基于知识感知提示与对比调优的事件元素抽取方法*
2023-11-20孙基航胡艳丽唐九阳
孙基航,胡艳丽,唐九阳
(国防科技大学系统工程学院,长沙 410073)
0 引言
作为事件抽取的子任务之一,事件元素抽取(event argument extraction,EAE)是指抽取出具有预定义元素角色的事件元素。其包含两个子任务:事件元素识别,识别出句子中的元素;事件元素分类,对识别出的元素进行分类,得到其元素角色。EAE在诸多自然语言处理中的下游应用,例如智能问答、时间事件信息检索和机器阅读理解[1-4]。因此,EAE 吸引了许多学者的研究。为了利用预训练语言模型中包含的丰富语言知识,已经有学者为EAE 任务提出了微调的方法。这些方法通常是将文本输入预训练语言模型中获得语义表示,然后将这些表示输入到各种各样的神经网络中以抽取事件元素。例如,YANG 等在预训练模型的基础上添加了多组二分类器,每组负责分类一种元素角色[5]。然而,EAE任务与预训练模型的目标形式之间存在着显著差距,导致任务对预训练模型中先验知识的利用不够充分。
最近几年,为了弥补EAE 任务和预训练模型之间的差距,一些学者将提示学习运用到EAE 任务中[6-8],将EAE 转化为与预训练模型的预训练目标更一致的任务形式。例如,HSU 等针对每类事件设计了不同的模板,以消除EAE 和预训练模型之间的差距[9]。但是,在这些基于提示学习的方法中,对于实体知识的利用有所欠缺。此外,大部分基于提示学习的方法没有重点关注元素的表示学习。
因此,本文提出一种基于知识感知提示与对比调优的事件元素抽取方法(knowledge-aware prompting and contrast tuning for event argument extraction,KPCT)。方法通过构建知识感知模板将实体知识注入预训练模型中,充分利用数据集中的实体知识;在预训练模型后添加中心对比学习模块充分区分元素表示;最后在预测阶段使用CRF-Viterbi 解码算法提升解码效果。在ACE 2005 数据集上的实验表明,本文所提出的方法可以在诸多基线中实现最佳的效果。
本文的贡献如下:
1)提出了用于EAE 任务的KPCT 框架,创新性地设计了知识感知模板,将实体知识注入预训练模型中。
2)提出中心对比学习方法,计算文本表示的中心作为对比学习的正负样本。
3)经过实验表明,本文提出的方法能够有效解决上述问题,优于现有的基线方法。
1 相关工作
1.1 事件元素抽取研究现状
早期的深度学习方法通过使用各种神经网络来捕获事件触发词和事件元素之间的依赖关系来抽取事件元素,例如基于卷积神经网络的模型[10],循环神经网络和图神经网络[11-12]。然而,由于预训练语言模型已被证明在自然语言理解和自然语言生成方面具有强大的能力[13-15],一些基于预训练模型的EAE 方法被提出。这些方法可以分为两类:基于微调的方法和基于提示学习的方法。基于微调的方法旨在设计各种神经网络模型,以将预训练语言模型运用到EAE 任务上。根据不同的建模方式,现有的基于微调的EAE 方法可以进一步分为3 类:基于分类的方法[5,16];基于机器阅读理解的方法和基于生成式的方法[17-19]。
