基于超轻量化孪生网络的自然场景奶牛单目标跟踪方法
2023-11-23刘月峰刘好峰
刘月峰 刘 博 暴 祥 刘好峰 王 越
(内蒙古科技大学信息工程学院, 包头 014010)
0 引言
随着经济的发展和社会的进步,消费者对于牛肉的品质、奶牛的奶质有着更高的要求,奶牛养殖场需要向大规模、科学绿色养殖的方向发展[1-2]。自然场景下奶牛身份识别和跟踪系统是奶牛养殖场智能化管理的重要内容[3-6]。对于需要着重关注的奶牛个体,例如刚治愈的奶牛、行为不正常的奶牛等,需要进行单目标跟踪,并且可以为接下来奶牛多目标跟踪奠定基础。单目标跟踪技术是近年来热门的研究工作,主要研究方向为基于相关滤波的方法[7]和基于Siamese FC[8-10]的孪生网络方法。基于Siamese FC的孪生网络方法由模板分支和搜索分支组成,模板由第1帧得到的Anchor获得,推理阶段将模板图像在搜索图像中进行局部搜索,类似于局部单次检测框架。基于孪生网络的方法分为Anchor-base方案和Anchor-free方案。Anchor-base方案大多基于多尺度测试,预设一定数目的Anchor在网络中进行训练,而Anchor-free方案大多通过分类和回归直接对目标进行跟踪,获取其位置和预测框。LI等[11]提出了区域特征提取网络(Siamese region proposal network,Siamese-RPN),它由特征提取的子网络和包括分类回归分支的区域提议子网络构成,在当时公开数据集上取得了领先的跟踪性能指标。LI等[12]随后又将Resnet深层网络作为孪生网络特征提取网络逐层聚合,证明了先前由于深层网络存在padding的原因破坏了跟踪平移不变性的要求导致跟踪失败,并加入深度交叉相关实现模板特征与搜索图之间的特征匹配,进一步提升了跟踪性能。ZHANG等[13]提出了一种Anchor-free的方案预测目标的位置和大小,引入特征对比模块,从预测的边框中学习对象感知特征,进一步帮助跟踪器对目标和背景进行分类。GUO等[14]使用逐像素卷积代替分离通道卷积,并加入Center-ness中心惩罚项进行跟踪,取得了较高的性能评估指标。CHEN等[15]使用Resnet50作为骨干网络,去掉了最后两个卷积块的降采样操作,采用不同的扩张率提高模型的感受野,用分类模块和回归模块组成自适应头部,超过了当时所有跟踪器的跟踪效果。为了解决背景干扰大、分类和回归样本不匹配的问题,FENG等[16]设计了基于排序的优化损失函数,包括分类和回归排名损失函数,进一步加强了跟踪的性能。上述方法采取的特征提取网络大多基于Resnet50网络进行改进,包含较大的参数量,选取一种轻量化模型提取特征是本文研究的重点。
传统正负样本选取策略[14-16]将视频数据前后相邻帧图像随机抽取1幅作为正样本,其他视频段中随机抽取1幅作为负样本输入模型训练,将图像数据经过翻转、平移、亮度变换等数据增强处理后输入训练。go-turn[17]方法根据目标运动轨迹设计出一种运动增广策略,正负样本靠近目标真实框中心分布密集,向四周发散分布。这两种选取策略对于帧速率高、视频流稳定的摄像头效果明显,然而若出现丢帧或目标相邻帧位移较大的情况,这两种策略效果较差,故设计合适的正负样本选取策略直接决定了本文跟踪器性能。
通用跟踪器[15-16]正负样本点划分区域方法各异,主要包括根据真实框(ground-truth)作为划分依据和根据真实框设计椭圆作为划分依据的方法。前者将真实框内部作为正样本点选取区域,外部作为负样本点选取区域,由于大部分物体真实框边界存在大量背景干扰,若将背景作为正样本传入网络则会增大模型学习难度。后者结合通用跟踪对象外形特征,设计两个椭圆作为样本点代选区域,增加无关样本点的选取,巧妙地将物体边缘较难学习位置忽略,提升了跟踪精度。
