配送属性数据驱动的协同配送联盟组建
2023-10-12邓建新韦婉冬贺秋瑶陈星雨
邓建新,韦婉冬,贺秋瑶,陈星雨
(1.广西大学 机械工程学院,广西 南宁 530003;2.广西大学 广西制造系统与先进制造技术重点实验室,广西 南宁 530003;3.吉利学院 商学院,四川 成都 641423)
0 引言
协同配送是具有配送任务的企业联合起来实现资源整合和配送集约化、规模化的配送方式,可提高资源利用率,减少运输车辆,进而可降低配送成本、减少交通污染和阻塞,是现代配送的发展趋势之一,尤其在“碳达峰、碳中和”等目标要求下更具有良好的发展前景。自2012年,我国已开始大力推行协同配送[1],相继选择广州、厦门等9个城市进行重点示范。但协同配送实施过程中面临协同伙伴选择、协同运作模式制定、成本分摊和利益分配、需要重新投资等核心问题或难题[2],实施难度较大,企业间缺乏自组织协同配送的动力,而政府等第三方又缺乏科学的协调组织方法,现实中成功的案例很少[3]。其中选择合适的协同伙伴和协同方式建立高效、稳定、可持续和公平的协同配送联盟是开展协同配送和实现其优势的前提和保证。但无论面对熟知还是知之甚少的企业,如何高效优化地选择或协调组织协同配送伙伴来建立稳定高效的协同配送联盟都是一个巨大的挑战。随着大数据技术在各行业的应用,大数据成为重要的生产资料[4]。设法基于配送大数据来推动协同配送必然成为新的技术需求和方式。
为了促进协同配送稳健发展和解决协同配送实施中的问题,越来越多的学者对协同配送进行研究,但都主要集中在协同配送利益分配[5-6]、成本分摊[7-8]、协同配送模式[9-10]、协同配送路径优化[11-12]等协同配送联盟形成之后的活动或问题,即都假定联盟已经形成。而合理优化的协同配送联盟是以上研究成果实施的支撑,也影响以上活动的理论研究,更决定了联盟的稳定性和生命周期[13]。因此,近年有少量研究开始探讨配送联盟的组建方法问题,主要涉及协同配送联盟组建的机制和步骤两个方面。如,文龙光等[14]指出选择联盟对象是建立物流配送联盟的首要任务,阐述了配送联盟组建步骤,包括选择合适的联盟对象,组织伙伴成员谈判等6个步骤,但未涉及具体方法。袁红霞[15]提出了城乡共同配送联盟的组建过程,包括发掘配送市场需求、制定联盟发展战略、选择联盟成员企业、确定联盟组织结构等,并对共同配送利益分配机制进行了重点研究,即该文献仍集中在协同配送联盟组建后的利益分配。沈政[16]分析了快递城市共同配送的组建机制,包括快递城市共同配送联盟的管理模式、运作模式、组织体系及构建流程。于承鑫[17]通过对各种企业联盟合作模式的分析,建立了共同配送企业联盟的构建、运营及协调机制。姚安琪[18]研究了共同配送合作联盟构建机制,涉及共同配送构建的过程、配送策略、组织模式以及协调机制等内容。这些步骤和机制研究对组建物流配送联盟有一定的指导意义,但都是定性研究。为此,也有少量研究提出了定量的协同配送伙伴选择方法,如HE等[19]提出一种综合模糊熵权、模糊层次分析法和模糊排序优选技术的理想解相似性方法来选择共同配送联盟最优合作伙伴组合,并对联盟中合作伙伴组合的绩效标准进行了评估。该方法基于某个主体去选择各配送阶段最优的合作伙伴,需要决策者精通标准权重的使用,同时并没有建立标准组合绩效的定量计算方法。CHENG等[20]研究了联合配送任务可拆分为多个子任务时的合作伙伴选择问题,建立了以供需匹配度最大化和总运营成本最小化为目标的协同配送伙伴选择优化模型,但仅围绕特定任务展开。王彬颖[21]通过改进的质量功能配置模型,将现有客户对物流配送服务需求指标与物流配送服务商的服务能力指标进行匹配,再根据网购客户的需求表现度与物流配送服务商的供给表现度,建立基于网购客户物流服务需求的配送联盟伙伴选择模型,筛选出最能满足客户需求且成本较优的物流配送服务。吴楠[22]构建了针对共同配送的物流企业评价指标体系,建立了伙伴选择的初选、细选和组合优化三阶段模型,通过运用AHP-TOPSIS确定各评价指标权重对候选企业排序,运用遗传算法组合优化可从8~10家候选合作伙伴选择最优伙伴。以上方法虽然提供了定量伙伴选择决策方法,但都是基于特定的第一方主体的需求(或任务)来选择最好的合作伙伴,不具有普适性,而缺少从协调组织或第三方视角来进行伙伴识别研究。课题组前期[23]也面向协同配送联盟开展了配送属性数据的分析方法研究,基于地理社会网络构建了配送属性数据的分析方法和可视化表达方式(即基础),为从可视化方式发现联盟提供了信息支撑,但还未形成确定合理优化联盟及其成员的定量决策方法。
伙伴选择也广泛存在其他领域,尤其是供应链、虚拟企业领域[24-28],如,WANG等[24]基于动态物流联盟的特点,从物流服务能力、成本、质量等方面构建了合作伙伴选择综合评价指标体系,然后用模糊层次分析法对可能的合作伙伴进行评价,并选出了一个综合评价最高的合作伙伴;赵金辉等[26]针对虚拟企业建立过程中的合作伙伴选择问题,提出了合作伙伴选择的粗糙可拓评价方法,实现了对各候选企业的综合满意度排序,从而得到最满意企业;PRAKASH等[27]提出了基于模糊层次分析法的逆向物流合作伙伴问题选择标准和排序的组合模型,以及逆向物流合作伙伴最终选择的优化模型,以从潜在逆向物流合作伙伴中选择出最佳合作伙伴。这些伙伴选择研究都与协同配送伙伴选择一样,主要研究的是面向单个企业的伙伴选择问题(即本质上都围绕一个联盟开展),都基于某个主体的需求来构建指标和多属性伙伴选择决策模型,实现对潜在或初选的合作伙伴的排序择优,且一般只选出一个最优合作伙伴,不具有普适性,由于考量指标存在差异,也不适合协同配送。由于需要决策者或专家根据自身需求来制定指标并评价较为主观。