战术级分布式计算框架
2023-11-20张宗兴闫雯罡张光亚
杨 峰,谢 帅,张宗兴,闫雯罡,张光亚
(解放军32124 部队技术研究室,吉林 延吉 133000)
0 引言
人工智能技术日益发展的今天,无人化作战成为一种趋势。无人机、无人车和无人艇等智能化设备不断问世,大大提升作战效率,降低战斗风险,具有重要的战略意义,而这都得益于控制单元计算性能提升。可以预见,未来战争交战双方的算力对比将成为决定胜负的一个关键因素。在复杂多变的战场环境中,会出现许多独立的作战系统或作战小队,尽管装备单体算力有限,但如果战术级分布式计算框架合理配置多台设备的算力,也能集中算力办大事,让现有算力发挥出更好的效能,具有很大意义。
大数据和人工智能领域,已经涌现出许多优秀的分布式计算框架,2006 年2 月Hadoop 成为Apache 的独立开源项目,DENG J 等人实现了GFS 和MapReduce 机制[1]。Apache Spark 是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009 年由加州大学伯克利分校的AMPLab 开发,并于2010 年成为Apache 的开源项目之一。2011 年9月,Storm 项目发布;2014 年9 月,Nathan 向Apache提交了Storm 孵化申请。2015 年发布的Dask 是用Python 编写,是一个灵活的、开源的并行计算库。2018 年UC Berkeley RISELab 出品的机器学习分布式框架Ray[2]。2021 年GUO 等提出了一种基于无人机边缘计算的集群框架[3]。这些分布式计算框架都获得了广泛的应用,取得了成功,但是都难以完全适应战术场景。因此,本文借鉴上述框架的设计特点,提出了一种战术级分布式计算框架,并命名为魔捷(Moj)。
1 需求分析
战场环境十分恶劣,无人作战单元与外界通信常常受限,但内部还能保持高速通信,形成了内部信息高速交换的“算力孤岛”,这时合理分配算力就相当重要。例如:
无人舰上的雷达系统想要侦察到隐身无人轰炸机反射信号,这个反射信号微弱,需要将无人舰上其他系统如通信、火控、导航等系统的算力集中起来,运行更大、更深的算法模型来做雷达信号识别。
无人机械狗小队,或者四旋翼无人小队,任务中采用菱形编队时,需要将算力集中在先头、后尾和侧翼的单位上,使其视觉传感器模块反应更快,先发现对手掌握主动。
无人作战基地的无线信号战场监视系统在多个信道获取大量数据,数据中有用信息较为稀疏,超出监视系统处理的极限,但不能丢弃数据,就可以将数据发往其他系统,协助筛查有用信息。
综上,在战术场景下,无人作战系统、作战小队或者作战基地通常需要在作战的某个阶段将大量算力集中在某个作战单元上,使其大幅度提高作战性能,作为战场上的突破点帮助无人作战单元战胜当面之敌。在对于当前任务单个节点计算能力不足且多个节点之间通信速率极高的情况,控制单元通过分布式计算框架将算力合理分配,使得某个无人作战单元在精度、速度和频率3 个层面的战斗力得到提升,如图1~图4 所示。

图1 原始模型Fig.1 Original model
图1 中节点1 做了两次相同的计算过程,耗时都是T1,由执行器2 输出结果,耗时T2,是一个常见计算模型的简化表达。其中,节点拥有多个执行器,执行器是一个执行任务的进程,考虑到效率,初始化情况下执行器的数量与节点计算核心数量相当。
图2 与图1 相比,通过分布式计算框架获得了另两个节点的算力,能够使用更大、更深、参数更多的AI 模型,输出结果可能时间滞后了,但是结果更加精准。从结果上看就是:雷达目标识别更加精准,图像目标检测识别更小的目标,对环境变化作出更明智的决策等。

图2 精度提升模型Fig.2 Precision improvement model
