基于改进YOLO6D的工业零件位姿检测算法
2023-11-25管声启刘懂懂张理博
刘 通,管声启,刘懂懂,张理博
(西安工程大学机电工程学院,陕西 西安 710048)
0 引言
在“中国制造2025”背景下,机器换人的趋势愈发明显,目前分拣机器人已经被广泛应用于上料、装配和码垛等领域。工业零件作为机械制造业的重要产品,也是工业现场常见的分拣对象,实现其位姿检测是自动分拣的前提,对打造智能化分拣系统具有十分重要的现实意义。目标检测算法通常采用神经网络对零件进行识别定位,获取零件的平面位置、类别和置信度等信息,通过固定相机获取零件的z轴深度信息,并不能确定零件在空间内的位姿,导致应用场景受限[1-3]。
随着传感器硬件技术的发展,采用深度相机获取目标的图像信息和深度信息的方法开始兴起。同时,广大学者针对三维空间内工业零件的位姿检测问题开展了深入的研究。根据输入数据类型的不同,6D位姿检测方法可以分为以下3类。
a.基于点云输入的方法[4-7]。由于点云的稀疏性和无序性,采用点云输入检测工业零件的6D位姿鲁棒性较差。同时,处理点云数据需要大量的计算资源和时间,限制了位姿检测算法的实时性和实用性。
b.基于RGB-D图像的方法[8-9]。采用RGB-D图像检测工业零件的6D位姿虽然精度较高,但因为数据获取对光照和环境条件要求较高,导致应用场景有一定的限制性。
c.基于RGB图像的方法[10-12]。由于YOLO算法在目标检测领域大放异彩,Tekin等[13]将其扩展到三维空间并提出了YOLO6D位姿检测算法,以单张RGB图像作为输入,采用端到端的方式直接回归输出关键点位置信息,通过关键点在2D-3D空间中的映射关系,利用PnP算法[14]计算目标的6D位姿,但位姿检测精度和鲁棒性有待加强。
为解决工业现场散乱堆叠零件位姿难以准确检测的问题,本文提出改进YOLO6D的工业零件位姿检测算法,通过在制作的三维工业零件数据集上进行实验对比,验证了本文算法的有效性。
1 改进YOLO6D网络结构
本文提出的改进YOLO6D网络结构如图1所示。改进YOLO6D网络采用Darknet53作为主干特征提取网络,通过增加神经网络的深度提高特征提取能力;在Darknet53内部的残差块部分引入坐标注意力(coordinate attention,CA)机制[15],增强神经网络对坐标信息的表达能力;在颈部添加空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块[16],实现多尺度特征信息融合;将主干网络中的LeakyReLU函数替换为Mish函数[17],增强神经网络的鲁棒性。
