考虑多维时域特征的行业中长期负荷预测方法
2023-10-31张昆明蔡珊珊章天晗潘一洲王思睿林振智
张昆明,蔡珊珊,章天晗,潘一洲,王思睿,林振智
(1.浙江大学电气工程学院,浙江省杭州市 310027;2.国网浙江杭州市余杭区供电有限公司,浙江省杭州市 311100;3.浙江华云信息科技有限公司,浙江省杭州市 310012)
0 引言
电力需求侧管理在削峰填谷与节能减排方面具有重要作用。近年来,随着“双碳”目标的提出,需求侧管理也成为电力系统研究热点领域之一。电力系统负荷预测是电力需求侧管理的基础,准确的负荷预测能够为需求侧管理方案提供重要参考。中长期负荷预测主要针对月度及以上时间尺度的负荷进行预测,准确的中长期负荷预测有利于供电公司掌握不同行业用户的用电规律,可为供电公司进行行业布局规划、资源优化配置、供电业务管理等提供重要的决策支持。
目前,负荷预测方法主要有基于时间序列分析的传统预测方法[1-4]和基于深度学习的智能预测方法[5-9]。其中,时间序列分析方法主要从负荷历史数据出发,挖掘自身时序规律,但较难考虑天气、节假日等外部非线性因素对负荷的影响。因此,当外部相关影响因素的变化导致负荷发生突变时,此类方法的预测准确率难以得到保证。另一类方法则是基于深度学习的人工智能算法,例如,时间卷积网络[6]、稀疏编码[7]等。文献[8]考虑不同时间尺度数据间的依赖性,提出一种堆叠长短期记忆(long short-term memory,LSTM)神经网络模型以整合多源异构数据,有效提高了中长期负荷预测的精度。文献[9]采用灰色关联度分析法评估外部因素与负荷的关联程度,并基于深度信念网络对不同行业的中长期负荷进行预测,有效降低了预测误差。虽然上述方法考虑了外部因素对负荷的影响,但均是直接将负荷历史相关值以及外部因素不作区分地输入单一模型,影响了模型的预测准确率和泛化性能。
为了解决上述问题,基于集成学习算法的负荷预测模型应运而生[10]。基于集成学习算法的组合预测模型主要分为串行式与并行式2 种形式。串行式组合预测模型中各子模型间存在强依赖关系[11-13]。并行式组合预测模型中各子模型之间为并列关系,最终预测结果通过对各子模型预测结果加权平均得到[14-17]。并行式组合预测模型主要是基于数学意义上的优化准则[18],从统计优化的角度确定不同模型的线性组合权重,缺乏机理性的解释。此外,对于负荷而言,非线性影响因素较多,负荷变化存在不确定性与波动性,采用线性权重将存在一定的局限性。除了加权式并行组合预测模型,也有不少研究将负荷曲线分解后再预测,X-12-自回归积分滑动平均分解[19]、经验模态分解[20]、小波包变换[21]是近年来常用的方法,但是上述方法更加侧重于信号高频、低频分量的分解,可解释性较差,并且由于分解后采用同质单一点预测模型,忽略了各分量特征与模型特点的相互匹配性,且无法量化负荷变化的不确定性,故预测可靠性不高。
在此背景下,本文提出一种考虑多维时域特征的行业中长期负荷概率预测方法。由于行业中长期负荷隐含有多维时域特征且受多方面因素影响,因此首先对行业中长期历史负荷数据进行分解,得到中长期负荷趋势分量、周期分量以及残差分量。然后,考虑负荷趋势分量以及周期分量时序依赖特征的差异性,分别构建基于门控循环单元(gate recurrent unit,GRU)与卷积神经网络(convolutional neural network,CNN)的分量预测模型。针对残差随机分布的特点,对自适应高斯核密度估计方法进行改进以构建残差分量的概率分布预测模型。最后,综合考虑GRU、CNN 以及高斯核密度估计的预测结果,得到基于局部加权散点图平滑季节和趋势分解(seasonal and trend decomposition using locally weighted scatterplot smoothing,STL)与门控循环单元-卷积神经网络-核密度估计(STL-gate recurrent unit-convolutional neural network-kernel density estimation,STL-GCK)复合模型的行业中长期负荷概率预测结果。