同时应当看到,这些伙伴选择与协同配送联盟伙伴选择存在明显的不同,供应链、虚拟企业的伙伴选择有明显的供需关系,即一方为合作服务需求方,一方为服务供给方,其不存在同业务竞争,有显性合作驱动力(需求方一定需要另一方的服务才能推进业务),因此,一般都是基于需求方角度的择优,而协同配送合作企业都是开展相同业务(即配送业务)的企业,存在明显的竞争关系而非供需关系,这决定了他们缺少供需合作的驱动力,因此参与积极性不高,不能单纯地从一方角度去评价合作伙伴,更应该关注彼此的合作效益,如没有明显的合作效益彼此不可能合作。同时,当前缺少(从第三方角度)针对众多企业间协调组织形成多个联盟的研究,即缺少从第三方角度就众多企业间识别和确定组建多个联盟的定量决策优化模型和方法,特别是大数据背景下直接基于数据的协同配送联盟伙伴识别的方法。无法从众多配送中心中,为多个配送中心较为快速地识别出潜在的可长期合作的多个协同配送联盟伙伴,更无法将所有的配送中心根据某些特征构成多个协同配送联盟。限制了协同配送应用和发展。
鉴于此,本文基于大数据背景,站在第三方的统筹视角,基于对配送属性数据的分析来构建多个协同配送联盟组织的研究;基于协同配送的目标确定了协同配送可能的维度,以辐射范围重叠、社会网络重叠、出车时段互补和车辆资源互补为导向,建立基于配送属性的协同效应定量评价指标和衡量方法、基于协同效应的优化组建模型,通过优化求解,实现从多个配送中心识别出可能的多个联盟和每个联盟的优选合作伙伴。该研究为单个配送中心确定最佳的协同配送伙伴,区域政府、物流园区等第三方协调组织配送,企业开展协同配送,都提供了定量的优化决策支持方法,也为协同配送的稳定性和高效运行奠定坚实的基础。
1 配送属性数据驱动的协同配送联盟组建模型
1.1 问题描述
在现代城市配送中,已知存在m个独立开展配送业务的企业,为简化问题,设定每个配送企业只有1个配送中心,所有配送企业直接统称为配送中心,设DCi表示第i个配送中心,每个配送中心有确定的位置,其对应位置用经纬度表示,配送中心i的位置记为(pxi,pyi),则有配送中心集合I={DC1,DC2,…,DCi,…,DCm};每个配送中心有一定的业务量(订单数量)、配送量(订单的需求量即为配送量)和车辆,配送中心i(DCi)的业务数量为Qi、配送量为Bi、有车辆类型资源tpi={A,B,C,…},其中A、B、C为车辆类型;每个配送中心有n个客户(称为配送点)需要配送货物,配送中心i的客户集合为Cui={cui1,cui2,…,cuin},每个客户有确定的位置、配送时间窗要求和需求量,记配送中心i的第n个客户的位置为(cxin,cyin),需求时间窗为[Ein,Lin],需求量为qin;每个配送中心根据客户需求,考虑成本等因素确定配送出车时间,将每天分为t个时段,时段集合为T={1,2,3,…,t},则可得到配送中心的出车时段。现需要通过协同配送来提高这些配送中心的规模,提高配送效率,降低配送成本和缓解交通环境压力,需要基于m个配送中心的配送属性数据,快速识别和发现他们可优化构建多少个有协同配送效益的协同配送联盟,取得协同配送效益。用uk表示第k个联盟,假定m个配送中心可形成l个联盟,则有联盟集合S={u1,u2,…,uk,…,ul}。需要求解l的最优值及每个联盟的最优成员。
1.2 联盟组建优化模型
协同配送的本质是通过合作来实现配送规模化以提高资源利用率,从而降低成本。因此,协同配送企业间要能产生配送量的规模化才可能有协同效益。而配送量的规模化要求不同配送企业的配送业务存在交叉重叠,对存在交叉重叠部分的业务量进行整合可提高规模,降低配送成本,取得协同效益。同时在合作过程中,虽然配送企业间存在竞争关系,但由于企业间的配送车辆等资源性质不同或相同,配送联盟的资源种类和数量得到扩充,可如供应链等伙伴选择一样,基于资源互补开展协同配送(供应链、动态联盟等伙伴选择基于业务供需关系进行,本质上是基于资源互补关系进行的)。对于性质不同的资源,配送企业之间形成资源互补,弥补自身资源的不足,可提高运作水平和提高资源利用率(如5吨车改为2吨车配送减少了空载率),从而产生协同效益。本文将前者定义为交叉协同,后者定义为资源互补协同。1.1节描述的具体的配送都可通过对应的配送属性数据(如图1)来体现。下面通过对配送属性数据的分析,识别和挖掘各配送中心间业务是否存在交叉重叠和资源互补关系及其强度,反映可能获得的协同效应和协同配送组织的可能性,并构建优化模型和求解,确定最优联盟组合。
为便于求解,设
并作如下约定:
(1)配送中心之间配送的不同产品可组合到一起配送;
(2)基于协同联盟的集中配送量不超过车辆的额定载重;
(3)一个配送中心至多参与1个协同配送联盟。
1.2.1 交叉协同效应模型
每个配送中心都有自己独立的多个配送点,配送中心与配送点之间的对应关系可视为一种社会关系,因此其业务的重叠情况也体现为对应社会关系的重叠情况。为此,基于社会网络理论,将每个配送中心和其配送点都视为社会网络的节点,彼此存在的配送关系通过网络的边来表示,以配送点和配送中心的位置来确定其在网络中的位置,则可构建配送业务社会网络。当不同配送中心的社会网络表示在一起时,很容易观察其是否存在相同或相邻的配送点以及社会网络重叠情况,如图2所示。配送中心之间可对配送业务社会网络重叠部分进行协同配送。因此,通过评定配送中心社会网络重叠的程度可评价其配送业务的重合程度和构建协配配送联盟的相宜程度和预期规模效应。
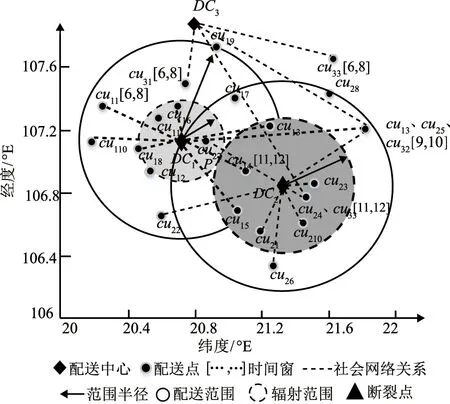
图2 配送中心间业务关系重叠识别的描述图
