沉浸式虚拟现实环境中认知投入的自动测评研究
2023-10-23张慕华李策祁彬斌白文倩
□张慕华 李策 祁彬斌 白文倩
一、引言
学习投入是衡量学习过程质量的重要指标,与学生学业成就息息相关(Xie,et al.,2020;李新,等,2021)。学习投入包含学生在学习过程中的认知投入、行为投入、情感投入和社会投入四个维度(Fredricks,et al.,2016)。随着信息技术与学习过程的深度融合,学生在技术支持环境下的学习投入测量及其对学业成就的影响受到越来越多研究者的关注(Bergdahl,et al.,2020)。以沉浸性和交互性为主要特征的沉浸式虚拟现实(Immersive Virtual Reality,IVR)环境被证明能够提升学生的认知投入(Chen,et al.,2021;Liu,et al.,2020)、行为投入(Chen,et al.,2021;Liu,et al.,2020)、情感投入(Lee,et al.,2022;Liu,et al.,2020;Parong,et al.,2021b;Wang,et al.,2021)和社会投入(Liu,et al.,2020)。可见,IVR 环境为提升学生的学习投入提供了必要的技术支持。然而,如何全面捕获技术支持环境下学生的学习投入一直面临很大挑战(Henrie,et al.,2015)。当前,IVR 环境中学习投入的测量主要采用基于问卷的自我报告方法(Chen,et al.,2021;Lee,et al.,2022;Liu,et al.,2020)。少数研究采用主观自我报告和客观生理数据流采集相结合的方式测量IVR 环境中的学习投入(Dubovi,2022;Parong,et al.,2021b),为深入理解IVR 环境中的学习投入提供了新的研究思路和方法。然而,由于技术的复杂性和生理传感设备使用的限制,基于生理数据的学习投入测量方法在短时间内难以在教学实践中被广泛使用(Henrie,et al.,2015)。
作为一种非侵入式检测方法,基于计算机视觉和深度学习的技术路线被认为是实现在线学习环境中学习投入自动测评的一种有效方法(Dewan,et al.,2019)。此外,计算机视觉技术也被越来越多地应用于自动识别学生在课堂学习环境中的面部表情(陈子健,等,2019;Pabba,et al.,2022;张永和,等,2021) 和行为姿态(Albert,et al.,2022;孙众,等,2020;王泽杰,等,2022;徐家臻,等,2020;赵春,等,2021),以实现对学习投入的自动评估。近年来,开始有学者探索基于计算机视觉技术自动评估学生在IVR 环境中的学习投入。例如,杜波维(Dubovi,2022) 采用计算机视觉技术中的表情识别算法实时追踪和评估学生在IVR 学习中的情感投入。达基莱等(Djilali,et al.,2021)采用机器学习中的无监督学习方法构建了人类在360 度视频中的视觉注意力模型,为自动识别和捕获学生在IVR 环境中的视觉注意力分配提供了技术支持。由于注意对人类的信息加工有着重要意义,是信息输入、编码、存储和提取的基础(张淑华,等,2007),上述研究无疑为IVR 环境中认知投入的自动测评提供了可行的技术路径。正如理查兹(Richards,2023)所言,随着计算机视觉、机器学习等技术的快速发展,研究者有望通过实时追踪学生在IVR 环境中的注意力分配、面部表情、生理信号等指标实现对学习投入的自动评估。然而,由于认知投入的内隐性,当前研究对IVR 环境中认知投入的评估主要采用事后自我报告的方法,无法全面捕获学生在IVR 环境中认知投入的过程性数据。基于此,本研究以计算机视觉和深度学习为技术支撑,以信息加工理论和具身认知理论为理论基础,探索对IVR 环境中认知投入的表征方法,并基于此实现对IVR 环境中学生认知投入的实时追踪和自动化测评,以期为全面捕获IVR 环境中学生的认知投入提供理论框架和实践方法。
二、文献综述
(一)基于计算机视觉技术的学习投入自动测评
计算机视觉(Computer Vision)是指让机器通过数字图像或视频等视觉信息来模拟人类视觉的过程,以达到对物体的理解、识别、分类、跟踪、重建等目的的技术(刘小文,等,2020)。因其在识别人类行为(特别是姿态估计和动作识别)和基本情感(如快乐、愤怒、恐惧、困惑等)方面表现优异,被广泛应用于各个行业。在教育领域,计算机视觉技术被用于自动监测和评估学生在传统课堂学习、在线学习等不同学习场景中的学习投入。就在线学习场景而言,基于面部表情识别的情感投入自动测评关注较多。例如,有研究(Kim,2021)提出基于人工神经网络(Artificial Neural Network,ANN) 的面部表情深度学习模型;何珊娜(Hasnine,et al.,2021)提出的基于卷积神经网络(Convolutional Neural Network,CNN)的面部表情识别模型以及相关研究(Shen,et al.,2022)针对大规模开放在线课程(Massive Open Online Courses,MOOC) 学习情境提出的基于领域自适应的CNN 面部表情识别模型。上述模型均为在线学习场景中学生的情感投入自动测评提供了技术支持。
