逆概率加权构建的边际结构模型在中介效应分析中的应用*
2023-10-18朱钲宏罗家俊
朱钲宏 罗家俊 陈 雯 王 琼△
【提 要】 目的 基于传统回归模型的中介效应分析方法需要混杂因素满足较强的假设,而对于一些复杂情景,如存在受到暴露影响的“中介-结果”混杂因素时,传统的回归方法可能不再适用。本文将介绍该情景下如何通过逆概率加权构建边际结构模型进行中介效应分析。方法 详细介绍存在受到暴露影响的“中介-结果”混杂因素时,传统分析方法的局限性以及通过逆概率加权构建边际结构模型进行替代分析的原理和方法。通过R模拟随机数据集,分别采用传统模型和逆概率加权构建边际结构模型进行中介效应分析,并比较不同方法的评估结果。结果 存在受暴露影响的“中介-结果”混杂时,传统模型效应的估计存在偏差。通过计算逆概率权重构建边际结构模型进行中介效应分析,所估计的总效应、直接效应、间接效应与模拟的真实效应具有较好的一致性。结论 存在受暴露影响的“中介-结果”混杂的情况下,可以利用边际结构模型有效地分析中介效应。
中介效应分析是探究风险因素和结局之间因果关系的重要方法之一[1],最初主要应用于心理学领域,成为许多经典和创新理论的基础。过去十年间,中介效应分析在公共卫生领域也得到了广泛的应用[2]。例如在流行病学研究中,研究者可以通过中介效应分析,评估危险因素和结局的总关联中不同生物通路的贡献,从而阐明危险因素影响健康的生物学机制[3]。近年来,随着中介效应分析在多个领域的广泛应用,其理论和方法也逐步得到发展和完善。本文将首先简要介绍传统的中介效应分析,进一步介绍当存在受到暴露影响的“中介-结果”混杂因素时,传统的中介效应分析的局限,以及如何采用逆概率加权构建的边际结构模型进行中介效应分析的思路和方法。最后,通过模拟随机数据集对几个方法的评估结果进行比较。
原理和方法
1.传统的中介效应分析
中介效应分析中涉及的变量及关系如图1(A)所示,自变量A如果通过某一变量M对因变量Y产生一定影响,则称M为A和Y的中介变量;协变量C对自变量A和因变量Y都存在影响,但A并不会通过C而影响Y的发生,则称C为影响A和Y之间关联的混杂因素。

图1 传统中介效应分析的关联模型
Baron和Kenny在1986年提出了经典的中介效应分析思路,即将总效应(TE)分解为直接效应(DE)和间接效应(IE)[4]。在这一思路的指导下,既往研究者主要基于图1(B)所示的暴露、中介、结果和混杂因素间的关系,采用传统回归模型进行中介效应分析[5]。以暴露、中介和结果均为连续性变量为例:首先拟合中介M与暴露A的回归模型(1),并控制协变量C;然后拟合结局Y与暴露A的回归模型(2),并控制中介M和协变量C。其基本结构如下:
E(M|A,C)=α0+αaA+αcC
(1)
E(Y|A,M,C)=β0+βaA+βmM+βcC
(2)
由模型估计的系数可以得到直接效应以及间接效应的估计值:DE=βa;IE=βmαa。间接效应(IE)的标准误差和95%置信区间推荐使用自举法(bootstrap method)进行估计[6]。自举法是在1个容量为n的原始样本中重复抽取一系列容量也是n的随机样本,并保证每次抽样中每一样本观察值被抽取的概率都是1/n,从而估计β的标准误差并确定一定置信系数下β的置信区间[7]。此外,德尔塔法(delta method)也称为误差传递法,亦可用于计算间接效应的标准误差和置信区间[8]。 需要注意的是,德尔塔法得到的标准误差是一种近似解,其置信区间是对称的;当使用德尔塔法得到的区间临近统计显著性边界时,须谨慎考虑置信区间的意义。
2.传统中介效应分析的局限性
随着中介效应分析在多个领域的广泛应用,研究者们在基于反事实理论的因果推断框架下进一步发展了中介效应分析[9-10],将总效应分解为自然直接效应(NDE)和自然间接效应(NIE)[11],其中的“自然”强调了它是通过反事实进行定义的。在此基础上,统计学家们提出中介效应分析结果用于进行因果解释时,混杂因素必须满足的假设条件:(1)没有未测量的混杂因素(包括“暴露-结果”混杂、“暴露-中介”混杂和“中介-结果”混杂);(2)不存在受到暴露影响的“中介-结果”混杂因素。
