用于通用目标跟踪的图记忆跟踪器
2023-11-10席佳祺陈晓冬蔡怀宇
席佳祺,陈晓冬,汪 毅,蔡怀宇
用于通用目标跟踪的图记忆跟踪器
席佳祺,陈晓冬,汪 毅,蔡怀宇
(天津大学精密仪器与光电子工程学院,天津 300072)
基于匹配的跟踪算法能够将特定目标的识别问题转化为模板匹配问题,具有较高的响应速度和跟踪精度,这使它在通用目标跟踪中占有优势.然而,此类算法缺乏在线适应性和对特定数据的针对性,难以应对目标和跟踪场景的复杂变化.针对这一问题,提出一种基于图结构的图记忆跟踪器以提升通用目标跟踪的准确性.首先,利用图的节点匹配机制实现目标先验知识与搜索输入的点对点局部匹配,并根据匹配结果定位目标位置.其次,利用目标位置信息生成新模板.为抑制相似实例的干扰,根据相似实例分类响应呈现多峰的特点对新模板进行动态筛选.最后,将经过筛选的新模板作为候选信息存入存储模块.为了防止筛选失误引起后续错误叠加、减少错误信息的参与度,存储模块对候选信息进行实时更新.视频序列上的测试结果显示,图记忆跟踪器的存储模块能够及时更新候选信息,保留目标不同时刻的状态.常用跟踪基准上的结果显示,图记忆跟踪器在成功率和精度上优于基于匹配的基线跟踪器SiamRPN.与最近的先进跟踪器CstNet相比,图记忆跟踪器在OTB100基准上获得了11.75%的重叠成功率增益,10.53%的精度增益,在VOT2016基准上获得了8.59%的预期平均重叠增益.速度测试的结果显示,图记忆跟踪器能够在单片RTX2070上实现29帧/s的运行速度.
目标跟踪;通用跟踪;图结构;局部匹配;模板更新
基于匹配的跟踪是一种成熟的通用目标跟踪策略.它利用视频第1帧或前1帧中的目标信息构建模型,学习通用的匹配函数来模拟目标的在线变化.近年来,基于匹配的跟踪使用深度学习来提高泛化能 力[1],它们通过海量数据的离线训练,学习不同帧中目标之间的相似性,实现了良好的跟踪结果.
然而,基于匹配的跟踪器性能主要依赖于离线训练网络对相似对象的判别能力,缺乏在线适应性和对特定目标的针对性,不能很好地捕捉对象、背景或成像条件的时间变化,且易受到相似实例或背景噪声的干扰.许多研究提出了不同的机制来更新模板特征,以提高跟踪器对当前任务的适应能力.基于线上学习算法利用相似性响应[2]和分支特征[3]的损失梯度推断模板更新残差,能够实现实时的跟踪效果,但这一结构的网络训练较为困难.基于相关滤波器的算法[4-5]训练相关滤波器对固定模板的特征进行调整,使其更准确地概括当前目标的特定属性.这类算法致力于提升网络对某一特定类别的识别能力,而使目标更容易被相似实例干扰.基于轨迹的算法[6-7]能够应对相似实例的干扰问题,但不适用于不限制镜头、目标和背景移动的复杂视频.针对复杂的跟踪场景,一些算 法[8-9]通过综合历史信息建立模板库来应对场景和目标的变化.这类算法的思路是提取历史检测信息作为候选信息,筛选可信任的信息作为模板,但其具有3个缺陷:第一,历史帧的目标形态差异较大,历史信息和特定帧信息的全局匹配是不稳健的;第二,目标特征被视为整体存入候选库,不可避免地保留了部分背景信息,对这些信息的学习使跟踪器将背景误认为是目标的一部分;第三,候选信息不一定正确,检测误差会在累加计算中造成检测错误.
针对以上问题,本文提出包含3点贡献的图记忆跟踪网络.①针对历史信息和特定帧信息的全局匹配的劣势,将图的节点匹配机制应用于先验知识的嵌入过程中,实现点对点局部匹配.②针对背景信息混入先验知识的问题,对即将存入存储模块的候选信息进行动态筛选,确保进入候选库的信息尽量少地包含无关的背景干扰.③对于检测失误引起的后续错误叠加的问题,通过对先验信息进行实时更新来减少错误信息的参与度.由于存储模块存入错误信息是无法避免的,这些信息会造成先验知识与当前任务的不匹配,因此引入注意力机制使网络关注于在当前检测任务中具有优势的先验知识.结果表明,所提出的方法优于基线跟踪器SiamRPN[10],在VOT2016和VOT2018基准上分别获得了10.17%和15.16%的综合性能预期平均重叠(expected average overlap,EAO)增益,同时能够保持29帧/s的实时运行速度.
1 图记忆跟踪器
图记忆跟踪器使用经典的Siamese构架[1]将视觉跟踪转化为模板匹配问题,并在其基础上设计了基于图的匹配模块、筛选模块和存储模块.其结构如图1所示.