除了基于面部表情单一数据源自动评估学生的情感投入外,也有研究综合面部表情、姿态、注视点等多个数据源,综合评估学生的在线学习投入。例如,有研究(Zhang,et al.,2020)综合了面部表情数据和鼠标点击流数据评估学生的在线学习投入状态,并发现基于多数据源的评估方法比基于单一表情数据的评估准确率更高。阿尔泰祁等(Altuwairqi,et al.,2021)提出了一种基于面部表情、键盘输入和鼠标点击流三个数据源的多模态学习投入自动评估方法,并通过三组实验验证了多模态评估方法的有效性。布诺等(Buono,et al.,2023)针对在线视频学习情境,提出了一种基于面部表情数据、头部姿态数据和注视点数据的学习投入自动评估方法,并通过与学生的主观报告数据的相关分析检验了该方法的有效性。有研究(Yue,et al.,2019)基于面部表情数据、注视点数据和鼠标点击流数据提出了一种识别学生在MOOC 学习中的情感、行为和认知投入的综合评估模型,用于实时检测学习者的在线学习投入水平。可见,综合多个数据源构建学习投入评估模型有助于提高评估模型的有效性。
就课堂学习场景而言,除了基于面部表情识别的情感投入自动测评外(Pabba,et al.,2022;Yun,et al.,2020),基于身体姿态识别的课堂行为投入自动测评也得到了较高的关注。例如,艾伯特(Albert,et al.,2022) 提出了基于3D-CNN 的学生课堂行为识别模型,该模型利用Yolov5 框架提取学生行为的时空特征,结合跟踪和目标检测技术将同一学生的时空特征联系起来,最后通过分类模型实现课堂环境中对多个学生的动作识别。王泽杰等(2022) 则提出了融合OpenPose 人体姿态估计算法和Yolov3 目标检测算法的学生课堂行为识别模型,该模型对于举手、书写、玩手机等常见课堂行为的识别精度高达95%以上,为教师全面高效地掌握学生课堂学习投入提供了重要的技术支持。此外,也有研究者采用计算机视觉技术自动提取学生的人体骨架信息,以此来自动识别听讲、看书、站立、举手、写字等学生常见课堂行为(徐家臻,等,2020)。赵春等(2021)则以计算机视觉技术(包括表情识别、姿态估计、目标检测等)为基础,开发了学生课堂学习行为投入测量和分析系统,识别了与学生身体姿态密切相关的6 个课堂行为投入指标。
综上可见,已有研究已经充分证明了计算机视觉技术在评估不同学习场景中的学习投入,特别是情感投入和行为投入方面的有效性。同时,由于认知投入的内隐性,已有研究主要采用情感和行为来间接表征学生的认知投入。然而,作为一种新兴的技术增强型学习环境,如何表征学生在IVR 环境中的认知投入,并基于计算机视觉技术实现对学生认知投入的实时追踪和自动测评还鲜有研究关注。
(二)IVR 环境中认知投入的多模态表征
认知投入指学生在学习过程中的内在心智参与,包括深入思考、使用认知策略、主动地付出必要的努力来理解复杂的思想或掌握复杂技能(Fredricks,et al.,2016)。如何对IVR 环境中的认知投入进行表征受到越来越多研究者的关注。除了基于主观报告的方式(Liu,et al.,2020;Wang,et al.,2021),已有研究开始采用多模态的方式表征IVR 环境中学生的认知投入。例如,帕龙等(Parong,et al.,2021a,2021b) 采用脑电图(Electroencephalogram,EEG) 信号和自我报告相结合的方式来表征学生在IVR 学习中的认知投入。杜波维(Dubovi,2022)基于眼动追踪数据、皮肤电活动(Electrodermal Activity,EDA) 数据和自我报告数据相结合的方式表征IVR学习中的认知投入。国内学者致力于构建IVR 环境中学习投入的评估框架。例如,何聚厚等(2018)设计构建了IVR 学习评价指标体系,并利用Microsoft Azure 平台的大数据技术,实现对学生学习过程和行为的动态跟踪和自动分析。该研究通过学生在IVR环境中的行为投入数据来表征其认知投入状态。例如,通过记录学生在不同骨骼处手柄停留的时间来表征学习者对该处内容的意义建构,记录完成骨骼拼接任务中的出错率、完成时间等来表征学生的问题解决策略的使用。马婧等(2023)构建了基于多维传感系统的学习投入综合模型,采用表情信息、语音信息、心率和皮肤电等生理信息综合表征学生在IVR 环境中的情感投入,采用在线实时测验中的答题行为(准确率、答题时间等),以及学生与智能教学代理间的互动问答行为(反应时间、语音信息、问答时的生理信息等)来综合表征学生的认知投入。综上可见,IVR 环境中的认知投入一方面通过生理数据(EEG 信号、眼动数据、EDA 数据等)来直接表征;另一方面通过行为数据(手柄停留时间、任务完成准确率、答题时间等)来间接表征。由于生理传感器的使用在真实的教学实践场域受到限制,采用基于行为数据来间接表征学生在IVR 学习中的认知投入是一种在教学实践中行之有效的方法。
