融合语步和文本多特征的科技论文结构化摘要生成
2023-11-21习海旭黄纯国
习海旭,何 胜,黄纯国
(1. 江苏理工学院计算机工程学院,常州 213001;2. 南京理工大学经济管理学院信息管理系,南京 210094)
0 引 言
随着以科技论文为代表的科研成果呈现爆炸式增长[1],科研工作者在文献调研和阅读上需要投入大量时间,科研工作负担较重,效率不高。信息检索和推荐技术能够快速定位重要论文,提高文献调研效率;借助移动智能终端能够实现随时随地移动阅读,拓展相关阅读并方便同行交流,一定程度上提高了文献阅读效率。然而,一方面,检索或推荐系统仅返回匹配论文列表,缺乏对论文内容的概要总结,科研工作者仍需要花费大量时间通读论文,并提炼论文的核心内容;另一方面,受限于阅读设备屏幕和操作限制,用户专注阅读文献的质量不高[2]。因此,在海量文献中抽取关键内容并形成摘要,不仅可以适应移动阅读的速读化特点[3],还能够大幅提高知识获取效率,成为提高科研工作者科研效率的重要途径[4]。
论文的摘要部分是作者对全文的主观概括,内容简洁但不完整[5],而自动摘要技术能够形成全面、准确表达原文中心内容的有效简短信息[6],提高科研工作者的文献阅读效率。目前,生成式摘要方法的最佳模型常生成大量和原文不一致的内容,缺乏实用性[7],因此抽取式摘要得到研究者们的广泛关注,尤其是在需确保严格符合原文事实的法律、医学和科学文本的摘要研究中[8]。抽取式摘要方法对单篇文献或主题相近的文献集合进行概括[9],从文献的句子分类或引文上下文聚类等角度[10],基于规则、统计学习或深度学习等方法,抽取摘要句形成文献摘要或文献综述[11]。其中,无监督的抽取式摘要方法因其易用性成为实用选择。在已有研究中,一方面,该方法没有对已有文本特征信息进行较好的整合,摘要文本的相关性、多样性较低且两者之间平衡性有待提升,连贯性和可读性不强;另一方面,该方法较少关注科技论文实现学术交流意图时采用的不同语步元素(如研究目的、方法、结果等),使得所形成的摘要文本难以概括和反映论文研究过程的全文细粒度内容,影响用户对论文的全面理解。
语步,又称为修饰功能,是实现交流功能的修饰单位[12]。与篇章结构不同,语步结构主要是从交际意图的角度对科技文本进行更细粒度的结构划分[13]。例如,可以把论文全文划分为研究目的、方法、结果与结论等语步结构。本文基于科技论文全文的语步结构,考虑论文文本的多特征权重融合和摘要文本的可读性特征,提出一种面向科技论文移动阅读的结构化摘要改进方法。一方面,该方法利用论文的语步文本分别生成摘要,能够全方位概括论文的细粒度研究内容;另一方面,不同语步文本中句法结构和句子成分信息的多个特征权重的累加迭代以及文本的冗余和简化处理,提升了摘要文本的相关性、多样性和可读性。
1 相关研究概述
本文旨在研究基于语步的科技结构化摘要生成方法,提高科技论文移动阅读的效率,涉及领域包括科技论文抽取式摘要和科技论文语步识别。下文对这两个方面的研究现状进行综述。
1.1 科技论文抽取式摘要研究