下页图3 与图1 相比,通过分布式计算框架获得了另一个节点的算力,通过任务拆解,将原本节点1 上作两次串行计算变成分别在节点1 和节点2作1 次并行计算,在忽略通信消耗的情况下,节约时间T1。从结果上看就是:图像或雷达目标检测速度更快,对当下环境变化更快地作出决策,密码破译更快等。

图3 速度提升模型Fig.3 Speed improvement model
图4 与图1 相比,通过分布式计算框架获得了另两个节点的算力,当实时的流式数据量超过本机检测的极限时,将数据分发到多个节点做计算,避免抛弃数据。t1数据在节点1 计算,将t2、t3时刻的数据分发到节点2 和节点3 计算,提高检测的频率,但没有提高实时检测反应的速度ΔT。从结果上看就是:对战场数据监视更加全面;对外界环境感知更加敏感等。
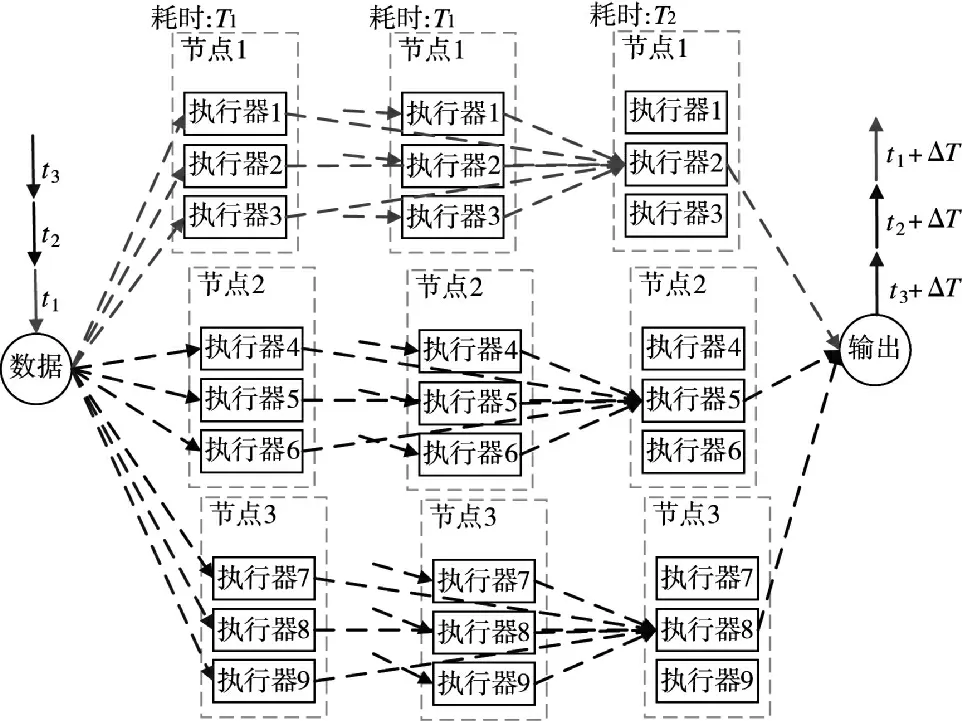
图4 频率提高模型Fig.4 Frequency improvement model
战术级分布式计算框架要达到上述性能提升目标,也要考虑适应战场复杂的环境,如通信系统受到干扰,内部关键节点受到打击而失效,敌方获取试图进入系统等等问题,现有的分布式计算框架要达到上述目标,都有一定的不足之处。与MapReduce 机制处理分布式文件系统中的数据存在大量的I/O 消耗不同,战术级分布式计算框架更像流处理框架Storm,通过网络直传和内存计算尽可能提高计算速率,但是Storm 输入形式和原语对机器学习不友好。Dask 是一个轻量级的Python 并行计算框架,适用于中等规模集群,但是主要应用于数据科学领域,对机器学习并不友好。Ray 是一个通用的集群和并行计算框架,可以用来构建和运行任何类型的分布式应用程序,实现了大量机器学习的算子,但它是典型的Master-Slave 的设计,不利于高容错和自恢复,而且不够轻量级。综上所述,战术级分布式计算框架应是一款轻量级的支持多种语言和多种异构处理器的机器学习分布式计算框架,适用于中小规模集群,并具有自组织、高容错、自恢复、安全可靠的特点。
2 Moj 理论模型
分布式计算框架对开发者屏蔽了分布式计算底层复杂逻辑,自动处理开发者提交的计算任务。自动处理分布式计算的难点有通信、调度、同步、容错等,处理复杂程序的节点还要能够自动获取环境依赖,考虑到战场网络对抗强度,安全性设计也是重要环节。这一节区分通信模型、任务模型、内存模型、资源调度模型、环境依赖模型、容灾控制和安全设计7 个方面介绍魔捷。
2.1 通信模型
魔捷使用高性能网络通信模型来降低分布式计算IO 消耗,高性能网络通信模型主要有Reactor和Practor 两种模式,Reactor 是非阻塞同步模式,而Proactor 是非阻塞异步模式,都可以采用多线程模型。
Reactor 模式是netty 的常用模式,建立在IO 多路复用的基础上,用户程序发起IO 请求后立即返回。如图5 所示,读数据时,内核负责监听已经建立连接的socket 列表,当有socket 发生可读事件时,在内核数据缓冲区准备完毕后,内核通知用户程序来将缓冲区数据拷贝到用户程序的内存空间;写数据时,用户程序发起写请求后立即返回,内核负责在写事件就绪时通知用户程序,将数据写入数据缓冲区,完成一次写事件。
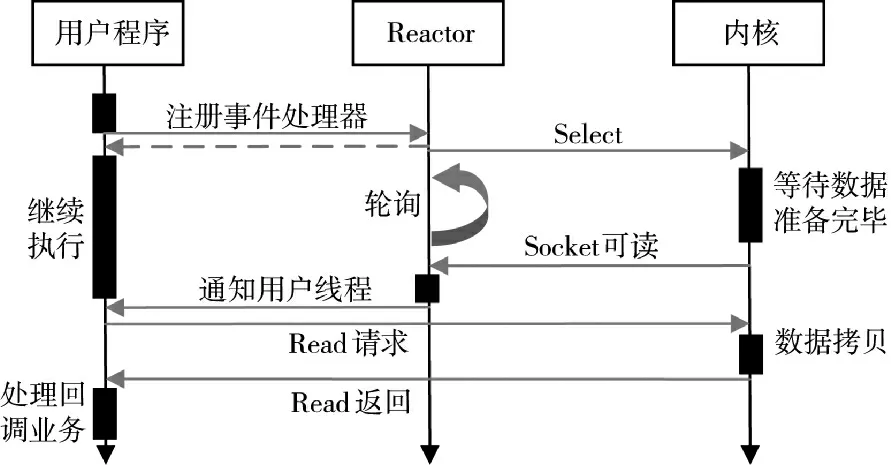
图5 Reactor 模型Fig.5 Reactor model
Proctor 模式建立在异步IO 基础上,用户程序发起IO 请求时,将用户程序的数据缓冲区地址传递给内核,然后用户程序返回。如下页图6 所示,读数据时,内核负责监听已经建立连接的socket 列表,监听的是数据传输完成事件,内核通知工作线程时,数据已经由内核拷贝到之前注册的用户程序数据缓存区,用户程序可直接进行逻辑处理;写数据时,用户程序发起写请求时将用户程序数据缓存区地址传递给内核,内核负责在写事件就绪时,将数据从用户程序缓冲区拷贝到内核数据缓冲区,并通过socket 将数据发给网卡完成一次写事件。

