从SHAP到概率*
——可解释性机器学习在糖尿病视网膜病变靶向脂质组学研究中的应用
2023-10-18金东镇郭城楠赵淑珍李慧慧夏喆铮车明珠王亚楠张泽杰毛广运
金东镇 郭城楠 彭 芳 赵淑珍 李慧慧 夏喆铮 车明珠 王亚楠 张泽杰 毛广运,2△
【提 要】 目的 基于可解释性机器学习算法构建糖尿病视网膜病病变(diabetic retinopathy,DR)的早期识别模型,并探讨SHAP(SHapley Additive exPlanations)在脂质组学数据中的应用。方法 基于本项目组的DR靶向脂质组学数据,通过可解释性机器学习的方法进行特征筛选;在建立糖尿病视网膜病变的早期识别模型后,通过全局、特征和个体三个层面对模型进行解释,并将SHAP值转换成概率以增强可解释的能力。结果 本研究筛选出了5种内源性脂质代谢物,构建了一个性能较为优秀的糖尿病视网膜病变的早期识别模型,并成功使用SHAP及概率解锁了模型。结论 脂质代谢物质可以应用于糖尿病视网膜病变的早期识别;SHAP在进行黑盒模型的解锁时表现出色,且有较高的实践应用价值。
糖尿病视网膜病变(diabetic retinopathy,DR)是以视网膜新生血管性增殖为特征的一种致盲性眼病,是糖尿病(diabetes mellitus,DM)最常见、最主要的并发症之一,也是劳动年龄人口失明的主要原因之一[1-2]。随着糖尿病的患病率增加、治疗手段进步、糖尿病患者寿命延长,伴有DR的患者急剧增加,预计在2030年全球糖尿病视网膜病变的患者将达到1.91亿人[3]。DR的经济影响巨大,相比于普通糖尿病患者,DR患者的医疗花费增加了两倍[4-5],视力障碍和失明也会对个人生活质量以及他们所生活的社会经济状况造成毁灭性的影响。早期识别对疾病的有效预防和控制至关重要且意义重大[6],同时有研究表明血脂异常与DR的发生发展密切相关[7],可能是DR发生发展的早期信号。而脂质组学(lipidomics)作为代谢组学的一个重要分支,已经被认为是有效识别潜在脂质生物标志物的优势技术。
随着机器学习(machine learning,ML)技术的蓬勃发展,ML目前已成为高维度大数据分析的主流技术。相较于传统的组学分析方法,机器学习方法如随机森林(random forest,RF)和支持向量机(support vector machines,SVM)已经在复杂的组学数据分析中显现出明显的优势[8]。