图1 图记忆跟踪器结构示意
图记忆跟踪器的输入为存储模块读出的先验知识[0,1,…,M]和=时刻的搜索输入S.当<+1时存储模块未满,以初始模板0代替先验知识.两路输入经过特征提取网络和层间串联函数提取特征编码,得到(M)和(S)分别为

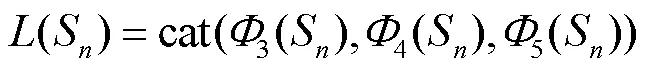
式中:M为存储模块读出的第个信息,∈[0,];3、4、5分别为特征提取网络的第3、4、5层特征;cat为通道串联操作.
两路特征编码共同输入匹配模块进行搜索输入与先验知识的局部匹配,得到匹配后的融合编码为

式中Graph代表图模块的处理过程.
Cls分类分支和Loc定位分支根据融合编码得到分类响应cls与包围框bbox为

由分类响应与包围框生成新模板,经过筛选模块筛选后作为候选信息输入存储模块,再由存储模块控制其读写.
1.1 基于图的匹配模块
图是一种常用的数据结构,常被用于局部信息处理中.GNNM[11]以空间方式对每个节点采用前馈神经网络.SSCGCN[12]通过傅里叶域中的卷积在图上提供明确定义的定位算子.对于计算机视觉任务,Wang等[13]提出将视频表示为时空区域图,其捕捉相似性关系和时空关系.在跟踪检测领域,GCT[14]采用时空图卷积网络进行目标建模.受此启发,将图用于先验信息与搜索输入的局部匹配过程中.图2显示了所设计模块的局部匹配过程.

图2 先验信息与搜索输入特征的局部匹配
首先,假设仅存在单个先验知识.如图2所示,将单个先验知识0与搜索输入S的特征编码上每个点看作图的一个节点.令p和s分别为(0)和(S)的节点集合,p中任意节点包含先验知识某一位置的不同尺度的特征信息,s中任意节点则包含搜索输入某一位置的不同尺度的特征信息.由于先验知识与搜索输入共享特征提取网络参数,节点、包含的特征信息呈现一一对应的关系.利用两组节点构建二分图为
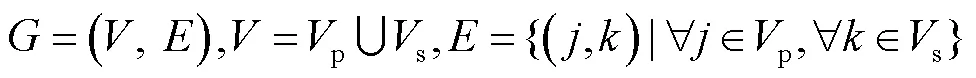
的两个子图分别为p=(p,)和s=(s,).通过s中每个节点对p中所有节点进行搜索,实现先验知识与搜索输入的局部匹配,其具体过程如下.
步骤1 获取节点之间的权并进行搜索.对于中每个点(,),令e表示节点和节点之间的权,其计算方式为两节点线性变化后的内积,即

