融合锚节点和三元关系向量的军事知识图谱表示学习*
2023-11-20覃基伟李建军马良荔何智勇周自成
覃基伟,李建军,马良荔,何智勇,周自成
(1.海军工程大学电子工程学院,武汉 430033;2.解放军91001 部队,北京 100036)
0 引言
随着计算机技术的快速发展,数据呈爆发式增长,这些数据蕴藏着丰富的知识,如何有效挖掘和表示这些知识成为了一个难题。在此背景下,知识图谱(knowledge graph)作为知识的一种结构化表达方式,近年来得到了广泛的关注。知识图谱通常以(头实体,关系,尾实体)的三元组形式表示客观世界存在的事实,这种简单、直观的三元组表示形式,能够清晰地表达出实体之间的关联,具有容易扩展、结构友好等优点,在各个领域都得到了广泛应用[1]。在军事领域中,通过知识图谱技术实现对军用信息系统数据库、文书资料、情报文本、图像和流媒体等海量多源数据的建模分析和深度挖掘,已成为军事数据融合的主要手段之一。然而,现有的军事知识图谱大多采用半自动化结合人工的方式构建,由于数据本身的不完整以及图谱构建人员的水平参差不齐,导致构建的军事知识图谱存在不完备的情况,具体表现在大量现实存在的三元组缺失,导致知识推理的难度增加,对辅助决策任务造成极大的影响,如何有效实现军事知识图谱的补全已成为亟待解决的难题。
为有效解决知识图谱补全问题,不少研究者通过表示向量的形式,在低维连续向量空间中学习实体和关系的嵌入特征,预测未知的三元组信息完成知识图谱补全,该方法既能简化计算又能缓解数据稀疏的问题,有效提升知识图谱的下游应用效果[2]。本文将锚节点编码技术NodePiece 和关系向量嵌入技术TripleRE 结合[3-4],构建军事知识图谱表示学习模型,以实现对知识的表示和推理。先利用NodePiece 对实体节点进行锚节点编码,然后通过TripleRE 对关系进行嵌入,通过对二者的融合实现军事知识图谱表示学习模型的构建,提升军事知识图谱推理能力。
1 研究现状
在知识图谱表示学习方面,目前主流的研究方法为将知识图谱中的实体和关系映射到低维向量空间,并在向量空间中进行逻辑推理。该方法可有效建模实体与关系之间的语义关联,同时具有一定的泛化能力。受启发于Word2Vec,TransE 将知识图谱中的实体和关系映射到向量空间,通过空间上的平移直觉设计得分函数对模型进行训练,但实际的知识图谱往往存在各种复杂关系,如“多对一”和“一对多”等,受限于简单的知识表示建模方式,TransE 难以对这些复杂关系进行建模[5]。TransH 将关系建模为超平面,将实体通过超平面的关系法向量映射到关系超平面空间中,成功地缓解了TransE难以对复杂关系建模的困境[6]。