信息加工理论和具身认知理论为IVR 环境中认知投入的表征提供了启示。信息加工理论将学习看作是学习者所面临的来自环境的刺激通过一系列内部构造被转化、加工的过程(Gagne,1985),认为学习的过程包含注意刺激、刺激编码、储存与提取信息几个阶段(张淑华,2007)。以沉浸性和交互性为特征的IVR 环境能够为学习者带来视、听、触等多重感官的注意刺激,特别是视觉注意刺激。作为人类信息加工的主要方式,视觉注意可以从注意的广度、稳定性、分配和转移四个方面来把握其特征(张淑华,2007)。注意的广度指个体在同一时间内能清楚地观察到对象的数量,而稳定性是指注意保持在某一对象或活动上的时间长短。当个体在同一时间对两种或两种以上的刺激进行注意或将注意分配到不同的活动中去时就涉及注意的分配;而当个体有意地把注意从一个对象转移到另一个对象,或是一种活动转移到另一种活动中去时就涉及注意的转移。由于注意是一切认知活动的起点,视觉注意刺激是人类信息加工的基础,学习者在IVR 环境中的认知投入可以从其视觉注意的广度(即观察到哪些学习内容)、注意的稳定性(即对所观察对象的持续注意时间)、注意的分配(即多个学习对象之间的注意选择)和注意的转移(即观察不同学习对象的顺序)四方面来表征。
不同于信息加工理论,具身认知理论认为我们思考和理解世界的方式取决于我们的感觉运动系统和身体与环境的相互作用(Wilson,2002)。具身认知理论强调身体在人类经验中的作用,并将其与认知过程联系起来(Stolz,2015),认为身体运动过程和视觉过程的联系越明确,学习效果就越好(Lindgren,et al.,2022)。戈尔丁-梅多(Goldin-Meadow,2011)的研究发现,当一种运动模式(如手势)被加入学习体验中时,可能会激活更多的神经通路,从而在大脑中留下更深的记忆痕迹。这与我们所熟知的“眼见千遍,不如手过一遍” 这句谚语的内涵不谋而合。有研究(Jang,et al.,2017)发现,当学生的身体互动和特定概念的视觉特征相协调时,学习会得到强化。例如,让学生直接操作一个对象来理解其物理特征(如大小、形态等) 时,学习的效果要更好。王辞晓等(2022)的元分析研究发现虚拟实验的具身程度对学生的学习成效具有调节作用,IVR 支持的全身交互型虚拟实验对学习成效的促进作用最大。在IVR 环境中,具身指学生能够体验拥有一个虚拟身体(例如一双虚拟手) 的感觉,也被称为身体所有权(Body Ownership) (Makransky,et al.,2021)。IVR 环境的高保真和交互性特征有助于促进学生在学习过程中获得具身体验,即身体所有权的感觉。而这种身体所有权的感觉可能会引发其认知改变(Kilteni,et al.,2013)。可见,在IVR 环境中,学生与虚拟环境的交互行为会引发其具身体验,而这种具身体验又与其认知加工密切相关。因此,学生在IVR 学习中的认知投入也可以通过其身体交互行为间接表征。
(三)IVR 环境中学习投入对学习结果的影响
已有研究对IVR 环境中学生学习结果的考察主要从知识保留和知识迁移两个方面进行。知识保留考察的是学生对学习材料的记忆能力;而知识迁移则考查学生在新的环境中使用学习材料的能力(Mayer,2005)。有研究(Lee,et al.,2022)表明,IVR环境中学生的积极情感投入能够预测其对科学概念知识的保留成绩。帕龙等(Parong,et al.,2021a)通过结构方程模型分析发现IVR 环境中学生的高唤醒情绪和高认知投入会正向预测其最终的科学知识保留成绩。刘妍等(2021)的研究发现IVR 环境的多通道感知有助于促进学习者的注意力水平和深层次信息检索,提升学习者的情感投入,继而促进学习者获得更为持久的记忆效果。杜波维(Dubovi,2022)采用多模态的方法分析了IVR 环境中学生的认知和情感投入,通过回归分析发现更少的愤怒表情、眨眼频率,以及对无关信息的视觉注视可以预测更好的知识保留成绩。埃西(Essoe,et al.,2022)的研究发现,学习者在VR 环境中的临场感体验越强时,其在一周后的单词记忆测验上的表现越好。该研究通过fMRI(功能磁共振成像)实验分析发现,在单词检索过程中,学习者的记忆表现提高与原始编码环境相关的大脑活动模式的恢复有关。根据信息加工理论,记忆是人脑对信息进行编码、存储和提取的过程。可见,IVR 环境可能会通过影响学生的认知投入(即信息编码能力)最终影响其知识保留成绩。
在知识迁移方面,马克兰斯基等(Makransky,et al.,2019a)的研究发现基于IVR 环境的实验技能迁移效果显著优于基于纸质材料的技能迁移效果。帕龙等(Parong,et al.,2021b) 对比IVR 和桌面VR 环境中学生的知识迁移成绩发现,IVR 环境中学生的知识迁移成绩更差,EEG 测量到的学生的认知投入也更低。高楠等(2023)的研究发现,IVR 学习比视频学习更有助于促进学习者对概念性知识和程序性知识的迁移效果;IVR 组比视频组的学习者在学习过程中付出更多的心理努力,即认知投入更多。同时,胡艺龄等(2021)的研究发现学习者的学习风格调节了IVR环境对实验技能迁移效果的影响。活跃型学习者比沉思型学习者在实验任务中表现出更多的动作类交互行为,这种交互行为有可能强化学习者在IVR 环境中的视觉加工,从而有助于促进学习迁移。虚拟环境中学生的交互行为已被证实能够显著提升深度学习效果中的内部关联迁移和外部拓展迁移(刘哲雨,等,2017)。综上可见,IVR 环境的高沉浸性和高交互性特征会通过促进学生的交互行为影响其认知投入,继而影响知识迁移效果。
基于上述分析,本研究采用基于行为数据的方式来表征学生在IVR 环境中的认知投入,旨在探索基于计算机视觉技术的认知投入自动测评方法,并验证该方法的有效性。具体而言,本研究旨在回答如下两个研究问题:(1)如何基于计算机视觉技术实现对IVR 环境中学生认知投入的自动测评?(2)认知投入的测评结果与IVR 环境中学生的知识保留和知识迁移之间是否存在显著相关性?