当假设(1)不能满足,即存在未测量的混杂因素U,如图2(A)所示。此时,对未测量的混杂因素进行敏感性分析,可以观察到暴露与结果之间的关联是源于暴露对结果的真实影响,还是仅仅归因于混杂因素。以“暴露-结果”混杂为例,敏感性分析的基本思想是指定未测量的混杂因素和暴露之间(即U-A),以及未测量的混杂因素和结果之间(即U-Y)的关联系数来构建变量U。在此基础上构建模型,控制协变量和未测量的混杂因素U以后获得“校正”后的效应估计。这些自定义的关联系数本身没有实际的意义,但研究者可以通过在合理的范围内取一系列不同系数获得对应的一系列“校正”效应,从而获得因果效应的合理估计范围[10]。

图2 不满足中介效应分析中混杂因素假设的两种情景
当假设(2)不能满足,即存在受到暴露影响的“中介-结果”混杂因素L,如图2(B)所示。此时情况变得更为复杂,因为L既是一个“中介-结果”混杂因素,同时又处于从暴露到结果的因果路径上,传统的回归方法此时受到了挑战。假设将L作为上述介绍模型(2)中的协变量进行控制,可能会阻断通过L的因果路径,即 A-L-Y,对A-Y的总效应估计会产生偏差。另一种情况,如果不在回归模型中调整L,那么对M-Y的效应估计又会存在偏差,因为L是M-Y的混杂因素。因此,无论是否在回归模型中控制L,都会得到有偏的估计,传统回归方法不再适用。此时,通过逆概率加权构建的边际结构模型可以较好地解决这个问题,也是本文将主要介绍的方法。
3.逆概率加权构建的边际结构模型
采用逆概率加权构建边际结构模型,是基于反事实理论的因果推断框架下一种中介分析的新方法。基本原理是利用逆概率加权构建一个新的虚拟人群。在新的虚拟人群中暴露和中介相互独立,且不再与其他混杂存在关联,所以此时的模型无需调整混杂C和L,且模型的因变量是反事实结局的边缘均值,因而也被称为边际结构模型[12]。
当暴露A为二分类变量时,每个人暴露A的逆概率权重被定义为1/P(A|C),每个人受到暴露的条件概率P(A|C)也被称为倾向性评分,因此逆概率权重也可以认为是倾向性评分的倒数。当暴露为连续性变量时,我们需要计算稳定的逆概率权重P(A)/P(A|C)。稳定权重的分子常用原始样本中暴露的概率P(A),亦被称为稳定因子,它可以有效缩小逆概率权重的取值范围。稳定权重的均值是1,这是因为此时虚拟人群和原样本的人数一样,因此需要检验稳定权重的均值是否为 1,如果偏离 1,则表明估计权重的模型设定可能有误,需要检验暴露变量的分布是否满足正态分布。
当存在受到暴露影响的“中介-结果”混杂因素L时,采用逆概率加权构建边际结构模型可分别将M看作独立中介因素,也可将M和L看作联合中介。
(1)M作为独立中介构建边际结构模型
第一步:计算暴露的逆概率权重(inverse-probability-of-treatment weight,IPTW)。分子为暴露A的估计边际概率,分母为协变量C条件下每个样本的实际暴露A的条件概率。IPTW的作用是移除C-A之间的关联,即使得暴露A不再受到混杂因素C的影响。
特别地,当暴露A为二分类变量时:
第二步:计算中介的逆概率权重(inverse-probability-of-mediator weight,IPMW),分子为中介M在暴露A为条件下的估计概率,分母为中介M在以暴露A,协变量C和受暴露影响的“中介-结果”混杂L为条件下的估计概率。IPMW的作用是移除C-M、A-M以及L-M之间的关联,即使得中介变量M既不受到暴露A影响,也不受到混杂C和L影响。然后通过IPMW乘以IPTW获得总权重W。
同理,当中介M为二分类变量时:
第三步:构建逆概率加权的边际结构模型。拟合IPTW加权的边际结构模型(3);拟合W加权的边际结构模型(4)。虚拟人群的变量间关系如图3(A)所示,由于IPTW和IPMW消除了混杂的影响,此时,构建边际结构模型可直接估计自然直接效应和自然间接效应:NDE=βa;NIE=βmαa。在边际结构模型中,反事实变量Ma表示暴露A取值为a时,观察到的中介变量M;反事实变量Ya,m表示暴露A取值为a以及中介M取值为m时,观察到的结局变量Y。
