m-NOD样本最近邻密度估计的相合性
2022-10-11刘子湘
王 巍,刘子湘
(池州学院,安徽 池州 247000)
0 引言
设总体X的密度函数和分布函数分别为f(x)和F(x),X1,X2,X3,…,X n是取自于总体X的样本。又设{k n,n≥1}是选定的正整数序列,满足1≤k n≤n,a n(x)为最小的正数a,使得[x-a,x+a]中至少包含X1,X2,X3,…,X n中的k n个。Loftgarden和Quesenberry[1]将f(x)的最近邻估计定义为
最近邻密度估计是一种较常用的非参数概率密度估计方法,目前已取得许多研究成果。在相依样本方面,Boente和Fraiman[2]研究了基于φ-混合和α-混合样本的最近邻密度估计的强相合性;Chai[3]得到了基于φ-混合平稳过程的最近邻密度估计的强相合性、弱相合性、一致强相合性及其收敛速度;Liu和Zhang[4]建立了φ-混合样本的最近邻密度估计的相合性和渐近正态性;Yang[5]研究了负相关(NA)样本的最近邻密度估计的弱相合性、强相合性、一致强相合性;Wang和Hu[6]将Yang[5]的结果从NA样本推广到WOD样本。基于上述文献,本文将进一步研究m-NOD样本的最近邻密度估计的弱相合性、强相合性和一致强相合性。
Joag-Dev和Proschan[7]提出了NOD随机变量的概念,它是一类非常普遍的相依结构,包含了独立随机变量、NA随机变量。许多学者研究了NOD随机变量的概率极限定理和统计大样本性质[8-14]。基于NOD随机变量,Wang等[15]引进了m-NOD随机变量的概念。设m≥1为固定整数,若任意n≥2和对于所有的1≤k≠j≤n,Xi1,X i2,...,X i n是NOD随机变量,则称{X n,n≥1}是m-NOD序列。Joag-Dev和Proschan[7]证明了NOD随机变量包含了NA随机变量。Hu和Yang[16]证明了NOD随机变量包含了NSD随机变量。由此可见,m-NOD随机变量包含了独立随机变量、NA随机变量、NSD随机变量以及NOD随机变量。因此,研究m-NOD随机变量的大样本性质具有重要的理论意义。
本文利用m-NOD序列的性质与Bernstein不等式,进一步研究m-NOD样本最近邻密度估计的相合性,推广和改进已有文献的结果。为行文方便,假设C为一个正常数,在不同的地方可以表示不同的值;除非另有说明,否则极限取表示不超过x的最大整数值,c(f)表示函数f的所有连续点,logx=ln max(x,e)。
1 引理与主要结果
为了获得本文的主要结果,首先给出以下几个引理。
引理1.1[15]设{X n,n≥1}是m-NOD随机变量序列,若{f n(⋅),n≥1}均为非增(或非降)函数,则{f n(X n),n≥1}也是m-NOD随机变量序列。

其中,对于每个1≤l≤m,{X mi+l,0≤i≤j}是NOD随机变量。故由引理1.2可得
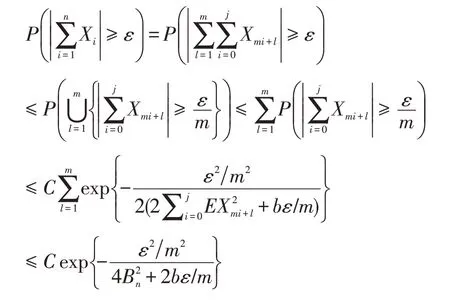
由此得到结论,证毕。
引理1.4[5]设F(x)为连续分布函数,对于n≥3,假设x nj满足F(x nj)=j/n,j=1,2,...,n-1,那么

下面给出本文的主要结果。

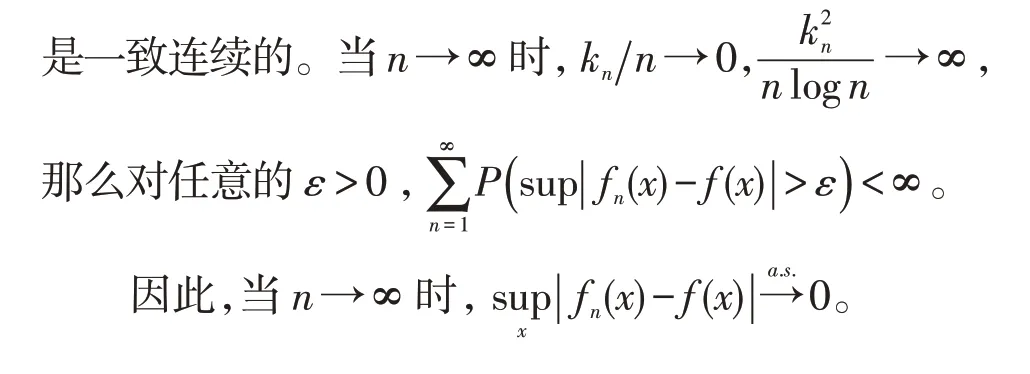
2 主要结果证明


同理,由式(3)和式(5)可得

定理1.1证明完毕。

由此推论1.1得证,证毕。
定理1.3的证明 证明将沿用定理1.1证明中的记号。由于f(x)是一致连续的,可推导出对于任何ε>0,存在一个正常数δ0,如果|x-y|<δ0,有



3 结语
本文首先建立了m-NOD序列的Bernstein不等式,利用m-NOD序列的性质和Bernstein不等式,研究了m-NOD样本的最近邻密度估计的弱相合性、强相合性及一致强相合性,将最近邻密度估计从NA样本推广到更一般的m-NOD样本,进一步拓展了最近邻密度估计的应用范围,为最近邻密度估计方法应用在更普遍的相依结构数据上奠定了理论基础。