步骤2 将搜索结果传递到s中以实现局部匹配.由于搜索输入中与先验知识越相似的区域越有可能存在目标,更多的目标信息应该被传递到那里.因此,使用e作为相似性度量进行信息传递.
具体来说,利用p中所有节点传递到s中第个节点的相关性得分计算节点的加权表达,则有
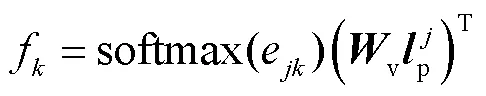
式中:softmax为归一化函数;v为线性层权重.
收集传递到s中所有节点的先验知识,得到局部匹配结果为
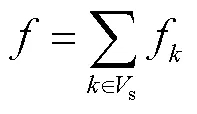
步骤3 为保留当前帧的目标信息,使定位分支更好地细化目标形状大小,对0与S的局部匹配结果与S的特征进行编码融合,即
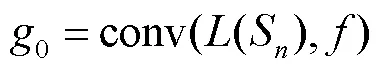
式中conv表示核为1×1的卷积层.
考虑存在多个先验知识0,1,…,M的情况.对于任意一个先验知识M得到的融合特征编码g,引入SE模块[15]生成权重编码,对融合特征编码g进行加权叠加得到最终的融合编码为

将融合编码输入分类分支与定位分支得到跟踪结果.
1.2 筛选模块
图记忆跟踪器将每一帧的跟踪结果剪切下来作为新模板.然而,这些新模板存在两点问题:第一,生成新模板时不可避免地保留了部分背景信息,对这些信息的学习使跟踪器将背景误认为是目标的一部分;第二,相似对象与目标混叠,跟踪器易将相似对象误认为目标.这使它们不能直接作为候选信息存入存储区.针对这些问题,设计了如图3所示的筛选模块.
筛选模块的具体工作如下.
首先,根据定位分支获得的包围框对搜索输入进行剪切生成新模板T,同时生成标记目标与背景的模板标签label,用于在后续的生成特征编码的过程中突出目标信息.
其次,对新模板进行筛选,筛选过程如图4所示.
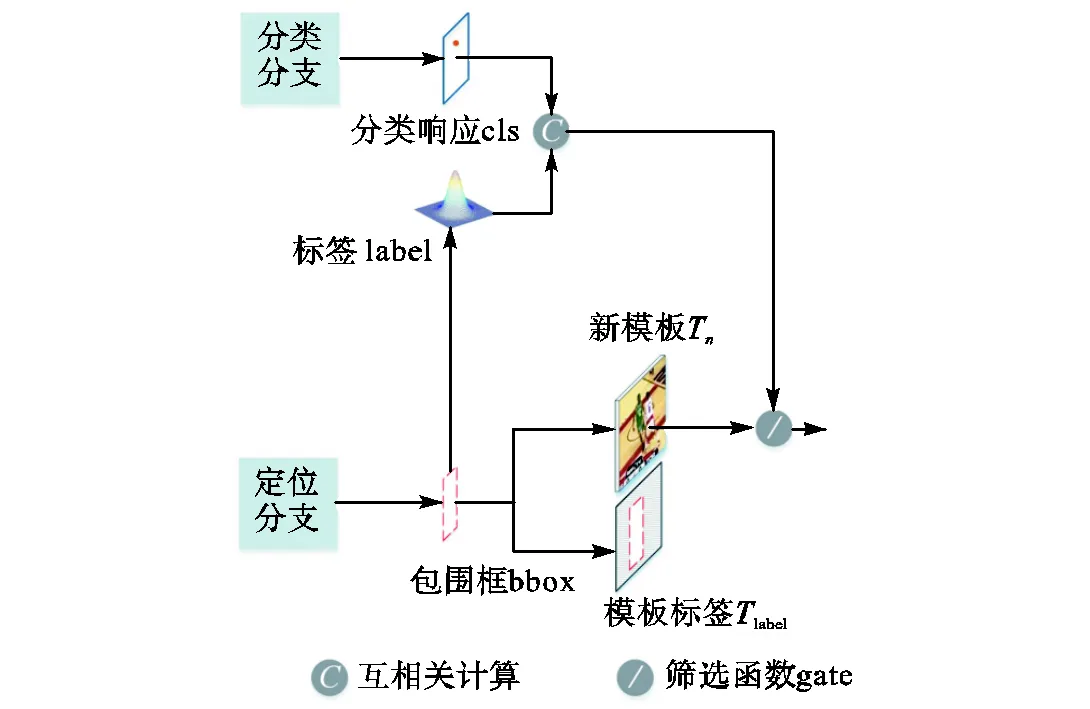
图3 筛选模块结构示意

