基于改进CNN和Kmeans的双转子轴承半监督故障诊断∗
2023-11-06崔锦淼
崔锦淼,贺 雅,2,冯 坤,2
(1.北京化工大学发动机健康监控及网络化教育部重点实验室 北京,100029)(2.北京化工大学高端机械装备健康监控与自愈化北京市重点实验室 北京,100029)
引言
双转子轴承是一种特殊的滚动轴承,其内外圈均与转子相连,以减轻重量获得紧凑结构,被广泛用于燃气轮机等双转子设备中[1]。作为双转子设备关键支撑部件之一,双转子轴承的可靠性直接影响设备的稳定健康运行,因此对其进行状态监测和故障诊断十分必要,其中振动监测是最常用的手段[2-3]。
双转子轴承内外圈均转动,无固定轴承座,振动信号只能在设备机匣间接采集,因此其振动信号相较于普通滚动轴承更为复杂。艾延廷等[4]利用局部包络谱峰值因子优化Morlet 复小波,然后对双转子轴承振动信号滤波,提取双转子轴承微弱故障。Jiang 等[5]利用AR 对双转子轴承振动信号进行去噪,基于快速谱峭度方法确定中心频率和带宽,并对信号再次滤波,共振解调得到包络信号,最后对包络信号角域重采样,提取双转子轴承阶次特征。上述方法虽然在一定程度上增强了双转子轴承微弱故障特征,但严重依赖专家诊断知识,智能化水平低。为了减轻故障诊断对信号处理技术及专家诊断知识的依赖,提高故障诊断智能化水平,缩短诊断维修周期,CNN 等端到端的深度学习技术逐渐应用于故障诊断领域[6]。王奉涛等[7]提出一种基于CNN 的双转子轴承故障诊断方法,对轴承振动信号进行灰度变换后输入CNN 进行诊断。王丽华等[8]以短时傅里叶变换后的时频谱图作为CNN 输入来进行诊断故障。
基于CNN 的有监督诊断方法,需要一定数量的各类轴承故障数据。工程实际中,轴承某些故障类型数据不易获取,限制了上述方法的工程应用。半监督深度学习利用标签数据和无标签数据共同训练网络,一定程度上减弱了网络训练对标签数据的依赖。Li 等[9]提出基于数据增强和深度稀疏自动编码器的半监督故障诊断方法,减小了网络训练对有标签数据数量的要求,但是网络微调仍需各类别的故障数据支撑。Lee[10]提出伪标签自训练的半监督深度学习方法,在一定程度上摆脱了测试集类别数不能大于训练集类别数的限制。
笔者提出一种基于改进CNN 和Kmeans 的双转子轴承半监督故障诊断方法。该方法基于AR 预处理双转子轴承振动信号,以频谱幅值序列作为改进CNN 输入,基于自训练思想在少类别训练数据下诊断双转子轴承故障,减小了网络训练对有标签故障数据的依赖,工程应用价值更高。
1 方法原理
1.1 自回归模型
AR 是一种常见的滚动轴承振动信号去噪预处理方法[5],可预测振动信号中平稳信号成分。从原始振动信号中剔除平稳信号成分即可获得滚动轴承非平稳振动信号,其原理如下。
通过t时刻前p个数据预测x(t)数据值,即
其中:x(t-i)为t时刻前第i个数据值;ai为x(t-i)对应的系数;x'(t)为t时刻预测值。
