基于多分支混合注意力的小目标检测算法
2023-11-29秦强强廖俊国周弋荀
秦强强,廖俊国,周弋荀
基于多分支混合注意力的小目标检测算法
秦强强,廖俊国*,周弋荀
(湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201)( ∗ 通信作者电子邮箱jgliao@hnust.edu.cn)
针对图像中的小目标特征信息少、占比低、易受环境影响等特点,提出一种基于多分支混合注意力的小目标检测算法SMAM-YOLO。首先,将通道注意力(CA)和空间注意力(SA)相结合,重新组合连接结构,提出一种混合注意力模块(MAM),增强模型对小目标特征在空间维度上的表达能力。其次,根据不同大小的感受野对目标影响的不同,基于混合注意力提出一种多分支混合注意力模块(SMAM);根据输入特征图的尺度自适应调整感受野大小,同时使用混合注意力增强不同分支下对小目标特征信息的捕获能力。最后,使用SMAM改进YOLOv5中的核心残差模块,提出一种基于CSPNet(Cross Stage Partial Network)和SMAM的特征提取模块CSMAM,而且CSMAM的额外计算开销可以忽略不计。在TinyPerson数据集上的实验结果表明,与基线算法YOLOv5s相比,当交并比(IoU)阈值为0.5时,SMAM-YOLO算法的平均检测精度(mAP50)提升了4.15个百分点,且检测速度达到74 frame/s;此外,与现有的一些主流小目标检测模型相比,SMAM-YOLO算法在mAP50上平均提升了1.46~6.84个百分点,且能满足实时性检测的需求。
小目标检测;多分支网络;混合注意力;特征融合;实时检测
0 引言
随着深度学习的不断发展以及硬件成本的不断降低,基于深度学习的目标检测算法取得了长足的进步。与中大型目标检测相比,小目标检测具有目标特征信息少、数据集比例不均衡以及易受环境影响等特点,这些特点导致小目标检测的精度不高。小目标检测在海上救援、监控识别、无人机识别、遥感卫星、海洋生物检测等任务中有广泛的应用。因此,研究小目标检测算法并提高小目标的检测精度与效率具有重要意义。
由于不断下采样,基于深度学习的目标检测在特征提取过程中过滤了相关噪声,增强了目标的特征表达,同时也导致小目标在网络的前向传播中丢失信息。为此,有些学者提出了基于特征金字塔网络(Feature Pyramid Network, FPN)[1]的多尺度特征融合网络,如路径聚合网络(Path Aggregation Network, PANet)[2]、神经架构搜索网络(Neural Architecture Search Network, NAS-Net)[3]、深度特征金字塔网络(Deep Feature Pyramid Network, DFPN)[4]、双向加权特征金字塔网络(Bidirectional Feature Pyramid Network, BiFPN)[5]等。但是,在这些网络中,不同层之间的融合方式仅仅是简单求和,忽略了目标在场景中的相关性,对于小目标检测的性能提升有限。挤压-激励网络(Squeeze Excitation Network, SE-Net)[6]、卷积注意力模块(Convolutional Block Attention Module, CBAM)[7]、频域通道注意力网络(Frequency channel attention Network, FcaNet)[8]等方法从通道和空间注意力等不同角度对小目标建模,得到了两个维度的注意力权重矩阵,从而增强小目标特征表达,抑制其他目标及复杂环境信息;但是,这些注意力网络设计忽略了不同卷积核对小目标检测的影响。
针对上述问题,本文提出了一种基于多分支网络结构与混合注意力的小目标检测算法SMAM-YOLO。该算法使用YOLOv5s作为小目标检测的基线算法,然后利用混合注意力机制和多分支网络结构对基线算法进行改进优化。主要改进如下:
