基于ChatGPT 的研究生人机协同学术写作实践研究及启示
2023-10-23李艳金皓月杨玉辉
□李艳 金皓月 杨玉辉
一、研究背景
以ChatGPT 为代表的生成式人工智能为人机协同学术写作带来了巨大的机遇与挑战。生成式人工智能不仅能够清晰理解用户的提问并在此基础上进行回应,而且还能生成文本、撰写摘要及翻译文字等。有研究发现甚至连专家评审都只能识别63%由ChatGPT 生成的摘要(Gao,et al.,2023)。《自然》杂志对他们的读者做了一项关于在科研中使用ChatGPT的调研,发现受访者分别使用该工具进行头脑风暴、撰写研究初稿或进行文献综述等,这些受访者认为ChatGPT 可以帮助他们完成无聊、繁重或重复的任务,但同时也带来学术造假、学术不端等问题(Owens,2023)。金皓月等(2023)通过对国内智能写作技术的发展与运用情况进行综述后发现,一些高校学生开始借助智能写作平台,帮助自身提高写作能力,但这类技术也存在引发学术不端的风险。因此,需要对这类工具潜在的用途、局限性和伦理风险展开全面的研究。然而,当前关于ChatGPT 对学术写作影响的争论主要来自研究经验丰富的教育者和研究人员,相对而言缺少来自学生的声音,特别是缺少学生人机协同学术写作的实证研究。鉴于此,本研究将通过案例比较,探究不同学术训练背景的研究生与ChatGPT 人机协同学术写作的异同,旨在帮助教育者深入了解ChatGPT 在人机协同学术写作中的潜在价值及伦理风险,并基于此更好地制定相关政策,同时也为未来人机协同学术写作发展提供建议。
二、文献综述与问题提出
培养研究生良好的学术写作能力是衡量高校人才培养质量的重要指标(教育部,等,2020)。研究生只有经过系统的训练,才能具备用抽象的学术话语来表达学术研究过程与成果的能力(朱旭东,等,2022)。然而,由于时间和精力有限,教师无法对每个学生进行有效的指导(陈文祥,2015),不少学生因为缺少前期学术积淀和对学术论文写作的正确认知,常常陷入不知如何入手的迷惘(梁晨,等,2022)。缺少规范的学术训练,研究生学术论文会出现各种问题。例如,常思亮等(2019)为了解 “差评” 论文的问题,选取S 大学2017 届411 份 “差评” 研究生学位论文盲审专家的评阅意见,通过编码法和词频统计法,发现这些论文主要存在研究主题不明确、逻辑结构混乱、论证方法不当、结论不实与建议泛化、写作不规范、写作态度不端正、创新性缺乏等七个问题。
已有研究认为ChatGPT 为学术写作发展带来了新的机遇。杨九诠指出,ChatGPT 的应用潜力可能颠覆传统的科学研究方式,如改变科学研究知识获取、科学研究实验设计规划、科学研究成果撰写等模式(邱燕楠,等,2023)。一些研究对ChatGPT 在学术研究中的辅助价值进行探索,无论是对经过同行评议的相关文献的综述(Dergaa,et al.,2023),或是通过对发表的文献、网站、博客等相关自媒体的内容述评(Rahman,et al.,2023),还是对ChatGPT 功能的详细测评(王树义,等,2023),均发现ChatGPT 在学术写作中有一定的应用潜力,具体包括文献概括与提炼、概念解释与对比、转化或改写语言文字表达等功能。为了验证生成式人工智能的科研论文写作能力,以色列两位科学家在ChatGPT 的帮助下,不到一小时便完成了一篇研究论文,研究发现ChatGPT 不仅可以处理原始数据,而且能撰写初稿并进行润色,生成的文章流畅且规范(Conroy,2023)。同样,《科学》刊发的一项探究ChatGPT 等生成式人工智能对写作影响的研究招募了453 名受过大学教育的各行各业人员,并要求参与者与ChatGPT 协同撰写他们实际工作中的任务。在参与者完成最初任务后,被随机分成实验组和对照组,实验组要求注册ChatGPT,允许他们使用该工具来完成第二个任务,对照组则相反。通过用时统计发现,实验组完成第二项任务要快得多,平均用时16 分钟,而对照组平均用时27 分钟。该研究让三位经验丰富的专业人员对生成的文本质量进行1~7 分的评分,发现使用ChatGPT 的小组比没有使用ChatGPT 的小组分数高18%。此外,在第一项中任务得分较低的参与者,在ChatGPT 的帮助下得分提高1~2 分,而那些最初获得高分的人在使用ChatGPT 的情况下依然保持了高分。这表明ChatGPT 对那些写作技能相对较弱的人特别有帮助,可以将他们的写作水平提升到接近熟练人士的写作水平(Noy,et al.,2023)。