现有跟踪器方法使用的特征提取网络大多基于浅层网络Alexnet和深层网络Resnet系列网络,Alexnet网络参数少但特征提取能力较差,Resnet网络有较强的特征提取能力却包含大量的冗余参数。Mobileone网络基于MobileNet网络[18]改进,是一种轻量型架构,它的特点是低参数量、高效率完成深度学习任务,合并冗余参数的设计压缩了网络结构,大大提升了推理速度,是一种十分适用于部署移植的网络架构[19-20]。
本文旨在研究一种适合在自然场景下部署的奶牛单目标跟踪器,“自然场景”即饲养奶牛的牛舍场景,其中包含奶牛间遮挡、牛舍栏杆遮挡、昼夜光线变化以及复杂的背景噪声等实际饲养场景。为提升数据样本采集多样性,还加入公开数据集的奶牛数据,并提高正样本质量来增强模型学习能力,最后将跟踪器轻量化压缩。
1 材料和方法
1.1 研究方案
本文首先将获取到的视频转换为图像数据后制作单目标跟踪数据集,并加入部分公开数据集中“牛”、“马”的跟踪数据,进行多数据集联合训练。首先进行正负样本的选取,结合传统方法和go-turn方法,将图像相邻n帧随机抽取2幅图像作为正样本,从其他视频序列随机抽取6幅图像作为负样本;接着进行样本预处理工作,将2幅正样本采用shiftbox-remo的数据增强方式,每幅图像随机增强11次,均匀正样本的分布,增加样本多样性,共组成24对正样本对,6对负样本对,并进行一定概率的遮挡、亮度变换、翻转操作;然后传入改进后的backbone特征提取网络Mobileone-remo,将Mobileone中步长(stride)为2的双、三支结构重参数化为单支结构,处理速度更快、参数量更少;预设2组自适应权重,将1/8、1/16、1/32尺度下的特征层进行融合,一组用于回归分支,一组用于分类分支;再采用分离通道卷积的方式传给分类分支和回归分支;最后模型通过分类损失、回归损失、中心排序损失(Center-rank loss)联合优化网络参数,完成奶牛单目标跟踪器的设计工作,本文具体研究方案流程图如图1所示,跟踪器Siamese-remo网络模型如图2所示。

图2 Siamese-remo网络模型示意图Fig.2 Schematic of Siamese-remo network model
1.2 数据材料获取和数据集构建
1.2.1数据材料获取
本文使用的数据集由两部分构成,一部分为2020年内蒙古自治区包头市某奶牛养殖场采集到的52头奶牛视频。视频共2 596段,每段60 min,视频格式为MPEG4,视频帧高度为1 080像素,宽度为1 920像素,码率为1 639 kb/s,传输速率为60 f/s。另一部分为公开数据集中牛类、马类视频和图像。由于牛和马的体型相似,且为了增添训练样本的多样性,本文扩充一定规模的数据,将搜集到的公开数据集中牛类、马类的单目标跟踪视频、图像加入训练集。
1.2.2数据集构建
本文结合自然场景下奶牛养殖场的视频图像,制作了符合单目标跟踪的数据集。由于奶牛在养殖场中行动缓慢,且处于进食状态的奶牛位置变化较小,故首先将奶牛处于进食状态的视频去除,仅保留奶牛处于移动状态的视频图像;由于奶牛在牛场移动缓慢,故将原视频每10帧抽取1帧图像;然后本文使用Labelme软件进行数据标注,将每段视频中每头奶牛的行动轨迹标注信息放在一个路径下,最终得到63段视频,1 890段奶牛跟踪序列;最后将数据文件进行裁剪和统一图像大小,整理成与GOT10K格式相同的数据形式,即以真实框中心坐标为中点,经过设计好的长宽计算方式裁剪出大小为127像素的图像作为模板图像,大小为511像素的图像作为搜索图像,若裁剪窗口超出图像范围,则用平均RGB值进行填充,如图3所示。
由于从自然场景下获得的上述数据规模较小,难以完成单目标跟踪的要求,故本文选择将DET[21]、COCO[22]、GOT10K[23]、VID[21]、YTB[24]、LASOT[25]公开数据集中标注为“牛”和“马”类的数据加入到训练集,模型根据不同数据集保存图像的方式分别读取到跟踪序列的真实框。
1.3 实验方法
1.3.1正负样本选取策略
