技术机会发现领域专利挖掘方法研究述评
2023-11-21韦婷婷冯丹钰宋世领张建桃
韦婷婷,冯丹钰,宋世领,张建桃
(华南农业大学数学与信息学院,广州 510642)
0 引 言
随着新一轮科技革命的到来,各国企业面临着急需加大自主创新、提供具有竞争性和差异化的产品、主动适应全球竞争格局等关键问题。技术机会发现(technology opportunities discovery,TOD),又称为技术机会分析(technology opportunities analysis,TOA),可通过专利挖掘方法发现新的技术动向,推断该领域可能出现的技术形态或技术发展点,从而帮助研究人员识别、推导和评估新技术理念,对于企业技术创新、产业发展具有重要的战略意义[1-2]。
早期的技术机会发现相关研究通常采用德尔菲法、层次分析法和情景规划等定性分析方法,分析结果受专家的经验和领域知识的影响较大[1]。随后的研究将文献计量、专利分析与专家意见相结合进行定量分析,发现可获得更客观的结果,但输出的领域技术机会粒度较大[3]。随着人工智能技术的发展,技术机会发现的方法也经历了一系列变革,近年来的相关研究将自然语言处理与机器学习、复杂网络分析等方法相结合进行定量分析,以期在降低专家依赖的影响的同时得到更具细粒度的分析结果。
图1 为技术机会发现方法的一般流程。首先,选取数据源并进行数据预处理;其次,根据IPC(international patent classification) 共现关系或专利引用关系构建技术网络,或根据技术功效属性的层次等级(高/低,强/弱)构建技术形态矩阵,建立技术知识的结构化表示;最后,通过挖掘专利技术集群或技术形态矩阵识别潜在的技术机会。
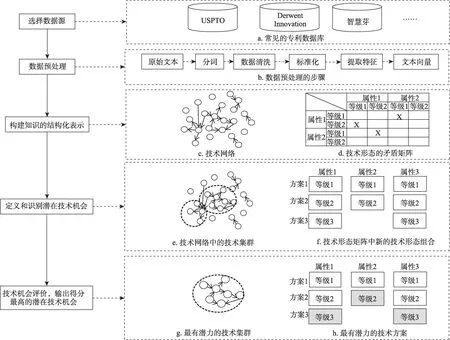
图1 技术机会发现方法流程图
目前技术机会发现研究领域已引起国内外学界的广泛关注,积累了大量研究成果,因此,对其分析方法进行梳理显得十分必要。然而,只有少数学者从特定角度对技术机会发现方法进行综述。例如,伊惠芳等[4]基于技术创新要素,从知识基础以及创新的环境、方式和类型4 个维度总结相关研究;任海英等[3]根据不同的主体指向性,将技术机会分为领域技术机会和研发机会两大类;苏娜平等[5]总结了目前技术机会分析的主要方法,如基于专利地图的方法、基于形态学分析的方法和基于科技关联的方法等,并指出目前技术机会发现方法的局限性在于数据源相对单一、多为静态分析以及缺乏完善的技术机会评价体系;Lee[6]指出,目前TOA 的研究热点包括从专利文本中提取技术信息、基于TOA 寻找新的技术灵感和目标技术领域推荐。
尽管国内外围绕技术机会发现的研究范围、研究对象和研究方法进行了大量的梳理,然而随着人工智能技术的不断发展及其在各个领域的渗透,技术机会发现的方法手段也在发生变化。因此,亟须梳理目前最新的应用进展,尤其是深度学习与自然语言处理相结合的专利挖掘方法在技术机会发现中的重要应用,从技术前沿追踪视角对近年来国内外技术机会发现领域的研究方法进行总结,帮助研究人员厘清分析方法与研究内容的适配关系,为该领域开展后续相关研究和实践的技术选型提供参考依据。
1 技术机会发现中的专利挖掘方法
由于以专利文献作为技术机会发现的数据基石,技术机会发现的相关研究通常采用专利挖掘与分析方法。本文根据技术机会发现领域包含的各子任务所需的底层共性分析方法,将专利挖掘在技术机会发现领域的应用分为5 个方面:专利知识表示、专利相似度计算、专利聚类、技术主题识别和链路预测。下文将详细阐述这些方法的应用研究现状。
1.1 专利知识表示
专利知识表示是指将专利知识单元进行编码,以便于计算机的识别与处理。表1 总结了现有文献中常见的模型及其代表性研究。
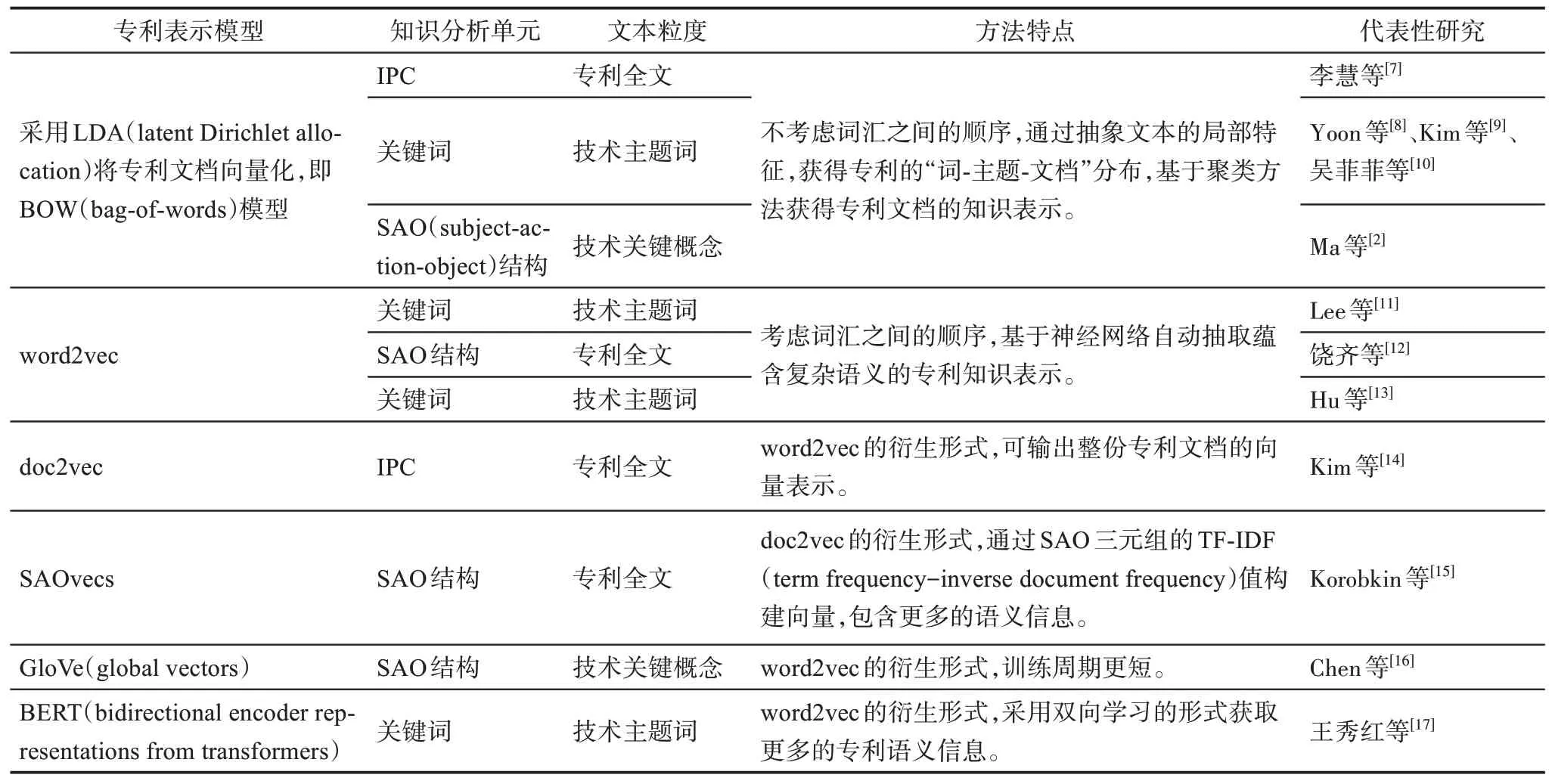