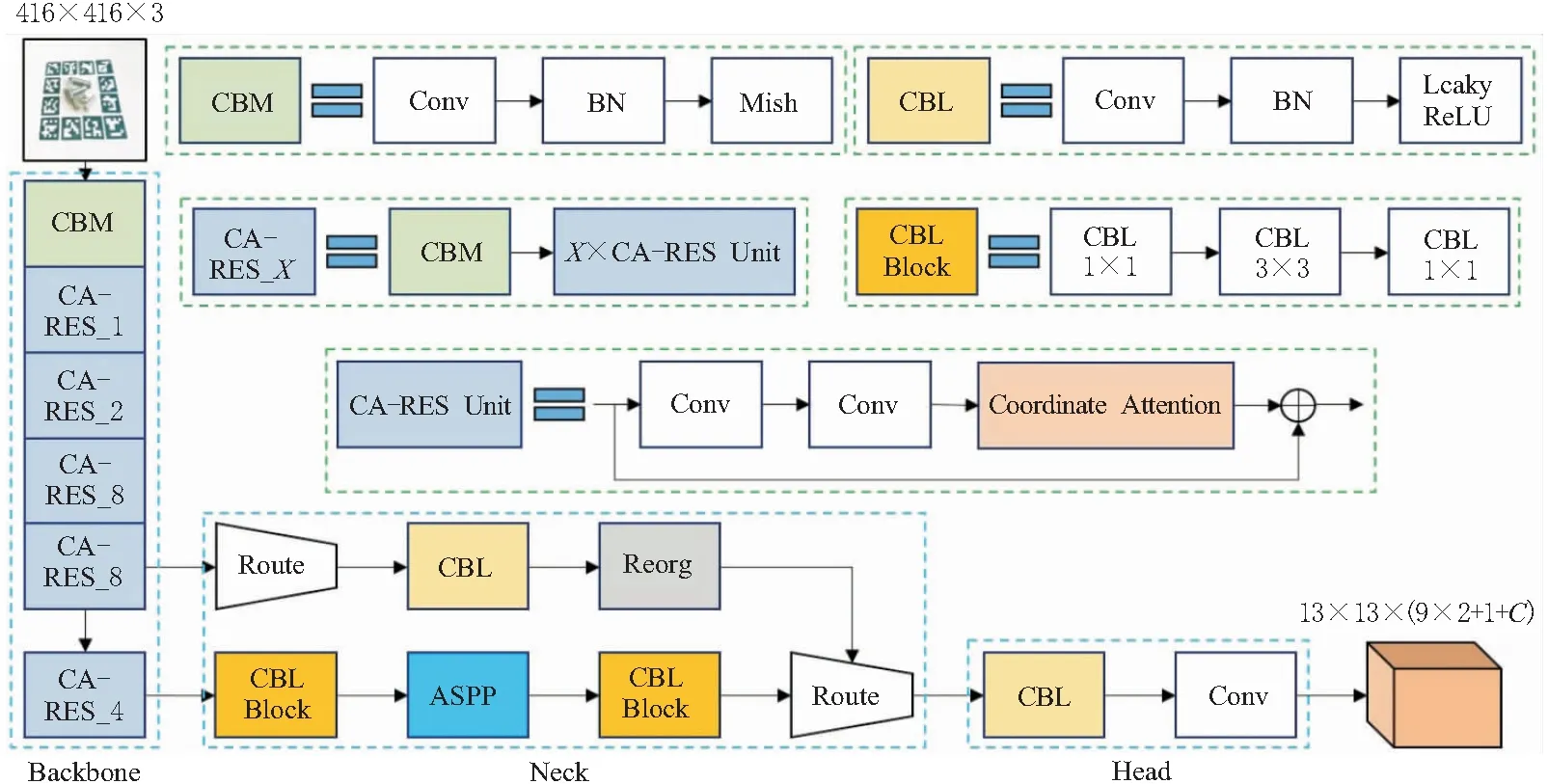
图1 改进YOLO6D网络整体结构
3D模型的8个边界角点及1个中心点可用于表示具有任意形状和拓扑关系的三维刚性物体,因此,将其作为描述物体6D位姿的关键点。将工业零件图像作为输入,采用如图1所示的神经网络架构提取目标特征信息,输出目标的9个关键点坐标、1个置信度值和C个类别概率。
1.1 坐标注意力机制
工业零件基本以银色金属为主,表面光滑,颜色单一,缺乏明显的纹理特征,使位姿检测增加了不小的难度。当工业零件相互遮挡时,目标特征信息缺失,将导致神经网络无法正确捕捉目标的关键特征,从而降低位姿检测精度。此外,神经网络深度的增加将更加注重抽象特征的提取,进一步弱化了对坐标信息的表达能力,降低了关键点的定位精度。针对以上问题,本文在残差块中引入CA注意力机制,用于捕获特征图在通道间的依赖关系和空间上的像素级关系,突出目标区域特征信息,抑制背景信息的干扰。其结构如图2所示,其中,C为特征图通道数,H为特征图高度,W为特征图宽度,r为控制特征图通道数的超参数。
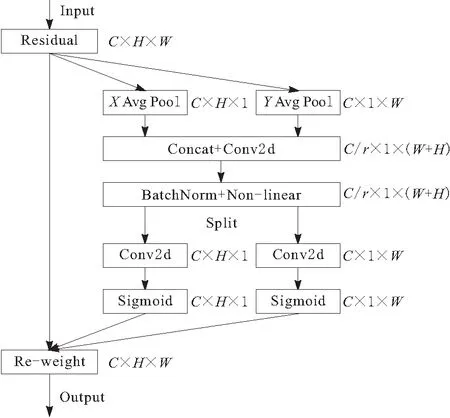
图2 坐标注意力机制模块
CA注意力机制模块不仅关注不同通道信息的关联性,还能感知方向信息和位置信息,有助于增强神经网络学习特征的表达能力,提高关键点定位的准确性,从而提升整体位姿检测的性能。
1.2 空洞空间金字塔池化
在一般目标检测中,通常采用最大池化下采样的方法增大感受野,扩大神经网络对输入图像的理解范围。然而,该方法会造成特征图分辨率降低,目标检测效果变差。因此,本文采用空洞卷积进行下采样,在扩大感受野的同时保持特征图的分辨率不变。获取不同的感受野可以捕获多尺度上下文信息,而分辨率保持不变可以提高目标的定位精度。本文在神经网络的特征融合部分引入以空洞卷积为主体而搭建的空洞空间金字塔池化模块,其结构如图3所示。

图3 空洞空间金字塔池化模块
ASPP空洞空间金字塔池化由1个1×1卷积层、3个3×3空洞卷积层和1个池化层组成。该模块采用1×1卷积层改变特征映射的通道数,在不改变特征图大小的情况下控制特征图的维度;采用具有不同采样率的多个并行空洞卷积层,提取图像中不同层次的语义信息;采用池化层提取图像的全局特征,从而获取具有上下文和全局信息的特征。将获取到的各种特征图在深度方向上进行堆叠,完成特征信息聚合,采用1×1卷积层对特征图降维,实现多尺度特征信息融合,提高神经网络位姿检测的精度。