然而正是对预测结果精确程度的追求,机器学习算法所构建的模型往往较为复杂,牺牲了一定的可解释性[9],即由于复杂模型只能给出输出而常被称为“黑匣子模型”。为了解锁复杂的机器学习模型,SHAP(SHapley Additive exPlanations)作为一种解释个体预测特征贡献的方法在2017年被提出[10],并且发展迅速。简单来说,SHAP解释方法根据联盟博弈理论计算某个个体不同特征的SHAP值(可以表示贡献,值越大贡献越大),来解释个体的预测,其中个体的特征值充当联盟中的参与者。在此基础上,SHAP创新性地将SHAP值的解释表现为一种可加的特征归因方法,可表现为:
yi=ybase+f(xi1)+f(xi2)+f(xi3)+…+f(xik)
yi:表示模型的预测;f(xik):表示第i个样本第k个特征对最终预测的贡献,即对应的SHAP值。
相较于其他模型解释方法,SHAP源于博弈论,有坚实理论基础;由于其所具有局部准确性(local accuracy)、缺失(missingness)以及一致性(consistency)等优良性质,可以通过SHAP值聚合获取模型全局的解释而广受欢迎[11]。
本文在课题组前期研究的基础上,将机器学习方法应用于糖尿病视网膜病变的靶向脂质组学数据分析中,在构建早期识别模型的同时,使用SHAP解锁模型并进一步将SHAP转换成概率,以获得其生物学和医学的解释,为DR早期诊断提供科学依据。
资料与方法
1.数据来源
该数据来自本项目组“基于代谢组学技术的糖尿病视网膜病变早期识别研究”,以糖尿病视网膜病变(DR)者为病例,以2型糖尿病(T2D)患者为对照,基于年龄、性别、体质指数(body mass index,BMI)、血压分级和糖化血红蛋白(glycosylated hemoglobin,HbA1c),采用倾向性评分匹配(propensity score matching,PSM)法,按1∶1的比例匹配出69对研究对象。所有受试者均接受详细的全身检查,包括身高、体重、坐位血压(blood pressure,BP)、空腹血糖等常规检查以及相关眼科检查等;而人口学指标通过详细的问卷调查获取,问卷均由统一受过标准化操作流程(standardized operation procedures,SOP)培训的研究者对受试者或其家属进行一对一的询问。脂质组学数据主要包含了22种本课题组的前期研究中被证实是差异性脂类代谢物,本项目通过进一步的靶向脂质组学分析对其进行分析。