1 行业中长期负荷滚动预测建模
基于数据驱动的负荷预测方法本质在于挖掘负荷历史变化规律的周期性、趋势性与随机性等负荷自相关特性,以及负荷影响因素与行业负荷的互相关特性。在构建行业中长期负荷预测的具体模型前,首先需明确负荷预测数据集的数据结构。由于行业负荷受自相关特征与外部多种因素综合影响,故将行业中长期负荷预测的初始输入数据X表示为:
式中:i=1,2,…,N;xi为第i月度行业负荷特征向量;fi为第i月度的辅助特征向量;li为第i月度统计口径的月度负荷用电量;N为样本数量;D为特征维数;si为第i月度所属季节类型编码向量;wi为第i月度的实际气温平均值;ei为第i月度工业增加值增速;ci为第i月度消费价格指数;mi为月度特征;vi为特殊月份标记。
受春节影响,春节假期所在月份的行业负荷数据与其他常规月份的行业负荷数据相比呈现明显的差异性。因此,将春节假期所在月份标记设为1,其余月份标记设为0。月度时标的常规特征化方法为直接采用整数1,2,…,12 循环表示该特征,但是这种特征化表示是非连续的,模型无法准确学习并反映负荷样本特征的真实距离。因此,本文采用一种正余弦的特征化表示方式,将月度时标映射为正余弦变量以输入模型,具体表达式为:
式中:msin,i和mcos,i分别为第i月度负荷时序的正弦、余弦映射值。
行业中长期负荷是多维因素共同作用的结果,一方面,行业中长期负荷与其历史负荷变化具有一定的自相关性;另一方面,行业中长期负荷与外部不确定性因素具有一定的互相关性。因此,行业中长期负荷预测需要综合考虑以上两方面的相关性。综合考虑以上两方面因素影响,行业中长期负荷预测模型可由式(4)表示。
式 中:xi,L为 第i月 度 输 入 长 度 为L的 历 史 负 荷 特 征向量,其中,L为输入的历史负荷特征向量长度;si,L,τ,K、mi,L,τ,K、vi,L,τ,K分 别 为 待 预 测 时 步 的 季 节 类 型编码、月度时标特征,以及特殊月份标记,其中,K为预测长度,K=1 代表单步预测,τ为预测提前量;θ*为训练得到的负荷预测模型参数向量;F(·)为映射函 数;为第i月度预测得到的统计口径月度用电量。
为构建行业中长期负荷多因素滚动预测模型,本文对原始数据集进行滑动窗口化处理,其中,多维负荷数据滑动窗口处理示意图如附录A 图A1 所示。本文以滑动窗口内的负荷历史相关特征及负荷同步相关特征作为负荷预测模型的输入特征,综合考虑负荷变化的自相关性及负荷与其影响因素间的互相关性,随滑动窗口移动滚动预测行业负荷。其中,滚动预测模型的输入特征集如附录A 表A1所示。
2 行业中长期负荷多维时域特征分解方法
行业负荷是由社会与环境多方因素共同作用的结果,行业负荷作为时间序列具有丰富的信息。行业的生产经营受到外部经济发展环境的影响,而行业中长期负荷与行业的生产活动强度密切相关。因此,行业中长期负荷变化存在一定的趋势性特征。此外,受行业年生产计划、季节性因素以及气候变化等不确定性因素影响,行业中长期负荷呈现出以年为周期波动变化的特点。若直接将行业中长期负荷数据输入模型,则难以直接捕捉到行业中长期负荷中所隐含的趋势性特征、周期性特征以及随机性特征。因此,本文基于分解和预测的思想,采用STL算法将原行业中长期负荷进行时间序列分解,得到对应的周期分量、趋势分量以及残差分量,即:
式中:St为时步t的负荷周期分量;Tt为时步t的负荷趋势分量;Rt为时步t的负荷残差分量。