1.2 基于提示学习的事件元素抽取研究现状
提示学习的核心是将给定的下游任务转换为与预训练模型的训练任务一致的形式[20]。由于提示学习更好地利用了预训练模型中包含的语言知识,这种新兴范式变得越来越流行,取得了较为优秀的结果[21-22]。例如,MA 等基于预训练BART 模型[6,14],将给定的上下文和根据事件类型设计的模板分别输入到编码器和解码器中,将EAE 任务转换为生成式的任务形式,抽取事件元素的开始结束位置。
2 方法
本章形式化了EAE 任务,并提出包括框架和模型细节在内的详细方法。
2.1 任务描述
事件提及是事件抽取任务中的一项术语,是一个短语或句子,其中,描述了事件,包括触发词和相应的事件元素,事件元素是组成事件的多个核心元素,与事件触发词共同构成了事件的整体结构。如图1 所示,对于句子“A reuters correspondent said dozens of iraqi civilians and soldiers were killed in what witnesses called a barrage of u.s.artillery.”中的单词“killed”触发的“Die”事件,EAE 的目的在于抽取出事件元素“u.s.”、“civilians and soldiers”、“artillery”和“iraqi”及其分别对应的元素角色“Agent”、“Victim”、“Instrument”和“Place”。
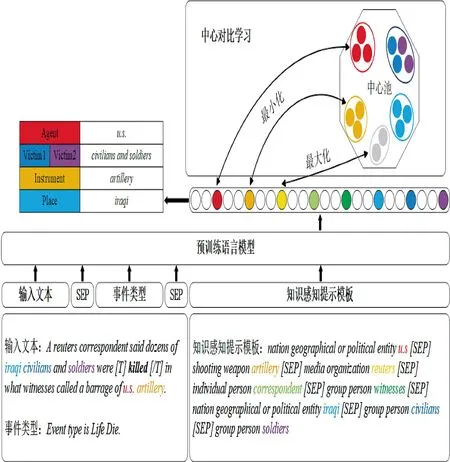
图1 基于知识感知提示与对比调优的事件元素抽取方法Fig.1 event argument extraction method based on knowledge-aware prompting and contrast tuning
2.2 算法框架
本文在预训练语言模型的基础上构建了EAE任务的解决方案。如下页图1 所示,名为预训练语言模型的模块说明了本文模型的基本工作流程:给定一段文本作为输入,使用预训练模型为每个词生成高维向量空间中的表示,然后将其输入到多分类器进行分类,得到其元素角色。
为了使模型能够充分获取实体知识并表达事件元素,本文构想了两个创新性的模块来升级预训练模型框架。KPCT 模型由3 个部分组成——编码模块、知识感知模板和中心对比学习模块。
在编码模块中,本文将输入文本的每个分词嵌入到高维向量空间中的上下文嵌入中,以便为其他模块提供语义特征。本文采用预训练的RoBERTa模型来实现这一目标[23]。
在对分词进行编码时,知识感知模板旨在使用实体类型及实体文本,构建提示学习所需的模板来向模型注入文本中的实体信息,实现知识感知的目的。