图4 筛选过程示意
如图4所示,筛选依据是由分类分支的分类响应决定的.如果=时搜索输入S中目标周围无相似对象,那么分类结果通常显示为单峰.如果目标与相似对象混叠,分类结果显示为多个峰值点,此时对搜索输入剪切生成的新模板将不可避免地包含部分相似对象,对后续结果产生影响.因此,筛选模块滤除分类结果为多个峰值点的新模板,以抑制相似对象的干扰.
具体来说,由定位分支生成的目标包围框bbox生成以目标中心点为中心的高斯分布图像label,对分类分支生成的分类结果cls进行相似性计算,若相似性大于统计平均值sim,则通过gate输入存储模块作为候选信息,否则放弃当前新模板,使用原始数据进行下一帧的跟踪.用于筛选的gate可表示为

1.3 存储模块
经过筛选的新模板作为候选信息输入如图5所示的存储模块,其主要工作是控制候选信息的读写.

图5 存储模块写入过程
如图5所示,存储区的输入是经过筛选的新模板T、初始模板0和分类响应cls.为了控制候选信息的写入,根据初始模板与候选信息的相似程度生成用于判断是否写入存储区的写权重阈值Initwrite和当前候选信息T的写权重write分别为



式中global为全局池化操作.
由于手动标记的初始模板是跟踪器唯一能够得到的绝对正确的目标信息,候选信息与初始模板的相似性越大,跟踪器对候选信息的信任程度越高,写权重write越大.Initwrite为存储区未满时生成的阈值,用于在后续帧中评估写权重write的大小.阈值越低,说明跟踪场景越复杂,对写权重的约束力越小.
存储模块的写入流程如下:当<+1时存储区未满,对于待检测的实时性视频来说,此时的目标和场景与初始状态基本相同,因此直接将候选信息写入;当>时存储区已满,根据写权重write判断是否写入,写入时替换旧的候选信息,替换位置由写权重write、读权重read和写入帧数frame决定,即


当模板的可靠性低,被读取的次数少,写入的时间长,则优先被替换.完成写入与替换后,对存储区各个位置的权重进行复位.进行下一帧识别时,由存储模块读出候选信息计算特征编码作为先验知识.

此外,值越大,存储的候选信息越丰富,但过高的值会导致训练时数据量成倍增加,因此在实验中将值固定为6,在可训练的范围内保留最高的值.
2 实验验证
本节介绍了图记忆跟踪器的训练细节和测试结果,并与成熟的跟踪算法进行了比较.为公平比 较,所有被比较的跟踪器数据来自文献或比赛结果[1-10, 16-18].
2.1 训练细节
使用分布训练对图记忆跟踪器的各部分参数进行训练.首先,训练不包含图模块和存储模块的网络模型,训练数据为同一视频序列裁剪的模板和搜索输入图像对.其次,冻结特征提取网络的前3层参数训练图模块、分类分支和定位分支.训练数据为同一视频序列裁剪得到的1张搜索输入和8张模板,随机抽取1张模板与搜索输入组成图像对输入网络,其他模板作为候选信息输入存储模块参与训练.
训练数据包含COCO[19]、VID[20]、LaSOT[21]和YoutubuVOS[22]数据集.模板与搜索输入的剪切方式采用SiamRPN剪切方式,模板尺寸为127像素×127像素,搜索输入尺寸为255像素×255像素.训练周期为30,批量尺寸为8,学习率为1×10-2~1×10-5,采用动量为0.9的随机梯度下降(SGD)来训练网络,权重衰减为1×10-5.
2.2 测试结果与分析
本节展示了存储模块测试结果、跟踪结果、基准测试结果和消融实验,以证明所提出跟踪器的先进性.测试平台是单片NVIDIA RTX 2070.
2.2.1 存储模块测试结果
存储模块存储的候选信息是否准确直接影响到跟踪的效果,因此,本文测试了存储模块的存储内容.
图6显示了视频序列Bird1的3帧图像,绿色包围框为跟踪器输出的目标框,0~6分别为对应时刻存储模块中存储的候选信息.视频序列中,目标在第81~221帧完全被云层覆盖.图6(a)、(b)、(c)分别展示了目标丢失前(第65帧)、目标丢失时(第139帧)和再次定位目标后(第358帧)的跟踪结果.
如图6所示,3帧图像的21张候选信息皆包含目标物,没有存入无关背景信息或相似对象.如图6(b)所示,第139帧识别到不含目标的包围框,但存储模块中并没有写入不含目标的候选信息,这说明存储模块能够及时更新候选信息,保留原始信息和与当前目标形态相似的信息.