x'(t)为平稳信号成分,从原始信号中剔除平稳信号成分即可获得轴承非平稳冲击信号
展开式(2)可得
e(t)可以看成滤波器系数a(p)={1,a1,⋅⋅⋅,ap}在时间序列x(t)={x(t),x(t-1),⋅⋅⋅,x(t-p)}上的卷积,其中AR 滤波器系数a(p)可通过Yule-Walker方程求解[5]。
1.2 权重归一化卷积神经网络
卷积神经网络是一种集特征提取与分类于一体的深度学习方法,其兴起于计算机视觉和语音识别领域,并逐步应用在设备智能故障诊断中[11]。卷积神经网络随输入数据维度可分为1DCNN 和2DCNN,其中1DCNN 更适用于振动波形和频谱等1 维输入数据序列。典型的1DCNN 结构示意如图1所示,包括卷积层、池化层和全连接层。为加速网络收敛,Salimans 等[12]提出权重归一化方法加速网络训练过程中权重调整。Jia 等[13]将权重归一化卷积神经网络应用于故障诊断领域,进一步验证该方法的有效性。权重归一化卷积神经网络通过约束卷积核和全连接层权重模长,加速随机梯度下降算法对卷积核和全连接层权重在空间方向上的调整,从而加速网络收敛,其原理如下。
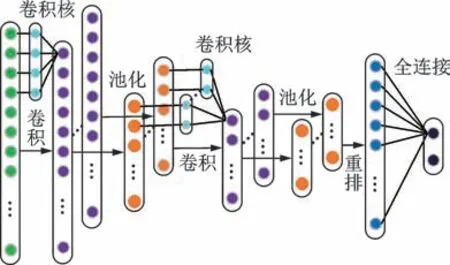
图1 典型的1DCNN 结构示意图Fig.1 Structure of typical one dimensional CNN
1)卷积层:利用卷积核在输入上滑动卷积自动提取数据特征,通过局部连接实现权值共享,相较于全连接结构大大减小了网络参数数量。其中,一个卷积核作用于输入得到的特征称为一个特征图,其前向计算公式为
其中:step 为卷积层的步长;wk为第k个n×m的卷积核;||wk||2为第k个卷积核的欧几里得范数;γk为卷积核wk对应的偏移系数;n为卷积层输入特征图的个数(第1 层卷积层中n=1);m为卷积核长度;bk为第k个卷积核对应的偏置;f(c⋅)为卷积层的激活函数为第k个特征图中第i个节点的输出。
2)池化层:通过下采样约减数据特征维度,提高网络的鲁棒性。常用的池化方式有最大池化和平均池化,本研究选取的平均池化前向计算公式为
其中:step 为池化层的步长;xk为池化层第k个输入特征图;为池化层第k个特征图第i个节点的输出。
池化层输入特征图个数等于输出特征图个数。
3)全连接层:通过全连接结构将网络学习的分布式特征映射到样本标记空间,起到分类器的作用,其前向计算公式为
其中:wi,j为全连接层第i个输出节点与第j个输入节点的连接权重;wi为所有输入节点与第i个输出节点的权重向量;||wi||2为wi的欧几里得范数;γi为wi对应的偏移系数;xj为第j个输入节点值;m为输入节点个数;bi为偏置,ff(⋅)为激活函数;yi为第i个节点输出值。
1.3 基于自训练的半监督深度学习
