基于多头自注意力机制的基数估计研究
2023-10-31陈珊珊
王 焱, 陈珊珊
(南京邮电大学 计算机学院, 南京 210023)
0 引 言
基数估计是数据库查询数据过程中的关键流程,数据库的查询优化器根据基数估计算法的结果来选择最终执行计划,所以提高基数估计的准确性对查询优化十分重要。
传统的基数估计方法,如采样法和直方图等,在数据量不大、数据分布较均匀的情况下能够获得相对准确的结果。 然而现实中数据分布差异明显,不同属性之间往往存在一定的关联性,数据规模也经常难以预料,基于直方图或采样法的基数估计准确性就会降低。 尤其是查询中关联到多张表,数据规模急剧增大时,计算结果的偏差会成倍增加,准确性快速下降,最终导致优化器选择非最优的执行计划[1]。 而Leis[2]等提出基于索引的IBJS(Index-Based Join Sampling) 方法,在一定程度上解决了数据量的问题,但比较依赖于表的索引结构,较差的索引结构会导致基数估计结果也较差。
近年来,以神经网络为代表的机器学习技术迅速发展,也推动了数据库相关技术的研究,尤其是在一些复杂场景,如Li[3]等针对参数调优的问题提出了一种基于深度强化学习的自动化调优系统。 为了提高基数估计的准确性,本文采用神经网络中的多头注意力机制对表中数据列之间存在的逻辑关系进行学习,并针对SQL 语句的特征编码算法进行研究,结合多种更细粒度的特征编码算法,提升数据的编码效果。 实验结果表明该方法可以有效提高基数估计的准确率,优化数据库的查询,验证了模型的有效性。
1 相关工作
最近一些研究者已经开始将机器学习与基数估计 结 合, Kipf 等[4]提 出 了 MSCN ( Multi - Set Convolutional Network)框架,开创了将机器学习用于基数估计处理的先河;Karamyan 等[5]在MSCN 的基础上进行扩展,提出了一种基于递归树型的神经网络框架;LingChen 等[6]则提出了一种结合算子级深度神经网络的基数估计方法。
从对数据处理方式上看,目前利用机器学习来优化基数估计的方法主要分为两种:数据驱动(Data-Driven)和查询驱动(Query-Driven)。 基于数据驱动的模型主要是利用深度自回归模型(Deep Autoregressive)分析测试集中数据列的分布来计算估计值,主要缺点是其假设数据每一列都和前面列存在相关性,而现实中数据一些列有关,一些列之间无关,所以数据驱动模型在数据分布偏差较大时会出现明显误差[7]。 查询驱动则主要依赖于对于查询语句的分析和学习,使用特征化方法将查询语句转化为特征向量。 现有基于查询驱动的方法基本都采用单热编码(One-Hot Encoding)、二进制编码(Binary Encoding)等特征化的编码方法。 本文采用基于查询驱动的方式进行研究。
在结合机器学习应用和基数估计的过程中,Karamyan 等[5]采 用 的 RNN ( Recurrent Neural Network)模型,严重依赖数据的序列顺序,在查询语句含有多表连接的时候速度较慢;而Sun J 等[8]采用CNN (Convolutional Neural Network)模型,针对复杂查询时需要构建较多的卷积核来进行特征提取,参数较多,模型复杂。 针对上述问题,本文创新性地采用多头自注意力机制来对基数估计进行优化。 注意力机制的优点主要是不依赖于数据的序列顺序,更擅长捕捉数据或特征内部的相关性,能够充分利用和灵活捕捉数据列之间存在的逻辑关系,提高基数估计的准确性,减小估计误差。 注意力机制(Attention Mechanism)最早由Mnih 等[9]提出,用于计算机视觉,后来慢慢扩展到其他诸多领域的研究,比如语音识别、视频解析等。