图6 存储模块的存储内容
2.2.2 跟踪结果
本节测试了跟踪器在不同挑战的视频序列中的效果.如图7~图12所示,选取了6组具有挑战性的视频序列,每个视频序列间隔选取5张图像.每个图像序列的尺寸和类型不一.蓝色包围框表示第1帧中手动标记的目标框,绿色包围框表示基线跟踪器SiamRPN的输出结果,红色包围框表示图记忆跟踪器输出结果.6组图像序列的主题分别是目标位移、目标丢失(目标在第81~221帧之间完全被背景遮挡)、相似对象干扰、目标形变、光照变化和相似对象遮挡.为了更清晰地区分图中的目标与相似实例,在存在多个相似实例的图8和图9中使用符号T标记了真实的目标对象.
如图7、图10、图11所示,在主题为目标移动、目标形变和光照变化的视频序列中,基线跟踪器SiamRPN与所提出的图记忆跟踪器均能识别到正确目标,但图记忆跟踪器得到的包围框更贴合目标.这是因为图记忆跟踪器使用局部匹配代替全局匹配,能够实现更精细化的定位.在图8、图9、图12中,SiamRPN丢失目标,而图记忆跟踪器仍能正确识别到目标.这是因为图记忆跟踪器获取了充足的模板信息,在丢失目标后能够由储存多种目标状态的先验知识找到目标,而SiamRPN需要根据第1帧固定的模板重新跟踪,这使它容易将相似性对象误识别为目标.图记忆跟踪器在不同主题和尺寸的视频序列中均能准确识别到目标,说明其对于目标和场景变化具有适应性,同时对不同大小的视频序列均能保持稳定 跟踪.

图7 视频序列Biker的跟踪结果

图8 视频序列Bird1的跟踪结果

图9 视频序列Bolt2的跟踪结果

图10 视频序列Diving的跟踪结果

图11 视频序列Man的跟踪结果

图12 视频序列GOT6的跟踪结果
2.2.3 基准测试结果
为测试图记忆跟踪器在普适性数据集上的跟踪能力,在3个常用跟踪基准上测试了所提出的跟踪器,并与基于匹配的经典跟踪器以及近几年的先进的模板更新跟踪器进行了比较.跟踪基准包括OTB100[23]、VOT2016[24]、VOT2018[25].
选用OTB2015的100个挑战性序列OTB100进行跟踪器评估.评价标准包含两个指标,即重叠成功率()和精度().重叠成功率通过显示真实边界框和跟踪器预测的边界框之间交并比大于给定阈值的视频帧数占总帧数的比例,来衡量跟踪器预测的边界框的准确程度.同时使用曲线下的区域对不同的跟踪器进行排序.精度通过显示真实边界框和跟踪器预测的边界框中心的距离大于给定阈值的视频帧数占总帧数的比例,来衡量跟踪器对目标进行定位的准确程度.同时选取距离低于阈值时跟踪的成功率进行排序.阈值距离通常设置为20个像素.
VOT2016和VOT2018是广泛使用的视觉目标跟踪基准.每个跟踪基准包含60个具有各种挑战性因素的序列,视频序列中的每一帧用单个目标对象的边界框标定真实值.VOT基准采用准确性、稳健性和预期平均重叠EAO作为衡量标准.准确性基于真实边界框和跟踪器预测的边界框的交并比来评估跟踪器.准确性的值越大,跟踪器对目标的定位越准确.稳健性用于评价跟踪器在跟踪目标过程中的稳定性.稳健性的值越大,跟踪器丢失目标的可能性越大,其稳定性越差.预期平均重叠EAO综合考虑了边界框重叠率和跟踪器丢失目标后重新初始化的时间,能够对跟踪器的整体性能进行评估.预期平均重叠EAO的值越大表明跟踪器的综合性能越好.
表1显示了3个常用基准上的测试结果.对比算法为一些经典的基于Siamese结构、算法和近几年的使用模板更新的跟踪算法,包括SiamFC[1]、SiamRPN[10]、DSiam[5]、CstNet[9]、TADT[3]、CFNet[4]、GradNet[2]、C-COT[6]、FlowTrack[7]、Memtrack[8]和杨浩等[16]、周益飞等[17]、邱云飞等[18]提出的算法.对于未提供测试数据的算法,表格中显示为空白.
表1 3个基准上的测试结果

