基于用户兴趣概念格约简的推荐评分预测算法
2023-11-29赵学健李豪唐浩天
赵学健,李豪,唐浩天
基于用户兴趣概念格约简的推荐评分预测算法
赵学健1*,李豪2,唐浩天2
(1.邮政大数据技术与应用工程中心(南京邮电大学),南京 210003; 2.南京邮电大学 现代邮政学院,南京 210003)( ∗ 通信作者电子邮箱zhaoxj@njupt.edu.cn)
数据稀疏性制约了推荐系统的性能,而合理填充评分矩阵中的缺失值可以有效提升预测的准确性。因此,提出一种基于用户兴趣概念格约简的推荐评分预测(RRP-CLR)算法。该算法包含近邻选择和评分预测两个模块,分别负责生成精简最近邻集合和实现评分预测及推荐。近邻选择模块将用户评分矩阵转化为二进制矩阵后作为用户兴趣形式背景,提出了形式背景约简规则和概念格冗余概念删除规则,以提高生成精简最近邻的效率;在评分预测模块利用新提出的用户相似度计算方法,消除用户主观因素造成的评分差异对相似度计算的影响,而且当两个用户共同评分项目数小于特定阈值时,适当缩放相似度,使用户间的相似度与真实情况更吻合。实验结果表明,与使用皮尔逊相关系数的基于用户的协同过滤推荐算法(PC-UCF)及基于用户兴趣概念格的推荐评分预测方法(RRP-UICL)相比,RRP-CLR算法的平均绝对误差(MAE)和均方根误差(RMSE)更小,具有更好的评分预测准确率和稳定性。
推荐系统;评分预测;概念格;稀疏性;精简最近邻
0 引言
移动互联网和物联网技术的普及引发了数据生成方式的变革,催生了大数据时代的来临。用户面临海量的数据,如何高效进行检索分析,获取对自己有价值的信息成为难题,这种现象被称为信息过载[1]。推荐系统作为解决信息过载问题的主要技术之一,近年来受到了学术界和工业界的广泛关注[2-3]。目前推荐系统中最常用的方法是协同过滤(Collaborative Filtering, CF)推荐算法。协同过滤推荐算法的主要思想是根据用户的历史行为数据,比如用户对项目的评分数据,分析用户与项目之间的关系,并依此给出相应的推荐[4-5]。
然而在实际应用中,由于评分数据集维度规模较大,数据的稀疏程度较高,导致传统的协同过滤推荐算法的推荐准确性较低[6],数据稀疏性成为制约推荐系统应用的瓶颈。为解决这一问题,研究人员进行了大量研究。研究表明,对评分矩阵中的缺失值进行有效的预测填充,有助于提升推荐算法的准确性[7]。
本文提出一种基于用户兴趣概念格约简的推荐评分预测(Recommendation Rating Prediction based on Concept Lattice Reduction, RRP-CLR)算法。RRP-CLR算法包含近邻选择和评分预测两个模块,分别负责生成精简最近邻集合和实现评分预测及推荐。本文主要工作包括:
1)基于概念格及其约简理论,实现对目标用户的近邻用户的有效精简,生成精简最近邻,提高评分预测的准确率。首先,将用户评分矩阵转化为二进制矩阵并作为用户兴趣形式背景,提出形式背景约简规则,提高概念格构建效率;其次,提出概念格冗余概念删除规则,提高生成目标用户精简最近邻的有效性。
2)提出新的用户相似度计算方法,消除用户主观因素造成的评分差异对相似度计算的影响,在两个用户共同评分项目数小于特定阈值时,适当缩放相似度,使用户间的相似度与真实情况更加吻合。
3)通过实验验证了RRP-CLR算法评分预测的准确性。
1 相关工作
为有效填充评分矩阵中的缺失值,研究人员开展了一系列探索性研究。相关研究成果可归纳为以下4类:
1)基于协同过滤思想进行评分预测。文献[8]中融合了基于用户和项目的协同过滤思想,利用相似用户或相似项目的评分信息进行评分预测,有效缓解了数据稀疏性问题。文献[9]中融合社交网络信息和用户评分信息,基于项目协同过滤框架,选择性地对评分矩阵中的缺失值进行评分预测,解决评分矩阵数据稀疏性问题。
2)基于信任关系及信任传递机制进行评分预测。文献[10]中融合专家信任度和用户兴趣相似度进行评分预测,以降低数据的稀疏性。文献[11]中指出将社会信任纳入矩阵分解方法可以明显提高评分预测的准确性,首先通过推荐系统中用户之间的Hellinger距离,从用户对项目的评分中提取社会关系;然后将预测的信任分数纳入社会矩阵分解模型实现评分预测。文献[12]中提出了一个简单、可扩展的文本驱动潜在因素模型,通过捕获评论语义、用户偏好和产品特征的语义,将文本分解为特定的低维表示,利用普通用户/产品评级之间的差异作为补充信息校准参数估计,准确进行评分预测,解决冷启动和数据稀疏问题。文献[13]中提出了一种新的隐式信任推荐方法,通过挖掘和利用推荐系统中的用户隐式信息生成项目预测评分。具体来说,首先通过信任网络中的用户信任扩散特征获取用户信任邻居集;接着,利用从用户信任邻居集中挖掘出的信任等级计算用户之间的信任相似度;最后,使用过滤的信任等级和用户信任相似性,通过信任加权方法得到预测结果。文献[14]中提出了一种改进的协同过滤推荐算法,该算法考虑到传统评分相似度计算过分依赖常用评分项目,引入了Bhattacharyya相似度计算方法和信任传递机制,计算用户之间的间接信任值,综合用户相似度和用户信任度,采用信任权重法生成评分预测结果。
3)基于深度学习模型进行评分预测。文献[15]中研究了用户因素和项目特征的真实性质之间的非线性复杂关系对评分预测的影响,提出了一种新的深度前馈网络学习相关因素及其复杂关系,在不使用任何人口统计信息的情况下自动构建用户配置文件和项目特征,然后使用这些构建的特征预测项目对用户的可接受程度,产生更好的评级预测。文献[16]中提出了一种基于评论、产品类别和用户共同购买信息的神经网络联合学习模型,用于评级预测推荐。该模型的评论提取模块从评论中学习用户和产品信息,异构信息网络提取模块则提取给定目标用户-产品对的关联特征,连接两部分数据即可实现评分预测。文献[17]中指出现有的基于用户的协同过滤(User-based CF, UCF)推荐算法往往关注如何查找最近的概念邻居以及如何基于预测生成推荐,忽略了如何聚合邻居的评分以预测未评分项目的评分,并为此提出了一种基于个人不对称响应的建议聚合算法。该算法首先使用线性回归方法了解每个用户对来自邻居的负面/正面建议的响应,然后使用梯度下降算法对用户的模型参数进行优化,从而实现更加准确的评分预测。文献[18]中提出一个异构融合推荐模型,用于从评论文本中提取细粒度的产品属性和用户行为信息,并将用户学习到的潜在因素和项目连接起来,在图上执行空间卷积,提升推荐评分的预测精度和推荐准确率。为了深入挖掘用户行为的潜在规律,文献[19]中提出了基于空间维度和距离测量的方差模型以及基于空间维度和距离测量的皮尔森相关系数模型,这两个模型通过计算项目和用户在每个特征维度中的距离来获得项目和用户的交互特征,分别利用方差和皮尔逊相关系数评估用户对每个特征维度的关注程度,从而进一步获得交互特征的权重向量,并采用专门设计的多层全连接神经网络进行评级预测。
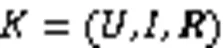
2 算法理论基础
2.1 概念格
概念格来源于形式概念分析(Formal Concept Analysis,FCA)理论,是形式概念分析理论中的核心数据分析工具,它本质上描述了对象(样本)与属性(特征)之间的关联。形式概念分析包括形式背景和形式概念两部分核心内容。

