面向云制造的资源集群聚类方法研究*
2023-10-24苑明海李子晨黄涵钰裴凤雀俞红焱
苑明海 李子晨 黄涵钰 裴凤雀 俞红焱
(河海大学机电工程学院,江苏 常州 213000)
在新兴信息技术及先进制造技术的不断发展下,云制造理念应运而生。云制造的关键是构建制造云,即通过构建云制造资源池,对制造资源进行统一封装、发布、集中管理和智能化服务[1]。云服务池的建立意味着将存在海量的服务资源,资源分配的好坏直接影响云制造运营商资源管理的规范性及用户按需索取的便捷度,因此对云制造资源进行有效的划分,探索出适用于云制造资源集群的聚类方法显得尤为重要。
对于云制造资源的分类已有大量研究,综合来看,云制造资源可以分为硬资源和软资源,二者资源还可继续细分,如软资源分为软件、知识和人力等;硬资源分为制造设备、计算资源和物料等[2]。上述分类只是简单地根据资源的某种属性进行划分,每一类的资源在一些属性上既有相同点也有不同点,缺乏进一步细致有效地分类。为了满足云制造用户快速准确地对资源进行选择的需求,有必要对云制造资源进行聚类分析。蔡安江等[3]针对资源组合优化问题,引入关联规则挖掘策略及聚类分析,实现了资源的精准定位与匹配。Tong H 等[4]为了降低云制造平台资源共享难度,根据聚类结果提出一种基于共识达成过程的子组间匹配方法。Cui J 等[5]结合粒子群算法(PSO)和k 均值聚类算法(k-means)解决了制造资源优化配置问题,但在资源利用率上存在不完善之处。
从已有的研究上来看,云制造的探索从资源服务的特点出发,对资源进行了表述、建模、配置、聚类、重构和调度等研究,各个部分相互影响,相辅相成,从而形成云制造一体化的服务体系。为了进一步规整云制造资源,探究能实现对云制造资源进行更为细致的聚类划分的聚类算法成为众多学者的研究突破点,如Huang M 等[6]采用k 均值聚类算法选择最短完成时间来表示聚类目标,通过对车间机床、工件等资源的聚类形成分拣计划,虽然在稳定性上有所改善,但是该算法运行时间较长。在不确定聚类方面,目前的研究大多按照分区或者基于密度进行聚类,Gullo F 等[7]致力于层次聚类,提出了一种基于原型的凝聚层次聚类方法(U-AHC)。为避免初始输入参数对聚类结果的影响,Zhang R 等[8]提出一种无参数约束的自加权谱聚类。模糊聚类上,Bagherinia A 等[9]提出一种新的基于层次加权的模糊聚类集成框架,Xu S L 等[10]研究了基于极限学习机的模糊粒度邻域聚类算法,这些算法对于一些模糊的数据聚类起到了很好的划分作用,但对噪音数据的免疫性有所欠缺。对于目前应用广泛的kmeans 聚类,Chunlei L 等[11]提出一种基于谱聚类思想和粒子群k-means聚类算法的工艺路线聚类模型,根据相似度实现工艺路线的聚类并挖掘高价值工艺路线以供复用。Wang T R 等[12]通过将k-means 算法与局部搜索策略结合提出一种改进的NSGA-II 以提高求解质量。
本文在分析云制造服务之间的关系的基础上,结合云制造环境下制造资源聚集的类型建立云制造下混合式服务资源聚集模型。对云制造资源集群的聚类进行研究,通过优化蛙跳算法扩大了初始解的搜索范围,提高了种群间信息共享的能力,并基于优化后的蛙跳算法提出了改进的k-means 聚类算法,在改善了聚类结果受初始参数及初始聚类中心的影响的同时,大大地提高了算法的稳定性并缩短了聚类的时间。