本文的正负样本选取策略通过结合Siamban方法[15]和go-turn方法[17]来增加网络泛化性能。孪生网络训练样本分为2个分支:模板分支和搜索分支,从数据集中随机抽取1幅模板图像,首先从其所在视频跟踪序列对应帧前后frame-range帧中随机抽取2幅图像,每幅图像进行12次shiftbox-remo图像增广操作后得到一组正样本队列;然后从其所在不同视频跟踪序列帧中随机取6幅图像,进行shiftbox-remo图像增广操作后作为负样本,即1幅模板图像对应24幅正样本,6幅负样本。
模板帧图像对应的正样本搜索图像区域中,根据图像中真实框划分区域,分为正样本点、负样本点和无关样本点,分别记为1、0、-1,如图4所示,中间小矩形面积包含的样本点为正样本点,大矩形外侧的样本点为负样本点,2个矩形中间部分为无关样本点,设计无关样本点的目的是图像中真实框边缘样本包含较多复杂背景噪声干扰,且理论上边缘信息网络较难学习,故将其设置为无关样本不参与损失计算。经过实验对比论证,奶牛单目标跟踪模型设计2个正方形区域划分正负样本点边界效果最佳,正样本取正样本区域内所有正样本点计算损失,负样本随机取3倍正样本数的负样本点计算损失。

图4 正负样本点选取策略示意图Fig.4 Schematic of positive and negative sample point selection strategy
1.3.2正负样本预处理
根据1.3.1节的描述,数据集包含尺寸为127像素×127像素的原始模板图像和尺寸为 511像素×511像素的原始搜索图像,本文根据原始模板图像,在搜索图中裁剪出相应像素的搜索图。首先以搜索图中真实框为基准,假设真实框宽高分别为w、h,裁剪出的搜索图宽wcrop、高hcrop分别为w+0.5(w+h)、h+0.5(w+h),为了增加泛化性能,对宽高进行小幅度形变处理。
自然场景下奶牛单目标跟踪受遮挡因素影响严重,为了解决这个问题,本文首先对裁剪框位置进行随机选取,模拟出奶牛部分区域未受遮挡时的真实场景,实现跟踪框“局部—整体”的跟踪能力。采用shiftbox-remo的裁剪方式,假设真实框左上角、右下角坐标分别为(x1,y1)、(x2,y2),裁剪框左侧可选择区域即(x1-wcrop,x2),裁剪框上侧可选择区域即(y1-hcrop,y2),若超出图像边界,则将坐标极值设为边界坐标,裁剪框位置范围如图5所示,正方形为原始搜索图,红色框为真实框,虚线框为裁剪框,A、B、C、D为裁剪框移动范围极限位置,本文为了提升正样本质量,选择将裁剪框与真实框之间的交并比Iou>0.3的图像作为搜索图像,最终将裁剪后的图像统一尺寸为160像素×160像素的搜索图。
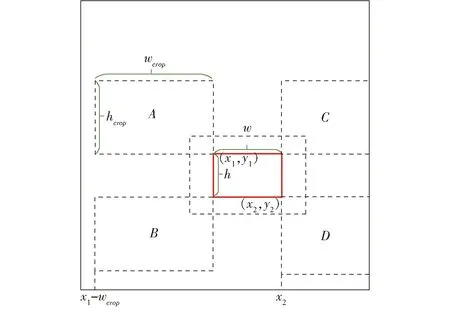
图5 shiftbox-remo裁剪方式示意图Fig.5 Schematic of shiftbox-remo cropping method
为了进一步解决遮挡问题对跟踪模型的影响,设计了适用于上述裁剪方式的正样本区域选取方式,如图6所示,图6a为裁剪框位置和原正负样本点选取区域示意图,回归分支正负样本点选取区域如黄色矩形所示,图6b为分类分支正负样本点选取区域随真实框更新示意图,红色区域为裁剪框位置。根据1.2.2节正负样本点选取策略,两个黄色矩形中间部分样本点将作为无关样本忽略,然而经过裁剪、resize操作后仅存在无关样本和负样本传入网络,无法学习到遮挡情况下局部正样本信息,这与本文实现“部分—整体”的跟踪目标相悖,故将分类分支中物体真实框坐标随着图像裁剪操作而更新位置,这样可以提升正样本多样性并提升其质量;回归分支仍保留裁剪操作之前的坐标,这样可以使网络具有预测“部分—整体”的能力,而并非仅可以预测局部位置。

图6 正负样本点划分区域示意图Fig.6 Schematics of dividing positive and negative sample points into regions
考虑到自然场景下昼夜变换亮度不同,且数据集光线较暗,本文对图像亮度进行数据增广,提升模型在夜间的跟踪能力,本文对模板图像和搜索图像进行了一定程度的翻转、旋转、随机擦除等数据增强方式,提升了模型泛化能力。
