软件定义异构车联网移动智能服务定制算法设计
2023-11-02朱剑宝谢道彪
余 庚,朱剑宝,谢道彪
(福建船政交通职业学院,福建 福州 350007)
0 引言
为顺应智能网联汽车发展,促进车联网QoS[1]服务成效走向纵深,SDN技术被广泛用于扩展异构车联网的各项应用服务。然而由于异构车联网所服务的移动车端存在接入规模较大且移动频繁等诸多复杂特征,导致SDN技术为异构车联网提供的在线计算服务时效存在不确定性,进而弱化了QoS服务成效。造成该现象的原因在于当移动车端发起数据流计算请求时,数据转发单元和控制器之间需交互较长时间以分割数据包长度,制定数据包适配规则,形成流表项并下发到每一个数据转发单元。尤其在上下班及节假日等繁忙时段,移动车端的接入规模呈现高度随机突发特征,接入状态呈现高频移动特性,导致每一次产生的数据流第一个数据子集需耗费较多的时延代价用于建立流表项。移动车端在高速移动期间总是频繁向附近车联网接入点提出获取相同服务的请求,这势必要求数据层面的数据转发单元之间不仅能够快速广播流表项,同时要求数据转发设备和应用服务器之间能够进行数据无缝传输。因此有必要根据异构车联网的接入特征重构SDN[2]数据路由机制,为移动车端设计一个兼具平滑和实时的在线移动计算方案。基于此,本文构思将SDN架构融入异构车联网,用于实现为移动车端提供移动智能服务定制(Mobile Intelligent Service Customization,MISC)的技术。
1 方案原理
在移动用户设备和移动车端所组成的异构车联网中,由于节点移动规律和移动范围须符合实际交通系统的部署,因此移动节点的运动需遵循道路网络规则。正是这样的移动局限性使得可以通过统计分析节点过往移动路径和移动模式来推算出移动节点未来的运动轨迹。目前已有学者陆续针对移动轨迹预测开展相关研究。张海霞等[3]通过为车载终端构建移动行为评估模型来实现导航路线测算。这为异构车联网移动节点的行车路径评估提供了良好的依据。同时依托强大的云计算能力不仅可以高速响应运动轨迹的移动计算,也能进一步提高预测数据的可信度。因此,通过重构SDN数据路由机制为异构车联网节点定制移动智能服务的方案具有可行性。
该方案首先根据移动行为推算出节点即将产生的概率最高的行车轨迹。再采用主动部署的方式由控制层发起监测,记录每个数据转发节点的通信范围。然后在可能性最大的评估轨迹所经过的节点中提前添加流表项来实现移动智能服务定制的目标。采用评估策略添加定制流表项不仅最大程度地缩小所涉及节点的规模,同时可有效约束定制流表项的规模,避免不必要的资源消耗。当异构车联网边缘移动终端靠近此节点申请接入时,无须频繁地向控制层提交数据适配的请求,控制器也不再制定流表下发给节点。当有新的移动数据流发起时,该数据流的第一个数据子集被转发到交换机。由于交换机内存已加载了该数据子集的流表,只需直接传输即可。通过缺省数据层和控制器的双工交互,加速了预加载的移动流表项读取速度,提高了定制移动智能服务的QoS成效。