故障诊断领域故障数据获取困难,半监督深度学习相较于有监督学习对标签训练数据依赖更小。基于自训练的半监督深度学习示意如图2 所示,其基于少量有标签数据预训练网络,利用大量无标签数据进行测试,并生成无标签数据的伪标签,结合标签和伪标签数据迭代网络,摆脱了测试集类别数不能大于训练集类别数的限制,应用价值更高[10,14]。如何确定无标签数据的伪标签是算法关键,聚类分析是常用方法之一。Kmeans 算法是一种典型的利用统计方法来分析数据分布特性的无监督学习算法,通过Kmeans 分析CNN 线性输出,可初步判断无标签数据对应的伪标签,其聚类数K可通过轮廓系数(silhoutte coefficient,简称SC)来确定[15]。
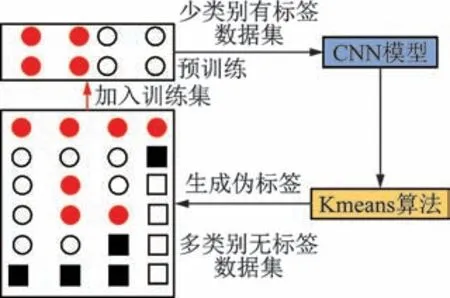
图2 基于自训练的半监督深度学习示意图Fig.2 Schematic diagram of semi-supervised deep learning based on self-training
SC 是衡量聚类效果的重要指标之一,单个样本的SC 计算公式为
其中:M为样本总数;bi为第i个样本与同类样本的平均距离;ai为第i个样本与不同类样本的平均距离。
样本集合的SC 为所有样本SC 的均值,即
SC 越大,则表示数据类内紧凑,类间距离大,聚类效果越好。通过比较各K值下SC 的大小,以SC随K变化的转折点作为最佳聚类数K值。
2 本研究提出的方法
2.1 改进CNN
为进一步提升CNN 从双转子轴承数据中提取复杂非线性特征的能力,笔者从激活函数和损失函数两方面改进CNN。从故障诊断角度选取非线性程度高且与CNN 输入更相关的函数作为激活函数,从CNN 内积运算的数学角度约束权重向量以增加权重多样性。
2.1.1 Morlet 小波频域激活函数
激活函数通过非线性激励神经网络,可拟合出任何复杂的非线性关系。各激活函数及导数如图3所示,其中Sigmoid 和Tanh 因导数计算简单被广泛应用,但其响应区间小,输出范围窄,仅在[0,1]和[-1,1]范围内输出,且随着网络层数的加深易造成梯度弥散,增加了网络训练难度[16]。Relu 和Leakyrelu 激活函数在一定程度上解决了Sigmoid 和Tanh的梯度弥散问题,但非线性程度低,仅在正负半轴具备不同斜率,不利于提取双转子轴承振动信号中的复杂非线性特征。文献[17]在以时域波形作为输入时,以非线性更强的Morlet 小波时域函数作为激活函数,增强了网络非线性特征提取能力,提升了故障诊断效果。
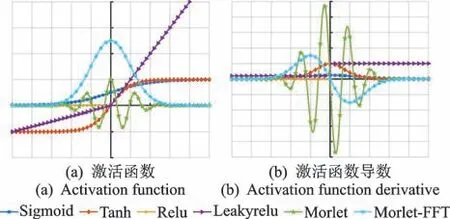
图3 各激活函数及导数Fig.3 Activation function and derivative curve
笔者在以频谱幅值序列作为CNN 输入时,相应的以Morlet 小波频域函数(Morlet wavelet frequency domain function,简称Moret-FDF)作为激活函数。