三、研究设计
(一)研究对象和实验材料
研究采用网络招募的方式邀请大学本科一年级新生群体参与实验,并从中筛选出符合本研究需求的实验对象。在被试招募前,研究采用Gpower3.1.9.2进行所需样本量计算,将显著性水平α 设置为0.05,效应量设置为0.5,统计功效(1—β)设置为0.8,计算所需样本量为26(Faul,et al.,2009)。考虑到筛选需求和样本数据回收率,研究最终招募到来自北京市某高校的43 名非生物学专业背景的学生。这些学生在高中均选修了生物,在高中会考中的生物学科成绩均为A 等级。这些参与者均有使用IVR 设备进行游戏的经历,对IVR 设备的操作较为熟悉,但没有使用IVR 设备进行学习的经历。参与者中男生较多,男女比例约为3:1;有40%大学所学专业为自然科学,60%所学专业为人文社科。
本研究中的IVR 学习系统由华为VR Glass 眼镜搭配6DoF 交互手柄,以及一台高性能工作站和显示器构成。研究所选用的实验材料为STEAM 平台上的科普资源(The Body VR: Journey Inside A Cell)。该学习材料涉及红细胞、白细胞、血小板、细胞膜、水、氧、葡萄糖、微丝、中间纤维、微管、驱动蛋白、细胞核、核膜孔、脱氧核糖核酸、核糖核酸、核糖体、囊泡和线粒体18 个知识点。如图1 所示,每个知识点中所涉及的三维模型都配有相应的文字信息。

图1 IVR 学习材料
利用头戴式显示器,学生可以身临其境地感受到自己乘坐一架置身于人体心脏内部小动脉的小飞船,以第一人称的视角观察这些不同类型的血细胞和细胞器的形态和内部结构,体验人体细胞与病毒作斗争的过程。逼真的三维场景配合必要的文字内容和语音讲解可以让学生在视听双通道的刺激中高效地完成信息加工。同时,在核心知识点的呈现阶段,学习者可以通过交互手柄触碰和操控这些细胞器实现多角度地观察,还可以体验用交互手柄 “制造”一个细胞器并发射到虚拟环境中。在人体细胞与病毒作斗争环节,游戏化的设计方式让学习者通过控制手柄发射白细胞和抗体的方式击退病毒,在持续不断的交互体验中理解人体是如何抵御病毒细菌的。
(二)实验设计
1.实验流程设计
整个实验由预调查、IVR 学习和测试三个环节构成。预调查环节主要用来收集学生的个人信息以及学生对将要学习内容的了解程度,用时约5 分钟。IVR学习环节,实验助手会告知学生如何正确佩戴好VR Glass,以及交互手柄的操控方式。同时,实验助手会告知学生即将学习的材料包含哪些交互设置(如触碰、旋转、发射等),为IVR 学习体验做好准备。IVR 学习环节持续约20 分钟。在IVR 实验环节,实验助手会使用屏幕录制软件录制学生的整个体验过程。在测试环节,学生要完成一份考察知识保留和知识迁移的测试题。测试题目由研究者和一位大学生物学专业教师在迈耶等(Meyer,et al.,2019)给出的测试题目的基础上改编而成,包含10 道检验知识保留的选择题和3 道检验知识迁移的简答题。为保证学生答题效果,测试环节给学生提供了充足的答题时间。
2.IVR 学习中认知投入自动分析系统设计
基于信息加工理论和具身认知理论,研究从视觉行为和交互行为两方面表征学生在IVR 环境中的认知投入。本实验所选材料为知识讲解型学习内容,各知识点的讲解顺序是固定的,且与每个知识点相关的三维模型在同一时间是单独呈现的。因此,本研究中的视觉行为主要考察视觉注意的广度(即是否注意到关键知识点)和稳定性(每个知识点的注意时长)两方面。同时,本实验所选材料包含有交互设置,学生在进行交互操作时虚拟手柄会出现在视频画面中。因此,本研究中的交互行为主要考察视频画面中手柄出现的次数,以及手柄出现的累计时长。