然而预测存在一定偏差,偏差将导致节点所加载的定制流表项失效。随着时间推移,流表项将占据更多节点内存,消耗更多网络计算资源,进而弱化异构车联网全网节点性能。且采用预测机制在部署成本上表现欠佳,缺乏实用性。因此有必要根据道路交通网络实际情况为所定制的流表项引入超时机制[4]。倘若在特定的时间间隔内节点未启用定制流表项,则将其从节点内存中移除。因此评估移动车端移动轨迹的精度决定了移动智能服务的定制成效。
2 方案模型
为使异构车联网能够为移动车端提供平滑的移动接入服务,通过挖掘分析既往移动轨迹信息来计算移动车端未来行车路线已成为研究车联网的关键技术之一。移动车端行驶过的每一个轨迹均代表了该移动车端过往每个时刻所处的离散位置。根据时序先后将这些位置点形成一个序列,再结合关联法则[5]运用数据挖掘算法对车端的移动方位开展测算。然而移动车端行驶轨迹的持续增加将增加算法复杂度。但该算法所涉及的马尔科夫方位评估模型被证实和实际异构车联网环境中终端行车规律较吻合,评估精度较高。即便如此,该模型依然存在一些不足。诸如,状态空间规模与阶数成正比、状态参数选取稍有偏差将造成预测轨迹严重偏离实际轨迹。随着异构车联网接入的移动车端规模不断增加,潜在风险也逐渐加大。因此本文考虑通过引入一个阶数自适应调整的马尔科夫方位评估模型(Markov Bearing Evaluation Model with Adaptive Order Adjustment,AOA)来解决该风险。模型的建立过程如下:
假设X是有限个状态构成的马尔科夫链状态空间集。其中随机状态序列长度有限,记作{Xk}。k为从0开始的自然数,状态nk和状态m均为空间集合X的子集。如果存在一个阶数为z的自适应马尔科夫方位评估模型,则状态空间集要满足如下规则:
P(Xk+1=m|Xk-z+1=nk-z+1,…,Xk-1=nk-1,Xk=nk)=P(Xk+1=m|X0=n0,X1=n1,…,Xk-1=nk-1,Xk=nk).
此时,{Xk}即为自适应马尔科夫链。通过统计第z-1个随机状态序列的概率和目前第z个随机状态序列的概率来共同确定第z+1个随机状态序列的概率。由于变量z的长度可调,故称为自适应模型。若变量z取值1,则自适应马尔科夫方位评估模型即为初始标准化的马尔科夫方位评估模型。该自适应马尔科夫方位评估模型的结构描述为:将随机状态序列集合转化为一棵非空概率的拓扑树,拓扑树的高度为H。将随机状态序列集合中的字符标识作为该拓扑树的边权重。任意一个树节点延伸出的边与该节点的其他边具有不同的字符标识。