分词通过编码器的表示之后,经过中心对比学习模块来更进一步学习其表示。对比学习通过区分事件元素和非事件元素的特征来改进分词表示。在对比学习中,通过最小化分词与其类别中心的表示距离,最大化分词与非本类别中心的表示距离,本文期望调整后的分词表示在识别触发词时更具辨别力。
2.3 编码模块
本文使用RoBERTa 预训练语言模型作为KPCT 模型的编码器。RoBERTa 由24 层相同的Transformer 模块构成,相比于BERT[13],RoBERTa的模型规模更大,用于预训练的文本量也从BERT的16 GB 增长到了160 GB。
由于本文解决的是EAE 任务,通常情况下默认已知文本中的事件类型和事件触发词,因此,在输入中增加事件类型及触发词信息对于任务是有帮助的。具体来说,KPCT 模型的每个输入形式如下:
[CLS]输入文本[SEP]事件类型[SEP]…,
其中,…省略部分为下一节介绍的知识感知模板;输入文本和事件类型如图1 所示,在图示文本中,单词“killed”是当前事件的事件触发词,本文遵循WANG 等的工作[24],使用“[T]”和“[/T]”凸显其语义;事件类型则是如同“Event type is
2.4 知识感知模板
知识感知模板旨在使用实体类型及实体文本构建提示学习所需的模板来向模型注入文本中的实体信息。知识感知模板形式如下:
实体1 大类实体1 子类 实体1 文本[SEP]
实体2 大类实体2 子类 实体2 文本[SEP]…,
以图1 为例,实体“u.s.”的实体大类为“GPE”,实体子类为“Nation”,实体文本为“u.s.”。由于ACE2005 数据集中的实体大类大都为“GPE”这样的缩写词,其语义过于抽象,本文在模板中使用如下文本将其替换:
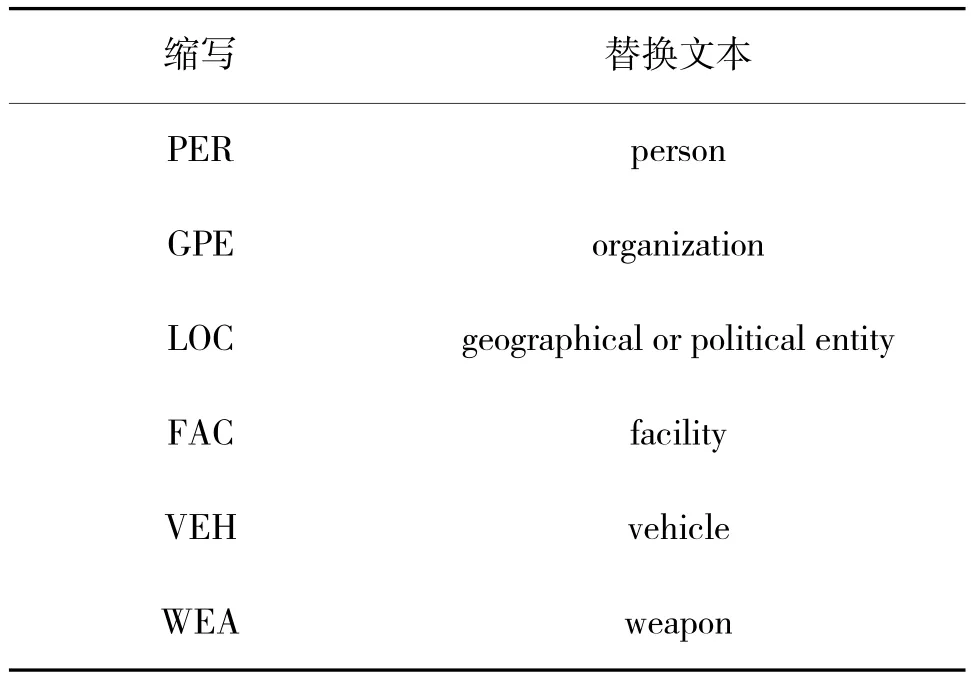
表1 ACE2005 数据集实体大类缩写替换Table 1 ACE2005 dataset entity class abbreviation replacement
因此,对于实体“u.s.”,其知识感知模板为“nation geographical or political entity u.s”。将所有单个实体的知识感知模板通过“[SEP]”连接起来,得到最终的知识感知模板,如图1 所示。模型最终的目的是学习所有实体文本的表示ei并对其元素角色进行分类。
2.5 中心对比学习
对比学习的基本思想是设计一种策略来利用原始数据集的特征同时不引入外部数据。对比学习已被证明可以有效丰富许多任务中的表示,包括但不限于知识图表示学习[25]、预训练语言模型的训练[13]和图像分类[26]等。
在对比学习算法中,样本分为三类。锚样本、正样本和负样本。例如,如果将“civilians”作为锚点,意为它是当前所需要分类的实体文本表示,则文本中的其他相同类别的词可以被视为正样本(例如,“soldiers”),不同类别的词可以被视为负样本(例如,“u.s.”)。
