基于实例分割的番茄串视觉定位与采摘姿态估算方法
2023-11-23庞月生
张 勤 庞月生 李 彬
(1.华南理工大学机械与汽车工程学院, 广州 510641;2.华南理工大学自动化科学与工程学院, 广州 510641)
0 引言
机器人采摘可降低种植成本、提高生产率、减轻工人劳动强度、保证果实质量,且适时采摘是未来的发展方向[1-5]。由于番茄串采摘环境复杂、品种多样且个体差异较大,开发通用、稳定、精确的番茄串视觉定位方法,引导机械臂以合适姿态完成采摘,是实现智能采摘的重要环节,也是实现无损、安全、高效、连续采摘的重要保证。
动态变化的非结构化作业环境、果梗纤细且姿态多样、传感器精度不足等因素,增加了采摘点定位和果梗姿态预测的难度,所以现有的智能采摘设备在采摘效率、识别准确率和稳定性等方面远低于人工采摘,无法满足商业化应用需求。
近年来,数字图像处理和神经网络广泛应用于采摘点的识别与定位中,加速了采摘机器人的产业化进程[6-10]。现有的果梗采摘点定位方法主要分为两类,第1类基于图像处理技术,根据果实颜色、形状或纹理等基本特征定位采摘点。JI等[11]基于颜色特征2R-G-B识别番茄果实与辅助标记,将拟合的果梗曲线与辅助标记边缘的交点作为采摘点,采摘成功率为88.6%。LUO等[12-13]基于颜色特征分割葡萄串,根据果梗与果实的约束关系定位采摘点,准确率88.33%,平均耗时0.346 7 s。冯青春等[14]基于黄瓜的形状特征和HIS空间阈值提取黄瓜轮廓,并从黄瓜轮廓顶部提取采摘点,定位精度达到2 mm。梁喜凤等[15]基于果梗骨骼线角点定位番茄串采摘点位置信息,成功率为90%。熊俊涛等[16]基于HIS空间对荔枝果实和果梗进行分割,利用Hough直线拟合确定有效的果梗采摘区域,通过连续处理多帧图像定位采摘点,深度误差小于6 cm。YOSHIDA等[17]利用颜色和点云特征识别番茄串采摘点,单帧图像耗时1 s,难以满足实时采摘要求。多特征融合比单特征识别方法鲁棒性更强,但两者都容易受光照变化和障碍物遮挡的影响,对环境依赖性强、通用性差且检测性能不稳定。此类方法多数要求果实与果梗的颜色、形态单一,相对位置固定。
第2类基于神经网络识别果实或果梗,基于颜色或形状等特征对识别结果进一步处理定位采摘点,神经网络的应用极大地提升了采摘点识别定位的速度和精度。陈燕等[18]基于改进YOLO v3与双目立体视觉对荔枝串预定位,处理速度为22 f/s,最大定位绝对误差为36 mm。YU等[19]提出了R-YOLO用于识别并估计草莓生长姿态,根据边界框轴线旋转角度计算采摘点,平均识别率为94.43%,采摘成功率为84.35%。XU等[20]基于改进的Mask R-CNN识别距离相机最近的番茄串作为采摘目标,准确率为93.76%,单帧图像处理时间为0.04 s。宁政通等[21]基于改进Mask R-CNN与颜色特征分割葡萄果梗并定位采摘点,单帧图像耗时4.9 s。KALAMPOKAS等[22]基于回归卷积神经网络识别葡萄串果梗,结合识别结果的形状和边缘特征定位采摘点,深度定位误差10 mm,算法速率为8.3 f/s。张勤等[23]基于YOLO v4与果梗颜色特征,融合深度信息分割果梗,番茄串采摘点定位成功率为 93.83%,单帧图像耗时54 ms。番茄串果梗纤细且颜色与枝叶相似,背景噪声复杂,受光照变化影响大,难以精确分割;番茄串形态差异大,果实与果梗之间无固定位置关系,作业环境复杂,增加了预测果梗姿态的难度;采摘过程中植株晃动,经济型深度相机精度不足和深度缺失,难以精确识别定位采摘点;由于果梗姿态多变,即使成功定位采摘点,也会由于剪刀的剪切姿态和干涉等问题造成采摘失败。现有的研究主要侧重于采摘点的精确定位,忽略了果实的可采摘性和生长姿态多样化的问题,造成“看到采不到”的现象,影响了采摘成功率和效率,限制了番茄串采摘机器人在实际中的广泛应用。
