基于深度强化学习的SWIPT边缘网络联合优化方法
2023-11-29王哲王启名李陶深葛丽娜
王哲,王启名,李陶深,葛丽娜
基于深度强化学习的SWIPT边缘网络联合优化方法
王哲1,2,3,王启名2,李陶深4,葛丽娜1,3,5
(1.广西民族大学 人工智能学院,南宁 530006; 2.广西民族大学 电子信息学院,南宁 530006; 3.广西混杂计算与集成电路设计分析重点实验室(广西民族大学),南宁 530006; 4.广西大学 计算机与电子信息学院,南宁 530004; 5.广西民族大学 网络通信工程重点实验室,南宁 530006)( ∗ 通信作者电子邮箱wqm082199@163.com)
边缘计算(EC)与无线携能通信(SWIPT)技术能够提升传统网络性能,但同时也增加了系统决策制定的难度和复杂度。而基于最优化方法所设计的系统决策往往具有较高的计算复杂度,无法满足系统的实时性需求。为此,针对EC与SWIPT辅助的无线传感网络(WSN),联合考虑网络中波束成形、计算卸载与功率控制问题,建立了系统能效最优化数学模型;其次,针对该模型的非凸与参数耦合特征,通过设计系统的信息交换过程,提出基于深度强化学习的联合优化方法,该方法无须建立环境模型,采用奖励函数代替Critic网络对动作进行评估,能降低决策制定难度并提升实时性;最后,基于该方法设计了改进的深度确定性策略梯度(IDDPG)算法,并与多种最优化算法和机器学习算法进行仿真对比,验证了联合优化方法在降低计算复杂度、提升决策实时性方面的优势。
无线传感网络;深度强化学习;无线携能通信;边缘计算;联合优化
0 引言
边缘计算(Edge Computing, EC)是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的开发平台,就近提供边缘智能服务,以满足行业数字化在敏捷联接、实时业务、数据优化、应用智能、安全与隐私保护等方面的关键需求[1]。其中,计算卸载是EC的核心技术之一,通过将终端节点的计算任务卸载至边缘设备完成EC过程,在可容忍的传输时延下大幅降低终端的计算压力与计算时延。如今,EC已融入移动通信、万物互联、未来工厂等应用场景[2],为网络的资源分配带来了更好的决策自由度和性能优化空间。
文献[3]中基于潜在博弈论研究移动边缘计算(Mobile Edge Computing, MEC)网络中计算资源的分配问题。其中设计的分配方案包括两部分:首先利用潜在博弈论控制MEC网络的基站发射功率,以最大化MEC网络势函数;其次,利用线性规划求解MEC低延迟高可靠模型。不同于文献[3]中的方案,文献[4]中考虑了区域MEC协作策略,根据计算任务的延迟容限度对任务分类,利用深度强化学习(Deep Reinforcement Learning, DRL)算法实现不同类型任务与差异化卸载策略的匹配,能联合降低服务时延与系统负载。文献[5]中提出有限资源约束下的计算卸载与资源分配联合优化问题,使用Stackelberg博弈均衡MEC与用户间的资源调度。文献[6]中针对多用户场景,提出了一种设备到设备(Device-to-Device, D2D)通信的计算卸载策略,直接均衡设备间的资源分配以降低系统的时延和能耗。文献[7]中引入了软件定义网络和功能虚拟化技术重构网络,提出了最大化实时任务处理成功率的在线资源分配问题,基于马尔可夫过程建立重构场景下的决策分配过程,以获取最优解。文献[8]中聚焦在车联网场景下的边缘资源分配问题,以最小化计算时延为目标,提出了边缘服务器能耗与负载均衡问题,并基于多目标免疫优化算法设计了相应的卸载方案。上述研究表明,边缘计算的应用提升了网络中计算资源分配的自由度,合理的计算卸载策略能够帮助网络实现更好的系统性能和服务质量。
然而,由于边缘网络承担着部分原中央网络的计算与存储服务,同时资源分配与调度决策也将在边缘侧制定,增加了边缘节点能量耗尽与节点间能量分布失衡的概率。无线携能通信(Simultaneous Wireless Information and Power Transfer, SWIPT)技术的加入在一定程度上降低了这一概率。SWIPT是一项新型的无线通信技术,利用射频(Radio Frequency, RF)信号同时携带能量和信息的特性,实现了节点间同步的无线信息与无线能量传输,以提升网络节点能量的自由程度。文献[9]中将SWIPT应用于多级边缘卸载网络以辅助解决变电站场景的巡检设备的接入与供能问题,设计了地面机器人和无人机协作的巡检算法,并提出了一种基于Q-Learning的最佳任务卸载算法。