负荷周期分量代表行业规律性用电负荷,负荷趋势分量代表行业中长期趋势性用电负荷,负荷残差分量代表因外部不确定性因素导致的随机波动负荷。STL 算法是以鲁棒局部加权回归作为平滑方法的时间序列分解方法,其核心是局部加权散点图平 滑(locally weighted scatterplot smoothing,LOWESS)回归方法。该算法基本思想是对拟合点lt局部邻域内邻近的点进行加权多项式回归得到回归函数,权重根据“近大远小”原则由邻近点与待拟合点lt的距离决定。STL 以LOWESS 为基础,采用内循环与外循环双层结构,其中,内循环计算趋势分量和周期分量,外循环用于增强算法鲁棒性,降低负荷异常值对残值的影响。STL 分解算法流程如附录B 图B1 所 示。
STL 算法内循环基于LOWESS 得到负荷序列的周期分量、趋势分量;外循环基于残差分量计算结果,由Bisquare 函数计算各节点的鲁棒权重以更新内循环LOWESS 过程的邻域权重,提高STL 分解算法的鲁棒性。鲁棒权重的计算方法为:
式中:ρt为时步t的鲁棒权重;median(·)为中位数函数;B(a)为Bisquare 函 数;a为Bisquare 函 数 的 自变量。
内循环LOWESS 的权重更新方法如式(10)所示。
式中:wt,k为第k次内循环在时步t的邻域权重。
通过STL 内外双循环分解得到的行业中长期负荷周期分量、趋势分量以及残差分量具有较强的鲁棒性,可针对各分量特征分别构建与之特性相匹配的模型进行预测。
3 行业中长期负荷概率预测模型
3.1 行业中长期负荷概率预测框架
行业中长期负荷通过STL 分解可以得到周期分量、趋势分量以及残差分量,其中,周期分量反映行业中长期负荷周期性变化规律,趋势分量反映行业中长期负荷长期变化趋势,残差分量反映行业中长期负荷变化的随机性与不确定性。各分量呈现不同的变化特征,若采用单一模型对各分量进行预测将无法提取捕捉到不同负荷分量的特征,进而限制行业中长期负荷预测的精度。因此,本文提出了基于STL-GCK 的行业中长期负荷概率预测框架,分别构建与负荷分量变化特性相匹配的子模型对各分量进行预测。基于STL-GCK 的行业中长期负荷概率预测总体框架如图1 所示。
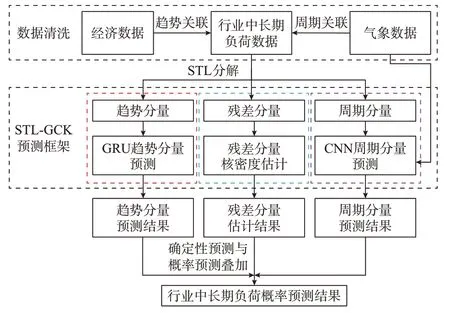
图1 基于STL-GCK 的行业中长期负荷概率预测框架Fig.1 Framework of medium- and long-term industry load forecasting based on STL-GCK
根据图1,首先将行业中长期负荷曲线进行STL 分解,分别得到负荷周期分量、趋势分量以及残差分量。接着,对于负荷周期分量,结合负荷周期性影响因素(包括气温、月度时标特征),构建考虑负荷周期性的CNN 预测模型,预测负荷周期分量;对于负荷趋势分量,结合负荷趋势性变化因素(包括工业增长、消费价格以及负荷历史数据),构建考虑行业负荷中长期趋势特征的GRU 预测模型,预测负荷趋势分量;对于负荷残差分量,基于高斯核密度估计对行业中长期负荷残差分量的概率分布进行分析量化,得到负荷残差分量概率分布情况。最终,综合CNN 周期分量预测结果、GRU 趋势分量预测结果以及由高斯核密度估计得到的负荷残差估计结果,获得行业中长期负荷概率预测结果。
为了避免总体分解抽样导致的信息泄露问题[22-23],本文提出以下基于“分解和预测”的实现思路:首先,对历史负荷数据进行STL 分解,得到负荷各分量结果,基于历史各负荷分量及影响因素数据构建各分量预测模型;然后,基于各分量预测模型对行业负荷进行动态分解和预测,得到未来各时步的分量预测结果及整体预测结果,动态分解预测示意图如附录B 图B2 所示。
3.2 行业中长期负荷全局趋势特征提取与预测模型
