基于DCF-DeepLab 网络的图像语义分割研究
2023-10-31蔡江海黄成泉杨贵燕罗森艳王顺霞周丽华
蔡江海, 黄成泉, 杨贵燕, 罗森艳, 王顺霞, 周丽华
(1 贵州民族大学 数据科学与信息工程学院, 贵阳 550025; 2 贵州民族大学 工程技术人才实践训练中心, 贵阳 550025)
0 引 言
随着计算机视觉技术的飞速发展,图像语义分割已成为该领域研究的热点之一。 基于深度学习的语义分割方法相较于传统图像处理方法,性能得到了极大的提升,被广泛应用于自动驾驶、医学图像处理、人脸识别等领域。 Long 等[1]提出的全卷积网络(FCN)是一种端到端的语义分割网络,可以有效应用于图像语义分割研究。 然而,连续的池化和下采样操作容易引起浅层语义信息丢失,进而导致小目标信息丢失和边界分割模糊。 Ronneberger 等[2]提出了Unet 语义分割模型,该模型引入编码器-解码器结构,利用上采样和下采样过程进行跳跃连接,实现了更高精确的分割。 Fu 等[3]提出了引入空间注意力和通道注意力的分割网络DANet,有效提升了模型的性能。 后续,相关研究者又陆续提出了更好的兼顾精度和速度的图像语义分割模型,如HMANet[4]、STLNet[5]等。 Chen 等[6]在DeepLabv1基础上提出了DeepLabv2,并引入ASPP (Atrous Spatial Pyramid Pooling)模块实现多尺度的特征提取。 之后又相继提出了基于 ASPP 模块的DeepLabv3 和采用编码器-解码器结构的DeepLabv3+,实现了更好的图像语义分割。
到目前为止,DeepLab 系列都是在降采样8 倍尺度上进行预测的,边界分割效果不甚理想。DeepLabv3 网络并没有包含过多的浅层特征,不仅在语义信息和位置信息的平衡上存在连续池化和下采样导致的小目标信息丢失的问题,并且由于该网络是通过多层卷积叠加而成的,存在训练时效长、目标边界分割粗糙等问题。 为此,Zhu 等[7]通过注意力式可分离卷积的编码器-解码器结构,在多尺度特征上有效均衡了训练效率和分割精度。 Wang等[8]利用基于注意力机制的优势,较好地克服了因下采样导致的浅层细节信息丢失的问题,但模型参数量大,训练时效长,实用性较低。
针对以上问题,本文提出了融合多模块的DCF-DeepLab(Double Cross-attention Fusion DeepLab)语义分割网络。 首先,设计了基于双注意力交叉融合的特 征 融 合 DAFM (Double Attention Fusion Moudle)模块,以融合浅层特征弥补深层特征的不足,并将其应用于主干特征提取网络的2、4、8 倍下采样的特征图上,充分提取小目标特征信息,实现特征图跨模块的融合;其次,在主干特征提取部分引入轻量级网络MobileNetV3-Large,加速整体网络的训练速率;最后,通过嵌入DAFM 模块、注意力模块和串联结构得到MA-ASPP(Multiple Attention ASPP)模块,实现多尺度信息编码,增强图像目标边缘的细节特征提取能力。 DCF-DeepLab 语义分割网络从整体上精细了语义分割结果,提升了语义分割性能。