2.统计分析
统计分析主要包括数据预处理、特征选择、模型的构建及评估、模型的解释四个方面。
(1)数据预处理
缺失值的存在会对数据挖掘结果产生较大偏倚,降低统计分析的效率,因此需要对缺失数据进行合理的删减和填补。考虑到组学数据缺失的三种原因[12],本研究在删除缺失比例超过20%的特征以后,一般资料用多重填补的方式进行填补,而脂类物质用最小值的一半进行填补[13]。
(2)特征选择
对于一般资料来说,定量资料使用独立样本t检验或Wilcoxon秩和检验比较两组间的差异;定性资料则用卡方检验或Fisher精确概率法进行组间的比较。两组之间存在统计学差异的特征被认为可以被纳入模型。而在进行脂质物质的筛选时,我们使用了lightGBM模型并通过SHAP获取各种脂质物质的重要性排序,随后按照特征重要性排序将脂质依次进入模型并计算其曲线下面积(area under the curve,AUC),并考虑奥卡姆剃刀原理[14],选取数量合适的脂质物质作为特征纳入模型。
(3)模型的构建
依据上述方式选择的一般特征以及脂质特征,基于训练集构建了DR的早期识别模型——lightGBM,并进行了参数优化。
(4)模型的评估和解释
为了验证模型的泛化能力,本研究基于验证集或使用10折交叉验证的方式对模型的预测价值进行判断。在10折交叉验证中,将数据集拆分成为10个不同的子集,每次用9个作为训练集,剩余1个作为测试集对模型性能进行验证,最后获得10个模型性能的平均表现作为10折交叉验证的结果。另外,我们也使用了HL(Hosmer-Lemeshow)拟合优度检验对模型的预测概率的效果进行评估。最后通过SHAP对用于早期识别的lightGBM模型进行解释。然而,相较于概率而言,SHAP值对那些不了解的人来说也并不友好,于是我们将SHAP值通过一元插值法转换成了概率并加以展示使其更加方便理解[15]。
结 果
1.特征筛选
(1)人口学特征及实验室指标
如表1所示,两组人群在经过倾向性评分匹配之后,无论是在训练集还是验证集中,年龄、性别、BMI、空腹血糖(FPG)、糖化血红蛋白等指标在两组间的差异均未达到显著性水平(P>0.05),而糖尿病病程无论是在训练集或验证集中两组水平均显示有差异(P<0.05),而高血压史在训练集中表现出差异(P<0.05)。因此我们在人口学特征及实验室指标中选择糖尿病病程以及高血压史进入模型。
