基于分布式深度神经网络的刮板输送机启停工况故障诊断方法
2023-10-10吕彦宝崔红伟牛锐祥孟祥龙
丁 华, 吕彦宝,3, 崔红伟, 刘 俊, 牛锐祥, 孟祥龙, 施 瑞
(1. 太原理工大学 机械与运载工程学院,太原 030024; 2. 煤矿综采装备山西省重点实验室,太原 030024;3. 江阴兴澄特种钢铁有限公司,江苏 无锡 214429; 4. 山西煤矿机械制造股份有限公司,太原 030031)
在物联网、大数据、边缘计算、人工智能等新兴信息化技术的推动下,矿山安全生产管理也不断向智能化、智慧化的方向发展[1-3]。刮板输送机是综采工作面唯一与采煤机和液压支架配套使用的运输设备,其工况差、负载大、受冲击多,工作过程中极易出现故障,实现刮板输送机实时精确的故障诊断对提高综采工作面智能化水平,促进煤矿智化建设具有重要意义。
由于刮板输送机具有多变量、强耦合和非线性等特点,建立复杂部件与系统的数学或物理模型十分困难,数据驱动的故障诊断方法逐渐获得重视并成为故障诊断领域的重要研究热点[4]。该方法大致分为以下两个方面[5]:
一是基于信号处理算法的研究,即利用快速傅里叶变换、经验小波变换、解析模态分解法等信号分析方法,通过与理论计算或经验知识比对,实现对故障部位、类型甚至程度的判定。文献[6]利用经验小波变换和时频区间分量重构的方法,构建了用来反映信号冲击频域分布特征的时频峭度谱,以此实现轴承的故障检测。文献[7]利用解析模态分析法提取滚动轴承故障频段的信号并求其频谱,以此来判断提取的信号中是否有故障频率。
二是基于机器学习算法的研究,机器学习时期分为3个阶段。第一阶段为连接主义,即利用基于渐进理论构建的感知机、人工神经网络等模型,对信号处理后的故障特征自动分类。文献[8]选取振动信号时域特征参数作为轴承故障特征,基于双层萤火虫算法的神经网络识别多负载工况下的轴承故障。第二阶段为统计学习,即利用基于统计学理论构建的支持向量机等模型,对信号处理后的故障特征自动分类。文献[9]利用经验解析模态分解和正交监督线性局部切线空间对齐的方法提取轴承故障特征,通过最小二乘支持向量机实现轴承故障在小样本下的有效诊断。第三阶段为深度学习,即在连接主义的基础上结合卷积神经网络(convolutional neural network,CNN)、深度残差网络等模型,对信号自动提取特征和分类。文献[10]将多尺度一维卷积神经网络中卷积核数目和尺度作为粒子群优化的粒子,在非经验指导下获取最优参数,对风机基础螺栓进行松动识别。文献[11]将基于注意力机制的挤压与激励网络结构引入到残差神经网络残差块之中,识别载荷变化以及信号受到噪声污染工况下的轴承故障。