1 DCF-DeepLab 网络
1.1 DeepLabv3 网络
DeepLabv3 网络主要由两部分组成:
(1)在编码端使用Resnet101[9]残差网络模型作为基本特征提取的主干网络,得到有效特征图,再利用ASPP 模块(由1 个1×1 卷积、1 个全局池化层以及3 个不同空洞率的空洞卷积共同组成)进一步提取特征得到多尺度特征图;
(2)在解码端将多尺度特征图进行拼接和1×1的卷积操作得到特征图(该特征图与基本特征提取主干网络下采样得到的特征图的通道数相同),最后通过上采样,将所得特征图还原回与原始图像大小相同的尺寸,得到语义分割的结果。 DeepLabv3整体结构如图1 所示。
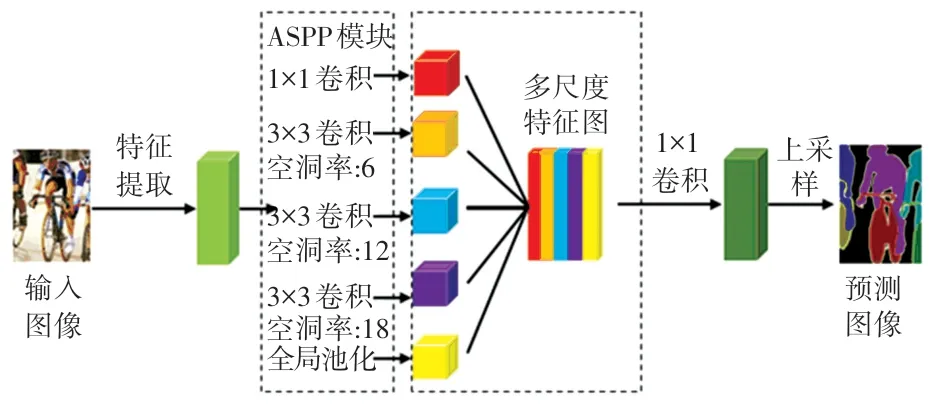
图1 DeepLabv3 整体结构Fig.1 Overall structure of DeepLabv3
1.2 MobileNetV3_large 网络
为了使DCF-DeepLab 网络高效地训练出预期的结果,提升网络训练参数的速度,解决因训练时间过长可能导致目标分割结果不佳的问题。 本文采用具有高效且网络参数量、运算量小的MobileNetV3_large 作为本文网络在编码端的主干特征提取网络。MobileNetV3_Large 网络结构见表1。

表1 MobileNetV3_Large 网络结构Tab.1 Structure of MobileNetV3_Large network
在MobileNetV3_large 网络结构中,“Input”表示输入当前层特征矩阵的尺寸;“Operator”表示输入特征矩阵在本层中进行的操作,主要由普通二维卷积操作、多个倒残差模块(bneck)操作以及池化操作组成,其中“NBN”表示不包含BN 层;“Exp size”表示利用1×1 的卷积核扩展后的通道数;“#out”表示输出特征矩阵的通道数,其中k表示类别数量;“SE”表示通道注意力机制;“NL” 表示激活函数,其中“HS”为H-Swish 激活函数、“RE”为RELU 激活函数;“s” 表示步距。
1.3 注意力模块
在计算机视觉领域,通道注意力机制[10]被广泛应用于各类研究。 SENet(Squeeze-and-Excitation Network)模块针对不同语义信息的属性特征,在通道上实现了更好的信息获取和分割效果。 SENet 模块结构如图2 所示。

图2 SENet 模块结构Fig.2 Structure of SENet module