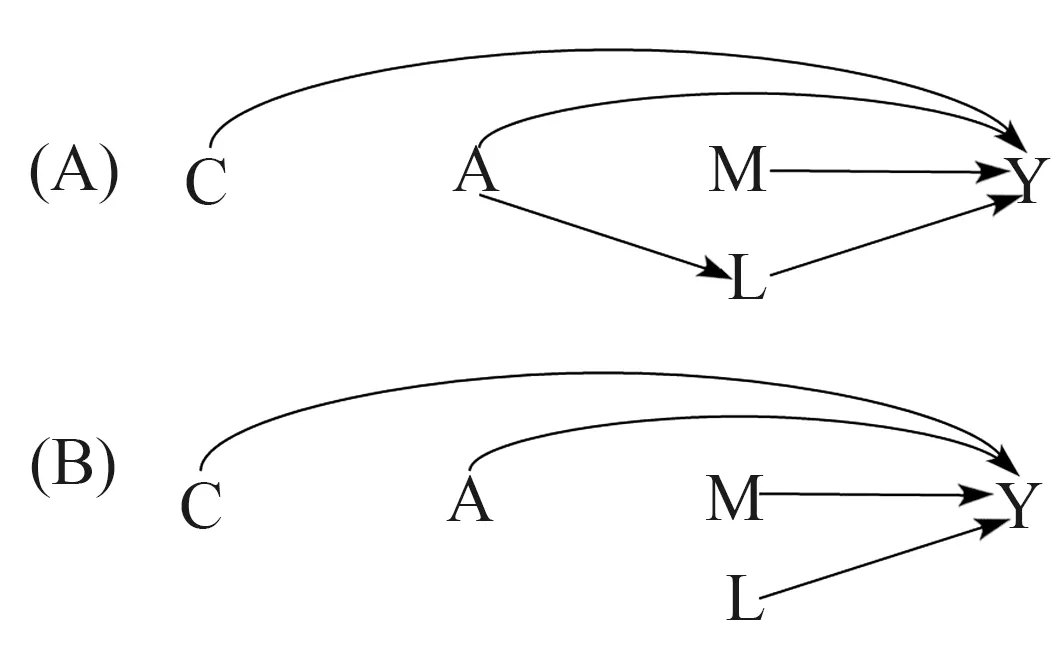
图3 逆概率加权构建的虚拟人群中变量的关联模型
E(Ma)=α0+αaa
(3)
E(Ya,m) =β0+βaa+βmm
(4)
(2)M和L作为联合中介构建边际结构模型
将M和L看作一个整体,即联合中介(M,L),那么假设(2)将再次得到满足[13]。在这样的处理思路下,也可以通过逆概率加权构建的边际结构模型来进行分析。
把M和L看作联合中介因素时,需要在第二步的基础上重新拟合一个IPMW,这个新的IPMW由两部分组成,分别对应两个中介变量M和L:①分子为中介M在暴露A、中介L为条件下的估计概率,分母为中介M在以暴露A、中介L、协变量C为条件下的估计概率;②分子为中介L在暴露A为条件下的估计概率,分母为中介L在以暴露A、协变量C为条件下的估计概率。
此时,通过逆概率加权,构建了一个暴露A不受到混杂因素C影响,中介变量M和L既不受到暴露A影响也不受到混杂因素C影响的虚拟人群,如图3(B)所示。
E(Ya) =β0+βaa
(5)
E(Ya,m,l) =β′0+β′aa+β′mm+β′ll
(6)
然后使用IPTW加权模型(5)可估计暴露影响结果的总效应:TE=NDE+NIE=βa;W加权的边际结构模型(6)可估计暴露影响结果的自然直接效应:NDE=β′a;采用差分法[2]从模型总效应中减去估计的自然直接效应,从而得到自然间接效应:NIE=βa-β′a。
数据模拟和结果
在R中,本文基于正态分布产生一个10000行的随机数据集,模拟了存在受暴露影响的“中介-结果”混杂因素时的数据结构。具体模拟参数设置如下:
1.混杂C满足均值为零,标准差为1的正态分布;
2.暴露A为二分类变量,与C的关系满足:
Log Odds=0.1-0.5C;
3.受暴露影响的“中介-结果”混杂因素L满足均值为1+0.2A,标准差为1的正态分布;
4.中介M满足均值为1+0.3A+0.5L+0.7C,标准差为1的正态分布;
5.结局Y满足均值为1+0.4A+0.5M+0.5L+0.7C,标准差为1的正态分布。
图4反映了模拟数据集中各变量之间的关联,本文通过简单的计算可得到:当M作为独立中介时,总效应为0.7,直接效应为0.5,间接效应为0.2;当M和L作为联合中介时,总效应为0.7,直接效应为0.4,间接效应为0.3。

图4 模拟随机数据集的变量间关联
基于该随机数据集,本文采用了以下分析策略:
1.通过传统的回归模型进行中介效应分析,将L作为混杂进行控制;
2.通过传统的回归模型进行中介效应分析,不对L进行控制;
3.通过逆概率加权构建的边际结构模型进行中介效应分析,将M作为独立中介;
4.通过逆概率加权构建的边际结构模型进行中介效应分析,将M和L作为联合中介。
不同建模方式下的估计结果对比如表1所示,当存在受到暴露影响的“中介-结果”混杂因素时,如果仍然使用传统回归方法,若控制变量L,将低估直接效应和总效应,而不控制变量L,将低估直接效应并高估间接效应。采用逆概率加权构建边际结果模型,不管是以M作为唯一中介,还是将M和L作为联合中介,模拟真实值均处于估计值的95%置信区间内,表明逆概率加权构建的边际结构模型有效地估计了中介效应。

表1 不同建模方式下的估计结果对比
讨 论
逆概率加权构建的边际结构模型在中介效应分析中已经得到了成熟的应用,如Kaisla Komulainen等人将其用于儿童社会心理环境与成年期心脏健康的分析中[14];Yongfu Yu等人采用该方法分析了早产和小于胎龄儿在产妇教育与婴儿死亡率关联中的中介作用[15]。本文系统介绍了当存在受暴露影响的“中介-结果”混杂时,如何通过逆概率加权技术构建边际结构模型,进而实现中介效应分析。并通过在R中模拟随机数据集,详细介绍了计算逆概率权重构建边际结构模型的步骤和代码。本文发现,当存在受暴露影响的“中介-结果”混杂时,采用传统回归模型估计效应存在偏差,而利用逆概率权重构建边际结构模型估计的总效应、直接效应、间接效应与模拟的真实效应具有较好的一致性。