1)将通道注意力(Channel Attention, CA)和空间注意力(Spatial Attention, SA)相结合,重新组合连接结构,提出混合注意力模块(Mixed Attention Module, MAM)。MAM可以获得丰富的全局空间权重注意力矩阵,增强小目标特征信息,抑制背景等无关信息。
2)结合多分支网络和MAM,提出一种新的多分支混合注意力模块(Split Mixed Attention Module, SMAM)。SMAM可以根据输入目标的尺度自适应调整感受野的大小,增强小目标的特征表达。
3)为提升小目标的特征提取能力,改进YOLOv5的核心残差块C3,将SMAM和C3结合,提出基于CSPNet(Cross Stage Partial Network)[9]的特征提取残差块CSMAM。CSMAM在特征提取时可以将更多的注意力聚焦在小目标上,增强小目标的特征信息。同时在P2层引入一个新的预测分支和小目标检测头,以获得更多的浅层信息,有利于小目标的检测。
1 相关工作
SMAM-YOLO是一种基于多分支混合注意力的小目标检测方法,涉及以下相关知识:1)小目标检测;2)多分支和注意力机制;3)多尺度特征融合;4)YOLO。本章对相关知识的研究工作进行简述。
1.1 小目标检测
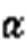
1.2 多分支和注意力机制
基于深度学习的目标检测方法大多使用卷积神经网络,然而不同的卷积核对不同大小的目标敏感程度并不同。2017年,Szegedy等[15]提出的GoogleNet取得了巨大的成功,网络中的Inception结构由4个具有不同卷积核的网络块组成。之后Xie等[16]提出的ResNeXt在ResNet的Bottleneck中引入分组卷积,在基础结构中使用了多分支结构,并通过实验证明了多分支结构的有效性。SE-Net通过在特征的通道层加入通道注意力机制来自适应地重新标定特征,从而增强有效目标特征、抑制背景信息。SK-Net(Selective Kernel Network)[17]使用2个不同卷积核分支网络,通过对融合特征引入通道注意力机制、再自适应拆分对分支网络重标定。ResNeSt[18]对SK-Net进行改进,使用个不同卷积核,同时为了共享计算,后续卷积核使用第一个空洞卷积,引入通道注意力后,拆分为个注意力重新校准不同感受野下的特征。CBAM使用通道间的均值和最大值之和重新定义通道注意力,同时引入空间注意力,使用通道和空间的串联混合注意力重标定特征图,实验证明CBAM的效果比单一的注意力效果更优。受到这些方法的启发,本文改进混合注意力结构,将多分支网络和混合注意力结合起来,并通过实验验证了方法的有效性。
1.3 多尺度特征融合
目前,绝大多数目标检测算法都使用多次下采样后的深层特征来分类和回归。但是,小目标的尺寸非常小,随着网络的不断深入,小目标的特征很难保留下来,将显著影响小目标的检测;而浅层网络的特征具有更加详细的位置信息和小目标信息,所以,将浅层特征和深层特征进行多尺度特征融合是一种有效的解决方法。FPN通过自上而下的横向连接网络将深层和浅层特征融合起来;然而,FPN自上而下的连接结构导致网络浅层拥有深层所有的语义信息,而深层没有融合相对应的浅层信息。PANet在FPN的基础上增加了一条额外的自下而上的连接网络解决了这一问题。
BiFPN改进了PANet的拓扑结构,并提出了更加高效的路径聚合网络。本文选择带有PANet的YOLOv5s作为基础网络。
1.4 YOLO
