基于神经心理测试的XGBoost在MCI亚型分类中的应用*
2023-10-18易付良陈杜荣张嘉嘉韩红娟葛晓燕白文琳安建华余红梅
易付良 陈杜荣 秦 瑶 张嘉嘉 韩红娟 葛晓燕 崔 靖 白文琳 安建华 余红梅,3△
【提 要】 目的 利用神经心理测试,构建机器学习模型,对轻度认知障碍(mild cognitive impairment,MCI)亚型(Ⅰ型-单认知域遗忘型,Ⅱ型-多认知域遗忘型,Ⅲ型-单认知域非遗忘型,Ⅳ型-多认知域非遗忘型)进行分类,促进MCI亚型早期识别、干预和个性化治疗。方法 数据来源于NACC公共数据库,Ⅰ型469人,Ⅱ型538人,Ⅲ型262人,Ⅳ型274人。神经心理测试包括学习记忆、语言功能、注意力、执行功能和蒙特利尔认知评估量表。采用随机森林填补缺失值,利用弹性网络选择不同MCI亚型的最佳特征,将这些特征输入极限梯度提升(extreme gradient boosting,XGBoost)对MCI亚型进行分类,并将分类效果与K-近邻(k-nearest neighbor,KNN)、支持向量机(supper vector machine,SVM)、随机森林(random forest,RF)进行比较。评价指标包括准确率、灵敏度、特异度、F1-score、G-means、AUC以及阳性/阴性临床效用指数(CUI+/CUI-)。结果 除Ⅰ/Ⅱ型MCI,4个模型对其他MCI亚型分类准确率均大于80%;除灵敏度和CUI-,XGBoost模型整体分类性能优于其他3个模型;除KNN,其他3个模型临床效用指标均大于0.49,且XGBoost对Ⅰ/Ⅲ、Ⅰ/Ⅳ型分类临床效用大于0.81;XGBoost分类aMCI/naMCI及Ⅰ/Ⅲ型MCI时,最重要的分类特征为延迟10~15min后复现本森图(UDSBENTD),分类Ⅰ/Ⅱ型MCI及Ⅰ/Ⅳ型MCI时,最重要的分类特征为连线B完成总时间(TRAILB)。结论 基于神经心理测试的XGBoost对MCI亚型分类性能较好,相较于经典的机器学习模型有所提升,有实际应用价值。
轻度认知障碍(mild cognitive impairment,MCI)是指认知损伤高于随年龄增长或“正常衰老”而出现的记忆和认知变化,但不足以引起日常功能显著受损和痴呆[1]。MCI通常被看作是阿尔茨海默病(Alzheimer′s disease,AD)的高风险状态,每年有5%~15%的MCI患者进展为AD[2-3]。根据认知损害的位置与数量,可将MCI分为以下亚型:Ⅰ型(单认知域遗忘型):仅表现为记忆领域损害;Ⅱ型(多认知域遗忘型):记忆损害伴语言/注意力/执行功能损害;Ⅲ型(单认知域非遗忘型):语言或注意力等单个认知损害;Ⅳ型(多认知域非遗忘型):表现为记忆正常,但多个其他认知领域损害。Ⅰ型和Ⅱ型MCI合称为遗忘型MCI(amnestic MCI,aMCI);Ⅲ型和Ⅳ型合称为非遗忘型MCI(non- amnestic MCI,n-aMCI)[4-5]。各亚型MCI在转归上有较大差别。aMCI被认为是AD的前驱阶段,5年后AD进展率高达60%[6-7],其中,Ⅰ型MCI进展为AD的可能性最大,Ⅱ型MCI次之;而n-aMCI更容易进展为原发性失语、额颞叶痴呆和路易体痴呆等[7-8]。因此,准确识别MCI亚型将有助于早期干预和靶向治疗[9]。