ChatGPT 在写作中的辅助价值让人机协同写作成为未来写作一种可能的趋势。人机协同是人类与智能代理相互协同实现目标的过程,两者协同期间不断进行双向信息交流,实现人类与智能代理的互相适应与相互学习(武法提,等,2023),该过程包括信息输入、信息加工、信息输出和内外反馈四个方面(何文涛,等,2023)。目前,有个别学者已经开展了学生和GPT 系列协同学术写作的实证研究。例如,美国学者费夫(Fyfe,2022)研究大学生对人机协同学术写作的态度与看法,邀请20 名来自不同年级、不同专业的学生使用GPT-2 来完成“数据与人类”(Data and the Human)课程的期末论文,要求学生在论文中标注哪些部分是自己创作的、哪些部分是由系统生成的,并在此基础上写一篇有关此次人机协同写作的反思。该研究发现,87%的学生认为人机协同学术写作比自己单独写作复杂得多,“是否或如何在论文中使用这些材料” 让写作变成了一件更复杂、需更多投入的工作。GPT-2 的优点包括提供一些新观点、帮助形成新想法、学习人类的语言表达风格,但不足之处在于编造看似合理的虚假信息,这就要求学生花更多的时间对信息进行辨别。学生在人机协同学术写作中的角色更像“编辑、策展人或调解人”。克罗地亚学者贝塞客等(Basic,et al.,2023)采用实验法,研究大学生有无使用ChatGPT 对论文写作质量的影响。其中,9 名学生为对照组,另外9 名学生为使用ChatGPT 的实验组,研究要求学生用克罗地亚语完成一篇论文,最后对论文进行打分,并比较了两组论文在分数、写作时长、文章真实性和内容相似性等维度的差异。该研究发现没有证据表明使用ChatGPT 可以提高论文质量,对照组在大多数维度上优于实验组,实验组并没有表现得更好,没有提供更高质量的内容,没有写得更快,也没有呈现更真实的文本。研究者认为由于该研究采用克罗地亚语,且受限于样本量,因此不能排除ChatGPT 在其他语言中的科研辅助价值。
目前,有关人机协同学术写作的实证研究刚处于起步阶段。ChatGPT 存在的虚假信息、学术语言表达问题、阻碍思维发展等问题也引发了学者的关注。有的学者认为ChatGPT 生成的虚假信息可能会扭曲科学事实并散播错误信息。例如,有研究通过让ChatGPT 综述一篇文献,发现其编造了一个令人信服的摘要,但存在事实错误、虚假陈述和错误数据等问题,更关键的是该摘要夸大了研究的有效性(Van Dis,et al.,2023)。由于鉴别虚假信息需要一定的能力,有学者(Han,et al.,2023)建议学识不足的学生群体不要太早拥抱ChatGPT。有的学者认为ChatGPT存在学术语言表达方面的问题。例如,有研究(Guo,et al.,2022)将多个领域中的ChatGPT 回答与人类专家的回答进行比较,发现ChatGPT 更喜欢使用长句子,运用的词汇量没有人类学者丰富,而且重复使用训练文本中的常见模式和句法结构。令小雄等(2023)对ChatGPT 的学术写作能力进行特征分析与描述,发现生成的内容虽然逻辑框架稳固有效,论证清晰充分,但缺乏应有的思想深度,论证语言单薄,说理手段较为单一。也有学者认为ChatGPT 可能会阻碍学生思维的发展。如艾斯(Else,2023) 指出,ChatGPT 模型是根据过去信息进行的训练,然而科学知识生产需要创新思维而非守旧陈因,过多地使用这类工具可能导致学生批判性思维和创新能力的匮乏。徐辉富认为学生可能加大对ChatGPT 的依赖,学术写作变得容易,但写作的洞见性和智慧却愈少(邱燕楠,等,2023)。由此引发的学术不端现象更是令学者们担忧(Owens,2023)。
综上,已有研究表明,ChatGPT 给学术写作带来了诸多机遇和挑战,为数不多的实证研究主要关注人机协同写作效果,鲜有研究探究人机协同的过程及影响因素。在高校研究生写作领域,已有研究显示研究生的学术写作需要以坚实的学科专业知识为基础(王立珍,等,2012),此外,有过学术论文训练与论文发表经历的研究生在发现问题、开展研究及撰写论文等方面有更好的表现(高文娟,等,2022)。鉴于此,本研究拟探究不同学术训练背景的研究生与ChatGPT 人机协同学术写作过程和效果的差异,通过案例比较,深入了解ChatGPT 在人机协同学术写作中的潜在价值及伦理风险。具体包括三个问题:
(1)不同学术训练背景的研究生在人机协同学术写作过程中的行为有何差异?
(2)与不同学术训练背景的研究生协同学术写作,ChatGPT 扮演的角色有无差异?
(3)不同学术训练背景的研究生如何看待和评价人机协同学术写作?
三、研究设计
(一)研究对象
本研究采用多案例比较的研究方法,这是一种证明因果推断和揭示因果机制的重要研究方法(Eisenhardy,1991)。我们于2023 年1 月初在网络上招募参与者,共有13 名研究生报名,按照 “最相似案例” 的选择方法(Gerring,2008)进行筛选,最终邀请到4 位研究生,按照参与顺序编号为A、B、C、D。他们分别来自化工专业和食品科学工程专业,且均为首次和ChatGPT 协同学术写作。4 位参与者的人机协同论文选题均是他们目前正在开展的研究选题,其中,A 和C 两位同学为研一学生,研究尚处于摸索阶段,并不熟悉选题;B 同学的选题与他本科毕业论文相关,D 同学的选题与她博士论文相关,他们对选题较为熟悉。同时,A 和D 两位同学有论文发表经历,A 同学发表的这篇论文和本次选题无关,D 同学发表的五篇论文均和本次选题有关,而B 和C 同学没有论文发表经历。