YOLO[19]是目标检测中单阶段网络结构的典型算法,它的检测速度比双阶段的Faster RCNN[20]、Mask RCNN[21]等算法更快,因为YOLO算法的核心思想是将整个分类和定位当成一个回归问题,在对图像提取特征后直接回归得到类别和位置,大幅降低了算法所消耗的资源和时间开销[22]。YOLOv2[23]在之前的基础上改进了锚框策略,使用K-means聚类生成更加贴合数据集的先验框;YOLOv3[24]使用Darknet53结构的骨干网络,增强了特征提取的能力与效果;YOLOv4[25]使用改进的CSPDarknet53结构,同时使用FPN的特征融合方法;YOLOv5在前述基础上作了很多改进,根据网络的深度和宽度提供不同复杂度的模型,包括YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x共五种大小的模型。YOLOv5整体网络包括输入(Input)、特征提取主干网络(Backbone)、特征融合层(Neck)、检测输出(Head)四个部分。一般来说,在YOLOv5中,Backbone采用CSPDarknet53和快速空间金字塔池化(Spatial Pyramid Pooling-Fast, SPPF),Neck使用PANet。本文选择YOLOv5s作为小目标检测的基线模型。
2 SMAM‑YOLO算法
2.1 总体架构
与背景相比,小目标的尺寸非常小,且自身信息非常缺乏,直接输入YOLOv5会导致网络将它当成普通目标计算,忽略了它的特殊性。首先,受文献[7,18]工作的启发,本文改进了单一感受野下的通道-空间注意力机制,并结合多分支网络结构,提出多分支混合注意力模块(SMAM)。相较于文献[7]的方法,SMAM在增加少量计算量的情况下,能更加有效地挖掘小目标的特征信息,并根据不同尺度的特征图动态地为小目标的贡献分配混合注意力权重。然后,在Backbone的最后一层引入改进的特征提取模块CSMAM,增强主干网络的特征提取能力;同时在Neck的多尺度融合过程的上下采样中引入SMAM和CSMAM,增强小目标的特征表达。最后,在PANet的网络结构中增加一个P2检测分支,用来检测小目标。综上所述,SMAM-YOLO算法的整体网络结构如图1所示,基于YOLOv5s主要作了以下改进:
1)主干网络:在Backbone末端中引入所提出的基于CSPNet的CSMAM。
2)特征融合网络:增加小目标检测分支,并在特征金字塔上采样的每一层融合后插入SMAM模块,在下采样的每一层插入CSMAM和SMAM模块。

图1 SMAM-YOLO算法的整体网络结构
2.2 SMAM

受文献[7]中工作的启发,本文设计了2个卷积注意力模块:CA模块和SA模块。
CA的结构如图2所示,计算公式如式(1)所示:
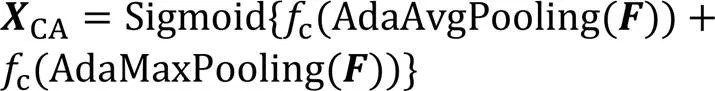
其中:输入特征图F大小为;Sigmoid为激活函数,AdaAvgPooling为全局自适应平均池化,AdaMaxPooling为全局自适应最大池化; 为全连接网络。首先,对特征图F分别作全局自适应平均池化和最大池化;然后将得到的2种通道权重通过全连接层fc(Conv+ReLU+Conv);最后对全连接的2个不同的权重求和,并由Sigmoid激活得到通道注意力XCA,此时大小为。
SA的结构如图3所示,计算公式如式(2)所示:
由于文献[7]在通道注意力后先重标定特征空间,再串联空间注意力后再次重标定,得到两次注意力加权后的特征图,但输出是加权后的特征图,不利于结合多分支网络;同时串联方式虽然简单且效果良好,但是没有充分考虑合理的连接方式对小目标的影响。为了在不增加额外计算量的情况下更好地结合多分支网络结构,对CBAM网络结构改进,提出MAM,结构如图4所示,计算公式如式(3)所示:
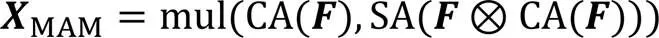
其中:输入特征图F大小为;CA是通道注意力,输出大小为;SA是空间注意力,输出大小为;mul是矩阵乘法;XMAM是CA和SA的未重标定的混合注意力权重,输出大小为。

图4 MAM的结构
文献[18]中的多分支注意力模块仅使用了通道注意力对小目标进行特征提取,有一定的效果,但是缺乏对空间的思考,并不全面。因此,将MAM引入多分支网络,提出SMAM,它的网络结构如图5所示。