TransR 分别将实体和关系建模到不同的向量空间中,通过关系矩阵将实体向量映射到关系向量空间进行平移操作完成建模[7]。360 公司提出的TripleRE 则利用更细粒度的关系向量,来增强知识图谱嵌入的表达能力和泛化能力,同时减少了参数数量和计算复杂度[4]。考虑到知识图谱中存在许多包含逻辑语义的关系,如“对称关系”“反对称关系”等,针对此类关系,ComplEX 和RotatE 等方法提出将知识图谱中的实体到复向量空间中,将关系建模为单位复向量,从而将关系对于实体的运算转换为复向量空间上的操作。此外,为了充分地将各个实体和关系的语义进行关联,基于图神经网络的知识推理模型将知识图谱中的结构信息进行编码,例如RGCN和CompGCN 等[10-11]。随着知识图谱的规模不断扩大,许多研究开始探索知识表示模型应用在大规模知识图谱上的可能性,NodePiece 从已知知识图谱中选取特定节点为锚节点,其他任意节点通过锚节点实现表示,研究表明NodePiece 不仅能降低实体表示所需的存储空间,而且提升了实体表示的泛化性[3]。
2 模型构建
为有效地处理和推理知识图谱中的关系和实体,本文构建融合NodePiece 和TripleRE 的军事知识图谱表示学习模型,以实现对军事知识图谱潜在的深层语义和表达能力的挖掘。
2.1 基于NodePiece 的锚节点编码方法
传统的知识图谱表示学习算法主要采用单一嵌入方式,即将每个实体映射到一个唯一的嵌入向量。这种表示方法虽然简单直观,但是会导致存储空间大量增加,而且不利于挖掘实体间的相似度关系,因此,单一嵌入方式不利于军事知识图谱补全工作开展。
受自然语言处理中常用的子词标记化工作启发,NodePiece 探索了具有可能的次线性存储需求的更参数高效的节点嵌入策略的前景,提出了一种基于锚节点的学习固定大小实体词汇表的方法,通过形成的锚节点词汇表,实现对任意实体的编码和嵌入。其中,锚节点是指已知的具有特定属性或标签的节点,其作用为提供一个已知的参照,所有实体节点的嵌入表示通过与该参照的关系学习得到。在NodePiece 中,实体节点的数量|V|与锚节点词汇表大小|N|之间的关系通常满足|V|<<|N|,由于锚节点的数量远小于实体节点数量,因此,向量嵌入表示所需空间能够大大减少。
2.1.1 锚节点生成
锚节点的生成方法主要有虚拟节点构建和实体节点选取这两种,考虑到构建的虚拟节点难以表现具体的语义信息,且无法直接和实际的实体节点关联,因此,采用选取实体节点形成锚节点的词汇表。为了能够让选取的锚节点代表整个知识图谱的特点和结构,涵盖不同类型的实体和类型,以便学习到的嵌入能够较好地反映整个知识图谱的语义信息。因此,在选取锚节点时综合节点度数、个性化PageRank 和随机选择3 种策略。
