科研兴趣空间挖掘与多任务推荐研究
——基于异质信息网络表示学习
2023-11-21崔鸿飞冯子函张靖雨
崔鸿飞,冯子函,张靖雨
(1. 北京科技大学经济管理学院,北京 100083;2. 北京航空航天大学经济管理学院,北京 100191;3. 爱丁堡大学商学院,爱丁堡 EH8 9JU)
0 引 言
随着科研进程的不断推进与发展,研究人员间的科研活动日趋复杂化、多样化,获得一项科研成果往往需要不同研究方向的研究者密切合作[1],以及从不同研究主题中获取新的灵感[2]。然而,由于各领域研究者不断增多,潜在的合作者变得越来越多,随着学术问题的研究日趋深入,研究者所面临的知识爆炸问题也日趋严重。在这种情况下,研究者难以在有限的时间中,对自己领域内外的潜在合作者和研究灵感进行全面了解。
与此同时,随着信息技术的发展,互联网上涌现了许多优秀的科研文献数据库,如美国科学信息研究所创建的多学科核心期刊文献数据库Web of Science (www.webofknowledge.com)、美国国立医学图书馆国家生物技术信息中心的医学文献数据库PubMed(http://www.ncbi.nl.nih.gov/pubmed)等,收录了其关注的各个领域的大量研究成果。这些成果主要以论文形式展示,囊括了作者的合作关系、作者对关键词的选择等大量科研行为。合理利用这些科研行为信息,个性化地提供潜在合作者和研究灵感的推荐列表以供筛选,对研究者来说,不仅可以有效地节约时间,更可以使其科学研究道路更具有方向性。
对科研论文中的科研行为信息进行挖掘,一种比较常见的做法是将大量论文中蕴含的科研关系抽象成同质(homogeneous)[1,3-4]或异质(heterogeneous)信息网络(information network)[5-7],各种科研主体(如作者、关键词等)被抽象为网络中的节点,对象间的各种联系(如合著关系)被抽象成网络中的边。这种网络化处理方法已经被广泛应用于科研关系分析及推荐任务的研究中,并在数据整合、数据挖掘、科研合作关系理解、科研个性化推荐研究等方面做出了重要贡献(详见下文“相关研究”)。然而,这类研究往往具有两个特点:其一,现有研究往往更关注科研共著关系(或科研合作者推荐),忽略了科研兴趣方向推荐任务的研究;其二,现有研究往往基于同质信息网络,忽略了作者与机构之间的从属关系、作者与文章关键词之间的学科领域与科研兴趣关系当中蕴含的巨大信息量。在最新的一些研究中,已经有学者开始关注并分析异质信息网络[5-7],但这些研究引入异质性的普遍目标依然是科研合作者推荐任务,或者即使涉及关键词推荐,也缺乏对关键词推荐正确率的量化分析。而完全从异质性视角出发,分析作者与关键词之间的关系,并为科研人员提供有效的关键词推荐列表,激发科研人员的研究灵感,是非常重要且至今尚缺乏深入研究的主题。
在关键词推荐和合作者推荐的双任务推荐背景下,本研究希望探讨与同质信息网络表示的视角相比,基于异质信息网络的节点表示与推荐方法是否更加适用。为此,本研究基于PubMed 文献数据库,选择当前研究热点之一,即生命组学及医学相关的机器学习、深度学习领域,分析科研工作者之间以及科研工作者与领域关键词之间的关系,同时解决合作者推荐与研究兴趣推荐两大任务。基于该领域2010—2021 年发表的13 万篇论文,本研究滤除仅出现1 次的作者与关键词,筛选出1.1 万篇适合进行科研合作者及关键词预测的文献,从异质性视角将文献抽象成为包含作者、机构、关键词、论文多种主体的“科研异质信息网络”,并使用异质信息网络表示学习算法metapath2vec 进行网络节点嵌入,生成一个同时对作者与关键词进行语义化向量表示、充分体现作者研究兴趣的异质科研兴趣空间,进而基于该异质科研兴趣空间同时完成科研合作者与科研关键词推荐两种任务,在两种任务中均获得更优的表现。此外,本研究的关注点不仅在于推荐任务,还对网络分析过程中生成的异质科研兴趣空间中蕴含的丰富语义信息开展进一步挖掘和研究,以证明该兴趣空间对表示科研人员潜在研究方向的有效性,并在科研领域交叉与关联的理解中提供启发性方向。
1 相关研究
1.1 基于经典网络视角的科研推荐研究
“科研推荐”是存在于两个科研主体(如作者、关键词、机构、期刊等)间的推荐任务的统称,其背后包含了各种具体的推荐任务,如本研究主要关注的科研合作者推荐、科研关键词推荐等。在网络视角下,科研推荐的本质是一种链接预测(link prediction),当模型预测两个科研主体在网络中有大概率产生联系时,其中一个科研主体就会被推荐给与之匹配的另一个科研主体。
现有关于“科研推荐”的研究主要集中于科研合作者推荐,“科研网络”是执行这一推荐任务的主要载体。比如,张金柱等[1]构建了作者-关键词二分网络,并使用基于路径组合的网络指标与逻辑回归进行了科研合著预测;刘萍等[8]、关盼盼[9]以社交网络理论为基础,在作者关系的研究中引入隐含狄利克雷分布(latent Dirichlet allocation,LDA)来刻画作者的研究兴趣,进而实现科研合作者的推荐;余传明等[3]、Yan 等[10]、吕伟民等[11]、秦红武等[12]在作者合著网络的分析中应用了链接预测的特征指标,如Adamic-Adar index(AA)、common neighbors(CN)、Katz indices(Katz)等,其中,吕伟民等[11]、秦红武等[12]分别将极端随机树、k-means 算法与这些指标结合,余传明等[3]将基于路径的与基于邻居的网络特征指标彼此间融合,以“特征融合”为基本思路完成科研合作推荐的任务。