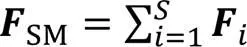
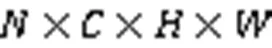
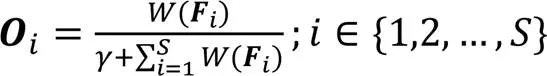
分配好各分支的权重后,对多分支特征图重标定,并且对应元素求和,得到多分支混合注意力加权后的特征图out,如式(6)所示:
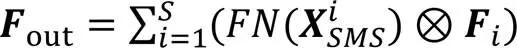
其中:S为分支数;i为重标定的分支;Fi是第个分支。最后输出大小为。
2.3 特征提取模块CSMAM
YOLOv5中特征提取的核心模块C3,主要使用基于CSPNet结构堆叠的Bottleneck残差块。对C3结构进行改进,将残差块中的3×3卷积替换为SMAM;同时为了降低参数量,替换过后不再堆叠残差块,提出基于CSPNet和SMAM的特征提取模块CSMAM,它的网络结构如图6所示。

图6 CSMAM的网络结构
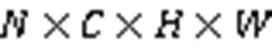
3 实验与结果分析
3.1 数据集与评估标准
3.1.1数据集概述
本文实验的数据集是一个具有高质量标注的小目标数据集TinyPerson[26],其中的图像场景多数为远距离大背景航拍下的图像,非常符合小目标检测的需求。TinyPerson数据集包含2个类别(earth person、sea person),一共有1 610张图片(其中训练集794张图片,测试集816张图片),共包含72 651个人类目标注释。
3.1.2评估标准
为了评估模型的有效性,本文使用平均精度 (Average Percision, AP)、平均精度均值(mean Average Precision, mAP)、每秒10亿次的浮点运算次数(Giga Floating-point Operations Per Second, GFLOPs)及帧率(Frame Per Second, FPS)作为评估标准。


再以轴为召回率、轴为精确率建立二维坐标轴,同时绘制精确率-召回率(Precision-Recall, PR)曲线,PR曲线所围面积即为AP大小,计算如式(9)所示:

mAP为多个类别的平均精度均值,其中表示类别总数,计算如式(10)所示:

GFLOPs为每秒10亿次的浮点运算,一般用于衡量模型的计算复杂度。
帧率表示每秒可以检测图片的数量(单位:frame/s),用于衡量算法是否具有实时性,一般认为FPS大于30 frame/s即具备实时检测效果。
AP50、mAP50表示交并比(Intersection over Union, IoU)阈值为0.5时的平均精度和平均精度均值。一般来说,IoU越高,表示预测出目标与真实目标交集越大,越贴合真实目标,此时检测精度越大即表明模型预测能力越强。由于小目标占比像素少,如果使用较大的IoU,检测精度将会非常低,不能较好地衡量小目标检测算法的效果,为此,本文选择IoU为0.5的折中方案。
3.2 实验环境及参数设置
实验的硬件环境为Intel Core i7-10750H CPU@2.60 GHz、16 GB内存、NVIDIA GeForce GTX 1660Ti GPU;软件环境为Windows 11家庭中文版系统、Python3.8、PyTorch 1.8.2、CUDA 10.2。
图7为训练时回归损失的变化曲线,其中BatchSize设置为4,训练150轮,前三轮为预热,优化器使用随机梯度下降(Stochastic Gradient Descent, SGD),初始学习率设置为0.01,动量设置为0.937,学习率衰减使用余弦策略。从图7可以看出,训练的回归损失值可以平滑下降,达到理想效果。除了必要的改进外,本文实验中所有模型的超参数都设置为默认(不一定是最佳参数),并在此设置下进行训练、验证和测试。

图7 训练损失曲线
3.3 分辨率实验及分析
