度阶梯型时频Conformer(MultiScale Ladder-type Time-frequency Conformer, MSLTFC)模块和两个解码器(掩码解码器和复数解码器),用于生成增强后的复数域频谱;指标判别器由扩张卷积网络组成,用于预测重建语音的音频质量。
本文工作包括:
1)提出一种基于MSLTF-CMGAN的语音增强算法,在频谱上多尺度地进行局部-全局表示学习,既能学习局部细节特征,又能捕获全局长距离依赖;此外,通过在不同尺度的特征图上学习的方式,在保留特征的同时解决了CMGAN中使用原维度特征图计算开销大的问题,加速了模型训练。
2)采用指标判别器预测重建语音的评价指标得分,有助于提升生成器生成语音的质量。
3)在公开数据集VoiceBank+Demand[22]上的实验结果表明,本文算法取得了可行有效的去噪效果,消融实验也验证了本文的多尺度阶梯型结构提升了语音增强的效果。
1 语音增强问题描述



频率域的语音增强,首先需要对语音信号进行STFT得到语音的频谱,即


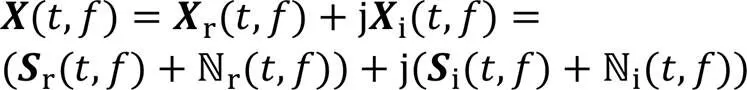
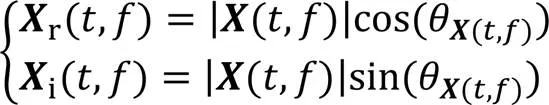
2 本文算法
2.1 语音增强模型原理
为了充分利用时间域和频率域信息进行语音增强,本文提出了MSLTF-CMGAN,它由一个基于时频卷积自注意力的生成器(图1~3)和一个用于预测评价指标得分的判别器(图4)组成,通过两者的极大极小训练来提升生成器的去噪能力以重建高质量的干净语音。下面分别对生成器和判别器的具体结构和语音增强的原理进行详细的介绍。
2.1.1基于多尺度阶梯时频Conformer的生成器
生成器网络结构如图1所示,它由一个稠密链接扩张卷积编码器Dense Encoder、一个MSLTFC模块和两个解码器组成(分别是掩码解码器Mask Decoder和复数解码器Complex Decoder)。

图1 生成器网络结构

通过幂律压缩[23]获得特征增强后的频谱:
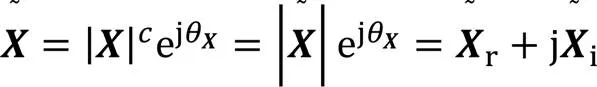







其中表示ISTFT。
从上述去噪过程可以看出,本文提出的MSLTFC模块可以从全局和细节上充分提取时域和频域特征,有效去除持续性的低频噪声和碎片化的高频噪声,不同尺度的音频特征相结合也可提升语音增强的质量,减少人工伪影。模型的两个解码器在有效保留语音主体的同时也规避了相位混乱导致的问题。

图3 Conformer模块的网络结构
2.1.2指标判别器
在语音增强任务中,模型的目标函数往往不能直接表示评价指标,并且一些评价指标函数是不可微分的,如语音质量的感知评估(Perceptual Evaluation of Speech Quality, PESQ)[24]和短时客观可懂度(Short-Time Objective Intelligibility, STOI)[25]。本文受MetricGAN启发,提出了一个轻量指标判别器来模拟语音评价指标函数,并将评价得分添加至模型训练损失以提升语音增强效果。
如图4所示,指标判别器包含4个卷积模块,每个模块包含二维卷积层、实例标准化层(IN)和参数化修正线性单元(Parametric Rectified Linear Unit, PReLU)激活函数。之后是1个最大值池化层和2个线性层,在2个线性层之间引入了PReLU激活函数和Dropout层以避免梯度消失和过拟合问题。模型最后是Sigmoid函数,将它的输出限制在[0,1],输出越小表示语音质量越差,相反输出越大表示语音质量越好。
该指标判别器将有噪声频振幅谱和干净语音振幅谱作为输入,判别器通过学习能够准确预测去噪后语音的PESQ/STOI得分。此外生成器通过对抗训练会生成PESQ/STOI得分越来越高的语音。