针对上述问题,本文提出基于实例分割的串番茄视觉定位与采摘姿态估算方法。基于YOLACT实例分割算法[24]的实例特征标准化和掩膜评分机制,输出番茄串的掩膜和ROI,保证果梗掩膜的连续性,过滤大量背景噪声实现果梗粗分割,基于果梗掩膜信息和ROI位置关系匹配可采摘果梗;其次,通过细化算法和膨胀操作对可采摘果梗进行精细分割,提取果梗骨骼线、定位采摘点图像坐标,降低光照和背景噪声对分割果梗的影响;基于果梗深度信息填补法与坐标系转换,融合深度信息定位采摘点空间坐标;通过果梗几何特征,识别果梗关键点预测果梗姿态,估算采摘姿态,引导机械臂以合适的姿态完成采摘。
1 数据集构建与标注
为解决非结构化种植环境下,番茄串采摘点识别定位、果梗姿态预测的问题,提出基于实例分割的串番茄视觉定位与采摘姿态估算方法,方法流程如图1所示。

图1 基于实例分割的番茄串视觉定位与采摘姿态估算方法Fig.1 Method for visual positioning and picking pose estimation of tomato clusters based on instance segmentation
数据采集地点为广东省某农业技术推广中心数字设施馆水培区,数据集包含4个品种的番茄串图像,分别为以色列红、金玲珑、粤科达202和鸿海HH10,每个品种的图像分别为1 307、2 942、1 065、1 206幅;上述图像使用不同设备、在不同时间段、从不同角度和不同光照条件下进行拍摄,相机与番茄串之间的距离为0.4~1.2 m,图像尺寸均为 1 280像素×720像素;每个品种按20∶3进行划分,然后汇总为训练集和测试集。测试集中的果梗数量为949,可采摘果梗数量为797,用于测试模型的识别准确率。
使用开源标注工具LabelMe[25]对数据集进行标注,共有2个标注类别,其中“stem”为果梗,“tomato”为成熟番茄串,其余部分均视为“背景”。图2为以色列红番茄串标注示例,分别使用多边形和矩形标注果梗和成熟番茄串,有效减少数据标注时间。为了提高模型的鲁棒性和防止训练过程中模型过拟合,标注完成后对训练集进行数据集增强,主要操作包括镜像、旋转、模糊、调节亮度和对比度等,增强后训练集图像总数为15 311幅。对4个品种的番茄串图像数据进行训练,能够有效增强番茄串和果梗识别定位的鲁棒性,满足该模型对不同番茄品种的适应性。

图2 数据标注示例Fig.2 Example of data annotation
2 番茄串视觉定位与采摘姿态估算
2.1 基于实例分割的番茄串视觉定位方法
2.1.1基于YOLACT的 ROI识别与果梗粗分割
YOLACT实例分割算法属于单阶段模型,在保持高质量分割的同时有效地减少计算成本,具有速度快、精度高的优点,能够快速识别番茄串与果梗ROI,有利于在复杂背景中分割果梗轮廓。采用残差网络(Residual network 101, ResNet101)和特征金字塔网络(Feature pyramid network, FPN)作为特征提取网络训练番茄串和果梗的检测模型,ResNet基于残差模块(Residual blocks)允许信息在不同深度之间流动,使得网络能够更好地提取图像特征,有助于提高模型的分割精度,具有更快的模型训练速度。
如图3所示,将图像调整为550像素×550像素后输入特征提取网络,提取番茄串和果梗的重要特征;预测模块对特征提取网络输出的重要特征进行整合与利用,由预测头分支输出各类候选框的类别置信度及位置信息、原型掩膜的掩膜系数;原型网络分支输出原型掩膜;原型掩膜和相应的掩膜系数进行组合得到番茄串和果梗的掩膜;后处理模块通过非极大值抑制、掩膜过滤、裁剪和二值化处理得到最终的掩膜结果与ROI。