表1 专利知识表示部分代表性模型
专利知识表示模型可划分为离散式表示模型和分布式表示模型两类[18]。早期研究通常采用离散式表示模型,即基于专利中术语的出现频率获得专利的知识表示向量。词袋模型(BOW)是一种经典的离散式表示模型,其通常与潜在狄利克雷分布(LDA)算法结合使用,直接输出文本向量表示和主题词概率分布,再进行后续的分析。李慧等[7]采用LDA 算法从专利样本中获取技术主题,再结合IPC 共现和共类关系构建技术网络,通过将主题词概率分布与IPC 分类号的各级含义对比验证,可以更准确地表示领域内的核心技术。Kim 等[9]将专利中术语的TF-IDF 矩阵输入LDA 模型,用输出的每份专利主题分布向量表示其技术类别。Ma 等[2]采用LDA 获得了各技术主题内关键术语分布,通过分析关键术语之间的SAO 结构,将句子结构信息视为技术关联的表示,探索技术主题之间的潜在联系。离散式表示模型是将专利的局部对象(词或短语)作为特征进行抽象以表示专利的含义。
分布式表示模型则是将词的语义分布式地存储在各个维度中,弥补了离散式模型并未考虑上下文单词之间的相互关联关系且不适用于表征长文本的缺点。在自然语言处理领域,代表性的分布式表示模型有word2vec[19]、doc2vec[20]、GloVe[21]和BERT[22]模型,这些模型也都被引入专利文本表示当中。
在word2vec 模型的应用方面,Lee 等[11]采用包含输入层、隐藏层和输出层的三层神经网络获得专利的word2vec 词向量,并基于词向量的相似度建立产品地图,将产品地图视为专利产品的知识表示。Zhu 等[23]采用图卷积网络(graph convolutional network,GCN)获得了专利文本的关键词向量表示,解决了先前基于词向量的方法不能表示专利与技术领域之间语义关系的问题。饶齐等[12]直接采用开源工具获得专利的word2vec 词向量,比较了word2vec词向量与基于词袋模型的词向量在中文专利SAO 结构抽取任务中的表现,并验证了将词向量用于关系抽取的可行性。
doc2vec 模型在word2vec 模型的基础上增加一个段落ID(identifier)特征向量,可用于获得整份专利文档的向量化表示。Kim 等[14]采用dco2vec 模型获得了每个技术领域的专利文档向量,从专利全文本的视角研究分属不同技术领域的一对IPC 分类号之间的语义相似性。Kim 等[24]利用专利文本的SAO 结构和词向量更新,通过doc2vec 模型得到句向量,此步骤提高了SAO 结构中单词间的余弦相似度,可以更好地反映专利的技术要素和上下文语义。Korobkin 等[15]基于词频、上下文语义和句子结构信息学习专利的SAOvecs 向量,提升了后续执行专利聚类、识别核心技术和热点技术的准确性。
GloVe 和BERT 也属于word2vec 的衍生模型。GloVe 可获得比传统的word2vec 模型更充分的全局信息。Chen 等[16]采用GloVe 模型,基于全局词共现生成专利向量,在语义信息抽取任务中能以更短的训练周期取得比word2vec 模型更好的效果。BERT模型则通过双向的学习方式更深度地学习词汇的上下文,仅需采用具体任务的数据集对通用BERT 模型的最后一层进行微调,就能够被应用于很多实际任务[25]。林原等[26]通过微调使BERT 模型能够包含更多的领域知识,获得更能精确表达语义的文本表示。王秀红等[17]采用BERT 模型获得了专利文本的词向量、文本向量和位置向量,再将通过BERT 训练的向量与采用LDA 获得的专利主题向量拼接,最终获取了包含丰富语法和语义信息的专利知识表示。