1)节点度数:节点度数是指节点与其他节点之间的连接数,节点度数较高的节点通常表示在知识图谱中具有重要性和影响力的实体,在选取过程中,优先选取节点度数高的节点。
2)个性化PageRank:个性化PageRank 是一种基于随机游走的算法,用于评估节点在图中的重要性,通常PageRank 值越高,节点就越重要,在选取过程中,优先选取PageRank 值高的节点。
3)随机选择:通过随机选择实体作为锚节点,可以保证锚节点的选择具有多样性和覆盖性,该方法可以避免过度依赖某些特定的实体节点,从而提供更全面和多样化的语义信息。

2.1.2 节点token 化
在完成锚节点的选取后,利用锚节点实现图谱中所有节点的token 化。对于每个节点n,使用k 个最近的锚节点及到锚节点的距离,以及m 个关系来进行表示,在实际应用过程中,为每个关系添加一个逆关系以提升知识表示的泛化性和鲁棒性。目标节点token 化过程如下:
1)寻找k 个最近的锚节点,具体而言,对当前节点n,遍历所有锚节点,寻找节点到锚节点的最短路径,根据最短路径从小到大选取Top-k 个锚节点用于节点表示,当满足条件的锚节点数量不足k时,使用标记[NOTHING]填充到k,生成锚节点向量an。若当前节点本身是锚节点,由于节点到自身距离为0,因此,将自身也纳入到an中。
3)随机选m 个节点n 的出边,即节点n 充当头实体的三元组中的关系,若满足条件的关系数量不足m,则用标记[PAD]填充到m,以此得到关系向量rn。
通过对节点n 的token 化,最终得到节点n 的哈希表示,如式(1)所示。
经过token 化后,军事知识图谱中每个实体节点n 被分解为由k 个锚节点、节点n 与这些锚节点间的k 个距离以及数量为m 的上下文组成的向量,该过程有助于对每个实体节点进行更细粒度的表示和处理。
图1 给出节点token 化的示例,生成向量结果如式(2)所示。

图1 节点token 化示例Fig.1 Node tokenization example
式中,关系r1i和r3i分别表示关系r1和r3、r7的逆关系。
2.1.3 节点编码
假设编码后节点n 的向量表示维度为d,即需要将hash(n)映射到d 维向量空间。该过程需要建立一个编码器,本文采用多层感知机来进行编码,其原理如图2 所示。

图2 NodePiece 编码原理Fig.2 Principle of NodePiece encoding
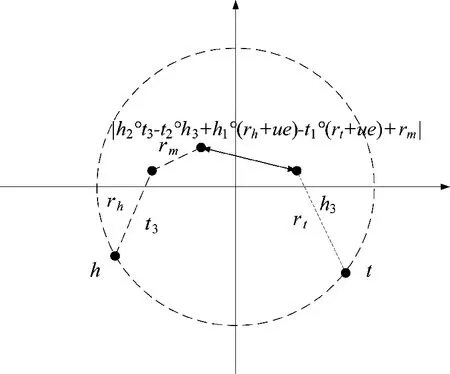
图3 TripleRE 示例图Fig.3 Example diagram of TripleRE