2 模型架构和技术要点
数据库的查询过程中,查询优化部分会根据基数估计的结果来选择最终执行计划。 而基于多头自注意力机制的机器学习模型能够根据样本数据进行训练和学习,找到不同列之间的内在联系,提高基数估计的准确性,从而提高查询效率。
现有基于机器学习的基数估计模型框架如图1所示。

图1 基于机器学习的基数估计模型框架Fig.1 Machine learning based cardinality estimation model framework
本文主要在现有的模型框架基础上,对编码和模型部分进行优化。 为了更好地获取数据列之间的关系,本文采用了多种编码方式,从而在编码环节提高对数据关系的提取;不同于其他大多模型采用的CNN 和RNN 神经网络模型,本文使用多头注意力机制作为模型主体。
2.1 查询特征表达(Query Featurization)
查询特征表达主要是将一条文字形式的查询语句通过编码转为查询向量,以作为后续训练模型的输入,所以特征表达的编码方式十分关键。 与通常的单热编码、二进制编码不同,为了提高特征表达编码后得到的信息量,能够更细粒度捕获列之间的相关性,针对不同SQL 不同部分采用了不同的编码方法。
一条典型的SQL 查询语句可以分为4 个部分:查询涉及到的表、WHERE 子句中的列、WHERE 子句中的值、JOIN 连接关系。 例如语句SELECT *FROM orders JOIN users ON orders.user_id =user.id WHERE order.create_time >=“2022-01-01”AND user.age >=25,组成部分可以表示为:表-orders,列-order.create_time 和user.age,值-“2022-01-01”和25,连接关系-orders.user_id =user.id。
2.1.1 表编码(Tables Encoding)
因为可以把数据库中的所有表看做一个无向图(Undirected-graph)G,其中顶点是单个表,每边连接两个可以JOIN 的表,所以针对表编码采用了图嵌入的编码方法。
2.1.2 列编码(Columns Encoding)
对于数据表中的不同列,本文采用随即相关系数(Randomized Dependence Coefficient,RDC) 计算出数据列之间的相关性,并设置关系阈值。 经过验证,将相关系数的阈值取值为0.5,当RDC >0.5时,认为两列相关,否则认为两列无关;基于每两列之间的RDC值,本文针对每个表都构建出一个有向无环图(Directed Acyclic Graph, DAG);最后,利用node2vec 算法进行编码。
2.1.3 值编码(Value Encoding)
值编码主要是对于WHERE 子句中出现的值进行编码。 先对WHERE 子句中所有的值筛选并进行格式规范化处理,转换为范围查询,即a≤V(c)≤b的形式,其中V(c) 表示表V中的任意字段c,[a,b]是c的取值范围。 具体过程为等值查询V(c)=x表示为x≤V(c)≤x;对于单边范围查询,假设字段的范围大小是[0,1 024],则V(c)>x可以表示为x <V(c) ≤1 024;最终对于一条含有m个字段查询语句的值编码,可以用向量<ac1,bc1,ac2,bc2, … ,acm,bcm >表示。