然而,第一类方法仅能有效地识别某类特定的工况,泛化能力低且提取故障特征的过程十分依赖人工经验,存在计算过程复杂和耗时的问题。第二类方法的前两个阶段能够有效地自动识别多类故障,但仍需人工经验提取故障特征。第三个阶段实现了故障特征的自动提取和多类故障的识别,但随着传感器产生的海量数据和深度学习模型网络深度的不断加深,传统的集中式云计算深度学习模型存在诊断延时和通讯成本显著增加的问题。
近年来,边缘计算和深度学习理论的融合为解决上述问题提供了可行的解决方法[12-15]。文献[16]提出了一种面向边缘计算的深度学习分布式深度神经网络(distributed deep neural network, DDNN)模型,通过边缘端模型样本置信度判断,可提前退出部分样本,减少后续网络层的样本量和通讯量,文献[17]针对CNN复杂模型需要使用强大的硬件来训练和部署,提出了卷积特征袋(convolutional bag-of-features, CBoF)的池化方法。该方法结合特征袋模型,将可训练的径向基函数神经元用于量化最终卷积层的激活,减少了网络中的参数数量,解决了边缘端计算和存储能力有限而受到限制的问题。基于上述理论,本文提出一种基于分布式深度神经网络的刮板输送机启停工况故障诊断方法,将刮板输送机监测数据转化的二维图像样本作为输入,利用边缘端设置的退出点,对网络置信度高的样本进行提前退出和分类,无需向云端发送任何信息,对于边缘端退出点无法处理的样本,将其在共享卷积层的特征向量发送到云端,使用额外的神经网络层执行进一步的推理,并输出最终的分类诊断结果。该方法使边缘端和云端计算资源利用率得到最大化,避免诊断过程中通讯资源的浪费,解决大量数据因远距离传输而导致的诊断延时问题,尤其是CBoF的引入,使得边缘端模型参数得到量化,改善边缘端计算能力和存储能力不足的缺陷,显著提升DDNN的诊断性能。
1 刮板输送机启停工况故障分析
刮板输送机是一种以挠性体作为牵引机构的连续输送机械,主要由机头(尾)传动部、中间部、推移装置及附属装置等组成。刮板输送机负载量大、运距长、启动频繁,故障产生源头集中在启动和停机状态,根据实际故障数据统计和故障机理,对刮板输送机的过载停机、卡链停机、重负载启动、启动功率不平衡和重复启动5种启停工况故障进行分析和识别。
通过对2020—2021年度某矿业集团4个煤矿智能综采工作面刮板输送机启停故障的统计,刮板输送机过载停机、卡链停机、重负载启动、启动功率不平衡和重复启动5种启停故障的具体统计数据如表1所示。其中过载停机故障率在40%以上,因过载停机后未及时清理负载的煤炭,导致重负载启动和启动功率不平衡的故障率之和接近过载停机的故障率,重复启动故障率在15%上下浮动,卡链停机故障率占比较小,稳定在2%以下。上述统计数据为刮板输送机启停工况故障诊断的必要性提供了事实依据。根据刮板输送机启停工况故障机理,各故障原因分析如下:
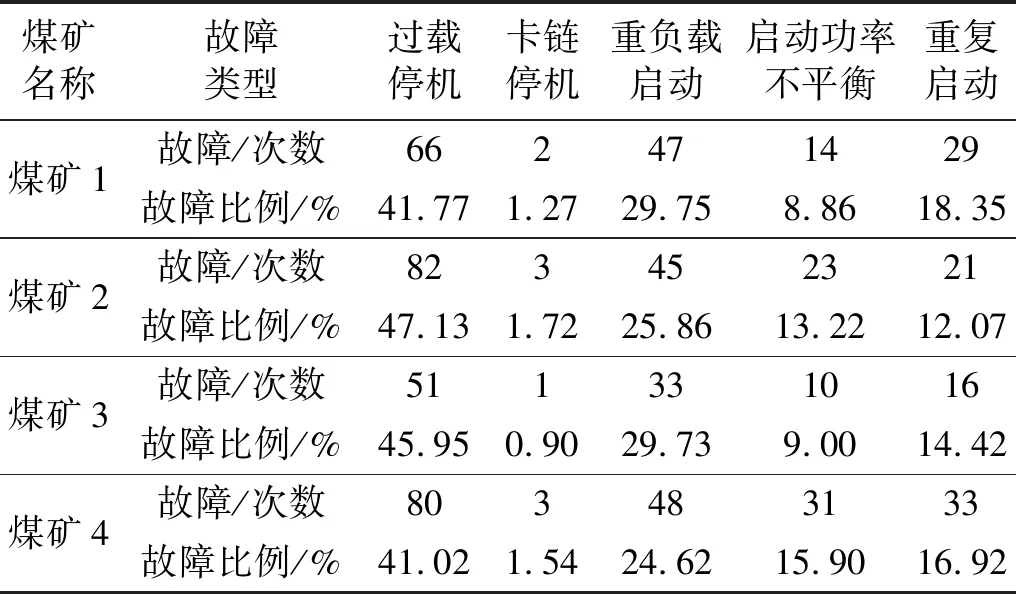
表1 2020—2021年度某矿业集团智能综采
(1) 过载停机。在实际生产过程中,刮板输送机经常出现因片帮、垮顶、负荷过重,导致减速器和电机处于超负荷状态,进而出现死机现象,影响整个输送机的可靠性。
(2) 卡链停机。刮板输送机在运行过程中,由于其底层运输大量的煤石而产生较多的浮煤、碎石等杂物、溜槽对口的错位、现场工作人员未严格按照刮板输送机的操作流程进行操作等原因,导致刮板输送机出现卡链现象,当刮板输送机发生卡链故障时,刮板会产生扭摆,易出现断链事故[18]。
(3) 重载启动。在实际生产过程中,为了确保整个综采工作面的安全生产或出现一些突发事故的情况下,常要求刮板输送机停机配合检查,而在再次启动时,由于刮板机上的原煤未及时清理,刮板输送机常处于满载或者超载状态。刮板输送机经常在重载工况下启动,会造成强烈的机械冲击,进而可能烧坏电机、使链条断裂、将链轮上的齿轮打坏等[19-20]。
(4) 启动功率不平衡。由于刮板输送机启动前的负载大小、位置及机头机尾电动机的启动时间差等因素,使得负载功率无法按比例分配至刮板输送机的不同电机,出现电机功率不平衡的现象。严重的功率不平衡可能造成设备零部件寿命缩短、电机烧毁、运行效率降低等问题[21]。
(5) 重复启动。刮板输送机在启动时,因变频器电路或信号反馈问题,导致刮板输送机多次启动的现象,刮板输送机的重复启动,加速了零件的磨损,影响其使用寿命。
2 基础理论
2.1 卷积神经网络
CNN是基于卷积运算与深度网络结构的前馈神经网络,主要由卷积层、批归一化(batch normalization,BN)层、激活层、池化层、全连接层等组成。
卷积层通过卷积核的移动实现输入数据的降维和特征提取,其内部包含多个卷积核,每个卷积核都对应一个权重系数与一个偏差。卷积层运算数学表达式为
(1)
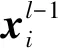
BN层通过引入均值和方差的运算,使数据同分布、更稳定,加快网络训练速度,使模型收敛更快。其数学表达式为
(2)
式中:μ为同时输入的一组数值的均值;σ为这组数值的方差;ε为一个极小的数,防止分母为零。
激活函数在网络学习中可以实现数据之间的非线性拟合。通常使用线性整流函数作为激活函数,其函数数学表达式为
f(x)=max(0,x)
(3)
池化层对卷积后的特征进行进一步降维和提取,常用的有平均池化和最大池化,原理分别是输出核覆盖范围内所有数的平均值和最大值。
全连接层将卷积和池化的输出进行非线性拟合,通过softmax分类器,实现提取特征与样本标记的对应。