科技论文抽取式摘要直接从论文原文、施引文献的引文上下文中抽取句子、关键词、主题词等信息作为摘要文本,或进一步按照指定模板形成结构化摘要[14],为科研工作者提供信息服务。其主要包括基于规则、基于统计机器学习和基于深度学习的方法。其中,基于规则的自动摘要方法在研究初期被广泛使用,该方法根据文本中的各种统计特征,按照预定规则确定文档各句子作为摘要句的可能性[15-17]。随后,基于统计机器学习的自动摘要方法通过从文本中学习特定的模式来对句子进行分类或排序,选择成为摘要句概率高的句子形成自动摘要,如TextRank 等无监督机器学习模型[18]和支持向量机等有监督机器学习模型[19];或者进行文本主题建模和关键词抽取,分别把主题词或关键词列表作为自动摘要。随着论文-摘要大规模数据集的增加和现代神经网络模型的发展,基于深度学习的方法得到了广泛应用,该方法利用多层非线性处理单元的级联从数据中学习文本特征的高级别抽象表示,再基于文本的层次化语义特征表示,通过序列到序列和融入注意力机制等学习方式建立模型,抽取摘要句。
1.2 科技论文无监督的抽取式摘要研究
在有监督的机器学习方法中,摘要模型的训练依赖于不同领域、语言和摘要风格下的大规模高质量标注数据,这使得该类方法难以被广泛应用。因此,基于无监督的抽取式摘要方法的研究成为更现实的选择。提升摘要句的相关性、多样性和可读性是无监督抽取式摘要研究关注的主要问题。其中,相关性是指摘要所选用的句子最能够表达文本的中心思想;多样性是指生成的摘要包含的冗余信息尽可能地少,每句话尽可能地单独表达文本的一层意思且所有摘要句尽可能包含文本表达的所有意思;可读性是指摘要文本叙述的流畅度、简洁性和被理解的难易程度。
研究人员利用能够体现句子重要性的不同特征来提升摘要的相关性。例如,Zheng 等[20]使用BERT(bidirectional encoder representations from transformers)模型编码句子语义,将句子位置信息引入TextRank 模型的节点中心性计算中,抽取关键句以形成摘要;Dong 等[21]针对科学长文本,使用方向性和层次结构扩展了文档的图表示,并使用不对称的边缘加权函数确定句子重要性;Ju 等[22]提出了一个多视图信息压缩框架,使用多个引导信号指导文档摘要,先通过多信号检索文档的关键内容,再使用预训练模型进一步检索和修改句子以形成摘要。
研究人员加入额外权重信息或采用结构化自动摘要方法提升摘要的覆盖范围和多样性。例如,Liang 等[23]为了避免科学长文档和多文档中图节点中心性计算方面偏差问题,在句子中心性得分中加入句子-文档权重,实现多面性摘要句的抽取;Gidiotis等[24]分别对科技论文的IMRD(introduction-methodresults-discussion,引言-方法-结果-讨论)篇章结构文本训练摘要模型,综合不同部分的摘要内容形成结构化摘要;李鲲[25]对科技文本中的每个句子进行事件要素类别识别,并计算其重要程度,选择各个事件要素类别下重要程度最高的句子以组成结构化摘要;Xu 等[26]从对话中抽取所有字段及其内在关系,并按照模板组织生成结构化摘要。其中,文本的结构分类和信息抽取方法直接影响结构化自动摘要的质量。
研究人员一般使用混合式摘要方法来提升摘要的流畅性、简洁性和可读性,即在精心选择原文档的子集上应用生成式摘要方法生成摘要文本[27]。例如,Manakul 等[28]使用局部自注意力和内容选择方法,解决了长文档摘要生成中的大型模型训练微调难和长跨度依赖的问题;Pilault 等[29]在使用Transform 模型生成摘要之前执行了一个简单的提取步骤;谭金源等[4]提出了一种基于BERT-SUMOPN 的抽取-生成式摘要方法,对抽取得到的关键句进行端到端训练以生成摘要结果。
上述研究中,结构化自动摘要研究较少关注科技论文实现学术交流功能时采用的语步结构,而全文的语步文本是实现知识交流功能的主要单位,影响用户对论文研究过程的全面理解;混合式摘要方法还依赖于有监督机器学习模型。已有研究单方面提升了自动摘要方法的性能,但在整合已有句子特征、从相关性和多样性之间找出最佳平衡并提升可读性方面仍值得进一步研究。