Tab.1 Results of three benchmarks
注:SiamRPN是本文的基线跟踪器,带*号的数据为最优数据.
由表1可知,所提出的跟踪器在基准OTB100上实现了0.656的重叠成功率和0.860的精度,与最优数据分别相差0.026和0.021,C-COT和FlowTrack虽然在其中一个参数上优于所提出的图记忆跟踪器,但在另一个参数上弱于它.在基准VOT2016和VOT2018上,图记忆跟踪器取得了最优的准确性和预期平均重叠,稳健性弱于其他跟踪器.这说明虽然所提出的跟踪器丢失目标后重新定位所需的时间更长,但其在跟踪准确率方面占有优势,且具备优秀的综合性能.
与基线跟踪器相比,所提出的跟踪器在比较的几个参数上皆优于SiamRPN,且在VOT2016和VOT2018上分别获得了10.17%和15.16%的综合性能(EAO)增益,证明了所提出模块的有效性.与最近的先进算法CstNet相比,图记忆跟踪器在OTB100基准上获得了11.75%的重叠成功率增益,10.53%的精度增益,在VOT2016基准上获得了8.59%的综合性能增益.与表中最先进的算法FlowTrack相比,图记忆跟踪器在OTB100上的精度略逊一筹,造成了2.4%的精度损耗,但在VOT2016上获得了13.4%的综合性能增益.
2.2.4 消融实验
匹配模块是所提出跟踪器的核心,为了评估其有效性,本文比较了消融匹配模块前后在不同数据集上的跟踪成功率和速度.消融匹配模块后,将存储模块提供的先验知识进行叠加后与搜索输入进行全局匹配.消融实验结果显示在表2中.表中显示的检测速度是跟踪器在一台配备Nvidia RTX2070图形处理器的计算机上的每秒处理的图像帧数.
表2 消融实验结果

