基于多源域深度域自适应的脑力负荷识别
2023-11-06陈长德陈兰岚张效艇
陈长德, 陈兰岚, 张效艇
(华东理工大学化工过程先进控制及优化技术教育部重点实验室, 上海 200237)
脑力负荷被认为是影响操作员分析信息和决策判断的重要因素,脑力负荷水平过低可能引起操作员精力不集中、对工作产生厌恶情绪,进而导致工作绩效达不到最佳水平;脑力负荷水平过高可能会导致操作员快速疲劳、反应速度减缓,因而造成操作失误增加。多数脑力负荷研究是在操作员不涉及体力活动的场景中展开的,但在真实作业环境中操作员的脑力负荷状态会伴随一定的体力负荷,例如急救人员、消防员等,体力负荷甚至会对脑力负荷的准确评估造成影响。所以,在伴随有体力负荷的任务场景中准确检测操作员的脑力负荷状态对合理分配工作任务、提高工作绩效、减少人因事故有着重要意义[1]。
目前,操作员脑力负荷状态的主流检测方法有三类,其中包括主观问卷评价、任务绩效测量和生理信号分析。随着生理信号采集设备的快速发展,采集信号的效率和质量都随之提升,基于生理信号的脑力负荷检测方法由于其客观、实时的特点愈发得到研究人员的青睐。常见的用于检测脑力负荷的生理信号有:脑电(Electroencephalogram,EEG)、心电(Electrocardiogram,ECG)、近红外光谱(Near Infrared Spectroscopy,NIRS)等[2-3]。
传统的基于生理信号的脑力负荷检测方法大多基于特征工程,需依赖丰富的先验知识。随着深度学习方法在计算机视觉、自然语言处理等领域的成功应用,该方法也被越来越多地应用到脑力负荷相关研究中,研究人员可以直接通过原始的生理信号构建端对端的脑力负荷识别模型。然而,无论是传统的浅层学习还是深度学习技术都需要大量人工标记的数据来为每个被试者建立个体模型。充分利用之前已标记过的其他被试数据可以有效解决目标被试标记信息不足甚至没有标记数据的问题。但由于生理信号的个体差异性和非平稳特性,不同被试间的数据分布存在明显差异,直接使用源域被试的训练模型去测试目标域数据效果欠佳。
针对上述问题,研究人员采用领域自适应技术来构建跨被试脑力负荷识别模型。领域自适应技术是迁移学习中一个重要分支,它放宽了传统机器学习中训练集和测试集数据必须服从独立同分布的前提条件[4],能够在建立模型时减小源域与目标域数据的分布差异,实现域间可迁移知识的跨域复用,最终提升模型的泛化性能。
经典的领域自适应方法大多关注于寻找某个特定的特征空间,将数据映射到该特征空间后源域与目标域特征的分布被拉近。其中联合分布适配方法(Joint Distribution Adaptation,JDA)[5]和适配正则化线性回归算法(Adaptation Regularization Transfer Learning,ARTL)[6]是其中两种经典算法。近年来,除传统的域自适应方法外,深度学习技术已成功地与特征空间映射相结合以解决领域自适应问题,称为深度域自适应技术[7],按照适配方法可以分为基于距离度量的方法和基于对抗学习的方法两类。其中,基于距离度量的深度迁移方法中具有代表性的算法有深度域混淆网络(Deep Domain Confusion,DDC)[8]和深度适应网络(Deep Adaptation Network,DAN)[9]等。DDC 在卷积神经网络中嵌入来自不同领域抽象特征间的最大均值差异(Maximum Mean Discrepancy,MMD)[10]作为损失的一部分进行深度域自适应,而DAN 将MMD 扩展为多核MMD (MK-MMD),同时适配了多个全连接层以增强迁移效果。经典的域自适应方法和基于距离度量的深度域自适应方法都是针对最小化域间分布展开,优化过程的计算较复杂。虽然引入核函数将特征映射到再生希尔伯特空间中进行距离最小化计算,但是核函数的选取依旧是一个难题。