配送业务社会网络描述了当前的配送中心与配送点的已有静态关联关系。但运营中,每个配送中心的配送客户并非一成不变(即是动态变化的),存在不确定性和动态关联关系,但其基本的配送范围是相对固定的。基于此,通过配送的地理范围来处理:以每个配送中心为圆心,以该配送中心最远的配送点到其的距离为半径作圆,将此圆定义为该配送中心的配送范围,其间包含了配送中心现有客户,也包含了该范围的所有潜在客户。但在该范围,始终都会有配送距离较近的客户,其配送成本相对较低,配送中心对其辐射能力较强(对应范围为经济辐射范围),也会有距离较远的客户,其配送成本相对较高,即不经济,辐射能力较弱。配送中心可通过联盟重新分配配送任务[28]来打破原有的经济辐射范围边界,扩大经济辐射范围,如图2所示。可通过评定联盟后经济辐射范围的扩大程度确定两两配送中心协同的优劣和效应。
因此,交叉协同效应的评定体现在规模协同效应和辐射范围协同效应两个方面。
(1)规模协同效应
基于前面分析提出“共同社会关系强度”来反映配送中心社会网络重叠的程度,进而衡量协同配送的规模效应,定义为配送中心之间配送业务的重叠比例,即配送联盟共同配送域的客户数量之和与各配送中心客户数量总和之比,其中配送域是指根据客户点地理位置、需求时间相似以及对应的配送中心点地理位置相似性划分的客户群,同一配送域内业务的配送网络高度重叠、可进行协同配送(常规配送中对相邻点一般都同次配送,对协同配送,如果只对与两个配送中心相同的配送点进行整合,则与其相邻点需要另外配送,可能增加成本)。可见,配送中心的共同社会关系强度越大,则协同后的规模效益越大,配送中心协同的可能性越高。以上评定只对期望参与协同配送的多个配送中心才有意义,即xiuk=1;若用D(i,h)=1或0分别数字化表示配送中心i是否有配送业务分布在配送域h(直接基于配送属性数据判定),D′(uk,h)=1或0分别表示配送联盟uk是否所有成员都有业务分布在配送域h,则
协同配送联盟的共同社会关系强度(CSRuk)计算为:
(1)

(2)辐射范围协同效应
根据辐射力模型[23],两配送中心间会产生一个辐射力平衡点(即配送中心断裂点)和相对经济的配送辐射范围。文献[23]在计算断裂点距离时仅考虑配送中心的配送量和配送中心之间的距离,忽略了配送中心与客户的距离对配送中心辐射力的影响。因此,本文将配送中心与客户的距离考虑到配送中心断裂点距离计算中,有:
(2)
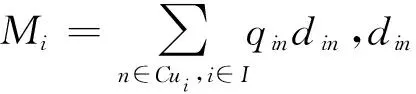
(3)
采用配送中心的平均辐射半径作为其辐射范围,以衡量多个配送中心之间的辐射力情况。配送中心之间若存在配送辐射范围重叠,则表明配送中心距离较近,且有配送点落在对方的经济配送范围内,联盟后运输距离合理且扩大了经济配送量,产生辐射范围协同效应。在配送中心辐射力模型基础上,提出配送中心经济配送占比来评价辐射范围效应,定义为配送中心在平均辐射半径内的配送量与配送总量之比;联盟的经济配送占比越高,说明联盟在经济配送范围业务占比越大,联盟的辐射范围协同效用值越大。为此,用C(i,e)=1或0分别表示配送中心i和e辐射范围是否重叠;用C′(uk)=1或0分别表示配送联盟uk的成员辐射范围是否两两重叠,具体有
则协同配送联盟uk的经济配送占比(Edruk)模型为:
(4)

1.2.2 资源互补协同效应模型
资源互补可促进联盟形成和发展,提高联盟成员之间的相互依赖性和合作效率[29],现有的供应链等伙伴选择实际上基于资源互补开展。因此基于多个配送中心的资源互补性来协同配送具有潜在的协同效应。配送业务的资源主要包括配送车辆、配送人员和路权。而人员不是关键因素,路权资源主要依赖于拥有的车辆资源类型,本文将其等价于车辆资源考虑。另一方面,由于每个配送中心为了节约成本等原因而综合调度优化得到的配送时间、频次不同(相对固定),导致配送的服务水平出现差异,使得配送时间实质上也具有资源的功能,形成出车时段互补,如在时段8:00~10:00,配送中心1、2在某个配送域均有配送任务,但只有中心1调度出车配送,但其车辆装载率极低,此时如联合中心2配送,无疑提高了中心2的服务水平和中心1的车辆利用率,降低其成本。因此认为配送的资源也包括配送时间和出车频次。则其资源互补协同涉及配送车辆(类型、载重、载容)、配送时间、出车频次资源,具体由车辆(类型、载重、载容)、配送时间、出车频次、配送主体关系、配送主体地理位置等配送属性数据来描述。通过评定配送中心间资源互补程度可评价其协同配送组建的潜力和资源互补效应。基于此定义了配送中心出车时段互补强度和配送中心车辆资源互补强度两个指标。
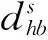

则配送联盟出车时段互补强度TRuk可如式(5)计算:

(5)
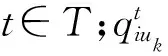
配送中心车辆资源互补强度指配送中心车辆类型的异质程度。设配送中心i和j的车辆资源合集分别为tpi、tpj,则定义配送联盟的车辆互补资源互补强度VRuk按式(6)计算:
(6)

1.2.3 优化模型
由以上分析可知,配送中心间的规模效益越大,配送中心协同的可能性越高,辐射范围协同效应越大,经济配送占比提高更多,越有利于组织协同配送;出车互补强度越大,配送中心协同之后车辆的利用率和配送的及时率提高得越多,异质程度越大说明配送中心协同之后能扩充的资源类型越多,协同的可能性更大。因此,将交叉效应值和资源互补效应值两个维度的综合协同效应值最大化作为组建稳定协同配送的优化目标,但二者性质不同,为此引入权重区分和协调。则综合得到的协同配送的组建优化模型为:
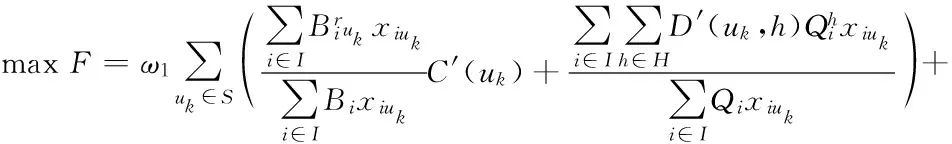
(7)
s.t.