由于YOLOv5s默认输入大小是640×640,但是TinyPerson数据集中的目标为小目标,图片为远距离大背景下的航拍图像,图片大小都远大于默认大小。显然,输入分辨率越大,对于检测小目标越有利,但是越大的分辨率会导致越大的计算开销,同时检测图像时的FPS也会更低。
为此,将YOLOv5s和本文算法在不同分辨率下进行测试,结果如表1所示。由表1可知,在TinyPerson数据集上,YOLOv5s训练的分辨率为960×960和1 280×1 280时,mAP50相较于640×640时分别提高了9.07和15.65个百分点,且测试分辨率为1 280×1 280时FPS都为122 frame/s;SMAM-YOLO在分辨率为960×960和1 280×1 280时mAP50相较于640×640分别提高了7.66和13.91个百分点,且测试分辨率为1 280×1 280时FPS都为74 frame/s。由此可见,在同一个目标检测网络结构下增大模型的图像分辨率可以提高模型的准确率;但增大分辨率也使计算量成倍增加、训练时间成倍增长。以SMAM-YOLO为例,在本文实验配置下,1 280×1 280分辨率输入时训练1轮需要26 min左右,74.4 GFLOPs;然而,640×640分辨率输入时训练1轮仅需要9 min左右,19.9 GFLOPs。同时生成的权重文件大小也会增加,加大模型部署难度。但是,如果同一个网络结构的算法使用不同分辨率训练得到的不同模型,在检测时图像的输入使用同一分辨率,对于FPS并无影响,这表明训练时可以适当增加模型输入分辨率来提高检测精度。此外,太大的分辨率也会导致过拟合,因此不能盲目增大分辨率。

表1 分辨率实验结果
注:FPS1 280中1 280表示测试时图像的分辨率为1 280×1 280。
3.4 消融实验及分析
为了验证本文所提出的SMAM和CSMAM的有效性,以及增加小目标检测头对结果的影响,对不同模块对结果的影响进行消融实验评估:使用YOLOv5s作为基线模型,训练图像输入分辨率为1 280×1 280,测试图像分辨率为1 280×1 280的场景下,共训练150轮,使用预训练权重加速训练,实验结果如表2所示。
1)额外检测头的影响。由表2可知,a模型为无改进的基线模型,b模型在基线模型上增加了P2检测头,由于P2检测层拥有更多的浅层信息,对小目标检测更加有利。实验结果表明,相较于a模型,b模型层数由270增加到328,GFLOPs由57.27到65.39,参数量从7.02×106增加到7.17×106,但是对于小目标的mAP50增加了1.78个百分点,同时FPS仍满足实时检测的需求。因此,增加少量的计算量,得到更好的小目标检测效果是值得的。
2)MAM的影响。SMAM可以自适应地结合混合注意力机制调整更适合小目标的不同感受野,以此得到对小目标充分加权并且重定向后的特征图。c模型分别在Backbone的SPPF层前和Neck的上下采样最后部分引入SMAM。相较于b模型,c模型的层数、GFLOPs、参数量分别增加了168、10.77个百分点、0.45×106,但mAP50提升了2.01个百分点。d模型以c模型为基础,在Neck的下采样输入Head之前,将原来无注意力加权的CSPNet结构C3模块替换成引入了SMAM的CSMAM结构。相较于c模型,d模型层数增加了91,GFLOPs减少了1.76,参数量减少了0.25×106,同时mAP50上升了0.36个百分点。这说明增加SMAM模块和在特征提取中将C3替换成更轻量的CSMAM后,能够使模型获得更加丰富的小目标特征。
综上所述,本文模型相较于基线模型YOLOv5s的mAP50提升了4.15个百分点,大幅提升了小目标的检测精度,同时FPS达到了74 frame/s,具有一定的实时检测效果。
3.5 对比实验及分析