基于对抗学习的深度域自适应方法无需依赖先验知识,单纯通过网络结构本身在训练时进行的对抗博弈过程即可完成域自适应任务,相比于其他方法更加方便高效。对抗式深度域自适应方法的代表性算法为域对抗网络(Domain Adversarial Neural Network,DANN)[11],其受生成对抗网络(Gener-ative Adversarial Network,GAN)[12]的启发,在网络中加入域鉴别器与原本的网络结构形成对抗博弈的关系,在使用源域样本训练网络参数的同时,使网络无法分辨出样本来自于源域还是目标域,达到领域混淆的目的。DANN 最终适配的效果是源域和目标域样本的整体距离被缩小,即适配领域间边缘分布。但是当域间条件分布差异明显且边缘分布相近时,即领域间分类超平面不同但样本所处范围相近时,DANN 调整能力有限而且会混淆不同类别的样本,可能使迁移效果适得其反。多域对抗网络(Multi Adversarial Domain Adaptation,MADA)[13]在域鉴别器中引入了样本的伪标签,将不同类别的样本单独进行迁移,实现更为细致的适配,更加适合迁移上述情形。但是MADA 忽略了适配域间边缘分布的重要性,在适配条件分布相近但边缘分布差异较大的源域和目标域时,直接拉近边缘分布的效果却更好。动态对抗域自适应网络(Dynamic Adversarial Adaptation Network,DAAN)[14]在网络中采用同时适配源域和目标域的边缘分布和条件分布的策略,引入动态调节因子在训练中自适应调节两类分布的权重,达到同时兼顾但却有所侧重的联合适配目的。
对抗形式的深度领域自适应技术目前已被应用到与大脑状态相关的识别任务中。Li 等[15]在DANN的基础上采用两个局部域鉴别器来学习大脑左右半球不对称的情感特征,在实现域自适应的同时,使识别结果更具有鲁棒性,在SEED 脑电情感数据集上获得92.3%的三分类精度。Tang 等[16]利用源域和目标域的分类伪标签构建了一个类似MADA 的条件域自适应对抗网络,并且将其用在运动想象的跨被试四分类任务中,取得了95.3%的分类精度。
由于生理信号的个体性差异,每个被试的数据分布都不可能完全相同,同一目标域与不同源域进行迁移的效果也相差较大。单源域迁移只能从单一源域中进行迁移,然而单一源域中所蕴涵的知识是有限的,可能存在信息不充分的问题。若随机选取某一源域和目标域进行迁移,当域间相关性较弱时,模型迁移效果不能保证。而多源域迁移策略能够充分利用更为丰富的多源域信息,提高迁移模型性能[17-18]。但是使用全部源域进行迁移一定程度上会存在信息冗余的现象,造成计算资源的浪费。
本文基于EEG 信号和ECG 信号,构建了端到端的多源域跨被试脑力负荷识别模型。
(1) 针对源域数量过多因而存在信息冗余、训练时间过长的问题,采用源域优选策略挑选出与目标域分布接近的源域集合,以减少负迁移和缩短训练时长。