行业负荷中长期趋势分量变化相对平缓,隐藏于长时间序列中,不易被捕捉,需要网络模型具有长期记忆并分析提取不同时刻信息耦合关系的能力。循环神经网络(recurrent neural network,RNN)具有记忆特性,在时序预测领域中有着广泛的应用。然而,传统RNN 在应用于长时间序列预测时,早期节点的输出在正向传递的过程中逐渐衰减,采用梯度下降算法训练网络时的误差在反向传播的过程中面临梯度消失的问题,导致网络参数在训练时无法得到有效的更新。GRU 具备记忆长时间节点隐含信息的能力[24],相比于传统RNN 以及基于RNN 改进的LSTM 网络,GRU 具有相似的结构但是更少的记忆单元,其结构如附录B 图B3 所示。通过实验验证,GRU 只需更短的训练时间就可实现与LSTM网络近似的效果[25]。
GRU 网络由多个多维GRU 串联构成,在时间维度,不同时刻的负荷状态特征信息通过隐藏状态ht进行传递,将不同时间节点的负荷信息耦合。在特征维度,某一时步t的负荷特征向量xt为多维向量,不仅包含当前时刻的负荷趋势分量,还包括当前时刻负荷的同步特征。基于GRU 的行业中长期负荷趋势分量预测示意图如附录B 图B4 所示。负荷的历史趋势信息由GRU 进行传递,信息的传输与控制由GRU 内的门结构实现,包括重置门以及更新门,GRU 网络内部特征信息传导的计算公式为:

负荷历史趋势分量信息及负荷影响因素趋势分量信息的传输由重置门及更新门系数控制。考虑到行业负荷的中长期变化趋势与外部经济环境转变密切相关,故在预测行业中长期负荷趋势分量的同时将外部经济因素数据与负荷数据拼接作为GRU 网络输入特征向量,通过误差反向传播及自适应梯度下降算法Adam[26]训练得到GRU 网络权重以及偏置,得到行业中长期负荷趋势分量预测模型。
3.3 行业中长期负荷局部周期特征提取与预测模型
在行业负荷序列中,隐含有固定相似的模式与规律,即行业负荷变化的周期性规律。GRU 能够传递不同时间节点的信息,捕捉全局特征,但是对于负荷局部的特征感知不足,而CNN 最大的特点是局部连接和共享权值。鉴于此特征,本文将CNN 应用于负荷局部特征提取及行业负荷周期分量的预测。CNN 的核心为卷积层,由于行业负荷及其相关影响因素均是时间序列,故本文采用一维卷积核进行行业负荷序列的局部特征提取,卷积运算过程如附录B 图B5 所 示。
卷积层采用多个卷积核以提取负荷变化的多种特征,每个卷积核都对应一组权重系数和偏置。卷积核内的每一个元素都与输入序列对应元素相连,区域大小与卷积核大小相同。卷积层的超参数主要包括卷积核长度以及卷积核个数(也即输出特征维数),二者共同决定特征提取映射图的大小。卷积核参数通过学习训练得到,最终确定的多种卷积核表征了负荷的多种局部特征,视为负荷典型局部特征图谱。
整合由多个卷积核进行负荷局部特征提取以及深度特征提取得到的特征向量,考虑到行业负荷周期分量与同样具有周期性的时标具有一定的关联性,故将特征向量与待预测时步的时标特征拼接输入全连接层,通过非线性映射得到行业负荷周期分量预测值。基于CNN 的行业负荷时序局部特征提取与周期分量预测示意图如附录B 图B6 所示。
为验证CNN 对行业中长期负荷周期分量局部特征的提取特性,可根据式(17)计算训练得到的卷积核参数与行业负荷周期分量之间的相关系数[27]。

3.4 行业中长期负荷不确定性量化模型
行业负荷受到外部不确定性因素影响导致负荷出现随机波动,经典确定性预测方法无法实现行业负荷不确定性的有效量化。因此,本文引入概率预测方法,在由CNN 与GRU 得到行业中长期负荷周期分量和趋势分量预测结果的基础上,对行业中长期负荷历史残差分量的概率分布进行建模量化,将残差分量的概率分布结果与确定性预测结果叠加得到行业中长期负荷的概率预测结果。
高斯核密度估计方法是一种基于高斯核函数的非参数估计方法,可以不依赖任何先验知识,完全根据数据自身特点与性质来拟合样本分布情况。基于高斯核函数的密度估计函数如式(18)所示。
式 中:σKernel(ξ0) 为 待 估 计 样 本ξ0处 的 核 密 度;Kernel(·)为核函数;ξi为第i个样本;μ为高斯核密度估计的超参数,表示核密度估计带宽,若μ设置较大,则得到的密度分布相对平滑,若μ设置较小,则得到的密度分布相对陡峭。