上述研究的共同特点是基于网络结构指标特征,结合统计学习理论建立模型,实现对网络链接关系进行预测的目标。这种方式非常依赖于模型开发者对网络的理解和对特征的选择经验,同时对于大规模数据集,这种传统的网络分析方法对计算力的要求非常高。随着深度学习领域研究的创新与突破,网络表示学习逐渐在科研推荐任务中得到越来越广泛的应用,这种方法直接通过模型训练从原始数据中自动提取特征,避免了对模型开发者经验的过度依赖;同时,在大规模网络的计算方面,往往可以比传统网络分析方法具有更优的速度,因此,在科研推荐研究中逐渐开始扮演重要角色。
1.2 基于网络表示学习的科研推荐研究
网络表示学习(network representation learning)是表示学习(representation learning)方法的一个重要分支。相关实验已经证明,将网络表示学习算法应用于链路预测等下游任务中,其表现往往优于一些基于指标计算的传统算法,在SDNE(structural deep network embedding)[13]与node2vec[14]等研究中皆可体现。随着深度学习技术的不断发展,这种以数据隐式特征提取为思路的研究方法,被广泛应用于科研行为数据的分析中。
在这些基于网络表示学习的科研推荐研究工作中,学者们往往先构建以推荐主体为节点的科研网络,再利用各种网络表示学习方法对网络主体进行向量化表示。例如,张金柱等[1]使用网络表示学习算法在合著网络中对作者向量进行表示学习以完成科研合作预测任务;余传明等[4]将不同网络表示学习算法下的作者向量表示进行了加权平均融合,并基于此构建科研合作推荐模型;张鑫等[15]将网络表示学习算法生成的作者节点嵌入与基于作者主题模型生成的作者主题向量表征进行线性特征融合,用于作者合作预测。上述研究的相似点在于它们的同质性视角:在这些研究中,被进行表示学习的网络都是科研合作网络,或称“共著网络”,其本质是一种仅包含作者节点,并以作者合作关系为边的同质信息网络。因此,上述研究中所利用的网络表示学习算法都属于同质信息网络嵌入方法,如Deep-Walk、node2vec、LINE (large-scale information network embedding)、SDNE 等。
事实上,在科研关系预测问题中,同质的作者合作关系仅是丰富科研行为信息中的冰山一角。一个直观的灵感是,如果把作者与研究机构的从属关系、作者对关键词的选取关系等信息融入网络进行挖掘,在科研关系预测中可能会获得更好的效果。随着网络表示学习方法的不断发展,异质信息网络表示学习方法越来越成熟,学者们对科研网络的构建与分析,自然而然地转向了异质信息网络表示学习方法。刘云枫等[5]在网络构建时引入作者、关键词、机构、论文、出版物多种主体,提出了一种基于不同元路径的多关系映射方法以获取表示学习的语料库;王鑫[7]在异质信息网络构建的基础上,提出了一种基于属性网络表示和主题感知的学术合作者推荐(topic-aware academic collaborator recommendation based on attributed network representation learning,TACR-ANRL)算法。这些研究通过在网络中引入异质信息,对作者向量给出了更精准的表示,从而获得了更优的合作者推荐结果。在本研究关注的另一个重要推荐任务即关键词推荐方面,相关研究非常缺乏。其中一项优秀的先驱性研究来自林原等[16],该研究将作者、地址、关键词3 种信息用于构建科研异质信息网络,利用node2vec 方法进行网络嵌入后,为科研工作者推荐了合作者、机构与关键词。在这项研究中,虽然科研网络为异质信息网络,但图嵌入算法依然为同质信息网络表示学习算法,这种方式是否能充分发挥异质信息网络的异质性优势,有待进一步讨论。同时,这项研究并未设计相关指标对合作者与关键词的推荐正确率进行评估。这些方面非常值得进一步探索。已有很多网络表示学习算法,如经典的以随机游走为基础的metapath2vec[17]和在其基础上从不同角度改进的spacey[18]、 JUST[19]、 BHIN2vec (balanced heterogeneous information network to vector)[20]、HHNE(hyperbolic heterogeneous information network embedding model)[21]等,以矩阵分解为基础的PME(projected metric embedding model)[22]、 EOE (embedding of embedding)[23]等,以及近年来不断涌现的深度学习方法GATNE(general attributed multiplex heterogeneous network embedding)[24]、 MAGNN (metapath aggregated graph neural network)[25]、HGT(heterogeneous graph transformer)[26]等,这些算法均能够应用于异质信息网络表示学习,其中部分算法被证明在一些作者合作网络的链路预测任务中可以获得良好效果[17,27-28]。