文献[10]的研究将SWIPT与MEC应用于物联网中,联合考虑功率分配、CPU频率、卸载权重和能量收获权重,提出了数据传输速率和传输功率的约束下系统能耗最优化问题,基于交替群迭代和群内点迭代优化算法进行求解,并设计了SWIPT辅助的MEC系统以延长节点设备的生命周期。文献[11]中则利用SWIPT与MEC技术应对物联网系统中设备计算能力和电池容量的有限性,建立了联合优化CPU频率、计算任务、终端传输功率和MEC任务比例的上行链路可实现速率最优化模型。与此同时,文献[12]中的研究针对传统的数值优化方法无法解决无线信道相干时间限制内的组合问题,提出采用深度强化学习算法求解SWIPT辅助的MEC网络任务卸载问题。文献[13]基于增强优先级深度确定性策略梯度算法,通过联合优化卸载决策最小化所有用户的能耗、动态SWIPT-MEC网络中的中央处理器频率和功率分配,能解决多用户场景下需求多样性和信道时变性导致的系统决策实时性较差问题。可见,SWIPT的应用增加了系统能量规划的可行性,能够延长系统的生命周期。然而,SWIPT的引入也伴随着网络中信号干扰的增加。文献[10-13]的研究忽略了信号干扰增加所导致的能量损耗,而及时且精确的信道状态信息(Channel State Information, CSI)在大规模网络中难以获知,导致系统决策的时延也随之增加。
最近,针对SWIPT应用伴随而来的系统决策实时性差和复杂度高的现象,有研究工作指出利用机器学习方法能够弥补这一缺陷。针对变电站场景,文献[9]中建立了关于系统能耗和时延的数学模型,并通过马尔可夫决策过程描述系统最优化巡检问题,设计了基于强化学习的卸载决策算法。文献[14]中提出了一种无线供电MEC系统,使用强化学习解决低复杂度系统的计算负载均衡问题,以此提高系统计算能力和对有限电池容量的高效使用。针对SWIPT辅助的MEC网络中无线信道的实时性要求,文献[15]中通过选择本地计算或计算卸载,建立了最佳计算速率下的计算卸载策略,提出了一种基于强化学习的智能在线卸载框架选取最佳的卸载动作。上述文献的研究验证了强化学习应用在SWIPT-MEC网络中的可行性,同时强化学习方法的应用尚处于初级阶段,联合考虑系统多项决策的高复杂度模型下的强化学习模型设计仍是当前亟待解决的问题。上述研究较多考虑强化学习方法在设计传统MEC决策中的应用,而在联合SWIPT后所需同步考虑的波束成形、系统周期规划、功率控制等均大幅增加了强化学习算法的设计难度。
基于上述分析,本文针对边缘计算与SWIPT辅助的传感器网络,在更好地处理网络中传感器设备相互干扰的同时降低网络中的能耗,并且保证在单位能耗下能够处理更多的卸载数据量。本文主要工作包括:
首先,联合考虑网络中波束成形、计算卸载与功率控制问题,设计系统上下行运行周期,建立系统能效最优化数学模型。
其次,针对该模型的非凸与参数耦合特征,通过设计系统的信息交换过程消除环境状态中的冗余信息,之后提出基于深度强化学习的模型求解方法。同时,针对传统深度Q网络(Deep Q-Network, DQN)无法处理连续性动作的问题,提出使用深度确定性的策略梯度(Deep Deterministic Policy Gradient, DDPG)算法进行求解;然而DDPG可能会出现过估计问题,所以改进DDPG框架,删除DDPG框架中的Critic网络,使用设计的奖励函数对动作进行评估,称作改进的深度确定性策略梯度(Improved Deep Deterministic Policy Gradient, IDDPG)算法。该算法能够解决传统最优化算法计算复杂度较高、实时性差的问题,同时无模型和无Critic网络算法设计可降低系统的求解难度。
最后,将IDDPG算法与多种最优化算法和机器学习算法进行仿真对比,验证了本文算法在降低计算复杂度、提升决策实时性方面的优势。
1 系统模型
基于SWIPT的无线传感网络(Wireless Sensor Network, WSN)系统如图1所示。其中全部传感器节点以等边六边形的区域划分为簇,分别接入个Sink节点,第(=1,2,…,)个Sink节点为它覆盖范围内的K个传感器节点提供SWIPT服务,并周期性地收集传感器节点所采集到的数据;与此同时,全部Sink节点组成边缘计算网络为传感器节点提供计算卸载服务。Sink节点由稳定电源供能,传感器节点的能量则全部收集自Sink节点的SWIPT过程。Sink节点配备天线数量为,传感器节点均配备单一天线。
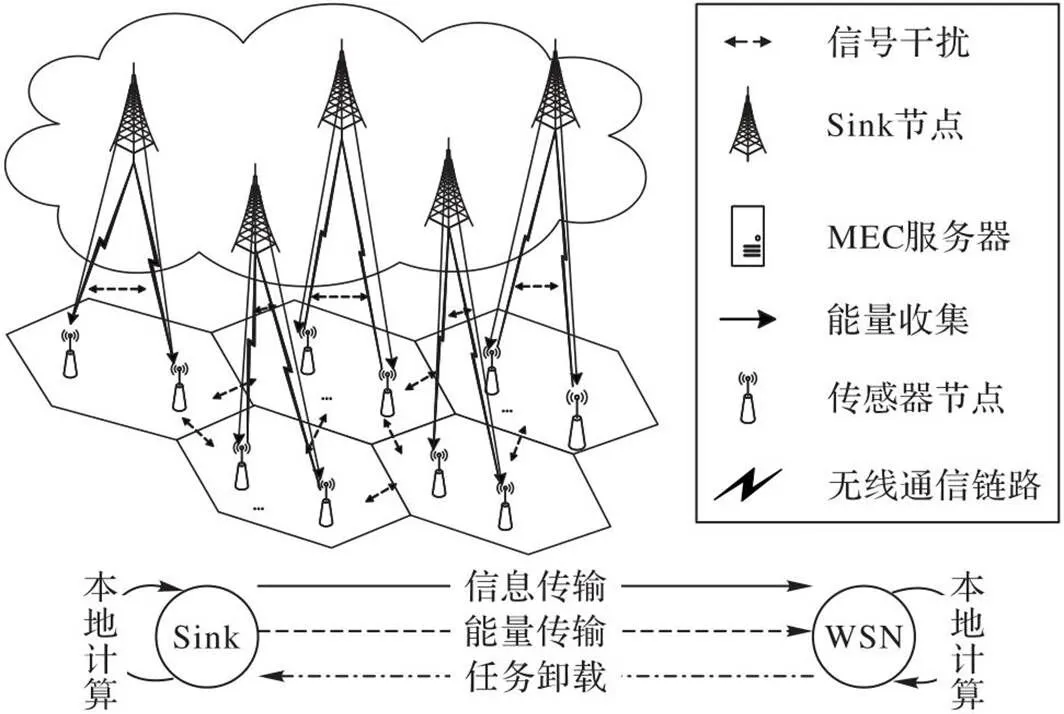
图1 基于SWIPT的无线传感网络边缘计算系统