传统核密度估计采用定常带宽核密度估计,对样本分布疏密程度的敏感度较低,导致核密度估计结果与实际样本分布结果的匹配效果一般。因此,文献[28]提出了基于两步法的自适应带宽核密度估计方法,第1 步设定某一全局带宽,得到不同点位的核密度估计结果;第2 步根据估计结果计算反映样本疏密程度的局部带宽因子,依据第1 步设定的全局带宽以及第2 步计算的局部带宽得到核密度估计综合带宽,最终获得核密度估计结果。然而,基于两步法的自适应带宽核密度估计方法对带宽初值选取较为敏感,若第1 步带宽初值选取不当,则第2 步局部带宽因子将无法较好地反映样本的真实分布。因此,本文提出一种基于迭代法的自适应带宽高斯核密度估计方法,通过迭代方式使局部带宽因子收敛到最优,迭代公式如式(20)—式(22)所示。
式中:λi,k+1为第k+1 次迭代的局部带宽因子;k为迭代 次 数;σKernel,k(ξ0)为 第k次 迭 代 得 到 的ξ0处 核 密度;gk为第k次迭代的核密度归一化因子;α为灵敏因子,反映了局部带宽对样本分布疏密的敏感程度,当α=0 时自适应带宽核密度估计则退化成固定带宽的核密度估计。
本文对STL 分解得到的行业中长期负荷历史残差分量进行高斯核密度估计,以残差分量的概率密度函数来描述行业中长期负荷变化的不确定性,基于自适应带宽高斯核的行业中长期负荷残差分量密度估计的迭代流程如附录B 图B8 所示。
3.5 行业中长期负荷预测评价指标
为了评估各分量以及整体行业中长期负荷预测的效果,分别采用不同评价指标进行评估。针对确定性预测结果,采用均方根误差γRMSE和平均绝对百分比误差γMAPE进行评价:

4 算例分析
本文以中国某地市2011 年至2020 年化工企业的月度负荷数据作为原始负荷数据集,并以国家统计局月度统计数据[29]以及气象数据作为特征数据集。将以上各项数据以4∶1 的比例划分为训练集与测试集。其中,训练集用于训练模型并调整模型超参数,测试集用于评估模型预测效果。
4.1 行业中长期负荷STL 分解结果
首先,按照本文所提出的行业中长期负荷概率预测总体框架,通过STL 分解得到行业中长期负荷趋势分量、周期分量以及残差分量。
由于行业负荷变化的趋势相对缓慢,故在长时间尺度范围内,行业负荷变化的趋势性更为显著,在短时间尺度范围内趋势性难以体现。在局部窗口内,行业负荷的波动变化较大,行业负荷受气象因素、时标因素影响,负荷变化表现出一定的周期性以及随机性。例如,在春节所在月份,行业负荷骤降,而当春节假期结束开工后行业负荷迅速回升,在其余常规月份负荷随机波动。行业负荷通过STL 分解得到的行业负荷趋势分量与行业中长期负荷的变化趋势相匹配,占行业负荷的主要部分,周期分量占行业负荷的次要部分,残差分量占比最小,部分月份残差分量占比较高。具体STL 分解结果如附录C图C1 所示。其中,周期分量反映了行业中长期负荷的周期性变化规律,残差分量反映了行业负荷变化的随机性与不确定性。
4.2 预测结果有效性验证
在STL 分解得到行业中长期负荷各分量的基础上,对各分量分别进行预测建模。首先,以行业中长期负荷趋势分量为预测对象,构建GRU 网络预测模型。由于月度负荷数据样本较少,根据文献[30],对于小样本,两层网络搭配适当的激活函数即可拟合任何精度的平滑映射,GRU 网络隐藏层数设为2层。对于负荷周期分量,基于CNN 构建行业中长期负荷周期分量预测模型。CNN 网络的超参数主要包括滑动窗口宽度、网络层数、卷积层维数以及卷积核长度等。参考GRU 网络超参数的确定方法,CNN 网络层数设为2 层,其他超参数通过网格搜索得到。
基于GRU 和CNN 对行业中长期负荷的趋势分量以及周期分量进行预测,叠加二者结果可以得到行业中长期负荷确定性分量的预测结果。对于STL 分解得到的行业中长期负荷不确定性分量,采用基于高斯核的自适应带宽核密度估计方法,量化估计其不确定性。基于高斯核的自适应带宽核密度估计方法对样本分布的疏密程度更加敏感,在样本分布密集处曲线相对陡峭,在样本分布稀疏处曲线相对平滑。