(8)
(9)
C′(uk)=1,uk∈S;
(10)
(11)
ω1+ω2=1;
(12)
xiuk={0,1},uk∈S,i∈I。
(13)
其中:ω1、ω2为权重,式(8)表示配送联盟至少存在一个共同配送域,式(9)表示配送联盟至少存在一个出车时段互补,式(10)表示配送联盟成员需两两辐射范围重叠,式(11)表示每个配送中心至多参加一个联盟,式(13)为决策变量。
2 模型求解算法
直接获取的配送业务数据不符合模型的数据要求。因此模型整个求解分为数据预处理、配送联盟寻优两个阶段,如图3所示。其中数据预处理阶段完成配送域划分等操作,为模型提供输入数据;配送联盟寻优阶段基于数据预处理的数据,找出协同效应最大的协同配送联盟组合。
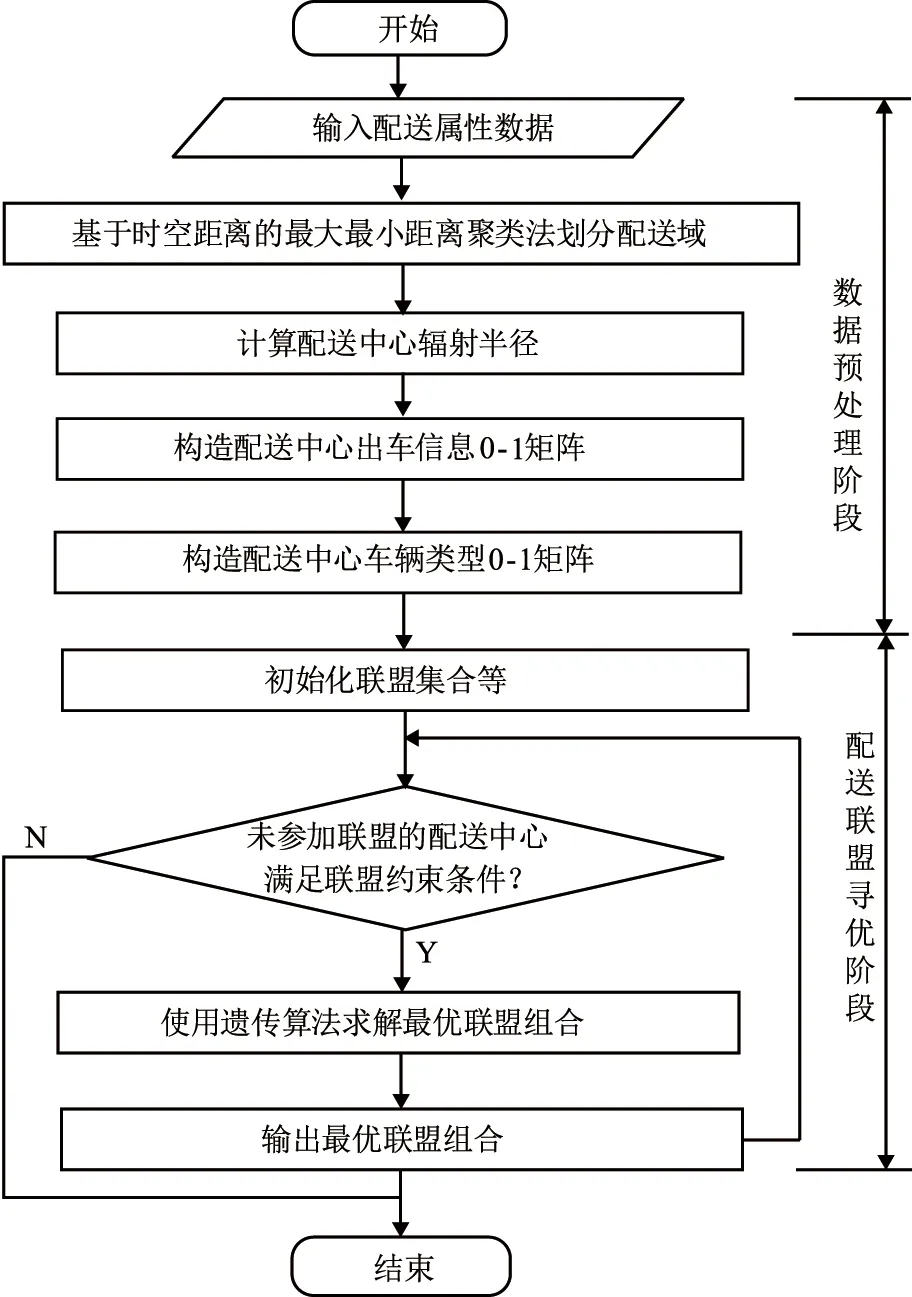
图3 算法流程图
2.1 数据预处理
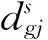

图4 数据预处理流程图
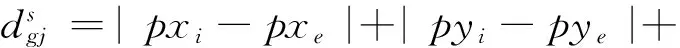
(14)
式中:|pxi-pxe|+|pyi-pye|表示DCi到DCe的转运曼哈顿距离,|cxg-cxj|+|cyg-cyj|表示cuig、cuej间的距离。
配送业务的时间距离通过改进文献[30]对客户时间距离的度量方法来计算,协同配送机会发现不涉及配送路径规划的早到晚到惩罚,因此去除早、晚到惩罚系数,保留其偏差系数。取业务的时空距离为客户的时间和空间距离的加权和,设时间距离的权重为α;引入时空距离转换系数ε来解决量纲问题。综上,得到客户cuig和cuej的时空距离为:
(15)
基于此划分配送域,具体步骤如图4所示。
2.2 寻找最优的配送联盟
1.2.3节的模型是组合优化问题,由于配送中心较多(决策变量多),传统的线性规划、穷举等精确方法虽能计算出全局最优结果,但难度较大且计算时间成本高。遗传算法依赖高效并行搜索优化能力,通常能够较快地获得较好的组合优化结果。因此,根据配送中心联盟组建联盟模型特点设计循环的遗传算法来求解出多个最优联盟组合,关键要点如下:
(1)编码。染色体长度为配送中心的数量,每位编码的位置代表对应编号的配送中心,值为1表示参与联盟(0表示不参与),则每条染色体代表一个联盟。如编码101000表示该区域共有6个配送中心,其中配送中心1和3形成一个联盟。设定每个配送中心只能参与1个联盟,为了避免某配送中心重复参加联盟组建,对已参加联盟的配送中心,在循环时设定其编码值为0,然后以该位置为中心,对其左右段分别使用随机二进制数编码,例如在以上6个配送中心的联盟问题中,若配送中心1和3已参加联盟,则设置编码的第1、3位置为0,对位置1和3之间(第2位)和位置4、6之间采用随机生成0或1方式填充。
(2)适应度函数。将目标函数进行指数变换得到适应度函数,取α=-0.5。
(3)交叉和变异操作。产生染色体长度内的两个随机整数来截取随机数间的染色体的片段进行交换。如对101010、010101,生成6以内的两个不同随机整数2和4,则交换它们第2、4之间的基因,可得到1|101|10和0|010|01。设交叉概率为0.8。通过随机选择和交换单个染色体上两个位置的基因来实现变异,设定变异概率为0.03。