在专利文本表示的对象中,专利的知识单元包括专利的IPC 分类号、关键词和SAO 结构。其中,IPC 分类号和关键词所包含的语义信息较弱,无法准确表示专利之间的关系[7,27];而SAO 结构是“主语-谓语-宾语”形式的三元组,在专利技术信息的表示上更具细粒度。因此,以IPC 分类号和关键词作为基础知识单元的通常是那些仅考虑结构化数据和词频概率分布的任务,如基于LDA 的专利聚类和主题识别[2];SAO 结构常被应用于考虑语义关系、对深度和精准度有要求的专利文本挖掘任务中[28]。
总体而言,在表示方法层面,分布式表示模型所取得的性能优势使其已逐渐取代离散式模型成为目前主流的专利文本表示方法;在分析对象方面,现有研究很少将整篇专利文档向量化,一般仅提取文档中可以有效表示技术知识的部分,如关键词或专业术语等[8-9]。
1.2 专利相似度计算
基于专利文本进行相似度计算能够获取技术间相似程度,可用于展示技术发展的脉络、现状和趋势,为技术机会发现提供分析基础。该环节的一般流程:先将专利转化为词、短语或句子的表示向量,再采用一些度量指标计算专利之间的相似度。
在专利文本表示方面,如1.1 节所提方法,专利相似度计算中主要采用了词袋表示法、主题表示法和分布式表示法。其中,基于词袋表示的方法仅利用简单的文本统计信息计算技术之间的相似度;基于主题表示的方法考虑了词共现信息,包含一定的语义;基于分布式表示的方法则是在融合了更多文本语义特征的基础上进行相似度计算[29]。
在相似度的度量方法上,经典的方法是余弦相似度计算法。例如,专利A和专利B之间余弦相似度的计算公式为
其中,fAi表示专利A的向量的第i个元素;fBi表示专利B的向量的第i个元素。两个向量之间夹角的余弦值越接近1,则两份专利的相似度越高。
另一种常用的专利相似度度量指标是Jaccard 指数,即将两份专利中相同关键词的数量除以两份文本的关键词总和得出的值,计算公式为
其中,NA1B1表示同时存在于向量A→和向量B→中的元素;NA1B0表示存在于向量A→但不存在于向量B→中的元素;NA0B1表示不存在于向量A→但存在于向量B→中的元素。Jaccard 指数的取值范围是0~1,值越大,相似度越高[30]。
在实际应用中,Song 等[1]利用专利关键词向量之间的余弦值表示对应两项技术的相似度,通过识别出与目标技术专利相似术语最多的其他领域专利文档,找到改进目标技术的解决思路以及潜在的技术融合机会。Arts 等[30]通过计算专利关键词之间的Jaccard 值测度专利所代表的技术之间的相似性,为从业者评估专利新颖性、寻找技术机会提供帮助。刘俊婉等[31]将Jaccard 指数作为相似度指标,用于测度专利技术主题词共现的强度,以发现新兴主题产生关联的机会。Lee 等[11]基于具有相似技术基础的产品彼此靠近的假设,根据word2vec 词向量之间的余弦距离建立了“专利-产品”网络,基于此确定目前公司有能力进入的新产品领域,即潜在的技术机会。席笑文等[32]将word2vec 词向量与LDA 主题向量拼接,通过拼接向量之间的余弦相似度测度专利权人之间技术产出的相似性,以帮助技术主体识别潜在的竞争关系或合作机会。Zhang 等[33]基于余弦相似度计算寻找关联的LDA 主题向量,结合专利发布时间轴获取区块链领域中各项子技术演变的轨迹,发现了当前的热点主题、突破性主题和空白主题,其中热点主题被视为最有前景的技术机会,突破性主题被视为有潜力的技术机会。
总之,现有研究采取的相似度度量指标比较固定,但是在技术挖掘层面根据其具体应用选择不同的方法模型,其中词向量与LDA 模型相结合的挖掘方法呈流行趋势。
1.3 专利聚类
专利聚类的核心思想是将高维的原始文本数据投射到低维空间,使相似的数据样本尽可能地集中,而不相似的样本则尽可能地分散。专利聚类的结果常被用于识别该领域的关键技术集群、构建技术网络、识别离群专利等,对于把握技术发展的态势具有重要意义,为技术机会发现提供直观的分析依据。