由参与者自行决定具体的人机协同学术写作方式及结束时间,研究者并未进行事先规划。此外,为了更好地了解研究生对人机协同学术写作的态度与看法,研究者在余下的9 名学生中邀请到4 位观察者,他们的主要任务是对4 位同学的人机协同学术写作进行全程观察,并在观察中记录自己的感想(见表1)。

表1 四个案例的概况
为更好地记录参与者和ChatGPT 协同学术写作的过程,每个案例均由一位参与者通过腾讯会议分享屏幕和 “出声思考”(Think Aloud)的方式呈现人机协同的过程。该过程主要包括:(1)参与者输入指令;(2)ChatGPT 依据指令生成相应内容;(3)参与者另起话题或针对生成的内容再次输入指令,直到生成参与者满意的内容为止(见表2)。出声思考是参与者在人机协同学术写作过程中的所思所想,这一方法不仅让研究者有机会了解参与者在人机协同中的想法,同时还能对参与者思考的内容、过程及结果进行探究。人机协同学术写作均在中文语境下开展。经研究对象同意,研究者对四个案例的人机协同全过程进行录像,最终获得总时长近11 小时的视频。人机协同学术写作时间为2023 年1 月24 日到1 月31 日。

表2 参与者和ChatGPT 协同学术写作的过程示例
(二)数据收集
本研究的数据包括三个方面:(1) 参与者和ChatGPT 协同过程的数据,包括每个案例的协同时长、对话次数、参与者的提问内容与ChatGPT 生成的文本内容;(2)出声思考数据,包括参与者出声思考的次数及转录后的文字内容;(3)访谈数据,包括4位参与者和4 位观察者的半结构访谈内容(见表3)。面向参与者和观察者的三个主要问题为“你对ChatGPT 有怎样的态度和看法”“你认为ChatGPT 在学术写作中有什么价值或问题” 及 “你对人机协同学术写作有什么看法”。
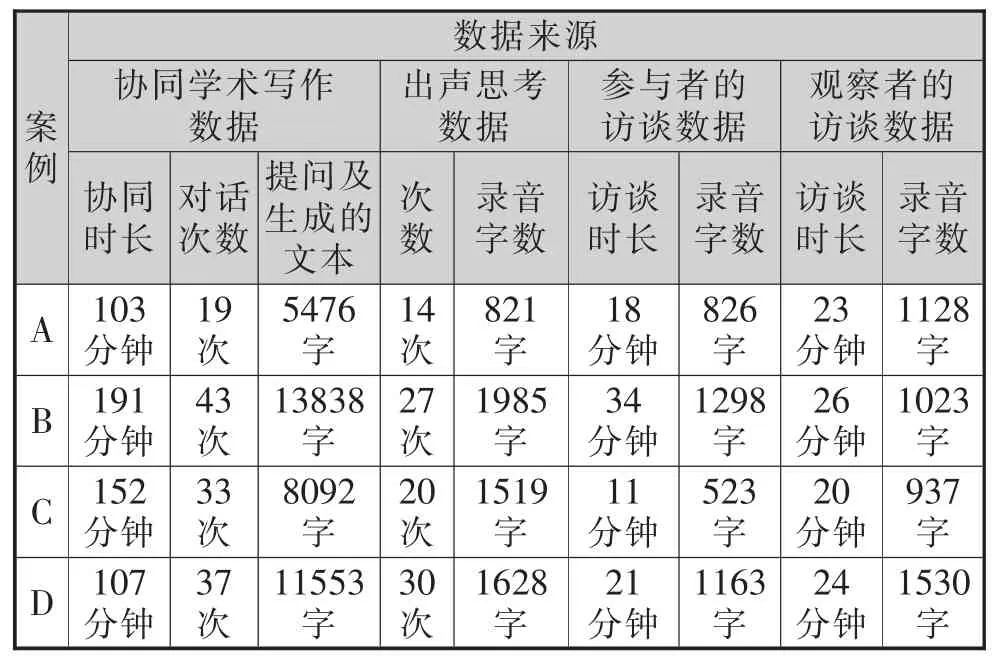
表3 案例数据收集情况
(三)数据分析
为更好地了解不同参与者在人机协同学术写作中 “提问” 的差异,研究者参考丹东尼奥等(Dantonio,2006)的提问结构,该结构由核心提问和各种追问组成,结合 “提问” 数据的实际情况,将分析维度划分为指示、评价、示范、追问和继续五类(见表4)。

表4 人机协同学术写作过程中的 “提问” 及 “出声思考” 特征描述及案例编码结果分布
对参与者的出声思考数据初步分析发现,该数据主要为参与者对ChatGPT 生成内容的评价及协同感受。为更好地了解参与者的评价类型,研究者参考美国心理学家斯滕伯格(Sternberg,2000)关于教师回应学生回答的分类,结合出声思考数据的实际情况,将分析维度划分为认可、疑惑、不认可和其他四类(见表4)。两位研究人员依据表4 对人机协同学术写作过程中的提问数据及出声思考数据进行独立编码,编码的一致性检验结果较好(Kappa 系数大于0.8)。
访谈数据分析采用类属编码法(陈向明,2000),该方法包括初级编码、类目识别和结果呈现三个步骤。研究者先将访谈数据进行初级编码,再在初级编码基础上进行类目编码。通过编码归纳后,总计产生34 条初级编码和 “价值判断、所需知识技能、问题风险感知” 三个要素类目(见表5)。
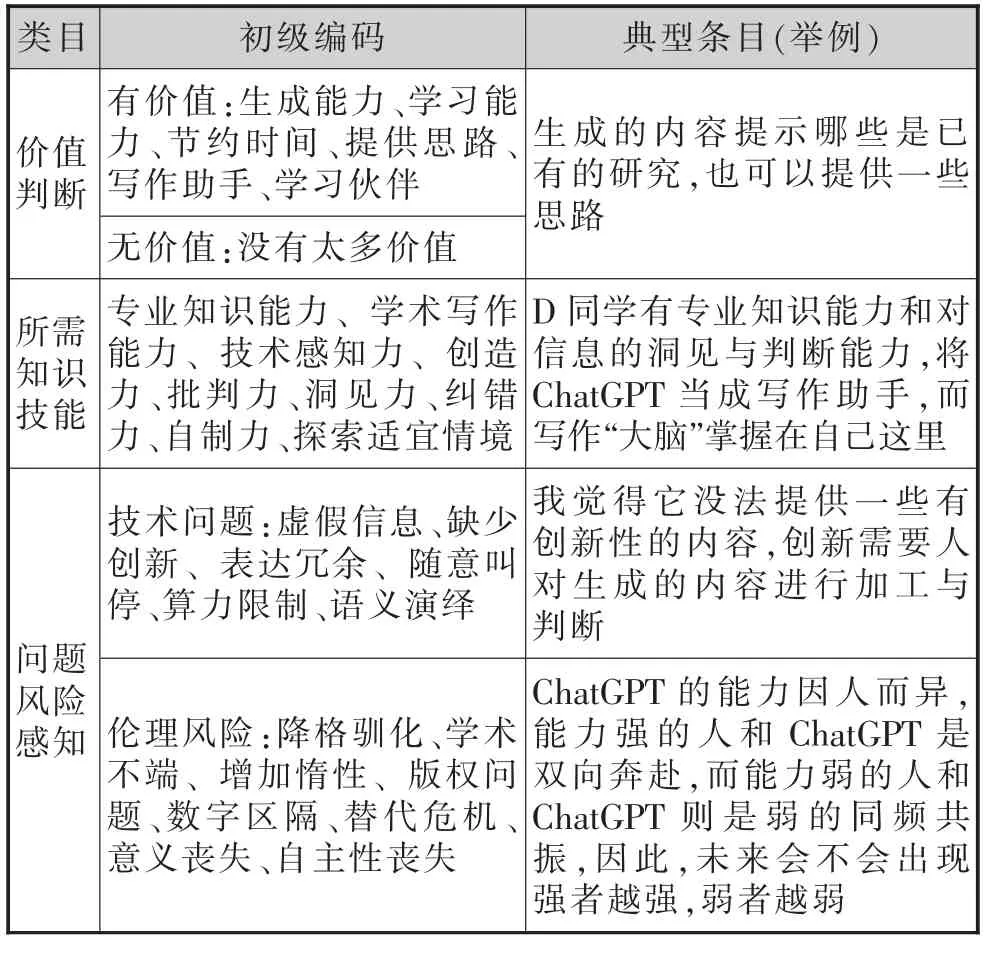
表5 访谈数据类目、初级编码与典型条目
四、研究结果
在人机协同学术写作过程中,四位同学不仅提问和出声思考的频次有所不同(见图1),而且叫停人机协同的原因各异。其中,A、B 和C 三位同学系主动叫停,A 同学叫停的原因在于ChatGPT 提供了太多 “不确定且胡说八道” 的信息,B 同学在完成计划内容后结束人机协同,C 同学由于ChatGPT 生成的内容 “实在离预期太远” 而终止人机协同。与这三位同学不同的是,D 同学由于提问次数太多被迫终止,ChatGPT 显示 “Too many requests in 1 hour.Try again later”(1 小时内请求次数过多,请稍后再试)。

图1 四个案例中的 “提问” 及 “出声思考” 频次
(一)不同学术训练背景的研究生在人机协同学术写作过程中的行为分析
针对问题一“不同学术训练背景的研究生在人机协同学术写作过程中的行为有何差异”,对四个案例中的 “提问” 及 “出声思考” 数据比较发现,研究生对选题的熟悉程度影响其和ChatGPT 的协同方式,具体包括提问具体程度、反馈次数、协同收获、协同感受及人机平均交互用时五个方面(见表6)。其中,“提问具体程度” 指参与者的提问中是否包含明确清晰的任务说明,以及是否用多个提示词(专业名词)对任务范围进行限制等。此外,研究生的发表经历影响其对ChatGPT 语言表达的评价、对生成内容的文字加工及思路整合等(见表7)。其中,有发表经历的A 同学和无发表经历的C 同学由于对选题不够熟悉,因此他们将关注点更多地落在生成文本的内容方面,对ChatGPT 的语言表达关注度并不高。