基于这些算法,本课题组的一项预研究工作[29]验证了基于metapath2vec 的网络表示学习方法,所得到的作者与其所发表过的关键词之间的平均距离显著低于该作者与随机选择的关键词之间的距离,这为本研究的双目标推荐系统提供了充分的可行性依据。
此外,尽管网络表示学习的方法有效地提升了科研推荐任务的效果,但对科研主体嵌入表示结果的解释和分析研究仍较为缺乏。从向量空间中深入分析同质或异质科研主体之间的位置和聚集关系,尤其是关键词空间或关键词相关的作者空间的分析,会为理解科研工作者视角下的领域定位、领域之间相关性与领域差异,提供丰富的可解释性资源。因此,本研究不但在异质信息网络构建、网络表示学习算法使用、推荐模型构建与评估等各方面进行了更深一步的探索,而且完成了科研合作者与科研兴趣推荐的任务,并对嵌入的向量空间进行了全局与个体视角的深入可视化分析。这些工作将为现有的科研推荐研究工作提供新的分析角度,研究结论也将为科研人员理解领域交叉、寻找新的研究方向提供灵感。
2 研究思路和方法
2.1 研究思路
本研究的整体思路如图1 所示。本研究聚焦于生命组学及医学相关的机器学习、深度学习大领域,收集了2010—2021 年发表的13 万篇科研论文,并根据数据记录质量、作者出现次数等标准(详见3.1 节),从中筛选出1.1 万篇,构成适合进行科研合作者及关键词推荐的科研数据集。基于作者、机构、关键词、论文信息,为了说明异质视角处理科研关键词及合作者推荐任务时相较于传统同质视角的效果差异,本研究构建了基于科研行为的异质信息网络(简称“异质科研行为信息网络”),并使用经典的异质信息网络表示学习算法metapath2vec学习这些科研主体在异质信息网络所抽象的科研行为背后的语义信息,得到作者、机构、关键词、论文4 种科研主体的向量表示。根据metapath2vec 算法的特性,上述4 种向量可以在同一个空间进行分析,本研究称之为“异质科研兴趣空间”,在此空间中,距离的远近表示同质或异质主体之间的相关程度,利用这种特性,分别计算不同科研主体的向量表示之间的相似度,并基于该相似度完成科研推荐任务;同时,针对该情景定义相应的评价指标,对推荐结果的正确率进行评价。
本研究的推荐任务包括科研合作者推荐和关键词推荐。考虑到推荐任务的一致性,本研究选取了现有研究中同时涉及这两项任务的林原等[16]的研究作为对比基线方法,该方法采用同质信息网络表示学习方法对异质信息网络进行分析,在合作者与科研关键词方面均给出了参考性的推荐结果。进一步将该结果的正确率指标化(详见2.5 节),并将其与本研究的推荐结果进行比较。此外,本研究的数据集规模较为庞大(训练集共3.9 万个节点),考虑到基线方法原始选取的同质信息网络表示学习方法node2vec 在大型数据集上所需内存极大,运行时间长,在实际应用中的计算效率受限,本研究采用速度更快、更适合大型数据集[30],且正确率表现不亚于node2vec[17-18,31-32]的方法LINE 作为替代,用于分析在异质信息网络的节点表示方面,异质信息网络表示学习算法相较于同质信息网络表示学习算法的特性。
2.2 异质科研行为信息网络的建立与嵌入
2.2.1 异质科研行为信息网络的建立
本研究构建的异质科研行为信息网络GHeter,包含的节点种类集合为TV={A,K,P,O},A、K、P、O分别代表作者(author)、关键词(keyword)、论文(paper)、机构(organization)4 种网络节点;包含的边种类集合为TE={(O,A),(A,P),(P,K)},(O,A)、(A,P)、(P,K)分别代表作者相对于机构的从属关系、作者相对于论文的发表关系、论文相对于关键词的包含关系3 种边。异质科研行为信息网络中节点与边的具体抽象方式如图2a 所示。
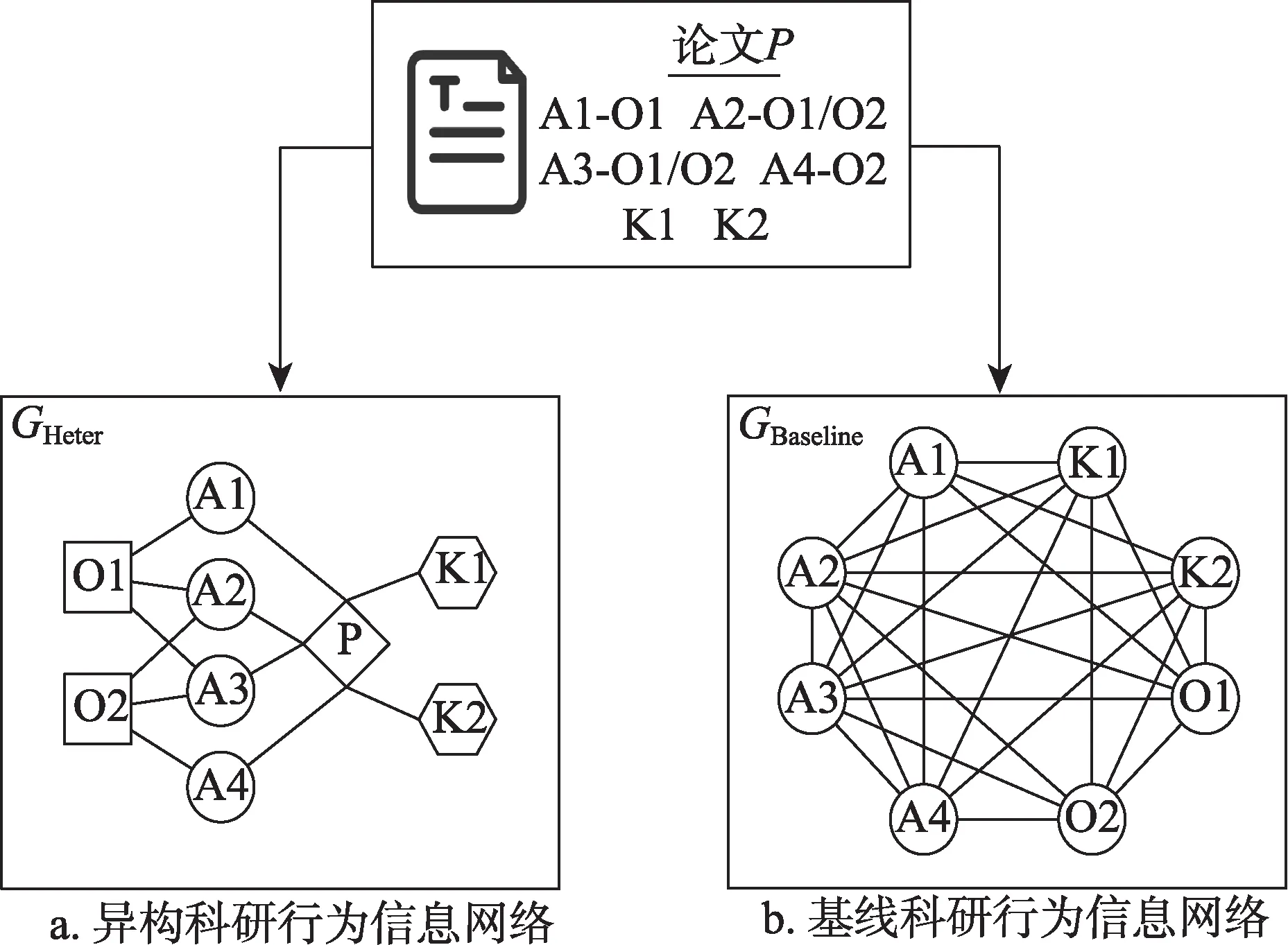
图2 科研行为信息网络构建方法
值得注意的是,该网络为无向网络,且作者A与机构O节点间通过边(O,A)直接相连;本研究在作者A与关键词K这两类节点间引入了论文P,并使用边(A,P)和(P,K)相连两者。一方面,相比于将作者A与关键词K通过边(A,K)直接相连,这种做法能够显著减少边的条数;另一方面,能更好地还原关键词与作者在现实语义上的联系。
2.2.2 异质信息网络表示学习与元路径