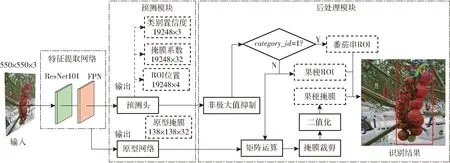
图3 基于实例分割的番茄串视觉定位方法Fig.3 Method for visual positioning of tomato clusters based on instance segmentation
由于番茄串果梗纤细且种植环境复杂,为了能够提取完整的果梗轮廓,在后处理模块通过降低掩膜精度对果梗进行粗分割,使果梗掩膜覆盖果梗轮廓,保证果梗的连续性;后续通过细化算法与形态学操作精确提取果梗轮廓,保证采摘点的识别定位精度和果梗姿态预测的可靠性。将识别结果存储于容器vector〈ROI〉Result,ROI包含下列参数:x、y、w、h、confidence、category_id;其中(x,y)为ROI左上角顶点坐标,w和h分别为ROI的宽和高;confidence为预测框置信度;category_id为0时表示果梗ROI,为1时表示番茄串ROI,果梗ROI与果梗掩膜一一对应。
2.1.2基于ROI位置和掩膜信息匹配可采摘果梗
由于识别结果中番茄串和果梗ROI数量不同,且位置具有随机性,需要进行匹配确定可采摘果梗,后续只处理可采摘果梗从而提高算法效率。主要依据为:①判断果梗掩膜是否连续,剔除部分可见区域较小、不利于提取果梗轮廓的番茄串。②果梗与果实的ROI位置关系。对识别结果进行分析,假设果梗和番茄串ROI的左上角顶点坐标分别为(xi,yi)、(xj,yj),Result[i]和Result[j]分别表示当前处理的果梗ROI和番茄串ROI(后文不再重述),具体步骤为:
(1)基于轮廓检测判断果梗掩模是否连续,若果梗掩膜不连续则剔除Result[i]。
(2)将Result内剩余的ROI按x坐标值由小到大进行排序。
(3)判断ROI是否有交集:if(Result[i]∩Result[j]≠0 &&yi 在步骤(3)中使果梗ROI下边框向下偏移0.15hi,番茄串ROI上边框向上偏移0.15hj,增强该方法对不同果梗长度的适应性。 2.2.1基于细化算法和膨胀操作的果梗精细分割 由于原始果梗掩膜存在番茄果实、植株主干或叶子等背景噪声,为了精确提取果梗轮廓,提高采摘点识别定位精度与稳定性,去除背景噪声的步骤为: (1)基于ZHANG等[26]快速并行细化算法提取原始果梗骨骼线。 (2)基于果梗ROI长宽比确定ROI中心线Lmid的取值 (1) (3)求取原始果梗掩膜图在第Lmid行(或列)像素值非零点的总数,即果梗掩膜宽度L(单位:像素),如图4红色线段所示。 图4 果梗掩膜宽度Fig.4 Mask width of stem (4) 对原始果梗骨骼线进行膨胀操作,获得新的果梗掩膜:膨胀操作内核形状为MORPH_ELLIPS,以果梗掩膜宽度L为参数调整内核尺寸。 (5)对新果梗掩膜进行细化处理提取果梗骨骼线。 2.2.2基于果梗深度信息填补的采摘点定位 首先计算果梗骨骼线图第Lmid行(或列)中第1个像素非零的点(xc,yc),设定(xi+xc,yi+yc) 为采摘点图像坐标(Px,Py),其中xi和yi分别为果梗ROI左上角顶点的坐标值,然后融合配准后的深度图信息精确提取采摘点的深度Pz。由于深度相机获取细小物体的深度信息时误差较大且不稳定,导致某些像素点丢失深度,为保证采摘点图像坐标(Px,Py)深度的可靠性,提出果梗深度信息填补法。设图像坐标点(u,v)的深度为d(u,v)(单位:mm): (1)新果梗掩膜上所有满足0 (2) (2)提取点(Px,Py)的原始深度doriginal。 (3)统计果梗掩膜宽度L上所有像素点的深度d(u,v),记所有满足0 (3) (4)选取最优采摘点深度Pz (4) 步骤(3)中通过计算线段的平均深度L作为采摘点的平均深度,即使采摘点原始深度异常或丢失,可以使用采摘点平均深度daverage_2填补原始深度doriginal,以保证采摘点的定位精度和可靠性。 由于番茄串果梗姿态各异,机械臂以固定姿态采摘时存在采摘效率低、植株或果实损坏等问题。为了避免采摘过程中末端执行器与果实或植株主干发生干涉,导致植株晃动剧烈影响识别定位和采摘,需要在实施采摘任务前对果梗生长姿态进行预测,从而引导机械臂以适合的姿态靠近果梗,提高采摘成功率和效率,保证果实质量。 如图5所示,以果梗骨骼线图上的采摘点(绿色圆点)图像坐标(xc,yc)为中心,分别向骨骼线两端各拓展10个像素值非0点,如图5中虚线框所示。记拓展后所得的上端点和下端点的图像坐标分别为(x1,y1)和(x2,y2),以两端点构成的直线斜率近似代替采摘点处的果梗切线斜率,果梗的倾斜角θ计算式为 图5 果梗骨骼线与采摘点处切线Fig.5 Skeleton of stem and tangent line at picking point (5) 根据果梗的倾斜角θ预测垂直生长的果梗,经过现场试验表明,当果梗倾斜角满足θ∈([4π/9, π/2]∪[-π/2,-4π/9]),可判断果梗为垂直生长,否则按如下方法继续预测果梗姿态:首先基于八邻域端点检测算法快速提取果梗的关键点,即果梗骨骼线的上端点和下端点图像坐标(xu,yu)和(xd,yd),其中yu 图6 番茄串采摘机器人结构Fig.6 Structure of tomato cluster harvesting robot1.移动平台 2.收纳筐 3.末端执行器 4.机械臂 5.深度相机 6.机械臂控制器 γ=atan2(yd1-yu1,xd1-xu1) (γ∈(-π,π]) (6) 通过γ的取值预测果梗相对于植株主干的生长姿态。 2.4.1采摘姿态估算 由于番茄串果梗木质化使其含有大量不易剪断的纤维,若果梗未被剪断,机械臂拖拽果梗会损伤番茄植株;番茄串生长姿态各异,如果末端执行器以固定角度进行剪切,靠近目标时容易与果梗或果实发生干涉,同时干扰了视野中已识别的可采摘目标,导致植株晃动,严重影响番茄串的识别定位和采摘。因此选择适合采摘目标生长特点的剪切姿态是成功采摘的关键。 如图5所示,通过采摘点处的近似切线计算果梗的剪切角β(逆时针为正方向,单位:rad);机械臂初始状态末端执行器剪切平面与地面平行,剪切角β=0,如图5中蓝色虚线所示。由于受果实重力的影响,大部分果梗的生长姿态为斜向下弯曲或垂直的状态,可以通过果梗倾斜角θ判断果梗被果实压弯的方向,剪切角计算式为 (7) 式中θs为变量(单位:rad),用于调节末端执行器的剪切平面(图5蓝色线段)与果梗切线(图5黄色线段)的夹角,满足不同的农艺需求和应用场景。但对于不同品种的番茄串,由于果梗直径、硬度、强度、果实重量不同等因素,有部分果梗为斜向上生长,如按式(7)计算剪切角,此时剪切平面与果梗切线平行,无法成功剪切果梗,或剪切后无法夹持番茄串,导致采摘失败。此时需要引入果梗和番茄串ROI的左上角顶点坐标 (xi,yi)、(xj,yj),以及ROI对应的宽度wi、wj,判断番茄串和果梗ROI的相对位置,剪切角计算式为: 当θ≥0时 (8) 当θ<0时 (9) 为了保证夹剪一体的末端执行器夹持稳定性,充分发挥末端执行器的容错性,选择切割强度最大的剪切姿态,如图5所示,即末端执行器的剪切平面与果梗切线垂直,此时θs=π/2。 2.4.2采摘机器人系统 番茄串采摘机器人主要由工业控制计算机、可升降移动平台、L515型深度相机(Intel RealSense)、Aubo-i5机械臂、末端执行器和收纳筐组成,如图6所示。 