语义增强型全文本共词网络的构建与分析
2023-11-21赵一鸣尹嘉颖
赵一鸣,尹嘉颖
(1. 武汉大学信息资源研究中心,武汉 430072;2. 武汉大学信息管理学院,武汉 430072;3. 武汉大学大数据研究院,武汉 430072;4. 武汉大学图书情报国家级实验教学示范中心,武汉 430072)
0 引 言
共词分析是图书情报学最常用的方法之一,其研究重心已经从关键词共现分析演变为面向全文本的共词分析。自然语言文本是一种复杂动态系统,呈现高度的复杂网络结构[1],构造一个可靠的词汇网络是自然语言文本理解与分析的重要环节[2]。通过不同的词汇网络,可以解决词义辨析[3]、主题建模与识别[4-5]、作者画像[6]、关键词提取[7]等问题。然而,由于语言的复杂性,单一维度的词汇网络在实际应用中存在较多缺陷,如难以揭示词汇共现的同量不同质现象、基于共词网络的下游任务结果(如词汇聚类得到的类团)缺乏解释性等。同时,虽然利用词汇的共现关系能够促成许多有价值的研究,但是促成词汇共同出现的“介质”是什么,目前仍未有定论[8]。
传统的共词网络研究通常把每一次共现都看作无差异的,仅仅是利用其共现的频次特征开展进一步研究。实际上,词汇共现具有典型的“同量不同质”特征,同样两个词在不同场景下的共现具有多维度的差异性。换句话说,一个共现词对可以拥有除共现频次特征之外的更丰富的内涵,如共现词之间的多重语义关系、共现词在原始文本中的跨距等。这些丰富内涵的揭示对于词汇共现研究、共词网络研究具有重要意义。
本文提出了一种语义增强型的共词网络的构造和分析方法,通过拓展共词网络中共现词汇的语义知识及其本身的共现特征、网络特征来构建共词网络,并结合语义学的相关理论进行分析。通过构建并分析语义增强型全文本共词网络,可以提升词汇聚类结果的可解释性,还可以通过词汇的结伴、结群关系反映词汇在语言系统中的作用等。
1 相关工作
为了探究语言构建过程中的词汇组织,Ferrer i Cancho 等[9]基于英语国家语料库(British National Corpus,BNC)构建了全文本词汇共现网络,并发现了共词网络的小世界效应和无标度特性。之后,共词网络的小世界效应和无标度特性也在新闻[10]、军事[11]、文献关键词[12]等语料库或数据集构建的共词网络中得到了验证。
已有的全文本共词网络的构造模型主要有n阶Markov 同现模型[2]、词相似模型[13]、词共现矩阵[14-15]等。其核心思想是以词作为网络的节点,通过测量两个词之间的共现来构造节点的边。
一些学者开始突破单纯的共现关系,引入共现强度、TF-IDF(term frequency-inverse document frequency)值、语义相关度等因素来改进共词网络的权重[16]。此外,有学者在共词网络上引入了方向、时间等各种维度,从而构建有向、加权、时序等共词网络[17]。随着复杂网络理论的发展,共词网络被广泛应用于信息检索、文本分析、话题与热点发现等领域。
语义网络及知识图谱的发展为词汇共现研究提供了新的契机。通过词典或语料库等语言资源构造的语义网络,可以反映人类储存知识的方式和结构[2]。在语义网络中,节点一般是概念或实词,节点之间的边表示节点的语义关系,如等同关系、等级关系以及相关关系等。现有的主流语义知识库包括Cyc、WordNet、ConceptNet、Freebase、DBpedia、Wikidata、BabelNet、YAGO、NELL (Never-Ending Language Learner)、Zhishi.me 等。这些知识库为各种自然语言相关研究提供了广泛的语义知识资源,如概念间的语义关系、概念的语义表示、知识推理等。Yang 等[18]为解决基于单词的主题检测模型准确率较低的问题,在词汇共现的基础上提出了胶囊语义图来进行新闻主题检测。