1 云制造资源间的关系及资源聚集描述
云制造下的资源并不是单独存在的,其资源之间存在着一定的关联性,通过分析之间的关系,有利于资源的分类与聚集,方便云制造系统的管理与运维,提高用户按需索取的便捷度。研究资源的聚集过程将便于我们理解云制造资源的走向和云制造服务的流程,为探索出适用于云制造资源集群的聚类方法提供参考。
云制造下资源聚集需通过先进信息技术手段实现资源及能力的虚拟化,利用服务化技术进行封装组合,其中服务化技术主要有两种方式:资源及能力的聚合和资源及能力的拆分。聚合是集中所有资源与能力,为指定用户提供服务;拆分是将聚集的资源及能力进行按需分组,为多用户提供各类服务,如图1 所示,云服务的形成过程即是云制造资源和能力服务化的过程。

图1 服务化技术的两种方式
针对不同的应用模式,服务资源聚集可以分为企业内聚集、行业内聚集和混合式聚集3 种,其中,混合式聚集融合了企业内聚集和行业内聚集两种聚集方式,是最为普遍的聚集方式。本文建立的混合式服务资源模型图如图2 所示,实现了企业和行业间私有云和公有云的集成,图中每一朵云代表一个大型企业或集团,资源提供方为企业内不同部门。

图2 云制造下混合式资源服务聚集
该混合式聚集中,企业内部由资源提供方将元数据发布或映射到虚拟资源池中,通过云服务中间件对元数据统一封装进行资源共享,最终将所需数据提供给用户。数据层一方面根据用户需求提供元数据,另一方面根据用户需求特征,为用户提供相关推送,满足用户个性化需求,同时,多企业间可以实现所有资源的共享。混合式服务聚集将行业内的资源进行了整合,用户只要通过云端就能获取所需要的制造资源和能力服务,在满足企业自身需求的同时,也促进整个行业的共同发展。
2 基于蛙跳算法改进的k-means 云制造资源聚类方法
云制造平台中的资源量大、种类多、功能各异且分布较广,合理有效地分配云制造资源有利于提高云制造系统服务化能力,从而提高整体系统互操性、开放性、敏捷性和集成能力。
2.1 k-means 聚类算法有效性评估
聚类的目标是实现类内样品相似度最大,类间相似度最小[13-14],即使聚类的簇内距离最小,簇间距离最大。通过对随机数组两两比较复合相关系数,建立聚类有效性评估函数如下:
类内距离D内(intra-cluster distance)
类间距离D间(inter-cluster distance)
最终建立目标函数F(objective function)
式中:类内距离采用欧式距离,k为类的个数,X为聚簇Ri中的元素,Ci为第i个类的聚簇中心,pdist代表欧几里得距离,类内距离计算的是所有类内元素到聚簇中心的欧几里得距离平方之和;类间距离采用类平均距离,na、nb为两个不同聚簇Ra、Rb中样本的个数,Xi、Xj分别为Ra、Rb中的元素,类间距离与相异两个聚簇内元素之间的欧几里得距离平方总和成正比,λ为调节系数,λ>0。为实现较大的类内聚合和类间分离,即对样本进行聚类,实现目标函数F的最小化。
2.2 基于蛙跳算法改进的k-means 聚类