2.2 分布式神经网络
DCNN具有多层结构,其表达学习也是层级分布的,对输入向量而言,海量数据的远距离传输及其神经网络的逐层传输都会带来延迟,而且随着运算参数不断累积,计算耗能也逐层增多。DDNN作为一种面向边缘计算的深度神经网络,具有分布式计算层次结构,不仅能在云端进行深度神经网络的推理,还能在边缘端上使用神经网络的浅层部分进行快速、本地化推理。DDNN由边缘端小型神经网络模型和云端较大的神经网络模型组成,其框架如图1所示。边缘端小型模型可以快速地进行初始特征提取,在置信度可信的情况下,对数据进行退出并输出分类结果,边缘端未退出的数据会传递到云端的大型网络模型中,进行下一步的特征处理和分类。DDNN与传统集中式云计算的神经网络相比,具有识别精度高、通信成本低的优点。
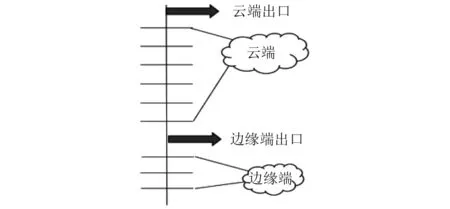
图1 DDNN框架Fig.1 The framework of DDNN
虽然DDNN模型的推理在分布式计算层次结构上分布,但其可以在单个强大的服务器或云端进行训练。与大多数传统神经网络训练不同,DDNN模型至少有两个出口点,在训练时,通过对每个出口损失值的加权求和,实现整个网络的联合训练,使每个出口点相对于其模型深度能够达到良好的准确性。模型使用softmax交叉熵损失函数作为优化目标,其数学表达式为
(4)
(5)
zk=fexitn(xk,θ)
(6)
DDNN模型通过加权损失函数对各个出口的损失值加权求和,并采用SGD(stochastic gradient descent)方法更新模型参数,加权损失函数数学表达式为
(7)
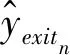
DDNN模型分支对输入图像进行快速地初始特征提取,在置信度可信的情况下,分支出口点对样本进行退出并输出分类结果,采用归一化熵阈值作为分支对样本的预测置信度,其数学表达式为
(8)
式中:C为所有标签的集合;x为概率向量;η⊂[0,1]。
η=0为置信度为1,η=1为置信度为0,使用多个预先配置的出口阈值T作为对样本预测置信度的衡量标准。如果分支出口点对预测结果有信心(即,η≤T)则退出样本并输出分类结果,否则,将未退出样本在共享卷积块中的图像特征传递到主干,进行下一步的特征提取和分类。
传统集中式云计算模型的推理通讯成本是将全部样本直接传输到云端,而DDNN模型推理是在分布式计算层次结构上分布的,其将分支嵌入到靠近数据源的边缘端,而主干则嵌入到云端。由于分支靠近数据源,故DDNN模型推理通讯成本只考虑将分支中未退出样本在共享卷积块中的特征图像传输到云端主干的通讯量,DDNN通讯成本期望数学表达式为