结合语义网络中的语义知识能够很好地从认知角度描述共现词汇之间的关系。Shi 等[19]使用预训练语言模型得到的词向量结合文档中的词义共现,提出了一种新的文本表示方法,从而能够灵活地进行跨平台和跨内容的新闻推荐。赵一鸣等[20]提出了一种融合概念知识图谱的中文文本语义图的构建方法,解决了传统文本表示方法中语义缺失的问题。冯佳等[21]基于语义知识构建了词汇间的语义距离,改进了共词矩阵分析方法。王忠义等[22]为解决共现词对间同量不同质的问题,通过关联数据对共现词的统计单元进行碎片化处理,利用LDA (latent Dirichlet allocation)主题模型将词汇的语义信息融入共词分析中,使基于词汇共现聚类出的类团更具有实际意义。
然而,现有的将语义网络应用于共词网络方法改进的研究主要是对共词网络连边权重的数值改进,对语义知识库的利用程度较浅,对共词网络构架方法的改进程度比较小。因此,本文结合传统共词网络的特征与共词网络的语义特征,如语义关系、语义韵等维度,构建语义增强型的全文本共词网络。
2 语义增强型全文本共词网络的构建方法
2.1 语义增强型共词全文本网络的定义及特征
语义增强型全文本共词网络是指以文本的全文为对象,加入节点之间的语义关系、语义关系的方向、跨距等语义特征信息的词汇共现网络。与传统的关键词共现网络相比,该共词网络可用于海量文本的全文本分析与挖掘。通过特定的特征选取和分析,可以实现更多元的研究目标。
语义增强型全文本共词网络中可以进行分析的特征如表1 所示,包括共现特征、网络特征和语义特征等三大类特征。其中,共现特征主要包括共现频次、包容指数、临近指数、等价指数、向心度、密度、Salton 指数等,这些指标的计算方式可以参见文献[23-24];网络特征包括点度中心度、声望、PageRank 值、中介中心度、接近中心度、平均路径长度、聚集系数等,这些指标的计算方式可以参见文献[17,25]等。本文选取研究所需的共现特征和网络特征,加入语义关系和语义关系方向等新特征,并借助共现特征中的跨距来研究词汇的语义韵,为共词网络分析引入了新的特征和分析维度。
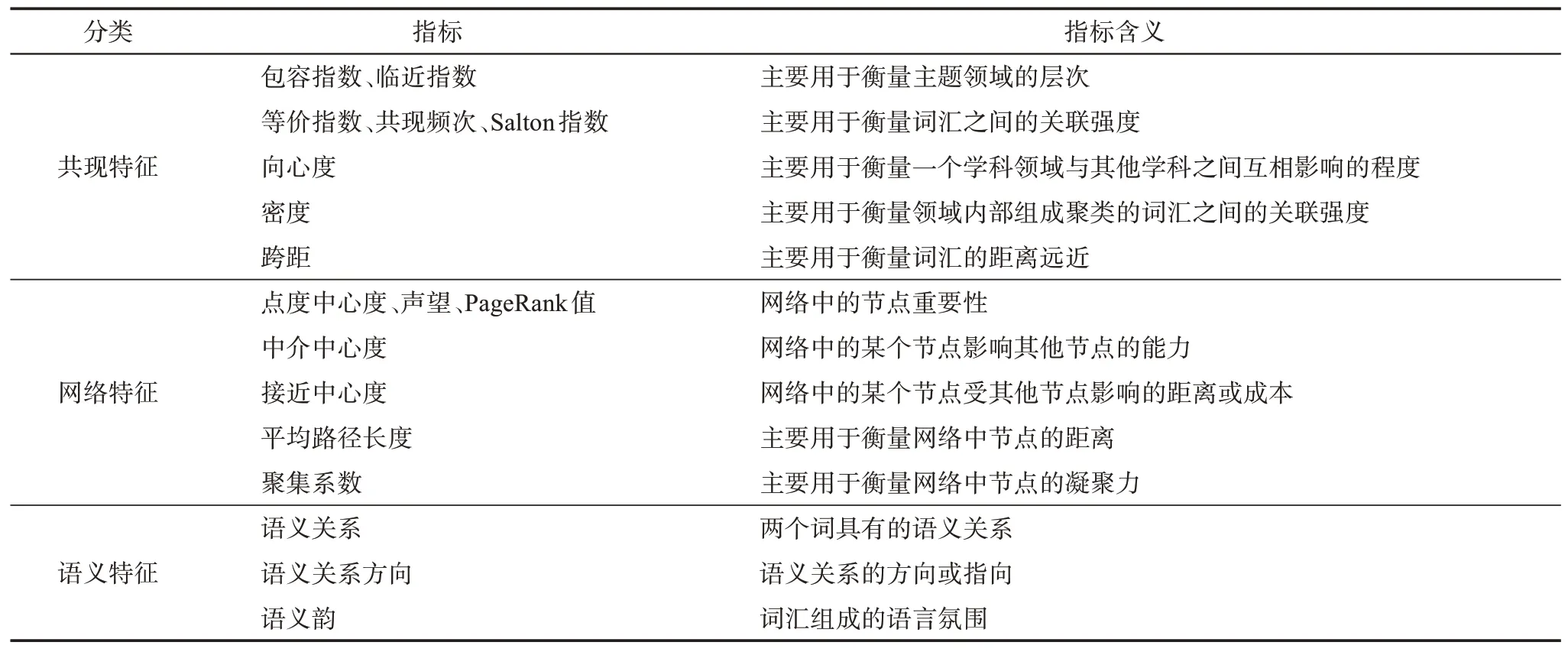
表1 词汇共现网络的特征指标
语义增强型全文本共词网络N可以被表示为语料库或数据集中的所有词汇w、共现词对具有的语义关系r和共现词对五元组t的集合,即
共现词对五元组t表示语义增强型全文本共词网络中的一组共现词对wi和wj具有的语义关系rx、语义关系的方向d以及其具有的特征p,即
共现词对具有的特征p由共现频次、共现强度、跨距等组成,即
跨距是指两个词汇在句子中的间隔距离。在语言学领域,往往通过短跨距下的固定搭配或意义拓展单元来研究词汇或词对。语言学家Sinclair[26]认为词汇搭配是文本当中较短距离下的词汇共现,并给出了一个词汇跨距为5 的推荐距离。虽然学界并没有完全规定何种距离下的词汇共现才能被视为搭配,但是搭配距离的研究却向人们传达出一种信息,即共现词对在句子当中的间隔距离伴随词汇共现现象所产生的一个重要特征。