在TinyPerson数据集上,对SMAM-YOLO和近年来已有的几种小目标检测模型(主要包含CBAM、PP-YOLO[27]、DETR[28]、YOLOv7[29]、YOLOX[30]、YOLOv5)进行对比实验,其中YOLOX和PP-YOLO使用S版本,YOLOv7使用tiny版本,YOLOv5s使用较新的6.2版本,实验结果如表3所示。由表3可知,在对比的算法中,引入CBAM的YOLOv5具有最高的mAP50,达到50.61%,比SMAM-YOLO的mAP50低1.46个百分点,其他参数与CBAM相差不大,在提高检测精度的同时,也保证了速度、参数量和模型大小的稳定。YOLOv7-tiny具有最快的检测速度,达到131.21 frame/s,同时参数量、模型大小、GFLOPs也最小,但是比SMAM-YOLO的mAP50低6.84个百分点。由此可见,SMAM-YOLO算法将更多的注意力聚焦到小目标身上,动态地对不同尺度下特征图中的小目标重定向,不仅提高了检测精度,同时保证了检测速度,具有一定的实时性,在实时检测小目标任务上具有更大的优势。

表2 消融实验结果

表3 不同小目标检测模型的对比实验结果
3.6 模块可视化分析
为了更直观验证SMAM对小目标特征的影响情况,以及对最后检测小目标时产生的影响,使用TinyPerson测试集中具有代表性的图片验证。
图8(a)是没有添加混合注意力的YOLOv5基线模型,图8(b)是添加了混合注意力的YOLOv5模型,分别使用Grad-CAM[31]做热力图可视化。从图的左上、右上、左下,右下对比中可以看出,在不同的角度,目标数量多且小的时候,MAM可以更加有效地聚焦小目标的特征,在图中则表现为目标边界更加清晰,颜色与环境差异明显,从而提高检测效果。
图9是添加混合注意力前后的YOLOv5的实际检测效果,其中红色框是模型检测的人类标签,黄色框为重点标出的差异。从图9可以看出,在不同的条件下,陆地或者海上、白天或者傍晚,基线模型对于小目标存在漏检的情况,而添加混合注意力后可以较好地检测出小目标。
综上所述,SMAM可以有效提升小目标的检测效果。
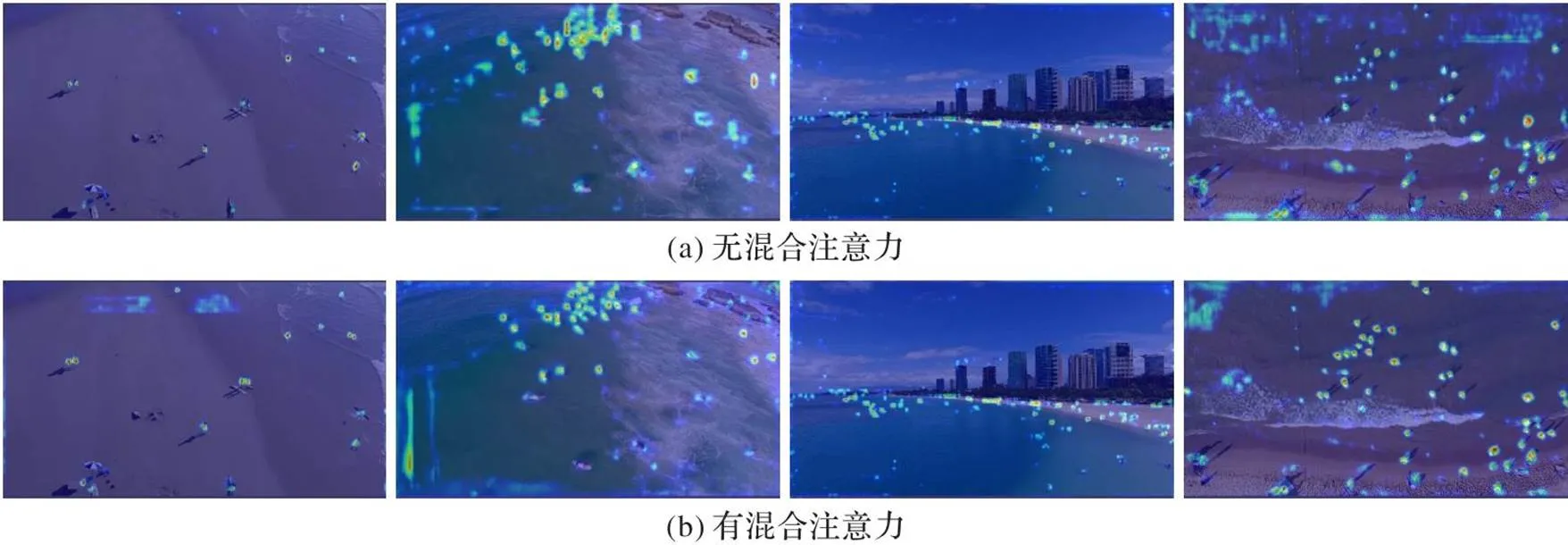
图8 添加混合注意力前后的热力图

图9 添加混合注意力前后的检测效果图
4 结语
本文结合通道、空间注意力与多分支网络结构,提出了多分支混合注意力模块,通过自适应的多感受野聚焦更适合小目标的丰富尺度信息,再结合混合注意力对小目标信息重标定,使小目标特征更加突出,以此提高对小目标特征的识别能力。对本文所提出的小目标检测算法SMAM-YOLO在TinyPerson数据集上进行实验,实验结果表明,SMAM-YOLO的检测效果较为优异,不仅检测精度高,而且检测速度高,能满足实时检测需求。
本文主要使用多分支混合注意力模块来改进YOLOv5s模型,以提升小目标检测的效果,并没有考虑与其他相关方法(如数据增强和自注意力机制等)相结合。因此,在后续的研究工作中,可以进一步研究如何将SMAM-YOLO与更多先进方法相结合,实现高性能的小目标检测。
[1] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 936-944.
[2] LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768.
[3] GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2019: 7029-7038.
[4] LIANG Z, SHAO J, ZHANG D, et al. Small object detection using deep feature pyramid networks[C]// Proceedings of the 2018 Pacific Rim Conference on Multimedia, LNCS 11166. Cham: Springer, 2018: 554-564.
[5] TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2020: 10778-10787.