由于实验材料中每个知识点的呈现都配有简短的文字说明,研究将IVR 视频画面中标识知识点的文字信息是否出现,以及出现的累计时长作为表征学生视觉行为的关键指标;将IVR 视频画面中手柄出现的次数,以及出现的累计时长作为表征交互行为的关键指标。研究通过计算机视觉技术自动检测和追踪IVR 视频画面中标识知识点的文字信息和手柄交互信息;采用深度学习技术中的Yolov5 模型对学生在IVR 学习中的视频画面进行目标检测,包括学习目标(标识知识点的文字信息) 和手柄交互目标。在此基础上,本研究开发的自动分析系统的总体架构图如图2 所示。
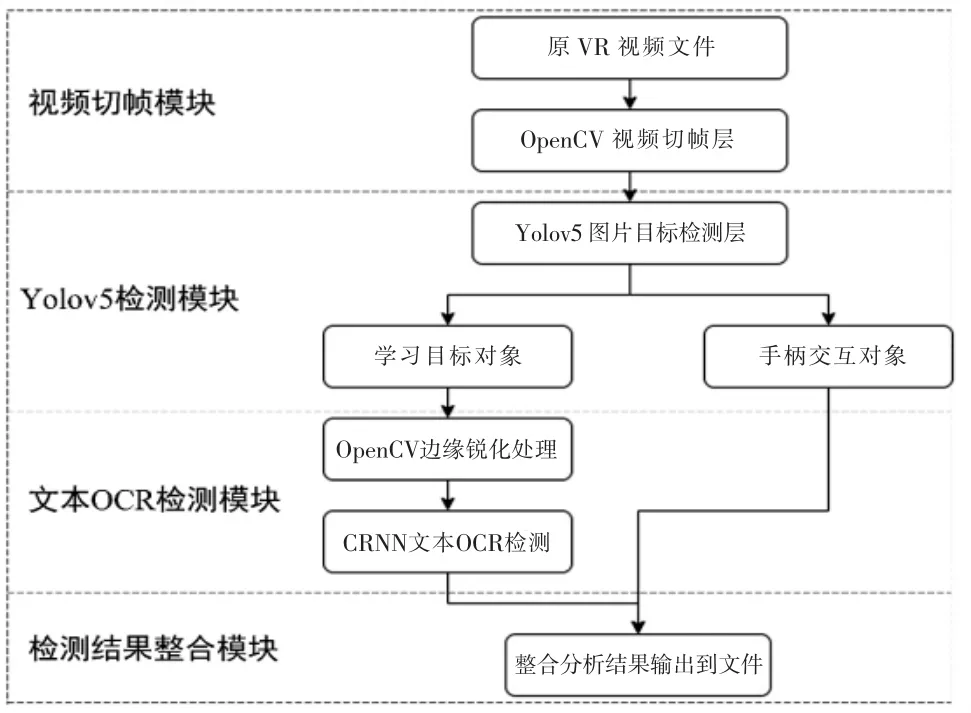
图2 IVR 学习认知投入自动分析系统总体架构
该自动分析系统总共包含四个模块:视频切帧模块、Yolov5 检测模块、文本OCR 检测模块、检测结果整合模块。在视频切帧模块,研究通过OpenCV 库对学生在IVR 学习中生成的录屏视频进行切帧,将每一帧转化为一个图像。OpenCV 是一个开源计算机视觉库,提供了各种函数和工具,可用于批量快速处理图像和视频。由于Yolov5 网络对于输入图像的大小不作要求,因此,OpenCV 库切帧得到的图像可以直接输入到下一层的Yolov5 网络中进行分析,从而简化了处理过程。
Yolov5 检测模块负责接收传入的切帧图像,并基于预训练的权重值来对图像进行目标检测。Yolov5 检测模块可以将检测对象分为学习目标对象和手柄交互对象,并经过分类后输出每个目标的窗口坐标。这些窗口坐标可以用来对目标进行定位和识别。在将窗口裁剪后,Yolov5 检测模块将检测到的目标传入后续的层级中进行分析和处理。通过对IVR 学习视频进行预训练和微调,可以获得围绕特定主题的IVR 视频目标检测结果。
文本OCR 检测模块用于识别IVR 视频中的文字信息。该系统的文本OCR 层使用了卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)模型,该模型是一个深度学习模型,可以同时进行卷积神经网络和循环神经网络的训练,以实现文本识别任务。文本OCR 检测模块使用CRNN 模型对输入的裁切窗口图片进行文本OCR 检测。具体而言,输入的窗口图片被预处理为一个统一的尺寸,并输入到CRNN 模型中进行处理。模型根据已经学习到的特征来识别图像中的文字信息,并输出一个字符串作为检测结果。这个字符串表示识别出来的文字内容,例如一个学习目标的名字 “红细胞”。检测结果会被传入到下一层检测结果整合层中进行处理和整合,以生成最终的文本信息。
检测结果整合模块主要对系统的数据进行整合并将结果输出到.csv 格式的文档中。其中,因为考虑到IVR 视频视角在不断地变化,所以检测目标有可能会出现误判或者由于文本OCR 检测出错导致的识别错误,为了模糊短暂几帧的识别错误,以及对于长时间没有追踪到的检测目标进行切分,本系统针对目标跟踪环节进行了模糊算法处理以提高检测的准确性。
(三)数据收集与分析
研究通过客观测验的方式收集学生在IVR 学习后的知识保留和知识迁移数据。实验结束后回收测验答题43 份。知识保留为选择题,依据标准答案进行评分。知识迁移为简答题目,依据采分点进行评分。在知识迁移题目的评分中,研究邀请两位具有生物学背景的研究人员进行评分。两位研究人员并未参与本实验,也不了解学生在实验过程中的表现,所以评分时不会受主观因素的影响。同时,为保护学生的个人隐私,知识迁移测试中只呈现了学生的编号信息。在评分环节,为保证评分结果的可靠性,两位评分人员首先学习评分标准并协商达成一致,然后对每道迁移题目开始独立评分。三道迁移测试题目的评分者一致性信度Cohen’s kappa 系数分别为0.86、0.84、0.88,表明两位研究人员的评分具有较高的评分者一致性。最终,研究将两位评分人员打分的平均值作为学生知识迁移的最终成绩。