语义韵(semantic prosody)是语料库语言学的一个重要概念,是指一个词吸引某类具有相同语义特点的词,从而形成某种搭配习惯和语义氛围的现象。词汇的语义韵体现在该词汇与其高频共现的一组具有某种语义关系的搭配词中[27]。进一步地,通过分析词汇共现网络中节点和与其具有特定语义关系的共现词集合构成的子网络,可以发现共现词之间语义氛围,从而理解词汇的语义韵。
2.2 语义增强型全文本共词网络的构建流程
语义增强型网络的构建方法和研究框架如图1所示。①选定需要研究的数据集或语料库;②通过分词、词形还原、删除停用词等文本处理得到语料库中的所有候选词,并挖掘候选词之间的共现关系,组成共现词对;③将作为网络节点的候选词映射到语义知识库的概念或实体中,并标注共现词对之间的语义关系,从而构成网络中节点的边;④对共现词对的特征进行提取或统计,如共现频次、Salton 指数、跨距、语义特征等,其中语义特征包括语义关系、语义关系的方向、语义韵,这些特征将被作为边的属性;⑤通过网络构建得到语义增强型的全文本共词网络,为后续的共现网络分析提供模型与数据支撑。
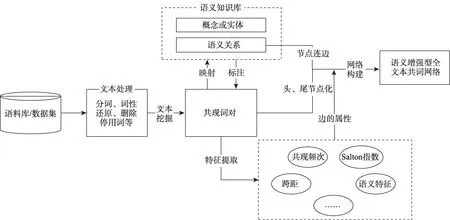
图1 语义增强型全文本共词网络的构建框架
3 实验及分析
3.1 基于新闻文本的语义增强型全文本共词网络构建
本文使用的语料库是著名数据科学和机器学习平台Kaggle 中的“All the News”新闻数据集[28]。此数据集包含从New York Times、CNN、Fox News 等15 个国际著名新闻平台上所收集到的14 万余篇新闻文本数据。
对每个语篇进行分句、分词处理,为了避免单词受单复数、时态等形式的影响,本文对句子中的每个词语进行词性标注及词形还原,以减少句子语法如时态、单复数、变形的噪音干扰对同一语义词语的影响。
为了避免一些无意义的介词、连词、助词、冠词、数字、感叹词等造成干扰,本文使用了Indri 停用词表删除了语料库中的停用词[29]。统计词形还原和删除停用词后的词汇出现频次,并根据齐普夫第二定律筛选高频词汇作为词汇共现的候选词。
通过编程抽取候选词之间的共现关系,从而得到语料库中的共现词对,具体思路:首先,对句子进行编号,并统计每个词语所在的句子编号序列。其次,对两个不同的高频词的所在句子编号序列取交集,若不存在任何句子编号,则这两个词语在语料库的句子窗口没有发生共现;反之,则存在共现现象,且交集中句子数量可视为该词对的共现次数。
在特征抽取方面,使用基于共现频次的Salton指数作为词对的共现强度,并统计每个共现词对在所有共现句子中的平均跨距。在共现词对的语义特征方面,使用ConceptNet 语义知识库对共现词对进行语义关系标注。ConceptNet 是在由麻省理工大学发起的Open Mind Common Sense 众包项目的基础上构建的开源语义知识库,包含了维基词典、专家构建的WordNet 和JMDict 等数据,通过专家标注和多重筛选标准的算法来保证数据的高质量[30]。其利用包含语义关系等属性的加权边来连接自然语言中的单词和短语,从而实现对自然语言中涉及的一般知识的理解,被广泛应用于信息检索、文本分析、机器翻译等领域。ConceptNet 中存在超过800 万个节点以及2100 万条边,核心语义关系共有34 种。其中,单向关系27 种,双向关系7 种。每两个节点间可以存在一种或多种语义关系。