1.3.3特征提取网络——Mobileone-remo
Mobileone网络是一个轻量化的深层网络模型,相较于Resnet系列网络等深层网络模型,具有简单、高效、即插即用的特点。如图7所示,为了进一步压缩网络模型结构,并尽可能减小深层网络中padding对于平移不变性的影响,类比于Siamese RPN++模型对Resnet50网络的处理[12],本文将Mobileone中stride为2的3×3卷积padding设置为0,由于scale分支、3×3卷积分支、skip分支尺度不同无法相加,故将3个分支进行重参数化操作。对于仅有scale分支和skip分支的结构块,实验发现将其重参数化后并不会影响跟踪性能,反而可以进一步压缩模型,减少运算成本,故对Mobileone-remo同样进行重参数化操作。

图7 基线模型Mobileone与本文模型Mobileone-remo的结构图Fig.7 Baseline model Mobileone and model Mobileone-remo
1.3.4多尺度预测
深层网络不同层可以提取到图像不同尺度的信息,较浅层可以获得图像高分辨率信息,例如颜色、位置,而较深层可以提取到图像丰富的语义信息,跟踪任务需要计算出跟踪位置和跟踪对象,故采取多尺度特征自适应融合方式训练网络。首先预设两组训练权重Wi和W′i(i=0,1,2),分别与1/8、1/16、1/32尺度特征相乘,一组用于分类分支训练,一组用于回归分支训练,由深层网络不同层提取图像信息特点可知分类分支深层网络权重占比较大,回归分支浅层网络权重占比较大。
1.3.5多功能特征头
Siamese-remo将模板图像和搜索图像融合后的特征进行分离通道卷积,包含两个功能头进行跟踪,一个用于分类,一个用于回归。考虑到模板帧在图像预处理阶段会将一定范围背景裁剪保留,本文经过仿真统计出中心9×9区域数据仍可以捕捉到完整的跟踪模板信息,故卷积前会对模板帧特征进行中心裁剪[12,15],以真实框中点为中心裁剪大小为9×9的区域,然后输入分离通道卷积网络,如图8所示。在分类分支中,本文将图像信息分为前景和背景,故输出通道数为2;在回归分支中,回归信息为训练样本点与真实框4条边的距离,分别记为L、R、T、B,故输出通道数为4。
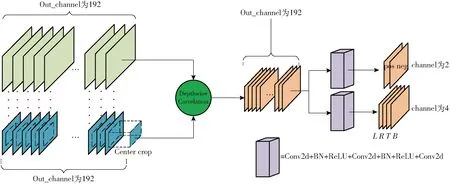
图8 分离通道卷积和多功能头示意图Fig.8 Depth-with cross correlation and multifunctional head
1.3.6损失函数
本文在分类分支使用cross entropy loss计算;在回归分支使用IOU loss计算;两种损失函数权重组合自适应调优,联合优化训练网络。Loss计算公式为
Loss=αLoss1+βLoss2
(1)
其中
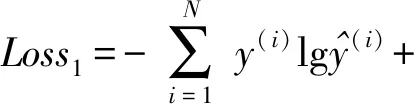
(2)
(3)
式中α、β——网络自适应学习权重,初始值取1
Loss1——cross entropy loss
Loss2——IOU loss
N——标签样本总数
y(i)——样本为正样本的标签
1-y(i)——样本为负样本的标签
A——预测框B——真实框
本文创新性地设计了一种基于真实框中心点位置距离的排序损失——Center-rank loss。考虑到本文研究对象为奶牛,目标一定会占据真实框中心点附近大面积区域,故根据坐标位置对目标的分类、回归得分进行排序,靠近目标中心的样本点置信度高于较远位置的样本点置信度;同理,越靠近目标中心的样本点IOU高于较远位置的样本点IOU。由于正样本点数量过多导致排序训练时间过长,且这种强制排名可能带来某些样本点排序的不合理性,本文选择距中心位置一定区域范围内,随机选n个样本点进行排序,可以在一定程度上提高模型预测能力。假设正样本i,j∈Apos,Center-rank loss的计算公式为
(4)
式中di——正样本i与真实框中心点的距离