研究通过屏幕录制的方式收集学生IVR 学习的视频数据。实验结束后收集到有效视频文件35 个。其余8 个视频因为屏幕录制程序出问题导致录制时长过短被剔除。如图3 所示,研究将35 个视频文件导入自主开发的VRTracker 视频分析软件中进行分析,实现对学生在IVR 环境中认知投入的自动追踪和捕获。VRTracker 视频分析软件会对每一个检测视频输出两个.csv 格式的文档。一个文档记录学生IVR 学习的视觉行为,包含的参数信息有:视觉注意对象名称、出现帧数、消失帧数、出现时间、消失时间、持续时间。另一个文档记录学生在学习过程中的手柄交互行为,包含的参数信息有操作对象名称(即手柄)、出现帧数、消失帧数、出现时间、消失时间、持续时间。

图3 研究自主开发的VRTracker 视频分析软件分析界面
研究将输出的两个.csv 格式的原始数据导入SPSS26 软件进行数据处理和分析。研究从视觉注意的广度和稳定性两方面表征学生IVR 学习中的信息加工投入,包含学习内容视觉覆盖度和学习内容关注时长两个关键指标;从身体交互频率和交互时长两方面表征学生IVR 学习中的具身认知投入,包含手柄交互的次数和手柄交互累计时长两个关键指标。通过对学习内容视觉覆盖度、学习内容关注时长、交互频次、交互累计时长四个自变量与知识保留、知识迁移两个结果变量进行相关性分析,验证本研究所选关键指标对IVR 学习中学生认知投入表征的有效性。
四、研究发现
(一)检测模型准确率分析
研究采用基于Yolov5 模型的目标检测方法,基于CRNN 模型的文本OCR 检测方法,以及过滤算法自动识别学生在IVR 学习中的认知投入。通过对系统自动识别的对象目标(标识知识点的文本、标识交互的手柄) 与人工识别对象目标(标识知识点的文本、标识交互的手柄)的比较来检测研究自主开发的自动分析系统结果的准确率。图4(左)展示了单个教学视频中学习目标和手柄交互的真实出现总帧数(深色)和检测出的出现总帧数(淡色),可以看出本系统对视频中关键目标的检测精确度较高(准确率为98.7%)。图4(右)展示了人工标注的IVR 教学视频中五个最常出现的学习目标的总帧数与通过本系统检测出的学习目标的总帧数的对比结果,对比发现本检测系统的检测准确性达到98%以上。
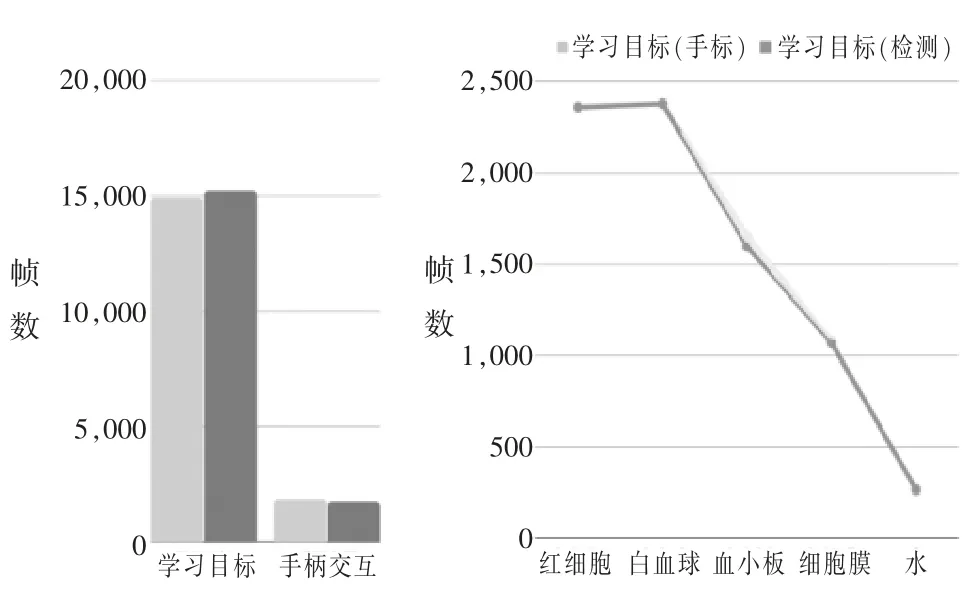
图4 模型检测准确率分析结果
上述研究发现表明,基于计算机视觉技术自动识别学生在IVR 学习中的视觉行为和身体交互行为是一种可行且有效的方法。研究采用的基于Yolov5 模型的目标检测方法,基于CRNN 模型的文本OCR 检测方法,以及相应的过滤算法能够有效识别IVR 学习中的特定对象目标和手柄交互目标。
(二)认知投入指标与知识保留、知识迁移的相关性分析
由于样本量较小,样本数据不服从正态分布,研究采用Spearman 相关分析,结果如表1 所示。
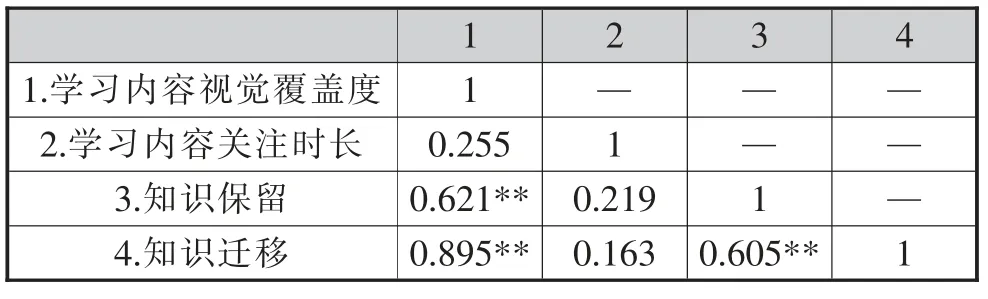
表1 视觉行为与知识保留、知识迁移的相关性分析(N=35)
由表1 可知,学习内容视觉覆盖度与学生的知识保留成绩在0.01 水平上显著相关,与知识迁移成绩在0.01 水平上显著相关。而学习内容关注时长与学生的知识保留成绩和知识迁移成绩并不存在显著相关性。这说明,在IVR 学习中学生是否注意到重要的学习内容会影响其最后的知识保留和知识迁移成绩,但对学习内容的关注时长并不会影响其在知识保留和知识迁移中的表现。
交互频次、交互累计时长与知识保留、知识迁移的Spearman 相关分析结果如表2 所示。
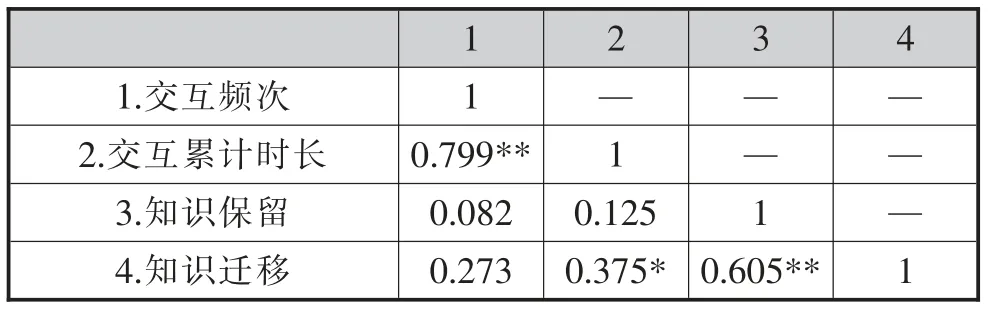