从ConceptNet 语义知识库中抽取语义特征的常用方法有两种。一是通过ConceptNet 的API 接口可以构建出特定的查询式,从而获取到关于某个词汇的三元组知识。调用ConceptNet 接口的具体方式为构建以下形式的URI——http://api.conceptnet.io/query?start=/c/en/keyword。其中,“start=”表示以某一单词作为三元组中头部节点进行相应信息的查找,若是按照尾部节点进行查找,则对应位置设置为“end=”;“/c/”表示节点;“/en/”表示所查询的词汇为英语单词;“/keyword”则表示所要进行查询的目标词汇。将所有共现词对分别作为头节点与尾节点,构建查询式的URL 来标注共现词对的语义关系及方向。二是通过获取ConceptNet 的离线版本并导入数据库,通过查询头尾节点来标注语义特征,离线版本数据中的URL 形式与API 接口返回数据的形式一致。以本文使用的数据为例,使用ConceptNet的API 接口标注1000 个共现词对之间的多重语义关系及每个语义关系方向,用时约1 小时26 分钟;使用ConceptNet 本地化标注80762 个共现词对之间的多重语义关系以及每个语义关系方向,用时约4分钟。
当ConceptNet 中的两个词汇节点之间无法查询到边时,表示共现词汇在ConceptNet 中不存在语义关系。若能够查询得到边,则需要判断头尾节点的连接边的数量及属性,即词汇之间存在的一种或多种语义关系。得到查询结果后,可以根据头节点、尾节点、边的数量及属性来抽取共现词对具有的单一或多种语义关系及方向,并构成共现词对五元组。然后,将每个词汇作为节点,语义关系的方向作为边的方向,汇总共现词对的共现特征和语义特征作为节点间的边的属性。
整理语义增强型全文本共词网络中的词汇集合W、共现词对具有的语义关系的集合R和共现词对五元组集合T,将数据导入Neo4j 数据库中。通过Neo4j 的查询语言,可以计算出节点数、边数等基本统计特征。 同时, 通过Graph Data Science(GDS)库可以进一步计算出节点中心度、节点最短路径、聚集系数等网络特征。GDS 是Neo4j 图数据库的一个插件库,提供了在图数据库中进行数据分析、机器学习等任务的算法,包括中心性度量(点度中心度、中介中心度、接近中心度、PageRank 值等)和社区检测(聚集系数、网络传递性等)等算法[31],可以更方便地挖掘图数据的结构、模式和关系,有助于计算和储存词汇共现网络中的相关网络特征。
综上所述,先通过Python 进行文本处理与共现词对抽取,计算共现词对的共现特征。然后,通过ConceptNet 本地化标注方式进行语义特征的抽取。最后,将数据整合导入至Neo4j 图数据库中,并利用GDS 库得到网络特征,即可实现语义增强型全文本共词网络的构建。
3.2 语义增强型全文本共词网络的特征分析
3.2.1 描述性统计
本文构建的共词网络基本统计特征如表2所示。

表2 语义增强型全文本共词网络基本特征统计
表2 中汇总了语义增强型全文本共词网络的一些基本特征,基于80762 对具有语义关系的共现词对,构建得到了由12808 个节点和约13 万条边构成的语义增强型共词网络。通过Neo4j 查询语句和GDS 库计算可知,网络的平均节点度数较高,平均每个词与其他20 个词连接;节点平均最短路径较短,约为3.458,即两个词之间的平均可通过另外3个节点进行连接;聚集系数为0.1151,而随机网络的聚集系数约为1.55×10-4[9]。由此可见,网络具有较高的聚集性。较短的平均最短路径和高聚集系数表明本文构造的语义增强型全文本共词网络具有小世界效应,这与一般语言网络的特征相符。
3.2.2 连接共现词对的语义关系分布特征