根据专利知识的使用,专利聚类方法可以分为基于IPC 代码的聚类、基于专利主题的聚类以及基于功能信息的聚类[34]等几大类。常用的聚类算法包括主成分分析(principal components analysis,PCA)、k均值聚类算法(k-means clustering algorithm,kmeans)和LDA 模型。此外,还有LDA 的变形模型,如标签化的多重混合狄利克雷模型(labeled Dirichlet multi mixture model,LDMM) 的半监督聚类模型。表2 总结了现有文献中常用的聚类算法及其应用领域。
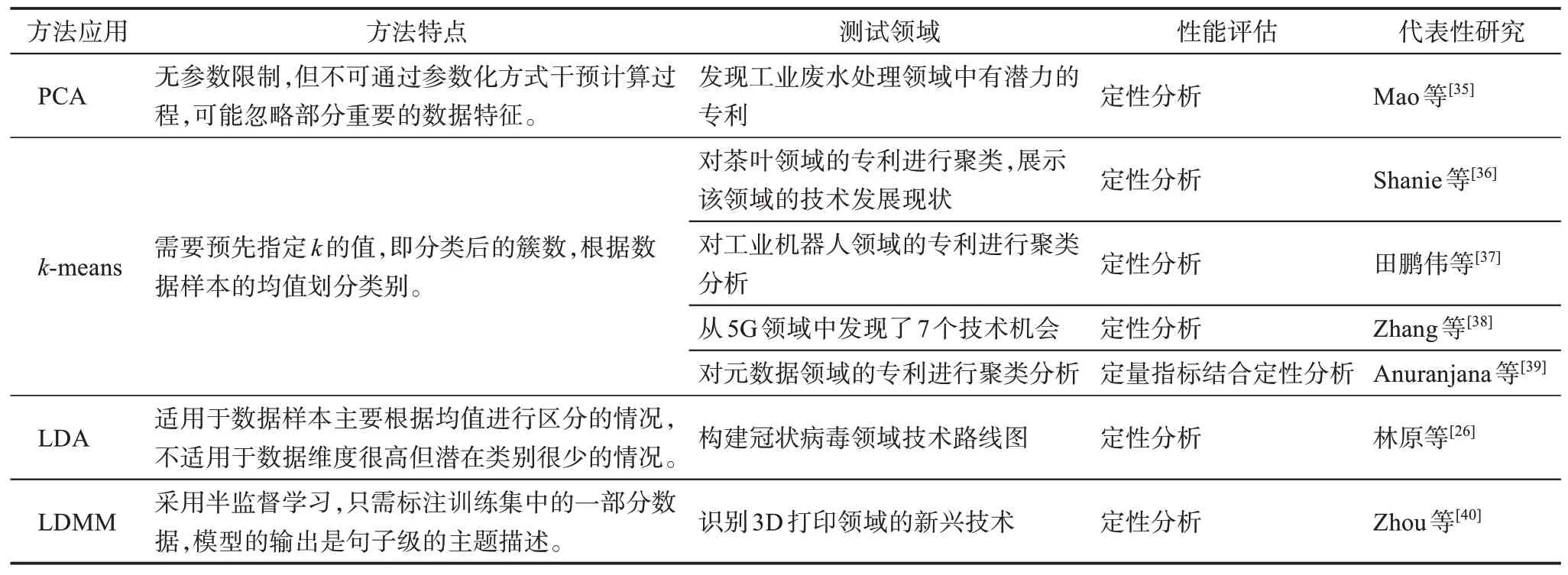
表2 常见的聚类算法
各聚类算法中,PCA 的特点是不需要输入参数,使用较为简便;k-means 需要预先设定集群的类别[38];LDA 则基于主题的分布划分集群,例如,李慧等[7]采用LDA 获得特定IPC 码类别下的专利主题词聚类,综合专利文本的结构化特征和非结构化特征对该领域中的核心技术演化轨迹和趋势进行分析。LDMM 采用半监督方式学习数据特征,Zhou等[40]采用LDMM 获得了专利的句子级表示,解决了有监督模型泛化能力不强和无监督学习模型不精确的问题,能够更好地识别新兴技术。除了应用算法,有些研究采取更直接的聚类方式,如Arts 等[30]根据专利关键词的共现程度判断技术之间的相似度,以此作为技术聚类的依据。此外,由于聚类结果呈现的是数据集中的专利被划分到不同的技术集群,因此,集群间的空隙、异常专利或离群专利也可被视为技术机会的表示[41]。目前已有一些研究采取了通过离群计算的方式进行技术机会分析。例如,Jeon 等[42]计算每份专利的局部离群因子(local outlier factor,LOF)值,从而得到专利的新颖度,识别出有潜力的新专利;Wang 等[43]则通过计算专利的LOF 值来寻找相似的专利集合。
目前,基于专利文本的聚类算法其测试领域较为多样化,但由于缺乏统一标准的公开测试集,聚类结果的性能评估通常以定性分析为主。因此,无法公平地对聚类算法进行统一评估,只能根据具体应用领域的需求特点选择更适配的专利聚类算法。未来可以从定量和定性相结合评估的角度针对性地提出技术机会发现中专利聚类的统一模型框架,从而提升技术机会发现领域其分析结果的可靠性。
1.4 技术主题识别
技术主题一般是指某技术领域的关键技术或子领域的关键技术[44]。主题识别旨在获取技术领域中核心或热门的技术主题,进而帮助把握技术发展态势和发掘技术机会。
技术主题识别的经典方法是LDA 模型。LDA模型是一种基于概率和统计方法的主题模型,能够从文本中提取出潜在的主题[45],是由“词-主题-文档”构成的三层贝叶斯概率模型。表3 列举了技术机会发现领域中LDA 的部分应用实例。
从方法本身而言,LDA 可以根据词频最高的词组得出潜在的主题,但没有考虑语义和词频以外的信息。因此,部分文献采用统计学方法对LDA 进行优化。比如,吕璐成等[46]将非负矩阵分解模型与LDA 结合,把主题识别任务转换为解决约束最优化的统计学问题,提升了动态识别专利主题的模型性能。此外,考虑到专利的主题词有时并不是独立的词汇,而是由2~3 个词汇组成的短语。马建红等[27]通过双向长短时记忆网络-条件随机场模型抽取出专利短语后,采用经广义波利亚瓮模型(generalized Pólya urn)引入先验知识后的LDA 模型进行主题短语抽取。该方法既解决了基于短语的主题模型常出现的稀疏性问题,又具备比传统主题模型更高的可读性和判别性。