在全局平均池化中将全局空间信息转换成通道统计信息,并执行压缩操作得到空间特征压缩量。假设输入特征统计量U ={u1,u2,…,uk,…,uα-1,uα},其中特征通道量uk∈RH×W,输出特征统计量经过全局平均池化得到,其中第k个元素值为
为了利用压缩操作中聚合的信息,完全捕获依赖通道的信息,执行激活操作。 实现上,通过引入全连接层对输出特征统计量Z进行通道依赖关系编码,学习通道之间的非线性交互作用,并结合Sigmoid 函数进行通道赋权,获取通道注意力信息[11]。 最后,将得到的权重系数应用于输入特征中,得到通道注意力的输出其计算关系为
其中,σ(·) 为Sigmoid 激活函数,Pfcl为全连接层参数。
CBAM(Convolutional Block Attention Module)模块分别在通道和空间维度上进行注意力操作,以获得全面的注意力信息,引导模型进行权重分配和信息指引。 CBAM 模块结构如图3 所示。
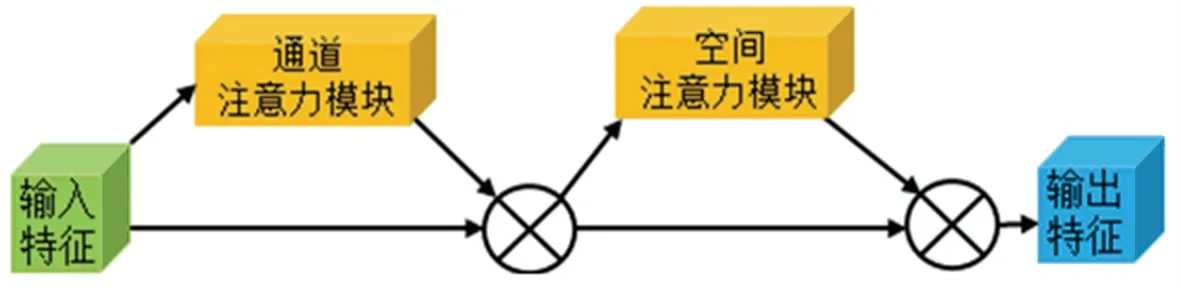
图3 CBAM 模块结构Fig.3 Structure of CBAM module
假设F∈ℝH×W×C表示输入的特征图,Mc∈ℝ1×1×C表示一维的通道注意力,Ms∈ℝH×W×1表示二维的空间注意力。 经过CBAM 模块依次推导出通道注意力和空间注意力的映射,计算过程如下:
式(3)中,将原始特征图F与其经过通道注意力模块操作后的结果进行元素相乘得到F′; 式(4)中,将输出F′与经过空间注意力模块做特征提取后的结果进行元素相乘,得到最终的输出结果F″。
为了提高通道注意力模块中网络的表征能力,首先,对输入的特征进行最大池化操作(MaxPool)和平均池化操作(AvgPool)聚合特征图的空间信息;其次,将池化后的特征信息输入到共享全连接层中以生成通道注意力图[12],其中共享全连接层由具有隐藏层的多层感知器(MLP)组成,并将输出的特征进行相加融合;最后,利用Sigmoid 函数进行激活操作,得到输入特征层中每一个通道的权重值。 通道注意力模块结构如图4 所示。
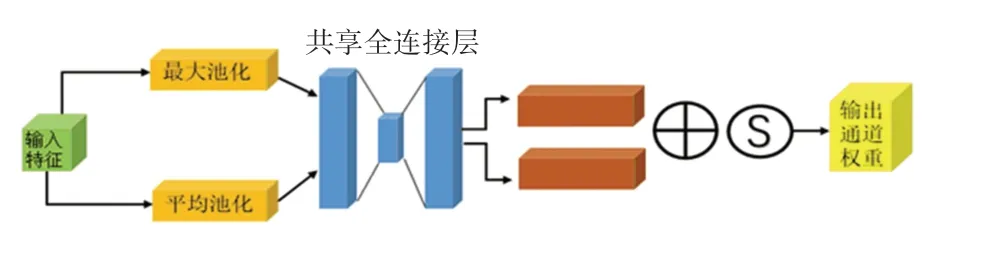
图4 通道注意力模块结构Fig.4 Structure of channel attention module
假设F∈ℝH×W×C表示输入的特征图,其经过通道注意力模块的计算过程为
式中:σ(·) 表示Sigmoid 激活函数,FMLP表示全连接层,W0∈ℝC/r×C,W1∈ℝc×c/r, 其中r为缩减比率,Fcmax、Fcavg分别表示最大池化特征和平均池化特征,MLP 权重W0、W1对于两个输入都是共享的。
在空间注意力模块中,为了计算空间关注度并聚合空间特征信息[13],在通道轴上应用平均池化操作和最大池化操作,并将其连接起来生成有效的特征描述,再利用通道数为1 的卷积核进行降维,最后利用Sigmoid 函数进行激活操作,获得输入特征层的每一个特征点的权重值。 空间注意力模块结构如图5 所示。