本研究选择了一种基于网络结构的异质信息网络表示学习算法——metapath2vec,用于尽量完整地表征网络结构。该算法在异质信息网络中使用元路径引导的随机游走策略来捕获不同类型节点和关系的结构以及语义相关性,然后利用针对异质节点的skip-gram 模型执行网络嵌入。该模型在提出时已经被证明当其用于一个计算机领域会议论文科研数据集时,可以有效地挖掘会议之间的联系,并能在一定程度上反映作者之间的研究方向关联(虽然该研究并未展示其在作者合作关系与关键词兴趣方面的挖掘效果)。
在metapath2vec 算法中,采样时的随机游走需要根据指定的元路径(meta-path) 进行[17],其中“元路径”
被定义在一种固定的R=R1◦R2◦… ◦Rl-1复合关系上,用于拓展网络节点之间的语义关联。本研究参考了一种常被应用于科研主题数据集如DBIS(database and information system)[33]、AMiner[34]等的有效元路径方案,并结合异质科研行为信息网络中的节点和节点间的语义关系,定义了元路径“OA-P-K-P-A-O”用于指导算法采样时的随机游走。该条元路径包含了网络中的所有类型节点,在随机游走过程中能够直接采样作者对关键词的使用关系(体现在A-P-K与K-P-A)。此外,还包括作者与机构的从属关系(体现在O-A与A-O)、作者与作者因关键词兴趣而产生的关联(体现在A-P-K-P-A)等各类联系。使用这样的元路径能够将更多的语义融合于算法生成的嵌入向量中,从而在下游任务中实现更可靠的关键词与合作者推荐。
2.3 基线方法中的科研行为网络建立与嵌入
基于林原等[16]研究中的网络构建方式与网络表示学习思维,本研究将相同的科研行为数据建立成为基线科研行为网络GBaseline。在该网络中,节点种类依旧包括作者(A)、机构(O)、关键词(K),边则刻画了作者间的合作关系(author-author,AA)、作者相对于机构的从属关系(author-organization,A-O)、作者相对于关键词的使用关系(author-keyword,A-K)、机构间的合作关系(organization-organization,O-O) 以及机构相对于关键词的使用关系(organization-keyword,O-K)。基线科研行为网络中节点与边的具体抽象方式见图2b。
根据基线算法的原设计,本研究采用同质信息网络表示学习方法对基线科研行为网络GBaseline中的节点进行嵌入表示。考虑到对大型数据集的适配,本研究使用同质信息网络表示学习方法LINE 替代原基线算法设计中的node2vec(详见2.1 节),用于探索利用基于同质的方法处理异质信息网络时会发生的现象。LINE 算法使用KL (Kullback-Leibler)散度作为损失函数,计算节点相似度在向量表示下的概率分布与实际网络中的经验分布之间的差异,并经过优化获得每个节点的低维向量表示。
2.4 科研主体间的相似度计算方法
得到作者、关键词等科研主体的向量表示后,本研究通过向量间的相似度来表征不同科研对象间的“距离”,相似度越高,表示两个对象在异质科研兴趣空间中的距离越近,越可能存在潜在的关联。本研究选择余弦相似度作为向量间的相似度的度量。向量X=(X1,X2,…,Xn)与向量Y=(Y1,Y2,…,Yn)间的相似度sim (X,Y)的计算公式为
其中,向量X与向量Y可以是同类型的科研主体,如作者向量Ai与作者向量Aj;也可以是不同类型的科研主体,如作者向量Ai与关键词向量Kj。具体的科研主体类型由推荐任务本身的需求决定。
2.5 推荐模型及其评价指标
本研究是双任务目标,即可以同时完成科研关键词推荐和科研合作者推荐。为了在推荐任务中充分为用户提供新信息,本研究以科研主体间的相似度为标准,在筛除用户已经使用过的关键词或已经合作过的作者后,再进行top-n推荐。在科研关键词推荐任务中,本研究为作者推荐其在异质科研兴趣空间中最接近(即向量相似度最大)的且未使用过的n个关键词。类似地,在科研合作者推荐任务中,与被推荐作者向量相似度最大的n个未合作过的作者将被推荐。
在评价指标方面,由于科研推荐任务与很多其他领域(如电影推荐等)的推荐任务有相通之处,本研究参考了电影推荐场景中衡量推荐效果的指标[35],利用“用户命中率(hit user proportion,HUP)”来描述在未来一段时间(即测试集时间范围)内使用了模型推荐的关键词或合作者的作者比例,计算公式为
其中,U表示测试集中的作者总数;Ii表示第i名作者在测试集中是否使用了模型推荐的关键词或合作者,若使用过,则Ii= 1,否则,Ii= 0。HUP 指标能够描述推荐列表在现实中将为多大比例的作者提供帮助,HUP 值越大,表示推荐的效果越好。
3 实验与分析
3.1 数据获取与预处理