1)首先将an、和rn分别通过嵌入层进行编码,将其映射到低维实体向量空间中。
2)将an的嵌入表示与的嵌入表示相加,以便综合利用节点特征和关系信息,从而提高节点嵌入的表达能力和鲁棒性,并增强相似性度量的能力。此时,节点n 的嵌入表示结果如式(3)所示。
3)通过多层感知机来对节点n 的嵌入表示进行编码,该网络从前到后依次为全连接层、Dropout层、ReLU 激活函数层和全连接层。在编码器训练过程中,采用TripleRE 模型计算损失并进行反向传播,最终生成目标实体的低维向量表示。
2.2 基于TripleRE 的知识表示
TripleRE 是一种基于三元组关系向量的知识图谱嵌入方法,其采用残差连接机制来捕捉三元组关系中的非线性交互特征,从而可以更好地学习实体和关系的嵌入向量。它继承了TransH 等模型将实体映射到关系向量空间的思想,在训练过程中学习3种关系表示:头实体关系投影向量、尾实体关系投影向量和关系平移向量。头实体关系投影向量和尾实体关系投影向量分别将头实体和尾实体投影至关系空间中;同时在投影过程中考虑头尾实体相互间的联系,以更全面地捕捉实体间关联信息;关系平移向量用于对投影过后的实体向量开展平移操作。
对于一个三元组,假设通过NodePiece 编码的头实体和尾实体嵌入表示向量分别为h 和t,关系的嵌入表示向量为r。在TripeRE 中,对向量进行划分,具体如下:
1)关系向量r 划分为rh、rm和rt3 部分。rh表示头实体关系投影向量,用于捕捉头实体与其他实体间的关系相关信息;rm表示平移向量,用于捕捉将头实体转化为尾实体所需的信息;rt表示尾实体关系投影向量,用于捕捉尾实体与其他实体间的关系相关信息。
2)头实体向量h 划分为h1、h2和h33 部分。h1和h2分别用于在不同关系投影计算中表示头实体;h3表示辅助头实体向量,用于将头实体信息纳入到尾实体的表示中。
3)尾实体向量t 划分为t1、t2和t33 部分。t1和t2分别用于在不同关系投影计算中表示尾实体;t3表示辅助尾实体向量,用于将尾实体信息纳入到头实体的表示中。
为了确保划分后所有向量的长度一致,对划分后的向量进行归一化处理。
对于每一个实体,综合两种方法进行投影,以便更全面地捕捉实体间的关系和语义信息。下面以头实体的投影为例进行说明,尾实体的投影同理,在此不再详述。
1)在利用头实体关系投影向量rh对头实体表示h1进行投影时,引入了残差项u*e来进行调整,其中e 是一个表示关系的单位向量,它与h1进行逐元素的乘法运算,生成一个调整项。而u 则是一个超参数,根据启发式方法设置。此时头实体关系投影向量。通过引入残差项,模型可以更好地捕捉实体和关系之间的关联。残差项可以看作是对原始模型的修正,它可以帮助模型更好地适应训练数据,并提高模型的性能。