1.3 科技论文语步识别研究
科技论文的语步识别是指把科技论文中的句子依次分类到不同的语步结构中,形成相比于篇章结构文本更细粒度的语步文本。已有研究通常采用基于规则匹配、基于统计机器学习和基于深度学习的方法,对科技论文的摘要、引言或全文进行语步识别分类。其中,基于规则匹配方法通过使用不同语步文本中常采用的词语和典型句式等词汇与句法特征构建规则模板来识别语步[30]。该方法的规则设计过程专业性强,可移植性差。为此,引入基于统计机器学习方法,以自动发现指定特征的语步文本的识别模式[31],包括朴素贝叶斯、支持向量机等各种经典分类模型,但该方法需要通过特征工程设计大量的特征。受益于深度学习的特征自动学习能力,CNN (convolutional neural network)、LSTM (long short-term memory)等神经网络模型被应用于语步识别任务[32],但该方法学习到的特征交叉严重且不够全面,通常使用词向量嵌入表示,导致难以获得篇章中句间的上下文特征。预训练语言模型BERT可以同时对词间关系和句间关系进行学习[13],直接获得句子向量表示,且可根据特定任务进行参数调优[33-34],已成为语步识别的主流方法。
2 基于语步的科技论文结构化摘要研究框架
为了使读者通过阅读科技论文的摘要文本就能够快速了解该研究各个方面的具体内容,本文提出基于语步的科技论文结构化摘要方法。首先,将科技论文全文按照学术交流的目的划分成不同的语步文本;其次,提取不同语步文本上的关键内容形成文本摘要;最后,组合不同语步文本的摘要生成流畅的科技论文结构化摘要。
2.1 整体架构
本文基于语步的科技论文结构化摘要研究框架如图1 所示,主要包括科技论文数据处理、语步识别和文本摘要3 个部分。其中,在数据处理步骤中,清洗论文文本中的噪声数据,解释论文不同区域的文本内容,将正文文本分割成句子,并对随机论文句子所属语步进行人工标注;在语步识别步骤中,使用基于规则和深度学习模型相结合的语步识别方法对论文正文的所有句子进行语步分类;在文本摘要步骤中,基于文本多特征融合的无监督抽取方法,分别形成不同类别语步文本的文本摘要。最后,将不同语步摘要文本填充到摘要模板中生成结构化摘要。
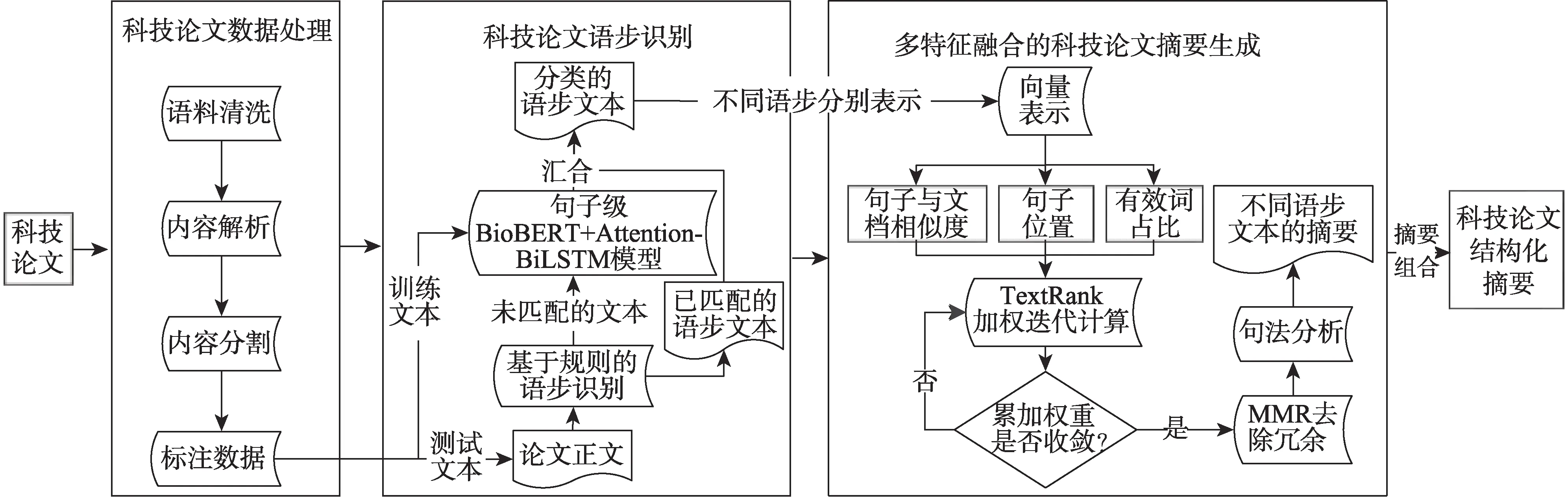
图1 基于语步的科技论文结构化摘要研究框架
2.2 科技论文数据处理
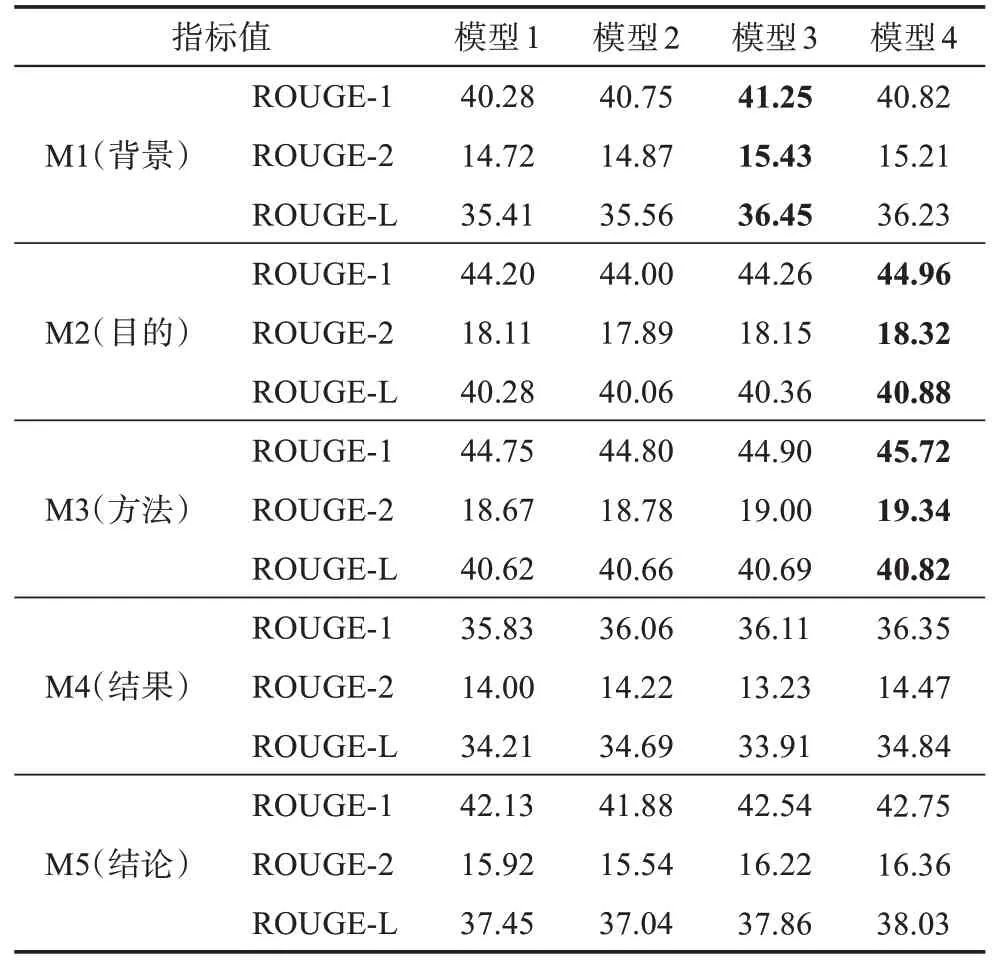
本文使用生物医学类科技论文作为语料进行结构化摘要研究。在数据处理阶段,需要清除论文噪声信息并对正文句子进行语步标注,包括语料清洗、内容解析、内容分割和标注数据4 个步骤。在语料清洗步骤中,首先,使用GROBID(generation of bibliographic data)①https://grobid.readthedocs.io/en/latest/工具将PDF (portable document format) 格式的论文转换为XML (extensible markup language) 格式。其次,使用Python 规则库②移除图表、上下标等;③删除论文中的致谢和参 https://tinyurl.com/q5v9p5d清除论文中的非文本内容,包括:①把论文中的引用和数字内容分别替换成 表1 生物医学类科技论文语步分类框架 本文将科技论文语步识别看作句子分类任务,已有研究表明,该任务需主要关注整个句子的特征构建和句间上下文信息。