1)频谱中包含有部件故障特征频率及特征频带等相关信息,相较于时域波形故障特征更直观,且数据内存小(一般情况下只考虑幅值谱,为时域的一半)。Xu 等[18]将图像变换至频域,以频域特征作为输入,相较于直接以空间域图像作为输入,在相同精度下大幅降低计算成本,验证了频谱特征的有效性。
2)Morlet 及Morlet-FDF 激活函数计算公式如表1 所示。a=1,b=0 时的激活曲线及导数见图3。相较于传统激活函数,该函数具有以下优点:①是Morlet 小波的频域响应,非线性程度更高,且曲线为单瓣,与冲击信号频谱最相似,频谱中主要信息位于窗函数效应的主瓣中,该种响应曲线可能更契合频谱输入;②是可变尺度自适应激活函数,自适应平移系数b通过调节激活函数的响应区间保留频谱有效频段特征,自适应缩放因子a通过调节激活函数响应宽度及平滑度放大有效频段特征,更有利于CNN自提取故障相关特征。

表1 常用激活函数计算公式Tab.1 Calculation formula of activation function and its derivative
2.1.2 权重内积最小化损失
Ayinde 等[19]通过设定卷积核间余弦相似度阈值,建立卷积核间相似度惩罚机制,提高网络各层特征提取的多样性,但卷积核间余弦相似度惩罚阈值难以设定,阈值过大达不到效果提升,阈值过小则易欠拟合。笔者结合网络权重归一化约束[12-13],在文献[19]基础上提出网络权重内积最小化损失。权重归一化约束通过规范权重的模长加速单位权重向量在空间方向上的调整,权重内积最小化损失则通过惩罚单位权重向量内积,增大各单位权重向量在空间上的角度,使不同权重向量提取的特征方向尽可能不同,以增强CNN 特征提取的多样性。
卷积神经网络权重内积最小化损失计算公式为
其中:l为卷积层或全连接层层数;N为l层中卷积核或权重向量个数;Lli,j为l层第i和第j个卷积核或权重向量间内积;Ll为l层权重内积损失。
对于卷积层则有
对于全连接层则有
选取Softmax 损失函数,网络最终损失函数为
其中:λ为Ls,Lw损失间的系数;M为训练样本数。λ可自适应给定,即
其中:λl为第l层λ参数;为第l层Ls损失对应梯度绝对值之和;为第l层Lw损失对应梯度绝对值之和。
通过系数λl保证第l层Ls损失和Lw损失梯度数量级接近,从而保证网络收敛。
2.2 基于改进CNN 和Kmeans 的双转子轴承半监督故障诊断方法
本研究以双转子轴承为研究对象,提出一种基于改进CNN 和Kmeans 的半监督故障诊断方法,如图4 所示,其基本步骤如下。
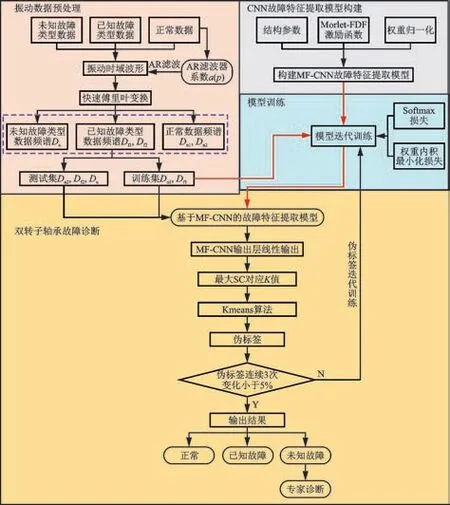
图4 基于改进CNN 和Kmeans 的半监督故障诊断方法Fig.4 The semi-supervised fault diagnosis method based on improved CNN and Kmeans