图4 指标判别器的网络结构
2.2 损失函数

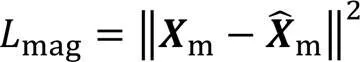

此外,本文还在时间域波形信号间应用了L1损失,如式(16)所示:



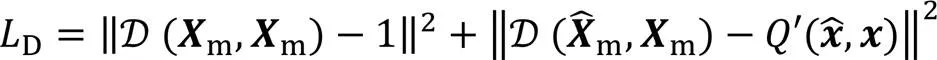

2.3 算法框架
本文算法的步骤如下:
输入有噪语音样本;干净语音样本;生成器模型;判别器模型;
初始化:0;0
forfrom 1 to
3 实验与结果分析
本文实验环境为Linux Ubuntu18.04操作系统,GPU显卡Tesla V100,显存32 GB以及CUDA 11.4、PyTorch1.11和Python3.8的软件平台。
3.1 实验数据集
为了验证本文算法的有效性,采用公开的经典数据集VoiceBank[26]+Demand[27]比较本文模型和前沿的基线模型。该数据集包含28个用于训练的人声和2个用于测试的未知人声,训练集包含11 572个有噪-干净音频数据对,测试集包含824个数据对,音频长度在2~15 s不等。训练集中的音频样本混合了10种噪声中的任意一种(包括2种人声噪声和8种来自Demand数据集的环境噪声),且按信噪比{0 dB,5 dB,10 dB,15 dB}添加噪声。测试集使用Demand数据集中5种未出现在训练集的噪声创建样本,按信噪比{2.5 dB,7.5 dB,12.5 dB,17.5 dB}添加噪声。数据集中的噪声类型广泛,如公共环境噪声(餐厅和办公室)、家庭噪声(厨房和客厅)以及交通噪声(地铁、公交和汽车)等,使该数据集具有挑战性。
3.2 实验设置
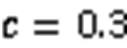
3.3 基线模型
为了体现本文算法对语音增强的效果,与近年来前沿的模型进行比较,基线模型包括传统方法维纳滤波(Wiener)和其他深度学习模型。其中,SEGAN、HiFiGAN[28]、MetricGAN、MetricGAN+[29]、DVUGAN[31]和CMGAN是基于GAN的模型,它们的生成器用于去除噪声、提升音频质量,判别器用于区分干净音频和带噪声频。SEGAN是首次使用GAN进行语音增强的方法,它的生成器是一个编码-解码的全卷积结构模型,用于在时域上进行语音增强。HiFIGAN包括一个前馈WaveNet生成器网络和一个时频多尺度判别器,利用对抗训练进行语音增强。MetricGAN基于来自判别器的评价得分损失训练生成器,生成器将振幅特征图作为输入和输出,通过反傅里叶变换得到增强后的音频,指标判别器解决了评价指标如PESQ、STOI计算不可微的问题,有效地提升了重建语音的质量。MetricGAN的改进版本MetricGAN+优化了损失并在模型中添加了可学习的Sigmoid函数,对不同频率段有更强的适应性。PHASEN[30]提出了双流的深度神经网络结构,分别用于处理幅度和相位,有助于频谱重建。DVUGAN设计具有变分编码结构的对抗网络模型,采用包含概率瓶颈的变分U-Net,增加未知数据分布的先验知识,还利用信噪比(Signal⁃to⁃Noise Ratio, SNR)损失指导判别器,提升了语音增强性能。TSTNN[32]提出了时域两级Transformer神经网络,能有效提取长距离语音序列的局部和全局上下文信息。DB-AIAT[33]提出了双分支Transformer结构网络,包括振幅分支和复数域分支,一起重建去噪后的频谱。DPT‑FSNet[34]提出了一种基于Transformer的全频段结合子频段的双路网络,用于在频率域进行语音增强。CMGAN由MetricGAN得到启发,设计了两阶段的Conformer模块提取时间域和频率域特征,达到了此前最高的PESQ/STOI得分。
3.4 评价指标
本文采用多种语音质量评价指标,如主观评价平均意见得分(Mean Opinion Score, MOS)[35],包括MOS信号失真CSIG(MOS prediction of the signal distortion)、MOS噪声失真CBAK(MOS predictor of intrusiveness of background noise)和MOS整体语音质量COVL(MOS prediction of the overall effect),三个评价指标数值均在[1,5];此外还采用了客观评价指标PESQ和STOI。PESQ用于语音质量的感知评估,数值在[-0.5,4.5],本文使用的是ITU-TP.862.2建议书提供的宽带PESQ。STOI用于评价语音可懂度,数值在[0,1]。对于以上5种评价指标,数值越高均表示语音质量越高。
3.5 模型对比实验
为了评估模型的语音增强性能,在VoiceBank+Demand数据集上与维纳滤波(Wiener)和前述的基线模型进行对比,结果如表1所示。