但需要指出的是,逆概率加权构建的边际结构模型本身也存在一定的局限性。如果暴露和中介是连续性变量,此时逆概率加权通常不够稳定。对连续性变量构建逆概率权重首先需要对连续变量的分布进行假设。当变量是二分变量的时候,“逆概率”中的“概率”就是预测变量取值为1(或0)时的概率;当变量是连续变量的时候,此时的“概率”应该是变量不同观测值下的概率密度。要得到准确的概率密度,就需要先验地假设变量分布。通常情况下,多数研究者会假设连续变量服从正态分布。但是在实践中,很难保证所有变量都服从正态分布。此外,如果暴露或者中介是连续性变量,逆概率权重的分母可能在样本之间变化很大,这种可变性将导致少数样本的权重值非常大,进而会为虚拟人群贡献大量的自身副本,从而主导加权分析。
解决连续性变量的逆概率权重有以下几种可能的途径:(1)对逆概率权重本身做一些处理,如剪切[16]或截断[17]。剪切的原理是将极端倾向性评分或权重的个体直接删除,截断是将预先设定范围之外的倾向性评分或权重,统一赋为范围临界点的值。在数据分析时,可将稳定权重与截断法结合使用,对比取不同截断点对应的效应值,从而获得稳健的估计。(2)使用更加稳健的权重,如协变量平衡的倾向性评分[18]或者双重稳健估计的逆概率权重[19]。(3)如果研究者对直接效应更感兴趣,可以使用结构均值模型来估计连续暴露的受控直接效应[10]。此外,即使不存在受暴露影响的“中介-结果”混杂,逆概率加权构建的边际结构模型依旧可以使用,作为传统回归方法的替代方法。然而,当不存在受暴露影响“中介-结果”混杂时,传统回归方法更有效(即有较小的标准误差)。因此,除非受暴露影响的“中介-结果”混杂确实存在,否则倾向于使用传统的基于回归的方法。
中介效应分析在流行病学研究中已经得到了快速的发展,但其所依赖的强假设使其在研究具体问题时遇到了许多挑战。与此同时,统计学家们不断地开发出了新的中介分析方法来适应不同的复杂情景,除本文介绍的基于回归的经典方法和逆概率加权构建的边际结构模型之外,还有VanderWeele提出的基于加权的方法[13],Tchetgen Tchetgen提出的逆比值比加权方法[20],Vansteelandt等人提出的自然效应模型[21]和Robins提出的g-formula方法[22]等。事实上,并没有一种完美的中介效应分析方法可以彻底解决所有问题,根据研究目的和感兴趣的中介变量,研究者可以灵活地选择适合的假设框架与分析方法,识别出感兴趣的效应并实现对因果机制路径的探索。
附录:R代码
#建立随机数据集
n<- 10^4
C<- rnorm(n,mean=0,sd=1)
A<- rbinom(n,size=1,prob=plogis(0.1 - 0.5*C))
L<- rnorm(n,mean=1 + 0.2*A,sd=1)
M<- rnorm(n,mean=1 + 0.3*A + 0.5*L + 0.7*C,sd=1)
Y<- rnorm(n,mean=1 + 0.4*A + 0.5*M + 0.5*L + 0.7*C,sd=1)
dat<- data.frame(id=1 :n,C,A,M,L,Y)
head(dat)
#第一步:计算IPTW(二分类变量算法)
mod<- glm(A ~ C,family=binomial(link="logit"),data=dat)
dat$ps<- predict(mod,dat,type="response")
summary(dat$ps)
dat$iptw<- ifelse(dat$A==1,1/dat$ps,1/(1 - dat$ps))
#第二步:计算IPMW(连续性变量算法)
model_num<- lm(M ~ as.factor(A),data=dat)
num<- dnorm(dat$M,predict(model_num),sd(model_num$residuals))
model_den<- lm(M ~ as.factor(A)+ L + C,data=dat)
den<- dnorm(dat$M,predict(model_den),sd(model_den$residuals))
dat$ipmw<- num/den
summary(dat$ipmw)