dj——正样本j与真实框中心点的距离
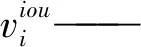
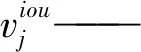
pi——正样本i的前景置信度
pj——正样本j的前景置信度
γ——超参数控制损失值
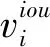
总损失函数为
Lossall=Loss+Losscenter-rank
(5)
最终本文Center-rank loss正样本点选取范围为原正样本选取区域的1/4,选取点数为15。
2 实验与结果分析
2.1 实验系统环境和参数设置
本实验操作系统为Ubuntu 18.04,CPU 为 AMD EPYC 7543 32-Core Processor,主频3 400 MHz,GPU为NVIDIA GeForce GTX 3090×4,运行内存为24 GB。奶牛身份跟踪模型训练共20个训练周期,对于维度为(N,C,H,W)的特征向量采用dropout方法防止过拟合,概率参数设为0.3对通道维度C进行冻结操作,并对H×W维度也按照类似dropout方式进行参数为0.05概率的冻结,以模拟出某些非全局特性,使模型学习到一定程度的局部特征。初始学习率为0.001,经5个训练周期的学习率预热达到0.005,backbone权重衰减系数为0.001,全局权重衰减系数为0.000 5,batch_size设置为4,num_workers设置为16,预训练模型使用ImageNet训练网络模型。
2.2 评估指标
现有的用于单目标跟踪评价的指标有准确率(Accuracy)、鲁棒性(Robustness)、期望平均重合度(EAO)、查准率(Precision)、成功率(Success plot)等。鲁棒性是体现跟踪器稳定性的指标,数值越大稳定性越差,定义为每个视频序列上跟踪失败的视频帧占总帧数的比例,平均鲁棒性即所有视频序列平均跟踪失败比例。
EAO结合跟踪器平均重合度和鲁棒性,是一个更全面的单目标跟踪性能评价指标,EAO数值越大跟踪性能越好。查准率为预测框中心点位置与真实框中心点欧氏距离小于一定阈值的视频帧百分比,以像素为单位,根据不同的阈值得到不同的百分比,该评估指标可以反映目标位置的准确性,但是无法反映目标大小与尺度变化。成功率含义为重合率得分,即IOU超过设定阈值即为跟踪成功的帧。
2.3 单目标跟踪实验
本文提出的单目标跟踪模型在奶牛测试集中准确率达到59.4%,鲁棒性达到0.172,EAO达到0.475,查准率为63.1%,成功率为52.1%,模型参数量达到2.7×106,在大幅缩小模型规模的前提下保持了较高的精度。本文还对模型在其他场景下的跟踪结果进行实验,验证模型的泛化能力,由于公开数据集中奶牛单目标跟踪数据遮挡情况较少且光线较亮,跟踪效果更优,结果准确率达到62.1%,鲁棒性达到0.162,EAO达到0.512,查准率为67.4%,成功率为54.4%。跟踪结果如图9所示,其中包含本文数据集场景和其他场景的可视化跟踪效果。为了更好地对比本文模型的优势,本文对比现在较为流行的一些单目标跟踪器训练本数据集的结果,采用相同的参数调优策略,尽可能达到该研究方法的最优结果,EAO值如表1所示,各跟踪器在本文测试集的查准率和成功率指标如图10所示。

表1 不同跟踪器跟踪性能EAO结果比较Tab.1 Comparison of tracking performance EAO results of different trackers

图9 奶牛跟踪模型结果可视化效果图Fig.9 Visualizations of dairy cow tracking model results
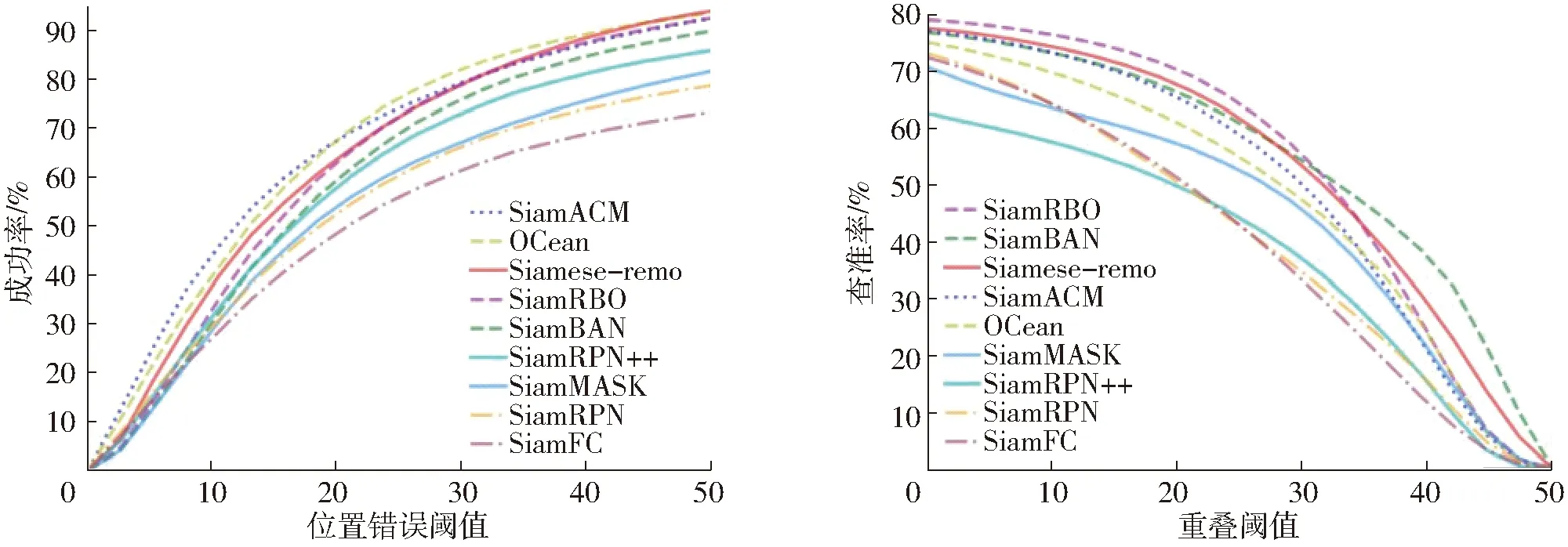
图10 不同跟踪器的成功率和查准率结果对比Fig.10 Comparison of success plot and precision plot results of different trackers