表1 不同算法在VoiceBank+Demand数据集上的性能评估

此外,还对本文算法在VoiceBank+Demand测试集上的结果进行了可视化,展示了不同算法增强的音频信号与频谱图,效果如图5所示。

图5 不同算法增强的语音信号的语谱图可视化
为了更明显地展现音频特征,本文将频谱转换至dB标度,即对原频谱取对数,残差图中颜色越红(即越接近色彩标度尺上方颜色)表示差值越大,反之越蓝表示差值越小(越趋近于0)、越接近干净语音。图5(a)为原始有噪声频,可以看出时域波形和频谱中存在大量噪声;图5(b)为对应干净语音,作为对比标签;图5(c)为维纳滤波增强后的语音,可见滤波后去除了高频和低频噪声,但是中段频率没有明显的去除效果;图5(d)为SEGAN增强语音,可见去噪效果较维纳滤波均有提高,但对低频噪声的去除效果较差,仍存在肉眼可见的白噪声,实际听感表现为机械化的电流杂音;而MetricGAN的提出解决了这一问题,图5(e)为MetricGAN增强语音,所有频段白噪声明显减少,语音可懂度较原始有噪声频大幅提高;图5(f)为CMGAN增强语音,在各频段均有去噪效果,在低频部分也更加接近干净语音,同时语音中没有音素的部分也有效地去除了噪声;图5(g)为本文算法增强语音,可见在高频部分和低频部分均能很好地去除噪声,在没有人声的时间段能有效去除无关的音素,整体和放大细节上均能明显看出去噪效果,且残差图显示与干净语音相差分贝小,语音质量和可懂度高。通过以上对比可以看出,本文算法在语音增强方面表现更好,在时间域和频率域都能明显去除噪声,以恢复高质量的干净语音。
3.6 消融实验
为了验证本文MSLTFC模块嵌入到网络中的提升效果以及模型设计的合理性,设计了如下消融实验:首先研究不同Conformer的组合方式对特征提取的效果,将两个Conformer分别以并行和串行的方式提取时间域和频率域特征;其次,研究两个Decoder的去噪性能,分别仅保留Mask Decoder和Complex Decoder;再次,分别研究不进行降采样的Conformer结构和采用多尺度时频Conformer的去噪性能;最后研究有无指标判别器对语音增强效果的影响。
表2展示了消融实验的结果对比,此外对测试样例绘制了消融实验结果图,如图6所示。图6(a)是有噪语音样例,频谱中黑框部分表示前部的一段尖锐持续噪声;图6(b)是对应的干净语音。表2中Parallel-Conformer表示两个Conformer以并行方式连接,分别用于提取时间域和频率域特征,传入的特征图变形以适配各自的维度,经过Conformer以后再变形为原始特征图维度并相加,结果表明,并行方式的语音增强效果低于顺序方式,它的CSIG和PESQ比MSLTF-CMGAN分别低了0.14和0.06,测试效果如图6(c)所示。
表2中Mask Decoder表示输入只使用了振幅谱,除了仅有一个掩码解码器以外其余网络结构保持不变,输出的重建振幅谱与原始相位相结合得到去噪后的频谱。同样的,Complex Decoder表示仅有复数解码器且只是用复数域频谱作为输入,直接输出重建复数频谱。将两种方式进行对比,由表2可知,仅采用振幅谱而忽略相位信息导致它的CSIG比MSLTF-CMGAN降低了0.22,同时仅采样复数频谱时PESQ降低了0.08。图6(d)、(e)分别为Mask Decoder和Complex Decoder语音增强效果,两者均去除了尖锐噪声,但在其他频段Complex Decoder去噪效果要稍优于Mask Decoder,如其中黑框部分所示。该结果也表明本文提出的掩码解码器结合复数解码器形成了互补的结构,在提升语音质量和可懂度方面有显著优势。
表2中Without Downsample表示不采用多尺度阶梯时频Conformer模块,取而代之使用三个不改变特征图维度的时频Conformer模块用于提取时频特征。结果表明,不采用多尺度阶梯时频Conformer模块在CSIG、CBAK、COVL上比MSLTF-CMGAN分别降低了0.31、0.33和0.25,此外如图6(f)所示,在去除无关音素和高频噪声时较本文算法有所不足。这说明本文提出的多尺度阶梯时频Conformer模块能进一步抓取音频结构上和细节上的特征,达到更高的语音增强质量。
最后,本文还验证了指标判别器对于语音增强模型的提升作用,Without Discriminator表示没有引入指标判别器进行对抗训练,由表2可知,这导致了语音增强模型在各项指标均有下降,由图6(g)可知,虽然去除了高低频噪声,但是引入了黑框中条纹形的噪声,实际听感表现为电流杂音,降低了语音的质量,这反映了只将频谱之间的闵可夫斯基距离(Minkowski distance,即Lp距离)作为损失函数并不能得到较高的语音质量。此外图6(h)所示为本文算法增强语音,各频段去噪效果显著,相较于图6(g),黑框部分也表明引入指标判别器显著提升了重建语音的质量。