(4)根据配送中心规模随机生成初始种群,采用轮盘赌策略进行选择操作。
3 实例分析
下面以南宁市主城区20个配送中心为例,来展示基于本文模型和方法组建多个协同配送联盟的过程,验证该方法的可行性,并通过对求解结果的分析验证其有效性。通过调研、爬虫等获取20个配送中心的配送属性数据。20个配送中心车辆类型信息和业务基本信息分别如表1和表2所示。将出车时段00:00~24:00均分为12段,随机取配送中心的1 008组业务进行研究,配送中心的配送网络如图5所示。通过式(2)和式(3)计算得到各配送中心的平均辐射半径,可视化后如图6所示,可见配送中心的配送网络存在明显的交叉重叠区域,有协同的潜力。

表1 南宁市主城区20个配送中心的车辆类型信息

表2 配送中心基础信息表
图5 南宁市主城区20个配送中心配送网络

图6 南宁市主城区20个配送中心辐射范围
3.1 数据预处理与求解
根据2.1节的方法,基于时空距离的最大最小距离聚类法划分20个配送中心业务配送域,选择第51个样本为第一个聚类中心Z1,算法则会选择距离第51个样本最远的样本Z2为第二个聚类中心,在样本中Z1和Z2的时空距离为73.987 km;取θ=0.25以控制类内距离不超过18.5 km,α=0.2,ε=30km/h,聚类得到33个配送域。得到的各配送中心在各配送域的业务量分布、配送中心的辐射半径、配送中心的各时段出车信息0-1矩阵、每个配送中心拥有的车辆类型矩阵如图7所示。

图7 配送属性数据预处理
设置遗传算法参数种群数量为900,迭代次数为400,其中联盟交叉协同效用值和资源互补效应值的权重设为ω1=0.6,ω2=0.4。经过寻优,共得到6个最优联盟组合,表明存在6种协同配送的可能,如表3所示。配送中心1、3、6和19被淘汰,没能参与配送联盟。各个协同配送联盟的规模不同,联盟u2、u4、u5有两个成员,u3、u6有3个成员,u1有4个成员,这突破了以往伙伴选择方法中只围绕一个联盟展开,只能选出一个最优合作伙伴的局限。
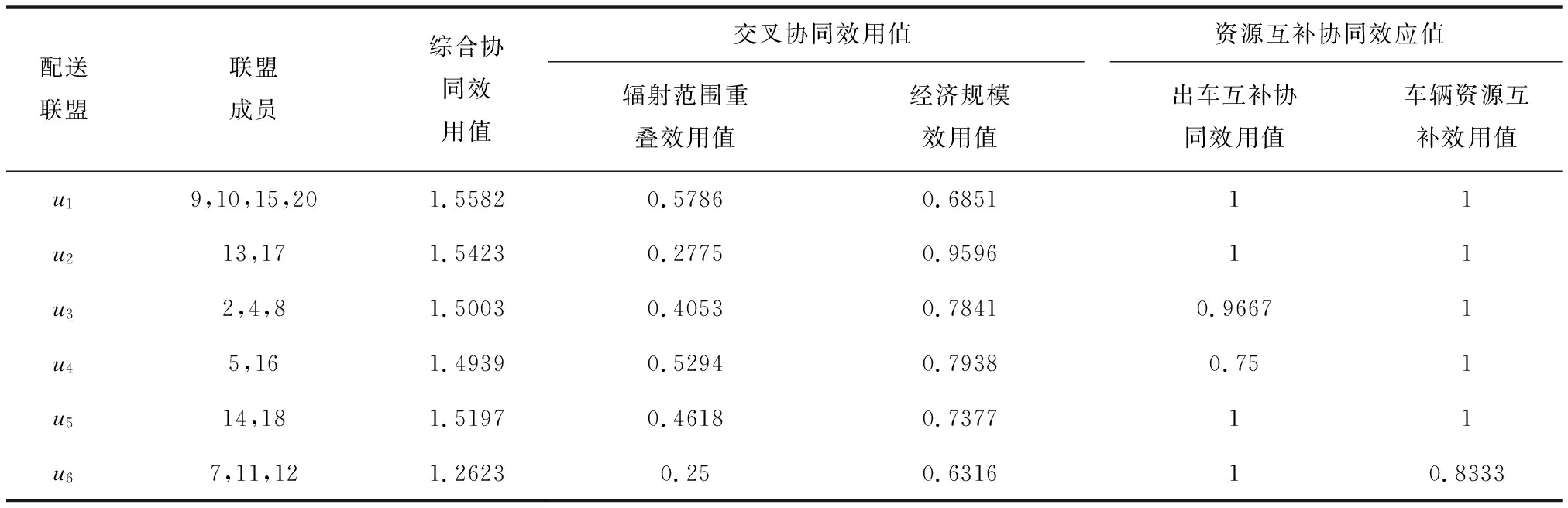
表3 南宁市主城区最优配送联盟组合
3.2 结果分析
协同配送联盟的综合效用值受到交叉协同、资源互补协同两个维度效用值的大小及其权重的影响,每种效用对综合效用值的贡献不同。如表3所示,6个联盟中,每种协同效应出现了波动,这表明其协同时存在最佳维度。如联盟u1虽然综合效应值最高,但其经济规模协同效用值并非最高,其综合效应最高主要是因为其辐射范围重叠效用、出车互补协同效用和车辆互补效用最高。按交叉协同效用权重0.6计算,可知其中辐射范围效用、经济规模效用、出车互补协同效用和车辆资源互补效用对综合效应的贡献度分别为22.3%、26.38%、25.67%、25.67%。由此可见,联盟u1资源互补协同效用对总效用的贡献较大(虽然其权重更小,但贡献超过50%),可知联盟最佳协同维度是资源互补维度,需要说明的是两个维度的协同并不互斥,可并行进行。