除了根部主节点之外的其他节点均有一个字符序列串。该字符序列串由从自身节点开始逐渐遍历到主节点过程中所涉及的所有边的字符标识权重组合而成。拓扑树的节点同时分配了概率向量用于表明自身节点字符标识串后续字符的惯性值。相对于传统马尔科夫方位评估模型(Traditional Markov Orientation Evaluation Model,TMOE),自适应马尔科夫方位评估模型优势在于算法可避免不断累积的历史行车轨迹规模对算法复杂度的影响[6]。同时由于移动车端受到实际道路驾驶环境的限制以及驾驶员行车习惯的影响,移动轨迹具有一定的约束性和规律性。因此部署自适应马尔科夫方位评估模型应首先将拓扑树节点存储的过往移动轨迹数据作为训练对象,通过定义信任阈值建立信任机制筛选出可靠性较高的节点进行拓扑树的优化重构。然后根据移动车端当前行程所组建的移动轨迹序列[7],去和优化重构后的拓扑树节点开展适配。直到遍历出从当前节点出发能够途经的概率最大的那个拓扑树节点,即作为本次评估的未来移动轨迹。由于实际道路交通网络环境中的交叉路口都部署了诸多路侧单元与移动车端进行交互,增加了问题的复杂度。为简化说明,本文将位于交叉路口的路侧单元视为移动轨迹的评估点,以便简化随机状态移动轨迹序列的表征,优化算法过程。
3 算法设计
设计算法前先规划道路交通网络和移动轨迹状态序列。具体规划步骤如下:假设道路的集合为D={d0,d1,…,dn},道路交叉路口的路口单元集合为L={l0,l1,…,ln}。引入一个路网有向图G=(D,L)。本文将位于交叉路口的路侧单元视为移动轨迹的评估点[8],因此移动终端途经的路侧单元即为移动路径序列,记作p={l1,l2,…,lm},其中n>m。每个移动路径的跨度为K。移动终端在整个图G的移动路径序列集合为P={p1,p2,…,pn}。为提高移动终端在下一时刻移动路径的评估精度,考虑将早期交叉路口的信息缺省,将剩余的移动轨迹序列定义为序列子集,记作Sm(p)={lm,lm+1,…,ln}。完整的算法实施过程应先对过往移动轨迹样本进行训练再对未来的移动趋势开展评估。
假设移动路径序列集合中长度最大的轨迹序列为pK,max,该序列长度记作kmax。从长度最小的轨迹序列开始遍历路径序列集合,直至遍历完高度为H的拓扑树。具体遍历过程如下:
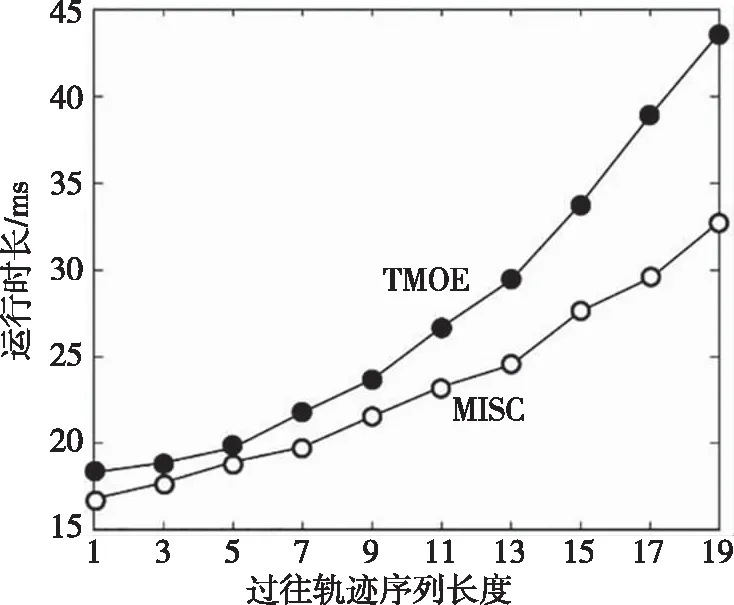
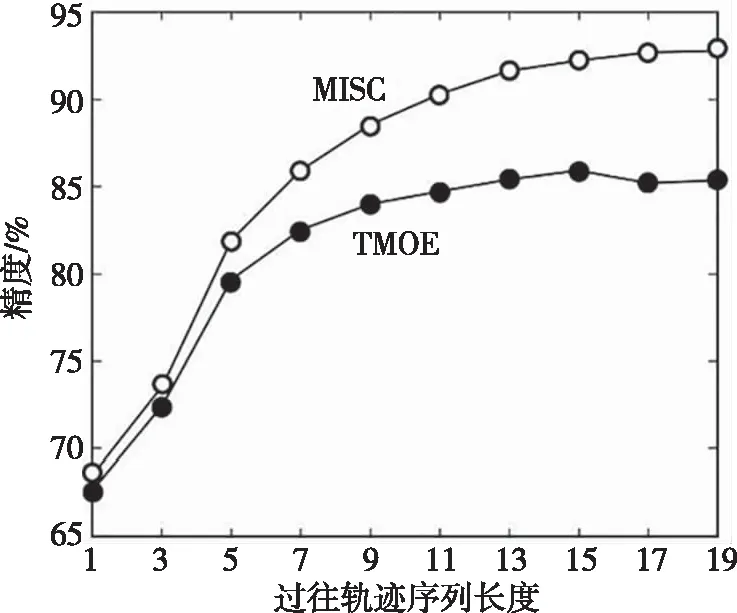
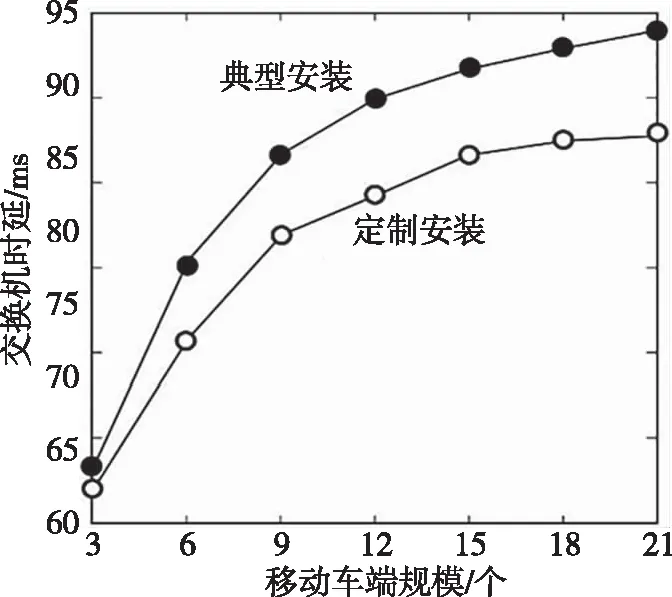
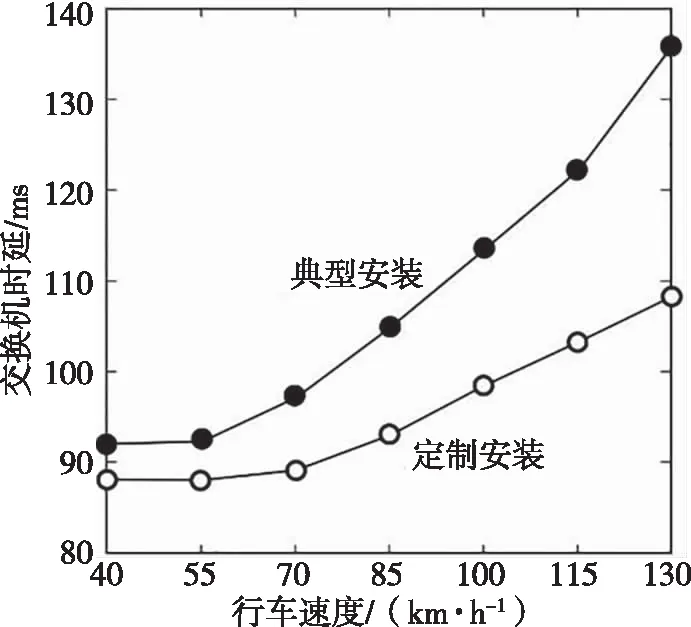
