基于无监督迁移成分分析和支持向量机的故障分类方法
2023-10-12马义中
蒋 兆,马义中
(南京理工大学 经济管理学院,江苏 南京 210094)
0 引言
近年来,迁移学习作为机器学习的重要分支开始兴起并得到广泛关注[1]。传统机器学习实现故障的分类与检测需要满足两个前提条件:①训练样本与测试样本服从独立同分布;②在足够多的训练样本数据下训练模型[2-3]。但因环境因素等影响,现实的工况环境往往无法满足上述条件[4-7],如,不同工况下数据分布不相同导致训练模型的泛化能力不理想[8];故障样本数量有限导致故障类型识别时发生误诊情况[9-11]。实际应用表明,支持向量机(Support Vector Machines,SVM)可通过核函数变换实现高维特征空间上的线性可分[12-13]。此外,为了突破传统机器学习方法的局限性,迁移成分分析(Transfer Component Analysis,TCA)被广泛地应用于故障分类中[14-17]。TCA能够减小不同领域数据分布的差异性,提高跨领域的学习能力,其主要思想是将源域知识迁移到目标域,以达到目标域分类的目的[18-22]。
近年来,TCA方法的知识迁移能力被应用到故障分类、监控与诊断等领域。例如,XIE等[23]将TCA方法应用在变速齿轮箱故障分类中;段礼祥等[24]应用TCA方法减小训练样本与测试样本的差异性,提高故障分类的准确性。沈飞等[25]通过应用TCA方法提取样本特征来提高电机故障分类的准确度。但TCA方法进行故障诊断时需要大量带标签的样本数据来训练分类器,而对实际生产中所产生的实时数据进行人为标签的成本高且不确定性大。由于工况的复杂性,数据的分布差异巨大,带标签样本并不一定适用于最新产生的数据,以此训练出来的分类器更是难以满足需求[26-27]。而且监测数据通常只有少量可以与目标域数据相匹配的标签数据,这将严重影响特征迁移的效率[28]。因此,本文提出无监督迁移成分分析(Unsupervised Transfer Component Analysis,UTCA),其核心思想是通过设置核函数,将两个样本集的特征映射到同一个核空间中,最小化领域之间的数据分布距离。在特征映射时无需考虑样本标注信息,能够有效提高特征迁移效率,降低人为标注的不确定性。UTCA方法的难点在于如何度量这两个领域间的分布距离,对此目前主要方法有Bregman差异[29]、基于熵的Kullback-Leibler差异[30]和最大均值差异(Maximum Mean Discrepancy,MMD)[31]。由于Bregman差异通过梯度下降方法来求解目标函数,计算比较复杂,而基于熵的Kullback-Leibler差异先验概率密度很难计算。MMD因其计算简单而获得了广泛应用。如PAN等[32]提出将MMD与主成分分析相结合,尝试通过减少数据分布差异来提高分类的准确度。LONG等[33]提出基于MMD的TCA分析方法并应用于风机故障分类中,获得了比较好的分类效果。
为解决因源域和目标域数据存在分布差异及故障样本缺乏,影响故障分类准确度的问题,本文将UTCA和SVM两种算法相结合,提出一种新的故障诊断方法。该方法主要由特征提取和故障状态分类两个部分组成,首先利用UTCA方法引入MMD来度量源域和目标域数据分布的差异,实现域间数据分布近似相同,进而获得故障诊断分类特征。在故障状态分类方面,由于SVM在解决小样本,非线性问题时表现出优异的性能,本文将SVM作为故障状态分类器来提高故障状态分类的准确率,并通过凯斯西储大学(Case Western Reserve University,CWRU)实验室所采集的滚动轴承实验数据作为实验对象,验证所提方法的有效性。
1 基于无监督迁移成分分析的分类方法
本文提出了基于UTCA和SVM的分类方法,首先利用UTCA将源领域和目标领域映射到再生核希尔伯特空间并进行降维并提取数据。其次利用SVM对于目标领域数据进行分类,解决了因缺乏目标域样本小而影响分类模型性能的问题。
1.1 无监督迁移成分分析
在应用UTCA方法时,首先将源域和目标域的样本数据映射到同一个特征子空间中,通过分布度量准则来缩小特征分布差异:即假设源域为Ds={Xs,Ys},其中:Xs为源域样本集,Ys为标签样本;目标域为DT={XT},其中XT为标签未知的目标域样本集。通过特征映射函数Φ,使映射后的边缘概率分布尽可能相似,即P(Φ(Xs))≈Q(Φ(XT))。
其中Φ(Xs)与Φ(XT)是经过Hilbert核空间映射后的源域特征样本集与目标域特征样本集,源域和目标域之间的距离表示为:

(1)
式中:‖·‖H为RKHS范数;N1为源域样本个数;N2为目标域样本个数;xsi∈Xs,xTj∈XT。将上述映射函数Φ转化为内核学习问题,则映射后的源域和目标域距离表示为:
dis(Φ(Xs),Φ(XT))=trace(KL)。
(2)
式中:trace(·)表示矩阵KL的迹,其中K=[KS,SKS,T]∈R(N1+N2),KS,S、KS,T分别为源域和目标域的核矩阵,
(3)
核矩阵K还可以表示为:
K=(KK-1/2)(K-1/2Κ)。
(4)
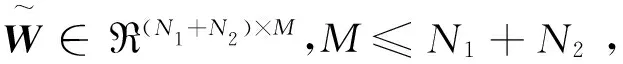
(5)
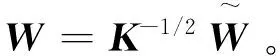
dis(Φ(Xs),Φ(XT))=trace((KWWΤK)L)=
trace(WΤKLKW)。
(6)

为使不同领域分布的间距离尽可能小,需要在式(6)中添加正则项μ·trace(WTW)来控制矩阵W的复杂度,优化目标转化为:
s.t.
WΤKHKW=IM。
(7)
式中:μ>0为平衡参数;IM∈RM×M为单位矩阵。
根据约束条件WΤKHKW=IM,式(7)可转化为目标函数求解:
(8)
可由式(8)求解(I+μKLK)-1KHK得到最佳映射核矩阵W,样本矩阵X*=KW。
1.2 支持向量机
SVM建立于统计理论中的结构风险最小化原理上,根据相对有限的样本信息,在模型复杂性和学习能力之间寻求平衡,以获得最佳的模型泛化能力。
(9)
s.t.
yi(ATφ(xi)+b)≥1-ξi,i=1,...,n。
(10)
其中:ξi为松弛变量,表示训练样本的错分程度;C为惩罚常数,控制对错分样本的惩罚程度;A和b分别为函数f(x)=A·φ(x)+b的权和阈值。利用拉格朗日法得到判决函数:
(11)
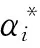
R(x,xi)=exp(-g|x-xi|2)。
(12)
1.3 GA-SVM模式识别模型的建立
SVM模型有两个非常重要的参数C与g,其中C为惩罚系数,即对误差的宽容度。当C取值过大时,对于错误的容忍度相对较高,边界会变宽。模型的波动相对较小,偏差较大。C取值过小情况正好相反。g越大,支持向量越少,这将影响训练与预测的速度。由于遗传算法不依赖背景知识,搜索方向由适应度函数决定,适合解决参数优化问题。因此,本文采用遗传优化算法(Genetic Algorithm,GA)优化SVM模型优化模型参数即式(9)中的惩罚因子C和式(12)中的核函数参数g,取值范围根据经验并参考文献[34-36]设置为[0,100]。将分类准确度作为适应度函数,以轮盘赌的方式进行选择,以0.6的概率进行交叉,变异概率为0.02,最大遗传代数为100。
2 基于无监督迁移成分分析的滚动轴承故障分类的实施步骤
实验主要由提取样本特征和分类器进行故障分类两个部分组成,因此本文首先应用UTCA算法进行样本特征的提取,然后应用SVM分类器对于故障状态进行分类,以达到提高滚动轴承故障状态分类准确度的目的,具体实施步骤如图1所示。

图1 基于无监督迁移成分分析流程图
无监督迁移成分分析—支持向量机(UTCA-SVM)故障分类模型对于轴承不同状态进行识别的具体步骤如下:
步骤1利用传感器采集原始信号,选取某种工况下4种轴承状态(健康、内圈故障、滚动体故障、外圈故障)的信号作为源域样本数据。另一种工况下4种轴承状态的信号作为目标域样本数据。
步骤2采用EEMD将原始信号分解,得到若干IMF分量;通过计算IMF分量与原始信号的相关系数筛选出含故障信息量较大的IMF分量;再对该分量进行Hilbert变换,获取频谱能量分布。
步骤3将源域和目标域样本信号通过MMD指标来度量迁移的源域样本数据并提取其样本数据特征。
步骤4将迁移学习的源域数据样本数据作为训练数据获得最优的参数组合,同时将目标域样本数据作为测试集来完成故障状态的识别。
3 实验验证与结果分析
3.1 实验数据
本文采用凯斯西储大学(CWRU)实验室采集的滚动轴承实验数据来验证所提方法的有效性,对表1所示的8种轴承状态振动信号进行识别。