图6 Proactor 模型Fig.6 Proactor model
Reactor 模式实现了一个被动的事件分离和分发模型,实现相对简单,在耗时短的处理场景处理更高效。Proactor 模式实现了一个主动的事件分离和分发模型,这种设计允许多个任务并发的执行,并发性能更高,能够处理耗时长的并发场景,但编程难度更大。考虑到战术级分布式计算框架节点之间频繁的数据交换,其中不乏流式数据,IO 消耗较大,魔捷采用Practor 模式,基于boost:asio 网络编程框架开发,降低了系统IO 消耗,配合gRPC 框架使用,提升任务远程调用的效率。
2.2 任务模型
任务是一种非阻塞原子计算,完全在一台机器上执行。任务分发和远程执行过程需要规定调用标准,最基础的方法是基于TCP/IP,通过socket 编程去实现调用方和被调用方,但是socket 编程的难度大,实现复杂。NELSON B J 提出机器之间互通这种远程调用的标准RPC(remote procedure call)即远程过程调用[4]。RPC 标准分为3 层,RPCRuntime 负责最底层的网络传输,stub 层处理客户端和服务端约定好的语法、语义的封装和解封装,用户和服务层负责处理业务逻辑。
主流的远程过程调用框架有简单对象访问协议(SOAP)、gRPC 和REST。SOAP 基于XML,通过HTTP 进行传输;gRPC 由Google 开源,是现在最流行的二进制RPC 框架之一;REST 准确地说是一种编程风格,基于JSON 文本格式,简洁易懂。考虑到效率,本框架基于gRPC 协议完成任务的远程调用。
任务可以分为无状态的任务和有状态的任务。无状态的任务对应基本函数,由Moj.R 装饰,可以直接进行远程调用,并且调用过程是异步的,调用后会马上返回一个回调对象,未来可以通过这个对象来获取实际运行的返回。有状态的任务对应类方法,引入actor 并发编程模型,actor 模型本身封装了状态和行为,只需要关注消息和其本身,而消息是一个不可变对象,所以actor 模型不需要去关注锁和内存原子性等一系列多线程常见的问题。Actor 本身是一个类对象,调用前先将类进行实例化或者通过远程方法返回获取实例,且actor 创建时分配到固定的执行器。
图7 是分布式任务add.R(a,b)的远程调用过程。第1 步,用户程序向本地调度器提交add(a,b);第2 步,本地调度器将其转发给全局调度器;第3步,全局调度器在全局对象表中查找add(a,b)的依赖的位置;第4 步,决定在存储自变量b 的节点N2上调度任务;第5 步,节点N2 的本地调度器检查本地对象库是否包含add(a,b)的依赖;第6 步,本地对象库不具有对象a,则在全局对象表中查找a 的位置。第7 步,得知a 被存储在N1,N2 的本地对象库复制它到本地。第8 步,由于add()的所有依赖现在都在本地对象库,因此,本地调度器在本地的执行器调用add();第9 步,add()通过共享内存访问这些依赖。

图7 远程任务调用Fig.7 Remote task call
如下页图8 所示,式在N1 处执行Moj.get()和在N2 处执行add()后结果返回过程。第1 步,在N1调用Moj.get(IDc)时,用户程序检查本地对象库中是否存在add()返回的future IDc;第2 步,由于本地对象库不存在c,因此,它在全局对象表中查找c 的位置,但此时,c 尚未创建,N1 的本地对象库向全局对象表注册一个回调,当c 被创建时,该回调将被触发;第3 步,在N2 中add()完成其执行,将结果c 存储在本地对象库中;第4 步,N2 将c 的引用添加到全局对象表;第5 步,全局对象表用c 的引用触发N1 的本地对象库的回调;第6 步,N1 从N2 复制c。第7 步,N1 本地对象库将c 返回给Moj.get()。至此,一个完整的远程任务调用的过程就完成了,至于有状态的任务actor,在创建实例时已经分配了执行器,actor 的相关任务调用都在该执行器完成,其他执行过程与普通任务执行过程类似,不再赘述。