首先,构建一个根主节点的拓扑树。将交叉路口单元集内所有路侧单元激活的频次视为该主节点的经验概率[9],即概率向量。假设有个特定的路口单元设备在路口单元集合采集的样本集合中激活的频次为fL,全部的路口单元设备在路口单元集合采集的样本集合中激活的频次为fA,则概率向量表征为C(lm)=fL/fA。由于传统马尔科夫方位评估模型在部署期间存在待用节点序列集合规模随时间推移呈现骤增的现象,本文引入一个可信度阈值门限Pth1。如果某节点属于可靠的待用节点,可考虑纳入序列集合,就须满足关系式Pth1 其次,循环开展迭代式计算,直至遍历完整个拓扑树完成可信节点的拓扑树优化重构。在待用节点集内选择一个当前待选节点,表征为pK。再推算出该待选节点的后面节点的概率向量。倘若节点li在集合P紧随pK被激活的概率C(li|pL)超过了可信度阈值门限Pth2,则节点li属于可信节点,可作为拓扑树的节点。字符串为pKli的节点作为节点li的备选后续节点。假设节点li紧随pK被激活的频次为f0,过往样本集合紧随pK出现的交叉路口的规模为fP,则概率向量表征为C(li|pK)=f0/fP。通过定义Pth2阈值门限机制高效地简化了拓扑树冗繁的结构。 考虑实际道路环境中的驾驶情况,移动终端的轨迹序列的后续备选节点和pK中末尾交叉路口单元总是保持相邻,故仅遍历S(lK)-1次即可算得移动轨迹序列的概率向量。其中,lK指pK末端的交叉路口;S(lK)指和路侧单元lK关联的路口单元集合。这样的设计可显著降低算法时间复杂度和空间复杂度。但在传统评估模型中需完成路侧单元集合内每一个路口单元设备的遍历。相比之下,传统评估模型的算法复杂度较高。 假设现有一个移动终端接入软件定义异构车联网,所产生的移动轨迹序列为pi={l1,l2,…,li},序列跨度为Ki。当H>Ki时,交叉路口单元l′满足条件l′∈{S(l1)-l2}。若概率向量符合Pth2 实施过往移动轨迹样本训练后形成一个可信度较高的优化拓扑树[10]。通过该优化拓扑树便可推算出移动终端后续的行车路径。推算过程为:借助路侧单元采集存储的数据来提取移动终端当前行车状态下的移动轨迹序列pl。从过往移动轨迹拓扑树的根主节点开始,让pl按照逆序的方式去遍历拓扑树直至遍历到可适配的拓扑树节点。相对而言,跨度较短的时间内所采集的移动终端行车轨迹对于测算未来移动轨迹更有参考价值。因此有必要更新pl中的序列,将时间跨度较大的过往交叉路口单元的节点剔除以便实现当前行车状态和拓扑树的精确适配[11]。所以如果pl按照逆序的方式遍历完整个拓扑树依然未能找到可适配的节点,需按照先后顺序选取pl中跨度第二长、第三长的子序列开展拓扑树节点的遍历配对。再从所适配的节点中选出概率向量最高的那个节点作为移动车端未来大概率途经的目标方位点。 MISC算法经由过往移动轨迹样本精确训练和未来行车路径精确评估两个步骤的设计,为软件定义异构车联网提前定制安装移动服务流表项提供了可靠的节点选择依据。