除了上述两种从LDA 的性能上提升主题识别准确度的做法之外,有文献将LDA 的结果与其他方法的结果相结合,以期在后续任务中取得更好的效果。例如,王秀红等[17]将通过BERT 获得的语义特征向量与采用LDA 获得的主题特征向量结合,弥补了单一LDA 模型缺乏上下文语义信息的局限性,在后续的专利聚类任务中取得了更具准确性和细粒度的结果。Kim 等[49]将LDA 与网络分析方法结合,通过链路预测从主题关键词网络中寻找技术机会。该方法实现了对LDA 输出的技术主题之间关系的挖掘,能更好地辅助技术机会发现。
在主题分析对象上,LDA 的分析对象通常为专利的部分文本,如摘要或权利声明,或者专利的引用网络。基于纯文本(摘要或权利声明)的主题识别主要利用文本内元素的共现信息;基于所有权人关系网络和引用关系网络的相关研究兼顾了专利文本的内部语义和每份专利文本与外部世界的信息交互。在进行主题识别时,若有多个分析对象,则根据需要对这些对象设置一定的权重比例。例如,Ma 等[2]根据经验将标题和摘要的权重设置为2∶1,其在后续研究中还将探索不同权重比例对识别结果的影响。
在实际应用中,Kim 等[9]将LDA 主题词分布与引用网络结合,通过可视化3D 打印领域中各技术集群内专利间的继承关系监测技术发展的轨迹,发现技术开发机会。该方法基于LDA 主题分布确定专利所属的技术主题集群。Choi 等[50]将技术主题的类型设置为主导型、新兴型、饱和型和下降型4类,采用LDA 分析物流领域专利的摘要,发现与数据库和传感器子相关的通常为新兴型主题,这意味着数据获取和数据分析可能是物流领域未来的技术热点,即有潜力的技术开发机会。此外,该项研究证明了当无法用某几个美国专利分类(United States patent classification,USPC)中子类的主题词完全覆盖该领域的专利主题时,可用LDA 主题模型的结果进行补充,以开展更全面的领域技术发展现状分析。韩芳等[51]采用LDA 识别出太阳能光伏领域中12 个拥有突破性创新潜力的技术主题,即有前景的技术开发方向。该方法具有比基于共词分析或向量空间模型的主题识别方法更低的算法复杂度。
技术主题识别的结果还可以通过可视化的方式呈现,可视化工具诸如LDAvis[33]、Gephi 软件[32]和t-SNE 算法[7,52]可被用于直观展示技术主题识别的结果。但是,主题模型的可视化往往仅能展示技术的动态演化过程,无法识别和预测技术的突变和融合。
总体而言,技术主题识别容易受所提取的术语和特征选择技术的影响,难以取得较好的性能。改进的方向之一是优化专利文本的向量表示,比如,刘小玲等[53]在构建文本向量时将专利的文本内容、引用关系和分类号信息3 个属性进行了融合,提升了专利向量表示的准确性。除了增强专利知识,未来可以从联合模型的层面考虑,利用模型之间相互知识补充的原理将有利于主题的精准识别,这类方法在技术机会发现领域尚处于初始探索阶段,具有很大的改善空间。
1.5 链路预测
在技术机会发现领域,实施链路预测的目的主要是预测技术发展的趋势,找到潜在的技术机会。链路预测的数据基础是技术网络,即先构建一个以节点代表技术、以边代表技术之间关联关系的网络,再通过已知的技术网络拓扑结构如技术节点和链接的特征,预测网络中尚未连接的两个技术节点之间产生链接的可能性[54]。图2 为在技术网络中开展静态链路预测的示意图。链路预测的方法可以划分为基于相似度、基于社会网络分析和基于机器学习三大类。表4 总结了技术机会发现领域常用的链路预测方法。
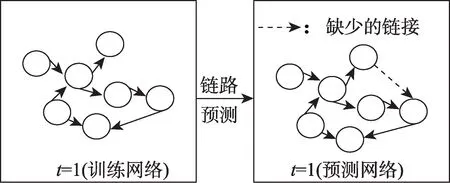
图2 静态链路预测示意图