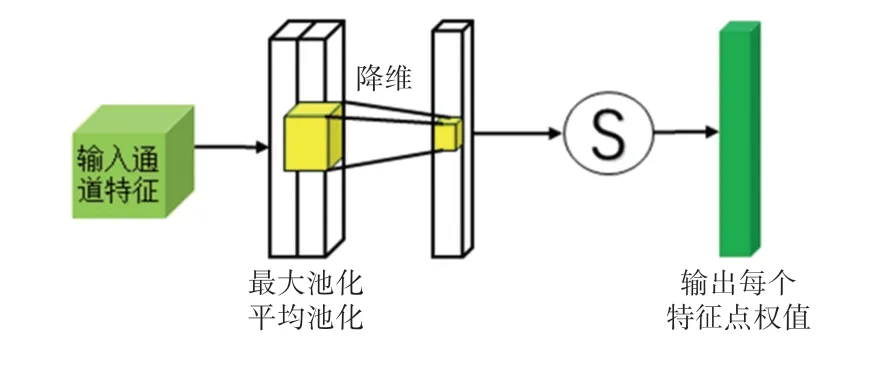
图5 空间注意力模块结构Fig.5 Structure of spatial attention module
空间注意力模块的计算过程为
式中:σ(·) 表示sigmoid 激活函数,f表示滤波器的卷积运算,Fsmax、Fsavg分别表示最大池化特征和平均池化特征。
1.4 DAFM 模块
SENet 模块给每个特征通道上的信号都赋予了一定的权重,对特征通道上的背景信息和前景目标信息有了更明确的选择,强化了感兴趣的特征,增强了特征通道下特定语义的响应能力。 CBAM 模块在通道和空间维度上对不同位置元素间的关系进行建模,其兼顾通道注意力和空间注意力的优势,获得更可靠的权重信息,增强了模型的表征能力。
计算机视觉领域常用的特征融合方式,是在同一张特征图上分别进行两种注意力机制操作,并进行结果的融合[14],其主要不同之处在于特征融合方式。 考虑到语义分割任务中对图像分辨率的影响,通常情况下,分辨率低的深层特征图采取通道注意力操作,其关注点放在相关的特征通道上;分辨率高的浅层特征图采取空间注意力操作,提取特征图中关于空间位置的关键信息。 因此,本文综合注意力机制对不同分辨率的深浅层特征图提取特征的优势,通过嵌入SENet 和CBAM 模块,得到有效融合浅层空间细节信息和深层高级语义线索的DAFM 模块,如图6 所示。

图6 DAFM 模块结构Fig.6 Structure of DAFM module
假设:在DAFM 模块中,输入的低分辨率深层特征图为ULR,尺寸大小为H1× W1;高分辨率浅层特征图的输入为UHR,尺寸大小为H ×W。 首先,根据公式(7),将ULR进行上采样操作得到U′LR使得尺寸大小与UHR相同,均为H × W。
式中:FUP(·) 表示采用双线性插值方法的上采样操作,其次,对UHR进行CBAM 注意力操作,得到。 并根据公式(2),对U′LR通过SENet 注意力操作得到权重Ws,其计算公式为
再将权重Ws与U′CHR相乘,即根据公式(9),得到:
最后,将与UHR相加,并进行1×1 的卷积核降维操作,得到最终的输出特征图,即
式中:c表示1×1 卷积操作。
在DAFM 模块中,浅层特征图和深层特征图为DAFM 模块的输入,深层特征图经过上采样完成,并经过SENet 注意力模块处理后,与经过CBAM 注意力模块处理后的浅层特征图进行像素级的相乘操作,最后经过相加以及1×1 卷积降维操作,得到最终融合后的输出特征图。
1.5 MA-ASPP 模块