表6 研究生是否熟悉选题对其人机协同学术写作的影响

表7 研究生有无发表经历对其人机协同学术写作的影响
第一,在提问具体程度方面,不熟悉选题的A 和C 同学提问不具体,而熟悉选题的B 和D 同学提问较为具体。对 “指示” 这一提问数据分析发现,不熟悉选题的A 同学15 个 “指示” 中只包含了4 个专业名词,不熟悉选题的C 同学28 个 “指示” 中包含了8 个专业名词。这两位同学的提问中包含的专业名词较少,且提问方式大多为 “专业名词+论文组成部分(如绪论)”。针对这样的提问,ChatGPT 尽管能够生成相应的内容,但主要是基于语言模型进行的内容演绎,生成的内容比较宽泛与笼统。相较而言,熟悉选题的B 同学25 个 “指示” 中包含18 个专业名词,熟悉选题的D 同学17 个 “指示” 中包含29 个专业名词。这两位同学的提问不仅用较多的专业名词对范围进行限定,而且对任务有清晰且明确的说明。这样的提问方式能够主导ChatGPT 生成让他们满意的内容。这表明参与者对论文选题的熟悉程度影响其提问具体程度,从而影响人机协同学术写作过程中ChatGPT生成内容的质量。
第二,在反馈次数方面,不熟悉选题的A 和C同学对ChatGPT 生成的内容反馈次数较少,而熟悉选题的B 和D 同学反馈次数较多。其中,不熟悉选题的A 同学针对ChatGPT 的15 次生成只进行了1次 “追问”,不熟悉选题的C 同学针对ChatGPT 的28次生成进行了4 次 “评价” 和1 次 “追问”。结合两位同学的 “出声思考” 数据分析发现,两位同学尽管对ChatGPT 生成的内容有所判断,但知识的欠缺让他们只能采用“我觉得你这个说得不对”“这句话我不能理解,讲得俗一点” 的提问方式。面对这类提问方式,ChatGPT 生成的内容 “答非所问”。相较而言,熟悉选题的B 同学针对ChatGPT 的25 次生成进行了7 次 “评价” 和1 次 “追问”,熟悉选题的D 同学针对ChatGPT 的17 次生成进行了13 次 “评价”、3 次 “追问” 和4 次 “示范”,且反馈次数是四个案例中最多的。这两位熟悉选题的同学均能提供正确的知识让ChatGPT 对虚假信息进行修正。此外,D 同学还提供写作表达的范例供ChatGPT 学习。这表明参与者对论文选题的熟悉程度影响其能否对ChatGPT 生成的内容进行高质量的反馈,并通过高质量的反馈提升ChatGPT 生成内容的质量。
第三,在协同收获方面,不熟悉选题的A 和C同学在此次人机协同中收效甚微,相反,熟悉选题的B 和D 同学颇有收获。由于知识受限,不熟悉选题的A 和C 同学有时无法理解ChatGPT 生成的内容,更无法在此基础上产生 “化学反应”。相较而言,熟悉选题的B 和D 同学能够利用已有知识和Chat-GPT 生成的内容进行对话。比如,熟悉选题的B 同学在人机协同中得到了一些思路启发;熟悉选题的D同学认为ChatGPT 具有 “点灯” 的作用,能将她的静默知识点亮,“这个方法我在文献中看到过,但我没有把它考虑到这个实验中”。此外,D 同学还就人机分歧的内容对ChatGPT 进行追问,人和机在高质量的探讨中周延了研究的设计逻辑。由上述可知,参与者对论文选题的熟悉程度影响其能否在ChatGPT生成内容的基础上形成新的认知,从而影响参与者的协同收获。
第四,在协同感受方面,不熟悉选题的A 和C同学感到失望和沮丧,熟悉选题的B 同学感到累和超负荷,熟悉选题的D 同学感到轻松和愉悦。具体而言,不熟悉选题的A 同学对ChatGPT 提供的虚假信息感到失望,同时也对自己缺少知识进行纠错而气馁。不熟悉选题的C 同学在参与人机协同前满怀期待(我感觉要多一个导师了),但到人机协同时频频叹息(12 次),变得异常沮丧。熟悉选题的B 同学由于与ChatGPT 交互措辞带来的负担而感到“累和超负荷”,“这种交互很累,跟哄孩子一样,表达得不够清楚它就不会明白”,并表示这场交互 “不亚于高考”。与这些同学相比,熟悉选题的D 同学是4 位同学中最轻松的,人机协同过程非常愉悦,共出现14次笑声。这表明参与者对论文选题的熟悉度影响其人机协同学术写作的轻松程度。此外,与ChatGPT 语言交流的方式也会影响参与者的协同感受。
第五,在平均交互用时方面,不熟悉选题的A 和C 同学平均每次交互用时较长,而熟悉选题的D 同学平均每次交互用时较短。B 同学尽管也熟悉选题,但由于自身语言表达的问题,在提问措辞构思方面花费较多时间,导致平均每次交互用时也较长(见表6)。进一步分析发现,信息判断和提问构思是造成平均交互用时长短差异的主要原因。这表明参与者对论文选题的熟悉程度影响其信息判断和提问构思的用时。另外,参与者自身的语言表达能力也会影响人机协同学术写作过程中的平均每次交互用时。