蛙跳算法(SFLA)结合了文化基因算法(MA)及粒子群算法(PSO)的优点,将局部搜索与全局寻优相结合,具有较强的鲁棒性[15]。其原理是借鉴了生物之间信息分享的社会机制促进了种群的进化过程:为快速而准确地寻找食物,青蛙群体划分成个数相同但模因信息不同的族群,组团搜索,形成局部范围的小团体,局部精英个体影响着其所在族群的每一个青蛙个体;而随着整个种群的进化,不同族群之间开始混合,进行信息交流,这个过程使得很多青蛙个体感受到不同族群之间(和自己不在一个族群内)的青蛙的模因,学习了新思想实现了全局的信息共享,使得整个种群沿着正确的方向搜索食物源。而为进一步增强蛙跳算法族群间的信息共享,使全局极值更快的接近最优解,对原始的蛙跳算法进行改进,主要是对族群中最差蛙向最优蛙学习过程的改进,由族群内部学习改为全局学习,扩大族群中最差蛙学习的搜索范围,提高进化过程中的族群多样性。
算法运行时,先产生D只青蛙,第j只青蛙可以表示为Cj=,为扩大解的搜索范围,产生D只新蛙作为反向解,第j只新蛙可以表示为,其中,,计算这2D只青蛙个体的适应度,比较适应度的大小,选出适应度较高的D只青蛙,并标记全局最优的个体Uzbest,适应度为Fzbest。将这D只青蛙划分为m个族群,每个族群包含n只青蛙,满足D=m×n,计算每个族群的最优解Ugbest和最劣解Ugworst,其对应的适应度值为Fgbest和Fgworst,按照式(6)对每个族群的最劣解Ugworst进行改进,比较更新过的最劣解适应度值F*gworst是否优于原始的Fgworst,若不优于原始解则按照式(8)更新Ugworst,再次比较更新过的最劣解适应度值F**gworst是否优于Fgworst,若不优于则按照式(9)更新Ugworst,重复上述局部优化L次。
式中:i代表第i个蛙群,m为族群总数,Ugavg计算的是所有蛙群最优解的均值,rand1及rand2为[0,1]的随机数,Gi和是第i个族群中最劣解移动的步长,及分别为第i个族群中最优解、最劣解及全局最优解,和是第i个族群中最劣解更新后新位置解,Umin和Umax代表族群计算过程中的最小值位置与最大值位置。
族群更新后将各蛙群进行混合,再次进行划分,记录全局最优的个体Uzbest,其适应度为Fzbest,循环族群局部更新、全局寻优及混合划分操作,直至满足终止条件。算法流程图如图3 所示。

图3 基于蛙跳算法改进的k-means 聚类算法流程图
基于蛙跳算法改进的k-means 聚类算法具体步骤可以描述为:
步骤1 输入数据集Data={X1,X2, ···,XN}和聚簇数k。
步骤2 利用改进的蛙跳算法生成初始聚簇中心C={C1,C2, ···,Ck},具体如下。
(1) 设置相关参数:设初始种群个体数为D,划分族群数m,其中每个族群包含n个个体,即D=m×n,每个族群局部优化次数为L,全局最大进化代数Maxgen。
(2)初始化种群:在Data最大值与最小值之间随机产生一群个体,第j个个体表示为Cj=,并生成相同数量的反向解,第j个新个体表示为Cˆj=,其中,j={1, 2, ···,D},
(3) 按照式(3)计算上述2D个个体的适应度F,选取F值较小的D个个体作为最终初始种群。
(4) 种群划分:将选取的D个个体按照F值大小进行排序,均匀地分配到m个族群内,即按照适应度排序将前m个个体分配到m个族群,紧接着的m个个体同样分配到m个族群,以此类推,确保每个族群优劣解均衡。
(5) 族群进化:按照3.2 节所述,利用式(6)、式(8)和式(9)更新族群最差个体,重复局部搜索操作L次。