灵敏因子α反映了自适应带宽核密度估计方法中带宽对样本分布密度的灵敏程度,最终影响自适应带宽核密度估计结果。α=0 表示核密度估计带宽对样本分布密度不敏感,自适应带宽核密度估计退化为固定带宽核密度估计。随着α增加,核密度估计带宽对样本分布密度的敏感度增加。为验证灵敏因子α对残差分量概率分布估计的影响,对参数α做灵敏度分析,针对自适应带宽核密度估计得到不同灵敏因子α下的负荷残差分量概率密度分布,计算相应的累积概率分布以及不同置信水平的最优负荷预测区间[31],某一时步的预测结果如表1 所示。表1 中,分 别 为 平 均 预 测 区 间 覆 盖 率 和 平均预测区间宽度。
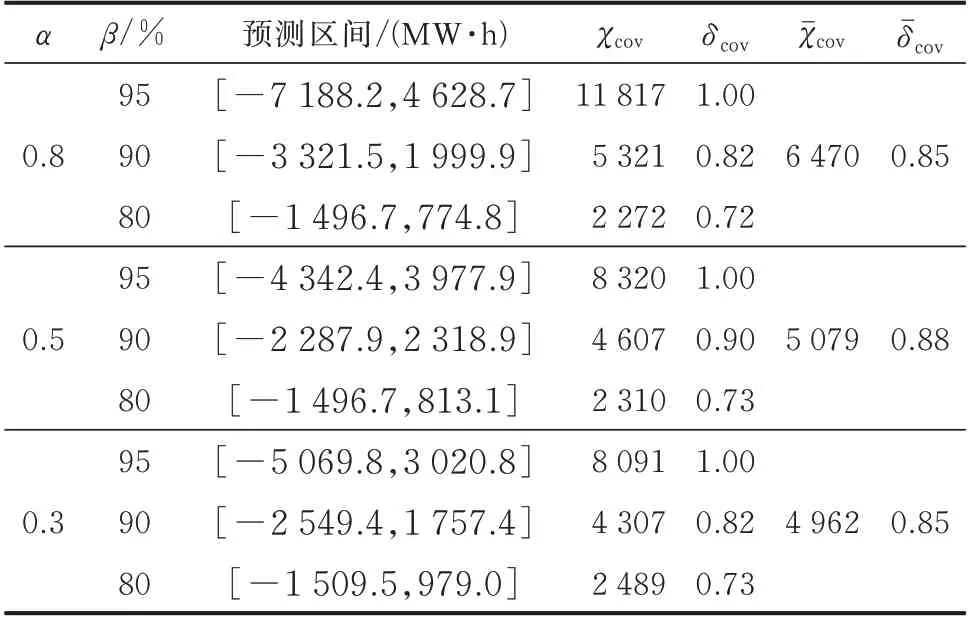
表1 不同置信水平的区间预测结果Table 1 Interval prediction results at different confidence levels
由表1 可见,当灵敏因子α相同时,随着置信水平下降,预测区间逐步收缩,预测区间宽度减小,预测的精准性提高。在相同置信水平下,灵敏因子α下降时,预测区间整体也呈逐步收缩的趋势,预测区间宽度逐渐减小,因为随着灵敏因子的下降,残差分量的密度估计曲线逐渐平缓,所以相同置信水平的预测区间更宽。由于采用最优置信区间求解算法,预测区间覆盖率受灵敏因子影响较小,预测区间覆盖率主要与置信水平相关。根据表1 训练集残差分量预测结果,本文从预测可靠性与精准性的角度综合考虑,将灵敏因子α设定为0.5。
基于训练集构建的GRU、CNN 及高斯核密度估计预测模型,在测试集上进行动态分解和预测,最终得到基于STL-GCK 的行业中长期负荷区间预测结果如图2 所示。
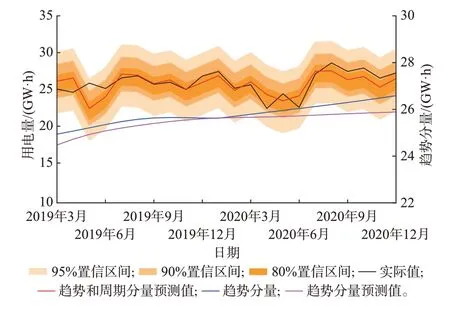
图2 行业中长期负荷预测结果Fig.2 Medium- and long-term industry load forecasting results
由图2 可见,基于GRU 预测得到的行业中长期负荷趋势分量与实际负荷趋势分量基本一致,偏差较小,验证了GRU 网络提取中长期负荷趋势依赖特征并预测负荷趋势分量的有效性(具体有效性验证结果见附录C)。在不考虑残差分量的情况下,行业负荷周期分量叠加趋势分量的预测结果能够较好地匹配行业负荷的实际值,通过计算得到均方根误差γRMSE为1 188.62 MW·h,平均绝对百分比误差γMAPE为3.64%(具体有效性验证结果见附录D)。基于自适应带宽高斯核密度估计残差分布,得到残差分量在不同置信水平(95%、90%与80%)下的置信区间预测信息,叠加行业负荷周期分量与趋势分量预测结果,最终得到行业负荷的区间预测结果(具体有效性验证结果见附录E)。
由图2 可见,在当前测试集上,90%置信水平的预测区间能够基本覆盖行业负荷变化的实际情况,预测区间覆盖率δcov达到95.5%,预测可靠性较高。当置信水平降低时,预测区间也将随之收缩,部分时步的负荷值将会处于预测区间外,预测的准确性降低,但是预测的精准度得到提高。综合考虑行业负荷趋势分量、周期分量等确定性分量以及残差不确定性分量后,模型的预测精度提高,泛化性能进一步增强。考虑到经济因素数据可能由于统计原因存在滞后,导致在预测下个月度的用电量时,当前月度的经济因素数据无法得到。因此,本文对比了3 种场景下所提预测方法的预测效果。场景1 为理想场景,即不考虑数据统计时延;场景2 为提前1 个月预测未来1 个月用电量(即τ=1,K=1);场景3 为不考虑经济因素数据直接预测。三者对比结果如表2所示。
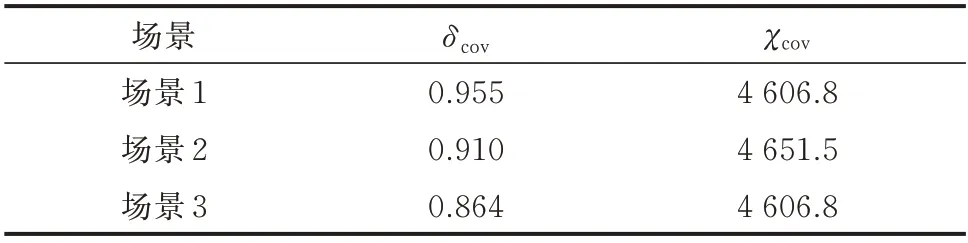