1.3 激活函数
激活函数是一种非线性函数,用于改善神经网络的学习和表达能力。本文采用Mish函数替换原有的LeakyReLU函数作为主干特征提取网络的激活函数,可以实现加快收敛速度、提高模型精度及减少过拟合现象的效果。Mish函数和LeakyReLU函数的表达式为:
Mish(x)=x·tanh(ln(1+ex))
(1)
(2)
x为输入特征图;α为一个很小的常数;tanh(·)为非线性激活函数。
当输入为正值时,Mish函数具有无上界的特性,可以有效缓解梯度消失问题;当输入为负值时,Mish函数并不是完全截断,而是允许较小的负梯度流入,从而保证信息的流动。相比于LeakyReLU函数,Mish函数是非单调光滑函数,具有更好的连续性与可导性,有助于提高神经网络的泛化能力,增强模型的鲁棒性。
2 改进YOLO6D网络关键点预测方法
在2D目标检测中,通常采用预测框和真实框的交并比(intersection over union,IoU)作为置信度值。然而,在3D目标检测中,为了计算任意2个3D边界框的等效IoU分数,需要进行复杂的计算来确定重合的3D区域,计算的复杂性会极大降低训练速度,从而导致该方法应用较为困难。为保证预测的准确性,本文基于欧氏距离设计置信度函数,对预测的置信度值进行建模来代替IoU的计算。
(3)
DT(x)为预测坐标与真实坐标的欧氏距离;dth为置信度函数的像素阈值,设置为80;α为指数函数的锐度,设置为2。
对于9个关键点,并不是直接回归坐标,而是预测相对于网格单元左上角的坐标偏移。9个关键点在网格中分布如图4所示。
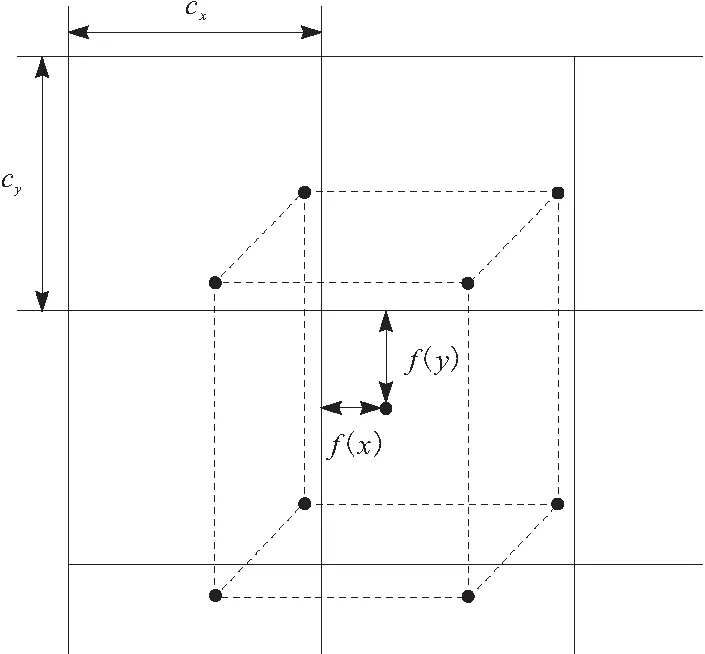
图4 关键点分布
中心点与网格的关联性导致其偏移被限制在网格之内,故采用sigmoid函数将网格的输出压缩到0~1之间。而其他8个角点则可能超出网格范围,不必对其进行限制。因此,9个关键点的坐标偏移可表示为:
g(x)=f(x)+cx
(4)
g(y)=f(y)+cy
(5)
cx、cy分别为坐标偏移量;对于中心点而言,f(·)为sigmoid函数;对于角点而言,f(·)为恒等函数。