2)使用辅助尾实体向量t3与头实体表示h2进行逐元素相乘,通过该种信息融合方式增加模型的表示能力,使其能够更好地理解头实体与尾实体之间的关系。
综合上述投影操作,为三元组定义评分函数,如式(4)所示。
在知识表示训练中,通常使用正负样本来训练模型。正样本是从知识图谱中提取的真实的三元组;负样本是通过对正样本的头实体或者尾实体替换得到,用于表示与真实关系不一致的事实,或者是知识图谱中不存在的事实。基于正负样本的损失函数定义如式(5)所示。
3 实验验证
3.1 实验环境与参数
3.1.1 数据集
由于现有的开源军事知识图谱较少,本文选择从环球网的武器装备板块中爬取部分国内外的军事装备文本,并通过百度的命名实体识别技术UIE结合人工手段实现军事领域的知识三元组抽取,共抽取得到8 550 个实体、4 种关系。其中,实体涉及到军事装备、国家、单位、装备描述信息等4 种类型,关系则分为产国、研发单位、生产单位和装备4种。由于本文的方法不考虑实体或关系内部的语义信息,因此,采用索引编码实现对实体和关系的处理,每一个实体和关系均映射为唯一的数字编号,可以快速地进行实体和关系的标识和索引。表1 给出了关系的索引编码信息。

表1 关系索引编码信息Table 1 Relationship index encoding information
根据索引编码结果,对抽取得到的原始三元组进行处理,形成索引编码形式的三元组,共计10 363个,三元组编码示例如表2 所示。

表2 三元组编码示例Table 2 Example of triple encoding
对得到索引编码形式的三元组进行划分,得到训练集、校验集和测试集3 个数据集,各数据集包含元素比例为8∶1∶1。同时,为进一步提升关系的表示能力,增强知识图谱的表示能力和推理能力,通过反向原有的关系来生成逆关系。假设存在一个三元组(h,r,t),其中,h 和t 是实体,r 为关系。逆关系可以表示为(t,ri,h),其中,ri表示r 的逆关系。关系的索引编码值与其逆关系的索引编码值Cri满足:Cri=Cr+|R|,其中,|R|表示关系的总数。
3.1.2 对比基准模型和指标
本文将融合关系建模和锚节点的军事知识图谱表示学习模型与多种知识图谱表示学习方法进行对比,包括TransE、RotatE、ComplEX 等。采用以下两个指标在军事装备数据集上开展实验。
1)平均倒数排序(mean reciprocal ranking,MRR):MRR 的计算方法是对于每个查询样例,根据模型的预测结果的得分从高到低进行排序,并计算正确答案的倒数排名,最后,将所有查询样例的倒数排名取平均得到MRR 值。MRR 公式如式(6)所示,其中,N 表示查询样例总数,Ranki表示第i 次查询正确答案的排名。MRR 的取值范围在0 到1 之间,值越接近1 表示模型在排序任务中的性能越好。