表2 不同场景下负荷预测评价结果Table 2 Evaluation results of load forecasting in different scenarios
由表2 可知,在理想场景下概率预测区间的准确率最高;考虑数据统计时延后,预测因需预留一定的提前量导致预测难度增加,负荷预测准确率下降;若不考虑经济因素,预测准确率相较于场景1 有所下降。在不考虑经济因素的场景下,由于忽视了经济因素同行业电量趋势分量的相互作用,负荷趋势分量预测精度下降导致整体电量预测准确率相对较低,而负荷的残差分量估计结果不受影响。因此,概率区间预测宽度保持不变。尽管在考虑数据统计时延以及不考虑经济因素场景下负荷预测的精度在一定程度上下降,但预测结果仍然能够保持较高的准确率与可靠性。
4.3 不同负荷预测方法对比分析
为验证本文所提组合预测方法的优越性,选取90%置信水平下不同概率区间预测模型,如分位数回 归 卷 积 神 经 网 络(quantile regression convolutional neural network,QRCNN)[32]和分位数回归长短期记忆(quantile regression long short-term memory,QRLSTM)[33]、随 机 森 林 分 位 数 回 归(quantile regression random forest,QRF)[34]对 行 业中长期负荷进行预测,区间预测对比结果如图3所示。
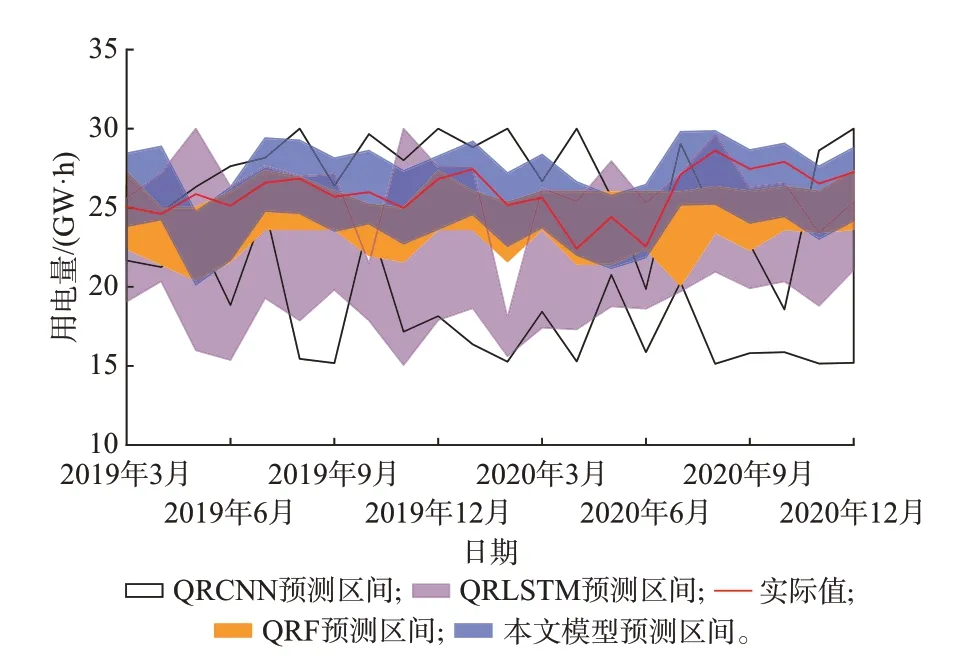
图3 不同负荷预测方法预测结果对比Fig.3 Comparison of forecasting results with different load forecasting methods
由图3 可见,QRLSTM、QRCNN 模型预测区间平均宽度较大,且不同时刻预测区间宽度变化较为显著,预测区间的覆盖率较低;QRF 模型相较于QRLSTM 预测区间覆盖率更低,但是平均预测区间宽度较小;本文所提方法基本能够捕捉行业负荷的变化趋势,除第3 时步预测结果落于90%置信水平预测区间外,其余时步预测结果均在预测区间内,预测区间的覆盖率较高,预测区间宽度较小,模型的可靠性与精准性均较优。各模型的区间预测评价指标如表3 所示。
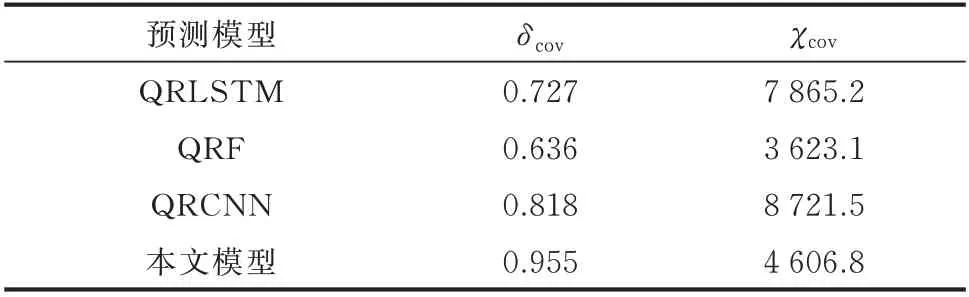
表3 不同预测模型评价结果Table 3 Evaluation results of different forecasting models
由表3 可知,相比于其他方法,本文所提方法的预测区间覆盖率最高,基本实现了行业负荷预测的全覆盖,可靠性较高。但是,本文方法在实现高区间预测覆盖率的同时牺牲了一定的算法精准性,预测区间宽度略高于QRF 方法,但从整体来看,本文方法对行业中长期负荷预测的效果更优。
以上分析验证了本文所提概率预测方法相较于传统直接概率预测方法的优越性。为了进一步验证本文所提“分解和预测”方案的有效性,采用基于经验模态分解(empirical mode decomposition,EMD)与最小二乘支持向量机(least squares support vector machine,LSSVM)的负荷预测模型[20]和基于完全自适应噪声集合经验模态分解(complete EEMD with adaptive noise,CEEMDAN)与双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)的确定性负荷预测模型[35]以及基于STL-QRLSTM及STL-QRCNN 的概率负荷预测模型对行业中长期负荷进行预测。其中,确定性预测模型通过模态分解方法将原始负荷曲线分解为各模态分量,然后分别采用LSSVM 子模型与BiLSTM 子模型对各分量进行预测,概率预测模型STL-QRLSTM 通过STL 方法将原始负荷曲线分解,趋势分量及周期分量分别由LSTM 预测得到,残差分量通过QRLSTM 预测得到,STL-QRCNN 预测方法流程类似,不再赘述。各模型预测评价指标及预测曲线分别见表4 及附录F 图F1 和图F2。