过去的研究常关注脑成像数据如核磁共振成像或正电子发射断层扫描以及脑脊液蛋白组学以评估中枢神经系统淀粉样蛋白沉积、病理学tau蛋白堆积和神经退行性变[10]。然而,作为诊断MCI和AD的临床核心标准——神经心理测试依然是临床医师的首选,被大量运用于识别MCI,而侵入性方法(脑脊液、血液)和脑成像生物标志物则在特定的环境下作为辅助的临床诊断[11]。有文献报道,敏锐的神经心理测试如听觉词语学习测试反映的细微认知损害相较于生物标志物的出现可能更早,这有助于早期发现MCI以及预测疾病进展[12]。
随着人工智能的飞速发展,机器学习和数据驱动方法在众多领域得到应用。本研究拟采用NACC数据库神经心理测试结合机器学习算法——极限梯度提升(extreme gradient boosting,XGBoost)对aMCI和n-aMCI、Ⅰ型MCI和Ⅱ型、Ⅲ型、Ⅳ型MCI进行分类,并将分类效果与K-近邻(k-nearest neighbor,KNN)、支持向量机(supper vector machine,SVM)和随机森林(random forest,RF)进行比较,识别最优分类效果,以促进MCI亚型早期干预和个性化治疗。
资料与方法
1.数据来源
本研究所采用的数据来源于NACC(National Alzheimer′s Coordinating Center)数据库(https://naccdata.org/),编号(1721)。研究对象为2015年1月~2021年3月确诊的MCI患者。
2.研究方法
(1)数据填补
采用随机森林对缺失值进行填补。随机森林可以用于混合类型的数据填补,在数据集缺失率高达50%的情况下,填补准确率依旧高达95%[13]。
(2)神经心理测试
根据第五版精神障碍诊断和统计手册划分的认知领域,结合NACC数据库神经心理测试UDS2和UDS3版本,本次研究纳入的因变量为4个MCI亚型。自变量包括,基本情况:性别、年龄、受教育年限、婚姻状态、独立生活、MCI家族史;学习记忆:故事单元召回(即时、延迟)、复现本森图(即时、延迟);语言功能:多语言命名测试、动物命名测试、蔬菜命名测试、语言流畅性测试;注意力:数字广度测试(前向、后向);执行功能:连线A、B,以及蒙特利尔评估量表。另外,还纳入了临床痴呆评分量表、功能活动量表,自变量共计83项。
(3)特征选择
惩罚技术的提出用来改善最小二乘估计在模型预测与解释方面表现不佳。例如,Hui Zou等人提出了弹性网络(elastic net,EN),该算法结合LASSO回归和岭回归的L1和L2正则化惩罚项,L1促使产生稀疏的特征,输出那些权重较大的预测因子,L2促使产生更分散的权重特征,输出更多的预测因子而非输入中的小部分特征[14-15]。因此,EN在去除对结果影响较小预测因子的同时还能降低模型过拟合风险[16]。
利用EN对特征进行筛选,aMCI/naMCI组筛选出37个特征,Ⅰ/Ⅱ型MCI组筛选出28个特征,I/Ⅲ型MCI组筛选出43个特征,Ⅰ/Ⅳ型MCI组筛选出29个特征。
(4)建立分类模型
将数据划分为训练集(80%)和验证集(20%),采用十折交叉验证在训练集上构建XGBoost模型并与KNN、SVM和RF模型比较,并在验证集上评价模型拟合度。
①XGBoost原理