(6) 族群混合:将划分进化后的族群进行混合,获取全局最优个体。
(7) 检验是否满足算法终止条件:根据全局最大进化代数Maxgen 判断是否终止算法,当未达到算法终止条件时,转到步骤(4),最终输出全局进化Maxgen 次后的最优解Uzbest。
步骤3 以上述改进的蛙跳算法生成的Uzbest作为初始聚簇中心C,按最近邻原则将Data 中数据进行聚类划分,分为k个样本集合R={R1,R2, ···,Rk}。
步骤4 更新聚簇中心C。取样本集合Ri中所有样本的均值作为新的聚簇中心Ci,Ri为R 中的一类样本集。
步骤5 重新聚类划分。按照最近邻原则结合新的聚簇中心对Data 中数据重新进行聚类划分,形成新的k个样本集合R*=。
利用上述改进的蛙跳算法对聚簇中心先进行优化再进行迭代,循环迭代步骤直至算法结束,降低算法对聚簇中心的依赖性,改善传统k-means 算法随机选取初始聚簇中心不同而造成聚类结果波动的情况,同时改进后的蛙跳算法通过引入蛙群最优解均值,在一定程度上改善了算法优化过程中族群信息共享能力差等问题,提高了算法的收敛速度及解的稳定性。
3 实例分析
以两种数据集及同类机床资源为例,利用本文所提出的算法对其进行聚类,数据集的点分布散乱且具有一定的相似性与交叉性,机床选择同类型的机床,根据其能力属性中的单位加工率、主轴最大转速和加工等级这3 个性能属性为特征进行聚类划分,以验证本文算法的可靠度。
3.1 改进的k-means 聚类有效性验证
为验证改进的k-means 聚类的有效性,利用本文算法对UCI 数据库中的Iris 测试数据集和一个自构数据集Self-cd 进行聚类。Iris 数据集由150 个数据点构成,分为3 类,第一类与第二、第三类分界明显,第二类与第三类存在数据交叉部分,每个数据点包含4 个特征;自构数据集Self-cd 内包含180个二维数据点,正态分布在6 组内,如图4 所示。改进的k-means 算法在两个数据集上的聚类收敛情况如图5 所示。
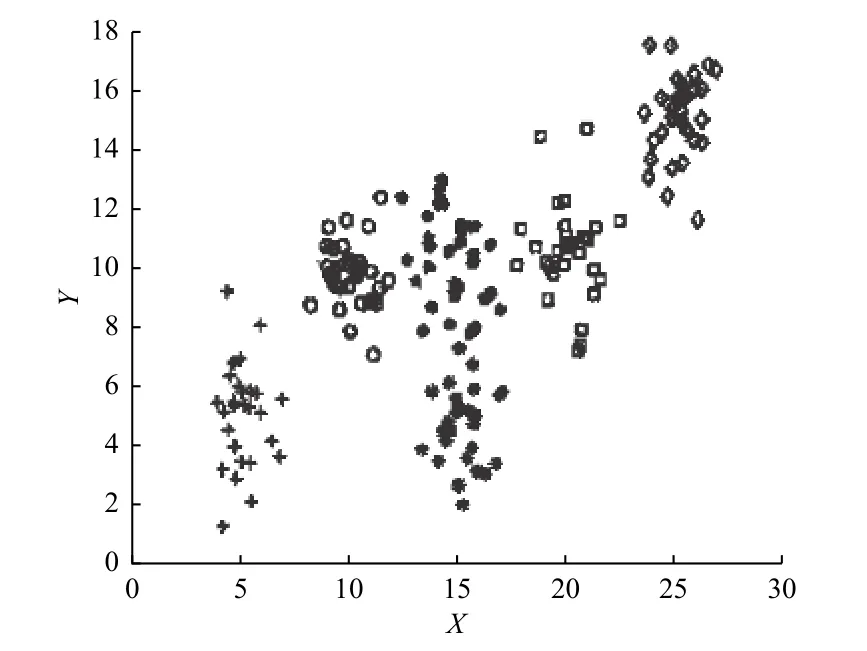
图4 自构数据集Self-cd

图5 改进的k-means 算法聚类收敛情况
从图5 可以看出由于Iris 数据集数据交叉部分较多,数据较自构数据集较为复杂些,因此最优的适应度值大些,算法在前5 次迭代收敛速度非常快,迭代50 次后算法几乎接近全局最优解,说明改进的k-means 算法具有很好的收敛性且聚类结果比较稳定。
为进一步验证该算法,同时采用模糊C均值聚类和GAk-means 聚类对这两个测试数据集进行聚类比较,主要对这两个数据集的聚类正确性进行比较,定义聚类准确度函数P=×100%,T与F分别为与已知正确聚类相比归类相同与归类不同的数据点个数,P越接近1 代表聚类结果越好,运行3 种算法各60 次,计算60 次运算中准确度最大值Pmax、均值Pmean、最小值Pmin(依次从上往下)如表1 所示。

表1 3 种算法聚类准确度P 比较
从图5 和表1 可见,模糊C均值聚类算法因易陷入局部最小值的缺点,无论是在Iris 还是在Selfcd 数据集上,相比于后两种算法,聚类的效果不佳,聚类准确度不高。GAk-means 聚类算法与模糊C均值聚类算法相比,聚类效果有所提升但不明显,本文所提改进的k-means 聚类算法准确度较高,收敛性好且具有较快的收敛速度,算法在保证解稳定性的同时,相比于前两种算法在聚类准确度方面也体现了较明显的优势,说明本文所提出的基于蛙跳算法改进的k-means 聚类算法可行有效。