图8 远程任务结果返回Fig.8 The return of remote task results
2.3 内存模型
为了最大限度地减少任务延迟,魔捷用一个内存中的分布式存储系统来存储每个任务的输入、输出和无状态计算结果。在节点上,使用Apache Arrow作为数据格式,通过共享内存实现对象存储和传输,这允许在同一节点上运行的任务之间共享零拷贝数据。如果任务的输入不是本地的,则在执行之前将输入复制到本地对象库,同时将其输出写入本地对象库。任务仅从本地内存读取数据和写入数据,消除了由于热数据对象引起的潜在瓶颈,最小化任务执行时间。为了降低延迟,魔捷将对象完全保留在内存中,并将它们按照LRU 策略添加到磁盘,防止意外丢失。
与现有的集群计算框架如Spark 和Dryad 一样[5-6],对象存储仅限于不可变数据。不更新对象,就不需要复杂的一致性协议,简化了对容错的支持。在节点故障的情况下,魔捷通过沿袭重新执行,恢复任何需要的对象,存储在全局控制中心的沿袭在执行期间跟踪无状态任务和有状态的任务,使用前者来重建存储中的对象。为简单起见,魔捷的对象存储不支持分布式对象,即每个对象适合单个节点;分布式对象,比如大型矩阵或树,可以在应用程序级别实现。
如图9 所示,a、b 是小对象,c 是大对象,存储的方式有差别。小于一定大小的对象就存储在执行器进程内部,通过进程间远程过程调用传递,这个大小的典型值为100 Kb,用户可以设置这个值。如果超过一定大小,就通过Apache Arrow 的Plasma 共享内存来传递,通常在进程内会有一个占位的对象,标记对象已经提交到了共享内存。本地对象库在内存将要溢出时将部分对象持久化存储到磁盘,使用时再读入内存缓冲区。

图9 对象存储的位置Fig.9 The location of the object storage
大部分的Moj 元数据都通过一种去中心化的概念来管理,叫做所有权。每个执行器进程管理并拥有它提交的任务以及任务的返回对象和通过Moj.put 创造的对象。这个所有者对任务是否执行以及返回对象对应的值是否能够被解析负责。所有权机制的提出可以解决中心化负担过重的问题,把很多处理逻辑让任务的调用进程来处理。当执行器进程就把对象存储在它的本地共享内存时,这个对象就被称为主拷贝,其他进程通过分布式对象解析的协议来获取一个普通拷贝,普通拷贝可以通过LRU 策略回收。但主拷贝只有在其引用计数为0 时才能被回收。共享对象的引用计数在引用该对象任务提交的时候递增,在任务完成的时候递减。
2.4 资源调度模型
在战术级分布式计算框架中,资源调度的单位是执行器进程,每个执行器进程被本地调度器分配唯一的16 位UUID,以及一个IP 地址和端口,IP 地址和端口是可重用的,但是UUID 随着进程的销毁而销毁。初始化时,为兼顾节点的执行效率,依据节点的处理器核心的数量构建与之数量相当的执行器进程池。本地调度器通过心跳消息将本地资源使用情况告知全局调度器,全局调度器同时广播维护的全局资源使用情况,这样本地调度器就有全局所有资源的使用情况。在用户程序向本地调度器提交任务时,本地调度器优先调度本地资源,本地资源不能满足任务需求时,根据全局资源使用情况,直接调度全局资源,这样完成分布式的调度流程,减轻全局调度器的调度压力。