表2 交互行为与知识保留、知识迁移的相关性分析(N=35)
由表2 可知,学生在IVR 学习中的交互频次和交互累计时长在0.05 水平上显著相关,但交互频次与知识保留和知识迁移均无显著相关性;交互累计时长与其知识迁移成绩在0.05 水平上显著相关,而与知识保留成绩无显著相关性。以上分析结果说明,学生在IVR 环境中的交互频次不会影响其在后续的知识保留和知识迁移中的表现,而交互累计时长会影响其在后续的知识迁移中的表现。
五、研究结论及启示
首先,基于计算机视觉技术自动识别学生在IVR环境中的视觉和交互行为是一种可行且有效的方法。检测模型准确率分析显示,基于深度学习技术中的Yolov5 模型,结合基于CRNN 模型的文本OCR 检测方法和相关过滤算法能够有效检测和识别学生在IVR 学习中的视觉行为和交互行为。检测准确率分析结果说明了该技术路线在自动识别IVR 学习认知投入方面的可行性。这一研究发现与艾伯特等(Albert,et al.,2022)与王泽杰等(2022)的研究结果一致,同时也进一步证明了Yolo 模型在IVR 环境中对不同目标对象(如学习目标对象、手柄交互对象)检测的有效性。上述研究发现为IVR 环境中认知投入的自动测评提供了重要依据。在理论研究层面,综合信息加工理论和具身认知理论,运用计算机视觉技术从视觉行为和身体行为两方面共同表征IVR 环境中学生的认知投入是未来值得深入探索的重要方向。在实践应用层面,无法实时追踪和有效监测学生在IVR 学习中的认知投入使得教师的及时支持和反馈无据可循,最终导致IVR 教学的常态化开展面临重重阻力。本研究提出的技术路线使得IVR 教学实践中基于数据驱动的教师的及时支持和个性化反馈成为可能。同时也将计算机视觉技术在教育领域的应用由在线学习、课堂学习等场景拓展到IVR 学习场景。
其次,IVR 环境中学生对学习内容的视觉覆盖度与其知识保留、知识迁移显著正相关。研究发现,学习内容视觉覆盖度与知识保留和知识迁移显著正相关。这一研究发现与杜博维(Dubovi,et al.,2022)的研究发现基本一致,即IVR 学习中学习者对无关信息的视觉注视越少,其最后的学业成就表现越好。不同于传统的多媒体学习,IVR 的高沉浸性和强交互性特征很容易引发学生在学习过程中的注意力分散,导致其错过一些重要的学习内容(张慕华,等,2022)。因此,IVR 环境中学生的注意力水平显得尤为重要。认知心理学认为,注意是学习的重要条件(张淑华,2007)。如果学生在IVR 学习中错过一些重要的学习内容,那么其在后续相关内容的知识保留(即记忆)和知识迁移方面的表现就会不佳(Makransky,et al.,2019b;Parong,et al.,2018)。然而注意并不等于记忆,根据多媒体学习认知理论(Mayer,2005),学生只有将进入工作记忆中的信息与先前知识进行有机整合才能将其存储在长时记忆系统中。除了是否注意到重要学习内容外,学生的已有知识储备、理解能力等因素也会影响到其最终的知识保留和知识迁移表现(Dubovi,et al.,2022;李文昊,等,2023)。这也解释了为什么学习内容关注时长指标与学生的知识保留和知识迁移表现并不存在显著相关性。上述研究发现为IVR 学习资源的设计提供了重要启示。一方面,研究者在设计IVR 学习资源时,可以采用特定的方式(如文字)标识关键信息,这样不仅有助于吸引学习者对关键信息的注意力以实现信息加工,也有助于采用计算机视觉技术自动识别学生学习过程中的视觉行为,从而实现对认知投入的追踪和测评。另一方面,基于认知投入的追踪和测评结果能够为IVR 学习资源设计的迭代优化提供有力的数据支撑,从而形成“设计-学习-测评-优化设计” 的闭环。