2)Hits@n:表示在给定的查询样例中,模型预测结果的前n 个位置中是否包含正确答案。例如,如果n=1,表示只考虑模型的第1 个预测结果。Hits@n 的取值范围在0 到1 之间,值越接近1 表示模型在预测中的性能越好。通常n 的取值为1、3、10。Hits@n 的公式如式(7)所示,其中,Hiti表示第i次查询时正确答案是否在前n 个位置上命中,命中则Hiti值为1,否则为0。
3.1.3 参数设置
本文采用多层感知神经网络开展训练,训练次数为1 000 次,在500 次训练后,学习率设置初始学习率的十分之一。为找到最佳性能的参数,采用如下页表3 所示的参数开展训练。
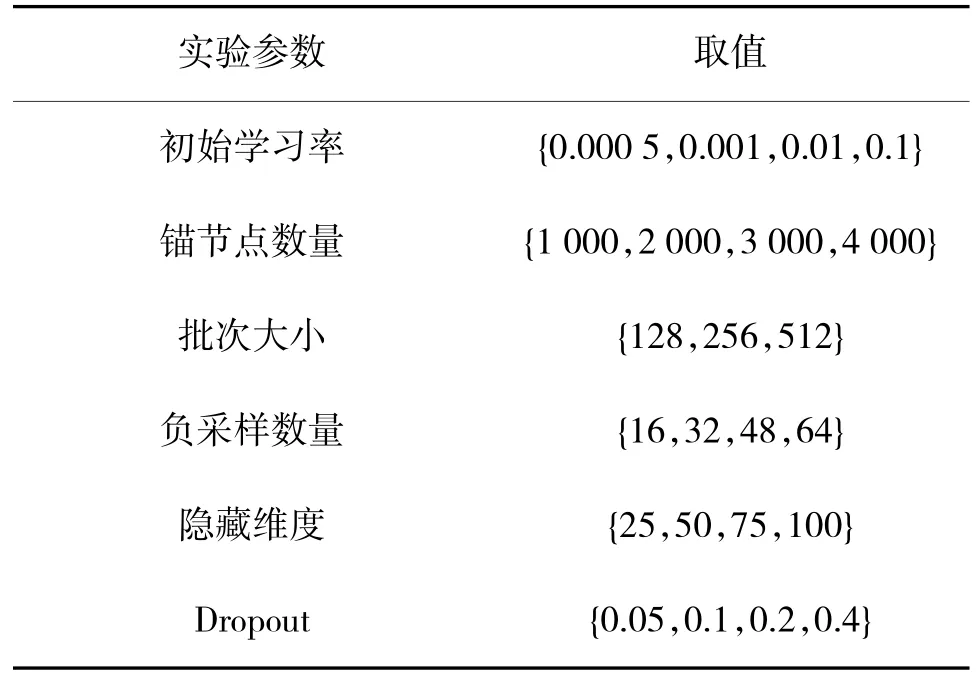
表3 实验参数设置Table 3 Experiment parameter settings
在其他参数方面,采用综合节点度、个性化PageRank 和随机的策略来实现锚节点选取,不同策略挑选的锚节点数量分别占总锚节点数量的40%、40%、20%。在计算每个实体节点和锚节点之间的距离时,考虑距离在50 以内的锚节点,并使用最多20个锚节点及这些锚节点与实体节点之间的距离表示实体节点。在关系上下文中,考虑最多5 个直连关系,关系的选择采用随机方式。
3.1.4 实验环境
实验在腾讯云主机上进行,实验环境为:操作系统Windows Server 2016,Python 版本3.8,Pytorch版本1.8.1。硬件环境为至强8255C 处理器,内存大小40 GB,显卡为NVIDIA Tesla V100 32 GB。
3.2 参数敏感性分析
在本文模型训练过程中,学习率、锚节点数量、批次大小、负采样数量、隐藏维度和Dropout 对模型的性能存在直接影响,因此,本文根据MRR 和Hits@n 对上述参数进行敏感性分析。
面向军事装备三元组数据集,上述参数分别采用表3 所列的参数范围,获得的知识表示学习结果如图4 所示,图4(a)~图4(f)分别为初始学习率、锚节点数量、批次大小、负采样数量、隐藏维度和Dropout 变化下的实验结果。由实验结果可见,在初始学习率为0.01、锚节点数量为4 000,批次大小为512、负采样数量为64、隐藏维度为50、Dropout 值为0.05 时取得最佳性能,训练时间为188 s,此时MRR值为0.878、Hits@1 值为0.853、Hits@3 值为0.89、Hits@10 值为0.927。
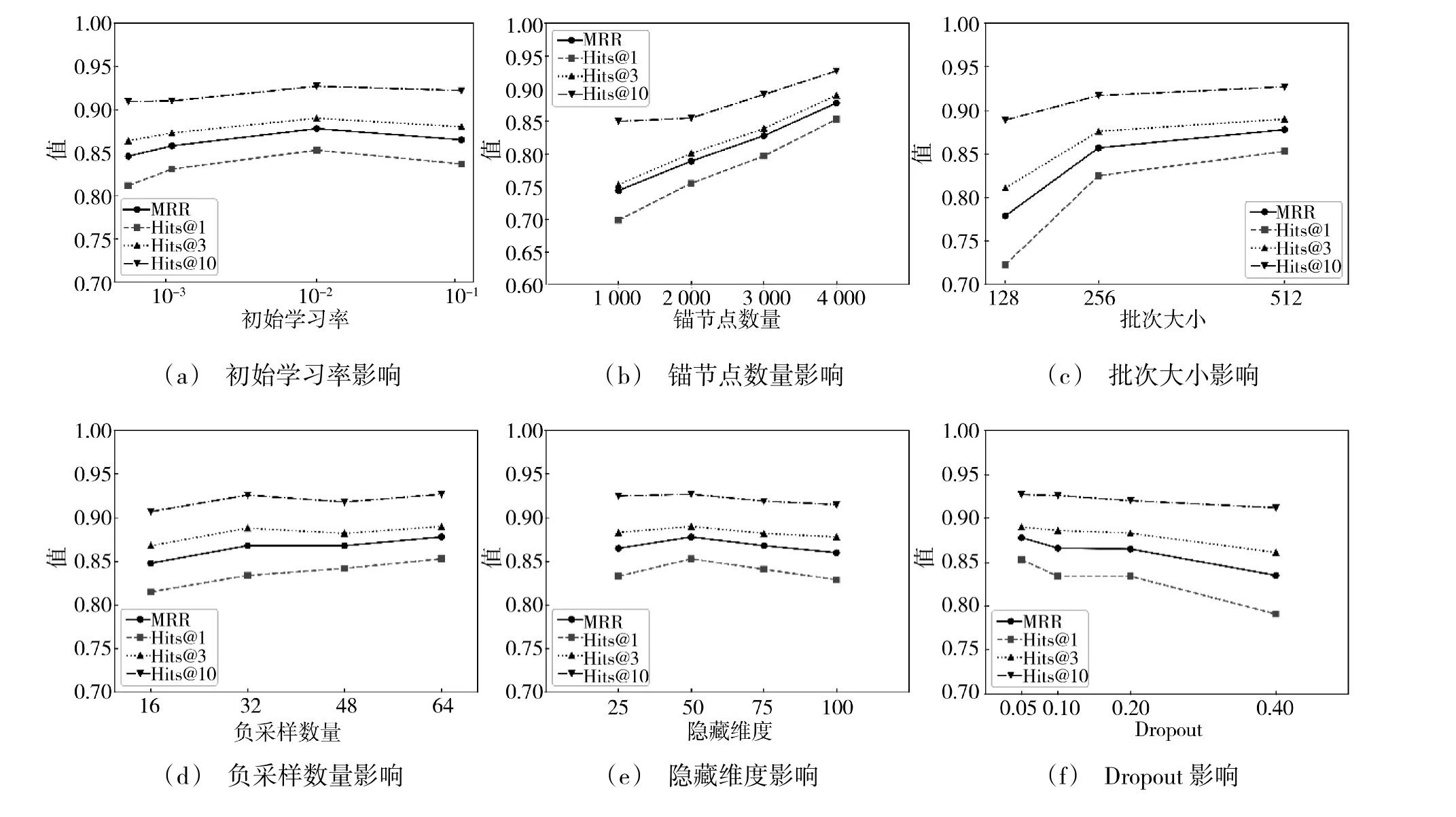