基于相似度的链路预测通常采用Jaccard 指标、Adamic-Adar (AA) 指标、共同邻居算法(common neighbors,CN)、优先依附算法(preferential attachment,PA)等相似度指标或算法预测可能出现的链接。Seo[55]将上述4 种方法结合用于链路预测,减少了计算过程中的信息丢失。Han 等[56]采用局部随机游走(local random walk,LRW) 算法获得技术节点的特征向量,与上述4 种方法相比,LRW 算法准确度更高。
基于社会网络分析的链路预测通常采用边缘中介中心性、度中心性、接近中心性等指标,根据技术网络的结构特征进行预测。比如,Park 等[58]采用基于边缘中介中心性的方法预测可能出现的跨领域知识流,用经过技术节点的最短路径数量刻画该节点在技术网络中的重要性。
上述两类方法皆是对技术网络的全局或局部特征展开定量分析,不能充分挖掘网络的深层信息。基于机器学习的方法能够更好地获取技术网络中节点和连边的属性和结构信息。涉及机器学习的方法包括基于统计的机器学习模型,如决策树(DT)、随机森林(RF)、支持向量机(SVM)和k-近邻算法(k-nearest neighbor,kNN)等[62];还包含基于深度学习的模型,如长短时记忆网络(long short term memory networks,LSTM)、图卷积网络(GCN)。Yoon 等[54]采用基于SVM 的链路预测模型,预测专利网络中可能出现的新节点;Cho 等[57]采用基于DT方法预测可能出现的IPC 共现;Kim 等[14]采用基于RF 的方法预测可能出现的技术融合。基于深度学习的方法在获取足够特征信息的同时能够降低对专家领域知识的依赖度[25]。Nakai 等[63]采用LSTM 预测专利网络中引文规模增长的趋势;Qi 等[61]采用GCN 将复杂的专家-机构网络简化为图的形式,预测专家合作关系;Zhu 等[23]采用GCN 获得专利文本的低维知识表示,结合两个能反映专利与技术领域的语义亲密度的指标——技术特征向量和强度坐标,来预测技术融合。
链路预测的应用主要有以下几个拓展方向。首先,需度量技术主体的内在能力是否足以实现该技术机会。例如,Seo[55]通过基于LDA 的链路预测发现技术主题网络中近期可能出现的新链接,然后采用关联规则分析生成技术主题之间有方向和权重的链接,找到与企业的能力相匹配的技术机会。其次,许多模型仅考虑生成的链路方向,没有保留网络的拓扑结构信息。Chen 等[64]采用PageRank 计算节点的影响得分,捕捉网络的全局结构信息,然后采用非对称链路聚类计算协同系数得分,获得网络的局部结构信息,最后在非负矩阵分解模型中联合优化这两个参数,使模型同时保留局部和全局信息。此外,除了从技术的角度挖掘有潜力的技术机会,链路预测还可在合作网络中挖掘潜在的合作者关系。比如,Qi 等[61]采用基于GCN 的链路预测识别论文和专利作者所属机构的合作网络中缺失的链接,以此作为潜在的合作机会。
目前,在链路预测的相关研究中,基于图卷积网络(GCN)的方法能够更全面、更深层次地挖掘技术网络所隐含的信息,极大地提升了预测性能,这将成为一个重要趋势。
2 结果与讨论
本文通过系统性回顾相关文献,总结了专利知识表示、专利相似度计算、专利聚类、技术主题识别和链路预测5 类技术机会发现中的底层共性分析方法的应用现状。图3 是上述方法在技术机会发现领域应用的结构图,将5 类方法与相关业务结合,以期能够从全局的视角展示各类方法与技术机会发现流程中各阶段任务的适配性。
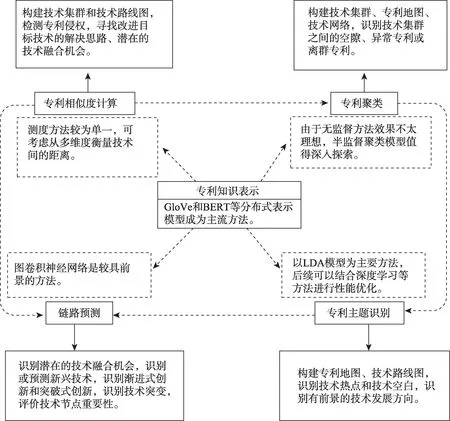
图3 专利挖掘方法在TOD领域的应用结构图
(1)专利知识表示具有关键性作用
在技术机会发现方法的一般流程中,专利知识表示主要应用于数据预处理和构建知识的结构化表示,是后续分析的基础数据。因此,选择何种类型的专利知识以及如何准确地将知识进行表示,对技术机会发现的有效性具有关键性作用。目前沿用的分布式表示模型是通用领域中的文本表示方法,但是针对领域术语较多、语义复杂的专利文本表示尚未发现相关研究。未来研究可以集中于普通文本和专利文本的具体差异和联系,深入探索更好的专利文本表示模型。