通过求解总体损失函数的最小值,训练神经网络模型。
L=λptLpt+λconfLconf+λclsLcls
(6)
Lpt、Lconf和Lcls分别为坐标损失、置信度损失和分类损失;λpt、λconf和λcls分别为各项损失对应的系数。坐标损失和置信度损失采用均方误差损失函数,分类损失采用交叉熵损失函数。
给定9个关键点的坐标预测,采用PnP算法即可计算目标物体在三维空间内的6D位姿。
3 实验结果与分析
3.1 数据集制作
现有的位姿检测方法大多是在LineMOD与YCB-Video等公共数据集上进行训练测试,但公共数据集目标物皆为生活物品,无法为本文的工业零件位姿检测提供充足的数据。为此,本文重新制作了三维工业零件数据集。
实验平台包括Aruco码、工业零件、Intel Realsense D455深度相机和三脚架。其中,Aruco码由内部ID和外部边框构成,内部ID用于错误检测,外部边框用于标签定位;工业零件包括螺钉、螺母、螺栓、螺柱、支撑座和轴销共6类。本文实验共采集图像1 200张,其中,80%作为训练集,20%作为测试集,图像尺寸为640 pixel×480 pixel。数据集制作的整体流程如图5所示。
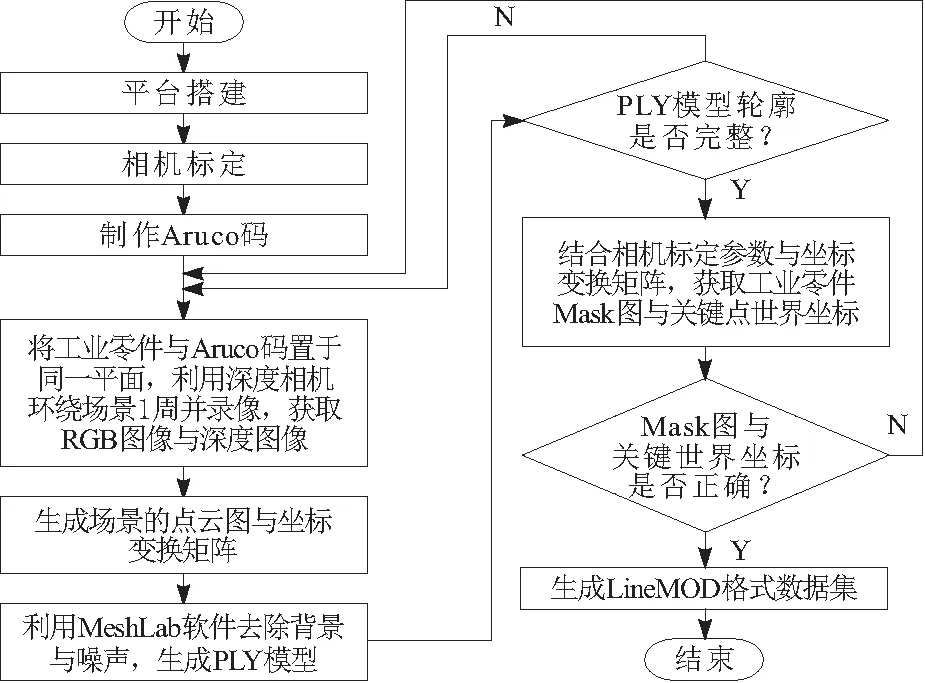
图5 三维工业零件数据集制作流程
首先,均匀分布Aruco码在实验场景中,将工业零件置于Aruco码包围的区域;其次,利用Intel Realsense D455深度相机环绕场景1周并录像,获取RGB图像与对应的深度图像,通过计算每帧相对第1帧实时位姿变化生成场景的点云图与坐标变换矩阵;再次,利用MeshLab软件去除点云图中的背景与噪声,生成每个工业零件对应的PLY模型;然后,结合相机标定参数与坐标变换矩阵,获取工业零件Mask图与关键点世界坐标;最后,通过Mask图获取关键点2D投影坐标,生成标签信息,完成工业零件LineMOD格式数据集制作。
3.2 实验环境配置
本文的实验环境分为硬件环境与软件环境2部分:硬件包括处理器为Intel(R) Core(TM) i7-7820X,机带RAM为16.0 GB,显卡为2张NVIDIA GeForce RTX 2080 Ti;软件包括64 bit Ubuntu操作系统,版本号为22.04.1 LTS,Anaconda 3,Python 3.6,Pytorch 0.4.1,Cuda 11.3及Cudnn 7.6.5。批次大小设置为8,训练轮次设置为200。初始学习率设置为0.001,每50轮降低为原来的0.1。