本研究使用的数据集来自生物医学和健康科学领域的PubMed(https://pubmed.ncbi.nlm.nih.gov/)数据库,它是当今国际最权威的医学文献数据库之一Medline 的免费检索工具,由美国国立医学图书馆开发,也是生物医学及健康领域使用最广泛的互联网文献检索工具。近年来,深度学习方法发展迅猛,在生物与医学领域也产生了深刻的影响。同时,PubMed 还有一套非常全面且规范的主题词表(medical subject headings,MeSH),其将论文中可能出现的各种科研概念的书写形式进行了严格的控制和规范,并对每一篇论文进行了主题词标注,可以认为,PubMed 数据库中的MeSH 主题词比作者在撰写论文时标注的关键词更加全面、规范和准确,因此,采用MeSH 主题词作为关键词的代表。本研究下载了2010 年1 月1 日至2021 年2 月28 日发表的所有深度学习、机器学习相关的主题论文,检索式为“(deep learning) OR (machine learning) OR (neural network)”,共下载131691 篇。
由于文化原因和语言习惯,英文姓名往往存在着大量重名。为了明确区分同名作者,避免在研究中将不同的科研实体混淆,本研究使用作者所属机构字段对作者姓名进行了消歧处理[29]。简而言之,若两篇论文中某两名作者所留姓名相同且其所属的若干机构中存在相同所属机构,则这两名作者将被视为同一个作者,并使用相同的作者ID 进行标识。
鉴于各文献所属期刊的记录习惯不同,为了按照统一的时间字段划分数据集,本研究选取相关文献数最多的时间字段,即PubMed 收录时间,作为划分训练集与测试集的标准。共有108477 篇论文拥有此字段,其中2010—2019 年发表的论文77467篇,2020 年及以后发表的论文31010 篇。训练集为构建异质科研行为信息网络和后续分析科研兴趣空间的基础。由于关键词推荐是本研究的重要目标之一,在进行数据清洗过程中,本研究将没有关键词字段的论文直接剔除。同时,由于仅出现一次的作者节点和关键词节点在网络中无法起到链接不同论文的作用,也无法用于推荐正确率的测试,无法提供额外的语义信息,因此,本研究对作者与关键词的累计出现次数进行了筛选,将所有只出现一次的作者与关键词剔除。清洗后的训练集剩余10670 篇论文。在测试集中,为了充分测试为已有论文发表的研究者推荐关键词或合作者的效果,本研究仅保留在训练集中出现过的作者和与其相关的机构、关键词、论文数据,清洗后的测试集剩余485 篇论文,其与清洗后的训练集共同组成适合进行科研推荐研究的高质量数据集。最终数据集情况如表1所示。
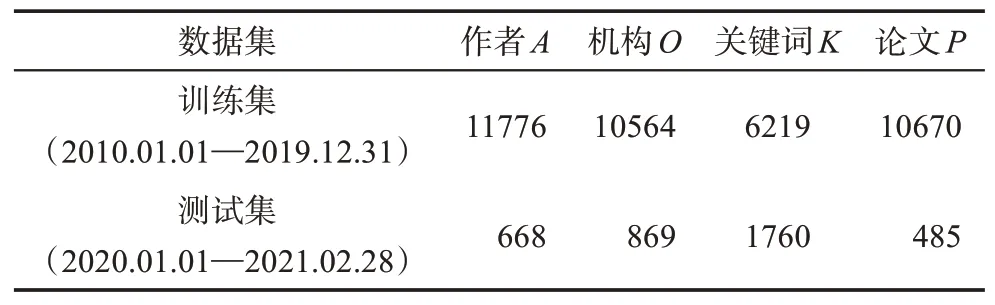
表1 数据集情况
3.2 推荐模型评价
为评价本研究方法的推荐效果,从两个角度对模型进行评价。从定量角度,基于上述以2020 年1月1 日为界的训练集和测试集,利用训练集的数据进行表示学习,并在测试集中验证推荐效果,通过与基线方法的效果进行比较分析,来说明本研究方法的优势和可靠性。从定性角度,在推荐结果中随机选取了一些案例,对照测试集中的真实数据,用于对模型效果进行更形象和具体的说明。
3.2.1 定量评价指标
基于预处理后的训练集,分别采用本研究方法(详见2.2 节)与基线方法(详见2.3 节)构建异质科研行为信息网络GHeter与基线科研行为网络GBaseline,并分别进行节点嵌入表示,最终得到两个不同的向量空间。本研究分别基于这两个向量空间,按照向量相似度指标从高到低排序,进行合作者与关键词的top-n推荐(详见2.4 节),并剔除训练集中已经与被推荐作者产生过联系的推荐对象,对两种方法分别计算用户命中率(HUP)(详见2.5节)。科研合作者与关键词推荐的top-10、top-20、top-50 和top-100 推荐结果如表2 所示。由于本研究方法使用的metapath2vec 与基线方法使用的LINE 在嵌入表示时均具有一定的随机性,为避免因单次实验结果的浮动而导致对比不公平,本研究将实验重复5 次,表2 所示为所有实验结果的平均值。
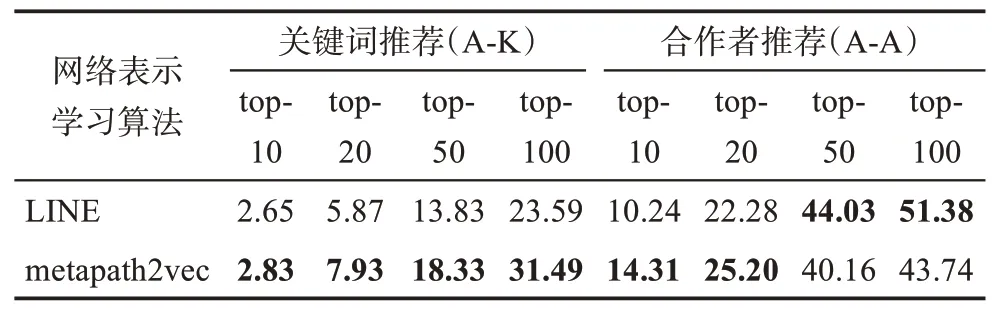
表2 推荐模型的HUP对比 %
结果表明,在关键词推荐任务中,本研究方法在所有推荐级别的用户命中率均高于基线方法,尤其是在top-20 以上的推荐级别,本研究方法的效果有非常明显的优势,均有约1/3 的提升。在进行top-100 推荐时,本研究方法的用户命中率可达31.49%;而由于本研究方法仅推荐了用户没有使用过的关键词,这意味着浏览本研究方法的推荐列表将为近1/3 的用户提供新的灵感。
在合作者推荐任务中,本研究方法并非在所有情况下都优于基线方法。在进行top-10 与top-20 级别推荐时,本研究方法表现优于基线方法,分别改善39.75%和13.11%;而在进行top-50 与top-100 级别推荐时,用户命中率较基线方法略低,分别下降8.79%和14.87%。尽管如此,依然可以看到,本研究方法倾向于把对用户信息量最大的结果集中在头部,在选取较小的推荐数量时,即可展现出较为优越的推荐效果,这种情况在top-10 级别时现得尤其明显,提升近40%。