第六,在对ChatGPT 语言表达的评价方面,有发表经历的A 和D 同学均认为ChatGPT 生成的内容较为啰嗦冗余,而没有发表经历的B 同学对生成内容的评价较高。其中,有发表经历的A 同学认为生成的文字比较啰嗦。相比A 同学,有发表经历的D同学对ChatGPT 语言表达的评价更加深入与具体。D 同学以期刊发表要求为标准,认为生成的内容尽管符合学术语言规范,但存在一些废话和重复性的内容,没有体现句子间的重点,更缺乏学术表达的洞见力。相较而言,没有发表经历的B 同学以自己的写作水平作为评价标准,认为ChatGPT 生成的内容质量较高,7 次出现“写得比我好”“写得比本科生好”等评价。除此之外,B 同学还认为ChatGPT 的论证逻辑能够带给他一些启发,可以帮助他减少语言构思的时间。这表明没有发表经历的B 同学对ChatGPT的语言问题缺少感知,而在语言表达逻辑方面却能得到一些启发。
第七,在对生成内容的文字加工方面,没有发表经历的B 同学采用 “扩写” 的方式,而有发表经历的D 同学采用 “示范” 的方式。具体而言,没有发表经历的B 同学43 次提问中10 次为“请对……内容进行扩写” 的指令,而没有对生成的文字进行加工与处理。对于他和ChatGPT 最终协同完成的论文,虽然通篇没有语病,但是B 同学自己认为水准不够,达不到本科生的水平,“仅仅只是像一篇论文而已”。有发表经历的D 同学对生成的内容进行改写,并提供自己的写作范例让ChatGPT 学习,人机协同生成的内容重点就相对突出,语言也较为凝练。这表明D 同学用自己的写作能力弥补了ChatGPT 的语言表达问题。
第八,在对生成内容的思路整合方面,没有发表经历的B 同学没有对ChatGPT 生成的思路进行整合,而有发表经历的D 同学进行了整合。没有发表经历的B 同学之所以不对生成的思路进行整合,一是他较为认可ChatGPT 生成的写作思路,“这个思路也可以吧”;二是出于惰性与省力,他认为 “如果要调整的话,要做大修改,还是算了吧”。相较而言,有发表经历的D 同学以自己的思路为主,因为她认为ChatGPT 生成的思路缺少创新性,有些篇幅安排不合理、重点不突出,“如果不进行加工与整合,这思路也没法用”。这表明有发表经历的D 同学能够识别ChatGPT 生成思路的问题并进行加工。此外,Chat-GPT 有增加没有发表经历的B 同学惰性的风险。
(二)ChatGPT 在与不同学术训练背景的研究生协同学术写作中呈现的角色差异
针对问题二“与不同学术训练背景的研究生协同学术写作,ChatGPT 扮演的角色有无差异”,对案例进行比较分析发现,受到参与者的不同学术训练背景的影响,ChatGPT 在四个案例中呈现的角色有所不同,总体特点是 “遇强则强,遇弱则弱”(见图2)。

图2 ChatGPT 与不同背景的研究生协同学术写作过程中所扮演的角色差异
ChatGPT 在与不熟悉选题但有发表经历的A 同学协同学术写作过程中,A 同学由于自身的知识储备不足导致提问不具体,也无法对生成的虚假信息予以纠正,外加ChatGPT 技术本身的问题,生成的内容出现了诸多虚假信息,包括定义错误、提供了虚假文献和虚假术语等。ChatGPT 在此次人机协同学术写作中扮演了 “离谱队友” 的角色。C 同学面临着和A同学一样的困境,外加多次采用 “你好好想想” 的提问方式,最终ChatGPT 生成的29 次内容中只有两次不包含虚假信息,始终处在 “胡说八道” 的状态,无法提供实验创新设计。ChatGPT 在此次人机协同学术写作中扮演了 “笨蛋学伴” 的角色。在这两个案例中,ChatGPT 的表现与参与者的期待完全不同,两位同学希望其能够充当 “导师” 的角色,给予必要的指导,结果发现ChatGPT 甚至不是一位可以信赖的伙伴,因此,他们和ChatGPT 再次协同的意愿并不强烈。
ChatGPT 在与熟悉选题但没有发表经历的B 同学协同学术写作过程中,通过B 同学的问题指引,尽管也出现了一些虚假信息,但能够进行修正,故生成的内容质量相对较高。B 同学不仅得到了一些研究与写作思路的启发,而且还发现自己的研究设计创新性不足。ChatGPT 在此次人机协同学术写作中扮演了 “学霸同桌” 的角色。B 同学认为这个同桌 “不仅学识比大部分同学丰富,而且永不疲倦,可以随时向它请教”。ChatGPT 在与熟悉选题且有发表经历的D同学协同学术写作过程中,D 同学具有的专业知识及写作能力让她不仅提问清晰,同时还能识别Chat-GPT 存在的问题并进行“喂养”。生成的内容显示ChatGPT 不仅可以学习D 同学的语言表达风格,承担部分文字工作,而且还能找到D 同学设计逻辑中的漏洞。ChatGPT 在此次人机协同学术写作中扮演了 “高级助理” 的角色。这两位同学均有与ChatGPT再次协同的意愿。与此同时,B 同学指出 “人机协同学术写作需要探索适宜的情境”;D 同学指出“人不能太依赖机器,因为机器会随时限制人的使用”。
(三)不同学术训练背景的研究生对人机协同学术写作的看法和评价