(2) 针对经典领域自适应方法和基于距离度量的深度域自适应方法计算复杂、核函数选取没有统一标准的问题,采用改进的动态对抗域自适应网络(modified Dynamic Adversarial Adaptation Network,mDAAN)建立跨被试的脑力负荷识别模型。
(3) 针对单源域迁移模型随机性强、稳定性差的问题,采用集成学习来构建多源域迁移模型,以提高跨被试脑力负荷识别模型的准确率与可靠性。
1 方法与模型
本文所构建的跨被试脑力负荷识别框架如图1所示。首先采用预处理后的EEG 信号和ECG 信号进行源域优选,利用被试间样本的分布差异来评估被试的相关性,筛选出与目标域被试分布差异较小的源域被试集合;再利用改进的动态对抗域自适应网络分别为每个优选源域和目标域构建一对一的跨被试识别模型; 最后采用不同的投票策略对单源域模型的结果进行集成,得到最终的跨被试脑力负荷识别结果。
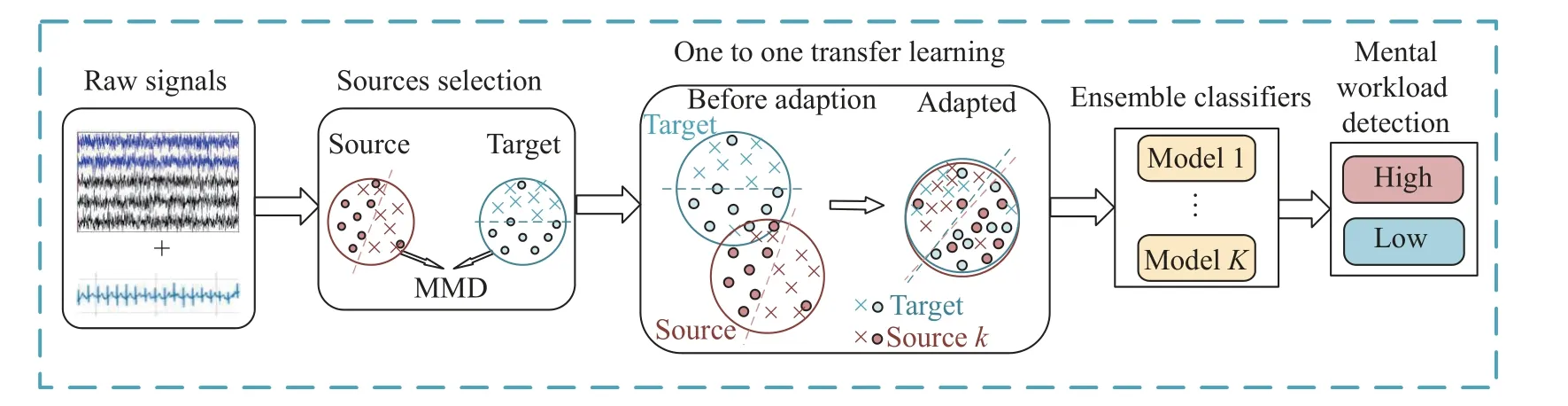
图1 跨被试脑力负荷识别框架Fig.1 Cross-subject mental workload estimation framework
1.1 多源域选择
本文采用基于最大均值差异(Maximum Mean Discrepancy, MMD)的度量方法来评估不同被试间的边缘分布差异,由此筛选出相似性强的被试集合。MMD 将源域和目标域的数据映射到可再生希尔伯特空间(RKHS)中,再求取两者的均值之差来代表域间数据分布差异的大小。MMD 越大代表源域和目标域的分布差异越大,域间相关性也越弱。
计算每个目标域被试与所有源域被试的MMD距离,选取MMD 距离最小的前K个源域被试构成源域被试集合。
1.2 动态对抗域自适应网络
从整体上看,动态对抗域自适应网络(Dynamic Adversarial Adaptation Network,DAAN) 由特征提取器Gf、标签分类器Gy、全局域鉴别器Gd和局部域鉴别器Gl等4 部分构成,网络结构如图2 所示。DAAN 采用对抗训练的方式,在训练过程中特征提取器与上述两种域鉴别器形成对抗博弈的关系。一方面,域鉴别器会尽量区分出源域与目标域样本;另一方面,特征提取器试图提取领域间不变特征来混淆源域与目标域样本。网络在从源域数据中学习分类知识的同时,寻找域间数据边缘和条件分布都接近的特征空间,达到域自适应的目的。此外,DAAN 利用域鉴别结果对域间边缘和条件分布差异进行定量估算,基于两类分布差异值设计了动态调节因子,在训练中实时调整分布损失的重要性,达到联合适配的目的。
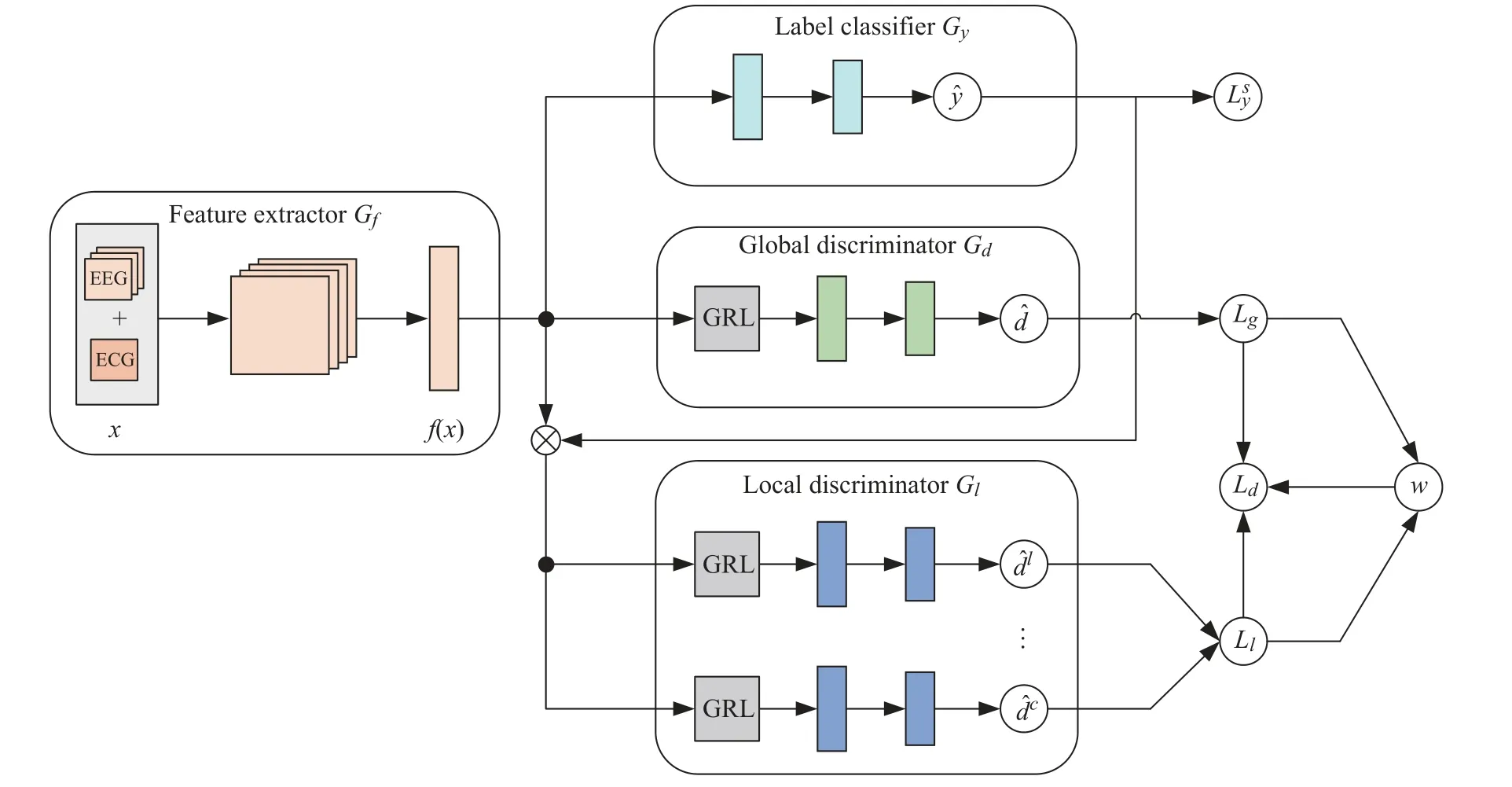
图2 动态对抗域自适应网络Fig.2 Dynamic adversarial adaptation network
1.2.1 特征提取器 特征提取器主要由卷积层、池化层和重构层组成,主要用于提取EEG 和ECG 中的抽象特征,并使得在该特征空间中来自不同领域的抽象特征间的数据分布是相似的。将经过预处理后的EEG 和ECG 信号进行组合输入到卷积层中,经过卷积核的卷积运算从中提取出抽象特征,再由池化层对特征进行降采样,减少网络整体参数的数量,本文采用的是最大池化。卷积函数如式(2)所示。
式中:xi为第i个输入样本,fmi为其经过卷积后得到的结果,wc和bc分别表示卷积核的权重与偏置,*表示卷积运算,g(·) 为激活函数,在特征提取器中全都采用Relu 激活函数,其计算如下:
池化公式如式(4)所示,采用最大池化操作,使用指定区域的最大值作为特征输出,得到pmi为池化层的输出结果。
使用重构层将该特征转化为最终的抽象特征向量f(xi) ,如式(5)所示。
1.2.2 标签分类器 标签分类器由全连接层组成,主要用于对输入的样本特征进行分类,得到其属于某一类别的概率。对于源域样本而言,全连接层的输出还会与其真实标签计算标签分类损失,作为网络在训练时的一项重要优化目标。标签分类器Gy的输出如式(6)所示。
其中:f(xi) 为第i个样本的特征,wg和bg分别表示全连接层的权重与偏置,为输出经过激活函数g(·)后得到类别概率,除最后一层外都采用Relu激活函数,最后一层采用sigmoid 激活函数,其计算式如式(7)所示。
第k个源域的标签分类损失如式(8)所示,和是对样本xi∈预测的类别标签和真实类别标签,为对应源域的样本数量,L(·) 为交叉熵损失,具体计算方法见式(9)。
1.2.3 全局域鉴别器 全局域鉴别器由梯度翻转层和全连接层组成,在网络中与特征提取器形成对抗博弈的关系。特征提取器在映射域特征不变时会对域鉴别器施加一个混淆域间特征的影响,而域鉴别器需要在该影响下区分出两个域的样本,在对抗中完成域自适应任务。为了实现对抗过程的一体化训练,在特征提取器和域鉴别器之间引入了梯度翻转层(GRL),使训练时特征的正向传播进行一个恒等变换,而在反向传播过程中梯度乘以一个负数再反向传递,使两类损失在训练时变化趋势相反。梯度翻转层输出R(x) 和其梯度的计算式如式(10)所示。
其中: α ∈(0,1) 是随着训练轮次增加而趋近于1,其计算式见式(11)。
其中: γ 为超参数,训练时设置为10;p∈(0,1) ,表示当前训练轮次在总轮次中的占比。
在全局域鉴别器中,全连接层的激活函数除最后一层外其余都设置为Relu 函数,最后一层采用sigmoid函数。鉴别目标是区分出样本来自于源域还是目标域。全局域鉴别器Gd的输出如下:
其中:f(xi) 为第i个样本的特征;wd和bd分别表示全局域鉴别器的权重与偏置;g(·)为激活函数,如式(7)所示。具体的全局域鉴别损失Lg如式(13)所示。
1.2.4 局部域鉴别器 局部域鉴别器同样由梯度翻转层和全连接层组成,该结构对网络整体优化目标施加一个子域对抗损失,可以实现颗粒度更为细致的子域自适应,从而拉近领域整体间的条件分布。
局部域鉴别器结构由C个子域鉴别器构成,C为类别数量,每个子域鉴别器对应一个类别,训练时负责拉近源域和目标域对应类别的数据样本。每个子域鉴别器和全局域鉴别器结构类似,都是由GRL和全连接层组成。
计算时使用目标域样本的预测伪标签来区分该样本属于哪一个类别。其中,第c个子域鉴别器的输出为:
其中:f(xi) 为第i个样本的特征;和分别表示第c个局部域鉴别器的权重与偏置;g(·)为激活函数,如式(7)所示;表示第i个样本属于第c个类别的概率。局部域鉴别损失之和如下式所示:
其中: λ 为对抗双方权重超参数,其取值范围为 λ >0 ;w为动态调节因子,训练过程在(0, 1)间波动,动态地调节全局域损失和局部域损失的相对比重。w的计算式如式(17)所示:
当域鉴别器的损失越大时,说明域间数据分布越相近,距离的计算值也越小。而分别表征了第k个源域和目标域间边缘分布和条件分布大小,当某一项越大时,动态调节因子w会使其对应的损失在总损失中的比重越大,表示对于该项损失的关注度越高。所以,动态调节因子会自适应地调节目标域对于源域的边缘分布或条件分布的关注程度,提升模型性能。
此外,式(18)中的域间分布距离估算值无法保证其非负性,当初始的全局域鉴别损失Lg或者局部域鉴别损失Ll大于0.5 时,会出现距离估计值为负的情况,这会导致动态调节因子越界。所以本文提出改进的动态对抗域自适应网络(modified Dynamic Adversarial Adaptation Network, mDAAN),将域间分布估计值修正为式(19)所示,保证其在任何训练情况下的非负性。

图3 动态调节因子Fig.3 Dynamic adversarial factor
1.3 集成学习
集成学习指通过构建多个基分类器并按照一定策略综合其结果来完成学习任务[19]。将第k个源域和目标域Dt训练所得模型的识别结果记为yk,k∈(1,2,···,K),K为优选源域的数量。基于这K个单源域识别结果,采用集成学习的投票策略来得到目标域样本最后的分类结果,本文主要采用硬投票(Hard)和软投票(Soft)两种方法建立多源域模型。
硬投票指每个源域训练所得的模型对于最终分类结果的重要性相同,采用少数服从多数的原则集成得到最终结果。软投票则利用1.1 节中计算得到的源域与目标域分布相似性,对模型的重要性进行衡量,最终的分类结果见下式:
2 实验结果分析
2.1 实验数据与实验设置
本文采用开源的WAUC 脑力负荷数据集[20],该数据集考虑到真实场景中体力活动会对脑力负荷评估带来的影响,采集了在3 种不同体力(高体力(High-Phy)、低体力(Low-Phy)和无体力(No-Phy))活动条件下48 个被试执行脑力负荷任务时的多源生理信号数据。采集的生理信号种类包括:EEG、ECG、皮肤电反应(Galvanic Skin Response, GSR)、血压(Blood Volume Pulse, BVP) 、呼吸以及体温。考虑到信号对脑力负荷变化的敏感性以及信号采样频率的差异,本文只使用47 个具有完整实验数据和标记的被试EEG 和ECG 信号数据。
实验设定每个被试进行6 组实验,每组实验在静息、低强度或高强度体力活动下分别执行MATBII 脑力负荷任务[21]。其中被试需要同时完成系统监控、跟踪和资源管理3 类任务,研究人员通过调节滑杆速度、故障率等参数来区分出低和高两种脑力负荷任务,被试可以选择跑步机或是固定自行车进行体力运动。每组实验由基线、任务和主观评价这3 个阶段组成,图4 显示了具体的实验流程。在实验的开始阶段,被试在60 s 内保持放松状态,该阶段称为基线1;然后执行120 s 的指定负荷强度的体力运动,该阶段称为基线2;之后开始执行600 s 的体力和脑力综合任务,最后在休息300 s 的过程中填写NASA-TLX 问卷[22],进行主观脑力负荷评估。为了避免实验顺序带来的影响,每个被试的6 组实验顺序都被打乱。文献[20]为了验证脑力负荷实验设置的科学性,对NASA-TLX 的6 个维度进行混合模型方差分析(Analysis of Variance, ANOVA),结果表明被试者的所有主观评分都受到任务参数变化的显著影响。
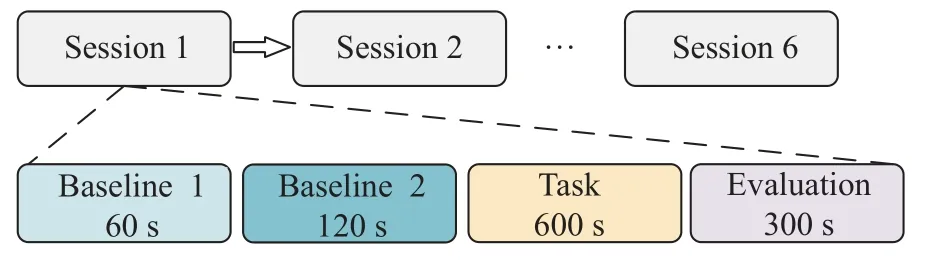