从图9可以看出,本文模型对于解决目标受复杂背景因素影响、遮挡因素影响等问题具有较好的处理能力。从表1可以看出,仅有SiamFC和SiamRPN模型采用浅层网络Alexnet作为特征提取网络,而其余模型所采用特征提取网络皆为Resnet50框架。本文选用改进的Mobileone超轻量化模型提取特征,在参数量较大缩减的情况下,通过上文的改进策略,Siamese-remo超出了大部分Resnet50模型的EAO,较性能最高的模型相比EAO仅落后2.1%,参数量却大大缩减。在对成功率和查准率的结果比较中(图10),本文模型较最优模型低1.1个百分点和5.2个百分点,进一步证明了本文模型的有效性。
2.4 消融实验
2.4.1正负样本选取及预处理策略实验
基线模型采用随机抽帧的方式从相邻帧抽取正样本,对图像不进行预处理;go-turn方法采用运动裁剪方式,模拟物体运动轨迹,对搜索图像随机裁剪,重复11次,构成12对正样本对;本文结合基线模型和go-turn模型样本选取方法,抽取2幅正样本,随机进行11次shiftbox-remo裁剪方式,构成24对正样本对。本文还对模板图像裁剪大小、形状进行对比,假设真实框宽高分别为w、h,裁剪中心为真实框中点,超出位置根据RGB均匀填充。裁剪方式共分为4种:①将h、w放大两倍,然后统一到160像素×160像素。②将h、w分别放大至h+0.5(h+w)、w+0.5(h+w),并比较h+0.5(h+w)与w+0.5(h+w)像素,选择数值大的值裁剪正方形区域,并统一至160像素×160像素。③在原图直接裁剪160像素×160像素大小区域。④本文方法将h、w分别放大至h+0.5(h+w)、w+0.5(h+w),然后统一到160像素×160像素。实验结果如表2所示。
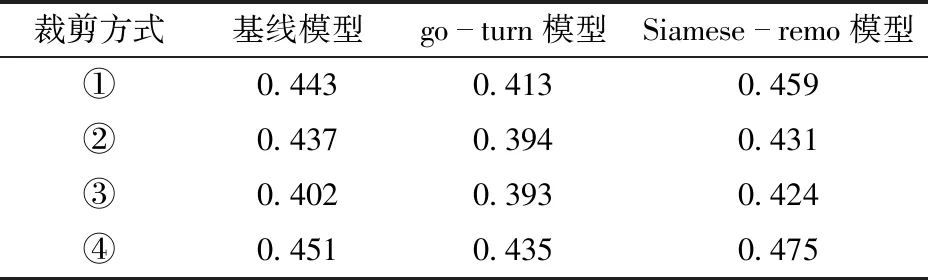
表2 不同正负样本选取及预处理策略的EAO比较Tab.2 EAO comparison of experimental results for different positive and negative sample selection and preprocessing strategies
由表2可得,对于宽高比例较大的奶牛目标,裁剪方式①会进行较大的形变处理,影响实验结果;裁剪方式②、③对目标没有形变处理,导致泛化性能较差,而本文方法对奶牛目标进行基于宽、高的形变,形变尺度比例适中,取得了最优效果。本文模拟了10 000幅图像通过3种裁剪方式的真实框中心点位置,如图11所示,可以看出基线模型没有对裁剪位置平移,故中心点位置全部落到中央;使用运动增广方式对裁剪框位置进行处理,模拟物体运动方向,但数据预处理后样本分布范围较小,泛化能力较差;使用本文的裁剪方式物体可以均匀分布在图像各区域位置,由于需要保证裁剪框与真实框之间IOU大于0.3,故中心点落在图像角落区域的概率逐渐降低,实验结果证明使用本文裁剪方法跟踪效果最佳。

图11 经图像裁剪后真实框中心点位置仿真结果示意图Fig.11 Schematics of simulation results of ground truth center point position after image cropping
2.4.2正负样本点划分方式及选取策略实验
实验对比采用图12a的正负样本划分方式,对比不同负样本点数目对跟踪结果的影响,包括随机取24个正样本点,随机取72个负样本点;取全部正样本点,取全部负样本点;取全部正样本点,随机取正样本点3倍数目负样本点;随机取24个正样本点,取全部负样本点。还对比3种正负样本点划分方式的有效性,分别为椭圆、圆、矩形,并且对于是否添加无关样本进行研究,对比实验如图13所示。 图13 中,p为正样本,n为负样本,i为无关样本,r为矩形,c为圆形,e为椭圆形,all p为全部正样本,all n为全部负样本,3num(p)n为3倍正样本数目的负样本数。