然而,简单的使用上述策略进行对比学习可能是行不通的。因为不是每条文本都包含相同元素角色类型的实体。因此,本文使用不同类别的中心表示作为正负样本。本文使用形如2.3 中的输入文本(但不包括知识感知模板)输入到预训练模型中,经过编码器得到每个实体在句子中的文本表示ti,根据实体对应的元素角色类别在整个训练集上计算其均值,得到每个类别的中心表示cj:
其中,T 是训练集中属于元素角色cj的实体数量。
此外,为了提高模块的泛化能力,本文不直接使用从上述模块获得的每个实体文本的表示ei,而是需要先经过一个激活函数:
其中,ReLU 是非线性激活函数,f 是全连接层。
2.6 模型的训练与预测
2.6.1 模型训练
KPCT 模型遵循多任务学习框架,所有模块都以端到端的方式进行训练。本文将中心对比学习任务定义如下:
其中,Sim 为相似度函数,用来衡量两个表示的距离,文中使用余弦相似度;xi是式(2)产生的输出,定义为经过激活后的实体文本表示;c 是由式(1)提前计算得到的类别中心;C 是类别中心的集合;TS是文本中的实体集合。
对于实体文本表示ei的分类损失定义如下:
其中,pi为xi经过softmax 多分类层得到对于每种元素角色的概率;ri为xi对应的真实元素角色类别;TS为句子中所有实体的集合;是控制损失值大小的超参数。
2.6.2 模型预测
KPCT 模型训练完成后,在使用训练完成的预训练模型与知识感知模板外,本文额外添加了一层CRF-Viterbi 解码层用于预测实体文本的元素角色类别。CRF-Viterbi 算法能够通过消除错误预测来提高模型的性能[27]。
3 实验
3.1 实验设置
本文对ACE2005 的事件抽取数据集进行评估。ACE2005 是事件相关任务中使用最广泛的数据集,包含599 个文档。所有事件被标注为8 个类型和33个子类型。对33 种组合类型分类进行评估。跟随之前的工作[10,16],将599 个文档分为529 个训练文档、30 个验证文档和40 个测试文档。
由于本文使用实体作为元素角色预测的单元,如果与元素对应的实体被预测为事件角色类型,则事件元素被正确识别。如果预测的角色类型与真实标签相同,则该元素被正确分类。上述评估方法本文称之为基于实体的评估标准。而以往方法的评估标准认为,只有当事件元素的位置和角色类型与真实事件元素匹配时,事件元素才被正确分类,可以认为是基于位置的评估标准。因此,为了对比公平,跟随之前的工作[7],使用基于实体的评估标准对之前的方法进行重新实验。评估的参数与之前的工作相同,使用精确率(P)、召回率(R)和F1 值(F1)用于评估所有方法。