设有数据集D={(x1,y1)…(xN,yN)},yi∈{-1,+1},第t轮迭代后模型预测值有:
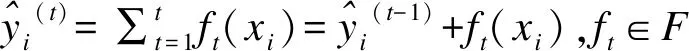
(1)
(1)式中ft(xi)为第t棵树的预测值,F为对应的树组成的函数空间。
②目标函数求解
利用XGBoost完成分类任务时,要保证每新加入一棵树后模型整体性能提升,即要最小化目标函数Obj(t),可通过正则项Ω对损失函数进行约束:
(2)
(3)

(4)
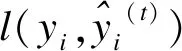
此时目标函数在样本上进行遍历。用泰勒展开式(5)近似目标函数:
(5)

(6)

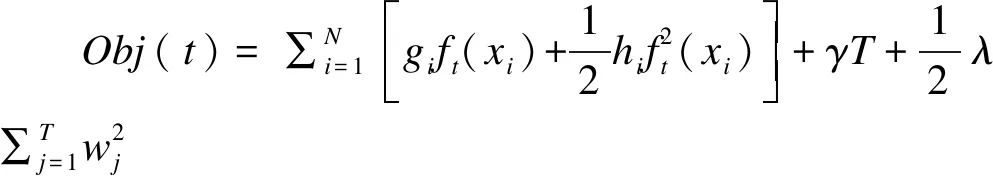
(7)
由于求解目标函数在样本遍历的复杂性,故将目标函数转换成在叶子节点上遍历。定义q函数将输入xi映射到某个叶子节点上,则有:ft(xi)=wq(xi),w∈RT,q:Rd→{1,2,…,T},定义每个叶子节点j上集合为Ij={i|q(xi)=j},则目标函数可以改写为:

(8)

(9)

(10)

(11)
③确定树的结构
对于树的结构,需要根据分裂后的增益Gain来确定,类似于决策树中的ID3信息增益,XGBoost的增益:
(12)

(5)评价指标
模型性能评价:包括准确率、灵敏度、特异度、F1-score、G-means、受试者工作曲线下面积(area under ROC curve,AUC)。
临床效用评价:阳性临床效用指数(positive clinical utility index,CUI+)、阴性临床效用指数(negative clinical utility index,CUI-)。CUI≥0.81:效用极好,CUI≥0.64:效用良好,CUI≥0.49:效用满意,CUI<0.49:效用较差[20]。
(6)软件实现
数据处理与分析基于R语言。缺失填补使用“missForest”包,特征选择使用“glmnet”包。构建XGBoost、KNN、SVM和RF使用“XGBoost”、“kknn”、“e1071”、“randomForest”包。绘制AUC使用“ROCR”包。
结 果
1.填补结果
填补前缺失值的数量与位置见图1,本次填补数据的标准化均方误差为0.26,错分率为0.13。
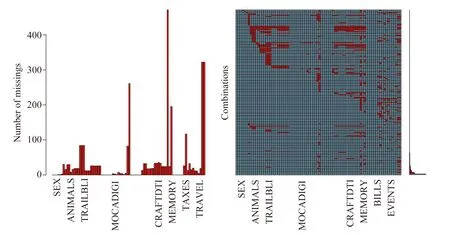
图1 数据缺失值(红色为缺失值数量、位置)
2.基本情况
研究纳入MCI患者1543人,其中aMCI1007人(Ⅰ型469人,Ⅱ型538人);naMCI536人(Ⅲ型262人,Ⅳ型274人)。年龄分布:Ⅰ型(74.86±7.98岁),Ⅱ型(76.49±10.00岁),Ⅲ型(71.34±10.27岁),Ⅳ型(72.55±9.47岁)。受教育年限:Ⅰ型(16.14±2.72年),Ⅱ型(15.42±3.26年),Ⅲ型(15.45±3.2年),Ⅳ型(15.66±3.04年)。其余信息见表1。