3.3 评估指标
基准标签与网格预测关键点坐标的不一致,将会造成旋转和平移矩阵的差异,进而导致位姿检测的结果存在误差。为了更加准确地说明位姿检测的效果,通常采用的评估指标如下。
a.2D重投影指标[18],表示预测关键点与真实关键点之间投影的平均距离,若平均距离小于5个像素,则判定正确。2D重投影定义为
eREP=‖pi-CHμ‖2
(7)
pi为像素i的位置;C为相机矩阵;H为目标位姿;μ为像素分布的混合权重最大的平均值。
b.ADD指标[19]表示预测位姿与实际位姿之间3D模型顶点的平均距离,若平均距离小于目标直径的10%,则判定正确。ADD定义为
(8)
m为3D模型顶点数量;M为3D模型顶点坐标集;x为3D模型顶点坐标集中的点;Rtru和Ttru分别为真实的旋转矩阵和平移矩阵;Rpre和Tpre分别为预测的平移矩阵和旋转矩阵。
针对具有对称性的物体在匹配点的过程中存在歧义的问题,采用ADD-S度量,平均距离基于最近点距离计算。由于本文采用的工业零件均为对称物体,因此采用ADD-S作为评估指标。ADD-S定义为
(9)
c.5 cm5°指标[20]表示6D位姿检测的精度。若预测位姿与实际位姿之间的平移误差和旋转误差分别低于5 cm和5°,则判定正确。平移误差和旋转误差定义为:
(10)
eR=arccos[(tr(RtruRpre-1)-1)/2]
(11)
tr( )为求矩阵的迹。
这3项评估指标均存在相对应的阈值判断条件,当满足阈值判断条件时,则判定位姿检测结果正确。由于各项指标表示满足该评估指标阈值判断条件的图像数在总图像中的占比,因此,各项指标数值越大表明位姿检测效果越好。
3.4 实验结果与分析
为了验证本文算法的有效性,本文采用2D重投影、ADD-S和5 cm5°作为评估指标在制作的三维工业零件数据集上进行实验验证,实验结果如表1所示。
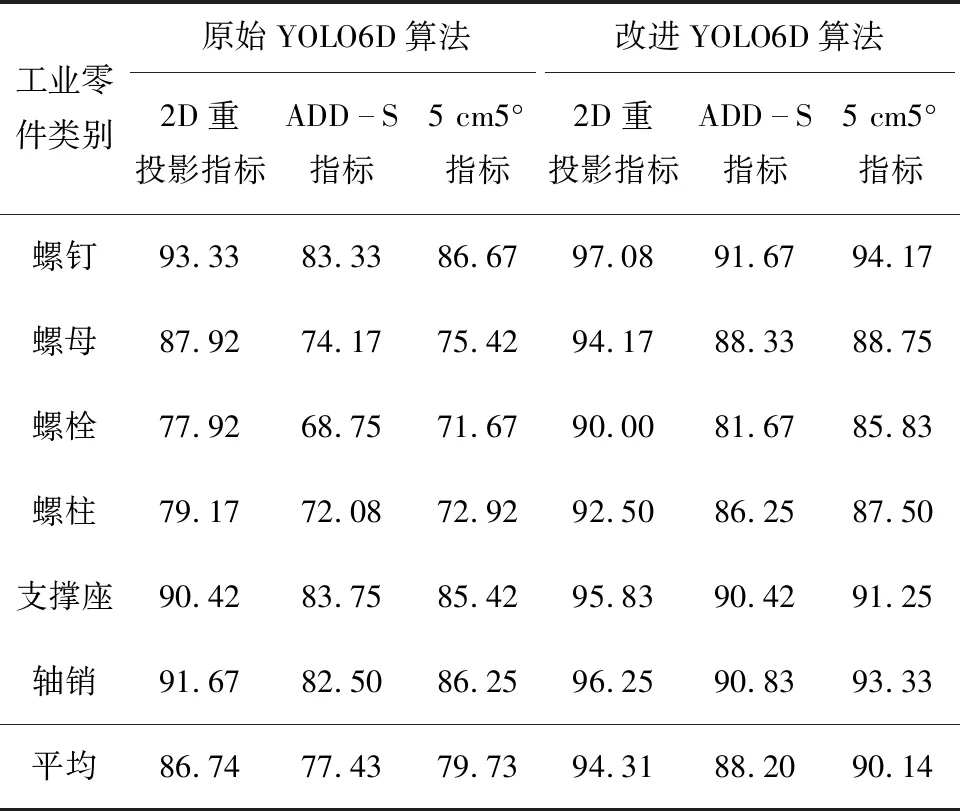
表1 实验结果对比 %
根据表1可知,相比于原始YOLO6D算法,改进YOLO6D算法在三维工业零件数据集上的平均2D重投影、ADD-S和5 cm5°指标分别提高了7.57百分点、10.77百分点和10.41百分点。对于堆叠放置的螺栓零件的位姿检测,各项指标分别提高了12.08百分点、12.92百分点和14.16百分点;对于遮挡放置的螺柱零件的位姿检测,各项指标分别提高了13.33百分点、14.17百分点和14.58百分点,取得了较为明显的提升。