表2 消融实验结果
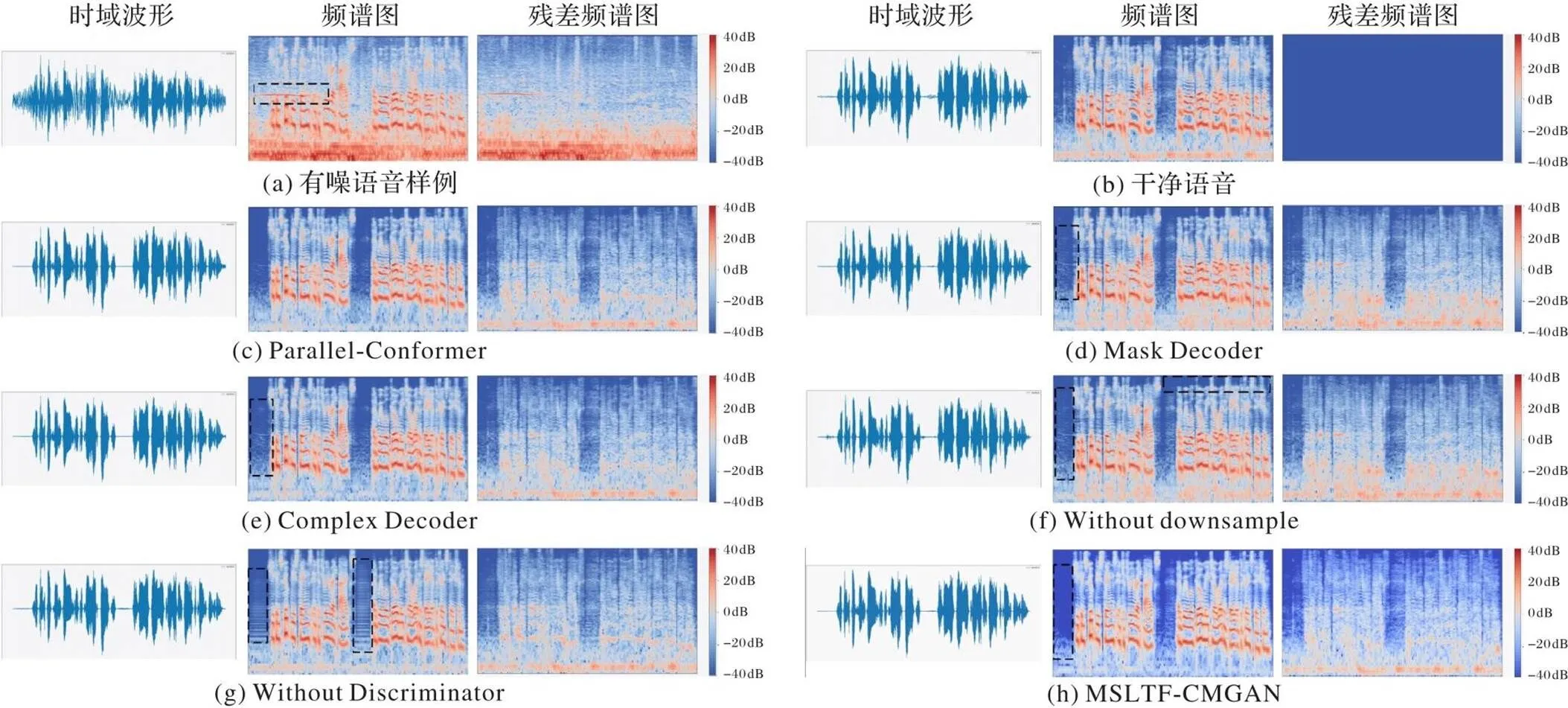
图6 消融实验的语谱图可视化
4 结语
本文提出了多尺度阶梯型时频Conformer生成对抗网络(MSLTF-CMGAN),用于去除音频中的噪声以恢复更高的语音质量。通过短时傅里叶变换,同时利用振幅谱和复数域频谱在时间域和频率域进行语音特征提取,有效保留振幅信息的同时规避了相位结构随机性的问题。本文提出的多尺度阶梯型时频Conformer(MSLTFC)模块能在不同尺度分辨率的特征图中提取细节和结构化特征,同时引入指标判别器解决了评价指标函数不可直接微分的问题,对抗训练也提高了整体语音增强质量。在公开数据集VoiceBank+Demand数据集上的实验结果表明,本文算法可行有效,取得了较好的去噪效果,甚至在一些指标上取得了最高得分,如CSIG。此外,消融实验也验证了本文模型中每个部分的有效性。本文中振幅谱结合复数谱导致了模型输入维度的增加,如何在保留振幅和相位信息的同时减小输入特征维度、提升语音增强效果是未来研究的重点。
[1] LOIZOU P C. Speech Enhancement: Theory and Practice[M]. Boca Raton, FL: CRC Press, 2007: 1-9.
[2] BOLL S. Suppression of acoustic noise in speech using spectral subtraction[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2): 113-120.
[3] ZALEVSKY Z, MENDLOVIC D. Fractional Wiener filter[J]. Applied Optics, 1996, 35(20): 3930-3936.
[4] EPHRAIM Y. Statistical-model-based speech enhancement systems[J]. Proceedings of the IEEE, 1992, 80(10): 1526-1555.
[5] EPHRAIM Y, TREES H L VAN. A signal subspace approach for speech enhancement[J]. IEEE Transactions on Speech and Audio Processing, 1995, 3(4): 251-266.
[6] TAMURA S, WAIBEL A. Noise reduction using connectionist models[C]// Proceedings of the 1988 International Conference on Acoustics, Speech, and Signal Processing — Volume 1. Piscataway: IEEE, 1988: 553-556.
[7] WANG Y, WANG D. Towards scaling up classification-based speech separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(7): 1381-1390.
[8] HEALY E W, YOHO S E, WANG Y, et al. An algorithm to improve speech recognition in noise for hearing-impaired listeners[J]. The Journal of the Acoustical Society of America, 2013, 134(4): 3029-3038.
[9] WENINGER F, HERSHEY J R, LE ROUX J, et al. Discriminatively trained recurrent neural networks for single-channel speech separation[C]// Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing. Piscataway: IEEE, 2014: 577-581.
[10] WENINGER F, ERDOGAN H, WATANABE S, et al. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR[C]// Proceedings of the 2015 International Conference on Latent Variable Analysis and Signal Separation, LNCS 9237. Cham: Springer, 2015: 91-99.
[11] PARK S R, LEE J W. A fully convolutional neural network for speech enhancement[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 1993-1997.
[12] 张天骐,柏浩钧,叶绍鹏,等. 基于门控残差卷积编解码网络的单通道语音增强方法[J]. 信号处理, 2021, 37(10):1986-1995.(ZHANG T Q, BAI H J, YE S P, et al. Single-channel speech enhancement method based on gated residual convolution encoder-and-decoder network[J]. Journal of Signal Processing, 2021, 37(10):1986-1995.)