2个深度相机对称安装于机械臂坐标系X轴线上,分别用于识别轨道两侧的番茄串;机械臂的工作半径为886.5 mm,末端执行器为夹持和剪切一体设计,最大开口宽度为23 mm,可剪切直径5 mm以内的果梗。机器人通过视觉识别系统实时获取图像,输出采摘点位置和果梗姿态信息,控制各个组成模块的协调运行,机械臂通过果梗姿态自主调节剪切姿态完成采摘;移动平台通过识别磁条与RFID实现自动导航与上下轨道,能够自动切换采摘方向并调节高度,实现对双侧番茄串的智能化采摘。 2.4.3手眼坐标转换 (10) 手眼标定测试中,重复标定误差控制在1 mm以内,为机械臂提供准确的采摘点位置信息。采摘过程中,机械臂根据果梗姿态预测结果γ和果梗倾斜角θ,即根据果梗生长方向,选择合适的姿态接近果梗,避免与植株或果实发生干涉;将采摘任务进行分解并分段规划采摘路径,同时利用剪切角β调整末端执行器的剪切姿态,引导机械臂以合适的姿态完成采摘[28]。 Windows 10(64位)系统下使用Anaconda3创建训练环境,Python版本为3.7.13,配备AMD Ryzen 5 1400处理器、16 GB运行内存、GPU为GeForce GTX 1080Ti,使用构建的数据集训练模型;训练结束后将模型文件转换成深度学习模型开放格式(Open neural network exchange, ONNX),基于C++部署该模型至采摘机器人系统并测试,开发环境为AMD Ryzen 5 1400处理器、8 GB运行内存、GeForce RTX2060 GPU、Qt Creator 4.11.0、VS2017、CUDA 10.2,Opencv-Contrib-4.5.4。 3.2.1模型识别准确率 为了测试模型对番茄串和果梗ROI的识别准确率,以召回率、预测精度作为主要评价指标。为了验证模型的分割精度,以平均交并比(Mean intersection over union, mIOU)作为评价指标。试验过程中以重叠系数[29]评估模型的ROI识别准确率,重叠系数表示预测框与实际目标框之间的重叠比例,计算式为 (11) 式中AT——实际目标框区域 AD——预测框区域 在试验中设定重叠系数大于0.5时,目标被正确识别。对第1节构建的测试集进行识别与统计,识别结果如表1所示,得到该模型对番茄串的预测精度和召回率分别为97.67%和98.89%,对果梗的预测精度和召回率分别为98.83%和98.00%;得到平均交并比为69.04%。图像分辨率为1 280像素×720像素时,算法处理速率达到21 f/s。 表1 模型识别结果Tab.1 Model recognition results 3.2.2采摘点识别成功率 使用同一模型对不同品种、不同姿态的番茄串进行采摘点识别定位,如图7所示。图7中红色箭头表示采摘点搜索方向,绿色圆点表示采摘点,若采摘点落入果梗轮廓内则采摘点识别定位成功。测试集中可采摘果梗实例测试结果如表2所示,以色列红、金玲珑、粤科达202和鸿海HH10番茄串的采摘点识别成功率分别为98.20%、98.94%、97.25%和97.89%,不同品种的番茄串采摘点平均识别成功率为98.07%。试验结果表明,提出方法对不同品种番茄串采摘点的识别定位成功率和速度能够满足采摘需求。 表2 测试集采摘点识别成功率Tab.2 Picking point recognition accuracy of test set 3.2.3采摘点图像坐标定位精度 试验地点位于广东省某农业技术推广中心数字设施馆水培区。为了确定采摘点的定位精度,从粤科达202品种中选取20串可采摘番茄,其中包含不同光照条件和不同姿态的果梗实例。