图4 参数敏感性分析结果Fig.4 Parameter sensitivity analysis results
3.3 实验结果测试和分析
实验方法采用用于评估知识图谱表示学习的链路预测任务,即给出头实体和关系,来预测直接与头节点通过指定关系相连的尾实体,即只使用单跳数据开展训练和测试,下页表4 给出了1 组关系预测结果得分排名前10 的结果示例,示例中头实体“双37 舰炮”的“产国”关系预测结果中,排名第1的“中国”为正确尾实体预测结果。
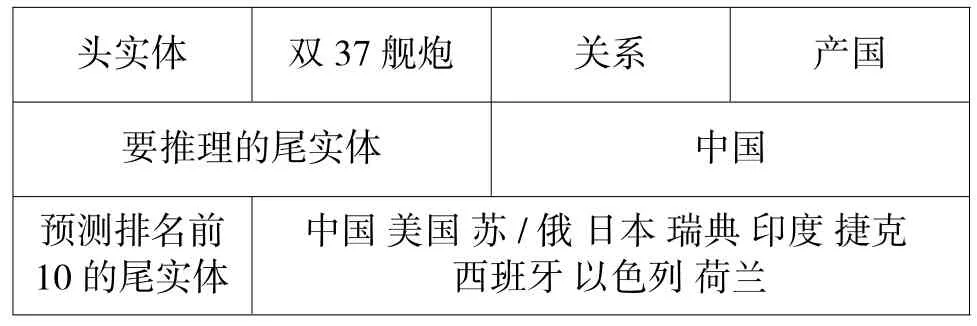
表4 尾实体预测示例Table 4 Tail entity prediction example
表5 给出了本文模型与TransE、RotatE、ComplEX 基准模型在军事装备三元组数据集上的对比结果。
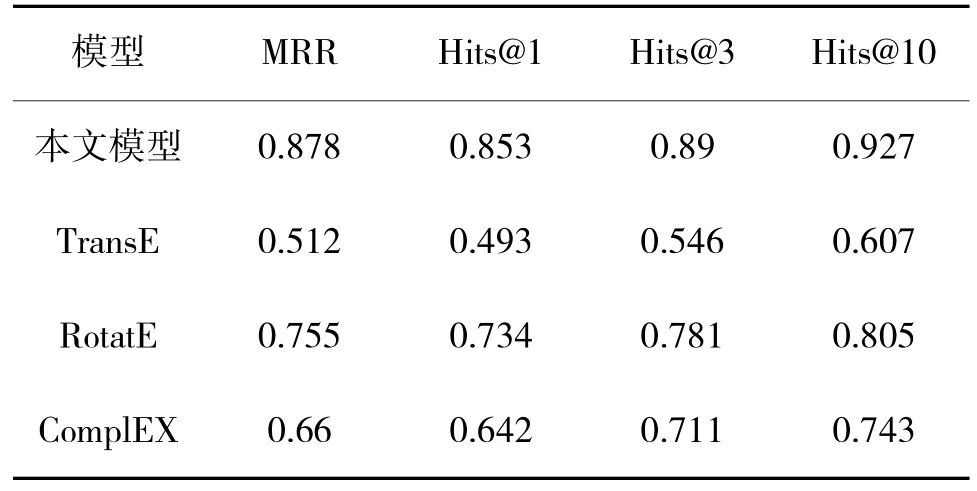
表5 单跳预测实验结果对比Table 5 Comparison of single-hop prediction results
从表中实验结果可以看出,采用NodePiece+TripleRE 方法的本文模型在MRR、Hits@1、Hits@3和Hits@10 上都取得了优势。这可能是由于以下两个原因:
1)NodePiece 编码:NodePiece 是一种基于节点的子图编码方法,它能够更好地捕捉节点的语义信息和关系结构。相比于传统的节点表示方法,NodePiece 编码能够更全面地表达关系的复杂性和语义含义,从而提高模型的准确性和泛化能力。
2)TripleRE 关系向量:TripleRE 使用多种关系向量嵌入技术捕捉实体对之间的关系信息,如关系投影向量和关系平移向量。采用多种关系嵌入方式能够更好地利用关系的多样性和复杂性,提高模型在关系推理方面的性能。
4 结论
本文提出了一种结合锚节点和三元关系向量的军事知识图谱表示学习模型。将基于锚节点的实体描述和三元关系向量融入至低维向量表示学习,实现对实体间语义相似度和关系强度的深层捕捉,并通过实验证明了其在提升军事领域内知识图谱的推理能力方面的优势。然而在大规模军事知识图谱中,某些实体和关系之间的连接可能非常稀疏,而本文模型的训练需要依赖一个较完备和准确的知识图谱,因此,对于知识图谱中隐藏的关系和实体,算法的推理结果会受到一定的限制。且对于更复杂的推理任务,例如逻辑推理和推理链的建立,本文算法的能力相对有限。未来的研究方向包括进一步优化锚节点编码和三元关系向量方法,以提升军事知识图谱表示学习的效果。此外,还需要在更大规模和复杂的军事知识图谱数据上进行实验,以验证本文方法的可扩展性和泛化能力。