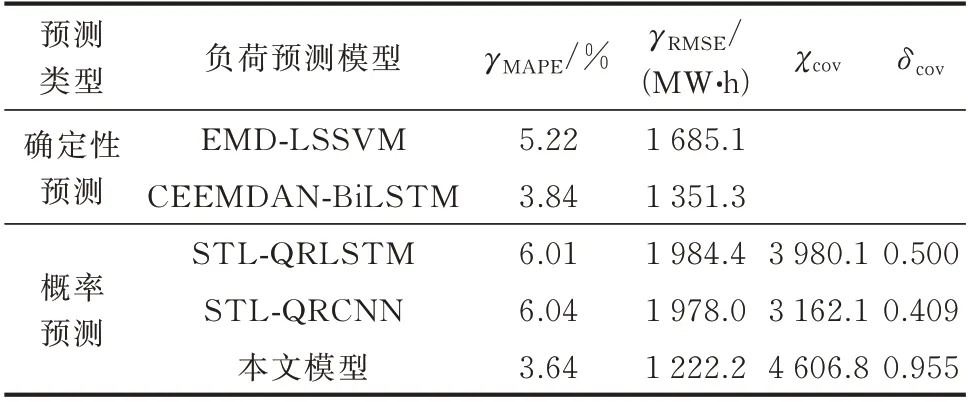
表4 行业中长期负荷预测结果Table 4 Forecasting results of medium- and longterm industry load
由于EMD-LSSVM 及CEEMDAN-BiLSTM模型预测结果均为确定性预测结果,为与之进行对比,抽取本文模型中最高残差分量密度对应的负荷值以及QRCNN、QRLSTM 中残差分量的中位数回归值,然后,叠加趋势与周期分量预测值,得到概率预测模型的确定性预测结果。由表4 可知,以上2 种模型与本文模型均能较好地预测负荷的变化趋势与波动,但本文模型利用不同子模型的特性对各分量进行差异化建模,整体预测精度高于其他2 种确定性模型(见附录F 图F1)。在部分时步(例如2019 年4 月、5 月),本文模型预测精度相对较低,这是由于在残差分量抽取时丢失了残差分量的概率分布信息,仅考虑了残差分量分布的局部信息(即概率密度最高对应的残差分量值),叠加周期分量与趋势分量预测结果后导致模型预测的可靠性与鲁棒性降低。若进一步考虑负荷残差分量不确定性量化与估计结果,结合残差分量概率分布信息,负荷预测结果的可靠性与鲁棒性将进一步提升。
需要说明的是,基于STL-QRCNN 和STLQRLSTM 得到的确定性预测结果预测精度较低,一方面是由于针对各分量均采用单一模型进行预测导致模型与分量特征的不匹配;另一方面是由于基于分位数回归的负荷预测模型的目标函数为所有分位数水平下总的分位数损失最小,而提取确定性预测结果时仅提取某一分位数的预测值,综合以上两方面原因,基于STL-QRCNN 和STL-QRLSTM得到的确定性预测结果误差较大。
由表4 可知,尽管基于STL-QRCNN 和STLQRLSTM 得到的概率区间预测宽度相较于本文模型较窄,预测结果更加集中,但是预测区间的覆盖率较低,仅有少部分时步的负荷结果位于预测区间内,预测的准确度和可靠性较差。本文方法通过STL分解得到具有不同时域特征的负荷分量,分别基于GRU、CNN 以及高斯核密度估计预测各分量,然后求和得到负荷总量,预测结果拥有更高的预测精度与可靠性(见附录F 图F2)。
相较于确定性负荷预测方法,概率预测方法能够更好地刻画负荷变化的不确定性,提供更加丰富的负荷预测信息。基于行业中长期负荷概率预测结果,电网企业以及售电公司等售电侧主体能够掌握电力市场中不同行业用户的用电规律以及用电需求增长趋势,进一步提升各类用户用电规模预测的科学性、准确性与可靠性。根据不同置信水平下的概率预测结果,售电侧主体能够有效量化收益与风险的不确定性,制定更加经济、科学的中长期市场交易策略,提升售电主体的经营效益。
5 结语
本文提出一种基于STL-GCK 模型的行业中长期负荷预测方法。该预测方法考虑行业中长期负荷在各时间维度的隐含特征,既能够挖掘行业负荷全局趋势特征及负荷周期局部特征,又能够计及行业负荷变化不确定性的影响,相较于其他机器学习方法和分解预测模型,本文方法具有更好的可解释性。算例仿真结果表明,相较于单一概率预测模型与常规分解预测模型,本文所提方法能够综合考虑负荷的趋势性、周期性以及随机性,具有相对较高的预测精度。
因行业隐私保护要求,无法获得行业内部诸如生产计划等多源异构数据,导致行业负荷预测的精度无法进一步提升。在未来数据开放共享的条件下,可针对各行业的相关特征进行深入研究,精细化建立各行业负荷特征体系,进一步提高行业负荷预测精度。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