图2 系统周期示意图
1.1 下行阶段


与此同时,考虑到信道的大尺度衰减分量[20],第个Sink节点与其服务的第k个传感器节点间的信道向量可表示为
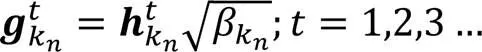
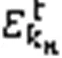

于是在下行阶段Sink节点损失的能耗为

由于传感器节点的采样为常态化过程,它们的运行状态不受系统决策影响,所消耗的能量为固定值,因此在系统资源分配决策制定过程中不考虑该常量能耗,并假定感知数据充裕且系统期望在单一周期内处理的数据量最大。
1.2 上行阶段
在上行过程中,传感器节点利用下行阶段收集到的能量进行数据清洗、融合、压缩等处理,并将处理结果上传至Sink节点。然而,由于传感器节点能量有限且收集能量的过程具有不稳定性,因此传感器节点需要依据自身能量将部分采样数据卸载至具有稳定供能的Sink节点进行数据处理。于是,上行阶段系统中的传感器节点存在两种运行状态:
1)传感器节点不卸载数据,自身完成数据处理并将处理结果上传至Sink节点,此过程产生本地计算能耗;
2)传感器节点卸载部分数据给Sink节点处理,在本地处理一部分数据并将结果上传至Sink节点,此过程产生本地计算能耗、卸载通信能耗和Sink计算能耗。
以上运行状态并未考虑传感器节点将采样数据全部上传至Sink节点进行处理,这是由于虽然此方式能够减少本地计算能耗,但未经处理的采样数据将产生大量的通信能耗,且通信过程中簇内和簇间都存在信道干扰,也将造成系统能耗的增加。因此,在传感器节点卸载采样数据至Sink节点的通信过程中,传感器节点同步进行本地计算,此过程等同于运行状态2。
假定上行过程中信道状态不发生变化[21],此时传感器节点k与其簇内Sink节点所形成的信道向量可表示为式(2)。
与此同时,上行通信过程中传感器节点的信干噪比可表示为

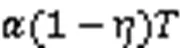

因此,系统在一个周期能处理的总数据量为
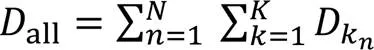
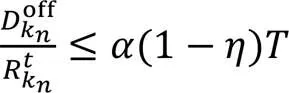

2 能效优化问题
在基于SWIPT协同边缘计算的无线传感器网络环境中,由于网络系统的计算资源有限,期望能够在有限的计算资源下处理更多的卸载数据量,以实现更准确和更及时的网络服务与应用。因此,系统能效可定义为在一个周期内单位能耗所获得的已处理数据量。由于传感器节点的全部能量均来自Sink节点的SWIPT过程,基于能量守恒定理,系统周期内的总能耗为Sink节点SWIPT能耗与Sink节点处理卸载数据的计算能耗之和,可表示为
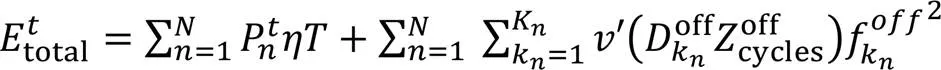

C2:(9)
其中,表示传感器节点的有效电容开关[23]。
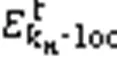
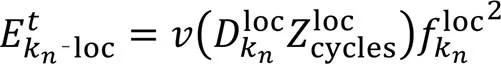


3 深度强化学习算法设计
对于深度强化学习算法来说,完整的环境信息通常是冗余的,所以本文将设计如下的信息交换过程,筛选出关键的环境信息后设计奖励函数,这样不仅能得到系统的最优能效,还能够代替Critic网络评价动作的优劣,克服了神经网络会出现过估计的缺点。最后,根据算法设计得到算法的伪代码。
3.1 信息交换过程
深度强化学习模型在训练过程中需建立目标网络的动作空间,即对网络中的信息交换过程进行设计,以实现状态空间中特征组与特征值的更新。与此同时,考虑到承担模型训练的云端设备资源有限,引入干扰者与被干扰者分集,以实现对状态空间中输入端口数量的限制,继而使网络规模有限,降低云端训练负荷。