本文采用规则和深度学习模型相结合的语步识别方法。首先,使用基于规则匹配的方法识别具有语步对应词汇和句法模式的句子,如“目的”语步文本中常有“purpose、objective”等线索词和“… of … be to, … is to …”等句型。其次,使用BioBERT+Attention-BiLSTM 深度学习模型识别未匹配的句子。 该模型包括7 层:输入层,特征学习层,前、后向LSTM 层,Attension 层,Softmax 层和输出层。①在输入层把词向量、词位置向量、句子分段向量和句子位置向量进行拼接,形成文本的多特征融合表示;②特征学习层通过BioBERT 模型[35]训练,获得整个句子的语义特征表示;③学习到的句子向量被输入BiLSTM 模型中,以便捕获句子中的双向信息,从而体现句子上下文特征;④在输出层之前增加Attention 层,生成权重向量对应每个词的权值,以提升句子中重点词语的权重;⑤通过Softmax 层输出句子分类标签。其中,BioBERT 模型的输入向量矩阵为 其中,词嵌入是词向量表示;词位置嵌入表明词在论文中的绝对位置;句子分段嵌入表明词属于哪个句子;句子位置嵌入表明句子在论文中的绝对位置。 句子位置向量的计算公式[15]为 其中,pos 为句子在全文的相对位置,例如,第i个句子的pos 值为i/m,m为全文句子总数;dmodel为模型输入向量的维度。 本文对上述操作识别出的语步文本分别进行文本摘要,提出了一种多特征融合的科技论文无监督摘要抽取方法以生成结构化摘要。首先,影响摘要的相关性存在各种外在因素,包括文本的整体框架结构信息和文本信息内容,每种因素在摘要生成过程中带来了不同的影响,需针对每种因素在TextRank 算法的累加权重迭代计算过程中提出相应的改进措施。其次,考虑到摘要相关性和多样性的平衡,对获得的候选摘要句群需做冗余化处理;在摘要的输出方面需要做相应的优化,以提升最终输出的连贯性和可读性。再其次,可以对摘要句做依存句法分析,在特定的场景下,通过提取句子主谓宾或其他内容实现对句子的理解功能,从而对抽取出的摘要进一步精简。最后,按照语步元素设计模板,分别将不同语步文本的摘要内容进行组合生成结构化摘要。 2.4.1 多特征融合TextRank改进算法 本文在TextRank 算法过程中,综合考虑文本多特征对迭代计算得到的累加权重WS 进行修正,将WS 与句子位置、句子与文档相似度和句子有效词占比3 类权重进行运算得到修正的累加权重WS′,以提升摘要句的相关性,计算公式为 (1)句子位置权重 句子位置影响句子的重要性。诸如新闻类的文章往往会在第一句阐明文本的主旨思想,在电商评论文本中会在最后一句表明买家对该商品的态度。因此,在处理文本时,距离文本开始位置和结束位置的句子应适当提高其权重。另外,有研究结果表明,人工生成摘要时,选择段落首句当作摘要的概率为85%,选择段落末句作为摘要的概率为7%[36]。所以,段落首句比段落末句更有可能被选择成为摘要,可根据句子的位置信息,赋予不同的句子权重得分。本文采用LocScore(Si)表示句子Si的位置权重得分,计算公式为 (2)句子与文档相似度权重 文本内容所包含的句子都是围绕中心思想展开的,因此,在文本中与文本内容相似度较高的句子更有可能成为最终的摘要句。本文使用余弦相似度衡量文中句子与整篇文本内容的相似性,计算每个句子与整段文本之间的相似值,若句子与文本内容具有较高的相似度,则对该句子的权重进行调整,调整规则为 其中,Si(w)为句子Si的最终权重;similarity(Si,Pi)为句子Si与文本向量Pi的余弦相似度。 (3)句子有效词占比权重 句子的有效词,是指符合一定条件、能够表达一定含义的独立词语。在英文中,有效词需满足:①词语是由字母、连字符和/或标点组成,不能包含数字;②至多一个连字符“-”,且连字符两侧是字母;③至多一个标点符号,且位于单词末尾。句子的有效词占比在一定程度上反映了该句子所包含信息的多少,通过对句子进行分词、去停用词来统计句子中有效词个数占整个句子词语总个数的分数SProportion,作为调整句子权重的调节系数。 2.4.2 基于最大边缘相关的摘要冗余处理 摘要相关性和多样性的平衡是指原文本表达的所有意思尽可能在抽取摘要中都有一句话单独进行表达。因此,对于最终获得的摘要候选句,为了增加其多样性,将相似度较高的句子进行权重值减分操作或者去除句子操作。本文引入最大边缘(maximal marginal relevance,MMR)算法思想,在按句子权重大小排序结果得到的预选摘要集中引入惩罚因子,对所有初次排序后的句子重新打分,计算公式为 其中,i表示排序后句子的顺序;vi表示已初步选中的句子;λ表示调整系数,表明该句的主题相关度。第一个句子不需要进行惩罚计算,从第二个句子开始,后面的句子依次与前一个句子的相似度进行惩罚。对于与已选摘要句相似度较大的句子,将其从预选摘要列表中删除,以保证提取的摘要句之间差异性较大。同时,如果只是把摘要句机械地按照句子权重排序组合在一起,那么不能保证句子间的有效衔接和连贯。为了保证摘要的连贯性和可读性,本文把选取的摘要句按照原文顺序输出。 2.4.3 基于依存句法分析的摘要文本精简 为了进一步精简摘要文本,本文使用依存句法分析各个语法成分之间的语义修饰关系,以获取距离搭配信息。通过构建句法依存树模型来提取句子的主干,实现句子语义理解的功能。将句法分析结果依次写入列表,遍历列表内容,取出依存关系为“主谓关系”的第一个词语,即该句的主语,根据该词所对应的“当前词语的中心词”编号取出对应的谓语动词,最后根据找到的谓语下标再次遍历列表寻找和谓语动词构成“动宾关系”的词语,即该句的宾语。 2.4.4 结构化摘要生成 为了获得科技论文全文内容的结构化摘要,使移动读者快速了解论文各语步的主要内容,本文对识别的不同语步文本分别采用多特征融合的摘要生成方法获得各语步的摘要句,将其分别填入结构化摘要模板中的相应位置,完成摘要生成。结构化摘要模板包含论文标题、作者等元数据,以及背景、目的、方法、结果、结论等内容要素,向读者展示了论文的研究动机与研究过程、研究结果与研究新发现等这些关键内容。 为了验证科技论文结构化摘要方法的有效性,本文对SumPubMed 数据集进行语步识别后生成每篇论文的结构化摘要,并将两个子任务的实验结果与相关基准进行对比与分析。 本文从数据来源和数据分布两个方面介绍实验数据情况。 3.1.1 数据来源 SumPubMed 数据集来源于PubMed 生物医学研究论文数据库,Gupta 等[37]从BioMed Central(BMC)选取了33772 篇论文并进行预处理,形成了XML、原始文本和名词短语3 个版本。论文涉及医学、药学、护理学、牙科、保健、健康服务等学科研究,每篇论文包括摘要和正文,正文部分包含3 个小节:背景、结果与结论。本文使用SumPubMed 数据集的原始文本版本,该版本对摘要和正文的科学实体进行过一致化处理。 3.1.2 数据分布 数据总集和已标注的数据集的数据分布情况如表2 所示,总体标注的科技论文语步句子数量及其占比情况如表3 所示。