由表2 可以看到,与基线方法相比,本研究方法在合作者推荐方面能获得同样理想的结果,并且更倾向于把有效结果集中在头部推荐结果中;在关键词推荐方面,本研究方法则具备极大的优势,改善效果十分明显。值得深思的是,在本研究方法构建的异质科研行为信息网络中,作者节点A与关键词节点K并没有直接相连;反而在基线方法的科研行为网络构建中,作者节点与关键词节点被直接连接。相较于两种节点直接相连的基线方法,没有直接相连的异质科研行为信息网络在进行嵌入表示后所得到的作者向量A与其关键词向量K之间相似度更高。其中的主要区别是,在基线方法中,虽然目标网络是异质信息网络,但网络嵌入方法是基于同质的方法,导致异质节点被当作同质节点进行嵌入表示,失去了异质节点之间本来的语义信息;而本研究充分考虑到这一点,通过异质信息网络嵌入方法充分挖掘异质科研主体之间的语义相关性,在为作者推荐关键词这种异质性推荐任务中,获得了非常明显的优势。
此外,为了衡量推荐模型的稳定性,本研究还计算了5 次重复实验中HUP 值的方差,结果如表3所示。可以看到,本研究方法中的模型在两种推荐任务的各个推荐级别中,方差均小于基线方法,尤其在合作者推荐方面更为明显,可以认为基于异质信息网络嵌入表示的推荐模型具有更优的稳定性。
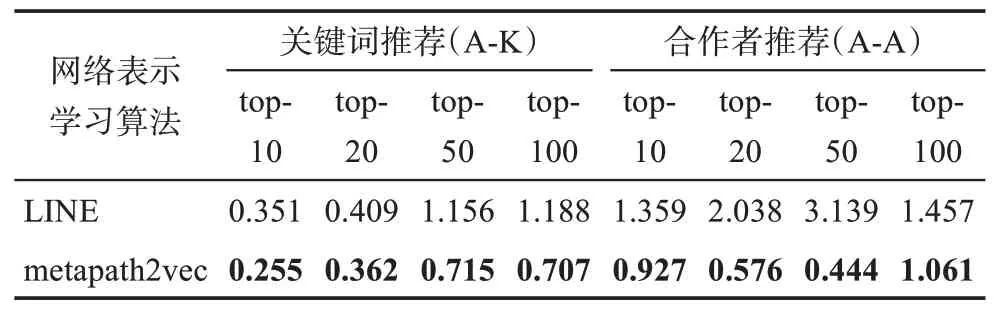
表3 推荐模型的稳定性对比 %
3.2.2 定性推荐案例
在真实的合作者推荐任务中,对于推荐清单中的潜在合作者,科研人员需要从论文、学术关系方面对被推荐者进行了解,并通过邮件、会议等渠道进行充分沟通,才会真正产生合作意向,因此,合作者推荐的清单宜少而精(如10 人)。因此,选取了3 个有代表性的top-10 合作者推荐案例,用于说明本研究方法的推荐效果,如表4 所示。
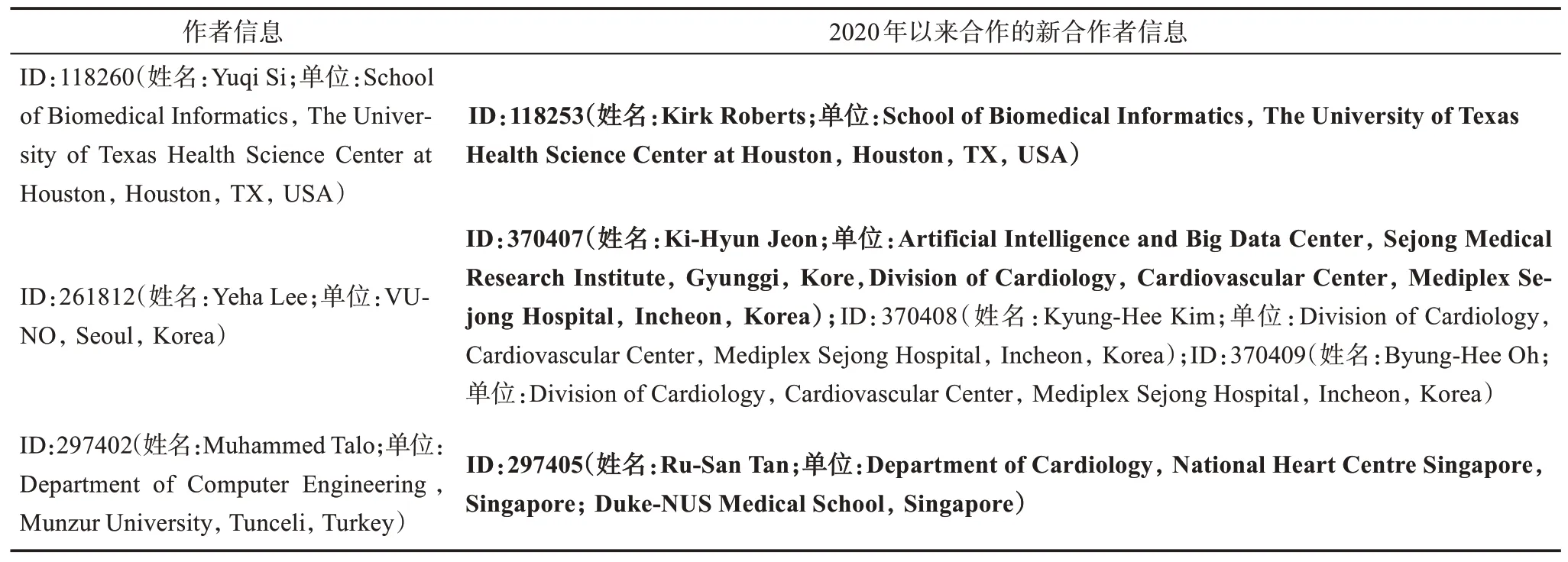
表4 合作者推荐结果举例
表4 展示了相同单位、相同国家不同单位、不同国家不同单位3 种合作者推荐的情况。对于一些研究方向较为集中的单位,同一领域的研究者通常人数较多,相互之间学术交流较为充分,学者之间的表示向量往往更加相似,因此,在top-10 合作者推荐时,更容易推荐本单位的研究者。例如,美国德克萨斯大学健康科学中心生物医学信息学院的Yuqi Si,被预测成功的是来自他同单位的合作者Kirk Roberts,这也是他在测试集中的唯一新合作者。Kirk Roberts 曾与同单位的另一学者Hua Xu 以共同通信作者的方式合作发表文章,而Yuqi Si 则曾经参与过Hua Xu 的其他文章工作。此后,以Yuqi Si 为第一作者、Kirk Roberts 为通信作者的方式展开了合作。此外,本研究方法也会对不同单位的研究人员进行有效的推荐。例如,来自韩国VUNO 公司的Yeha Lee,2020 年以来共有3 位新合作者,均来自韩国世宗医院,其中Ki-Hyun Jeon 被本研究算法预测成功。虽然以前从未合作过,但他们有一个共同的合作者,来自韩国世宗医院的Joon-Myoung Kwon。来自不同国家的研究者也会被推荐,如Muhammed Talo 来自土耳其Munzur 大学的计算机工程系,其测试集中的唯一新合作者被本研究方法预测成功,新合作者是新加坡国家心脏中心的Ru-San Tan。这两位研究者虽然以前从未合作过,但他们都各自与对方单位的其他研究人员进行过合作。可以看到,在本研究模型对潜在合作者的推荐过程中,有效抓取了作者以往合作关系网络中蕴含的信息。
在关键词推荐任务中,目标是为科研工作者提供潜在的兴趣方向。在此场景下,科研人员往往通过自身的研究经验和适度的相关文献查询,即可从推荐的关键词列表中提取自己真正感兴趣的主题。因此,用户对关键词推荐列表的信息处理成本较低,可以推荐较多关键词(如50 或100 个)供用户参考。
表5 展示了随机选取的3 个top-50 关键词推荐案例。Robert Whelan 来自爱尔兰都柏林圣三一大学,本研究方法为其推荐成功的关键词为“冲动行为/生理学”,这个关键词在其训练集数据中并没有字面上非常贴近的表述,3 个比较接近的关键词为“前额叶皮层/诊断成像/生理病理学”“延迟贴现/生理学”和“新纹状体/诊断成像和生理病理学”,因为大脑前额叶皮层受损会导致冲动控制能力降低,纹状体也和冲动行为的可能性成正相关,而延迟折扣则是研究冲动行为的重要视角之一。这说明本研究模型可以从医学语义方面对关键词进行理解并推荐。同时,推荐列表中的一部分其他关键词也与Robert Whelan 在测试集中使用的新关键词高度相关,如“神经网络/诊断成像/生理学/生理病理学”“功能神经成像/方法”“心理/生理学理论”等,分别与作者实际的“神经网络/诊断成像/生理学”“功能神经成像”“心理/生理学”等非常接近。另外,两位研究者获得的关键词推荐列表也有类似现象。例如,美国斯坦福大学计算机科学系的Jure Leskovec,除推荐了与实际使用“RNA 序列分析”“RNA/遗传学”等高度相关的关键词“序列分析”“RNA/方法”“外显子”以外,还推荐了与骨关节炎在医学上高度相关的“树突状细胞/免疫学”“T淋巴细胞亚群/免疫学”等,而这些在训练集上并无直接关联的关键词,应是综合研究者的合作关系与关键词使用综合推荐的结果;日本大阪大学医学研究生院眼科的Atsuya Miki,在命中“青光眼、开角/诊断成像/生理病理”等关键词之外,还推荐了大量直接包含“青光眼”的关键词,这些应是通过与训练集中的“眼内压/生理学”和“房角镜检查”在医学语义上的相关性进行推荐的。由此可见,在本研究方法的关键词推荐过程中,确实能基于医学语义相关性进行有效的推荐。