3.2 云制造平台某同类机床的聚类划分
由于云制造资源具有海量性、多样性、大规模性等特点,对云制造资源有效聚集的策略便成为资源初步处理的重要环节,本文在上述聚类算法得到有效性验证的前提下,将该聚类算法运用于云平台某铣床资源聚类上,以云平台上1 000 个功能相似的铣床资源为例进行分类,以制造资源能力属性中的单位加工率、主轴最大转速和加工等级这3 个性能属性为特征进行聚类划分,即样本数据集Data={X1,X2, ···,X1000},每个样本Xi具有3 个属性指标,即Xi={xi1,xi2,xi3}。
为方便描述,将其具体参数描述如图6 所示,单位加功率范围为0.6~0.95,越大代表加功率越高,主轴最大转速范围为20~100,单位为 r/s,加工等级范围0~10,越大代表加工精度越高,利用上述基于蛙跳算法改进的k-means 聚类算法对云制造平台的资源进行进一步管理,其步骤如下:

图6 1 000 种机床的性能参数
(1)初始聚簇中心的确定
利用上文所提出的改进的蛙跳算法确定初始的聚簇中心,选取k=4,蛙跳算法中取初始种群个体数为1 000,根据上述机床3 个特征参数的最大值与最小值随机产生
1 000 个初始三维始个体,根据适应度排序划分种群,族群数为50,每个族群包含20 个个体,组内迭代次数L设为30,种群总进化代数为100,局部优化与全局寻优混合进行,最终确定初始聚簇中心C={C1,C2,C3,C4},其中Ci包含3 个参数,对应个体的3 个特征。
(2)聚类划分
按照最近邻原则将所有数据集分配给最近的聚簇中心,形成4 个聚簇,根据每个聚簇中的数据均值更新聚簇中心,再次进行数据的分配,直至非负代价函数收敛,最终输出分类好的样本集合,聚类结果如图7 所示。

图7 机床聚类结果图
由图7 可见,本聚类算法在1 000 个功能相似的铣床资源的聚类划分上,能够较为清晰地将1 000个铣床以单位加工率、主轴最大转速和加工等级这3 个性能属性划分为合理的聚类,使相似资源聚集为一类,以便资源的实时分配及空缺资源的及时替补,以供云制造运营方进行管理与匹配用户的个性化需求。
云制造系统对资源进行了高度的抽象,而用户只关心资源的外部状态,上述方式根据资源所具备的特征属性实现了云制造资源的进一步划分,该聚类方法同样适用于特征值较多的海量样本数据集,可对云制造平台内不明数据资源进行归类,剔除噪音数据,在减轻云制造运营方的管理压力的同时,为用户个性化的需求提供便捷的服务。
4 结语
本文对云制造环境下的服务进行研究,结合服务化技术聚合和拆分两种方式建立了云制造下混合式服务聚集模型,基于k-means 聚类建立了聚类有效性评估函数,解决了传统k-means 算法初始聚类中心随机选取带来的聚类结果不稳定问题,引入蛙跳算法对k-means 算法进行改进,又通过扩大初始蛙群和引入族群最优解均值改善蛙跳算法族群间学习能力弱的缺点,以改进后的蛙跳算法确定kmeans 初始聚簇中心,提出基于蛙跳算法改进的kmeans 聚类算法,通过实例验证了该方法的有效性和可行性,为其他云制造资源的进一步划分提供了参考与依据。