图4 实验流程Fig.4 Experiment flow
被试在实验过程中佩戴Enobio 头盔和Bioharness胸带分别用于采集8 通道的EEG 信号和1 通道的ECG 信号,采样频率分别为500 Hz 和250 Hz。其中,根据国际10-20 系统,EEG 信号的8 个导联位置为P3、T9、AF7、FP1、FP2、AF8、T10 和P4,2 个参考电极位于Fpz 和Nz 处。本文对每名被试每种体力负荷下两类脑力负荷状态共计1 200 s 的生理信号分别进行预处理。EEG 信号首先对其降采样到250 Hz,再进行0.1~45 Hz 的带通滤波,最后采用小波增强独立主成分分析(wICA)去除运动伪迹。对于ECG 信号采用0.5~30 Hz 的带通滤波,之后采用Pan-Tompkins 算法进行R 波提取,得到心率变异性信号(Heartrate-variability,HRV)作为输入。
预处理之后按照大小为1 s 的窗口对数据进行切片,得到每类脑力负荷样本各600 个。为了适应卷积神经网络的输入形式,将每个样本的250 个采样点按照每行采样点连续排列的方式转化为15*15 的格式,舍弃了每秒样本最后25 个采样点。
本文基于Python3.8 下的Pytorch 框架实现,实验环境为:AMD Ryzen 7 4800H CPU @ 2.90 GHz,16 G内存, NVDIA GeForce GTX 1650 显卡, 64 位Windows10 操作系统。在反复实验的基础上,特征提取器由2 个卷积层和最大池化层构成,在卷积之后进行批标准化操作;标签分类器、全局域鉴别器和局部域鉴别器均由2 个全连接层构成,每层全连接层都采用dropout 来避免参数过拟合。
本文采用留一法,每个被试轮流当作目标域,其余被试作为多源域集合。在建立一对一的深度迁移模型过程中,训练阶段除了利用到源域和目标域的样本信息外,还利用了源域数据的标签信息,测试时只用到目标域的样本信息,在每次网络参数更新后,都用目标域的数据对网络性能进行测试。网络训练选取Adam 优化器,Batch Size 设置为30,Epoch 设置为100,学习率设置为0.001,网络整体损失中超参数λ设置为0.25。
2.2 源域优选效果分析
为了验证源域优选的效果,分析了源域被试数量与目标域平均分类精度的关系,结果如图5 所示。该曲线的计算流程如下:首先将多源域集合中所有源域分别与目标域计算得到MMD 距离,根据MMD距离由小到大对源域优先级进行排序;然后按照顺序为源域与目标域数据建立一对一的深度迁移模型;当建立的模型数量大于1 个时,采用软投票的策略集成多个模型的识别结果。
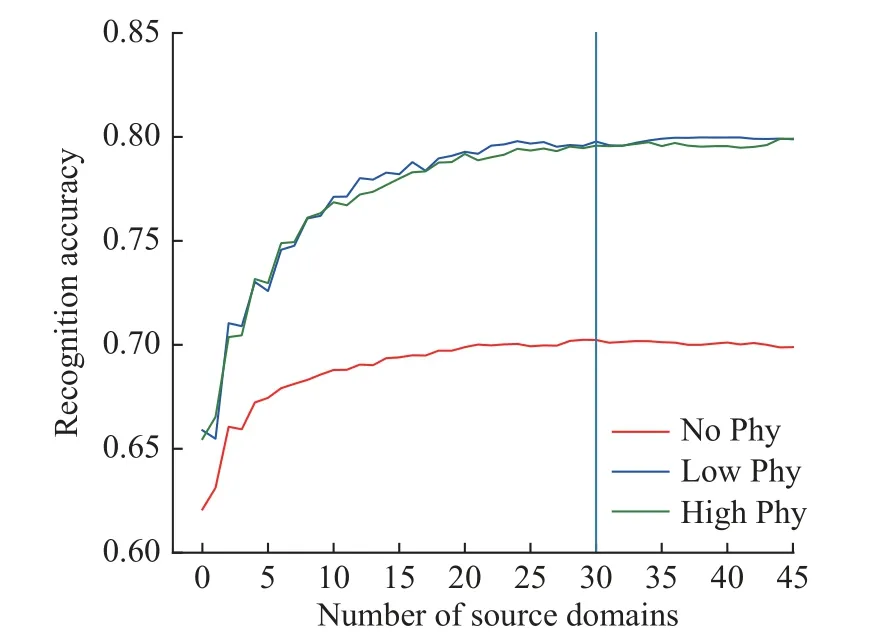
图5 分类精度与源域数量关系图Fig.5 Relationship between recognition accuracy and number of source domains
由图5 可见,当源域被试数量小于10 个时,分类精度处于快速上升阶段,而当源域被试数量增加到超过30 个时,精度处于相对稳定的状态。本文将源域被试集合中被试个数K设为30,在减少了1/3的训练时间的同时,最大可能保证了目标域数据的分类精度。
2.3 改进的动态对抗域自适应网络效果分析