1)振动数据预处理:利用双转子轴承正常状态下振动数据求解AR 滤波器系数a(p),基于a(p)对所有振动数据滤波去噪。对滤波后的时域波形进行傅里叶变换,得到1 维频谱序列,并将数据划分为训练集和测试集。其中:训练集包含有标签正常数据Dn1和有标签故障数据Df1;测试集包含正常数据Dn2、已知故障类型数据Df2和未知故障类型数据Du。
2)CNN 故障特征提取模型构建:根据样本频谱序列长度确定1DCNN 结构参数,基于提出的Morlet-FDF 激活函数及权重归一化方法构建MFCNN 故障特征提取模型。
3)模型预训练:基于有标签的训练集数据Dn1和Df1,结合提出的权重内积最小化和Softmax 损失,迭代训练MF-CNN 故障特征提取模型。
4)双转子轴承故障诊断:将训练集数据Dn1,Df1和测试集数据Dn2,Df2,Du输入MF-CNN,得到MFCNN 线性输出特征。基于Kmeans 算法对MFCNN 输出特征聚类,计算各聚类数K(K≥k,k为训练集数据类别)下的SC 值,选取最大SC 值对应的K值作为最终聚类数,得到最终聚类结果,即无标签数据伪标签。利用有标签训练数据和伪标签测试数据共同迭代网络,直至伪标签连续3 次变化小于5%,即认为伪标签最吻合测试集真实标签,从而判别测试集样本状态。
当模型诊断出未知故障时,通过专家诊断确定故障类别后,可对未知故障数据重新标记以扩充故障数据库。
3 试验验证
3.1 试验台介绍
双转子轴承故障模拟试验台如图5 所示,利用相关数据验证所提方法的有效性。试验台主要由电主轴(外)、联轴器、轴承座、双转子轴承、普通滚动轴承、轴承座、联轴器及电主轴(内)组成。由于双转子轴承内外圈不固定,无法直接安装传感器,因此只能在临近的#2 轴承座上安装振动加速度传感器。振动信号通过转子传递至#2 轴承,然后传递至2#轴承座,传递路径相较于普通滚动轴承更为复杂。

图5 双转子轴承故障模拟试验台Fig.5 The fault simulation test rig of the dual-rotor bearing
以LMS Test.Lab 振动测试系统采集双转子轴承在正常(N)、外圈故障(OF)、内圈故障(IF)及滚动体故障(RF)下轴承座处外侧垂直方向的加速度信号,其中加速度传感器型号为BK4519,采样频率为25.6 kHz。选取内圈转速为900 r/min、外圈转速为1 500 r/min 工况下的轴承数据组成验证数据集,为模拟实际中有标签故障数据类别缺乏现象,选取正常数据、某一类轴承故障数据或干扰噪声数据(IN)构成训练集,正常数据和所有轴承故障数据构成测试集,数据集组成如表2 所示。

表2 数据集组成Tab.2 Composition of data
3.2 数据去噪预处理