表5 关键词推荐举例
3.3 异质向量空间的语义分析
上述实验结果证明,本研究方法具有更好的推荐效果,其核心在于使用异质信息网络表示学习算法metapath2vec 生成的异质向量空间(异质科研兴趣空间),这个空间可以同时表示作者之间、关键词之间以及作者与关键词之间富含语义相关性的丰富信息。为了呈现这种语义相关性,本研究重新使用全部数据集,刨除没有关键词字段的论文以及仅出现一次的作者节点和关键词节点后,构建异质科研兴趣空间,并对其中包含的关键词向量与作者向量分别进行可视化与语义分析。本研究使用t-SNE(t-distributed stochastic neighbor embedding) 算法,将关键词向量与作者向量同时映射到二维平面,并结合关键词与作者的特点,进行可视化及相关讨论。
3.3.1 关键词向量空间
本研究涉及的所有关键词在异质科研兴趣空间中的低维分布如图3 所示。可以看到,尽管各关键词向量广泛分散于整个向量空间中,其局部依然展示了非常明显的聚集现象。语义相近或逻辑相关的关键词会聚集分布在近似的区域,即关键词向量具有“语义聚集”的特点。例如,在图3 中,空间第二象限框出的几个关键词均倾向于与“空气污染(air pollution)”话题相关,这个区域除该关键词本身,还包括“空气污染物/分析(air pollutants/analysis)”“颗粒物(particulate matter)”“二氧化氮(nitrogen dioxide) ”“气溶胶/分析(aerosols/analysis) ”以及“气象学(meteorology)”等。有趣的是,“早产/化学诱导(premature birth/chemically induced) ” 和“环境暴露(environmental exposure)”等关键词也在此区域内。事实上,环境暴露主要是指以各种形式接触环境中的污染物,而空气污染是最普遍、影响最广泛的暴露因素之一。近年来,随着国内外科学界对空气污染的关注,在空气污染暴露与妊娠结局相关性方面,涌现了越来越多的研究,其中包括空气中各类污染物对早产的影响。在关键词空间的其他区域,也存在着这样表面看似不相关,却在科学研究中联系密切的关键词语义聚集现象。比如,空间最右侧框出的“农作物育种”区域,尽管大部分关键词都和农作物种子的分类与培育直接相关,如“种子/分类(seeds/classification) ”和“发芽(germination)”等,但同时也存在着“高光谱成像(hyperspectral imaging)”这样表面上无关,但在科研语义上高度相关的关键词,这是因为高光谱成像可以在分析种子活性、活力、潜在缺陷、净度等问题上发挥巨大作用。

图3 关键词空间
为了进一步研究局部区域中关键词远近分布的细节特性,本研究选取了图3 右上侧作为示例区域并进行局部放大,研究各个关键词向量的词义和位置(图4a)。该区域明显与遗传发育相关,除了包括“大脑皮层/细胞学/生长发育(cerebral cortex/cytology/growth & development) ”“哺乳动物胚胎(embryo, mammalian)”这种细胞发育和分化研究中常见的目标细胞类型,还有研究细胞发育与分化时所使用的常见手段,如“基因表达/生理学(gene expression/physiology)”“发育中的基因表达/生理学(gene expression regulation, developmental/physiology)”,也包含了各种蛋白质的遗传代谢问题,如“转录因子/遗传学/代谢(transcription factors/genetics/metabolism) ”“钙黏蛋白/遗传学/代谢(cadherins/genetics/metabolism) ”“同源结构域蛋白质/遗传学/代谢(homeodomain proteins/genetics/metabolism)”这种蛋白质大类,以及“分化抑制蛋白2/遗传学/代谢(inhibitor of differentiation protain 2/genetics/metabolism) ”“EphA7 受体/遗传学/代谢(receptor, EphA7/ genetics/metabolism)”等特定蛋白质。值得注意的是,与遗传代谢相关的各种蛋白质研究形成了极为密集的聚集现象(图4b)。与其聚集在一起的是“LIM 同源结构域蛋白(LIM-homeodomain proteins) ”,虽然该主题词不带“genetics/metabolism”,但其与同区域的几种蛋白质都在各种肿瘤演化及进展中扮演了非常重要的角色,这一现象更体现了关键词在科研兴趣空间中“语义聚集”的特点。可以看出,虽然局部区域内部的关键词表面上并非十分相似,但从研究兴趣、科研问题和研究手段上来看,它们之间有着密不可分的联系。这种联系若由研究人员挖掘,则需要大量的时间用于文献调研和分析,而本研究方法可以自动地发现这些潜在的关联,在充分节约时间的基础之上,为研究人员提供更多的灵感,甚至可以让不熟悉某个领域的新研究者,通过科研兴趣空间中特定关键词的局部分布,快速了解整个相关小领域。