DeepLabv3 网络中的ASPP 模块是由1 个1×1卷积、1 个全局平均池化层和不同空洞率的空洞卷积[15]简单拼接而成的,存在易失去图像中被忽略的小尺度目标信息的问题,进而降低特征提取能力,导致分割精度不高。 因此,在空洞率不变的前提下,提取目标多尺度信息并获得足够大的感受野变得尤为重要。
针对存在的问题,对ASPP 模块进行了一系列的改进。 首先,受DenseASPP[16]网络结构的启发,将3 个不同空洞率的空洞卷积由简单的堆叠变为密集连接的形式,即在原有3 个空洞卷积并行的基础上增加了串联结构,将空洞率较小的空洞卷积输出和主干网络的输出级联,再依次送入空洞率较大的空洞卷积中。 由逐级递增的并行操作,实现更密集化的像素级采样,增强提取细节特征的能力;其次,对于另外两个分支的卷积和全局平均池化操作,通过嵌入CBAM 模块以获取更多浅层特征的细节信息;最后,将融合5 个分支后的特征信息输送到DAFM 模块中,加强对重要目标信息和细节信息的选择性注意,并结合1×1 卷积操作,构成了具有强大特征提取能力的像素级MA-ASPP 模块。 MAASPP 模块结构如图7 所示。
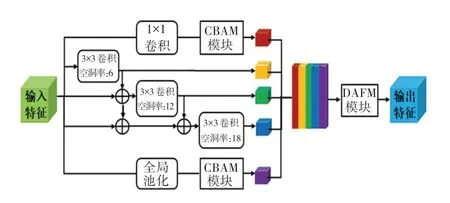
图7 MA-ASPP 模块结构Fig.7 Structure of MA-ASPP module
MA-ASPP 模块中的3 个空洞卷积分支以密集连接的方式组织,其中任意一层的空洞卷积层输出可表示为
式中:k表示卷积核的大小,rn表示第n层的空洞率,[…]表示拼接操作,[yn-1,yn-2, …,y0]表示将所有前一层的输出拼接起来形成的输出。
密集连接的方式不仅可以获得更密集的像素级采样,还可以提供更大的感受野[17],其计算过程如下:
式中:RFn表示第n层感受野大小,kn表示第n层卷积核大小,Sn表示前n层的总步长,Sn表示当前层步长。
由于所采取的空洞卷积步长为1,因此Sn的值恒等于1,有:
在DeepLabv3 网络的ASPP 模块中,采取空洞卷积rates ={6,12,18} 并联连接方式的最大感受野大小为
通过叠加空洞卷积,采取串联并行的连接方式,其所能获得的最大感受野大小为
因此,可以计算出DA-ASPP 模块采取rates ={6,12,18} 的空洞卷积所对应的RFmax大小为
通过计算,由式(14)和式(16)已知,DA-ASPP模块中的RFmax值明显大于ASPP 模块中的RFmax值。 DA-ASPP 模块通过逐层连接实现信息共享,不同空洞率的空洞卷积相互补充,使其细节信息更加丰富,并增大了感受野的范围,有利于增强特征提取能力。
1.6 DCF-DeepLab 网络结构
本文将主干特征提取网络MobilenetV3_Large中2、4、8 倍下采样获得的浅层特征图与DAFM 模块连接,并与后续通过多个模块获得的深层特征图进行融合。 DCF-DeepLab 整体网络结构如图8所示。

图8 DCF-DeepLab 整体网络结构Fig.8 Overall network structure of DCF-DeepLab