使软件定义异构车联网提供平滑、无缝的快速移动智能定制服务成为可能。 为验证所构思的MISC算法模型的合理性,测试环节设计了两组测试工作。第一组测试工作旨在验证MISC算法模型相对于TMOE算法模型的优势。第二组测试工作旨在验证MISC算法模型部署在软件定义异构车联网中的定制成效。 针对第一组测试工作,相关参数设置为:Pth1=3×10-4,Pth2=3×10-3,K<20。假设通过模拟器安排的移动轨迹序列规模为A=8 000。将此规模序列随机地设置成8个轨迹序列小组,任意选择2个小组开展行车状态评估,任意选择6个小组开展样本训练。每个小组安排1 000条轨迹序列。算法所在路段的交叉路口单元设为80个。循环执行上述分组操作10次后再收集测试数据开展分析。该项测试工作主要考察两个算法方案的复杂度以及行车轨迹测算精度。 图1描述了两种算法方案在开展移动轨迹预估时,过往轨迹长度变化对算法运行时间的影响程度。从曲线走势可见,随着过往移动轨迹序列长度持续增长,两种算法开展未来移动轨迹测算的时间成本持续增加,但本文构思的MISC算法运行时间成本相对低一些。究其原因,MISC算法思想是将过往移动轨迹序列和拓扑树节点开展适配,算法复杂度仅为O(A·K)。而TMOE算法则利用传统矩阵转移的方式来开展轨迹测算,导致算法复杂度高达O(n3·z)。随着时间推移,引入信任阈值门限机制的MISC算法逐渐卸载了参考价值不大的交叉路口单元信息,算法性能得到持续优化,这样的优化机制是TMOE算法所不具备的。因此随着轨迹序列规模和长度持续增加,MISC算法下的时间成本优势表现得越加明显。 图1 算法时间成本 图2描述了两种算法方案在开展移动轨迹预估时,处理不同长度的过往移动轨迹序列所消耗的内存硬件资源情况。从曲线走势可见,两种算法在处理长度较小的过往移动轨迹序列时消耗的内存空间大小相差无几。随着长度持续增加,本文提出的MISC算法在处理数据时消耗的空间增量逐渐减小。出现这样的曲线走势是由于在评估未来移动轨迹时MISC算法方案通过创建优化拓扑树进行节点和序列适配的方法,该方法的复杂度仅为O(A)。而TMOE算法方案采用传统马尔科夫模型矩阵转移方法来开展预测,复杂度高达O(n2·z)。 图3描述了两种算法通过处理不同长度的移动轨迹序列评估的未来行车轨迹精度。不难看出,评估初期由于过往移动轨迹序列长度较短,两种算法在低阶状态下评估未来行车轨迹的精度没有太明显的区分。当增加过往移动轨迹序列长度,两种算法精度开始明显提升。随着过往移动轨迹序列长度进一步增加,MISC算法开始持续发挥出潜在计算优势,精度曲线继续走升,而TMOE算法的精度曲线则开始趋于平稳。