图13 正负样本点选取区域划分方式及样本点选取数目实验结果Fig.13 Experimental results on division of positive and negative sample point selection regions and number of sample points selected
实验证明,由于本文跟踪器为特定类别实例跟踪,对于奶牛个体,外观更接近于矩形,椭圆和圆形会将奶牛边缘位置部分特征点定义为负样本点进行学习,影响跟踪器的准确性。在是否加入无关样本的实验中,加入无关样本的跟踪器EAO比不加无关样本的跟踪器EAO高1.3%,因为无关样本的存在将物体边缘难以学习到的样本忽略,这样可以提升正样本数据的质量,并且可以减少由于边缘背景噪声带来的影响。根据图13可知,正样本点全部选取,随机选取正样本数量3倍的负样本效果最佳,并且结合测试结果可知正样本数量越多对于跟踪器的学习效果越好。由于自然场景下背景复杂,负样本如果全部选取会在一定程度对边缘位置正样本有抑制作用,小概率情况下将导致跟踪过程预测框略小。
2.4.3特征提取网络及多尺度预测实验
本文对不同模型特征提取网络backbone进行比较,包括Alexnet、Resnet18、Resnet34、Resnet50、MobilenetV1、MobilenetV2、Mobileone、Mobileone-remo,利用本文制作的数据集分别训练上述模型,实验结果如表3所示。

表3 不同模型跟踪性能Tab.3 Results of tracking performance indicators for different models
从表3可以发现,由于浅层网络无法获得深层网络的语义信息,相较深层网络回归准确率较差;而深层网络中Resnet系列网络精度明显高于轻量化网络模型,但网络模型包括大量参数,参数量为轻量化网络模型的10~30倍;相较于其他深层轻量化网络模型,Mobileone-remo具有跟踪准确率更高,参数量更少的优点,在Mobileone的基础上缩小一半的参数量,由于对步长为2的Padding置零,可以尽可能减小对跟踪模型平移不变性的破坏,故跟踪性能有所提升。
为了探究多尺度特征对跟踪模型的影响,以及采用两套初始化权重分别对分类回归进行训练的作用,设计相关消融实验,实验结果如表4所示。

表4 消融实验结果Tab.4 Ablation experiment resultts
实验结果表明,经过对多尺度特征进行融合,效果明显优于仅使用单一尺度特征跟踪,浅层网络提取到高分辨率特征和深层网络提取到的语义信息共同对跟踪网络起作用,故采用3种尺度特征自适应融合效果最佳。现有孪生网络跟踪器对于分类分支和回归分支采用相同的权重参数进行训练,并不能很好地利用多尺度特征完成不同任务的优势,本文采用不同初始化参数单独训练分类和回归,网络自适应训练后打印权重信息发现,在回归任务上深层网络权重占比较高,在分类任务上浅层网络权重占比较高,实验结果证明该方法对跟踪性能有一定程度的提升。
2.4.4不同损失函数实验
本文比较了不同损失函数训练对跟踪性能的影响,仅对算法损失函数部分进行改动,实验数据、模型以及训练方法不变。SiamBAN模型[15]使用二元交叉熵损失函数用于分类,使用IOU损失用于回归,按两者所占比重1∶1进行权重计算,记为type 1,实验结果如图14所示;本文采用了基于样本点与真实框中心点距离进行分类回归排序,记为type 2;Siamese-CAR模型[14]在分类分支中加入center-ness并用于分类损失,记为type 3;回归模型计算真实框坐标(x1,y1,x2,y2)替代L、R、T、B,使用L1损失,记为 type 4;根据Siamese-Mask模型[26]加入二值分割分支损失函数,记为 type 5;根据Siamese-RBO模型[16]在分类分支加入了基于IOU和置信度的动态排名损失,记为type 6。
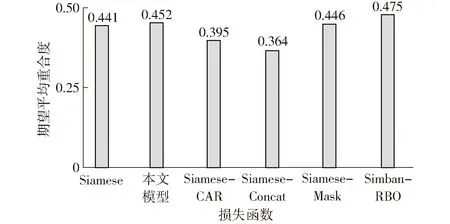