针对问题三“不同学术训练背景的研究生如何看待和评价人机协同学术写作”,在每个案例结束后,研究者对参与者和观察者进行了访谈。对访谈数据分析发现,8 位不同背景的研究生对ChatGPT 应用价值的判断、人机协同学术写作所需的知识技能及对ChatGPT 的风险感知各有不同(如表8 所示)。

表8 参与者和观察者对人机协同写作的评价与看法
首先,熟悉选题的参与者认为ChatGPT 在人机协同学术写作中有一定的应用价值,而不熟悉选题的参与者认为应用价值有限。相比选题熟悉程度,有无发表经历对价值判断的影响不明显。观察者的观点与参与者的观点基本一致。析言之,熟悉选题的B同学认为ChatGPT 可以充当学习伙伴,熟悉选题的D 同学认为可以节约时间。同样,观察者在这两个案例中发现了ChatGPT 的诸多辅助价值,比如提供写作思路、充当学术助手等。相较而言,不熟悉选题的A和C 两位同学均认为ChatGPT 在学术写作中没有明显的应用价值。观察者在这两个案例中的观点与参与者基本一致,稍有不同的是,在A 案例中,观察者首次了解ChatGPT 的生成性能,认为ChatGPT 有充当写作助手的价值,但到了C 案例,由于ChatGPT 不具有创新能力且胡说八道,4 位观察者也认为应用价值甚少。综上所述,参与者和观察者对ChatGPT 在人机协同学术写作中的价值判断,受到ChatGPT 扮演的角色影响,ChatGPT 表现得越好,越能让参与者和观察者看到其价值。此外,参与者和观察者都基于工具的角度对ChatGPT 的价值进行判断。
其次,对于人机协同学术写作所需的知识技能,不同背景的参与者思考的角度有所不同,观察者思考的角度也发生了变化。不熟悉选题或没有发表经历的参与者主要从自身的不足进行反思,而熟悉选题且有发表经历的参与者主要从ChatGPT 在写作中存在的问题进行思考。比如,不熟悉选题的A 和C两位同学强调人需具备一定的专业知识才能和ChatGPT 进行协同学术写作,C 同学还指出人需要具有一定的想法才能进行人机协同写作,这些均是两位同学基于自身问题而进行的思考。而熟悉选题且有发表经历的D 同学则是针对ChatGPT 在内容及文字表达方面的问题,提出人需具有批判、选择、创新等能力。此外,观察者在观察不熟悉选题或没有发表经历的参与者和ChatGPT 协同学术写作案例时,均是站在 “他” 的角度,提出人机协同学术写作所需的知识技能。比如,他们针对B 同学在人机协同中表现出来的惰性,提出人需要具有写作的 “行动力”。而在观察熟悉选题且有发表经历的D 同学和Chat-GPT 协同学术写作案例时,观察者转向 “我” 的角度进行思考。比如,4 位观察者均表示D 同学让他们意识到,关键在于 “我” 需要具有相应的知识与技能,才能让ChatGPT 成为 “我” 的科研助手。他们还认为,D同学在一定程度上消解了他们的忧虑,面对强大的ChatGPT,人的能力能够重塑人的尊严。由上述可知,人机协同学术写作实践不仅有助于提升参与者对ChatGPT 的认识,而且还能帮助他们从自我角度反思人机协同学术写作所需的知识技能。全面观察成功与失败的人机协同学术写作案例,会让观察者的思考视角 “由外向内”,帮助观察者产生提升自我能力的想法。
最后,不熟悉选题或没有发表经历的参与者主要从学生视角感知ChatGPT 对他们的冲击与威胁,包括自主性丧失、替代危机、意义丧失、学术不端、数字区隔及降格驯化等;而熟悉选题且有发表经历的参与者主要从技术角度评价ChatGPT 存在的问题,包括虚假信息、表达冗余、缺乏创新及算力限制等。观察者的观点也包括以上两个角度。例如,有的担心自己的研究地位被ChatGPT 取代,“我觉得导师招收我还不如招收ChatGPT”(观察员E)。又如,有的认为自己的学术写作水平不如ChatGPT,进而否定自身的写作意义。再如,7 位同学(除熟悉选题和有写作发表经历的D 同学外)担心ChatGPT 可能会增加他们的惰性及让他们产生学术不端行为。此外,参与者和观察者的观点也不尽相同,有些观点是参与者通过自己与ChatGPT 协同学术写作实践后发现的,而观察者难以察觉。比如,C 同学感到“自主性丧失”,就是因为在人机协同中他寄希望于ChatGPT 能够生成创新性的内容,导致自己似乎丧失了思考力,而观察者在C 案例中没有发现这个风险。综上可知,能力暂时不足以与ChatGPT 协同学术写作的参与者,担心ChatGPT 对自己的冲击,其中有些风险只有在人机协同学术写作实践后才能察觉;具备与Chat-GPT 协同学术写作能力的参与者,则从ChatGPT 内生性的技术问题出发,思考其对学术写作的影响。
五、结论与讨论
通过比较不同学术训练背景的研究生和Chat-GPT 协同学术写作的案例,本研究得出以下结论:
第一,熟悉选题的参与者在协同学术写作中提问比较具体,能通过判断、追问、示范等提问方式与ChatGPT 进行高质量对话,在人机协同学术写作中不仅有收获,而且相对愉悦,而不熟悉选题的参与者恰好相反。这一定程度上说明,首先,参与者对论文选题越熟悉,越有助于提出清晰与具体的问题,从而ChatGPT 生成的内容质量也越高。这在一定程度上验证了沃尔弗拉姆(Wolfram,2023)的观点,即人类给予的提示越具体与清晰,越可以将ChatGPT 引入到具体的数据集轨迹中,答案的质量也越高。其次,参与者与ChatGPT 进行对话需要以专业知识为基础。熟悉选题的参与者能够很好地评判ChatGPT 生成的内容并进行反馈,而不熟悉选题的参与者不仅不能很好地辨别ChatGPT 生成的虚假信息,同时对生成的肤浅、浮泛的信息缺乏足够感知,这和已有研究(Han,2023)的观点一致。再次,选题熟悉程度影响参与者能否对ChatGPT 生成的内容进行加工并创新。在学术写作中,人机协同学术写作的本质在于人通过评价、示范和追问等提问方式和ChatGPT 进行对话,其中,提问和对话隐含着对判断、加工及创新等能力的考查,而这些能力以知识为基础。此外,ChatGPT 读取的数据库较丰富,所生成的文本内容较为全面,但启发效果受参与者已有专业知识的影响。熟悉选题的参与者具有相应的专业知识,能够和ChatGPT 进行对话并有所收获。由上述可知,和传统学术写作一样,专业知识仍然是人机协同的关键因素,缺少相应的专业知识,学生无法进行具体的提问,无法用已有的知识和ChatGPT 对话,一定程度上也无法形成新的认知。
第二,有学术发表经历的参与者能够鉴别Chat-GPT 生成的内容,能够清晰分辨ChatGPT 语言表达及写作思路的问题,并对生成的文字进行加工与整合,而没有发表经历的参与者对这些问题缺少感知。有发表经历的参与者以学术期刊发表的标准审视ChatGPT 生成的内容,认为其存在语言表达缺少重点、问题分析不深入、论证较为单一、缺少洞见力与深刻性等问题,他们对ChatGPT 语言的感知和已有的研究(Gao,2023;令小熊,等,2023)观点相似。本研究进一步发现没有发表经历的参与者由于缺少写作经验和学术鉴赏力,对ChatGPT 在学术语言表达中存在的问题缺少感知,长此以往,这类学生存在着被ChatGPT 降化为机器类成员的风险。结合ChatGPT生成的内容可以带来语言表达逻辑方面的启发这一观点,对于缺少写作经验的学生而言,可能更适合将自己写作的版本与ChatGPT 生成的版本进行对照,并在比较与对话中提升自己的学术表达能力,这在一定程度上可以弥补传统学术训练中指导不足的问题。但是,本研究发现ChatGPT 存在增加学生惰性的风险,徐辉富指出,有了ChatGPT 等的辅助,学术写作可能越来越容易,但也可能越来越平庸(邱燕楠,等,2023)。因此,怎样发挥ChatGPT 的学习伙伴价值,同时又防止其导致的平庸,就需要思考如何在人机协同学术写作中扬长避短,平衡好两者的关系。
第三,ChatGPT 在人机协同学术写作中扮演的角色受到参与者不同学术训练背景的影响,总体呈现 “遇强则强,遇弱则弱” 的特点。与熟悉选题并有发表经历的研究生协同学术写作,ChatGPT 的表现也越强。这是因为这类参与者能够纠正ChatGPT 生成的虚假信息及肤浅信息,识别ChatGPT 生成内容的空洞与浮泛,并用自己的写作能力弥补机器表达上的缺陷。由此表明,传统写作中的关键因素依然是成功的人机协同学术写作的基础。熟悉选题和有发表经历的D 同学与ChatGPT 的协同学术写作,在一定程度上说明ChatGPT 可以提升科研人员的工作效率,可以承担创新性不强的文字处理任务。这一发现呼应了王树义等(2023)学者的观点。在创造力和思维发展方面,已有观点(Else,2023)认为使用ChatGPT 会妨碍学生批判力和创造力的发展。但本研究发现,熟悉选题且有发表经历的学生能对ChatGPT 生成的内容进行批判性思考并在此基础上创新,因此ChatGPT 不会妨碍这类学生批判力和创造力的发展,相反,能够成为他们的科研助手。而如果学生对ChatGPT 存在的问题缺少感知、对生成的内容缺少批判性思考并将生成的内容奉为圭臬,则有可能变得越来越平庸,并导致创造力和批判力的匮乏。此外,ChatGPT “遇强则强,遇弱则弱” 的特点,在未来的人机协同学术写作时代,可能将进一步拉大学习者之间的差距,造成新的 “数字鸿沟”。
第四,不同学术训练背景的参与者和观察者对ChatGPT 学术写作的价值判断有所不同。不熟悉选题或无发表经历的参与者,往往从自身不足反思人机协同学术写作所需的知识及技能,这类学生也更容易感受到ChatGPT 对他们的冲击与威胁;而熟悉选题和有发表经历的参与者往往审视ChatGPT 的不足,进而思考内生性的技术问题对学术写作的影响。首先,ChatGPT 在与不同学术训练背景的研究生协同写作中表现出来的差异,影响参与者和观察者对ChatGPT 应用价值的判断及人机协同学术写作所需知识技能的思考。不熟悉选题或无发表经历的参与者在人机协同学术写作中,首先看到的是自己的不足,而观察者看到的是ChatGPT 的缺陷;熟悉选题且有发表经历的参与者在人机协同学术写作中,看到的是ChatGPT 的问题,而观察者看到了自己能力的欠缺,从而产生提升研究能力的想法。