对于有状态的actor 在创建实例时,已经由本地调度器分配了一个执行器,actor 实例方法的远程调用都在该执行器上执行。而无状态的远程任务在调用时,再由调度器分配资源。本文将数个无状态的任务和有状态的任务的集合称为一个工作组,将一个工作组的动态运行时远程调用的过程描绘为一个动态任务流图,根据这个动态任务流图,调度器可以从全局的角度去调度资源。
图10 是一个简化的监督学习模型分布式训练过程的动态任务流图,为了方便与下页图11 的Python 代码对照理解,用英文做标注。其中椭圆表示有状态的任务和无状态的任务,长方形表示对象,实线箭头是数据流,虚线箭头是控制流,空心箭头是有状态任务流。当代码调用trainTask.R()时,用户程序将该任务提交到本地调度器,本地调度器通过解释器生成动态任务流图,参照通过心跳信息同步的全局资源的使用情况,进行分布式调度。当代码执行Moj.get 时,用户程序阻塞等待,在当分布式计算框架如代码描述的经过10 000 次随机梯度下降算法更新权重,把计算结果返回给用户程序时,用户程序才被唤醒,然后继续执行下面的代码,完成一次监督学习分布式训练。

图10 监督学习训练的简化动态任务流图Fig.10 Simplified dynamic task flow chart for supervised learning training
本地调度器通过动态任务流图和代码中任务对资源的显示需求,优先考虑本地资源,本地资源不满足的情况考虑其他各节点的负载情况,作出调度决策。更确切地说,本地调度器通过心跳获得每个节点处的任务队列大小和节点资源可用性,以及任务输入的位置和它们的大小,并使用简单的指数平均来计算平均任务执行时间和平均传输带宽。调度器筛选具有任务所请求类型的足够资源的节点集合,并且从这些节点中选择估计等待时间最低的节点。等待时间包括任务将在某节点处排队的估计时间,即任务队列大小乘以平均任务执行实际和任务的输入流的估计传送时间,即远程传输的总大小除以平均带宽。
本地调度器还支持优先级调度,用户程序可以在提交任务的时候指定任务的优先级,优先级可以设置为1 到16,数字越小优先级越高,默认优先级为16。对于分配到同一个节点的任务,在任务等待队列中,优先级越高被优先调度执行的概率也越高。对于优先级为1 的任务及其派生任务,会认定该任务及其派生任务是长期循环执行的任务,调度器将这些任务看作一个工作组,采用自适应的优先级调度策略调度工作组内的任务。调度器跟踪任务的执行节点、执行时间和执行状态并记录。具体做法是先利用SHA1 算法获取任务代码的哈希值;再通过哈希值查询调度记录,如果没有记录,以该哈希值为key 生成新的调度记录;最后结合工作组的动态任务流图与任务记录,以缩短任务执行总时间为目标对任务做出自适应的调度。
调度器再次分配工作组中的并行任务时,查询所有节点平均任务执行时间和平均传输带宽加权和,作为节点执行效率;然后将任务执行记录中平均耗时较长的任务分配给执行效率高的节点。并行任务的分配随着自身平均执行时间和节点执行效率变化而变化,动态调整趋近理想分配方案。例如,在动态任务流图中,任务A 和任务B 的起点与终点都相同,是并行任务,且A 的计算复杂度低于B。在初次调度时,调度器并不知道任务执行复杂度,将A分配到执行效率较高的M 节点,将B 分配到执行效率较低的N 节点,导致B 任务计算耗时远大于A。再次调度A 和B 时,将A 分配给N 节点,将B 调度到M 节点,这样两个任务结束的总耗时缩短了。
主流的分布式计算框架可以部署在AWS 云、华为云或者阿里云等云计算平台上,可以弹性伸缩,自动在集群上增加节点,但是战术级分布式计算框架通常运行环境资源受限,不能弹性伸缩。为了防止可能会出现资源不能满足任务需求的情况,魔捷使用了与决策高度统一的资源调度模式。分布式计算框架提供api,将现有系统资源的使用情况实时反馈给调用该api 的决策模块,决策模块根据现有资源选择适合的算法模型防止系统资源不足。