Tab.2 Results of the ablation experiment
从表2的跟踪成功率可以看出,匹配模块能够将OTB数据集上重叠成功率从0.447提升至0.656,说明匹配模块对于提升跟踪器性能有积极作用.从速度测试数据来看,所提出的匹配模块虽然取得了性能提升,但增加了时间成本.尽管如此,它仍然可以以29帧/s的速度运行.
3 结 语
基于匹配的跟踪通过计算通用的特征相似性来定位目标,这一过程抛弃了对特定跟踪场景和目标状态特征表示的学习.而跟踪器是根据所有类型的视频设计的,无法在训练阶段保留对所有状态的目标和跟踪场景的辨别能力.本文提出了图记忆跟踪器,它能够在跟踪时获取当前视频的先验知识以学习当前跟踪任务的特征表示.针对先验知识的筛选、生成和嵌入方式,分别设计了筛选模块、存储模块和匹配模块.本文的思路是使筛选模块尽可能地筛除背景和相似对象对候选信息的干扰,存储模块提取最适合于当前任务的候选信息生成先验知识,图模块实现先验知识与当前搜索输入的局部匹配与融合.通过测试结果可知,所提出的跟踪器能够获得正确的候选信息和目标跟踪结果,这说明所提出的模块能够满足设计思路的要求.
此外,测试结果同样体现了所提出的跟踪器在稳健性方面的不足.具体来说,相比于其他先进的跟踪器,所提出的跟踪器丢失目标后重新定位所需的时间更长.这是因为跟踪器为了减少丢失目标后错误识别到相似对象的情况,由目标丢失的位置为中心向外寻找新目标,而不是在全图范围内寻找目标,这使所提出的跟踪器需要多帧进行重新定位.如何在保持高效的跟踪的前提下提升跟踪器的稳健性,仍需要进一步研究.
[1]Bertinetto L,Valmadre J,Henriques J,et al. Fully-convolutional siamese networks for object tracking[C]// European Conference on Computer Vision. Amsterdam,Netherlands,2016:850-865.
[2]Li Peixia,Chen Boyu,Ouyang Wanli,et al. GradNet:Gradient-guided network for visual object tracking[C]//International Conference on Computer Vision. Seoul,Korea,2019:6161-6170.
[3]Li Xin,Ma Chao,Wu Baoyuan,et al. Target-aware deep tracking[C]//Computer Society Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:1369-1378.
[4]Valmadre J,Bertinetto L,Henriques J,et al. End-to-end representation learning for correlation filter based tracking[C]//Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:5000-5008.
[5]Guo Qing,Feng Wei,Zhou Ce,et al. Learning dynamic siamese network for visual object tracking[C]// International Conference on Computer Vision. Venice,Italy,2017:1781-1789.
[6]Danelljan M,Robinson A,Khan F,et al. Beyond correlation filters:Learning continuous convolution op-erators for visual tracking[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:472-488.
[7]Zhu Zheng,Wu Wei,Zou Wei,et al. End-to-end flow correlation tracking with spatial-temporal attention[C]// Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:548-557.
[8]Yang Tianyu,Chen A. Learning dynamic memory networks for object tracking[C]//European Conference on Computer Vision. Munich,Germany,2018:153-169.
[9]Yao Siyuan,Zhang Hua,Ren Wenqi,et al. Robust online tracking via contrastive spatio-temporal aware network[C]//AAAI Conference on Artificial Intelligence. Hawaii,USA,2019:8666-8673.
[10]Li Bo,Yan Junjie,Wu Wei,et al. High performance visual tracking with siamese region proposal network [C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:8971-8980.
[11]Franco S,Marco G,Ah T,et al. The graph neural network model[J]. Transactions on Neural Networks,2009,20(1):61-80.
[12]Kipf T,Welling M. Semi-supervised classification with graph convolutional networks[C]//International Conference on Learning Representations. Palais des Congrès Neptune,France,2017:1-14.
[13]Wang Xiaolong,Abhinav G. Videos as space-time region graphs[C]//European Conference on Computer Vision. Munich,Germany,2018:413-431.
[14]Guo Dongyan,Shao Yanyan,Cui Ying,et al. Graph attention tracking[C]//Conference on Computer Vision and Pattern Recognition. Nashville,USA,2021:9543-9552.
[15]Hu Jie,Shen Li,Albanie S,et al. Squeeze-and-excitation networks[J]. Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011-2023.
[16]杨 浩,钟小勇,黄林辉. 基于先验机制的级联目标跟踪算法研究[J]. 无线电工程,2023,53(2):371-380.
Yang Hao,Zhong Xiaoyong,Huang Linhui. Research on cascaded target tracking algorithm based on prior mechanism[J]. Radio Engineering,2023,53(2):371-380(in Chinese).
[17]周益飞,徐文卓. 基于响应正则化的孪生网络目标跟踪算法[J]. 计算机应用与软件,2022,39(11):154-159.
Zhou Yifei,Xu Wenzhuo. Target tracking algorithm based on response regularization siamese network[J]. Computer Applications and Software,2022,39(11):154-159(in Chinese).
[18]邱云飞,卜祥蕊,张博强. 动态时空异常感知的相关滤波目标跟踪算法[J/OL]. 系统仿真学报,https://kns. cnki.net/kcms/detail//11.3092.V.20221201.1149.001.html,2022-12-01.