训练过程中源域的分类损失和目标域的测试损失如图6 所示。在网络训练的开始阶段,源域的分类损失下降较快,随后由于特征提取与域鉴别器在训练中不断地对抗博弈,目标域与源域实现了域自适应的训练目标,目标域测试的损失也随之下降到稳定的状态。
本文采用t 分布随机邻域嵌入算法(t-distributed Stochastic Neighbor Embedding, tSEN),将特征提取器所提取的高维抽象特征映射到二维空间中,并保留样本间的相关性,实现域自适应前后数据分布差异的可视化。图7 所示为抽象特征的可视化图像。
如图7(a)所示,在域自适应之前源域和目标域数据分布是杂乱无章的,但是两者边缘分布具有一定相似性;图7(b)所示DANN 网络适配后目标域的两类样本虽然不再随机分布在平面中,但是仍然具有重叠部分无法分离;由图7(c)可见,MADA 网络适配后虽然目标域的两类样本变得可分离但是与源域的分类超平面差异依然存在;在图7(d)中,目标域的边缘和条件分布在经过DAAN 适配后更接近源域,其样本在特征空间中变为线性可分离,而且分类超平面与源域相似,这说明DAAN 的适配效果明显好于DANN 和MADA。
2.4 集成学习效果分析
表1 中对采用集成学习前后的识别结果进行了比较。“Avg”为30 个单源域模型的平均识别精度,比采用集成学习构建多源域模型的识别精度低12%左右。表1 中还对比了不同集成学习的结果,其中软投票的识别效果要略优于硬投票。由表1 可知,低体力活动下脑力负荷识别精度比高体力活动状态下略高,而无体力活动下的识别精度较有体力活动下的精度低10%左右,这与单被试脑力负荷识别结果一致[22]。文献[20]中给出的原因是体力活动和脑力负荷间存在相互作用,在进行体力活动时被试要付出额外的精力来维持运动稳定,比如跑步的速度或是自行车的平衡,而这将对被试脑力资源的分配产生影响。而当体力负荷达到一定水平后,被试者脑力负荷水平变化将会更有区分度。
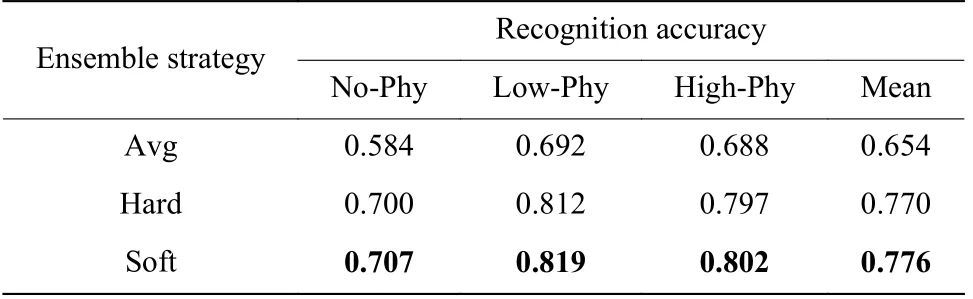
表1 不同集成策略的识别精度Table 1 Recognition accuracy of different ensemble strategies
2.5 迁移学习算法比较
为了验证动态对抗域自适应网络的迁移性能,本文选取了2 种浅层域自适应方法和3 种深度域自适应方法进行对比。其中对比的浅层域自适应方法为JDA 和ARTL,这两种域自适应方法同时考虑适配边缘分布和条件分布,但由于这两种方法无法直接处理原始信号,所以本文对EEG 信号提取其δ、θ、α、β和γ等5 个频带的功率谱密度(Power Spectral Density, PSD)特征,对ECG 预处理后得到的HRV 信号提取均值、标准差、一阶和二阶差分均值以及标准差等时域特征作为浅层域自适应的输入。
本文还对比了DDC、DANN、MADA 及未改进的DAAN 这4 种深度域自适应方法,其中DDC 为非对抗形式的深度域自适应方法。DANN 和MADA本质上分别为只包含全局域鉴别器和局部域鉴别的动态对抗域自适应网络,即动态调节因子w恒定设置为1 和0。
这些方法都采用上述的多源域迁移策略,被试数量也设置为30,识别精度最终结果如表2 所示。采用深度域自适应方法后迁移性能要明显优于传统的领域自适应方法,且无需繁琐的特征提取步骤。而在深度领域自适应技术的对比中,DAAN 在综合考虑边缘分布和条件分布后迁移的效果明显好于其他只考虑单一分布的深度域自适应方法。此外,相比于原始的DAAN,调整域间分布估计公式后的mDAAN 其迁移性能也有所提高。