2.5 环境依赖模型
用户程序在集群上运行时,除了脚本,还需要导入一些依赖,例如脚本引入的一些特定的包、环境变量和其他文件等等。如任务分布式执行时,某些执行器所在的节点不存在相应的依赖,可能会遇到ModuleNotFoundError、ConfigurationNotFoundError和FileNotFoundError 等问题。为解决这个问题,用户程序的环境依赖可以通过两种方式引入,一种是在搭建集群环境时安装,另一种是在运行时安装。参与集群的节点可能是完全不同的设备,执行器的运行环境可能大不相同,因此,在任务远程调用的过程中不能期望远程任务的依赖都预先安装在远程节点上了,常常需要运行时安装依赖。在主流的分布式框架中提供了conda、pip、和npm 等方式使得运行时环境可以依赖远程资源库动态扩展,但是战术级分布式框架所在网络环境中没有管理各种安装包的服务器,因而不能采用这种方式。
如图12 所示,用户程序向本地调度器提交任务,本地调度器根据全局资源使用情况分布式调度,其他节点再向用户程序所在节点拉取运行时环境相关文件。用户程序在提交任务时,通过runtime_env 字段为任务显示配置运行时环境,作为其他节点拉取运行时环境相关文件的依据。节点1 运行一个文件传输服务,将依赖相关文件都放在RuntimeEnvironment 目录下,runtime_env 显示指定了任务my_task 依赖的类型和文件的URL,runtime_env={"pip": ["/root/RuntimeEnvironment/pip/my_moudle.whl"]},本地调度器将my_task 调度到节点2 上执行。节点2 就会从节点1 拉取my_moudle.whl 文件,缓存到相应工作组的目录下,然后通过pip 安装到本地,这样用户脚本就能通过import my_moudle 引入相关依赖。如果runtime_env 指定环境依赖的类型是files,那么节点2 拉取相关文件后就放在对应目录,不做安装。如果runtime_env 指定环境依赖的类型是EnvironmentVariable,那么节点2 拉取相关描述文件后将其中的环境变量注册到系统中。如果runtime_env 指定环境依赖的类型是docker 镜像,节点2 拉取文件后,会安装该docker 镜像,在镜像中执行任务。
用户程序可以给一个工作组配置运行时环境,也可以每一个任务单独配置运行时环境。当一个节点上的两个任务的运行时环境中引入同一个包的版本不同时,可能会产生冲突。开发人员在用户代码中检测引入的依赖模块的版本再做出相应的处理是非常繁琐的,因此,对于开发中的项目使用安装包安装运行环境,对于投入使用的项目,多个节点使用统一的docker 容器来解决依赖环境的问题。每个节点上针对同一个工作组缓存一定量的Runtime 环境资源,以便在同一个工作组中的不同运行时环境中快速重用,各个工作组缓存10 GB 的依赖资源,要更改此默认值,可以修改每个节点上的yaml 设置文件中 MOJ_RUNTIME_ENV_MYGROUP_ CACHE_SIZE_GB 字段的值,例如MOJ_RUNTIME_ENV_MYGROUP_CACHE_SIZE_GB=15。
2.6 容灾控制
容灾控制忽略失败的能力可以使应用程序更容易编写,因此,容灾控制就是分布式式计算框架的重要一环,而对于分布式计算框架,本文主要考虑的是分布式任务异常和节点异常两个方面。