2 实验
2.1 实验环境与数据集
本文各项实验均在GPU 上完成,软硬件环境配置说明见表2。

表2 实验环境配置Tab.2 Experimental environment configuration
本文在公开的PASCAL VOC 2012 数据集上进行了一系列的实验,以验证DCF-DeepLab 网络的有效性。 PASCAL VOC 2012 数据集包括人物、动物、室内外场景、交通工具等20 个具体前景类别,外加背景共21 类。 分别采用训练集上1 464 张训练图像、验证集上1 449 张验证图像以及测试集上449张图像进行网络的性能评估。 为了加速实验结果的收敛性,在训练阶段采用了基于COCO 数据集(COCO 数据集是提供80 个目标类别、91 个材料类别的大型常用数据集)训练得到的预训练权重,且训练时只针对和PASCAL VOC 2012 相同的类别进行训练。
2.2 训练细节及参数设置
本文采用了在COCO 数据集上预先训练得到的预训练模型MobileNetV3_Large 和ResNet_50 的模型权重,分别对网络DCF-DeepLab 和DeepLabv3 进行初始化,以加速收敛。
训练参数设置如下:图像预处理过程中随机水平翻转概率为0.5,图像训练块大小为480×480 像素,在验证阶段采取的大小为520×520 像素;批量大小设置为6,初始学习率为0.001,动量设置为0.9,权重衰减为10-4,模型训练的迭代次数为500 次。
采用Poly 学习率策略[7], 其作为一种指数变换的策略,具体计算公式如下:
式中:lr表示初始学习率,iter表示当前迭代步数,max_iter表示最大迭代步数,power取0.9。
启用混合精度训练,以减少显存占用,加快网络训练速度。 使用交叉熵损失函数[18]计算主输出上的损失,并结合使用全卷积网络分割头辅助训练[19],得到的网络总输出损失为主输出和辅助分类器上的损失加权代数和,比率为2 ∶1。
2.3 消融实验
为了验证DAFM 模块、MA-ASPP 模块和特征融合模块对网络性能的影响,设置了一系列相关的消融实验。 所有实验均在PASCAL VOC 2012 数据集上进行,以语义分割中常用的标准度量平均交并比(MIoU) 作为衡量评估指标,定义为真实值和预测值的交集和并集之比,其计算公式如下:
式中:N表示前景目标类别个数,Pij表示真实值i被预测为j的数量。
2.3.1 DAFM 模块
为了验证本文所提出的DAFM 模块对网络性能的影响,通过与SENet 模块和CBAM 模块基于DeepLabv3 进行对比实验,实验结果见表3。

表3 注意力机制对模型性能的影响Tab.3 Effect of attentional mechanism on model performance