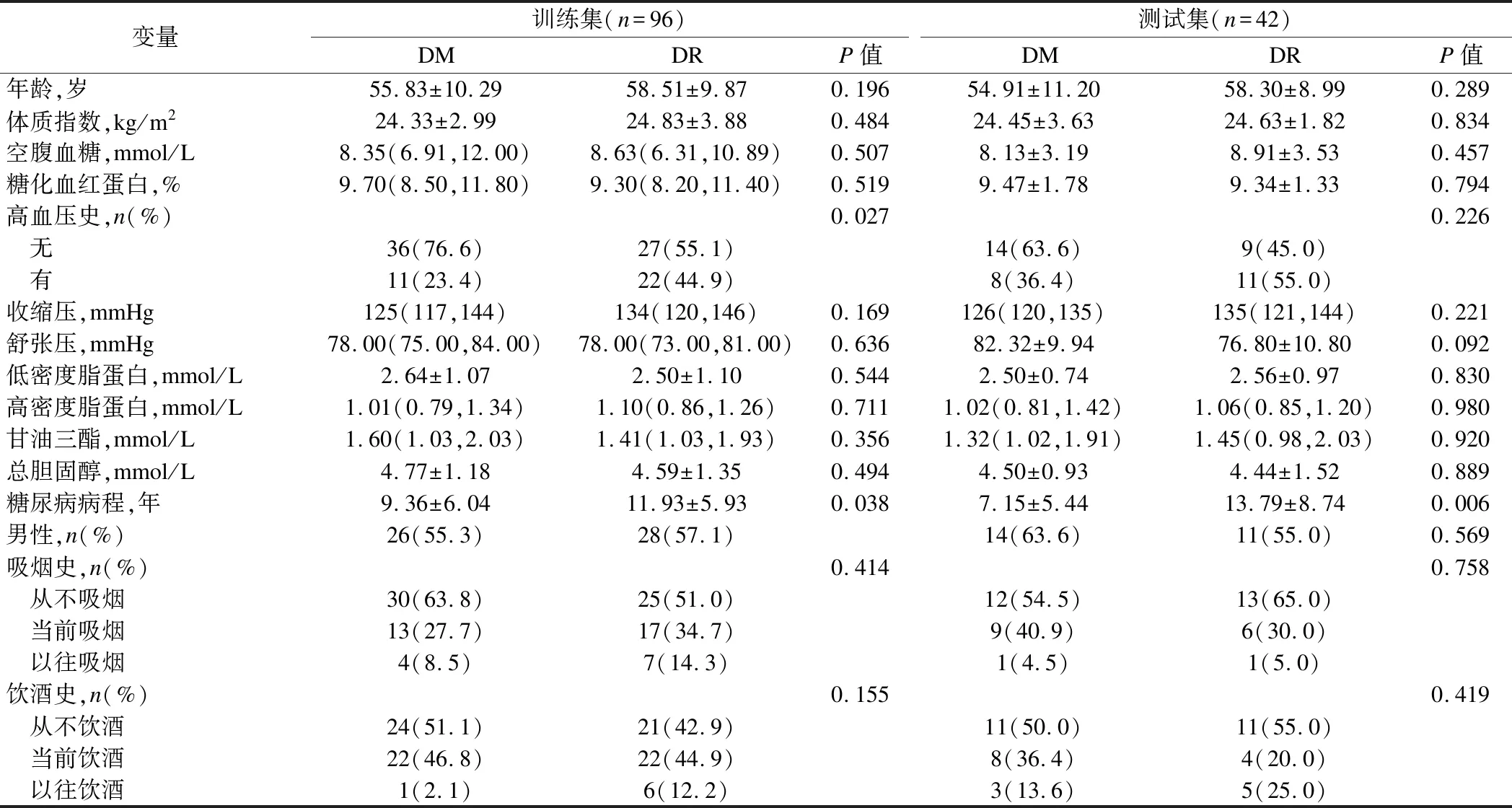
表1 研究对象的人口学和临床特征等一般情况
图1A显示了22种脂质物质在模型中的重要性排序,22种脂质的特征重要性是从上到下依次排列的,其排列的方式主要由模型中某一特征的平均SHAP绝对值所决定。随后我们按照图1A所示的特征重要性排续依次将脂质物质纳入模型,并对不同数量的脂质物质所构建模型的AUC进行评估,发现不管是在验证集或交叉验证中,当纳入前五种脂质时AUC达到较为稳定的状态。再考虑到临床实际应用和奥卡姆剃刀原理,最后我们选取了前5的特征进行模型的构建,依次为:OxPC_2[OxPC 34∶2+1O(OxPC 16∶0-18∶2+1O)]、LPG[LPG 18∶1]、FA_3[FA 18∶1]、Acar_1[ACar 16∶2]、Acar_2[ACar 8∶0]。

图1 脂类物质的筛选过程
2.模型构建及评价
根据上述的选择标准,我们最终选择了OxPC_2[OxPC 34∶2+1O(OxPC 16∶0-18∶2+1O)]、LPG[LPG 18∶1]、FA_3[FA 18∶1]、Acar_1[ACar 16∶2]、Acar_2[ACar 8∶0]、糖尿病病程以及高血压史共7种特征在训练集中构建lightGBM模型。为了评价已构建模型的性能,我们使用了各项评价标准对其进行评估。如图2所示,在训练集中构建的lightGBM模型的ROC曲线下面积为0.92,在测试集中同样表现出较好的区分能力,AUC为0.84。除此之外,如表2所示,模型在训练集中的Accuracy、Precision、Recall、F1-score分别为0.823、0.776、0.918、0.841,而在验证集中分别为0.810、0.800、0.800、0.800,在10折交叉验证中分别为0.861、0.769、0.779、0.846,均显示出了较为优秀的分类能力。并且我们对模型的预测概率进行了HL拟合优度检验,在训练集中卡方值为10.07(P=0.359),测试集中卡方值为5.54(P=0.854),表示该模型具有较好的校准度。
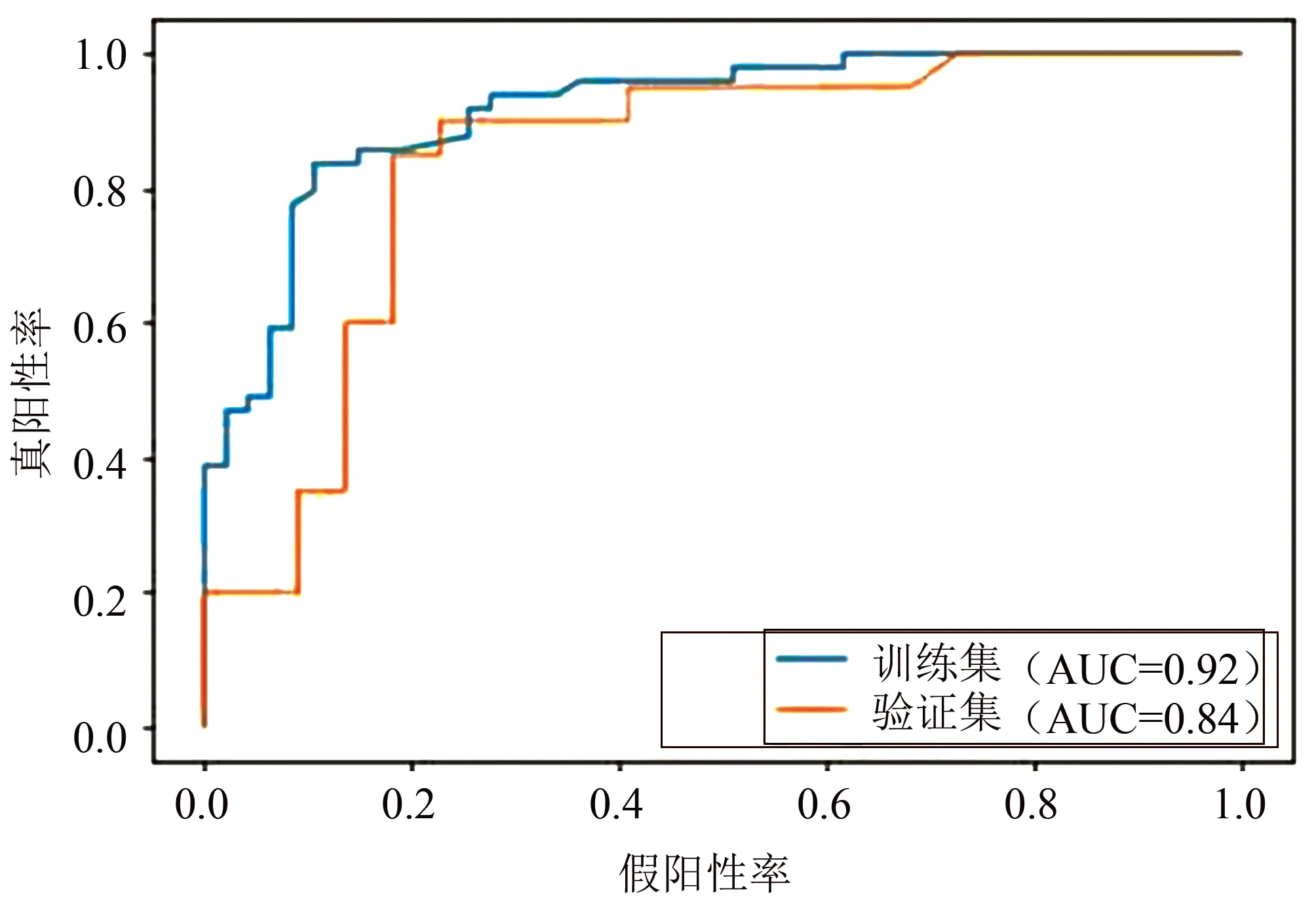
图2 lightGBM在训练集和验证集中的ROC曲线分析

表2 lightGBM模型性能的评估
3.模型解释
(1) 全局的解释