在MapReduce 和Dryad 中,如果一个任务的后台服务进程异常,该任务就会完全失败。例如,Hadoop 的JobTracker 异常退出,分布式执行的任务都会失败,并且后台服务进程异常通常会导致多次重复提交作业的用户程序异常。但是在CIEL 中[7],所有任务状态都可以从沿袭任务表中派生出,持久化存储每个工作组的沿袭,允许失败的任务重新获取资源并快速恢复执行,CIEL 提供了持久化保存沿袭、主从master 和对象表重构3 种容灾机制。魔捷采用相似的策略,用redis 内存数据库对任务执行过程的产生的数据进行缓存,并且定期将redis 数据刷新到磁盘中。在通过gRPC 分布式远程异步调用任务异常后,本地调度器会先进行重试,默认重试的次数为3,这个次数可以通过参数动态设置,也可以在配置文件中修改全局配置。重试失败后,本地调度器会查看本地任务缓存、对象表和任务沿袭,对任务数据进行恢复,以达到任务异常自恢复目的。
普通节点因为通信、系统或者其他原因异常下线,全局控制中心在一定时间内监控不到该节点的心跳消息,判定该节点异常,便从资源表中删除该节点,从对象表中减少该节点对象的引用计数,转移该节点拥有对象的所有权,删除该节点发起的根任务并根据任务沿袭通知相关节点。对于全局控制中心,魔捷在Redis 之上构建了一个轻量级的链复制层,兼顾高吞吐量和高可用性。为防止全局控制中心异常下线,魔捷引入哨兵模式,每个节点都运行着一个哨兵进程,哨兵发现全局控制中心异常下线,则通知全局控制中心的哨兵,尝试重启全局控制中心。重启失败,则发起重新选举新的全局控制中心的广播,如果有多个哨兵同时发出选举广播,则由时间搓最早的哨兵负责根据资源和通信带宽等因素选出新的全局控制中心。
2.7 安全设计
分布式计算增加了网络通信的开销,一旦攻击一方监听到这部分数据流量,就为分析我方通信和网络体制提供了数据支撑,因此,分布式框架的部署对网络安全设计提出了更高的要求,身份认证和加密数据传输是必要的手段。魔捷的安全控制中心借鉴kerberos 协议的认证授权流程,并建立了密钥定时更新的机制,节点与节点之间利用安全套接字建立连接,确保用户数据安全传输。安全控制中心和全局调度器位于同一个节点,由注册服务、票据授权服务和数据库3 部分构成。在节点被选举为全局控制中心后,便将自己的公钥和服务端口信息广播给其他所有节点,同时启动本地的安全控制中心。安全控制中心在所有节点都有备份,并配置完毕,提供注册服务和票据授权服务,数据库中包含节点用户和密码等注册准入信息,具体安全认证机制流程如图13 所示。

图13 安全认证机制流程图Fig.13 The flow chart of security authentication mechanism
如图13 所示,第1 步,节点1 通过安全客户端,将利用注册服务的公钥加密的用户名和密码等注册信息发送给注册服务;第2 步,注册服务访问数据库并比对注册信息,比对成功后利用自己的私钥加密该用户的基本信息和一个随机数生成证书,并在数据库保存该证书;第3 步,注册服务将证书返回给节点1;第4 步,节点1 将证书发送给票据授权服务;第5 步,票据授权服务先访问数据库比对证书,比对成功后,解密该密钥获取用户基本信息,与发送客户端IP、端口、用户名物理地址等基本信息一致,则用自己的授权服务私钥制作包含节点1基本信息和失效时间搓的票据;第6 步,将票据和自己的授权服务公钥返回给节点1;第7 步,节点1和节点2 都通过安全控制中心获得票据和公钥后,先交换票据,互相验证票据成功后,通过TLS 协议建立安全套接字连接,一段时间后票据失效,连接断开,节点从第4 步开始重新获取票据。
该安全认证机制主要有两方面的考虑,一方面,通过票据的失效机制,重新建立安全套接字连接,使得数据传输的密钥定期更新,防止攻击方破解我方数据传输密钥;另一方面,将票据发放和注册分开,防止在全局控制中心暴露了服务接口的情况下,攻击方通过仿造票据的方式接入分布式计算框架。
3 Moj 架构设计
魔捷致力于提供一套针轻量级对分布式系统的通用API,添加尽量少的代码,使得一个单节点的应用能够分布式地在多个节点上运行,以获得更好的性能。为支持多种语言的分布式调用,魔捷采用分层设计思想,将整体架构分为应用层和系统层。系统层为应用层提供了一套基本原语;应用层可以通过装饰器或接口的方式调用系统功能,支持多种语言调用。