#计算总权重W
dat$w<- dat$iptw*dat$ipmw
#第三步:建模(3)-(4)
mod3<- lm(M ~ as.factor(A),weights=iptw,data=dat)
mod4<- lm(Y ~ as.factor(A)+ M,weights=w,data=dat)
#自然直接效应
confint(mod4,"as.factor(A)1",level=0.95)
#自然间接效应
NIE<- coef(summary(mod3))[2,1]*coef(summary(mod4))[3,1]
#使用自举法估计间接效应的标准误差和95%置信区间
library(boot)
fc<- function(dat,i){
newdat<- dat[i,]
mod3<- lm(M ~ as.factor(A),weights=iptw,data=newdat)
mod4<- lm(Y ~ as.factor(A)+ M,weights=w,data=newdat)
out<- coef(summary(mod3))[2,1]*coef(summary(mod4))[3,1]
return(out)
}
set.seed(123)
bootm=boot(dat,fc,R=1000)
boot.ci(boot.out=bootm,type=c("basic"))
#使用德尔塔法估计间接效应的标准误差和95%置信区间
library(msm)
estmean<- c(coef(summary(mod3))[2,1],coef(summary(mod4))[3,1])
estvar<- matrix(c(vcov(mod3)[2,2],0,0,vcov(mod4)[3,3]),2,2)
beta_se<- deltamethod(~ x1 *x2,estmean,estvar)
beta_lwr<- NIE - qnorm(0.975)*beta_se
beta_upr<- NIE + qnorm(0.975)*beta_se
round(c(beta_lwr,beta_upr),2)
#计算IPMW(联合中介算法)
model_num1<- lm(M ~ as.factor(A)+ L,data=dat)
num1<- dnorm(dat$M,predict(model_num1),sd(model_num1$residuals))
model_den1<- lm(M ~ as.factor(A)+ L + C,data=dat)
den1<- dnorm(dat$M,predict(model_den1),sd(model_den1$residuals))
model_num2<- lm(L ~ as.factor(A),data=dat)
num2<- dnorm(dat$M,predict(model_num2),sd(model_num2$residuals))
model_den2<- lm(L ~ as.factor(A)+ C,data=dat)
den2<- dnorm(dat$M,predict(model_den2),sd(model_den2$residuals))
dat$ipmw<-(num1/den1)*(num2/den2)
summary(dat$ipmw)
#计算总权重W
dat$w<- dat$iptw*dat$ipmw
#建模(5)-(6)
mod5<- lm(Y ~ as.factor(A),weights=iptw,data=dat)
mod6<- lm(Y ~ as.factor(A)+ M + L,weights=w,data=dat)
#总效应
TE<- coef(summary(mod5))[2,1]
confint(mod5,"as.factor(A)1",level=0.95)
#自然直接效应
NDE<- coef(summary(mod6))[2,1]
confint(mod6,"as.factor(A)1",level=0.95)
#自然间接效应
NIE<- TE - NDE