(2)技术机会定义决定方法选择
从图3 可以看出,尽管专利相似度计算方法、专利聚类方法、技术主题识别方法和链路预测方法均可以达到技术机会发现的目的,但是各研究根据技术机会内涵的不同定义而选择不同的底层分析方法。上述4 种类型挖掘方法的应用场景各自具有相应的侧重点。
专利相似度计算通常用于技术机会发现领域的各个子任务,它在寻找相似技术解决方案上具有一定优势。例如,专利相似度计算通过识别其他领域中与目标专利相似度最大的专利,可以找到改进目标技术的解决方案以及发现目标技术与其他领域的技术发生融合的机会。除了传统的余弦相似度计算之外,目前有些研究利用深度学习模型进行专利之间的自动距离测量,但是需要一定量的标注数据。
专利聚类方法的主要目的是自动发现技术集群,在大规模数据场景下,该方法相比于专利相似度计算方法更为灵活,但是其效果易受数据样本不均衡的影响。根据聚类输出结果,可以将专利数量庞大的技术集群视为当前的技术热点,将集群之间的空隙视为有待开发的技术空白区域,将明显独立于集群的专利视为可能发生技术突变的异常或离群专利。该方法可用于基于离群点检测的技术机会发现上。但是,目前的聚类手段仍是传统的机器学习方法为主,虽然无监督的方式避免了数据标注的问题,但是技术集群中也包含了大量噪声数据,不利于技术机会的发现。
专利主题识别方法基于专利之间主题的关联度构建技术集群,它将与大量技术主题有关联的目标主题视为技术热点,找寻有前景的技术开发或融合方向。目前的方法以LDA 模型为主,该方法的底层思想是从词共现角度识别专利技术主题,对于领域术语多样复杂的专利文本而言,其效果仍有待提升。尽管有将LDA 与其他深度学习模型结合使用的相关研究工作,但是目前仍处于探索阶段,在其他子任务的适用性方面还有待考究。
相比于前几类方法,链路预测方法更贴近面向未来的技术预测这个内涵。其通过预测技术网络中缺失或即将出现的链接,识别潜在的技术融合机会,也能识别可通过历史数据预测到的渐进式创新,找到目标技术的改进机会。此类方法也可通过预测技术网络中空白区域新出现的链接和节点,识别可能的技术突变和突破式创新,寻找将在目标技术领域引起重大变革的技术机会。此外,部分文献将通过链路预测获得的边的权重与关联规则分析或综合评价指标结合,评价技术机会的前景和可行性。从现有研究工作来看,图神经网络方法逐渐引起相关研究人员的关注,将成为具前景的热门方法之一。
综上所述,在进行技术机会分析时,往往需要根据通用流程中各个步骤的具体业务,选择合适的方法。其中,预处理阶段的方法最为模式化,通常采用专利知识表示的模型,输出专利文本向量。知识结构化表示的建模方法较为丰富,主要用于构建技术网络或技术路线图,此类方法的输出对技术机会发现的结果影响较大。现有文献对技术机会的定义各不相同,包括但不限于技术热点、技术空白、跨领域的技术融合等,因此,可应用于技术机会识别阶段的方法及其应用形式也最为多样。专利相似度计算方法可用于找寻与目标技术相关的改进和融合机会,专利聚类方法和专利主题识别方法可用于找寻技术热点和技术集群之间的空隙,链路预测方法可用于识别和预测技术融合,也有文献选用两种以上的方法构建混合模型,以达到更优的识别效果。目前,适用于技术机会评价阶段的方法主要是基于链路预测的权重计算或评价指标,形式较为单一且未能形成规范的评价体系。有效的评价方法将能够反过来促进专利挖掘方法的进一步改善。未来有前景的研究方向包括优化专利的知识表示、探索效果更好的技术机会识别模型,以及在技术机会的评价阶段应用更多样的方法。
3 面临的挑战
总结现有文献,目前在技术机会发现领域有关专利挖掘方法的应用主要存在以下几个有待解决的问题。