从表2 可看出,SENet 模块和CBAM 模块均可提升网络整体的分割性能,MIoU值较原始网络分别提高了0.4%和0.6%。 DAFM 模块结合了两者的优势,分割性能效果最好,MIoU值达到75.1%。 因此,本文考虑选取多个DAFM 模块作为网络解码部分的主体框架,以使网络达到更好的特征表达效果。
2.3.2 MA-ASPP 模块
实验采用DeepLabv3 作为基准模型,对ASPP模块、MA-ASPP 模块以及DAFM 模块进行组合实验,以验证MA-ASPP 模块的有效性。 实验结果见表4。

表4 不同模块组合对模型性能的影响Tab.4 Effect of different modules on model performance
从表4 可看出,对比ASPP 模块,MA-ASPP 模块和DAFM 模块均可提升网络整体的分割性能,MIoU值分别提高了0.9%和0.7%。 而将MA-ASPP模块和DAFM 模块同时组合进网络,融合浅层特征和深层特征,提取出了更多关键的目标特征信息,网络效果提升显著,MIoU值达到74.1%。 因此,本文最终选择将MA-ASPP 模块和DAFM 模块同时组合进网络。
2.3.3 特征融合模块
在编码端使用不同尺度采样所得的特征图对网络解码端DAFM 模块特征提取效果有不同程度的影响,本实验在DAFM 模块和MA-ASPP 模块的基础上,对DAFM 模块结合主干特征提取网络不同下采样率所得特征图的网络整体组合效果进行实验。实验结果见表5。
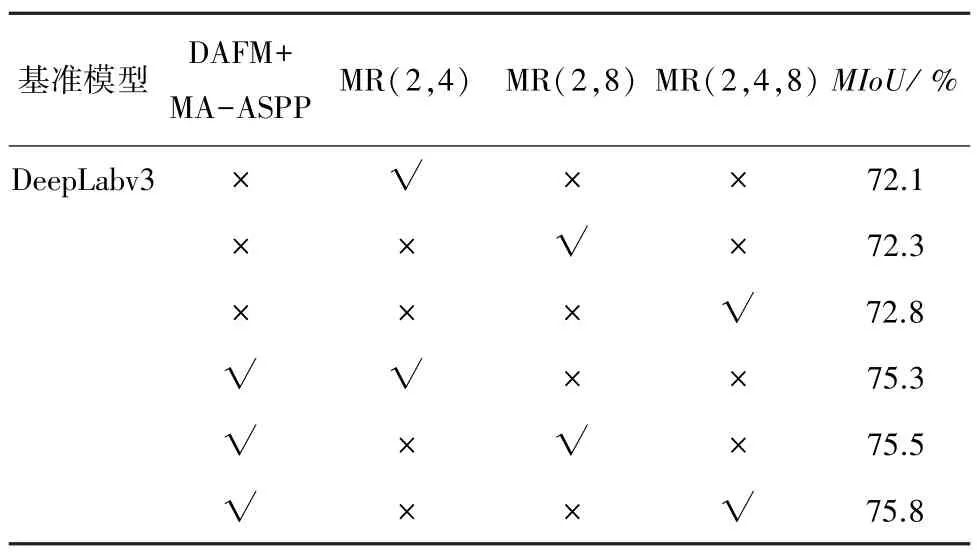
表5 不同尺度特征图对模型性能的影响Tab.5 Effect of different feature scales on model performance
从表5 可看出,在DeepLabv3 的基础上,对主干特征提取网络采取不同尺度的下采样,均可提升网络性能,其中使用MR(2,4,8)对DeepLabv3 的分割效果最优,达到72.8%。 在结合DAFM 模块和MAASPP 模块的基础上,当对主干网络使用MR(2,4)下采样特征图进行组合时,MIoU值为75.3%;当使用MR(2,8)下采样特征图进行组合时,MIoU值为75.5%;当使用MR(2,4,8)下采样特征图输入DAFM 模块时,网络的整体性能最佳,MIoU值达到75.8%。 因此,本文还基于多尺度下采样倍率MR(2,4,8)结合DAFM 模块来改进原始网络,实现了更密集化的像素级采样,使得DCF-DeepLab 网络具有更好的分割性能。
2.4 实验结果分析
DeepLabv3 与 DCF - DeepLab 在 PASCAL VOC2012 验证集上包括背景的21 个类别的测试结果见表6。 从表中可看出,相比于基础语义分割网络DeepLabv3 在PASCAL VOC2012 验证集上的测试结果,基于DAFM 模块的DCF-DeepLab 在其中18 个类别上的检测精度都有所提升,尤其在自行车、瓶子、沙发这3 个类别上检测精度提高了2% ~4%。 总体上,MIoU值由69.7%提高到70.6%,提升了0.9%。