[13] PALIWAL K, WÓJCICKI K, SHANNON B. The importance of phase in speech enhancement[J]. Speech Communication, 2011, 53(4): 465-494.
[14] TAN K, WANG D. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 380-390.
[15] PARVEEN S, GREEN P. Speech enhancement with missing data techniques using recurrent neural networks[C]// Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing — Volume 1. Piscataway: IEEE, 2004: 733-736.
[16] PASCUAL S, BONAFONTE A, SERRÀ J. SEGAN: speech enhancement generative adversarial network[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 3642-3646.
[17] FU S W, LIAO C F, TSAO Y, et al. MetricGAN: generative adversarial networks based black-box metric scores optimization for speech enhancement[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2031-2041.
[18] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[19] KIM J, EL-KHAMY M, LEE J. T-GSA: Transformer with Gaussian-weighted self-attention for speech enhancement[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6649-6653.
[20] GULATI A, QIN J, CHIU C C, et al. Conformer: convolution-augmented Transformer for speech recognition[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 5036-5040.
[21] CAO R, ABDULATIF S, YANG B. CMGAN: conformer-based metric GAN for speech enhancement[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 936-940.
[22] VALENTINI-BOTINHAO C, WANG X, TAKAKI S, et al. Investigating RNN-based speech enhancement methods for noise-robust Text-to-Speech[C]// Proceedings of the 9th ISCA Speech Synthesis Workshop. [S.l.]: International Speech Communication Association, 2016: 146-152.
[23] BRAUN S, TASHEV I. A consolidated view of loss functions for supervised deep learning-based speech enhancement[C]// Proceedings of the 44th International Conference on Telecommunications and Signal Processing. Piscataway: IEEE, 2021: 72-76.
[24] RIX A W, BEERENDS J G, HOLLIER M P, et al. Perceptual Evaluation of Speech Quality (PESQ) — a new method for speech quality assessment of telephone networks and codecs[C]// Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing — Volume 2. Piscataway: IEEE, 2001: 749-752.
[25] TAAL C H, HENDRIKS R C, HEUSDENS R, et al. An algorithm for intelligibility prediction of time-frequency weighted noisy speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(7): 2125-2136.