各联盟每种效应值趋势以及对总效应的贡献情况如图8所示,其中折线反映了每种效应值在联盟之间的变化以及各联盟每种效用值的排名。由折线可知,辐射范围效应值和规模效用值的波动较大,说明各联盟的经济配送水平和规模化水平相差较大,由联盟u1、u3、u4、u5和u6的辐射范围效用和规模效用值变化趋势可知,辐射范围效用值越大的联盟规模效用值越大,这是因为辐射范围重叠表明配送中心相近(配送起点近)、辐射范围重叠处存在共同的客户(配送终点近)的几率也比较大,而配送起点和终点的相似度正是衡量规模效应的因素;出车互补的效用值和车辆资源互补的效用值波动较小,且联盟的出车互补的效用值和车辆资源互补的效用值普遍较高,说明配送中心存在很大的资源互补机会。由图8中的柱状图可知,虽然每个联盟的资源互补效用值普遍比交叉协同效用值大,但在权重的影响下每个联盟两个维度的效用贡献相差并不大,说明联盟不存在绝对优势的协同维度;其中,联盟u4的最佳协同维度是交叉协同维度,其他联盟的最佳维度都是资源互补协同维度,说明配送中心协同之后间接的资源互补效应相对配送集约规模化效应更为明显。以下对联盟的每种效用值进行分析。
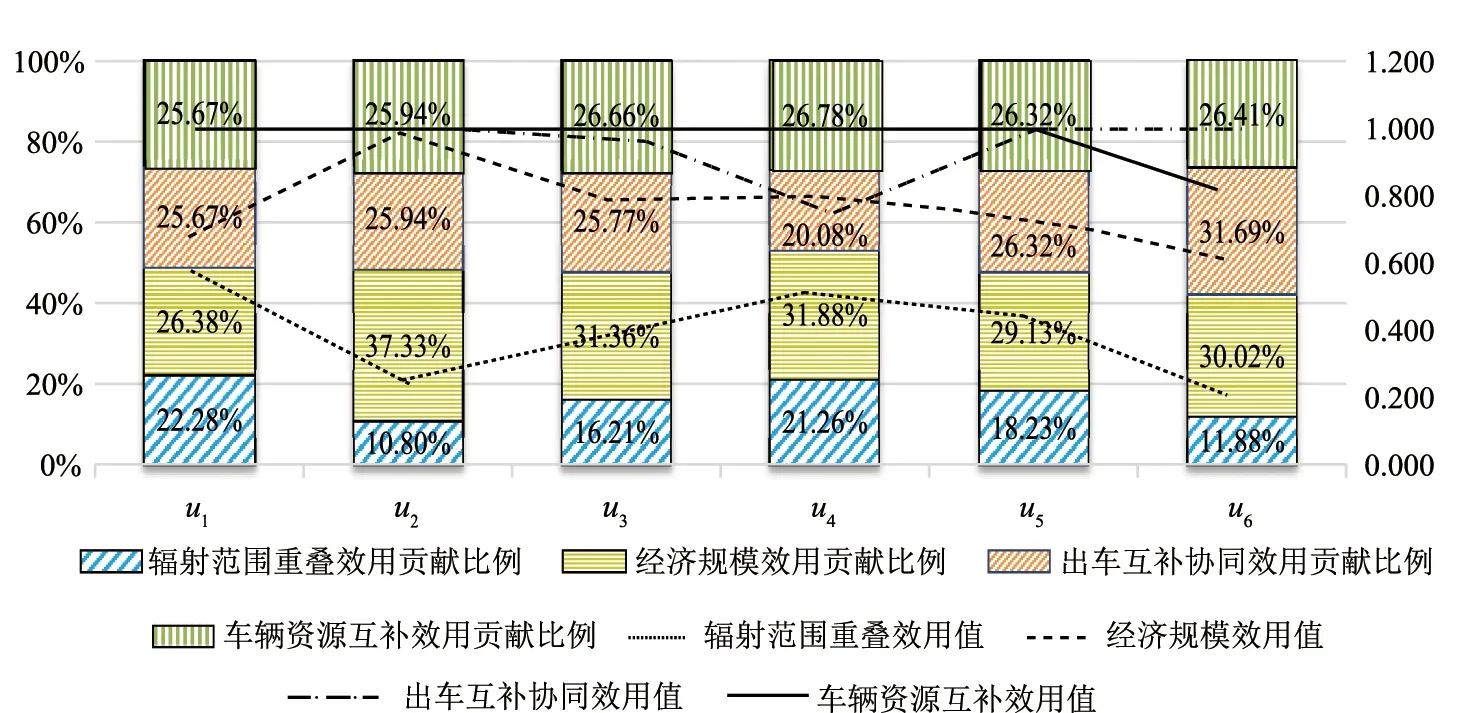
图8 配送联盟各效用与总效用的占比图
辐射范围重叠效应值反映了联盟辐射半径内的配送量占联盟总配送量的比例,例如,联盟u1的辐射范围重叠效应值0.578 6,表示其有57.86%的配送量在辐射范围之内。各配送中心联盟前后的经济配送占比如图9所示,每个联盟可根据成员原本的效益以及联盟之后提升的效益,合理分配成员的权利和利益,从而保持联盟的稳定性。例如,配送中心9在联盟之后提升的经济配送占比最大,提升了0.34,联盟之后受益最大,可指导其成为协同配送具体联盟的主要推动者和维护者,在协同配送利益分配时,降低效益分配比例,维护联盟的稳定;配送中心4在联盟的经济配送占比提高的最少,仅提高了0.03,但其联盟之前的经济配送占比最高,高达0.521,说明该配送中心本身的辐射范围较大或配送点分布较为合理、配送的效率较高、有较强的实力,有成为联盟盟主的潜力,在协同配送利益分配时,提高效益分配比例。配送联盟可根据联盟成员的辐射半径对业务重新分配,来提高配送中心经济配送量。例如,联盟u1可根据联盟辐射范围对配送中心9的业务重新分配,在联盟之前配送中心9的辐射范围和业务分布如图10所示,只有cu97、cu98、cu99、cu928、cu929、cu930、cu932、cu933等8个配送点在经济辐射范围内,联盟之后配送点cu92、cu93、cu94、cu96、cu910、cu911、cu912(新增)落在配送中心20的辐射范围内,可将这些配送点分配给配送中心20,配送点cu95落在配送中心20和15的辐射范围内,该配送点具有较大的柔性,可分配给其中的任一配送中心进行配送,此外,在配送中心9辐射范围内的配送点cu97、cu98、cu99、cu32落在配送中心10的辐射范围内,在配送中心9辐射范围内的配送点cu928、cu929、cu30落在配送中心15的辐射范围内,这些配送点同样有较大的柔性。可见,联盟重新分配业务后,配送中心9的经济配送点增多,处于配送中心辐射范围重叠处的配送点可由任一配送中心进行配送,存在较多的配送可能。