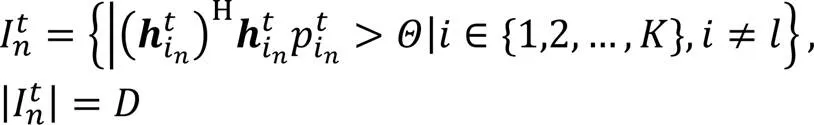

图3 信息交换示意图
3.2 IDDPG算法设计
在完成以上信息交换设定后,接下来对本文的深度强化学习方法进行设计。针对式(11)中的最优化问题,传统的基于模型求解的最优化算法往往需要对模型中的非线性和非凸特征进行松弛或转换,导致原模型精度有所损失,同时所制定的最优化算法往往具有较高的计算复杂度,不适用于低功率和低算力的传感器网络。于是,本文提出基于系统数据,利用深度强化学习方法设计低复杂度的求解算法实现功率控制与计算卸载的联合优化。首先,DQN算法能够解决传统的Q学习算法访问状态信息有限且无法存储查找表的问题;其次,采用DDPG解决DQN无法处理连续性动作的不足,DDPG以Actor-Critic框架为基础,通过Actor网络将离散的动作空间连续化[24];最后,由于DDPG网络可能存在过估计的问题,设计了IDDPG算法,移除了传统DDPG中的Critic网络,改用设计的奖励函数对Actor网络动作进行评价,这样可以避免Critic网络评价结果出现过估计的问题,能提高系统深度强化学习的求解精度(具体原因将在奖励函数设计处说明)。
下面对本文IDDPG设计中的三个关键要素,即空间状态、动作空间和奖励函数进行说明。

第三个特征组为受干扰邻居的信息
本文奖励函数的目的是反映系统在单位能耗下能够处理更多的任务量,即所实现的优化问题(11)中目标函数值越大,则受到奖励;同时,如果不能满足式(11)下的约束条件C1和C2,则应受到惩罚。于是,系统的奖励函数设计如下:






利用式(16)代替Critic网络对Sink节点动作进行评价,主要原因在于本文系统能够处理的任务量由传感器和Sink节点的动作自身决定,与算法取得动作的中间决策累积过程无关,而一般马尔可夫决策奖励函数与所有步的累积效果相关,因此设计式(16)对动作进行评价,无须通过神经网络对奖励函数(16)进行拟合,避免了传统的DDPG评价网络在函数拟合过程中产生的过估计问题[26]。


其中:为IDDPG算法中的状态量;为动作网络;为动作网络参数。




在完成动作网络参数更新工作后,边缘服务器对更新的参数进行广播,发送给每个智能体,继而Sink节点根据策略控制本小区内传感器设备的发射功率、波束成形和卸载策略使目标函数(11)最大化。需要注意的是:虽然每个Sink节点都共享相同的IDDPG参数,但每个Sink节点依然有着不同的动作,因为每个Sink节点根据自己的本地状态来执行相同的IDDPG算法。而且在训练过程中,为了验证本文算法的鲁棒性,在下一次训练之前,将传感器设备在小区内进行随机移动,这样使CSI有更多的变化,保证CSI的时变性,并且在该过程中CSI也具有一定的延时性,从而使本文策略在训练过程中观察到更多的状态变化。
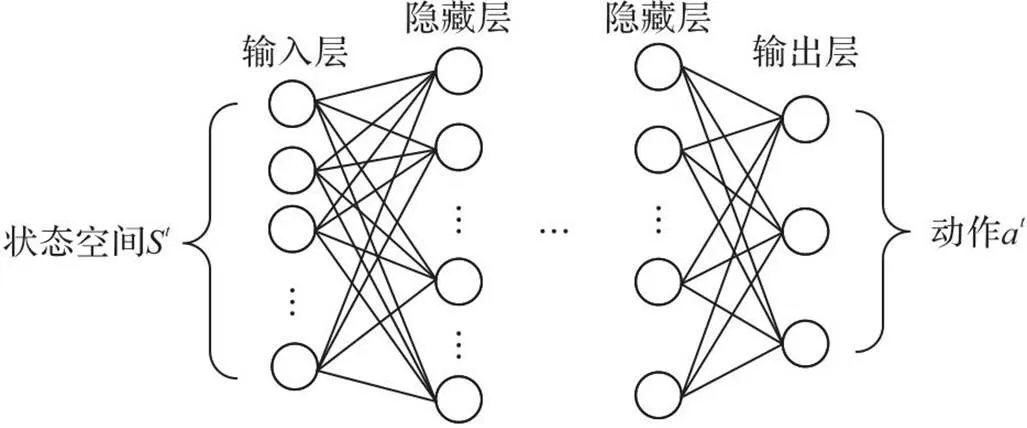
图5 网络结构
IDDPG算法如算法1所示。
算法1 基于深度强化学习的SWIPT边缘网络联合优化算法。
① 初始化一个噪声项,完成动作探索;

④ end for
5) end for
本文采用深度强化学习对模型进行训练,该过程中需要大量数据样本。首先,本文参考文献[30]的信道数据根据标准正态分布生成,即利用瑞利(Rayleigh)分布函数随机生成参数状态下的信道状态信息,Rayleigh衰落是一种合理的信道模型,被广泛应用生成信道数据;其次,将生成的信道状态信息输入传统的最优化算法WMMSE并输出优化后的动作参数,将信道状态信息和这些参数信息组成元组形成一个样本数据;最后,依据上述流程不断迭代生成本文大量的数据样本。接下来,本文算法将采用试错法进行训练,在无指导的情况下,通过每个智能体不断和环境交互,积累经验,对好的动作赋予更高的奖励,最终得到策略。
4 仿真实验与结果分析
4.1 仿真设置
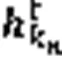