Qiu Yunfei,Bu Xiangrui,Zhang Boqiang. Dynamic spatio-temporal anomaly-aware object tracking algorithm[J/OL]. Journal of System Simulation,https://kns. cnki.net/kcms/detail//11.3092.V.20221201.1149.001.html,2022-12-01(in Chinese).
[19]Lin T,Maire M,Belongie S,et al. Microsoft COCO:Common objects in context[C]//European Con-ference on Computer Vision. Zurich,Switzerland,2014:740-755.
[20]Russakovsky O,Deng Jia,Su Hao,et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision,2015,115(3):211-252.
[21]Fan Heng,Lin Liting,Yang Fan,et al. LaSOT:A high-quality large-scale single object tracking bench-mark[C]//Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:5369-5378.
[22]Xu Ning,Yang Linjie,Fan Yuchen,et al. YouTube-VOS:Sequence-to-sequence video object segmentation[C]//European Conference on Computer Vision. Munich,Germany,2018:603-619.
[23]Wu Yi,Lim J,Yang M H. Object tracking benchmark[J]. Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1834-1848.
[24]Kristan M,Leonardis A,Matas J,et al. The visual object tracking VOT2016 challenge results[C]//Euro-pean Conference on Computer Vision Workshop. Amsterdam,Netherlands,2016:192-217.
[25]Kristan M,Leonardis A,Matas J,et al. The sixth visual object tracking VOT2018 challenge results[C]// European Conference on Computer Vision Workshops. Munich,Germany,2018:3-53.
Graph Memory Tracker for Generic Object Tracking
Xi Jiaqi,Chen Xiaodong,Wang Yi,Cai Huaiyu
(School of Precision Instruments and Optoelectronic Engineering,Tianjin University,Tianjin 300072,China)
Matching-based tracking algorithm transforms the issue of detecting specific targets into template matching and has a high response speed and tracking precision. As a result,it has an advantage in generic target tracking. How-ever,lack of online adaptability,applicability to specific data,and difficulty in coping with the complex changes in targets and tracking scenes are some of the issues it faces. To address this issue,a graph structure-based graph mem-ory tracker is presented to enhance the accuracy of generic object tracking. First,the node-matching mechanism of the graph was used to achieve point-to-point local matching between the prior knowledge of the target and the search input. The target position was then located using the matching result. Second,the new template was created by processing the target location information. To suppress the interference from similar objects,the new template was dynamically screened according to the characteristics of the multi-peak classification response of similar objects. Finally,the new screened template was saved as candidate information in the memory module. The memory module updated candidate information in real-time to prevent subsequent error superposition produced by screening errors and to decrease the participation of error information. The results from the video sequences demonstrated that the memory module of the graph memory tracker can update the candidate information in time and store the target’s state at each instance. The results on common tracking benchmarks reveal that the graph memory tracker is superior to the matching-based baseline tracker SiamRPN in success rate and accuracy. Compared with the latest advanced tracker CstNet,we achieved an 11.75% overlap success rate gain,10.53% accuracy gain on OTB100,and 8.59% expected average overlap gain on VOT2016. The graph memory tracker achieves a running speed of 29 frames per second on a single RTX2070 in the speed test.
object tracking;generic tracking;graph structure;local matching;template updating
the National Natural Science Foundation of China(No. 82027801).
10.11784/tdxbz202210023
TP391.4
A
0493-2137(2023)12-1317-09
2022-10-19;
2023-02-27.
席佳祺(1995— ),女,博士研究生,xijiaqi@tju.edu.cn.Email:m_bigm@tju.edu.cn
陈晓冬,xdchen@tju.edu.cn.
国家自然科学基金资助项目(82027801).
(责任编辑:孙立华)