图3是对模型全局的解释,根据图3A所示,左侧纵坐标表示了各种特征在模型中的重要性排序,而右侧的黑色柱状图则根据平均SHAP值所得出的每种特征的具体重要程度,由此可见在lightGBM中期重要性依次为:LPG[LPG 18∶1]、OxPC_2[OxPC 34∶2+1O(OxPC 16∶0-18∶2+1O)]、Acar_2[ACar 8∶0]、Acar_1[ACar 16∶2]、FA_3[FA 18∶1]、高血压史[HYPERTENSION]以及糖尿病病程[DM_duration]。横坐标表示了每一个个体,相对应上方的f(x)则是表示每个个体的SHAP值,由此可见在LPG[LPG 18∶1]的SHAP值较低时多数人相较于平均水平患DR的风险下降。而图3B不仅特征重要性的同时,可以观察到每个特征SHAP值的分布而进一步了解特征对结局的影响是正相关还是负相关。如LPG[LPG 18∶1]的值越小而SHAP值增大,说明了LPG[LPG 18∶1]的增加可能发生DR的概率下降,Acar_2[ACar 8∶0]、Acar_1[ACar 16∶2]、FA_3[FA 18∶1]与LPG[LPG 18∶1]相类似,而OxPC_2[OxPC 34∶2+1O(OxPC 16∶0-18∶2+1O)]、高血压史则相反。

图3 lightGBM模型的全局解释
(2) 特征的解释
上述的图形只能表示特征对结局的影响方向,为进一步探究特征如何对结果产生影响的,我们绘制了SHAP依赖图对某一特征的边际效应进行描述。然而由于文章篇幅的限制,本文仅选取了FA_3[FA 18∶1]进行展示。如图4A所示,随着FA_3[FA 18∶1]的增大,SHAP值降低,也就是说,随着FA_3[FA 18∶1]的上升,发生DR的概率下降。然而,正如上文中提到的,相对于概率来说SHAP值对于多数人来说并不友好,因此本文在此基础上,将SHAP值转换成概率(如图4B所示),相较于A图来说,我们可以清楚知道,在FA_3[FA 18∶1]的值为75以下,DR发生的概率增大,并且在FA_3[FA 18∶1]值达到100以上时,其边际效应保持在了-0.18%左右,继续增大也并未起到较好的效果。
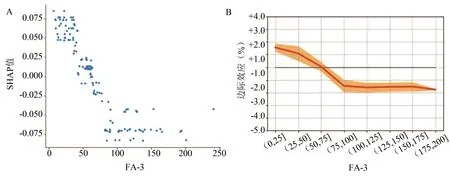
图4 FA_3[FA 18∶1]在模型中的边际效应