[6] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 7132-7141.
[7] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19.
[8] QIN Z, ZHANG P, WU F, et al. FcaNet: frequency channel attention networks[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 763-772.
[9] WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC: IEEE Computer Society, 2020: 1571-1580.
[10] 李科岑,王晓强,林浩,等. 深度学习中的单阶段小目标检测方法综述[J]. 计算机科学与探索, 2022, 16(1):41-58.(LI K C, WANG X Q, LIN H, et al. A survey of one-stage small object detection methods in deep learning[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(1): 41-58.)
[11] KISANTAL M, WOJNA Z, MURAWSKI J, et al. Augmentation for small object detection[EB/OL]. [2023-02-12].https://arxiv.org/pdf/1902.07296.pdf.
[12] GONG Y, YU X, DING Y, et al. Effective fusion factor in FPN for tiny object detection[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 1159-1167.
[13] JIANG N, YU X, PENG X, et al. SM+: refined scale match for tiny person detection[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 1815-1819.
[14] 李文涛,彭力. 多尺度通道注意力融合网络的小目标检测算法[J]. 计算机科学与探索, 2021, 15(12):2390-2400.(LI W T, PENG L. Small objects detection algorithm with multi-scale channel attention fusion network[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(12): 2390-2400.)
[15] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1-9.
[16] XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 5987-5995.
[17] LI X, WANG W, HU X, et al. Selective kernel networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2019: 510-519.
[18] ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC: IEEE Computer Society, 2022: 2735-2745.