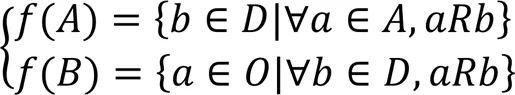
2.2 概念格约简理论
3 基于概念格的推荐评分预测算法
本文基于概念格及其约简理论提出一种用户评分预测及推荐算法RRP-CLR,包含近邻选择和评分预测两个模块。近邻选择模块主要负责将评分矩阵转化为二进制矩阵,并通过用户兴趣概念格构造及约简实现目标用户广义最近邻的筛选,从而得到精简最近邻;评分预测模块主要负责计算用户之间的相似度,并完成目标用户对项目的评分预测,实现Top-推荐。
3.1 近邻选择模块

表1 用户评分矩阵
表2 二进制矩阵

图1 概念格

图2 精简概念格
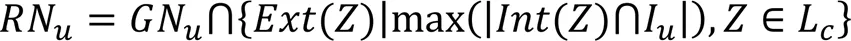
3.2 评分预测模块
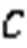
综上所述,用户相似度计算方法如下所示:

完成用户之间相似度计算后,可根据式(4)计算目标用户对项目的预测评分:

评分预测完成后便可从所有项目中为目标用户选择评分最高的个项目进行TOP-推荐。
4 实验与结果分析
本文使用MovieLens数据集(https://grouplens.org/datasets/movielens/)对RRP-CLR算法的性能进行验证,该数据集包含了943名不同用户对1 682部电影的10万个评分。评分1~5表示用户对电影的喜爱程度,从1到5表示偏爱程度逐渐增大。原始MovieLens数据集中的可用评分数量过多,密度偏大,而RRP-CLR算法主要用于解决数据稀疏情况下的评分预测问题,因此本文在实验过程中对MovieLens数据集中现有评分进行随机清除;将数据集ML-1稀疏度设置为98%,保留可用评分31 726条;数据集ML-2稀疏度设置为99%,保留可用评分15 889条。
4.1 评价指标
本文主要采用平均绝对误差(Mean Absolute Error, MAE)和均方根误差(Root Mean Squared Error, RMSE)评价RRP-CLR算法的性能,并与文献[20]提出的基于用户兴趣概念格的推荐评分预测方法(Recommendation Rating Prediction method based on User Interest Concept Lattice, RRP-UICL)及使用皮尔逊相关系数的UCF推荐算法(UCF recommendation algorithm based on Pearson Coefficient, PC‑UCF)[20]进行对比分析。

RMSE也称之为标准误差,是均方误差的算术平方根。引入RMSE与引入标准差的原因是完全一致的,但均方误差的量纲与数据量纲不同,不能直观反映离散程度,故在均方误差上开平方根,得到RMSE。在本方法中,RMSE表示所有预测用户评分和实际用户评分偏差平方和的均值的平方根。该指标也可以反映预测的精度,RMSE值越小,预测的精度越高;反之,RMSE值越大,预测的精度越低。与MAE指标不同的是,RMSE先对偏差作了一次平方,因此如果误差的离散度高,RMSE就会被加倍放大。因此,RMSE指标不仅可以反映预测的精度,同时可以反映预测的离散度。均方根误差RMSE的计算方法如式(6)所示:

4.2 实验结果
由图3可以看出,在数据集稀疏度、推荐项目数相同时,本文RRP-CLR算法的MAE比PC-UCF、RRP-UICL的MAE值更小。在数据集稀疏度为98%时,RRP-CLR、RRP-UICL和PC-UCF算法的MAE平均值分别为0.40、0.46和0.75。RRP-CLR算法的MAE相较于RRP-UICL及PC-UCF分别降低13.04%和46.7%。此外,三种算法在ML-1数据集中的MAE值均小于在ML-2数据集中的MAE值,表明数据集的稀疏度对算法的MAE具有显著影响,数据集稀疏度变大时,MAE相应增大。数据集稀疏度由98%增大到99%时,RRP-CLR算法对应的MAE平均增加8.07%,小于RRP-UICL的11.97%和PC-UCF的39.36%,表明RRP-CLR算法在数据集稀疏度较高的情况下优势更大。总之,在稀疏场景下,RRP-CLR算法基于概念格及其约简理论,实现了对目标用户的近邻用户的有效精简,生成精简最近邻,相较于PC-UCF及RRP-UICL具有更高的预测精度。
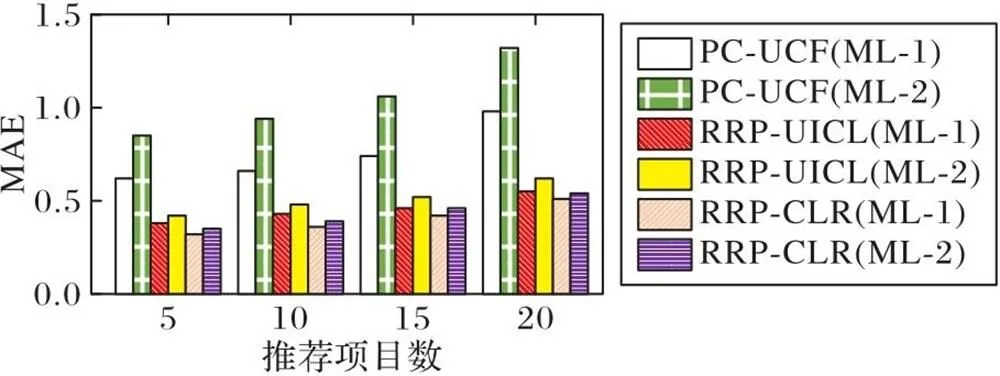
图3 MAE对比分析
由图4可以看出,在数据集稀疏度为98%时,RRP-CLR、RRP-UICL和PC-UCF算法的RMSE值分别为0.61、0.76和0.99。当数据集稀疏度由98%增大到99%时,RRP-CLR算法对应的RMSE平均增加13.89%,小于RRP-UICL的21.05%和PC-UCF的39.93%,表明RRP-CLR算法在数据集稀疏度较高的情况下预测结果稳定性愈发突出。总之,与MAE指标类似,在数据集稀疏度、推荐项目数相同时,RRP-CLR算法的RMSE值比PC-UCF、RRP-UICL的RMSE值也更小,且稀疏度越高,优势越明显,表明RRP-CLR算法不仅具有更好的预测精度,而且预测的离散度更小,即预测结果的稳定性更高。