参与者和观察者视角的倒置,一方面说明 “做” 与 “看” 的区别,另一方面说明学生并非总是以人类中心的视角看待ChatGPT,而是能够从整体视角出发,反思人机协同所需的知识技能,并意识到自己的不足。其次,不熟悉选题或无发表经历的参与者更容易感知到Chat-GPT 对他们的冲击。另外,B 同学提到的 “语言降维”和C 同学提到的 “自主性消失”,均属于参与者独特的 “内视角”,只有在人机协同学术写作的基础上才能发现,而要找到这样的 “内视角”,需要参与者具有一定的反思力,并对ChatGPT 存在的问题保持足够警醒。由上述可知,在关于ChatGPT 对研究生学术写作影响的这场争论中,应鼓励研究生群体在协同学术写作实践中进行自我评估与反思。
六、建议及启示
本研究发现,在人机协同学术写作过程中,ChatGPT 对不同学术训练背景的研究生有着不同的影响,也因此人机协同学术写作的重点在于学生要充分意识到ChatGPT 的局限之处,以及自身学科基础及学术写作能力对于人机协同学术写作质量的重要性。鉴于研究生学科知识的积累以及学术训练需要较长时间的积淀,教育者与其担心ChatGPT 被滥用于研究生学术写作,不如思考怎样在教学设计中融入ChatGPT,通过与学生分享ChatGPT 的优缺点以及人机协同写作的训练来逐步提升研究生的学术写作能力,以防科研能力尚未成熟的研究生被Chat-GPT 降维。基于本研究的发现,尝试提出以下建议:
第一,教师可以让研究生根据写作内容提出不同的问题,并将这些不同的问题提交给ChatGPT 进行回答,组织研究生就ChatGPT 生成的内容进行讨论,比较不同的提问及回答,分析怎样的提问方式会使生成的内容更清晰,以此帮助研究生了解提问对于人机协同的重要性。之后,教师可以引导研究生通过评价、追问、示范等方式进一步和ChatGPT 进行互动,由此引导学生如何人机之间产生高质量的对话。
第二,教师可以使用ChatGPT 就某一主题生成一篇文章,再在课堂上组织研究生对生成的论文进行学习和发表评论。在课堂讨论中,教师引导研究生关注ChatGPT 在语言表达、思路整合中存在的局限性,并就如何改进这些局限鼓励学生给出建议。对生成文章优缺点的评论有助于培养研究生的批判性思维。教师还可组织比较阅读,比较ChatGPT 生成的内容和人类学者所写论文的异同点,并在比较中引导研究生发现机器和人类在语言表达等方面存在的区别,以此提升研究生的学术鉴赏力。
第三,教师可以鼓励研究生开展人机协同学术写作,允许研究生在提交的论文中部分使用ChatGPT 提供的帮助,但需要他们提供人机交互的全部过程,同时也需提交对相关内容的修改说明,鼓励研究生不断对人机交互的结果进行分析,通过添加信息、澄清观点、提供证据、增加分析等方式来完善文章,直到他们认为这是一个可以提交的版本。这一过程有助于研究生了解人在人机协同写作中的价值,只有人类通过适当的反思、批判、选择、加工等过程才能提升人机协同写作文本的质量。同时,教师也需帮助研究生明白人机协同学术写作的价值在于经历写作本身,并通过多次迭代看到论文的变化以及自我写作能力的发展。
第四,教师可以鼓励研究生在人机协同学术写作过程中开展反思和评价等活动,一方面主动思考并评估ChatGPT 生成内容的质量,另一方面学会反思自身的投入和表现。在这一过程中,教师可以为学生提供指导,帮助学生了解ChatGPT 的优缺点,更好地应对ChatGPT 带来的挑战,以防研究经验尚未成熟的研究生被ChatGPT 降维或挫伤研究积极性。同时,教师需开展伦理教育,引导研究生在符合学术伦理的条件下正确且合理地使用ChatGPT,发挥其作为学习伙伴的价值,助力学业学习,而非替代人类写作。
本研究聚焦研究生论文选题熟悉度和发表经历对人机协同学术写作的影响,但本研究的参与者仅为4 名研究生,主要参与者为化工与食品科学领域这两个理科专业学生,学科因素可能影响研究结果。此外,尽管本研究采用 “最相似原则” 对参与者进行选择,但无法控制4 位参与者在其他变量上完全相似,因此可能存在未察觉的因素影响实验结果。后续研究可以在扩大样本量的基础上,通过准实验设计开展人机协同学术写作的相关研究,或提升样本的多样性,开展不同学科人机协同学术写作的实证研究,并在此基础上进行学科间的比较。
总之,人机协同学术写作并非 “另谋新篇”,传统学术写作中的专业知识积淀、学术写作基本功等仍然是人机协同学术写作的关键与基础,而生成式人工智能等只是辅助科学研究的工具与载体。但是,这个工具对使用者的能力提出了要求,而且还带来不可忽视的伦理风险。如果使用得当,这会是一个得力的科研助手;若使用不当,不仅引发学术不端,而且会使学习者忽视自身学术能力的提升,从而导致自身智能的废弛与荒漠化(李政涛,2023)。面对Chat-GPT 等生成式人工智能带来的机遇与挑战,需要高校教学科研部门、教师和学生协同努力,在发挥机器效能的同时防止机器带来的流弊。简言之,即由人类引导机器,而非机器主宰人类。