[26] VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: design, collection and data analysis of a large regional accent speech database[C]// Proceedings of the 2013 International Conference of the Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4.
[27] THIEMANN J, ITO N, VINCENT E. The diverse environments multi-channel acoustic noise database: a database of multichannel environmental noise recordings[J]. The Journal of the Acoustical Society of America, 2013, 133(S5): No.4806631.
[28] SU J, JIN Z, FINKELSTEIN A. HiFi-GAN: high-fidelity denoising and dereverberation based on speech deep features in adversarial networks[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 4506-4510.
[29] FU S W, YU C, HSIEH T A, et al. MetricGAN+: an improved version of MetricGAN for speech enhancement[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 201-205.
[30] YIN D, LUO C, XIONG Z, et al. PHASEN: a phase-and-harmonics-aware speech enhancement network[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 9458-9465.
[31] 徐峰,李平. DVUGAN:基于STDCT的DDSP集成变分U-Net的语音增强[J]. 信号处理, 2022, 38(3):582-589.(XU F, LI P. DVUGAN: DDSP integrated variational U-Net speech enhancement based on STDCT[J]. Journal of Signal Processing, 2022, 38(3):582-589.)
[32] WANG K, HE B, ZHU W P. TSTNN: two-stage transformer based neural network for speech enhancement in the time domain[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2021: 7098-7102.
[33] YU G, LI A, ZHENG C, et al. Dual-branch attention-in-attention transformer for single-channel speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 7847-7851.
[34] DANG F, CHEN H, ZHANG P. DPT-FSNet: dual-path transformer based full-band and sub-band fusion network for speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2022: 6857-6861.
[35] HU Y, LOIZOU P C. Evaluation of objective quality measures for speech enhancement[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2008, 16(1): 229-238.
Speech enhancement algorithm based on multi-scale ladder-type time-frequency Conformer GAN
JIN Yutang1, WANG Yisong1*, WANG Lihui1, ZHAO Pengli2
(1(),550025,;2,461000,)
Aiming at the problem of artificial artifacts due to phase disorder in frequency-domain speech enhancement algorithms, which limits the denoising performance and decreases the speech quality, a speech enhancement algorithm based on Multi-Scale Ladder-type Time-Frequency Conformer Generative Adversarial Network (MSLTF-CMGAN) was proposed. Taking the real part, imaginary part and magnitude spectrum of the speech spectrogram as input, the generator first learned