结果语步的文本明显多于其他语步文本,表明生物医学类科技论文更加重视研究结果的描述和分析。 表2 数据总集和已标注的数据集的数据分布情况 表3 标注的科技论文各语步句子数量及其占比情况 本文的评价指标包含语步识别和文本摘要两个子任务的评价指标。 3.2.1 语步识别评价指标 语步识别本质上是一种经典的分类任务,而分类性能常采用查准率(precision)、召回率(recall)和F1值3 个指标来评价。由于不同语步的识别效果不一定完全相同,故常常采用这3 个指标的宏平均值来对语步识别的整体性能进行评估。 3.2.2 文本摘要评价指标 文本摘要的评价包括相关性、多样性和可读性3 个方面。本文采用ROUGE-1 (R-1)、ROUGE-2(R-2)和ROUGE-L(R-L)的查准率、召回率和F1值3 个指标的宏平均值来度量摘要整体的相关性。采用句子语义的不相似性来度量摘要的多样性,即 其中,n是文本的句子数;MSi是句子Si的词数;SiWi是句子Si第i个词的向量表示;sim()表示句子间的余弦相似度;no_Distinct 值越大,文本多样性就越高。采用句子概率[38]来度量摘要的可读性,即 其中,N是文本长度;p(wi)是第i个词的概率;Readable 值越高,文本通顺度越好。相关性一般体现在自动摘要包含标准摘要中常见词与短语的多少,但词汇重叠少并不代表不好的摘要;多样性主要体现在语步摘要内冗余文本的多少,但不冗余并不代表涉及文本的多个方面;可读性主要体现在自动摘要是一个句子的概率,但句子不一定都能清晰表达文本含义。因此,本文结合人工评价,分别对摘要的相关性、多样性和可读性做主观评分。 3.3.1 实验设置 按照8∶1∶1 将1000 篇论文标注数据集随机划分为训练集、验证集和测试集。选择基于Attention BiLSTM(简称“方法一”)、基于BERT 和人工特征结合深度森林(简称“方法二”)和基于句子位置向量的SciBERT 结合多层感知机分类器(简称“方法三”)与本文方法进行语步识别性能对比。实验选用Python 3.9.7 版本语言,方法一的模型参数包括词向量维度为300,隐藏层神经元个数为800,激活函数选择tanh(),损失函数选择交叉熵损失函数,批训练大小为64;方法二中深度森林算法采用DeepForest 实现;方法三的最佳模型参数包括批处理大小为32,学习率为2e-5,训练期为4,分类器隐含层节点数为128。 3.3.2 结果与分析 不同模型下不同语步的F1值与宏平均F1值如表4 所示。本文提出的规则匹配+多特征向量+BioBERT+Attention-BiLSTM 模型效果最好,宏平均F1值达到0.821。其原因可能在于:相比于方法一,本文使用专门面向生物医学文本的大规模预训练语言模型BioBERT,能够得到区分度较高的句子隐含语义特征表示。相比于方法二,本文采用BiLSTM 模型捕获上下文词语之间的语义依赖关系,且Attention 机制能够自动增加对语步识别起关键作用的“线索词汇”的权重。由于“目的”“结论”语步中通常包含“aim to”等线索词汇,因此,本文方法和方法一对这两个语步识别的F1指标排名高于其他方法。相比于方法三,本文在模型中引入了规则匹配和预训练语言模型BioBERT,通过语法规则、句法表达习惯和特定领域的语言模型提升识别性能,同时,能够减少模型训练对语料规模和质量的依赖。使用方法一的宏平均F1值最低,为0.630,其原因可能在于:BERT 模型和方法一一样,能够训练单词的双向表征并动态调整词汇权重。