使用的基线如下:1)HMEAE[16]。HMEAE 是一种分层模型,使用元素角色的上级概念及元素角色之间的联系来提取事件元素。2)ONEIE[28]。ONEIE是一个利用全局特征联合提取实体、关系和事件的框架。3)BERD[29]。BERD 是一个双向循环解码器,使用上下文实体的元素角色逐个实体地预测元素角色。4)DEGREE[9]。DEGREE 根据事件类型、事件触发词设计模板来进行事件元素抽取。5)PAIE[6]。PAIE 基于编码器-解码器架构,将给定的上下文和根据事件类型设计的模板分别输入到编码器和解码器中,抽取事件元素的开始结束位置。6)X-GEAR[30]。X-GEAR 基于编码器-解码器架构,为每类元素角色分别设计了html 风格的模板。前三者是基于微调的方法,后三者是基于提示学习的方法。具体实验结果如表2 所示。
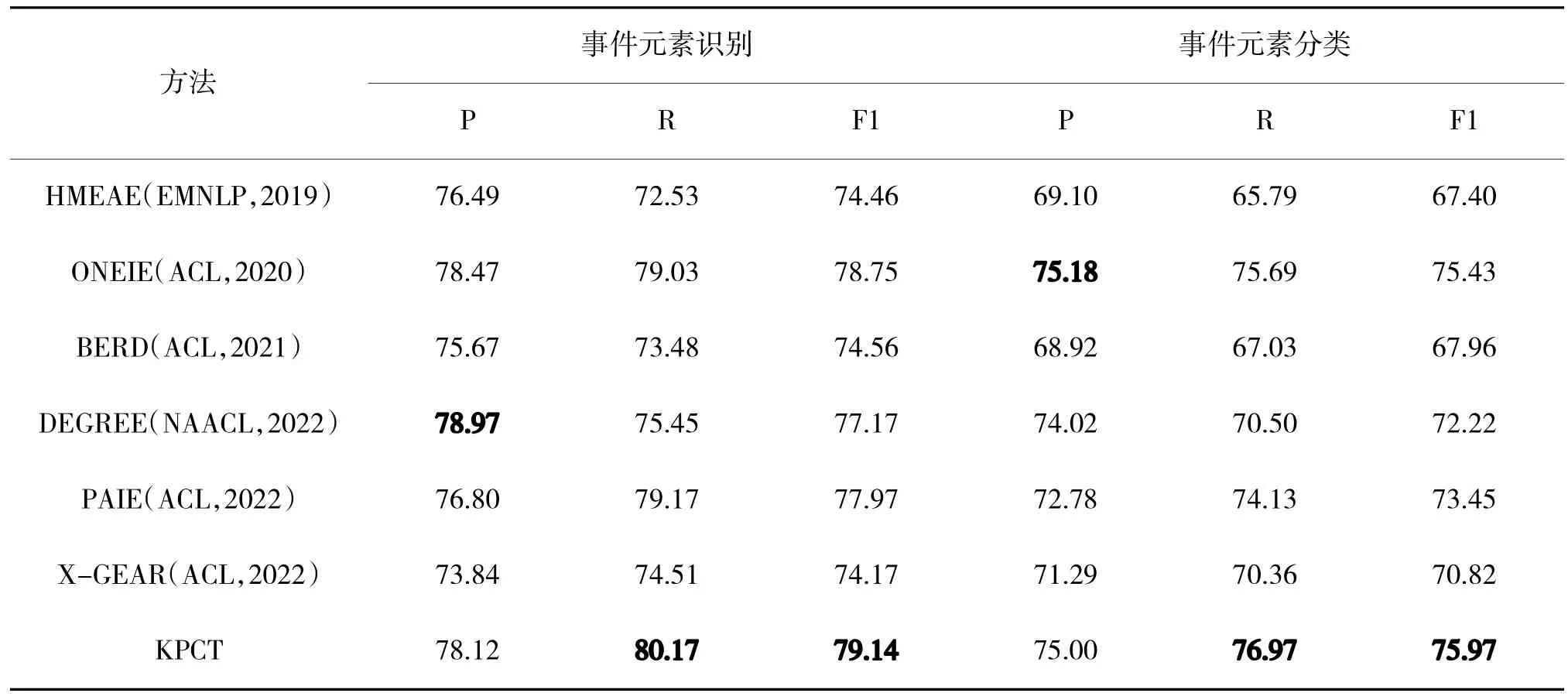
表2 实验结果对比(加粗的为最优)Table 2 Comparison of experimental results(the bold is optimal)
3.2 总体结果
经过表2 对比,可以得出以下结论:首先,KPCT 在事件元素抽取方面获得了显着的改进。KPCT 的F1 值比所有基线高0.47%以上,优于最优的ONEIE,这些结果表明,经过训练的模型确实可以通过实体来预测事件元素;其次,KPCT 作为基于提示学习的方法,效果远高于基线中同样基于提示学习的后三者(DEGREE、PAIE 和X-GEAR),说明使用实体构建模板确实达到了知识感知的目的;最后,在实际应用场景中,人们大都只关注哪个实体是事件元素,而不是实体中的哪个部分是事件元素,因此,使用实体预测事件元素是一种较为合理的方式。
3.3 消融实验
本文针对提出的方法进行了消融实验。其结果如表3 所示。
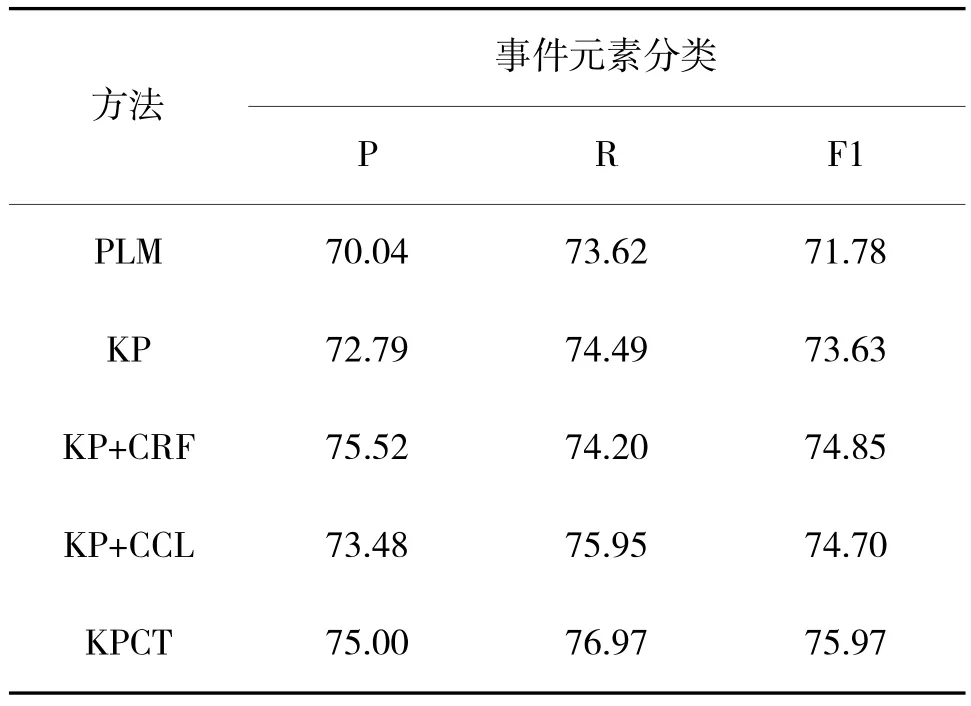
表3 消融实验结果对比Table 3 Comparison of ablation experimental results
其中,PLM 是仅使用预训练语言模型本身,对输入文本中的实体进行分类;KP 则是加入知识感知模板;KP+CRF 则是在加入知识感知模板的基础上在预测阶段加入CRF-Viterbi 解码层;KP+CCL 则是在加入知识感知模板的基础上使用对比学习区分不同类别的实体表示。可以看到,与使用知识感知模板的KP 方法相比,PLM 的效果很差;在加入CRF解码层或中心对比学习模块后,模型效果均有不同程度的提升,说明两种策略都是有效的。
4 结论
本文提出了一个EAE 框架KPCT,使用知识感知模板将实体知识注入预训练模型;针对事件元素表示不充分的问题,引入中心对比学习模块来获取帮助模型更好地区别不同类别的实体表示。综合实验表明,KPCT 模型优于目前流行的大部分EAE 方法。
本文提出的模型在模板的设计上还较为粗糙,尚处于起步阶段。在未来的工作中,可以使用动态模板的方法更进一步地提升模型效果。此外,还可以针对中心对比学习提出更多的正负样本采样方法。