the local and global feature dependencies between temporal and frequency domains by using time-frequency Conformer at multiple scales. Secondly, the Mask Decoder branch was used to learn the amplitude mask, and the Complex Decoder branch was directly used to learn the clean spectrogram, and the outputs of the two decoder branches were fused to obtain the reconstructed speech. Finally, the metric discriminator was used to judge the scores of speech evaluation metrics, and high-quality speech was generated by the generator through minimax training. Comparison experiments with various types of speech enhancement models were conducted on the public dataset VoiceBank+Demand by subjective evaluation Mean Opinion Score (MOS) and objective evaluation metrics.Experimental results show that compared with current state-of-the-art speech enhancement method CMGAN (Comformer-based MetricGAN), MSLTF-CMGAN improves MOS prediction of the signal distortion (CSIG) and MOS predictor of intrusiveness of background noise (CBAK) by 0.04 and 0.07 respectively, even though its Perceptual Evaluation of Speech Quality (PESQ) and MOS prediction of the overall effect (COVL) are slightly lower than that of CMGAN, it still outperforms other comparison models in several subjective and objective speech evaluation metrics.
speech enhancement; multi-scale; Conformer; Generative Adversarial Network (GAN); metric discriminator; deep learning
1001-9081(2023)11-3607-09
10.11772/j.issn.1001-9081.2022111734
2022⁃11⁃22;
2023⁃02⁃27;
国家自然科学基金资助项目(U1836205)。
金玉堂(1999—),男,贵州安顺人,硕士研究生,主要研究方向:数字信号处理、语音增强、信号去噪; 王以松(1975—),男,贵州思南人,教授,博士,CCF会员,主要研究方向:知识表示与推理、回答集程序设计、人工智能、机器学习; 王丽会(1982—),女,黑龙江哈尔滨人,教授,博士,主要研究方向:深度学习、机器学习、医学成像、医学图像处理、计算机视觉; 赵鹏利(1992—),女,河南许昌人,助教,硕士,主要研究方向:数据库、软件工程。
TP391.9
A
2023⁃02⁃28。
This work is partially supported by National Natural Science Foundation of China (U1836205).
JIN Yutang, born in 1999, M. S. candidate. His research interests include digital signal processing, speech enhancement, signal denoising.
WANG Yisong, born in 1975, Ph. D., professor. His research interests include knowledge representation and reasoning, answer set programming design, artificial intelligence, machine learning.
WANG Lihui, born in 1982, Ph. D., professor. Her research interests include deep learning, machine learning, medical imaging, medical image processing, computer vision.
ZHAO Pengli, born in 1992, M. S., teaching assistant. Her research interests include database, software engineering.