除此之外,方法二使用了擅于学习高维数据隐含模式的深度森林分类算法,方法三与本文方法同时丰富了模型输入的分类特征。 表4 科技论文语步识别结果(F1值) 相同模型下不同语步识别的F1值存在差别,总体上,所有模型下“结果”语步最高,其次是“方法”语步,其他语步在不同模型下的排名存在不一致现象。例如,“背景”语步在其他模型中均排名第三,但在带有Attention-BiLSTM 的模型中排名最后。其原因可能在于:首先,“结果”语步文本内容在论文全文中占比较高,可得到较好的分类效果;其次,在生物医学实验中,“方法”具有较为规范的专业写作方式,该语步的分类特征较为明显。 3.4.1 实验设置 把标注好的1000 篇论文作为文本摘要的实验语料,将作者撰写的论文摘要作为自动摘要方法评估的金标准,使用评估包pyrouge①https://pypi.org/project/pyrouge/计算各语步自动摘要文本的ROUGE 值;编码实现各语步自动摘要文本多样性和可读性指标值的计算。选择经典的TextRank 模型[39]、Dong 等提出的HipoRank 模型[21]和Liang 等提出的FAR(functional-coefficient autoregressive)模型[23]这3 种无监督抽取式摘要方法进行自动摘要质量对比。 为了进一步客观地评估自动摘要的质量,随机抽取50 篇论文并邀请10 位生物信息学博士对4 种方法产生的论文自动摘要进行评价,每位博士参考15 篇论文的金标准摘要分别对本文方法生成的摘要进行人工评分,每篇论文由3 位博士评分。评分标准包括摘要的相关性、多样性和可读性,得分范围为1~5 分(1 分为最差,5 分为最好)。 3.4.2 结果与分析 不同方法下自动摘要文本的ROUGE-1、ROUGE-2、ROUGE-L 的F1值如表5 所示,大部分方法在语步上的ROUGEF1值基本遵循“方法>目的>结论>背景>结果”的规律。ROUGE-2 的F1值最低,其原因可能在于:文本长短对摘要性能的影响较大,相比于长文本,短文本更容易生成相关性大的自动摘要,且两个单词组成的词组被同时匹配的概率较低。本文方法的ROUGEF1值全面超过TextRank 和FAR 方法,但只在“目的”“方法”语步上高于HipoRank 方法。在其他语步上低于HipoRank 方法。其可能的原因在于:本文方法较关注句子整体特征,对句子的分析粒度较粗,忽视了句子的语义特征以及长距离句子之间的不同关联权重。本文方法不同语步间的ROUGEF1值差异较大,说明本文方法易受语料文本的长短和句法表达方式的影响。 表5 科技论文各语步自动摘要相关性计算结果(F1值) 不同方法下自动摘要文本的多样性和可读性度量值相关统计信息如表6 所示。在可读性得分上,HipoRank 模型得分最高,本文方法位于第二,TextRank 模型最低;在多样性得分上,本文方法和FAR 模型分别位于第一和第二,且本文方法的得分显著高于其他模型,HipoRank 模型最低。HipoRank模型在进行句子语义表征的同时,考虑了句子位置信息,能够更为准确地抽取摘要句;FAR 模型则考虑了句子-文档权重,从全局的角度抽取中心度高的句子;本文方法在不同语步文本中使用句子位置以及句子与文档相似度等多特征,在提升抽取相关性的同时,也提升了摘要句的多样性。实验结果表明,本文方法所产生的自动摘要可读性和多样性较为均衡,受益于语步识别之后再结合MMR 执行自动摘要,多样性得到了显著提升。 表6 科技论文各语步自动摘要多样性与可读性计算结果 不同方法下自动摘要文本的人工评分均值和方差值结果如表7 所示。