表1 人口统计资料
3.分类结果
除Ⅰ/Ⅱ型MCI,4个模型对其他MCI亚型分类准确率均大于80%,且XGBoost表现最好。除灵敏度和CUI-,XGBoost模型分类性能整体优于其他3个模型。除KNN,其他模型临床效用指标均大于0.49(效用满意),且XGBoost分类Ⅰ/Ⅲ、Ⅰ/Ⅳ型MCI效用大于0.81(效用极好),见表2。XGBoost对各亚型MCI分类AUC均大于0.85,且分类aMCI/naMCI、Ⅰ/Ⅲ型、Ⅰ/Ⅳ型MCI时AUC大于0.95,见图2。
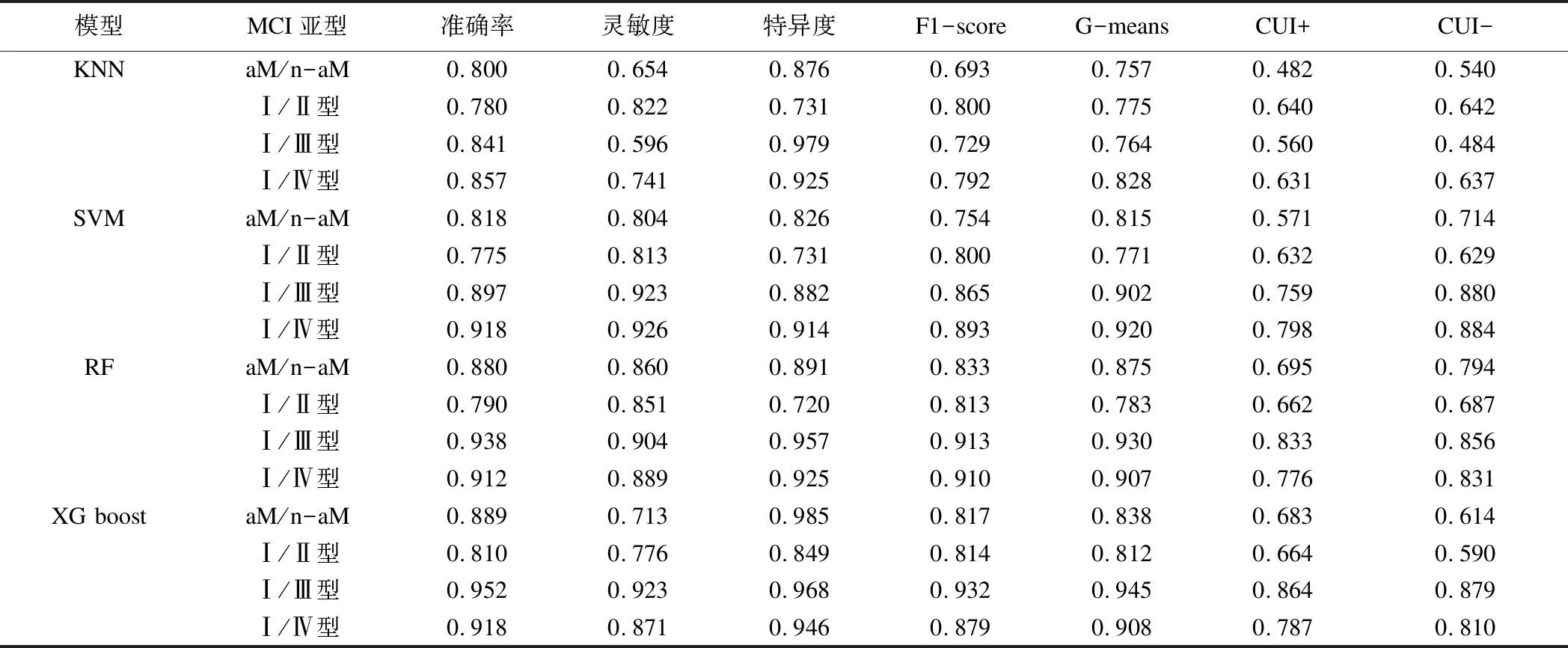
表2 MCI亚型分类评价指标