表1 仿真参数

表2 IDDPG的超参数
4.2 仿真结果分析
为验证本文深度强化学习算法在无线携能MEC网络中联合优化功率和计算资源的有效性和性能,与以下9种策略(分别简称为方案1~9)进行对比:1)IDDPG,表示基于多智能体IDDPG算法策略;2)FP,表示基于传统算法分式规划算法的策略,分式规划算法的框架参考文献[34],该方案中使FP算法拥有完美的CSI;3)MaxPower,表示基于分配最大发射功率策略,即传感器节点以最大发射功率来计算系统的目标函数;4)WMMSE,表示基于WMMSE的策略,是本文的理想算法,具有完美CSI,相较于FP算法,它需要更多的迭代以达到收敛;5)IDDPG-perfectCSI,表示具有完美CSI的IDDPG算法策略;6)DQN,表示基于DQN算法策略;7)IDDPG-SWIPT,表示只考虑波束成形下的IDDPG算法策略;8)IDDPG-功率控制,表示只考虑功率控制下的IDDPG算法策略;9)DDPG,表示基于DDPG 算法策略。本文在传感器节点不移动的情况下便能够获得完美的CSI。
图6展示了本文算法策略在不同学习率下的收敛性,从中可以看出,在学习率为0.1和0.01时,本文算法并不收敛,当学习率大于0.01时,算法才收敛,但学习率为0.000 1时获得了算法的局部最优,未获得全局最优奖励。因此本文算法将采用的学习率为0.001。
本文深度强化学习算法分为训练和测试两部分,在训练阶段将50 000个样本分为10个训练集,每个训练集5 000个样本,智能体经验池的大小设置为1 000,将训练集代入方案1、6、7、8和9算法策略进行训练,结果如图7所示。对于IDDPG策略,随着IDDPG的每一次训练网络参数更新,一个训练集将参数在各个智能体直接共享。从图7中可以看出,在大概2 000次训练迭代时,本文的深度强化学习算法便开始快速收敛,在大概完成第一个训练集时便已经逼近了传统的理想算法;并且与基于DQN的训练策略方案相比,在迭代10 000次以后,本文算法更优。与此同时,从图7中还可以看出,本文算法相较于方案9具有更好的性能,这是因为DDPG算法中使用Critic网络对动作进行评价,该方式导致了过估计问题,使系统精度下降,目标函数值陷入了局部最优的陷阱。此外,本文算法在考虑CSI的不完美性和延时性的情况下,在训练中经历各种其他设备干扰和位置改变,目标函数不断提高体现了本文算法的高性能。从图7中还能看出目标函数的数据较震荡,原因是本文的实验场景是在无线携能MEC边缘网络中,所以传感器节点是移动的,这样在每一周期的信道状态信息都是改变的,造成的干扰也会改变,系统的目标函数训练结果也随之变化。

图6 不同学习率下的算法收敛性
然而,方案7相较于方案1和6存在更低的能效结果,这是因为在仅仅考虑波束成形的情况下,方案7策略无法处理每个周期都在改变的信道状态信息,无法排除系统中的信号干扰问题,这也是导致线条较平滑、收敛不明显的原因。与此同时,方案8相较于其他三种方案存在更低的能效结果,这是因为在仅考虑功率控制的情况下,系统由于缺少了SWIPT的能量收集利用,导致系统能耗增加;并且传感器设备需要根据收集的能量来处理数据,能量的缺失将导致系统能够处理的数据任务量减少。因此方案8存在最低的能效结果。综上所述,本文提出的联合优化策略优于只考虑一种因素的单步策略。

图7 训练结果
本文基于多智能体IDDPG算法的损失值如图8所示,验证了本文算法的收敛性。

图8 损失值变化曲线
测试阶段根据训练得到的策略,测试新的数据集结果如图9所示,在图9中取每一个数据集的平均目标函数值。

图9 测试集结果图
从图9中可以看出,在经过第一次数据集迭代后,测试数据快速收敛,达到传统FP算法的目标函数值,并且随着数据集测试次数的增加,训练目标函数值不断提高,向理想WMMSE算法逼近。通过图9还可以看出方案3的目标函数值最小,这是因为以最大发射功率进行任务卸载所造成的干扰最大;其次方案2中的FP算法通过迭代对干扰信息进行了处理,目标函数值明显高于方案3;方案4作为理想算法比FP算法性能更优,这是牺牲了系统复杂度的情况下所造成的结果;方案1与方案5相比,本文设计的策略比具有完美CSI的IDDPG算法结果更优,这是因为本文的深度强化学习算法方案通过对不同信道状态信息的训练形成策略,使Sink节点能够根据该最优的波束成形策略及时调整传感器的发射功率;而且Sink节点会将训练参数进行共享,以此降低系统的复杂度。与传统的WMMSE和FP算法相比,深度强化学习算法将系统信息作为神经网络的输入得到策略的输出,并没有对数据进行迭代计算,这也没有提升系统复杂度,验证了本文算法的有效性。在实际场景中信道状态信息往往是不完美的,为了进一步证明本文算法的有效性,将方案1和6进行对比,从图9中可以看出在第一个测试集时,两种算法迅速收敛,但本文的算法始终优于DQN算法。这是由于IDDPG算法的动作空间是连续的,相比DQN算法输出为量化的离散值,使信息的精度受到影响,所以本文算法策略更优。
表3展示了每个测试集执行时不同算法所消耗的时间、算法的迭代次数和算法相较于最优化算法WMMSE的准确度。每个测试集包含5 000个样本数据,所以每个数据集的周期长度为100 ms。从表3可以看出,本文的深度强化学习算法消耗的时间最少,其次是DQN算法,之后是FP算法,WMMSE算法耗时最多。这是因为WMMSE算法相较于FP算法迭代次数更多,而本文IDDPG算法和DQN算法无须进行迭代计算,只是将信息作为神经网络的输入来得到策略的输出。本文算法比DQN算法有更短的耗时,这是由于本文算法采取集中式训练和分布式执行,所以本文算法的训练信息能够共享,复杂度更低。综上所述,本文的基于多智能体IDDPG算法策略实时性更好。从表3中还可以看出,虽然随着Sink节点和传感器节点的增加,网络空间更加复杂,导致算法的准确性会有所下降,但本文算法基本和传统FP算法持平,并优于DQN算法,验证了算法有效性。
根据测试数据集的目标函数的累计分布函数(Cumulative Distribution Function, CDF)验证本文深度强化学习算法的性能,结果如图10所示。从图10(a)中可以看出,在考虑传感器节点非移动性的情况下,即信道具有完美CSI,本文的深度强化学习算法策略相较于最大发射功率策略,DQN策略有更高的目标函数值,这是由于本文算法策略能够处理更复杂的动作空间,但低于传统FP算法策略和WMMSE算法策略。然而,从图10(b)可以看出针对传感器节点移动性的情况下,本文IDDPG算法却拥有最广泛的分布空间,这是由于本文算法策略可以根据信道状态信息和干扰信息调整自己的策略,Sink节点控制传感器节点调整自己的发射功率,减少相互的干扰,提高目标函数值。图10(b)并未考虑WMMSE算法的移动情况,这是因为WMMSE算法作为本文最优算法的策略,它应拥有最广泛的分布空间。综上所示,本文算法在考虑移动性的情况下比基于分配最大发射功率策略、基于FP算法策略和DQN策略有更广泛的分布空间,更加适合处理移动性的情况。