同时,为了探究FA_3[FA 18∶1]与高血压史[HYPERTENSION]是否存在交互作用,通过对高血压的分层,我们绘制了特征交互图。由图5可知,有高血压史的人相较于无高血压史的人患有DR的风险较高,而黄色和蓝色两条曲线并无相交,说明了FA_3[FA 18∶1]与高血压史[HYPERTENSION]不存在交互作用。

图5 FA_3[FA 18∶1]和高血压史[HYPERTENSION]在模型中的交互
(3)个体的解释
我们通过SHAP解释某一特征的同时,想具体了解某一个体在模型中的预测结果及其被预测正确或错误的原因,因此我们针对不同的个体绘制了SHAP解释力图。如图6所示,A、B、C分别显示了三个不同的个体在模型中的表现。其中图6A表示了被模型预测为低风险的个体,由于其LPG=0.01492导致其预测有DR的概率下降的最大,而OxPC_2=0.1431则增加了这个个体被模型判定为发生DR的概率;而图6B则是被模型预测为高风险的个体,其中导致他被预测为高风险的原因是LPG=0.00669;图6C则是一个被模型预测为中等风险的个体。而其中值得一提的是,f(x)在下图中的解释是模型的输出概率的对数,因此其产生了负值。

图6 SHAP解释力图:不同的个体在模型中的表现
讨 论
首先,本文在这项基于PSM的多中心病例对照研究中,成功筛选出5种差异内源脂类代谢物质与DR发生风险显著相关,可作为糖尿病病人中早期识别DR病人的标志物。另外,我们将5种差异性特征代谢物结合糖尿病病程、糖尿病史构建DR早期识别模型,经过模型评估后验证了其良好的分类效果,为糖尿病视网膜病变的早期识别提供新思路。其次,本文使用了一种可解释的机器学习框架对黑盒模型进行解锁,主要从全局解释,特征的边际效应以及个体层面的解释三个不同的角度解释模型,完整地介绍了SHAP。最后,本文在SHAP的基础上,将SHAP值转换成了概率,不仅进一步增强了机器学习的可解释性,同时也量化了某一特征对结局的影响程度。
近年来,机器学习已经被广泛应用于生物医学领域,然而由于其较难解释的特性,在临床环境中的应用仍然有限,而SHAP能解锁黑盒子模型的能力将会极大推动机器学习模型在临床的实际应用。另外,SHAP中针对个体可解释能力不仅能推动模型应用于临床实际工作中,而且将会成为精准医疗和个体化医疗的重要决策依据。
(致谢:感谢所有项目组成员的支持和帮助,感谢温州医科大学公共卫生学院预防医学系代谢组学研究团队的奉献和辛勤工作,感谢2021年浙江省大学生科技创新活动计划暨新苗人才计划、国家重点研发计划等项目的支持。)