使用ConceptNet 语义知识库标注得到的具有语义关系的共现词对共80762 对,这些共现词对一共呈现30 种语义关系,每种语义关系的定义详见附表1。受篇幅所限,本文仅展示占比前15 位的语义关系,如图2 所示。

附表1 ConceptNet语义知识库中的核心关系及其定义[30]
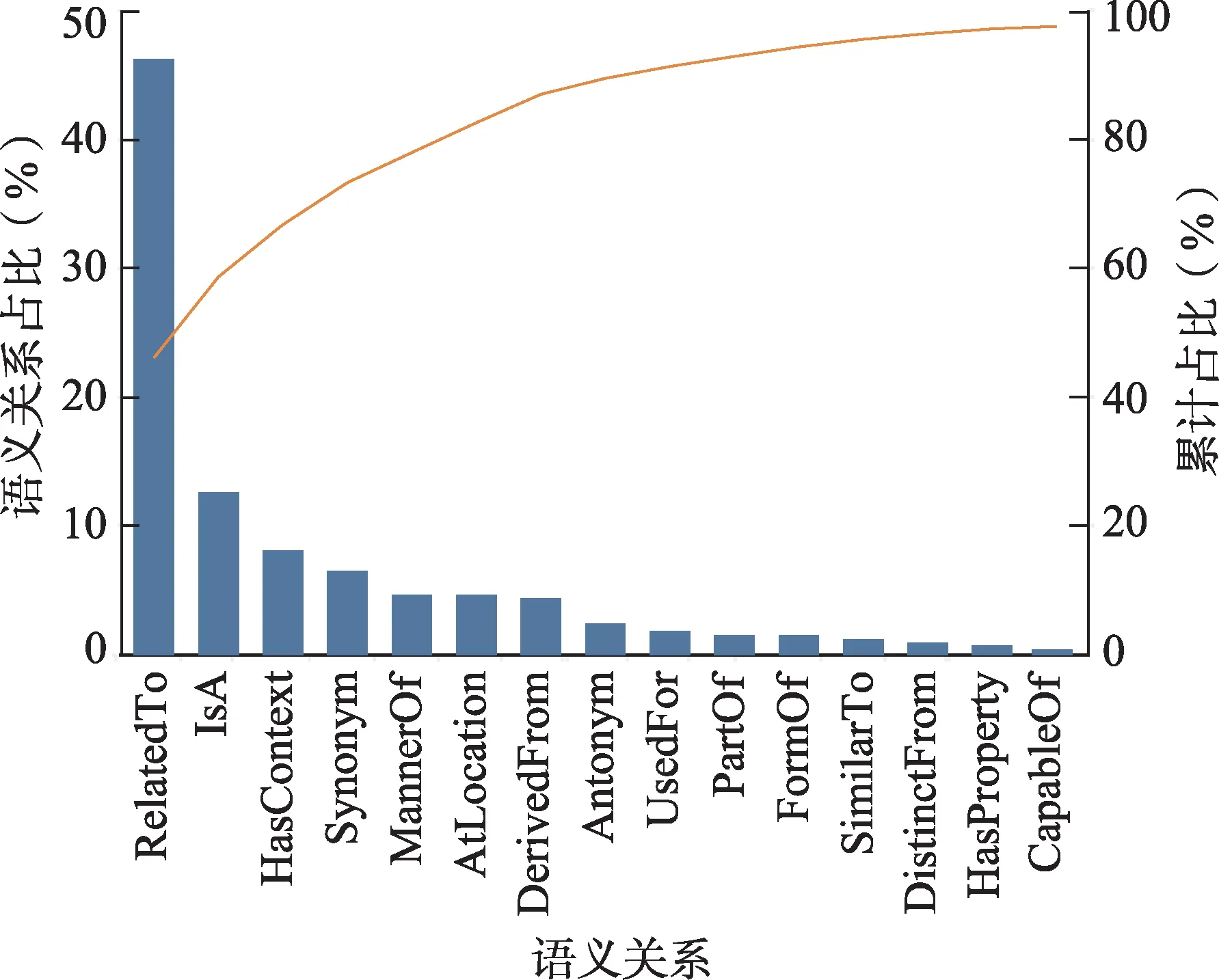
图2 共现词对语义关系分布
由图2 可以看出,RelatedTo 是共现词对中最主要的语义关系,占比约为所有语义关系的一半,其后依次是IsA、HasContext、Synonym、MannerOf、AtLocation 等语义关系,这6 种语义关系累计占比超过80%。其中,在ConceptNet 定义的34 种语义关系中,没有出现的语义关系为EtymologicallyRelatedTo、HasProperty、ObstructedBy 和Etymologically-DerivedFrom。
3.2.3 共现词对在自然句中的跨距分布特征
词汇在自然句中的跨距特征对于揭示词汇共现的差异性、从语义韵视角丰富共现词汇的内涵具有重要作用。本文计算了每种语义关系连接的所有共现词汇在原始文本中的平均跨距,受篇幅所限,图3 展示了出现频次占比前15 位的语义关系连接的共现词对的平均跨距及其分布特征。图3 中的每一格表示某一种语义关系连接的所有共现词汇的平均跨距的分布情况。以第一行为例,在CapableOf 连接的所有共现词对中,49.22%的词对在原始自然句中的平均跨距为1,即两个词在句子序列中的位置差值为1(两个词之间没有间隔其他词),28.53%的词对在原始自然句中的平均跨距为2,即两个词之间被一个词隔开,以此类推。
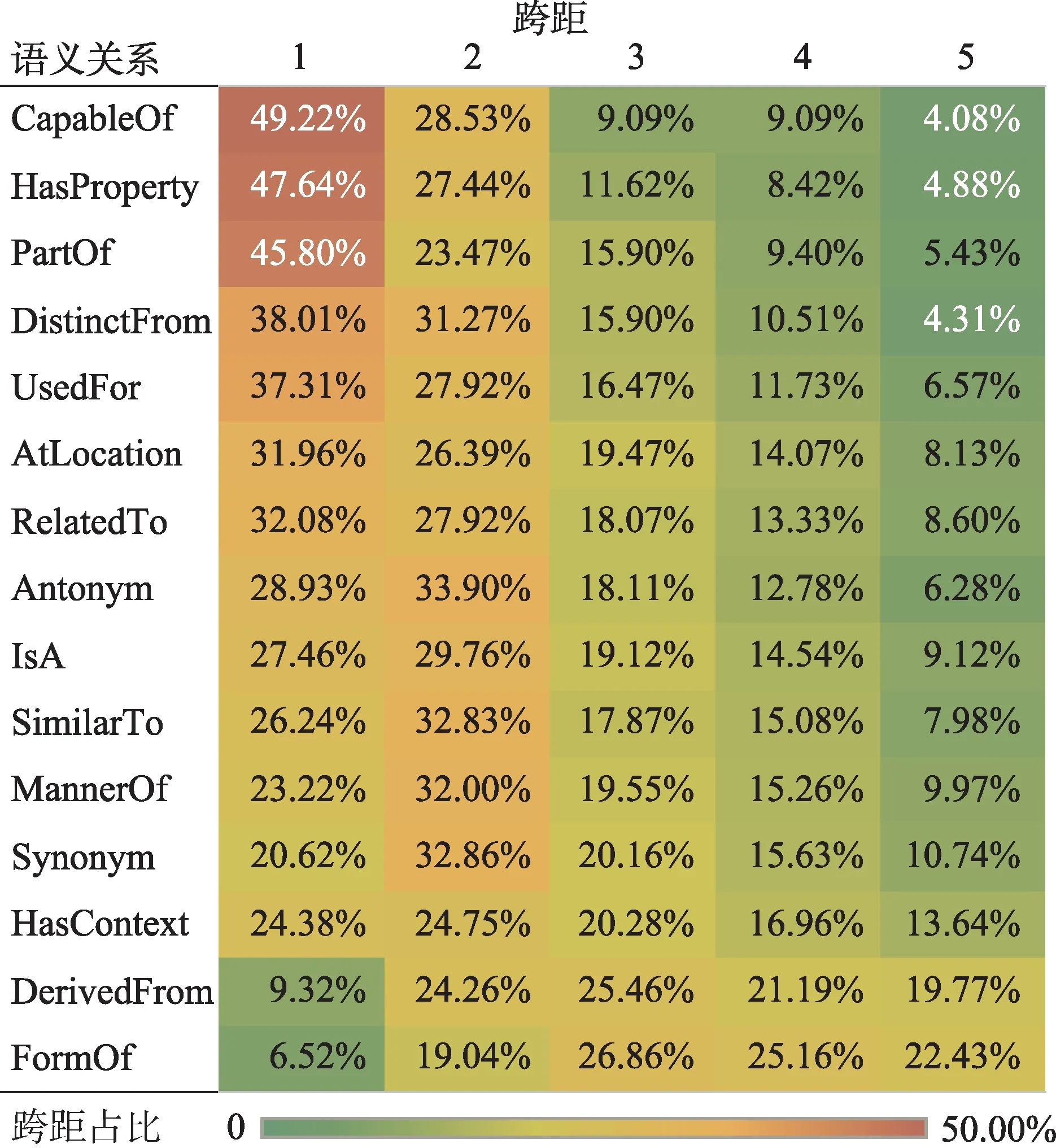
图3 语义关系跨距热力图(彩图请见https://qbxb.istic.ac.cn)
如图3 所示,共现词对的平均跨距一般较小,但不同语义关系连接的共现词对的跨距分布呈现不同的特征。例如,具有CapableOf、HasProperty、PartOf 语义关系的共现词对中,40%以上的词对跨距为1,即往往会以词组或固定搭配的方式出现。相似地,具有Antonym、IsA、SimilarTo 等语义关系的占比最大的跨距为2,即中间往往会被另一个词隔开。同时,HasContext、DerivedFrom、FormOf 的词语跨距较为平均,即这3 种语义关系可能并不会给其共现词对的跨距带来影响。
从语义的视角出发可以看出,跨距不超过5 的共现词对占比普遍较大。同时,若要更细粒度地研究共现词对的共现窗口,则可以考虑不同的语义关系来选取共现窗口的强度。
3.2.4 共现词对的多重语义关系
一个特定的词汇可能表示多种意义,而一种词语搭配也可能产生不同的含义。因此,一组共现词对可能出现多重语义的现象,通过研究共现词对的多重语义关系,可以在一定程度上反映词对的共现现象的语义原因。共现词对的统计结果如表3所示。

表3 共现词对具有的语义关系数量统计
以表3 中的示例词对为例:①news 和fox 仅具有RelatedTo(相关)关系,即这两个词有一定的相关关系,而组合起来为Fox News(福克斯新闻)。②drink 和coffee 具有Antonym 和RelatedTo 两个语义关系,可以发现,当drink 表示名词酒时,其与coffee 在某种程度上是相反的;当drink 表示动词饮用时,可表示drink coffee,呈现相关关系。