表3 测试集上的性能检测结果对比

图10 系统传感器不同运动情况的目标函数CDF
为了验证本文传感器移动性对系统性能的影响,设置了在不同数量Sink节点和传感器节点移动和不移动情况下的测试集,根据所得策略测试不同测试集的CDF结果如图11所示。从图11可以看出,无论节点数量如何变化,传感器节点移动的测试结果比不移动具有更广阔的分布空间。这是因为本文策略是针对传感器移动情况下训练所得,所以该策略能够很好地处理传感器的移动性。与此同时,随着节点数量的增加,测试结果分布结果略有降低,这是因为随着节点的增加,系统处理的任务量增加,导致精度下降,但结果仍接近(10,20)节点数量结果,验证了本文算法的有效性。

图11 不同数量节点移动和非移动(perfectCSI)情况下的CDF
5 结语
机器学习方法在无线网络中的应用能够降低系统决策的计算复杂度并提升系统实时性。本文针对SWIPT使能的边缘无线网络,设计系统运行周期,提出基于深度强化学习的联合优化方法。通过设计系统信息交换过程建立IDDPG算法,实现网络中波束成形决策、功率控制决策、计算卸载决策的联合求解。仿真结果验证了本文方法的有效性,同时通过与多种最优化方法和机器学习方法对比,表明本文所述方法在降低计算复杂度,提升决策实时性方面的优势。
[1] 刘通,方璐,高洪皓. 边缘计算中任务卸载研究综述[J]. 计算机科学, 2021, 48(1):11-15.(LIU T, FANG L, GAO H H. Survey of task offloading in edge computing[J]. Computer Science, 2021, 48(1): 11-15.)
[2] 陈霄,刘巍,陈静,等. 边缘计算环境下的计算卸载策略研究[J]. 火力与指挥控制, 2022, 47(1):7-14, 19.(CHEN X, LIU W, CHEN J, et al. Research on computing offload strategy in edge computing environment[J]. Fire Control & Command Control, 2022, 47(1):7-14, 19.)
[3] LIU H, JIA H, CHEN J, et al. Computing resource allocation of mobile edge computing networks based on potential game theory[EB/OL]. [2022-11-16].https://arxiv.org/pdf/1901.00233.pdf.
[4] WANG G, XU F. Regional intelligent resource allocation in mobile edge computing based vehicular network[J]. IEEE Access, 2020, 8: 7173-7182.
[5] 鲜永菊,宋青芸,郭陈榕,等. 计算资源受限MEC中任务卸载与资源分配方法[J]. 小型微型计算机系统, 2022, 43(8):1782-1787.(XIAN Y J, SONG Q Y, GUO C R, et al. Method of task offloading and resource allocation in MEC with limited computing resources[J]. Journal of Chinese Computer Systems, 2022, 43(8):1782-1787.)
[6] 李余,何希平,唐亮贵. 基于终端直通通信的多用户计算卸载资源优化决策[J]. 计算机应用, 2022, 42(5):1538-1546.(LI Y, HE X P, TANG L G. Multi-user computation offloading and resource optimization policy based on device-to-device communication[J]. Journal of Computer Applications, 2022, 42(5):1538-1546.)
[7] 李燕君,蒋华同,高美惠. 基于强化学习的边缘计算网络资源在线分配方法[J]. 控制与决策, 2022, 37(11): 2880-2886.(LI Y J, JIANG H T, GAO M H. Reinforcement learning-based online resource allocation for edge computing network[J]. Control and Decision, 2022, 37(11): 2880-2886.)
[8] 朱思峰,蔡江昊,柴争义,等. 车联网边缘场景下基于免疫算法的计算卸载优化[J/OL]. 吉林大学学报(工学版) (2022-07-26) [2022-11-16].https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13229/j.cnki.jdxbgxb20220193.(ZHU S F, CAI J H, CHAI Z Y, et al. A novel computing offloading optimization scheme based on immune algorithm in edge computing scenes of internet of vehicles[J/OL]. Journal of Jilin University (Engineering and Technology Edition) (2022-07-26) [2022-11-16].https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.13229/j.cnki.jdxbgxb20220193.)
[9] 李斌,刘文帅,谢万城,等. 智能超表面赋能移动边缘计算部分任务卸载策略[J]. 电子与信息学报, 2022, 44(7):2309-2316.(LI B, LIU W S, XIE W C, et al. Partial computation offloading for double-RIS assisted multi-user mobile edge computing networks[J]. Journal of Electronics and Information Technology, 2022, 44(7): 2309-2316.)
[10] CHEN F, WANG A, ZHANG Y, et al. Energy efficient SWIPT based mobile edge computing framework for WSN-assisted IoT[J]. Sensors, 2021, 21(14): No.4798.
[11] FU J, HUA J, WEN J, et al. Optimization of achievable rate in the multiuser satellite IoT system with SWIPT and MEC[J]. IEEE Transactions on Industrial Informatics, 2021, 17(3): 2072-2080.
[12] TIONG T, SAAD I, KIN TEO K T, et al. Deep reinforcement learning online offloading for SWIPT multiple access edge computing network[C]// Proceedings of the IEEE 11th International Conference on System Engineering and Technology. Piscataway: IEEE, 2021: 240-245.
[13] LI N, HAO W, ZHOU F, et al. Smart grid enabled computation offloading and resource allocation for SWIPT-based MEC system[J]. IEEE Transactions on Circuits and Systems Ⅱ: Express Briefs, 2022, 69(8): 3610-3614.
[14] WANG X, LI J, NING Z, et al. Wireless powered mobile edge computing networks: a survey[J]. ACM Computing Surveys, 2023, 55(13s): No.263.