2.1.4 连接编码(Join Encoding)
连接编码采用Joins2Vec 算法。 该算法分为3步:
(1)获取查询表的所有连接图;
(2)获得每个连接图的上下文关系;
(3)对连接图进行编码和优化。
假设分别有表T1、T2 和T3,其中T1 和T3 均与T2 存在连接关系,则获取表T3 的JOIN 编码过程如图2 所示。
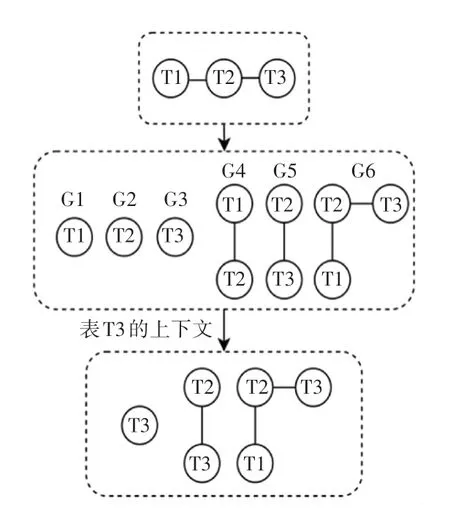
图2 JOIN 编码过程示例Fig.2 Join coding process example
本文模型特征表达原理示例如图3 所示。
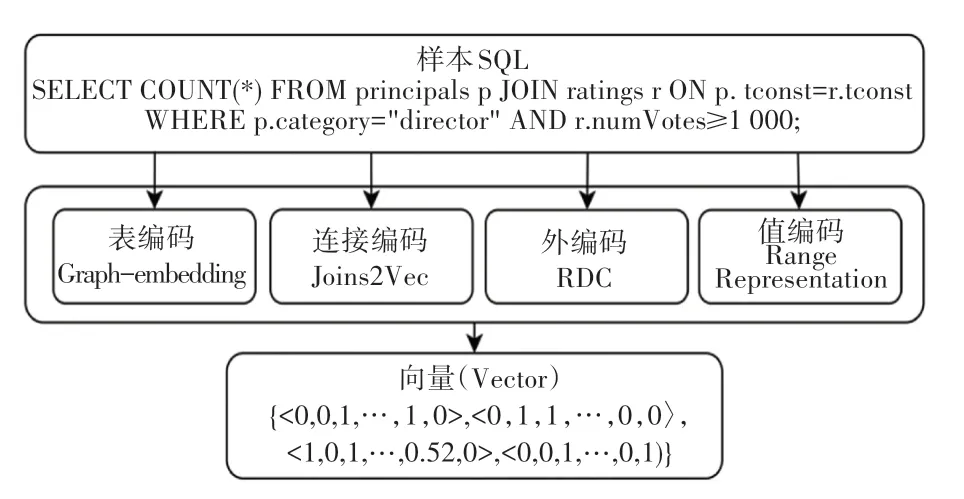
图3 模型特征表达原理示例Fig.3 Example of model feature expression principle
2.2 多头自注意力机制
由于自注意力机制在对特征加权处理等多方面优势,逐渐成为深度学习领域的热门方向[10]。 而多头自注意力机制是针对需要获取多个维度特征等场景需求对注意力机制的一种优化[11]。 多头自注意力机制利用多个头部采用相同的计算方式,给予不同的参数,从而从多个子空间进行特征表达,能够捕捉到更加丰富的特征信息,其基本原理是缩放点注意力机制如图4 所示,主要公式(1):

图4 缩放点积注意力机制Fig.4 Scaled dot-product attention mechanism
其中, 输入参数Q(Query)、K(Key)、V(Value)均为矩阵参数,分别代表查询矩阵、键矩阵和值矩阵;代表调节因子;k是矩阵K的维度;W0为转换矩阵。
在注意力机制中Q、K、V均由同一个输入,即由数据编码最终生成的特征向量,经过线性变换得到。 这样每一列都会和查询中涉及到的其他列进行注意力计算,从而提取学习列与列之间的依赖关系。 在对QKT点乘操作后,为避免维度爆炸导致梯度消失,增加因子进行调节。 多头注意力机制会赋予多个头部不同的参数来进行多次的线性映射,最后拼接所有子空间的注意力值。
本文考虑到某一列可能同时和其他多个数据列之间存在关系,所以选择多头自注意力机制提高对于不同字段关系的特征提取效果,其原理如图5所示。
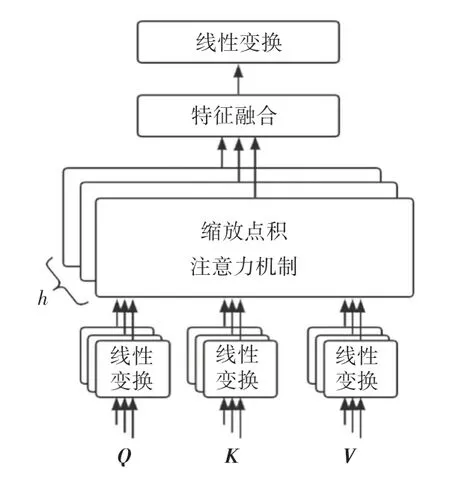
图5 多头自注意力机制Fig.5 Multi-head self-attention mechanism
3 实 验
本文实验步骤主要分为3 步:
(1)根据IMDb 数据集生成随机样本数据;
(2)对样本数据进行查询特征编码;
(3)将第二步得到的查询向量表达和实际基数作为机器学习模型的输入,然后进行模型训练,最终得到结果。
3.1 实验环境
实验配置见表1。

表1 实验配置Tab.1 Experimental configuration
3.2 数据集和训练集生成
IMDb 是一个收集全球影视数据的数据集,主要包括名称、演员、评论、票房、评分等信息,被广泛应用于科学研究。