图4 RMSE对比分析
5 结语
针对数据稀疏性导致的推荐算法准确率下降问题,提出一种基于概念格的评分预测填充算法。该算法将用户评分矩阵转化为二进制矩阵,并将该矩阵视为用户兴趣形式背景,提出了形式背景约简规则及概念格冗余概念删除规则,提高了概念格构建效率及生成目标用户精简最近邻的有效性。此外,该算法采用了新的用户相似度计算方法,消除了用户主观因素带来的评分差异对相似度计算的影响,并在两个用户共同评分项目数小于特定阈值时,对相似度进行适当的缩放,使用户间的相似度与真实情况更吻合。实验结果表明,本文 算法在数据集具有明显稀疏性时具有更好的预测准确度和稳定性。
[1] 刘华锋,景丽萍,于剑. 融合社交信息的矩阵分解推荐方法研究综述[J]. 软件学报, 2018, 29(2):340-362.(LIU H F, JING L P, YU J. Survey of matrix factorization based recommendation methods by integrating social information[J]. Journal of Software, 2018, 29(2): 340-362.)
[2] LIU L, DU X, ZHU L, et al. Learning discrete hashing towards efficient fashion recommendation[J]. Data Science and Engineering, 2018, 3(4):307-322.
[3] GAO D, TONG Y, SHE J, et al. Top-team recommendation and its variants in spatial crowdsourcing[J]. Data Science and Engineering, 2017, 2(2): 136-150.
[4] WANG C D, DENG Z H, LAI J H, et al. Serendipitous recommendation in e-commerce using innovator-based collaborative filtering[J]. IEEE Transactions on Cybernetics, 2019, 49(7): 2678-2692.
[5] SRIVASTAVA R, PALSHIKAR G K, CHAURASIA S, et al. What’s next? A recommendation system for industrial training[J]. Data Science and Engineering, 2018, 3(3): 232-247.
[6] ADOMAVICIUS G, TUZHILIN A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734-749.
[7] BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]// Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 1998: 43-52.
[8] WANG J, DE VRIES A P, REINDERS M J T. Unifying user-based and item-based collaborative filtering approaches by similarity fusion[C]// Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2006: 501-508.
[9] 郭兰杰,梁吉业,赵兴旺. 融合社交网络信息的协同过滤推荐算法[J]. 模式识别与人工智能, 2016, 29(3):281-288.(GUO L J, LIANG J Y, ZHAO X W. Collaborative filtering recommendation algorithm incorporating social network information[J]. Pattern Recognition and Artificial Intelligence, 2016, 29(3): 281-288.)
[10] 张俊,刘满,彭维平,等. 融合兴趣和评分的协同过滤推荐算法[J]. 小型微型计算机系统, 2017, 38(2):357-362.(ZHANG J, LIU M, PENG W P, et al. Collaborative filtering recommendation algorithm based on fusion interest and score[J]. Journal of Chinese Computer Systems, 2017, 38(2):357-362.)
[11] TAHERI S M, MAHYAR H, FIROUZI M, et al. Extracting implicit social relation for social recommendation techniques in user rating prediction[C]// Proceedings of the 26th International Conference on World Wide Web Companion. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2017: 1343-1351.
[12] SONG K, GAO W, SHI F, et al. Recommendation vs sentiment analysis: a text-driven latent factor model for rating prediction with cold-start awareness[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 2744-2750.
[13] LI Y, LIU J, REN J, et al. A novel implicit trust recommendation approach for rating prediction[J]. IEEE Access, 2020, 8:98305-98315.
[14] CHEN H, SUN H, CHENG M, et al. A recommendation approach for rating prediction based on user interest and trust value[J]. Computational Intelligence and Neuroscience, 2021, 2021: No.6677920.
[15] PURKAYSTHA B, DATTA T, ISLAM M S, et al. Rating prediction for recommendation: constructing user profiles and item characteristics using backpropagation[J]. Applied Soft Computing, 2019, 75:310-322.
[16] TANG J, ZHANG X, ZHANG M, et al. A neural joint model for rating prediction recommendation[J]. Journal of Computational Methods in Sciences and Engineering, 2020, 20(4):1127-1142.