c=4(1-r)fo
(9)
式中:r为分支退出样本百分比;f为共享卷积块向主干输出的特征图像尺寸;o为共享卷积块向主干输出特征图像的通道数,常数4指在64位普通的Windows系统中,一个32位浮点数占据4 B。
2.3 卷积特征袋
DDNN 在边缘侧的全连接层节点越多,边缘侧模型越复杂,分类能力越强,边缘设备的计算开销也会增加,但边缘侧计算和存储资源有限,对此,需要在边缘设备资源和误差之间实现一个平衡,CBoF通过对神经网络压缩编码,可以大幅度减少参数计算量。CBoF模型结构如图2所示。
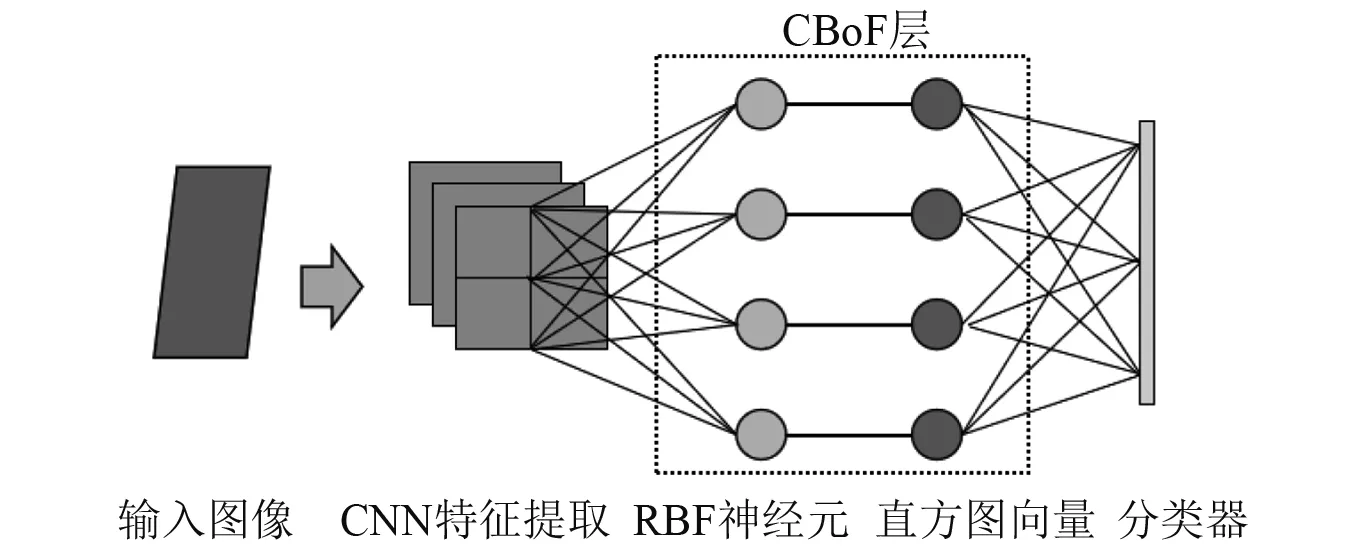
图2 CBoF模型结构Fig.2 Model structure of CBoF
构建CBoF 模型的关键步骤有3个,分别是图像特征提取、构造视觉词典以及图像的直方图表示。
(1) 图像特征提取,转化后的二维图像送入边缘侧模型后经卷积层自动提取特征向量。
(2) 构造视觉词典,通过特征向量与视觉单词的相似度来确定视觉词典中视觉单词的个数,特征向量与视觉词典的相似度用径向基函数(radial basis function,RBF)来计算,RBF第k个神经元的输出表示为
[φ(X)]k=exp(-‖X-Vk‖2/σk)
(10)
式中:X为特征向量;Vk为RBF的第k个神经元的中心;σk为核函数的宽度参数。
(3) 图像的直方图表示,视觉词典得到了特征图关于各视觉中心的相似性度量,图像的直方图表示需要对量化特征进行统计。计算公式表示为
(11)
式中:φ(Xij)=([φ(Xij)]1,…,[φ(Xij)]Nk)T∈RNk;Nk为RBF神经元个数。
3 基于分布式深度神经网络的故障诊断
3.1 模型搭建
基于第2章基础理论,所搭建的DDNN模型结构如图3所示。模型由共享卷积块、分支和主干组成,主干和分支各有一个退出点。将CBoF放置在分支最后一个卷积块后面代替全连接层,以量化卷积块最终输出的特征向量,减少模型运算参数;主干采用残差网络块和全局平均池化层结构,用来代替全连接层,增加特征向量的流动性,减少模型参数量;通过分支和主干的联合训练,实现故障特征的识别和分类。

图3 DDNN模型结构Fig.3 Model structure of the DDNN
模型参数如表2所示。模型卷积层全部采用3×3卷积核堆叠的方式提取输入图像的特征向量,以提高卷积层的感受野和非线性表达能力。共享卷积核的个数设为1,用来减少共享卷积块与主干临近卷积块之间的通讯量并最大程度的保留原始图像特征。分支两个卷积层的卷积核个数分别为4和8,主干中前两个卷积层的卷积核个数为8,其余卷积层的卷积核个数为32,卷积层的填充为1,卷积核移动步长为1。