表1 信号采样频率为12 kHz的滚动轴承故障数据
CWRU数据集中按照功率的不同可分为0 HP、1 HP,本文将不同的功率之间相互迁移。每个样本为6 000个采样点构成的信号,在0 HP功率下采集200个源域数据样本作为训练集;在1 HP功率下采集100个目标域数据样本作为测试集,共300个样本。
3.2 实验步骤
首先,利用传感器采集不同故障状态的原始信号并通过小波变换得到时域和频域数据。其次,通过EEMD方法分解3层原始振动信号,再计算各IMF分量与原始振动信号的相关系数R,选择相关系数R最大的IMF分量对其进行Hilbert变换,求出各频带信号的能量。

(13)


图2 功率0HP工况下轴承信号能量谱
从图2中可以看出:
(1)在0 HP工况下,内圈、滚动体和外圈未发生故障时,序号1,2的能量谱明显高于故障状态,表明轴承能量谱特征的故障状态与正常状态差异明显。
(2)对比正常状态及不同位置故障状态能量谱可以看出,3种故障类型的轴承序号都是3、7能量谱明显高于正常状态,而3种故障状态的能量谱之间的区别不明显。
本文采用以上相同的步骤计算出功率1 HP工况下轴承的频谱能量分布,然后通过UTCA方法将两者的频谱能量映射到同一个核希尔伯特空间中,通过MMD指标来度量可以迁移的源域样本数据并提取其样本数据的特征。如图3所示,滚动轴承不同故障类别之间Hilbert边际谱能量有着显著差异,所以该特征向量可以用来区分滚动轴承的故障类别。


图4 遗传算法参数优化过程
3.3 故障分类结果对比
最后为验证UTCA-SVM方法的有效性,使用PCA-SVM和SVM方法进行对比。将相同训练样本输入到两种分类器中,算法初始种群数都设置为20,最大迭代次数为100。通过遗传算法对参数寻优后得到3种分类器对于滚动轴承故障状态分类的结果如图5~图7所示。

图5 UTCA-SVM分类器对于滚动轴承故障状态分类的结果

图6 SVM分类器对于滚动轴承故障状态分类的结果

图7 PCA-SVM分类器对于滚动轴承故障状态分类的结果
从图5~图7中3种分类器对于滚动轴承故障状态分类的结果来看,展示了不同算法生成的用于进行多类别样本分类的决策边界。一个好的决策边界应该包含更多的己类样本和更少的他类样本。从3张图中的决策边界的划分来看,本文所提方法产生的决策边界能够将4种故障类型的轴承准确划分,而SVM和PCA-SVM方法都出现不同程度的划分错误,决策边界内不仅包括己类故障样本数据,还包括其他类型的故障数据样本。因此,UTCA-SVM方法的分类效果明显要优于SVM和PCA-SVM方法。再将测试集数据输入到训练集训练好的3种分类器模型中,故障分类结果如表2所示。

表2 故障分类结果 %
由表2故障分类结果可以看出,相较于SVM和PCA-SVM方法,UTCA-SVM方法对于故障识别的准确度最高。这是由于UTCA-SVM方法不仅能够缩小源域与目标域间样本数据分布的差异性,更为重要的是UTCA-SVM方法能够减少人为标记对样本标签的不确定性,提高故障分类的准确度。
4 结束语
为解决因源域和目标域数据存在分布差异及故障样本缺乏影响故障分类准确度的问题,本文提出一种基于无监督迁移成分分析的滚动轴承故障状态分类方法,该方法通过寻找共同成分进行迁移学习来实现不同工况下故障的分类。迁移学习可通过有效减小域间数据的分布差异来达到满足测试样本与训练样本独立同分布假设的严苛要求[32]。最后通过实验进行验证,从图5~图7决策边界的划分结果可以可视化地看出本文所提方法只包括己类故障样本数据而PCA-SVM和SVM方法不仅包括己类故障样本数据,还包括其他类型的故障样本数据。从实验结果中可以看出,本文所提方法相较于PCA-SVM和SVM方法对于轴承故障状态分类的准确度分别提高约6%和12%。因此UTCA-SVM方法相较于传统机器学习方法能够明显地提升轴承故障状态的分类准确度,适用于轴承故障状态的分类。本文重点研究轴承故障诊断方法,并进行实验验证,但还有许多方面有待进一步研究:(1)考虑其他基于迁移学习的故障状态识别方法,通过集成不同的分类器构建一个分类能力更强的分类器;(2)针对筛选样本数据,考虑其他度量源域和目标域数据分布差异的方法,进一步提高迁移学习的效率。