冲击调制是滚动轴承发生局部故障的重要特征,滚动体转过滚动轴承缺陷处会产生瞬时冲击,同时激起轴承固有振动产生幅值调制现象,将低频滚动轴承故障特征频率调制至高频段,因此故障特征主要集中在加速度频谱高频段。为验证AR 预处理方法去除双转子轴承中低频干扰噪声的有效性,以高频段能量占频谱全频带的大小作为评价指标,对比原始信号、AR 处理、小波软阈值降噪处理以及经验模态分解(empirical mode decomposition,简称EMD)处理后频谱中高频段能量占比。其中高频段能量占比计算公式为
其中:Af为信号频谱幅值序列;fl为高频段截止频率。
处理后频谱中高频能量占比见图6,处理过程如下:①依据2.2 节中步骤1 进行AR 处理,其中预测阶次为100[5];②小波软阈值降噪,分解层数为4 层,小波基取与冲击信号最相似的sym8 小波[20];③进行EMD 分解,取与原始信号相关系数最大的本征模态分量分析[21]。取fl=8 kHz,可以看出,AR处理后故障数据高频能量均占比相较于其他处理方法增大最明显,且故障数据间高频段能量占比差异更大,但外圈和滚动体故障间差异仍不明显,再次证明了双转子轴承信号的强噪声干扰性。
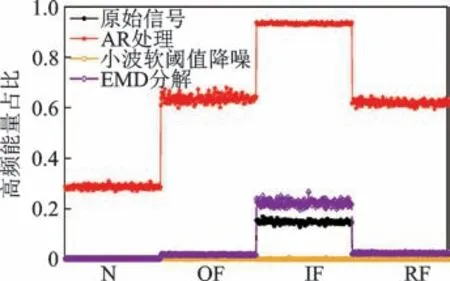
图6 高频能量占比Fig.6 Proportion of high frequency energy in spectrum
图7 为内外圈转速为900 和1 500 r/min 时双转子轴承各状态原始数据及经AR 滤波处理后数据的频谱,可以看出,AR 滤波处理抑制了故障数据低频平稳干扰信号,突出了高频成分,增强了双转子轴承微弱故障特征。
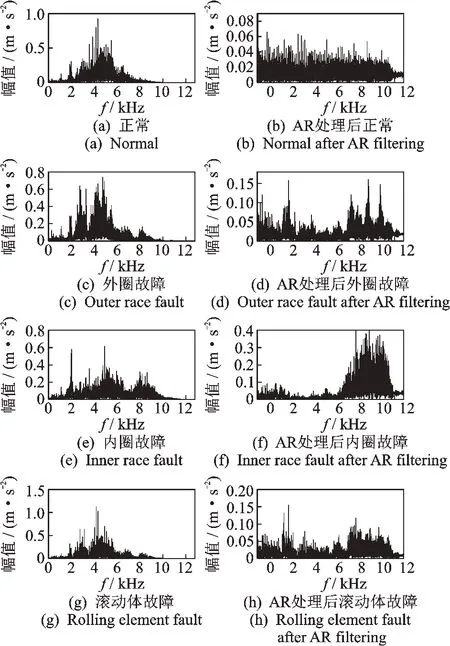
图7 双转子轴承频谱Fig.7 Data spectrum of dual-rotor bearing
3.3 CNN 模型构建与训练
为使各样本中充分包含故障信息,本研究截取0.64 s(时域波形为16 384 点,频谱序列为8 192 点)振动数据时域波形作为一个样本,以频谱序列作为CNN 输入,并结合图1 所示的网络结构构建CNN,网络结构参数见表3,其中c为训练数据类别数。
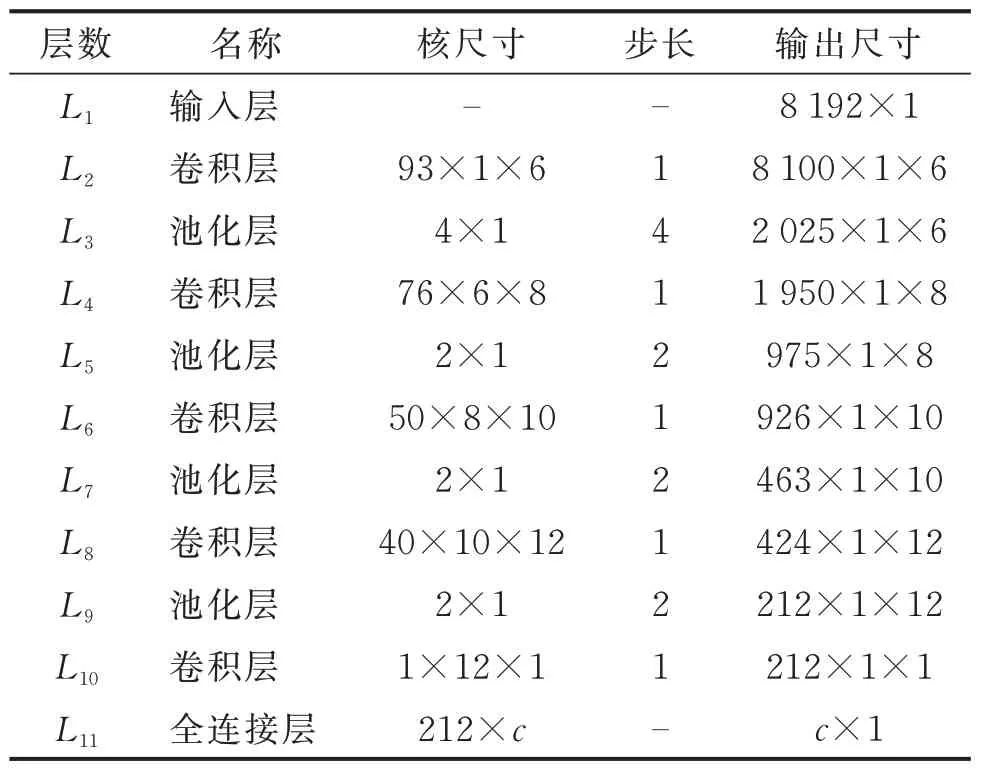
表3 网络结构参数Tab.3 Parameter of CNN
从激活函数、CNN 输入及损失函数3 个方面对比验证本研究所提方法有效性。首先,以Sigmoid,Tanh,Relu,Leakyrelu,Morlet(取f0=5[17])及Morlet-FDF 激活函数构建S-CNN,T-CNN,R-CNN,LCNN,M-CNN 及MF-CNN 网络模型;其次,分别以原始频谱数据和经AR 处理后的频谱数据作为CNN 输入,利用表2 中的训练集数据在Softmax 损失(J1损失)、结合权重内积最小化的Softmax 损失(J2损失)下预训练各网络模型;最后,基于训练数据和测试数据,结合自训练思想迭代训练网络并测试网络效果。网络迭代参数如表4 所示。