[17] JI S, YANG W, GUO S, et al. Asymmetric response aggregation heuristics for rating prediction and recommendation[J]. Applied Intelligence, 2020, 50(5): 1416-1436.
[18] YANG Z, ZHANG M. TextOG: a recommendation model for rating prediction based on heterogeneous fusion of review data[J]. IEEE Access, 2020, 8: 159566-159573.
[19] ZHOU D, HAO S, ZHANG H, et al. Novel SDDM rating prediction models for recommendation systems[J]. IEEE Access, 2021, 9: 101197-101206.
[20] 朵琳,杨丙. 一种基于用户兴趣概念格的推荐评分预测方法[J]. 小型微型计算机系统, 2020, 41(10): 2104-2108.(DUO L, YANG B. Recommendation rating prediction based on user interest concept lattice[J]. Journal of Chinese Computer Systems, 2020, 41(10): 2104-2108.)
Recommendation rating prediction algorithm based on user interest concept lattice reduction
ZHAO Xuejian1*, LI Hao2, TANG Haotian2
(1(),210003,;2,,210003,)
The performance of the recommendation systems is restricted by data sparsity, and the accuracy of prediction can be effectively improved by reasonably filling the missing values in the rating matrix. Therefore, a new algorithm named Recommendation Rating Prediction based on Concept Lattice Reduction (RRP-CLR) was proposed. RRP-CLR algorithm was composed of nearest neighbor selection module and rating prediction module, which were respectively responsible for generating reduced nearest neighbor set and realizing rating prediction and recommendation. In the nearest neighbor selection module, the user rating matrix was transformed into a binary matrix, which was regarded as the user interest formal background. Then the formal background reduction rules and concept lattice redundancy concept deletion rules were proposed to improve the efficiency of generating reduced nearest neighbors. In the rating prediction module, a new user similarity calculation method was proposed to eliminate the impact of rating deviations caused by user’s subjective factors on similarity calculation. When the number of common rating items of two users was less than a specific threshold, the similarity was scaled appropriately to make the similarity between users more consistent with the real situation. Experimental results show that compared with PC‑UCF (User-based Collaborative Filtering recommendation algorithm based on Pearson Coefficient) and RRP-UICL (Recommendation Rating Prediction method based on User Interest Concept Lattice), RRP-CLR algorithm has smaller Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE), and better rating prediction accuracy and stability.
recommendation system; rating prediction; concept lattice; sparsity; reduced nearest neighbor
1001-9081(2023)11-3340-06
10.11772/j.issn.1001-9081.2022121839
2022⁃12⁃07;
2023⁃01⁃18;
国家自然科学基金资助项目(61672299); 中国博士后科学基金资助项目(2018M640509)。
赵学健(1982—),男,山东临沂人,副教授,博士,主要研究方向:数据挖掘、无线传感器网络; 李豪(1999—),男,江苏扬州人,硕士研究生,主要研究方向:数据挖掘; 唐浩天(2001—),男,四川阿坝人,硕士研究生,主要研究方向:数据挖掘。
TP391
A
2023⁃02⁃01。
This work is partially supported by National Natural Science Foundation of China (61672299), China Postdoctoral Science Foundation (2018M640509).
ZHAO Xuejian, born in 1982, Ph. D., associate professor. His research interests include data mining, wireless sensor network.
LI Hao, born in 1999, M. S. candidate. His research interests include data mining.
TANG Haotian, born in 2001, M. S. candidate. His research interests include data mining.