[15] MUSTAFA E, SHUJA J, BILAL K, et al. Reinforcement learning for intelligent online computation offloading in wireless powered edge networks[J]. Cluster Computing, 2023, 26(2): 1053-1062.
[16] 施安妮,李陶深,王哲,等.基于缓存辅助的全双工无线携能通信系统的中继选择策略[J]. 计算机应用, 2021, 41(6):1539-1545.(SHI A N, LI T S, WANG Z, et al. Relay selection strategy for cache-aided full-duplex simultaneous wireless information and power transfer system[J]. Journal of Computer Applications, 2021, 41(6):1539-1545.)
[17] 陈艳,王子健,赵泽,等. 传感器网络环境监测时间序列数据的高斯过程建模与多步预测[J]. 通信学报, 2015, 36(10): 252-262.(CHEN Y, WANG Z J, ZHAO Z, et al. Gaussian process modeling and multi-step prediction for time series data in wireless sensor network environmental monitoring[J]. Journal on Communications, 2015, 36(10): 252-262.)
[18] 侯艳丽,苏佳,胡佳伟. 基于有限反馈机会波束的无线传感器网络[J]. 传感器与微系统, 2014, 33(2): 57-60.(HOU Y L, SU J, HU J W. Wireless sensor networks based on finite feedback opportunistic beamforming[J]. Transducer and Microsystem Technologies, 2014, 33(2): 57-60.)
[19] DENT P, BOTTOMLEY G E, CROFT T. Jakes fading model revisited[J]. Electronics Letters, 1993, 29(13):1162-1163.
[20] 王强,王鸿. 智能反射面辅助的下行NOMA系统和速率最大化研究[J]. 南京邮电大学学报(自然科学版), 2022, 42(1): 23-29.(WANG Q, WANG H. On sum rate maximization for IRS-aided downlink NOMA systems[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2022, 42(1): 23-29.)
[21] 吴毅凌,李红滨,赵玉萍. 一种适用于时不变信道的信道估计方法[J]. 高技术通讯, 2010, 20(1): 1-7.(WU Y L, LI H B, ZHAO Y P. A novel channel estimation method for time-invariant channels[J]. Chinese High Technology Letters, 2010, 20(1): 1-7.)
[22] SEID A M, BOATENG G O, ANOKYE S, et al. Collaborative computation offloading and resource allocation in multi-UAV assisted IoT networks: a deep reinforcement learning approach[J]. IEEE Internet of Things Journal, 2021, 8(15): 12203-12218.
[23] 罗斌,于波. 移动边缘计算中基于粒子群优化的计算卸载策略[J]. 计算机应用, 2020, 40(8):2293-2298.(LUO B, YU B. Computation offloading strategy based on particle swarm optimization in mobile edge computing[J]. Journal of Computer Applications, 2020, 40(8): 2293-2298.)
[24] LUO Z Q, ZHANG S. Dynamic spectrum management: complexity and duality[J]. IEEE Journal of Selected Topics in Signal Processing, 2008, 2(1): 57-73.
[25] 张淑兴,马驰,杨志学,等. 基于深度确定性策略梯度算法的风光储系统联合调度策略[J]. 中国电力, 2023, 56(2): 68-76.(ZHANG S X, MA C, YANG Z X, et al. Deep deterministic policy gradient algorithm based wind-photovoltaic-storage hybrid system joint dispatch[J]. Electric Power, 2023, 56(2): 68-76.)
[26] 韩佶,苗世洪, JON M R, 等. 基于机群划分与深度强化学习的风电场低电压穿越有功/无功功率联合控制策略[J]. 中国电机工程学报, 2023, 43(11): 4228-4244.(HAN J, MIAO S H, JON M R, et al. Combined re/active power control for wind farm under low voltage ride through based on wind turbines grouping and deep reinforcement learning[J]. Proceedings of the CSEE, 2023, 43(11): 4228-4244.)
[27] 邓晖奕,李勇振,尹奇跃. 引入通信与探索的多智能体强化学习QMIX算法[J]. 计算机应用, 2023, 43(1): 202-208.(DENG H Y, LI Y Z, YIN Q Y. Improved QMIX algorithm from communication and exploration for multi-agent reinforcement learning[J]. Journal of Computer Applications, 2023, 43(1): 202-208.)
[28] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2022-11-16].https://arxiv.org/pdf/1509.02971.pdf.
[29] 蒋宝庆,陈宏滨. 基于Q学习的无人机辅助WSN数据采集轨迹规划[J]. 计算机工程, 2021, 47(4): 127-134, 165.(JIANG B Q, CHEN H B. Trajectory planning for unmanned aerial vehicle assisted WSN data collection based on Q-learning[J]. Computer Engineering, 2021, 47(4): 127-134, 165.)
[30] SUN H, CHEN X, SHI Q, et al. Learning to optimize: training deep neural networks for interference management[J]. IEEE Transactions on Signal Processing, 2018, 66(20): 5438-5453.
[31] 李烨,肖梦巧. 大规模MIMO系统中功率分配的深度强化学习方法[J/OL]. 小型微型计算机系统 (2022-08-01) [2022-11-16].http://kns.cnki.net/kcms/detail/21.1106.TP.20220729.1115.010.html.(LI Y, XIAO M Q. Deep reinforcement learning approach for power allocation in massive MIMO systems[J/OL]. Journal of Chinese Computer Systems [2022-11-16].http://kns.cnki.net/kcms/detail/21.1106.TP.20220729.1115.010.html.)