表2 DDNN模型参数Tab.2 Model parameters of the DDNN
3.2 故障诊断流程
构建的DDNN模型故障诊断流程如图4所示,主要包括数据预处理、云端模型训练、云边协同推理三部分。
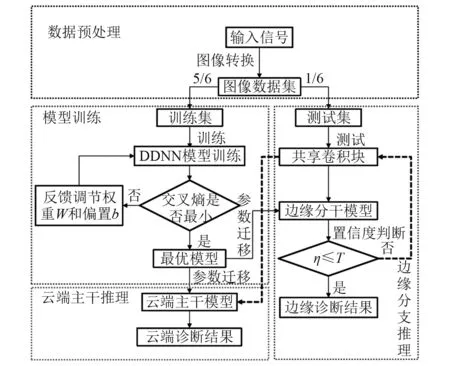
图4 DDNN模型故障诊断流程Fig.4 DDNN model fault diagnosis process
3.2.1 数据预处理
时域信号到矩阵的转换过程如图5所示。首先在大量连续样本中选取一维时间序列信号,选取方式为每784个信号点截取一次,即K=28,然后将一维时间序列信号转换的矩阵进行灰度化处理生成二维图像,此外,为更充分地提取二维图像的边缘特征,再对其进行padding=2的数据预处理。矩阵到图像的转换数学表达式为
图5 信号到矩阵的转换过程Fig.5 Signal to matrix conversion process
(12)
式中:p为二维图像的像素强度;L为数据灰度值;a,b⊂[1,K];K为二维图像的边长尺寸。
通过上述数据转换方式,对一维时域信号的曲线形数据重新排布,生成CNN擅长处理的图像数据,利用CNN的自适应学习,实现对一维时域信号故障特征的提取和识别。
3.2.2 云端模型训练
使用Pytorch深度学习框架和Python编程语言构建DDNN故障诊断模型,涉及到的参数设置如下:激活函数为Relu,目标函数为交叉熵损失函数,优化器为随机梯度下降(stochastic gradient descent,SGD),batch size为16,动量参数为0.9,初始学习率为0.1,学习率衰减值为0.000 1,迭代次数为100。
3.2.3 云边协同推理
训练好的模型完成参数迁移后,将测试集输入到模型中,在分支出口处将测试集样本的置信度η与设置的阈值T进行比较,若η≤T,则退出样本,输出边缘端故障诊断结果;否则,将其在共享卷积块中的特征图输入到云端主干模型进一步推理,输出云端故障诊断结果。
4 工程实例分析
4.1 数据来源
以上述矿业集团煤矿1的61120智能综采工作面前置SGZ-764/630型刮板输送机为试验对象,试验平台包括刮板输送机、变频器、组合开关、顺槽集控中心、汾西华益智慧云平台等,如图6所示。

图6 试验平台Fig.6 The test platform