其三,IVR 学习中学生的交互累计时长与知识迁移显著正相关。研究发现,交互累计时长与知识迁移显著正相关。这与刘哲雨等(2017)的研究不谋而合,即虚拟现实环境中学生的交互行为投入能够显著提升深度学习效果中的内部关联迁移和外部拓展迁移。交互行为投入一方面能够不断强化学习者在IVR 环境中的视觉注意(即将注意力集中在操纵对象上)和深层次信息加工,从而促进其在知识迁移中的表现(胡艺龄,等,2021)。另一方面,学生在IVR环境中交互行为投入有助于促进其在学习过程中的临场感体验和积极情感体验(如自我效能感、享乐感等),从而有助于促进学习迁移的发生(高楠,等,2023;张慕华,等,2022)。教育的最终目标是促进学习迁移,IVR 在促进学习迁移方面的潜能已被越来越多的研究证实(高楠,等,2023;胡艺龄,等,2021;刘革平,等,2021;Makransky,et al.,2019a)。在IVR学习中,学生对虚拟对象的抓取、旋转等交互操作为体验式学习、情境化学习和做中学提供了机会。IVR环境的高保真性和高交互性特征为学生从知识习得到知识迁移创造了绝佳环境,有助于促进学生获得具身体验,从而有助于学习迁移的发生(Di Natale,et al.,2020)。根据多媒体学习认知情感整合模型(Cognitive-Affective Theory of Multimedia Learning,CATML),IVR 环境的交互性可以通过激发学习过程中的临场感(Presence)和能动性(Agency),进一步促进学生的具身认知,最终促进学习迁移的发生(Makransky,et al.,2021)。上述研究发现为学术界深入探索学习迁移的发生机制提供了重要启示。作为一种高度可控的人造环境,IVR 为探索学生的交互行为和学习迁移的关系提供了绝佳的实验场。通过计算机视觉和深度学习技术检测和自动识别IVR 环境中的交互行为,在此基础上进一步探索交互行为与学习迁移之间的复杂关系,有望从人与环境的交互层面揭示学习迁移的发生机制。
六、总结与展望
研究基于信息加工理论和具身认知理论,从视觉行为和身体交互行为两方面间接表征学生在IVR环境中的认知投入,探索了基于计算机视觉技术和深度学习技术的IVR 学习认知投入自动测评方法。模型检测准确率分析发现,基于计算机视觉技术和深度学习技术自动识别学生在IVR 学习中的视觉行为和身体交互行为是一种可行且有效的方法。相关性分析发现,学生在IVR 学习中对学习内容的视觉覆盖度与其后续的知识保留和知识迁移成绩显著正相关;学生在IVR 学习中使用手柄交互的累计时长与其后续的知识迁移成绩显著正相关。上述研究发现证明了基于计算机视觉技术和深度学习技术的IVR 学习认知投入自动测评技术路线的可行性,同时也为IVR 学习资源设计实现“设计-学习-测评-优化设计” 这一闭环提供了可能,为从人与环境的交互层面深入探索学习迁移的发生机制提供了重要思路。然而,由于样本量的限制,研究只分析了视觉行为和交互行为的观测指标与知识保留、知识迁移的相关性。未来的研究需要扩充样本量,进一步利用回归分析探索视觉覆盖度、交互累计时长等观测指标对学习成绩的预测作用,以此来判断其对认知投入的表征效果。由于实验材料的限制,研究对视觉行为的表征只考察了注意的广度和稳定性两项指标,未来的研究可以选择其他类型的学习材料,考查学生在IVR 环境中的注意分配和注意转移行为,探索对这两种行为的自动检测和识别的技术路线,以完善IVR 环境中认知投入的视觉行为表征方法。此外,研究对身体交互行为的分析仅考察了手柄交互的频次和交互累计时长两项指标,未来的研究需要使用强交互的学习材料(如实验操作类),探索对IVR 环境中抓取、旋转等更细粒度的身体交互行为的检测和自动识别方法,以进一步揭示身体交互行为与认知投入、学习迁移的复杂关系。