[32] 张先超,赵耀,叶海军,等. 无线网络多用户干扰下智能发射功率控制算法[J]. 通信学报, 2022, 43(2): 15-21.(ZHANG X C, ZHAO Y, YE H J, et al. Intelligent transmit power control algorithm for the multi-user interference of wireless network[J]. Journal on Communications, 2022, 43(2): 15-21.)
[33] 陶丽佳,赵宜升,徐新雅. 无人机协助边缘计算的能量收集MEC系统资源分配策略[J]. 南京邮电大学学报(自然科学版), 2022, 42(1): 37-44.(TAO L J, ZHAO Y S, XU X Y. Resource allocation strategy for UAV-assisted edge computing in energy harvesting MEC system[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2022, 42(1): 37-44.)
[34] SHEN K, YU W. Fractional programming for communication systems — Part I: power control and beamforming[J]. IEEE Transactions on Signal Processing, 2018, 66(10): 2616-2630.
Joint optimization method for SWIPT edge network based on deep reinforcement learning
WANG Zhe1,2,3, WANG Qiming2, LI Taoshen4, GE Lina1,3,5
(1,,530006,;2,,530006,;3(),530006,;4,,,530004,;5,,530006,;)
Edge Computing (EC) and Simultaneous Wireless Information and Power Transfer (SWIPT) technologies can improve the performance of traditional networks, but they also increase the difficulty and complexity of system decision-making. The system decisions designed by optimization methods often have high computational complexity and are difficult to meet the real-time requirements of the system. Therefore, aiming at Wireless Sensor Network (WSN) assisted by EC and SWIPT, a mathematical model of system energy efficiency optimization was proposed by jointly considering beamforming, computing offloading and power control problems in the network. Then, concerning the non-convex and parameter coupling characteristics of this model, a joint optimization method based on deep reinforcement learning was proposed by designing information interchange process of the system. This method did not need to build an environmental model and adopted a reward function instead of the Critic network for action evaluation, which could reduce the difficulty of decision-making and improve the system real-time performance. Finally, based on the joint optimization method, an Improved Deep Deterministic Policy Gradient (IDDPG) algorithm was designed. Simulation comparisons were made with a variety of optimization algorithms and machine learning algorithms to verify the advantages of the joint optimization method in reducing the computational complexity and improving real-time performance of decision-making.
Wireless Sensor Network (WSN); deep reinforcement learning; SWIPT (Simultaneous Wireless Information and Power Transfer); Edge Computing (EC); joint optimization
1001-9081(2023)11-3540-11
10.11772/j.issn.1001-9081.2022111732
2022⁃11⁃22;
2023⁃04⁃30;
国家自然科学基金资助项目(61862007); 广西自然科学基金资助项目(2020GXNSFBA297103); 广西民族大学引进人才科研启动项目(2019KJQD17)。
王哲(1991—),男,河南南阳人,副教授,博士,CCF会员,主要研究方向:计算机网络、携能通信、联邦机器学习; 王启名(1997—),男,江苏宿迁人,硕士研究生,主要研究方向:计算机网络、携能通信、机器学习; 李陶深(1957—),男,广西南宁人,教授,博士,CCF杰出会员,主要研究方向:移动无线网络、无线能量传输、物联网、智慧城市; 葛丽娜(1969—),女,广西环江人,教授,博士,CCF高级会员,主要研究方向:网络与信息安全、移动计算、人工智能。
2023⁃05⁃12。
This work is partially supported by National Natural Science Foundation of China (61862007), Natural Science Foundation of Guangxi Province (2020GXNSFBA297103), Scientific Research Start Project of Talents Introduced by Guangxi Minzu University (2019KJQD17).
WANG Zhe, born in 1991, Ph. D., associate professor. His research interests include computer network, simultaneous information and power transfer, federated machine learning.
WANG Qiming, born in 1997, M. S. candidate. His research interests include computer network, simultaneous information and power transfer, machine learning.
LI Taoshen, born in 1957, Ph. D., professor. His research interests include mobile wireless network, wireless energy transmission, internet of things, smart city.
GE Lina, born in 1969, Ph. D., professor. Her research interests include network and information security, mobile computing, artificial intelligence.