以刮板输送机启停工况故障机理和变频器中电流传感器、电压传感器、频率传感器反映出来的机头机尾电流、转速参数值作为故障判定依据,其中,传感器返回的数据类型为float32,采样频率为每秒4次,通讯协议为Modbus。采样数据通过专线传输到云平台数据中心,每个参数值的提取方式为每49 s提取一次并将其按时间顺序转换成7×28的矩阵,通过上述4个参数转化矩阵的垂直堆叠和数据灰度处理,生成一个28×28的灰度图像。数据集共8 400个灰度图像样本,包括过载停机、卡链停机、重负载启动、启动功率不平衡、重复启动5种故障工况和轻负载启动、正常停机2种正常工况,数据集按照5∶1的比例划分为训练集和测试集,样本具体组成信息如表3所示。
4.2 数据分析
数据转换图像的方法不仅可以在二维空间内更直观地表征一维数据的分布变化,而且卷积运算在计算机领域多用于减少图像复杂度、降低计算负担。此外,利用卷积层自动挖掘图像特征,避免了人工提取特征向量过程中计算复杂、耗时以及人为因素导致的局限性等弊端。转换图像如图7所示。其整体等分为四部分,从上到下依次为机头电流、机尾电流、机头转速和机尾转速,图像中不同深度的黑白色带对应不同的数值,数据由小到大显示为由黑到白。

图7 转换图像结构示意图Fig7 Structure diagram of transformed image
刮板输送机主要技术参数如表4所示。在运行过程中,电流持续高于额定电流且突然大范围波动,转速骤降为零视为卡链停机,电流呈指数上升的趋势和转速阶梯下降为零视为过载停机。

表4 SGZ-764/630型刮板输送机主要技术参数
故障停机时域曲线及转换图像如图8所示。图8(a)电流的指数上升和转速阶梯下降为零的特征,映射出图8(b)电流位置末端由黑骤变为灰的色带,转速位置末端由白变黑的色带显著拉长。图8(c)机尾电流的大范围波动和转速骤降为零的特征,对应图8(d)机尾电流位置末端黑灰色带的相互交替,转速位置末端由白变黑的较短色带。
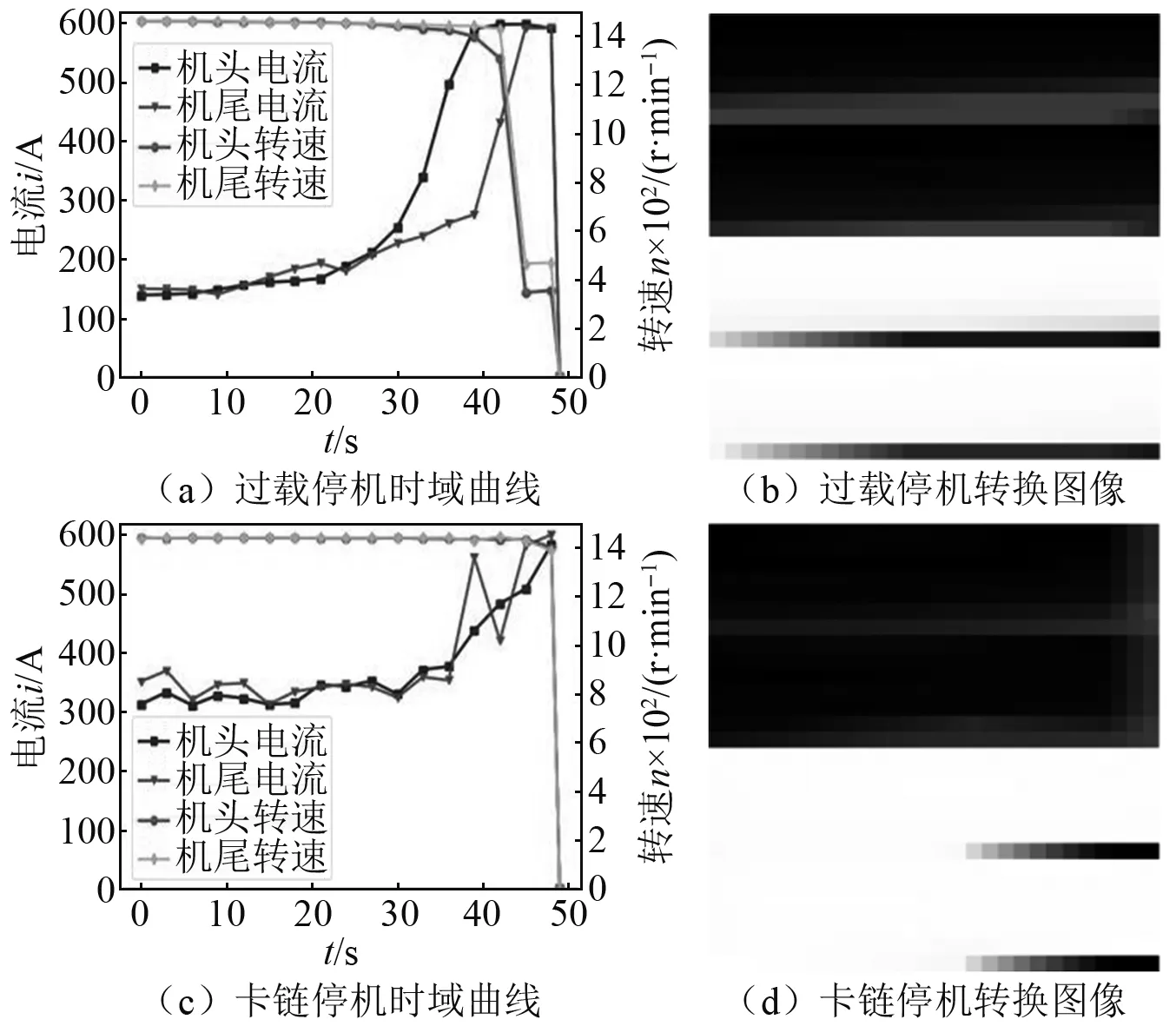
图8 刮板输送机故障停机时域曲线及其转换图像Fig.8 Time domain curve of scraper conveyor fault shutdown and its transformation image
将额定电流的70%作为重负载和轻负载判定依据,机头机尾电流差值与平均值比值的35%作为启动功率不平衡判定依据,即整个启动过程中,当机头机尾电流差值与平均值比值小于35%时,若瞬时电流过后电流维持在140 A以上,则视为重负载启动,否则视为轻负载启动;当机头机尾电流差值与平均值比值大于35%时,视为启动功率不平衡。启动时域曲线及转换图像如图9所示,图9(a)和图9(c)各自机头机尾电流值及差值在图9(b)和图9(d)的机头机尾电流位置分别映射出不同深度的色带。

图9 刮板输送机启动故障时域曲线及其转换图像Fig.9 Time domain curve of scraper conveyor startup fault and its transformation image