[19] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the IEEE 2016 Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 779-788.
[20] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015:91-99.
[21] HE K, GKIOSARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988.
[22] 曹家乐,李亚利,孙汉卿,等.基于深度学习的视觉目标检测技术综述[J].中国图象图形学报,2022,27(6):1697-1722. (CAO J L, LI Y L, SUN H Q, et al. A survey on deep learning based visual object detection[J]. Journal of Image and Graphics, 2022, 27(6): 1697-1722.)
[23] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 6517-6525.
[24] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2023-02-12].https://arxiv.org/pdf/1804.02767.pdf.
[25] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2023-02-12].https://arxiv.org/pdf/2004.10934.pdf.
[26] YU X, GONG Y, JIANG N, et al. Scale match for tiny person detection[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 1246-1254.
[27] LONG X, DENG K, WANG G, et al. PP-YOLO: an effective and efficient implementation of object detector[EB/OL]. [2023-02-12].https://arxiv.org/pdf/2007.12099.pdf.
[28] ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection[EB/OL]. [2023-02-12].https://arxiv.org/pdf/2010.04159.pdf.
[29] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. [2023-02-12].https://arxiv.org/pdf/2207.02696.pdf.
[30] GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. [2023-02-12].https://arxiv.org/pdf/2107.08430.pdf.
[31] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 618-626.
Small object detection algorithm based on split mixed attention
QIN Qiangqiang, LIAO Junguo*, ZHOU Yixun
(,,411201,)
Focusing on the characteristics of small objects in images, such as less feature information, low percentage, and easy to be influenced by the environment, a small object detection algorithm based on split mixed attention was proposed, namely SMAM-YOLO. Firstly, by combining Channel Attention (CA) and Spatial Attention (SA), as well as recombining the connection structures, a Mixed Attention Module (MAM) was proposed to enhance the model’s representation of small object features in spatial dimension. Secondly, according to the different influence of receptive fields with different sizes on the object, a Split Mixed Attention Module (SMAM) was proposed to adaptively adjust the size of the receptive field according to the scale of the input feature map, and the mixed attention was used to enhance the ability to capture small object feature information in different branches. Finally, the core residual module in YOLOv5 was improved by using SMAM, and a feature extraction module CSMAM was proposed on the basis of CSPNet (Cross Stage Partial Network) and SMAM, and the additional computational overhead of CSMAM can be ignored. Experimental results on TinyPerson dataset show that compared with the baseline algorithm YOLOv5s, when the Intersection over Union (IoU) threshold is 0.5, the mean Average Precision (mAP50) of SMAM-YOLO algorithm is improved by 4.15 percentage points, and the detection speed reaches 74 frame/s. In addition, compared with some existing mainstream small object detection models, SMAM-YOLO algorithm improves the mAP50by 1.46 - 6.84 percentage points on average, and it can meet the requirements of real-time detection.
small object detection; split network; mixed attention; feature fusion; real-time detection
QIN Qiangqiang, born in 1990, M. S. candidate. His research interests include artificial intelligence, object detection.
1001-9081(2023)11-3579-08
10.11772/j.issn.1001-9081.2022111660
2022⁃11⁃09;
2023⁃03⁃03;
秦强强(1997—),男,安徽芜湖人,硕士研究生,CCF会员,主要研究方向:人工智能、目标检测; 廖俊国(1972—),男,湖南衡阳人,教授,博士,CCF会员,主要研究方向:网络安全、人工智能、模式识别; 周弋荀(1998—),男,湖北黄石人,硕士研究生,CCF会员,主要研究方向:人工智能、目标检测。
TP391; TP183
A
2023⁃03⁃03。
LIAO Junguo, born in 1972, Ph. D., professor. Her research interests include cyber security, artificial intelligence, pattern recognition.
ZHOU Yixun, born in 1998, M. S. candidate. His research interests include artificial intelligence, object detection.