如图14 所示,应用层主要由执行用户代码和分布式任务的执行器构成,执行器可以分为executer、driver 和actor 3 种。executer 是一个完成无状态分布式任务的进程;driver 是直接执行用户代码的执行器进程;而actor 是执行有状态任务的进程。executer、driver 和actor 都可以向本地调度器提交任务和创造对象,可以作为任务和对象的所有者。系统层为应用层提供服务调用接口,是用C++语言编写的,具有跨平台特性,主要包括节点的本地对象库、本地调度器和全局控制中心(GCC),以及全局控制中心的UI 界面和分析、调试和错误诊断工具。

图14 整体架构Fig.14 Overall architecture
全局控制中心由节点自主选举产生,也就是说每个节点都部署了全局控制中心的完整代码,但没有激活。全局控制中心与GCC_client 建立心跳信息机制,同步生成的任务表、对象表和延迟表等全局信息。各节点的本地调度器维护了一套完整的任务调度体系,通过心跳信息获取全局信息后,可以完成分布式的全局资源调度。
图15 将节点程序模块化地展示出来。一个计算机系统成为分布式计算的节点是由用户代码的start_node 函数开始的,运行用户代码的执行器称为driver,driver 可以提交任务和实例化actor。Driver 初始化节点时,开启了内存数据共享服务,开启本地调度器,初始化执行器进程池,注册到内存数据库,绑定到一个执行器。与此同时driver 可以通过arrow获取共享对象,通过task 模块提交任务等操作。

图15 节点程序模块框架Fig.15 Framework of the node program module
Executer 初始化后,可以通过GCC_client 访问全局调度器,获取对象表和依赖表等信息。通过local_sheduler_client 访问本地调度器,可以获取相应的资源和信息。通过task_manager 接收用户代码提交的任务,然后对任务进行封装,包含内存引用计数、任务ID、重试次数等信息。任务封装完毕后,通过task_submiter 提交给本地调度器。
在本地调度器中,main 函数首先被调用,进行配置和初始化。其中,accept_handler 接收executer的连接请求和消息,消息基于asio 异步通信机制把读写进行了异步封装,保证了效率。根据配置的调度策略对executer 提交的任务进行调度,优先分配给本地执行器。也就是将任务放入本地调度队列,在本地资源不能满足任务时,通过GCC_client 提交给全局调度器。Node_manager 管理分布式任务工作组的沿袭和本地任务队列,通过rpc_server 调度本地的执行器有序的执行任务,这个执行顺序会根据用户代码指定的任务优先级改变。Objec_manager 则负责内存管理和数据共享。容灾控制中心、依赖管理中心和安全控制中心实现细节参考第2.5、2.6 和2.7 节。
4 结论
本文从需求分析、理论模型到架构设计,提出一种适用战术场景的轻量级分布式计算框架,名为魔捷。魔捷区分应用层和系统层,应用层为用户提供了多种语言支持的API;系统层采用C++编写,具备跨平台能力。并且魔捷采用一种自适应的优先级调度算法提高系统性能;引入哨兵模式加强系统的容灾能力;提出一种适用于局域网内使用的依赖构建机制;设计了身份认证、多重加密与密钥定期更新的机制,提高系统的安全性能。下一步将致力于提高循环任务执行效率、缩短系统灾难恢复时间和系统安全性能测试;在代码模块实现时,合理调整程序模块架构,做到高内聚、低耦合和易扩展的同时,减少用户程序从单节点迁移到分布式的额外代码和配置。