③rock 和roll 两个词具有Antonym、RelatedTo 和MannerOf 这3种语义关系,即当rock 表示动词剧烈晃动时,与roll 表示动词翻转在某种程度上是相反的;当rock表示名词石头时,rock roll 可以表示石头会滚落的行为语义关系;当组成rock & roll 这一搭配时,又可以表示摇滚的意义。因此,也具有某种程度上的相关关系。④country 可以表示国家、乡村等含义,国家和城市是不同的,城市位于国家中,乡村和城市具有不同的内涵,且这两个词语经常一起出现,因此,country 和city 还具有相关关系。⑤相似地,trash 和garbage 都可以表示名词垃圾,而garbage 还具有垃圾桶的含义,因此,除了Synonym、Related-To、IsA、SimilarTo 的语义关系外,还具有AtLocation 的语义关系。⑥faith 和belief 都有信心、信仰的意思,但是从语义关系而言,faith 是belief 的一部分,来源于belief,由此也能看出,该组同义词具有一定的上下位关系。⑦rest 和sleep 都可以作为名词或动词使用,语义关系更加丰富,不仅具有DistinctFrom、Synonym 等概念性的语义关系,还具有HasFirstSubevent、HasPrerequisite、MotivatedByGoal等动词间的语义关系。
在连接同一个词对的多重语义关系之间,也存在着某种共现关系。此处以表3 第3 行的数据为例对语义关系的共现进行分解,即把Antonym、RelatedTo、MannerOf 这3 种语义关系的共现分解为(Antonym, RelatedTo)、 (RelatedTo, MannerOf) 和(Antonym, MannerOf)的形式进行统计,绘制热力图,如图4 所示。其中,由于RelatedTo 语义关系占比最大,且每一种语义关系均与RelatedTo 语义关系共现最多,为了更好地对比与其他语义关系的占比,在图4 中剔除了RelatedTo 这一语义关系。
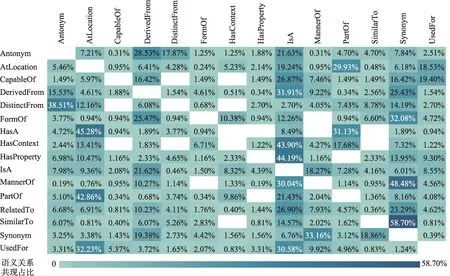
图4 语义关系共现热力图
由此,可以从数据角度侧面证实语义关系的非对称性与传递性,为语义关系的分类与推导提供数据验证。如图4 所示,每一行表示该语义关系与其他语义关系的共现占比。可以发现,一些定义相似的语义关系往往一起共现,如Synonym 和Similar-To、MannerOf 等,其中SimilarTo 与Synonym 的共现占比最高,达到了58.70%。
同时可以发现,语义关系的共现并不一定是对称的,图5 统计了5 种语义关系之间的共现占比。HasA 和AtLocation 两种语义关系由于定义相反,往往一起出现,且占比均超过90%,证实了语言共现现象的对称性。在事件的发生条件的3 种语义关系中,HasFirstSubevent 常常与HasPrerequisite 一起出现,占比达到了77.78%,且与其他语义关系出现较少,所以占比较低。结合语义学知识可知,这是由于这两个语义关系是充分不必要关系,具有语义关系的传递性与非对称性。

图5 语义关系共现的对称性
如图6 所示,relax 与sleep 具有HasPrerequisite语义关系,sleep 与close eyes 具有HasFirstSubevent语义关系,因此,后者是前者的充分不必要条件,也可以证实语义关系的传递性与非对称性。

图6 HasFirstSubevent和HasPrerequisite语义关系示意图
3.3 语义增强型全文本共词网络的应用