改进YOLO6D算法通过引入CA注意力机制和ASPP空洞空间金字塔池化,增强目标信息,抑制背景信息,对于堆叠放置和遮挡放置的工业零件可以实现较高精度的关键点定位与位姿检测。实验结果表明,本文所提出的改进YOLO6D算法在散乱堆叠场景下具有较强的鲁棒性,适用于工业零件的位姿检测。
为更加直观展示本文算法对于工业零件的位姿检测效果,对实验结果进行随机可视化,实验结果如图6所示。图6中,白色实线框表示基准位姿信息投影的3D边界框,黑色虚线框表示原始YOLO6D算法检测位姿信息投影的3D边界框,黑色实线框表示改进YOLO6D算法检测位姿信息投影的3D边界框。

图6 实验结果对比
根据图6可知,改进YOLO6D算法对于工业零件的位姿检测效果优于原始YOLO6D算法,更加接近基准位姿信息投影的3D边界框。对于未受遮挡的螺钉、螺母、支撑座与轴销4类零件,改进YOLO6D算法可以更准确地实现关键点定位与位姿检测;对于堆叠放置的螺栓零件,原始YOLO6D算法检测的关键点位置出现较大偏差,不利于准确描述螺栓的位姿信息,而改进YOLO6D算法形成了较为准确的3D边界框,提高了螺栓位姿检测的精度;对于受到遮挡的螺柱零件,改进YOLO6D算法依然取得了较好的位姿检测结果。综合分析可知,引入CA注意力机制和ASPP空洞空间金字塔池化可以使神经网络有效感知目标零件的方向信息与位置信息,弱化堆叠因素和遮挡因素带来的干扰,增强预测关键点向真实关键点逼近的能力,提高整体位姿检测的精度。通过对不同工业零件的位姿检测效果进行随机可视化,表明改进YOLO6D算法具有较高的准确性与鲁棒性。
4 结束语
为有效检测三维空间内工业零件的6D位姿,本文设计一种改进的YOLO6D网络结构。采用带有残差连接的Darknet53作为主干网络,并选择Mish函数作为激活函数,提高了特征提取能力的同时避免了神经网络的退化;引入坐标注意力机制,缓解了堆叠因素和遮挡因素引起的特征信息缺失的影响;进一步添加空洞空间金字塔池化,建立了底层坐标特征与高层语义特征的信息关联,弥补了特征信息的断层,从而改善了输出结果与基准关键点的匹配程度,有效提高了整体位姿检测精度。在制作的三维工业零件数据集上,采用改进YOLO6D算法进行实验验证,各项评估指标的平均值均高于88%,能够有效实现工业现场散乱堆叠零件的位姿检测。