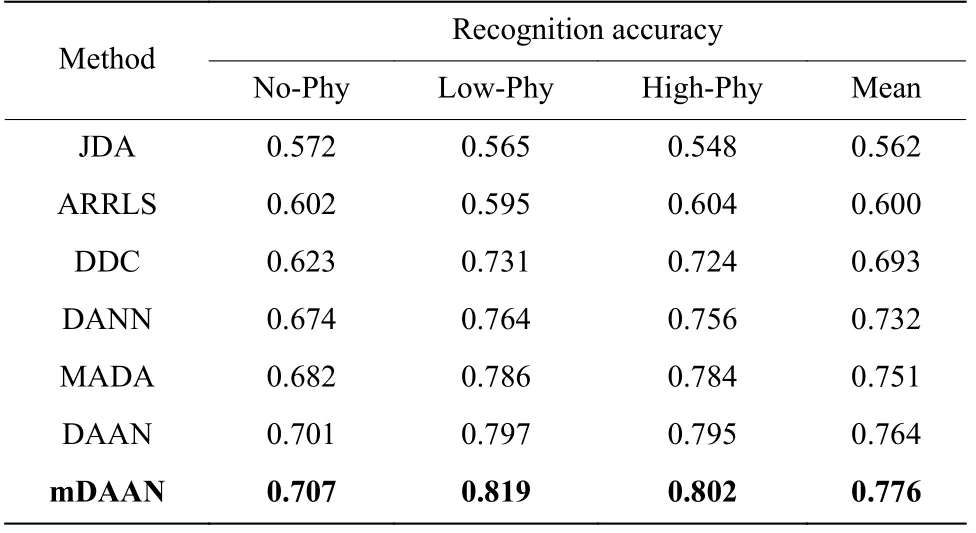
表2 不同域自适应方法的识别精度Table 2 Recognition accuracy of different domain adaptive methods
表3 中示出了mDAAN 算法与对比算法在多源域迁移框架下进行迁移的平均离线训练和测试时间。浅层的JDA 和ARRLS 在提取手工特征的基础上进行,训练时间和测试时间都比深度方法少;深度迁移方法由于其输入为原始的生理信号,训练时同时完成特征提取和迁移学习任务,训练时间较长,但训练完成后测试时间与其他方法差距较小。在对抗形式的深度域自适应方法中,模型间整体的训练和测试时间相差不大。

表3 不同域自适应方法的训练与测试时间Table 3 Training and testing time of different domain adaptive methods
2.6 同类结果对比
同类研究的对比结果见表4。文献[20]和文献[23]同样使用WAUC 数据集展开研究,其中文献[20]在没有采用迁移学习方法的基础上直接进行迁移只得到平均51.3%的分类精度,而文献[23]使用K-L 散度定量评估被试间边缘和条件分布差异,使用zscore 归一化方法减少被试间数据分布差异,得到63.7%的平均跨被试分类精度。文献[24]对8 个被试在aCAMS 任务下采集到的EEG 信号提取了小波包特征,然后采用核谱回归和可转移判别降维方法对特征向量进行降维的同时完成被试间迁移,在KNN 分类器上取得了72.3%三分类精度。文献[25]采集了被试在执行N-back 任务下的fNIRS 信号,使用瞬态伪影去除算法(TARA)去除信号伪迹,采用基于Fused Gromov-Wasserstein (FG-W)的域自适应方法在对齐被试间数据分布的同时获得跨被试识别模型,得到55%的四分类精度。文献[26]采集了真实驾驶环境中的4 种生理信号数据和2 种车辆信息数据,提出MTS-ADNN 模型进行域自适应,该模型主要在DANN 的域鉴别器中引入伪标签信息使其在一定程度上也能适配条件分布,最终得到74.3%的二分类识别精度。上述研究结果表明,本文利用深度域自适应方法在基于生理信号的跨被试脑力负荷识别任务上相较于同类研究取得了更好的效果。
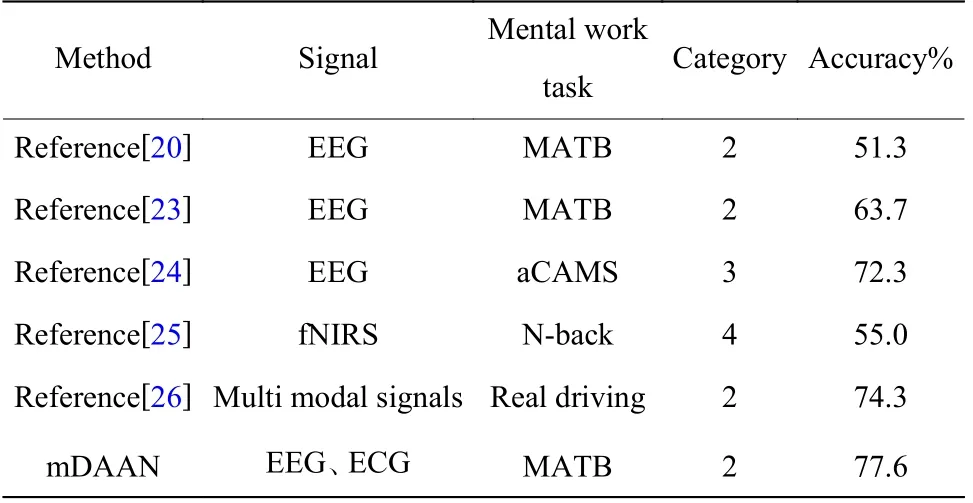
表4 同类研究对比Table 4 Comparison of similar studies
3 结束语
本文采用EEG 和ECG 信号构建了跨被试的脑力负荷识别模型,筛选出与目标域被试数据分布相近的源域被试集合后,采用改进的动态对抗域自适应网络进行模型迁移,最后采用不同的投票策略集成识别结果。实验结果表明,源域优选策略能够减少训练成本并且可以避免负迁移的影响;改进的动态对抗域自适应网络能够很好地实现迁移目的;集成学习策略能够综合利用多个源域的互补信息,进一步提升模型的性能。本文构建的脑力负荷识别模型属于离线状态下的建模分析,在实际的应用情景下对脑力负荷状态的检测以及预警需要具有一定的实时性,下一步研究将考虑在模型中引入网络预训练等手段对网络实时性进行优化,建立在线的脑力负荷识别模型。