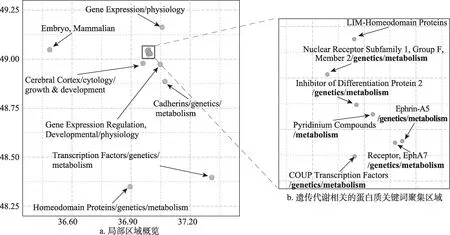
图4 遗传发育相关关键词区域示意
3.3.2 作者向量空间
与研究关键词向量空间类似,本研究对科研兴趣空间中的作者向量进行可视化分析。为了体现科研兴趣视角下的作者向量间关系,考虑到作者文章中包含的关键词能够在一定程度上反映作者的研究兴趣与研究方向,选取了一些整体热度较高的关键词,并以“是否使用过某关键词”为标准对作者向量空间中的点进行标注,“使用过”为深灰色,反之为浅灰色(图5、图6),进而对这些区域进行研究。
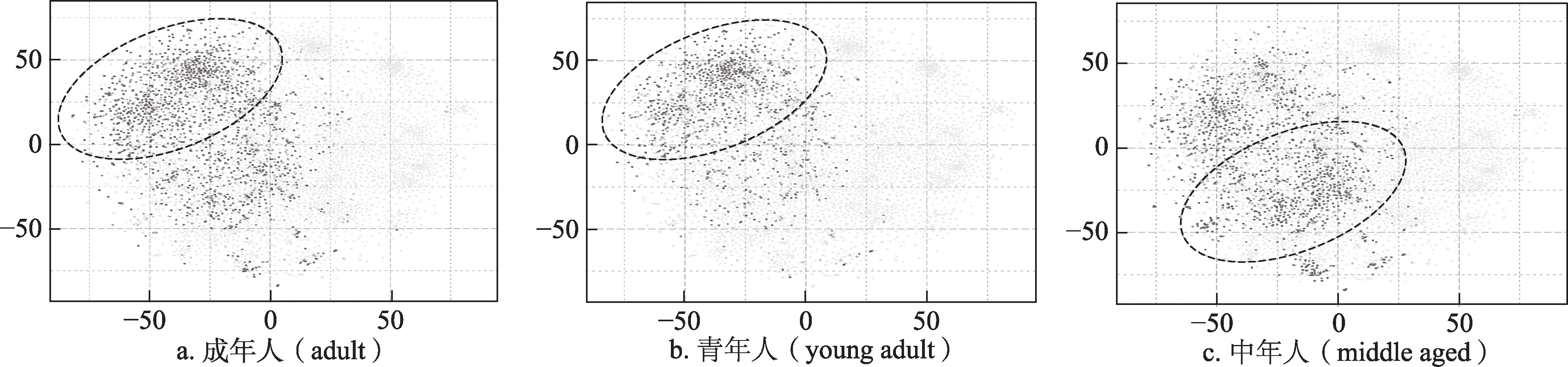
图5 相关主题的作者分布区域差异示例
可以看到,在人类主题相关的研究中(图5),研究“成年人(adult)”主题的作者主要分布于第二象限,并少量分布于第三象限。相对来说,“青年人(young adult)”作为成年人的子群体,该主题相关的作者分布范围也是研究“成年人”作者分布范围的子集,有所不同的是,“青年人”主题的作者分布更偏重于第二象限,而第三象限分布非常少。有趣的是,“中年人(middle aged)”虽然也是成年人的子群体,该主题的研究者分布范围却与“成年人”主题研究者形成了交错趋势,更偏重于第三象限,且在区域下侧明显聚集了更多的作者,这可能是由于研究“中年人”的作者从兴趣上还有一部分倾向于细胞老化的研究话题。
图6 展示了相同主题下的作者分布与作者研究侧重点之间存在的联系。其中,图6a 与图6b 的研究主题均包含“计算机辅助的图像处理(image processing, computer-assisted)”,两者唯一的区别为是否具有副主题词“方法(methods) ”(图6b),这一微小差异却使两个关键词的使用者产生了巨大的差异(分别分布在第二象限与第三象限)。类似地,图6c 与图6d 的研究主题均为“核磁共振成像(magnetic resonance imaging) ”,但由于副主题词“方法(methods)”的存在,两个关键词的研究者也分别分布于两个不同的象限区域。可以看到,“计算机辅助的图像处理”作者的分布范围,大部分在“核磁共振成像”作者分布的区域子集中,除此之外,仅在第四象限与第三象限下部有小簇聚集,与“核磁共振成像”区域有明显区别(图6a、图6c),这说明目前大部分计算机辅助的图像处理研究都应用在核磁共振成像数据中。对比图6b 与图6d 可以发现,核磁共振成像的方法学研究者分布在第三象限的部分明显与计算机辅助图像处理的方法学研究者分布区域重叠。根据上述结果可知,在作者向量空间中,医学图像处理领域的方法驱动研究者倾向于分布在第三象限,即使这些研究者的研究主题不同(如一部分研究者研究核磁共振成像,另一部分研究者研究其他种类的图像处理),他们也可能因各种图像处理方法学研究的模型理论相关性而聚集在一起。这充分说明了在科研兴趣空间中,作者向量分布的语义学意义。
4 结 语
本研究将科研行为数据抽象成具有4 类节点、3类边的异质信息网络,使用异质信息网络表示学习算法metapath2vec 对其进行了嵌入表示,再通过余弦相似度计算向量间的相似度,据此构建了基于异质信息网络表示学习算法的科研关键词推荐与科研合作者推荐模型。与基线方法的对比结果,验证了本研究构建的模型在完成科研关键词与科研合作者推荐任务中均具有良好的效果和稳定性,尤其在科研关键词推荐任务方面有着非常强的优势,这主要得益于本研究更关注科研行为网络本身的“异质”特性,并使用了相应的异质信息网络表示算法对其进行处理,合理地挖掘了不同种类节点之间的语义信息。同时,通过对异质信息网络表示学习算法生成的异质科研兴趣空间中作者与关键词的向量进行可视化分析,本研究发现各主体向量表示具有非常明确和合理的语义聚集特点,这些语义特点往往需要研究者耗费大量时间进行文献阅读与总结,但本研究方法能够自动挖掘和发现它们,有助于从研究兴趣视角更为快速、深入与准确地理解领域中各个子领域的特点与关联。
需要说明的是,本研究尚有一些可以改进的方面。比如,作为一项探索性工作,本研究倾向于阐述在双任务目标的前提下,异质信息网络表示学习算法相较于同质信息网络表示学习算法在处理异质信息网络方面的优势。本研究使用的metapath2vec仅是众多异质信息网络表示算法的典型代表,还有更新的方法值得尝试。在后续研究中可以对异质信息网络表示学习算法做进一步改进,构建更适合科研推荐任务的模型,从而进一步提升推荐效果。此外,本研究仅考虑了作者、论文、关键词、机构4种较为基础的科研主体及其之间的关系,未来可考虑引入更多样的科研主体(如文献出版物、发表时间等),以进一步丰富对科研行为的研究与探索。