为了防止多层JOIN 产生的空间爆炸,样本数据被限制最多包含2 层JOIN 关系。 基于IMDb 数据集,从表编码中抽取至少含有一个连接表的表t,以t为根节点进行广度优先搜索找到所有可以连接的表Dt,从Dt中选择一个表t′与t进行连接,整个过程重复[0,2]次;从每个表中抽取相应的列,根据列的类型和表中数据的范围大小选择值,随机组合谓词(=、<或>)生成WHERE 子句,这样就得到了一条完整的样本语句;最后,实际运行语句获得真实的查询基数,同时排除结果为空的样本,反复执行上述流程,即可获得实验所需的数据集,总计60 000 条,其中训练集40 000条,测试集10 000 条,验证集10 000 条。
3.3 数据预处理
为了简化并对输入参数统一处理,本文对实际获得的查询基数进行最大-最小缩放处理。 假设一个查询基数的集合为S ={card1,card2,…,cardn},其中 最 小 值 和 最 大 值 分 别 为card(min) 和card(max),则S中的每个数均可以用式(2) 代替。
3.4 实验结果分析
为验证方法的有效性,本文实验选择了两种流行的 关 系 型 数 据 库PostgresSQL (v13)、 MySQL(v5.7),和一种新型的基数估计方法(IBJS)、一种基于机器学习的基数估计方法(MSCN)作对比。采用式(3) 中的Qerror和式(4) 中的Loss来对方法的准确性进行描述,Qerror用于衡量测试结果与真实基数的偏差,Loss为模型的损失函数。 实验结果见表2。
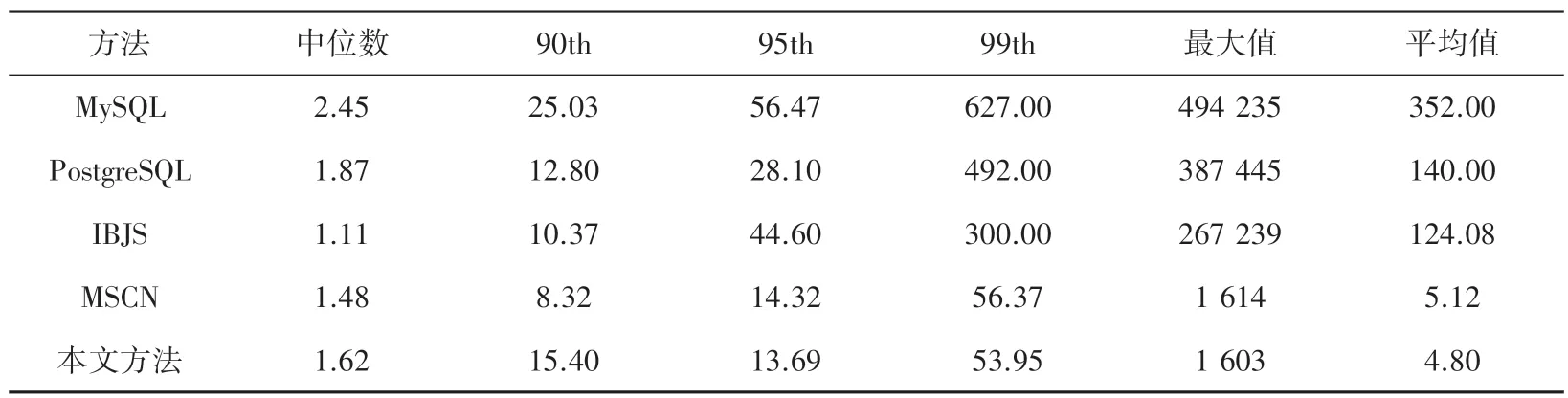
表2 与其它4 种方法的结果对比Tab.2 Comparison with the other four methods
由表2 可知,IBJS 方法在Qerror中值表现最好,但是过于依赖索引结构使得如果表中没有合理的索引结构,IBJS 的性能就会变得较差。 本文方法在第95 和99 个百分位上优于其他方法。 从平均值上看,方法的鲁棒性要优于IBJS 和MSCN。
基于机器学习的本文方法(SELF)和MSCN 方法在不同训练周期后的损失收敛对比如图6 所示。可以看出利用机器学习的基数估计方法在经过多次训练周期之后,其方法的损失迅速下降,准确度迅速提高;基于多头自注意力机制的本文方法在初期时效果不如MSCN 方法,但是经过20 次左右的训练周期之后,在准确性上略优于MSCN,并且在75 次训练周期之后,这两种基于机器学习的模型损失收敛趋于接近。
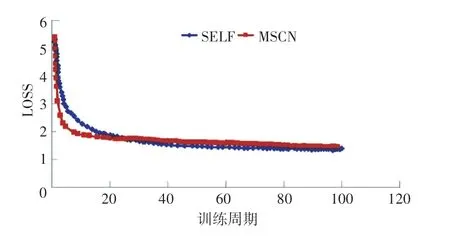
图6 本文方法和MSCN 方法的损失收敛对比Fig.6 Comparison of the loss convergence between the proposed method and the MSCN method
4 结束语
本文针对传统基数估计方法存在问题,以及现有深度学习模型(RNN/CNN)的不足,提出了一种基于多头自注意力机制,并结合图嵌入等多种编码进行特征提取的基数估计方法。 实验结果表明该方法能够有效提取和利用数据列之间的关系,提高基数估计结果的准确性,且该方法不依赖与特定的数据库平台和存储引擎,能够和绝大多数的数据库结合,是数据库和机器学习领域相结合一次应用创新和探索。
因为实验是基于查询驱动,受到查询数据样本和真实数据的差异影响较大,且实验采用的是静态数据,所以对线上动态数据进行有效建模,解决模型实时训练慢等问题将是未来的研究重点。