在相关性评价结果上,本文方法低于HipoRank 模型,比FAR 模型略高;在多样性上,本文方法显著高于其他模型;在可读性上,本文方法接近于HipoRank 模型。由此可见,在语步文本的基础上,结合文本多特征进行自动摘要生成,能够提升摘要多样性,并在一定程度上同时提升了摘要的相关性和可读性。 表7 自动摘要人工评分均值(方差)结果 不同语步识别模型下自动摘要文本的ROUGE-1、ROUGE-2、ROUGE-L 的F1值如表8 所示,各种语步识别模型融合文本多特征的结构化自动摘要方法同样基本遵循“方法>目的>结论>背景>结果”的规律,且ROUGE-2 的F1值最低。本文提出的语步识别模型所形成的结构化摘要的ROUGEF1值在“背景”语步以外的其他语步上均表现最优,且所有语步识别模型所形成的结构化摘要在所有的语步上均的ROUGE 值均高于TextRank 和FAR 方法,但在“背景”“结果”和“结论”语步上低于Hipo-Rank 方法,上述实验的结果和分析得到了验证。但不同语步识别模型的ROUGE 值差异不大,结合表5可以发现,基于所有语步识别模型的摘要方法ROUGE 值和其他摘要方法相差较大,且结合表4 可以发现,不同语步识别模型的F1值差异较大。由此可见,相比于语步识别模型,文本特征的选择和融合在摘要相关性上具有更重要的影响。 表8 不同语步识别模型下科技论文各语步自动摘要相关性结果(F1值) 从科技论文移动阅读的需求出发,针对现有自动化摘要方法存在与论文原文相关性不高和内容涵盖范围不广的问题,本文在对论文全文进行语步识别的基础上,综合考虑句子位置、句子与文档的相似度等文本多特征实现不同语步文本的自动化摘要,以摘要文本相关性和多样性平衡以及可读性的原则最终生成科技论文的结构化摘要。通过融合语步识别、无监督文本摘要和语义分析等技术,拓展了自动结构化摘要的研究思路,丰富了摘要抽取的方法。本文使用规则匹配结合特征向量改进输入深度学习模型的方法实现了科技论文全文的语步识别,采用句子位置、句子与文档相似度等文本多特征融合的方法优化TextRank 算法,使用MMR 算法去除了摘要句的冗余,通过依存句法分析简化了摘要句的表述,最终把不同语步的摘要内容组合生成了结构化摘要。研究结果表明,本文方法在不同语步的相关性、多样性和可读性指标提升上具有一定的差异;结合人工评价发现,本文方法在显著提升摘要多样性的同时,在一定程度上提升了摘要的相关性和可读性,能够自动提供科技论文全文的结构化摘要,促进移动读者快速了解和掌握论文的核心内容,有助于缓解“信息过载”现象。 本文提出的摘要方法忽略了全文中图和表的内容,而这些内容往往包含了关键知识。此外,本文在摘要句抽取任务中还存在优化空间。因此,后续工作主要包括两个方面:首先,在全文语步识别过程中,提取图和表的内容,以识别其中重要的知识实体,并生成相应的摘要;其次,在摘要句抽取过程中,关注句子语义特征的表示,并考虑句子全局上的关联,从而进一步提升摘要相关性,降低摘要受语料文本长短和表达方式的影响。
2.3 科技论文语步识别
2.4 多特征融合的科技论文摘要生成
3 实验与讨论
3.1 数 据

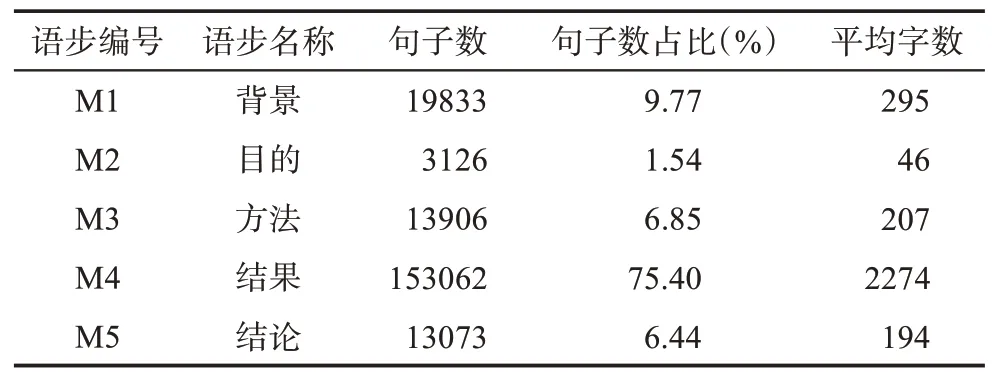
3.2 评价指标
3.3 科技论文语步识别实验

3.4 科技论文语步文本摘要实验

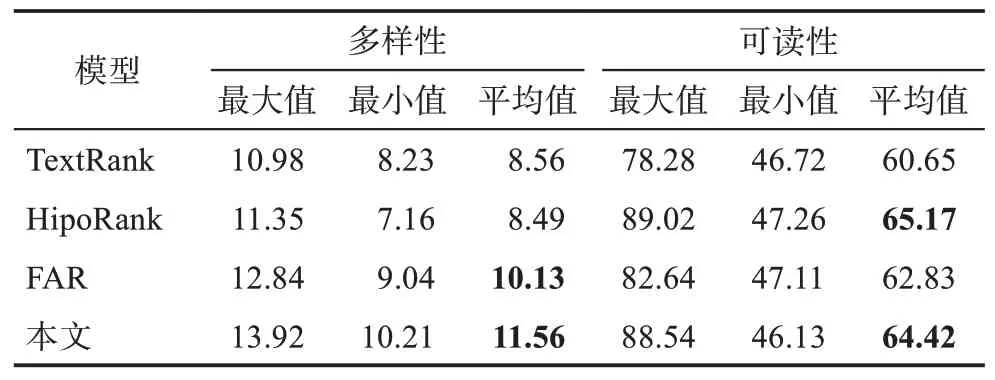
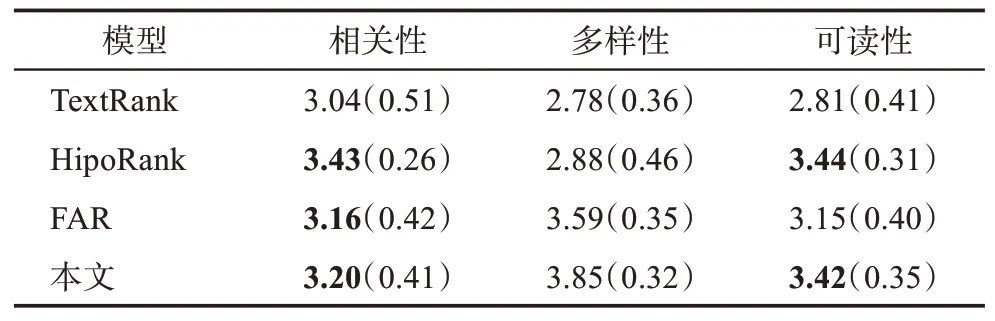
4 结论与展望