机器人运动至指定位置后,对每串番茄连续拍摄6帧图像(1 280像素×720像素)并识别定位采摘点,同时保存拍摄的彩色图与深度图,使用文献[23]方法进行采摘点定位精度测试。 设最佳采摘点图像坐标为果梗ROI第Lmid行(或列)与果梗中轴线的交点,记为(Ox,Oy)。算法识别的采摘点与最佳采摘点之间的误差Δe计算式为 (12) 其中 ex=|Ox-Px| (13) ey=|Oy-Py| (14) 式中ex——采摘点在行方向上的偏差 ey——采摘点在列方向上的偏差 按照2.2.2节的方法提取采摘点的原始深度doriginal与平均深度daverage_2,当两者均为非零值时,采摘点平均深度与原始深度的误差ε计算式为 ε=doriginal-daverage_2 (15) 分别记录每串番茄的6次采摘点识别定位结果,如图8所示,其中图8a记录了采摘点处平均深度误差的平均值和标准差,可知采摘点处平均深度误差ε为±6 mm,证明当采摘点原始深度异常或丢失时,可以采用平均深度代替原始深度。由于文献[23]方法的番茄串检测模型和数据集差异,有4串番茄未能成功识别,因此图8b仅统计了16组数据。由图8可知,提出方法和文献[23]方法的采摘点图像坐标最大定位误差分别为3像素和10像素,平均定位误差分别为0.84像素和3.62像素,其中输入图像中果梗直径为7~15像素,与文献[23]方法相比,采摘点平均定位精度提高76.80个百分点。此外,提出的方法对同一帧图像连续进行10次采摘点识别定位,每次输出的采摘点坐标(Px,Py,Pz)均为定值,表明该方法的定位精度和稳定性能够满足采摘需求。 图8 采摘点定位误差分布Fig.8 Picking point error 3.2.4番茄串视觉定位与果梗分割性能对比试验 为验证提出方法的有效性,将该方法与文献[23]提出的方法进行对比试验,图9为两种方法对不同形态的番茄串处理结果,蓝色圆点为文献[23]方法识别结果,绿色圆点为提出方法的识别结果。当番茄串背景环境复杂或光照不稳定时,文献[23]方法通过深度分割算法,随机选取聚类中心进行K-means聚类分割果梗,鲁棒性较差,难以精确、稳定地定位采摘点图像坐标和深度。如图10所示,文献[23]方法在相同条件下对试验2中的番茄串重复识别,分割果梗时存在较多背景噪声且聚类结果不稳定,导致采摘点定位误差较大。 图10 文献[23]方法重复识别试验Fig.10 Repeated recognition of reference[23] method 试验结果表明,在相同场景下提出的方法具有更高的准确率和稳定性,能够准确分割果梗并提取果梗骨骼线,有利于精确定位采摘点和预测果梗姿态。 3.2.5采摘方法对比试验与误差分析 以往的采摘方法,基于番茄串和果梗ROI位置关系,将番茄串生长姿态分为向左、向右和垂直生长3个类别,经常出现果梗姿态预测错误的情况,且末端执行器只有3个对应的采摘姿态,容易与果实、果梗或植株主干发生干涉,存在“看到采不到”的现象(方法1)。提出的采摘方法不局限于3种采摘姿态,机械臂通过估算的果梗姿态自主调节剪切姿态,以合适的姿态靠近果梗,避免发生干涉(方法2)。 基于同一个番茄串检测模型,使用方法1和方法2,对不同果梗姿态的番茄串进行采摘试验,试验对象为1垄粤科达202番茄和1垄鸿海HH10番茄。采摘机器人在轨道上运行,通过视觉识别系统实时控制机器人移动,识别到可采摘目标后机器人触发制动指令,重新获取最新一帧图像并识别定位采摘点;机器人根据采摘点与果梗姿态信息调整采摘姿态,规划采摘路径,采摘完成后或连续3次采摘失败,机器人继续向前运动,重复上述步骤实现连续采摘,使用方法2采摘粤科达202番茄串过程如图11所示。 