图9 配送中心联盟前后经济配送占比对比图

图10 联盟u1中配送中心9联盟前后配送点分布以及辐射范围
经济规模效用值反映了联盟重叠的业务数量占联盟总业务量的比例,联盟可对重叠部分进行协同配送以扩大配送规模。例如,联盟u1的经济规模效用值为0.685 1,表示其有68.51%的业务存在重叠。根据1.2.1节的分析可知,配送业务在同一配送域则认为业务重叠、可以协同配送,据图7a划分的配送域结果可知联盟u1有配送域1,16,21,27和31等5个共同配送域,共有68.51%的业务在共同配送域上。各联盟共同配送域拥有的共同配送域和业务重叠情况如表4所示,其中联盟u2的共同配送域最多,共有9个共同配送域,有95.96%的业务在这9个配送域上,其他联盟也都有超过60%的业务重叠,对重叠业务协同配送后可大幅度提高配送规模而降低配送成本。这也反映了本文方法对提高规模化的协同配送成员的识别准确有效。
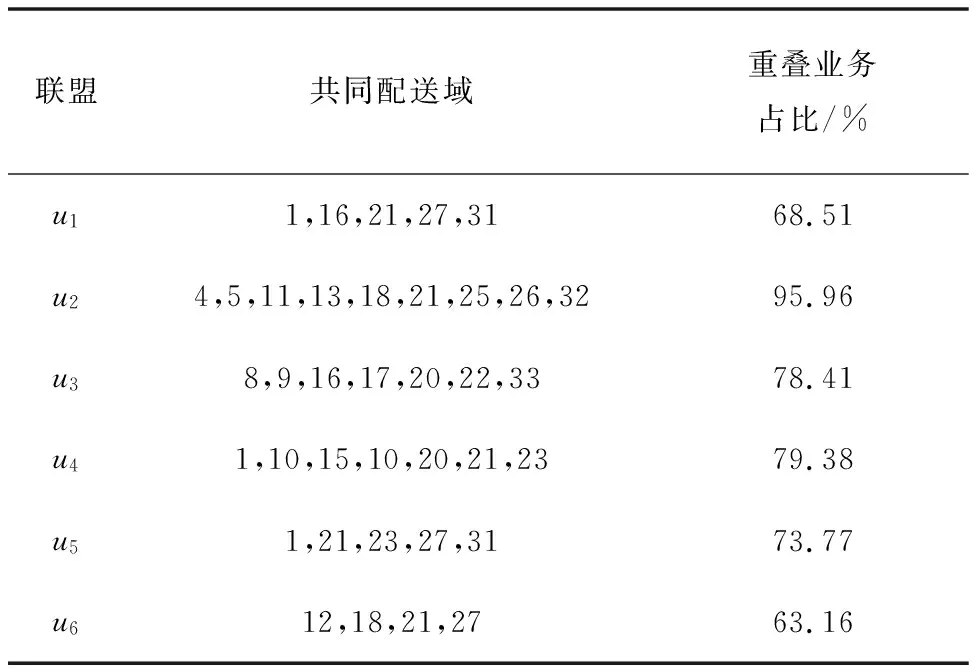
表4 联盟共同配送域与业务重叠情况
出车互补时段效用值反映了联盟成员出车互补时段相似的业务量与原来不出车的业务量之比以及成员间出车互补关系的密度。例如,联盟u1、u2、u5、u6的出车互补效用值都为1,说明联盟每个成员所有不出车时段的业务量与其他成员的出车时段的业务相似,且出车互补关系的密度大,两两成员之间都存在出车互补关系,这有利于提高配送的及时率;而联盟u3和u4的出车互补效用值都小于1,说明联盟有成员在不出车时段的业务与其他出车时段不相似或与其他成员没有形成出车互补时段,联盟u3的配送中心8在不出车时段12:00~14:00共有4组业务,其中有1组业务和该时段出车的配送中心2的业务不相似,联盟u4的配送中心5在不出车时段18:00~20:00与配送中心16没有形成出车互补时段。联盟通过出车互补减少配送中心不出车的配送量,各配送中心联盟前后不出车业务量对比如图11所示,除配送中心5和17外其他配送中心在联盟之后不出车的配送量都得到减少,其中配送中心17原本的出车频次刚好满足其配送的频次需要,联盟前后的不出车配送量都为0,该配送中心的及时率较高;而配送中心5在和配送中心16联盟后,不出车配送量没有得到减少,正如图8所示,联盟u4的最佳协同维度是交叉协同而非资源互补协同。每个联盟的出车互补时段如表5所示,联盟u1有5个出车互补时段,u3和u6有4个出车互补时段,u3有3个出车互补时段,而u2和u4只有1个出车互补时段,可见联盟成员越多出现出车互补的概率越大。此外,u2只有1个出车互补时段但其出车时段互补效用仍然是1,可见配送中心13不出车配送量在配送中心17得到了帮助且配送中心13原本也只有1个在其需求时段不派车,因此从出车互补时段层面,配送中心17是联盟中有实力的配送中心,应给配送中心17分配更多的权利和利益。

表5 配送联盟出车互补时段

图11 配送中心联盟前后不出车业务量对比图