本节将通过具体的应用案例来证明和验证语义增强型全文本共词网络构建方法的有效性,并凸显该网络在语义消歧和词义理解方面的应用与价值。
3.3.1 语义增强型全文本共词网络在语义消歧方面的应用
语义增强型全文本共词网络中的语义韵信息是观察和描述词汇的新视角,在同义词辨析等语义消歧方面具有应用前景。在已有研究中,语义韵是基于专家的经验进行观测和判断的,难以支撑大规模词汇网络中的语义分析。使用本文构建的语义增强型全文本共词网络则可以查询以词汇为中心的子网络,更清晰地展示词汇与其具有某种语义关系的共现词的集合,从而构建出语义韵的研究结构,有助于揭示词汇的语义韵特征。
虽然happen、occur 在概念上是绝对的同义词,但实际上在搭配关系和语义韵等语言特征中存在差异。通过语料库中的检索结果进行精读分析,可以发现如happen 往往与“事故”“问题”等具有“消极结果”语义的词汇共现,但occur 则不具有明显的消极语义韵倾向性,表明了语义韵的态度标示功能和在同义词差异辨析中的作用。
以happen 和occur 为例,这两个词汇的共现词对在语义增强型共词网络中的查询结果如图7 所示,两个词分别具有18 个和11 个共现词汇,其中4个为共同的共现词。由此可以看出,这两个词语具有较大的语境差异,且happen 比occur 具有丰富的共现词汇和语义关系。其中,与happen 共同出现的词汇中包括一些让人感觉到“消极结果”的语义氛围,如intervene (干涉)、backfire (适得其反)、transpire (泄露)、force (强迫) 等,由此可见,happen 比occur 具有更消极的语义韵态度。

图7 happen和occur词汇的子网络
因此,当面临同义词选择问题时,可以将词汇在共词网络中的共现词汇和语义关系构建为向量特征,用于衡量词向量的差异性,通过模型训练进行分类或选择,从而通过共词网络中的词汇特征改进语义消歧方法。
3.3.2 语义增强型全文本共词网络在词义理解方面的应用
帮助使用者确定一些语义模糊词语在特定语义中的确切意义,是语义增强型全文本共词网络可以带来的又一好处,可以解决很多行业问题。
以法律行业为例,美国法律界对法律条款中关键词的解释往往需要通过词汇的“平义”(plain meaning)来裁定。然而,词典中枚举了词汇的所有释义,很难辨别词汇的“平义”,且缺乏词汇使用的语境,因此,许多法律专家开始通过语料库来寻找词汇的平义。其中,知名的案例包括“联邦通信委员会诉美国电话电报公司案”(FCC v. AT&T Inc., 562 U.S. 2011)、“美国诉科斯特洛案”(United States v. Costello, 666 F.3d 1040, 2012)、“犹他州诉J.M.S 案”(State of Utah v. J.M.S, 2011 UT 75) 等。Mouritsen[32]统计了20 世纪60 年代到21 世纪初的美国最高法院裁决记录,发现ambiguity、plain meaning 等词语频率急剧增长,说明法律条款的解释已经成为庭审中的难点问题。
本文构建的共词网络有助于揭示一个词语的平义。以“联邦通信委员会诉美国电话电报公司案”为例,庭审中的核心纠纷之一为《信息自由法案》条例中的侵犯个人隐私(personal privacy)是否适用于公司(corporation)。在本文构建的共词网络中查询privacy 一词可以得到该词汇的共现子网,如图8 所示;与privacy 共同出现的词汇及其语义关系和语义强度如表4 所示。