表4 网络迭代参数Tab.4 Iteration parameter of CNN
3.4 结果分析
除构建T-CNN,L-CNN,M-CNN 及MF-CNN网络外(S-CNN,R-CNN 出现梯度弥散不收敛),本研究还依据表3 中MF-CNN 结构构建卷积自动编码器(convolutional autoencoder,简称CAE)、网络层数更多的深度卷积神经网络(deep convolution neural network,简称DCNN)及ANN,并将频谱划分为11 段提取频谱能量作为ANN 的输入。各网络模型以N+IN(IN 为正常数据频谱和AR 处理后频谱之差,保证噪声数据也具备频谱特征)、N+OF,N+IF及N+RF 等少类别标签数据作为训练集,各模型故障识别效果如表5 所示,可以看出:

表5 各模型故障识别效果Tab.5 Fault identification results of each model
1)MF-CNN 较T-CNN,L-CNN 及M-CNN,预训练时故障识别准确率更高,说明Morlet-FDF 激活函数优于Tanh,Leakyrelu 和Morlet 激活函数;
2)基于J2损失训练的MF-CNN 较基于J1损失训练的MF-CNN,3 次迭代后故障识别准确率更高,说明权重内积最小化损伤有助于网络提取多样性特征,提升了故障识别准确率;
3)以AR 处理后的频谱数据作为输入,较以原始频谱数据作为输入,3 次迭代后故障识别准确率更高,进一步说明AR 模型对双转子轴承数据进行了特征增强;
4)以AR 处理后的频谱数据作为输入,J2损失训练的MF-CNN 网络输出特征聚类时,SC 值随聚类数K的变化趋势如图8 所示。可以看出,SC 值转折点对应的K值即为聚类数K=5 或4,与实际相符。
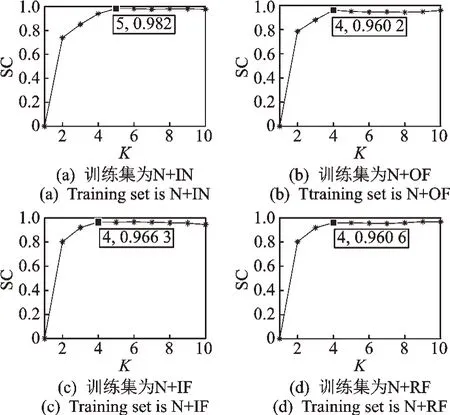
图8 SC 随K 值变化趋势Fig.8 Variation of SC with K value
综上,通过分析各模型故障识别准确率及模型SC 随K变化曲线,验证了本研究提出的AR 信号去噪方法、Morlet-FFT 激活函数及权重内积最小化损失的有效性,以及基于改进CNN 和Kmeans 的双转子轴承半监督故障诊断方法在少类别故障数据训练时进行故障诊断的有效性。
4 结论
1)基于AR 对振动信号预处理,并进行快速傅里叶变换获取频谱输入,减小了CNN 特征提取复杂度。
2)从激活函数、损失函数角度改进CNN,增强了CNN 特征提取能力。
3)根据自训练思想,在故障数据缺乏情况下,基于少类别训练数据结合Kmeans 算法迭代训练网络,减小网络训练对有标签故障数据的依赖。
4)通过双转子轴承故障模拟试验台数据,验证了所提方法在故障数据缺乏时进行双转子轴承故障诊断的有效性,双转子轴承正常、已知故障和未知故障状态识别率达到100%,减小了双转子轴承智能诊断方法对故障训练样本类别的依赖,提高了工程应用价值。