车辆资源互补效用值反应了配送联盟成员不同车辆类型的数量与联盟总车辆类型的数量之比。联盟u1、u2、u3、u4、u5的车辆资源互补效用值都为1,说明这5个联盟中每个成员都至少有一种或多种车辆和其他成员的车辆类型不同(存在互补),如u4中配送中心5的车辆类型合集tp5={面包车,高栏式小货车,高栏式中货车},配送中心16车辆类型合集tp6={小面包车,厢式小货车,厢栏式中货车},两配送中心的车辆类型各不相同,联盟的车辆资源异质性较大。而u6车辆资源互补效用值为0.833 3,反映该联盟成员拥有同种车辆,由图7可知u6所有成员都有中面包车。各联盟的车辆资源互补情况如表6所示,联盟u1、u3、u4、u5在6种车型都存在互补,u2和u6在5种车型上存在互补,说明配送中心联盟之后得到了很好的车辆类型扩充,有利于优化运作;u2没有形成小面车互补,但其车辆资源互补效用值为1,这是因为u2没有小面包车。由此可见,由配送属性数据驱动组建的协同配送联盟,可得到较好的车辆资源互补效果,为配送中心的配载优化和路权拓展提供了更多种可能,这为取得协同效应提供了支撑。
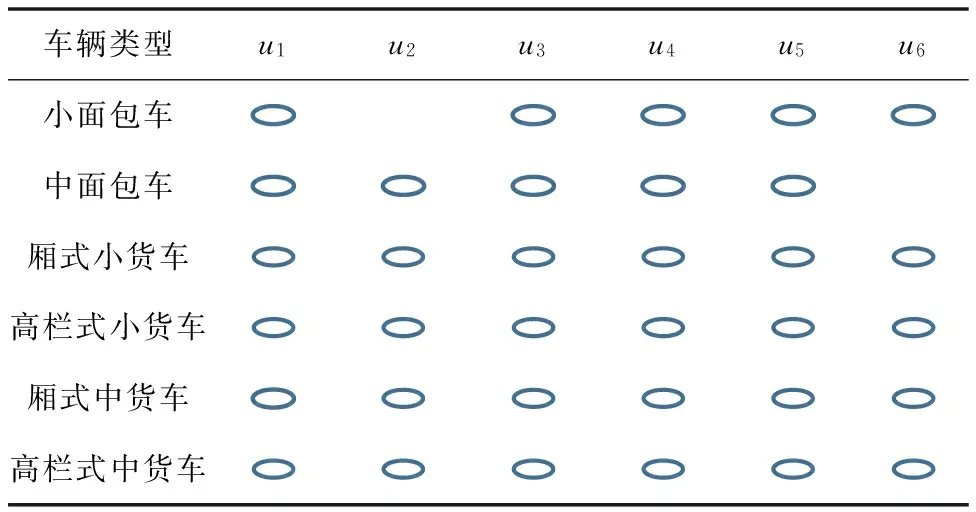
表6 配送联盟车辆资源互补情况
综上分析,得到的6个联盟有着不同的联盟规模和潜在协同配送机会,在配送辐射范围和配送网络上存在着交叉重叠,在出车时段和车辆资源上存在着互补,为这些配送中心的协同配送提供了方向和策略基础。与其他中间求解结果(即非最优解)进一步对比显示,最优联盟组合中联盟综合效应值都高于非最优解联盟组合,特别是经济规模效用值明显低于最优解,即最优解联盟组合的业务重叠比例非常高,有利于协同配送。这表明,本文构建的配送属性数据驱动的协同配送联盟组建模型可以有效识别多个潜在的稳定协同配送联盟,也可为单个配送中心选择最优的配送联盟组合。
4 结束语
本文针对协同配送联盟组建研究定性化,联盟伙伴选择单一化问题,站在第三方视角,提出了由配送属性数据驱动的快速识别联盟伙伴和联盟组建方法。为大数据下的协同配送组织和数据分析提供了支撑方法。构建了配送属性数据驱动的协同配送联盟组建模型和求解方法,实现了协同配送伙伴和联盟的数字化以及优化识别和评定;能通过配送属性数据一次并行构建出多个辐射范围重叠、配送网络重叠、资源互补的协同配送联盟,并为单个配送中心确定最优联盟组合;避免了主观的评价和排序,也突破了以往单个联盟选择一个最优合作伙伴的伙伴选择模型,从根本上延长了协同配送联盟的生命周期,为协同配送伙伴选择和组建难题、第三方协调组织提供了决策方法。此外,该方法也可延用到其他领域潜在的稳定联盟组建。
基于模型可分析每个联盟的最佳维度,为实际运行提供依据。交叉协同维度的辐射范围重叠效用和规模效用相互关联,存在一定的一致性,联盟成员越多,存在出车互补时段和车辆资源互补的概率越大,每个联盟成员的基础实力、联盟之后的受益情况不同,可根据此来分配联盟中的权利和利益,由实力比较强的配送中心主导联盟、受益较大的配送中心来维护联盟,给实力较强的配送中心较高的利益份额、受益较高的配送中心分配更少的利益份额,以保证联盟的稳定性。基于此可开展协同配送组织模式的优化设计。另外,本文研究限制了配送中心仅能参加一个联盟,且默认了配送中心货物的兼容性。因此,下一步将考虑配送中心参与多个联盟和配送货物的兼容性组建配送联盟和组织模式设计问题。