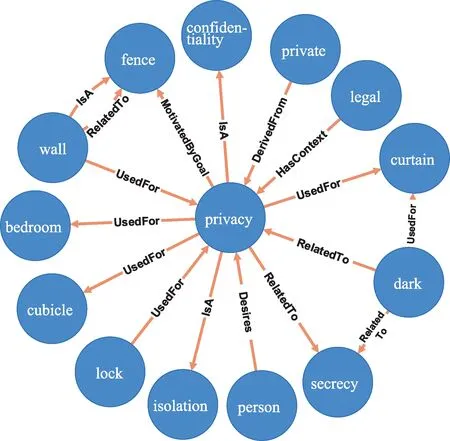
图8 privacy词汇的共现子网
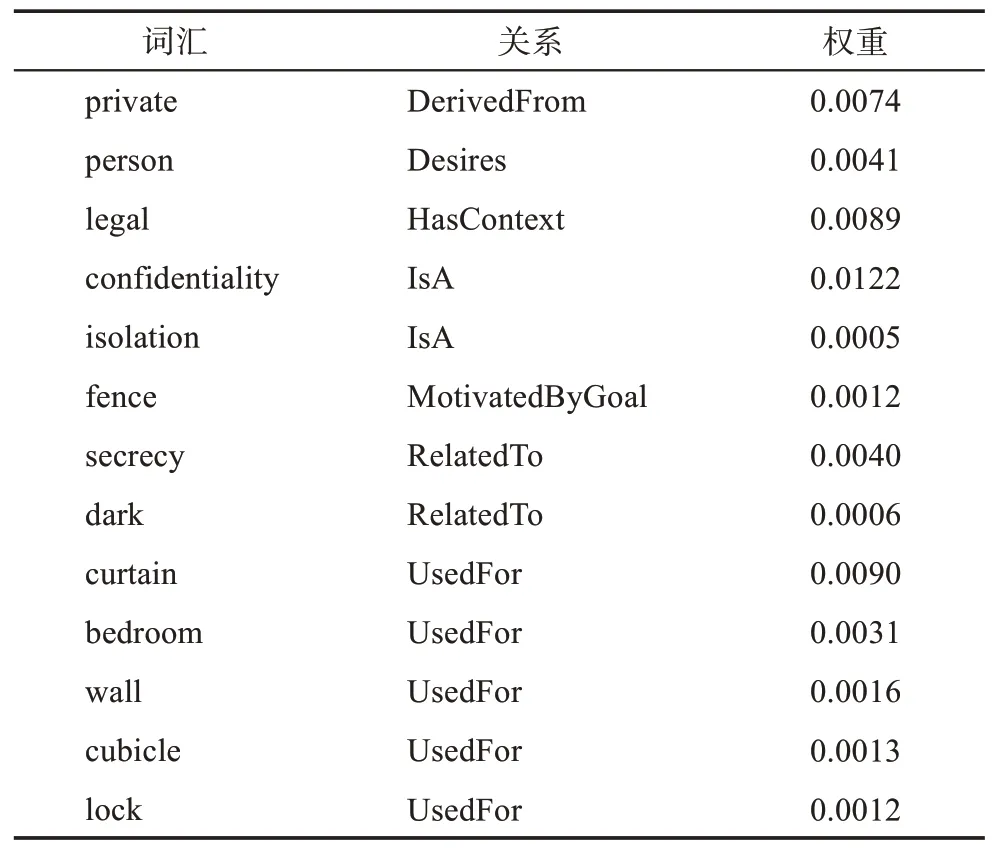
表4 privacy词汇的共现词
可以看出,privacy 一词与person 具有较高的共现强度,具有Desires 的语义关系;而在以privacy为中心的子网络中却不存在corporation 一词。其共现词主要包括:①隐私的主体:person;②描述隐私的相关定义:private、legal、confidentiality、isolation、secrecy;③保护隐私的方式或条件:fence、curtain、dark、bedroom、wall、cubicle、lock。由此可知,个人隐私不适用于公司这一主体,这也与“联邦通信委员会诉美国电话电报公司案”的裁决结果一致,且该案裁定之后,美国公司的隐私权不再受《信息自由法案》的保护。
通过语义增强型全文本共词网络对特定词汇的子网进行来查询和分析,可以加深对特定词汇的词义理解,进而分析词汇的常用语境,辨别词汇的平义,从而为法律行业等需要明确厘清词义的领域提供词义理解的数据验证方法。同时,通过查询子网络,可以避免在语料库中通过检索行来总结和判断词汇的词义的复杂流程,大大减少词汇“平义”的语义知识检索时间,实现更精细化的词汇检索,提高词义理解在行业使用中的效率。
4 讨论与结论
本文提出的语义增强型全文本共词网络构建方法引入了共现词对间的多重语义关系、语义关系方向、共现词对在原始文本中的平均跨距等新特征,揭示了共词网络中蕴含的RelatedTo、IsA、HasContext、Synonym、MannerOf、AtLocation 等语义关系,并发现共现词对语义关系的类型会影响词汇在句子中的跨距,通过研究实例证明了该网络的应用价值。
相较于以往的共词网络研究,本文提出的语义增强型全文本共词网络有3 个方面的学术贡献。
第一,引入了词间语义关系、跨距等新的语义特征,极大地丰富了共词网络的理论内涵。已有关于共词网络的研究通常是对共现词对进行数值上的统计分析,把每一次共现都看作无差异的,主要利用共现频次等统计特征开展应用研究,未考虑词语之间差异化的语义关系[11,14],没有解决词汇共现“同量不同质”的问题。本文通过共现词对词间语义关系的揭示,较好地解决了该问题。
第二,揭示了共现词之间的多重语义关系,通过实例证明了共现词之间语义关系的非对称性与传递性[33],为共现词对词间语义关系的分类与推导提供了理论依据,这一点在已有研究中尚未被清晰地揭示出来。
第三,从语义层面刻画了同一共现词对在不同情境下的差异性,提升了共词分析的精确性。已有研究大多没有考虑这种差异性,忽略了同一个共现词对在不同的情境下表达出的不同含义[14,21]。本文通过共现词之间多重语义关系的识别与表示,揭示了这种差异,为精细化的共词分析打下良好的基础。
本文的实践启示包括两点。
第一,提供了同义词辨析等语义消歧问题的解决思路,通过语义增强型全文本共词网络中词汇子网络的识别,揭示了词汇的语义韵特征,发现同义词的在语义氛围上的差异性,有利于语义消歧中词向量的构建,提高词汇语义研究的效率。
第二,有助于抽取出更高质量、更有意义的共现词对,从语义关系的视角增强词汇共现现象的可解释性,从而为词汇聚类、知识发现等下游任务提供全新的思路和视角。
未来研究将基于语义增强型全文本共词网络,通过构造语义词向量等方式,推动该方法在词义理解、语义消歧等领域的应用。