图2 XGBoost分类MCI亚型AUC
XGBoost对MCI亚型分类时,aMCI/naMCI最重要的3个分类特征依次为:延迟10~15min后复现本森图(UDSBENTD)、故事单元召回(延迟15min)回忆的故事总数:释义评分(CARFTDRE)、临床痴呆评分量表—记忆(MEMORY);Ⅰ/Ⅱ型MCI最重要的3个分类特征依次为:连线B完成总时间(TRAILB)、正确说出带F和L字母的单词总数(UDSVERTN)、连线A完成总时间(TRAILA);Ⅰ/Ⅲ型MCI最重要的3个分类特征依次为:UDSBENTD、MEMORY、TRAILB;Ⅰ/Ⅳ型MCI最重要的3个分类特征依次为:TRAILB、CARFTDRE、UDSVERTN。见图3。
讨 论
利用神经心理测试结合XGBoost对aMCI和n-aMCI、Ⅰ型MCI和Ⅱ型、Ⅲ型、Ⅳ型MCI进行分类,并将分类效果与KNN、SVM和RF进行比较。XGBoost在分类MCI亚型的整体性能较其他模型均有提升。
XGBoost是基于树的集成模型,建树的过程中最耗时的步骤就是特征值排序,而Block结构的引入减少了排序时间,同时也使并行运算成为了可能,但其并行不是基于树的粒度,而是特征粒度[19-21]。
本研究结果显示,XGBoost模型识别各亚型MCI时灵敏度和CUI-略低于RF和SVM,与赵永鹏[22]等人的研究相似。可能的原因是XGBoost对类别不平衡数据更敏感,模型更关注样本较少的类别,而我们在建立模型时,预先设定Ⅰ型MCI为Negative,而Ⅱ、Ⅲ、Ⅳ型MCI为Positive。参数调节也会对模型性能产生影响,我们在输出混淆矩阵前调节threshold值,灵敏度和CUI-随之变化,最佳threshold以牺牲灵敏度为代价输出最高准确率所对应的混淆矩阵。
此外,XGBoost更注重模型的可解释性。通过输出特征重要性排序图,我们可以直观地认识对分类结果影响更大的特征。各亚型MCI最重要的3个分类特征,aMCI/n-aMCI为UDSBENTD、CARFTDRE、MEMORY,相较于n-aMCI,aMCI主要累积记忆损害[23],故延迟回忆花费时间较长、得分较低;Ⅰ/Ⅱ型MCI为TRAILB、TRAILA、UDSVERTN,前两者可以反映MCI患者的执行功能,而UDSVERTN可反映MCI患者的语言流畅性,Ⅱ型MCI患者在执行功能和语言流畅性上低于Ⅰ型MCI患者[24];Ⅰ/Ⅲ型MCI为UDSBENTD、MEMORY、TRAILB,Ⅰ型/Ⅲ型MCI损伤领域分别为记忆单领域、非记忆单领域[8],UDSBENTD、MEMORY主要累积记忆领域,TRAILB与执行功能有关,分类结果与临床一致;Ⅰ/Ⅳ型MCI为TRAILB、CARFTDRE、UDSVERTN,此3项指标分别反映MCI患者的执行功能、延迟回忆、语言流畅性,即Ⅰ型和Ⅳ型MCI患者在延迟回忆、执行功能、语言流畅性上表现不同[25]。
然而,医疗决策的制定更多依赖于诊断试验的临床价值——诊断试验的目的在于改善患者的最终结局、提高医疗质量和成本效益,而非简单地衡量试验准确性[26]。因此,本研究引入临床效用指标,以评估模型的临床实用性。相较于其他模型,XGBoost模型CUI+较高,而CUI-略低,但均大于0.49,表现为效用满意。说明XGBoost模型的分类效果具有临床实用价值,但多模型结合CUI表现可能更为出色。
本研究的局限性在于,Ⅰ型/Ⅱ型MCI分类效果不及其他亚型,这可能是因为两者都存在记忆领域损害。因此,我们拟在下一步研究中结合神经心理测试和其他生物标志物以充实研究结果,并寻找合适的外部验证。