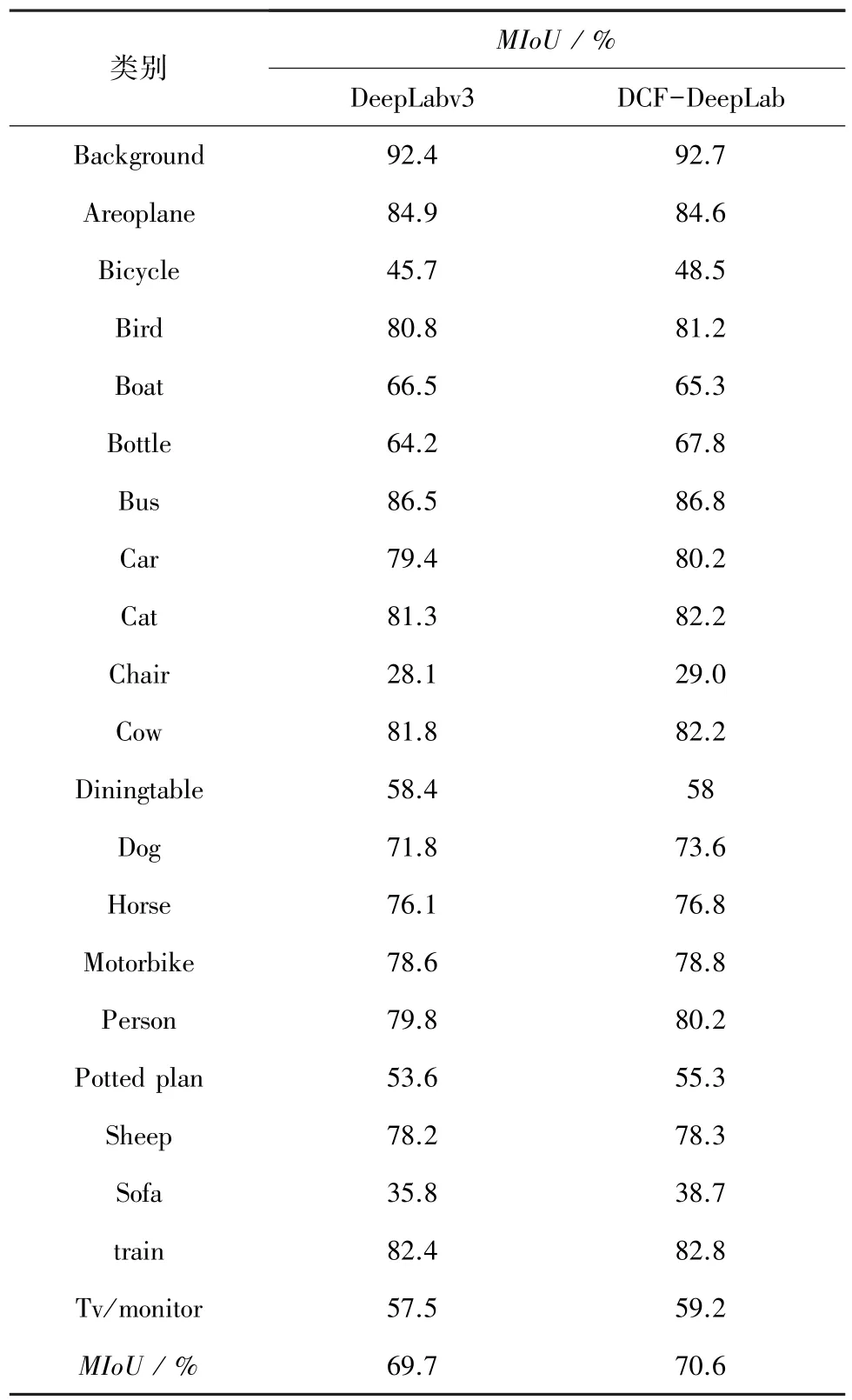
表6 不同类别检测性能对比Tab.6 Comparison of detection performance on different categories
为了进一步验证本文提出的DCF-DeepLab 网络的有效性,在PASCAL VOC 2012 数据集上将DCF-DeepLab 网络与其它经典语义分割网络的实验对比结果见表7。

表7 不同网络模型测试结果对比Tab.7 Test results of different network models
从表7 可看出,DCF-DeepLab 在融合多尺度语义信息的基础上,MIoU达到75.8%,优于其他以VGGNet 和ResNet50 为主干特征提取网络的语义分割模型。 同时,DCF-DeepLab 在模型参数量和分割时间上取得了较好的平衡,其模型参数量大小为48.9 MB,每张分割时间为0.123 s,明显优于对比网络。 DCF-DeepLab 和DeepLabv3 在PASCAL VOC 2012 数据集上的部分可视化结果如图9 所示。

图9 部分可视化结果图Fig.9 Visualizations of several prediction results
从图9 可见,DCF-DeepLab 的分割性能整体上优于DeepLabv3,尤其对精细的小目标进行分割时,其能够更好地捕捉小尺度细节语义特征,使目标边缘分割更加精细、光滑且完整。 如:可视化结果中飞机的轮子和绵羊脚部位的轮廓分割等,较好地改善了DeepLabv3 分割目标时存在的图像边界响应丢失及远距离小目标信息和目标边缘分割粗糙的问题。
3 结束语
本文针对DeepLabv3 中存在的图像小目标信息易丢失等问题,提出了基于注意力机制的DAFM 模块,融合浅层特征弥补深层特征的不足,实现特征图跨模块的融合。 同时,为了减少训练时长,在主干特征提取网络部分引入轻量级网络MobileNetV3_Large。 针对目标边界分割粗糙等问题,通过引入注意力模块和串联结构改进ASPP 模块,以增强局部特征提取的连贯性,进而从整体上提升语义分割性能。
消融实验表明,DAFM 模块和MA-ASPP 模块对原始网络的语义分割性能有一定程度的提升;对比实验表明,DCF-DeepLab 网络在参数量大小和分割效率等方面都取得了一定成效,验证了本文设计网络的有效性。
在后续的研究中考虑将网络的小目标分割特性拓展到其他领域(如:苗族服饰图像分割、医学图像分割、建筑物裂缝等工程问题),以提高网络的泛化性。