(1)专利全文本分析方法有待挖掘。鲜少文献采用整份专利文本作为研究对象,大部分文献仅采用专利的标题和摘要作为语义分析对象。部分专利挖掘任务相关的研究考虑到了权利要求书中权利要求人之间的关系[65],但受限于算法效率和硬件算力,对于专利其他部分,如属于长文本的说明书,开展分析的难度依然较大。
(2)用于分析的文本知识结构较单一。现有研究的知识分析单元包括IPC 分类号、关键词、SAO结构等。其中,SAO 结构的提取需要预先设置技术关键词,即需要充足的领域知识作为支撑,但仍可能忽略有价值的技术知识。基于IPC 分类号和关键词的文本分析所包含的技术信息较为宽泛,难以识别出具体的技术机会。目前,大部分文献仅基于专利文本结构的某一类技术要素展开分析,未来的拓展方向之一是基于混合的文本知识结构展开分析。值得注意的是,有时将两类知识分析单元关联起来的做法可能使分析结果变得模糊和不准确[54]。
(3)技术主题识别方法具主观性。技术机会的表征主要由技术主题关键词构成,然而在现有的主流方法中,关键词的提取高度依赖于专业领域词典,并且在提炼技术机会的过程中需要人工定义技术主题的具体名称和内涵,主观成分较大。缺乏客观及普适性的挖掘方法将难以保证结果的可靠性。
(4)检验技术机会的方法有待完善。现有文献对技术机会的检验过程常常是不充分的,模型的输出结果并不一定就是技术机会,因此,需要设计诸如专利被引量、被引量增长率、专利与相关聚类集群相连的节点数等验证指标[66]作为补充。
4 改进思路
基于技术机会发现的流程、各类方法的应用现状及当前研究所面临的挑战,本文提出了一些应用创新方面的切入点,如图4 所示。
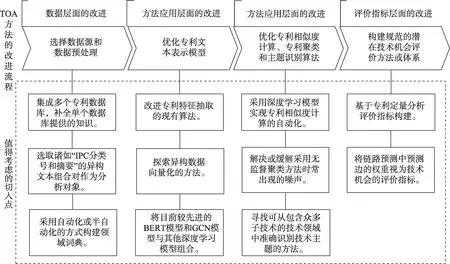
图4 专利挖掘方法应用创新的思路图
(1)数据层面的改进。数据层面的改进主要是选用内涵信息更丰富的专利对象。涉及多源异构专利数据的研究是近年的热点,主要通过集成多个专利数据库并选取不同结构的文本分析对象,从而实现较为全面、深入的分析。此外,鉴于专利主题识别对领域词典的高度依赖,领域词典的自动化或半自动化构建将是未来发展趋势之一。
(2)方法应用层面的改进。方法应用层面的改进主要是对算法本身进行优化,探索组合模型在不同应用场景中的适用性,以及寻找能解决现有问题的新方法。比如,提出可将异构数据向量化的新方法,探索更新颖的文本表示模型,探索BERT、GCN 及其衍生模型与传统机器学习模型组合后在专利特征抽取、专利相似度计算、专利主题识别、链路预测等任务中的适用性。此外,可从无监督聚类方法角度,尝试缓解或消除噪声,以实现不需要主题词表的专利聚类,寻找可以快速处理大规模复杂数据的新方法。
(3)评价指标层面的改进。评价指标层面的改进主要是提出具有实践价值的技术机会评价体系。可根据现有研究中常见的社会网络分析指标、文献计量指标、专利质量评价指标等,构建一套较完整的技术机会评价体系;还可采用GCN 模型预测技术关系,以被预测边的权重作为技术机会的评价指标[61]。
5 结 语
本文对技术机会发现领域中的专利挖掘方法应用进行了文献综述,总结了该领域底层共性的专利挖掘方法在整个技术机会发现方法流程中的研究现状,构建了研究方法和该领域研究子任务的适配结构图,提出该领域面临的方法上的挑战,并提出了几点改进思路。
在人工智能、大数据技术背景下,未来希望研究者们可以共同丰富专利挖掘对象的内涵,优化专利特征抽取算法,实现大规模领域专利数据集的规范化构建,探索先进的文本表示模型和图卷积网络模型与其他模型组合后在各类专利挖掘任务中的表现,从而能够更好地借鉴目前前沿的深度学习思想,对技术机会发现领域提出针对性的改进方法,并完善技术机会发现定性和定量相结合的统一评价体系,增强技术机会发现结果的有效性和可靠性。