这是由于MISC算法方案采用了自适应评估模型,可根据过往移动轨迹序列长度动态调整序列评估参数,并结合阈值门限机制进一步提升了MISC算法评估未来移动轨迹的精度。定制算法的部署成效主要取决于数据转发节点和控制层之间交互时延,以及终端移动的平滑性。因此第二组测试工作以响应时延为考察指标将MISC算法下的定制级安装方式和典型安装方式[12]开展对比。典型安装方式是在所有车联网数据转发节点中提前安装移动服务流表项。借助Mininet软件模拟搭建软件定义异构车联网环境,定义6个交换节点。通过变化接入异构车联网的移动车端行驶速度和移动车端规模来考察节点通信时延,进而验证定制级安装方式的智能性。 图3 算法评估精度 图4描述了两种安装方式在应对不同移动车端规模时交换机的通信时延。从曲线走势可见,接入软件定义异构车联网的移动车端数量越多,交换机通信时延代价总体越高,尤其是典型安装方式下的交换机通信时延代价更高。这是因为本文设计的定制级流表安装方式将典型安装方式中上行移动服务请求和下行计算服务响应两个流表降至一个流表。当移动车端行驶到异构车联网交换机节点附近并向其提请移动服务请求时,只要适配到该交换机内存中的移动服务流表即可获取下发的响应数据。这不仅缺省了服务请求转发到远程云数据中心的过程,也免去了控制层制定流表项下发的步骤。同时,由于持续增加的流表数量过度消耗交换机内存空间,导致交换机性能下降,进而引发通信迟缓的问题也得到有效解决。因此,定制级安装方式更有利于提升节点的通信效率,控制通信时延代价。 图4 交换机通信时延 图5描述了两种安装方式在应对不同移动车端行车速度时节点通信时延对比情况。由图5可见,当行车速度增加,两种安装方式下的节点通信时延都在增加,但本文定制级安装方式下的时延变化率较低。这是由于行车速度增加导致软件定义异构车联网节点拓扑结构发生更加快速的变化,加剧了网络变化的复杂度。此时典型安装方式因缺乏智能化移动流表适配的预安装功能,其移动支持能力较弱,导致节点通信时延延长。定制级安装方式则是在精确预测的下一个移动交换节点中提前定制安装了移动流表,显著地降低了通信时延,高效地增加了移动服务定制成效。这种成效将随移动车端速度增加而表现得更加明显。因此定制级安装方式在高速公路环境中也具备有一定的适应性。 图5 交换机通信时延 本文设计的移动智能服务定制算法依托软件定义网络架构优势,通过分析移动车端过往行车轨迹特征开展未来行车路径的评估。定制算法中关于未来移动轨迹的评估方案,不仅充分考虑了过往轨迹序列长度和数量等因素对异构车联网节点性能的影响,同时通过淘汰信任度较低的路口单元信息来确保子轨迹序列具有实时的参考价值,为软件定义异构车联网节点提前安装移动流表提供了科学的节点评估机制。经测试表明,该移动服务定制算法部署在软件定义异构车联网中具有良好的自适应性。4 方案测试
5 结语