图14 6种不同损失函数跟踪结果Fig.14 Tracking results of six different loss function
通过图14可以看出,本文提出的基于中心位置的排序损失评估结果仅次于基于IOU和置信度动态排序的损失评估指标。结合图15可视化分类效果,分析可得加入Rank-remo loss后,由于分类得分排序受距离影响,分类响应在目标中心至边缘区间有一定梯度的缓慢下降;而原始损失函数由于没有距离的影响,分类响应仅在目标边缘突然下降,与距离无关。本文选取分类得分最高值点进行回归训练,选取到的最高值点距离目标中心越近,则越有利于目标回归学习,而原始方式选取到分类得分最高值点位置区域更大,当选取到样本点接近目标边缘位置时会影响回归效果,故说明在解决跟踪问题的过程中,基于样本点与真实框中心点距离对其分类和回归结果进行重新排序是有效果的。基于IOU和置信度动态排序的方法,需要根据样本点置信度排名调整IOU排名,根据样本点IOU排名调整置信度排名,这种动态算法无疑需要更大的计算量,严重影响了训练时间,这与本文设计网络算法的初衷相违背,故设计统一排序标准——按与真实框中心点的距离进行排序,有效地降低了算法复杂度,减少了一半的训练时间,且跟踪性能也取得了较好的结果。

图15 Rank-remo loss与原始损失函数分类计算结果可视化示意图Fig.15 Visualization diagram of Rank-remo loss and original loss function classification calculation results
2.4.5数据增强实验
本文数据为自然场景下的奶牛图像,存在大量遮挡、光线变换等场景,为了扩充样本多样性,本文进行了尺度变换(SCALE)、灰度变换(GRAY)、模糊处理(BLUR)、翻转(FLIP)、随机擦除(ERASE)等数据增强工作,有效提升了模型性能,实验结果如表5所示,经实验对比各数据增强操作得出最优超参数,并设置数据增强概率SCALE为0.5, GRAY为0.4, BLUR为0.2, FLIP为0.5, ERASE为0.5。
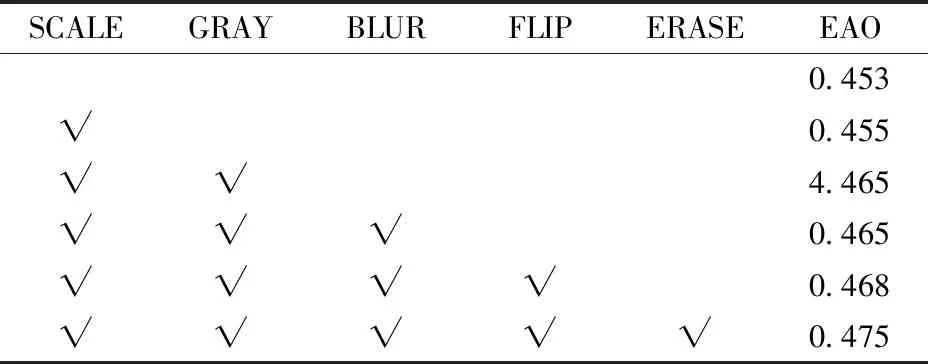
表5 数据增强结果Tab.5 Results of data enhancement
从表5可以看出,经过采用5种常见的数据增强工作,实验EAO提升0.022,加入灰度和随机擦除方式的效果最为明显,这是由于本文实验数据集背景为牛舍,夜间光线较暗,加入灰度增广来丰富数据多样性,对于解决夜间跟踪“误跟”、“漏跟”问题效果明显。而牛舍中存在大量遮挡场景,加入随机擦除的方式也有利于模型的性能提升。
2.4.6其它实验
本文对推理阶段模板帧是否更新进行比较,在模板帧更新模型中,将前一帧作为后一帧跟踪模型的模板图像进行处理[27]。实验发现,模板帧更新会导致跟踪失败,实验结果较差,模型跟踪失败后也缺乏纠错能力,当预测框位置准确率较低时,会影响模板帧更新后质量,导致跟踪失败。还比较了不同预训练模型对实验的影响,分别包括使用ImageNet[28]预训练模型、通用多类别跟踪数据集预训练模型、奶牛目标检测数据预训练模型等,比较发现使用ImageNet预训练模型效果较好。
3 结束语
提出了一种自然场景下奶牛单目标跟踪模型,基于传统孪生网络算法,设计了一种新型的正负样本选取策略,提升了模型样本的多样性,并进行shiftbox-remo数据增强处理,提升正样本采集质量。然后使用改进后的Mobileone-remo网络提取特征,融合1/8、1/16、1/32尺度特征,并分别输入分类分支和回归分支,采用超轻量化模型提取到高质量特征。最后加入了中心点排序损失函数进行训练,根据样本点与真实框中心点距离优化模型参数。实验证明,本文提出的跟踪器在奶牛测试数据集的EAO评估指标达到0.475,模型参数量缩小至1/20,节省了计算资源,提高了计算效率,验证了本文方法的有效性,为奶牛身份识别与目标跟踪系统的研究提供了技术支持。