图11 番茄串采摘过程Fig.11 Action sequence of tomato cluster harvesting 两种方法的采摘试验结果如表3所示,方法1的采摘成功率为82.98%,平均采摘效率(成功采摘的番茄串总数量与采摘动作总次数的比值)为55.71%。方法2的采摘成功率为98.15%,平均采摘效率为86.89%;相比于方法1,采摘成功率提高15.17个百分点,平均采摘效率提高31.18个百分点。采摘试验过程中,采摘失败通常会导致番茄植株剧烈晃动,严重影响后续的番茄串识别定位和采摘。图12为方法2采摘失败案例,试验过程中为了限制机械臂的运动范围,对获取的图像进行裁剪。由于该番茄串处于图像的顶部被裁剪区域,因此番茄串在距离相机较远时才进入识别范围,此时部分果梗被番茄植株主干遮挡,且相机成像平面与果梗平面不平行时,相机深度缺失、误差较大,使采摘点定位存在较大偏差,导致采摘失败。 表3 采摘试验结果Tab.3 Results of picking test 图13为不同果梗姿态的剪切角,以末端执行器剪切刀刃中点为参考点,如图13a黄色标记所示,设果梗采摘点与参考点的相对距离为深度误差Δd;试验过程中选择切割强度最大的剪切姿态,即末端执行器的剪切平面与果梗切线垂直,如图13b所示,设末端执行器剪切平面与果梗切线正方向(指向植株主干的方向为正方向)的夹角为α;若剪切平面垂直于果梗切线,即α=90°,此时剪切角误差为0°,剪切角误差评价指标Δα计算式为 图13 不同果梗姿态的剪切角Fig.13 Cutting angles of different stems Δα=α-90° (16) 对方法2中成功采摘的番茄串进行深度误差与剪切角误差分析,误差分布结果如图14、15所示,深度误差Δd为±4 mm,剪切角误差Δα为±6°。误差来源主要包括深度相机测量误差、手眼标定误差、采摘点图像坐标定位误差、移动平台振动、试验场地排气扇和采摘过程使植株产生晃动等。试验结果表明,使用方法2进行采摘试验,即使采摘点识别定位和果梗姿态预测存在一定误差,高容错率的末端执行器依然能够成功采摘番茄串。 图14 采摘点深度误差分布Fig.14 Distribution of picking point depth value error 图15 剪切角误差分布Fig.15 Distribution of shear angle error 考虑番茄串果实生长姿态的多样性和可采摘性,基于实例分割提出番茄串的视觉定位与采摘姿态估算方法。通过果梗的粗分割、精细分割以及深度信息的填补、融合,精确定位采摘点;基于果梗关键点预测果梗姿态,并根据果梗姿态确定适合采摘的末端执行器采摘姿态,有效提高了采摘成功率。研究和试验结果表明,该方法对4个品种的番茄串采摘点平均识别成功率为98.07%,采摘点图像坐标最大定位误差为3像素,深度误差为±4 mm,相对于果梗的剪切角误差为±6°,成功识别后采摘成功率为98.15%,图像分辨率为1 280像素×720像素时算法处理速率达到21 f/s。与现有的同类方法相比,采摘点图像坐标定位精度提高76.80个百分点,采摘成功率提高15.17个百分点,采摘效率提高31.18个百分点。该研究以番茄串采摘为例提出的视觉定位与姿态预测方法,同样适用于其他串收果实的采摘。2.2 采摘点定位方法

2.3 果梗姿态预测方法
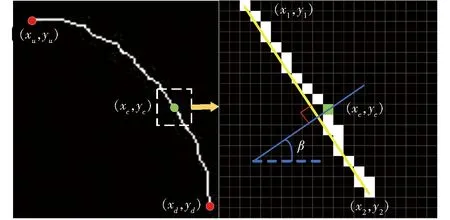

2.4 采摘姿态与采摘方法

3 试验
3.1 模型训练与部署
3.2 番茄串视觉定位方法性能试验

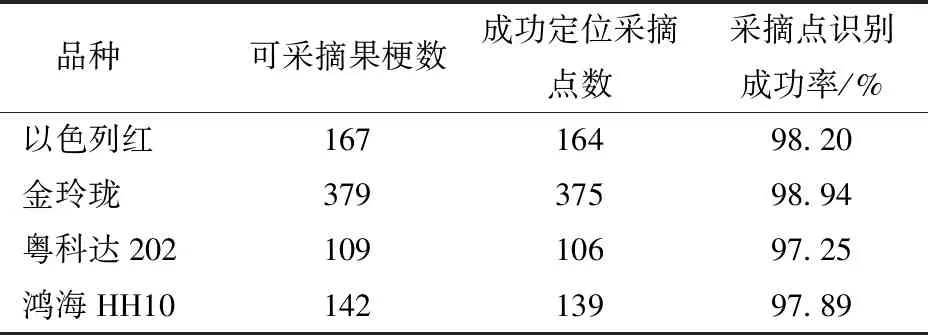







4 结束语