刮板输送机在启动时,因变频器电路或信号反馈问题,导致刮板输送机多次启动的现象视为重复启动。重复启动的时域曲线及转换图像如图10所示。图10(a)机头机尾电流、转速频繁为零的特征,在图10(b)映射出机头机尾电流、转速位置黑灰色带的频繁交替。

图10 刮板输送机重复启动时域曲线及其转换图像Fig.10 Time domain curve of scraper conveyor repeated start and its transformation image
4.3 模型分支和主干训练权重值的确定
为使分支进行更多的判别特征学习,使更多的样本以较高置信度提前退出,将分支给予全部加权值(即W分支=1),主干权重加权值进行递减以寻求最优值。试验预先将分支CBoF层中的字典数设为10进行变量控制,其结果如表5所示,当W主干=0.3时出现拐点,与主干和分支均赋予全部加权值相比,分支单独推理精度提高了0.66%。此外,主干单独推理精度的稳定,反映出主干训练损失函数值足够小,分支损失函数值的变化对其影响甚微。

表5 权重加权值对分支和主干单独推理精度的影响
4.4 模型分支CBoF字典数的确定
在分支与主干的权重加权值确定后,需对分支CBoF层字典数进行确定,选择不同大小的词典数进行试验,分别为10~100,间隔为10,试验结果如表6所示。字典数与分支单独推理精度呈现一定的周期波动趋势,当字典数为10时,分支单独推理精度最高,达到了96.93%,此外,主干单独推理精度的稳定,也反映出分支字典数导致分支损失函数值的变化对主干影响甚微。
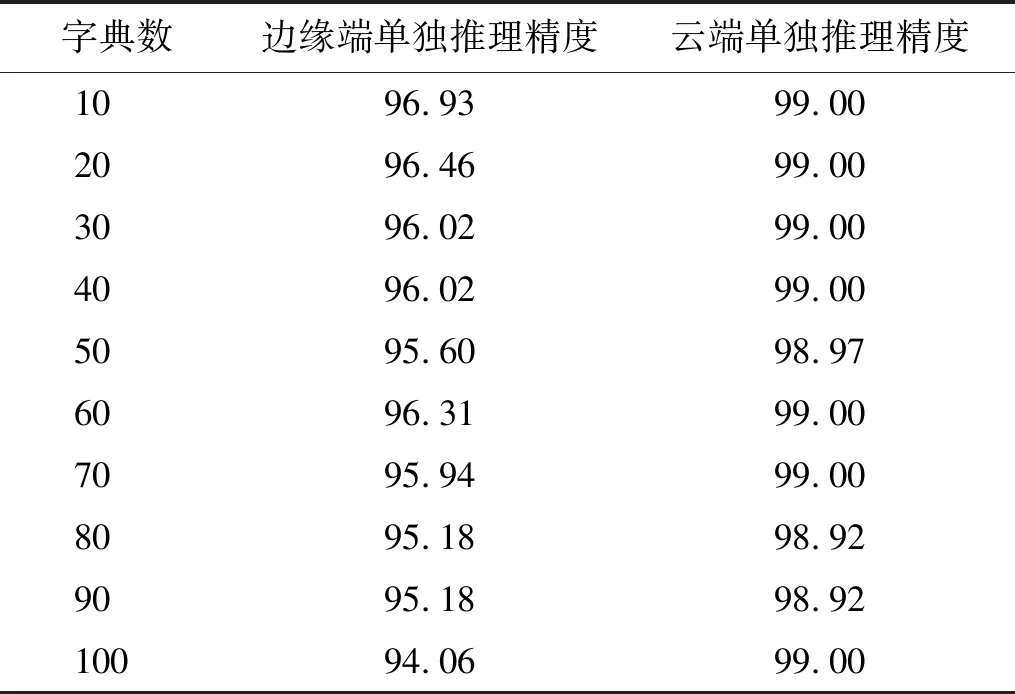
表6 字典数对分支和主干单独推理精度的影响
4.5 模型分支出口阈值的确定
DDNN不同的分支出口阈值T对其识别精度的影响,如表7所示。当T=0时分支出口样本退出率为0,样本全部交由主干进行单独推理,当T=0.5时,分支出口样本退出率为100%,样本全部交由分支进行单独推理,二者的识别精度分别为99.0%,96.93%。而当T=0.1和T=0.2时,分支出口样本退出率为73%和88.71%,样本由分支和主干进行协同推理,分支识别精度都达到了100%。
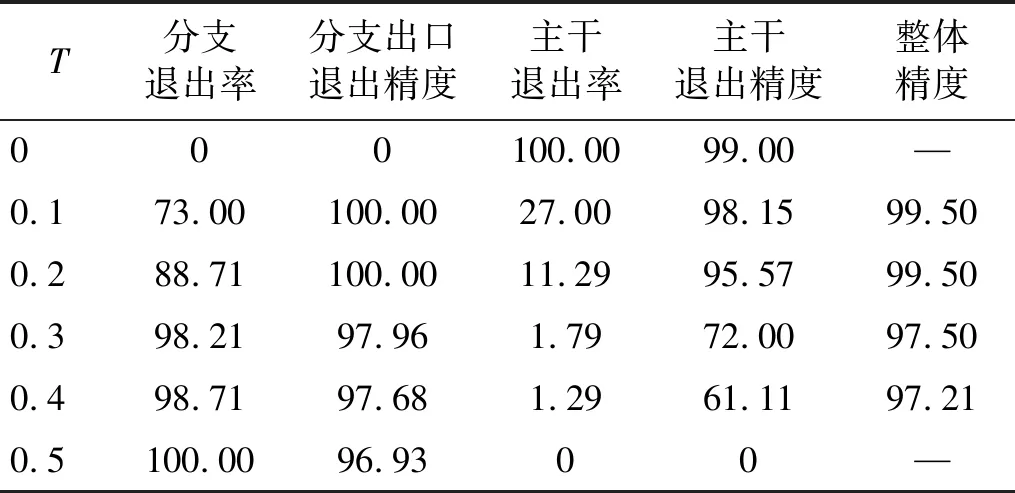
表7 不同阈值对DDNN模型的影响
4.6 DDNN模型协同推理与单独推理效果对比分析
故障诊断模型效果除了考虑识别精度外,还应考虑推理速度、通讯成本和模型参数量。DDNN模型协同推理与单独推理效果对比,如表8所示。分支单独推理的DDNN(T=0.5)参数量少,推理速度快,适合布置在靠近数据源的边缘端,因此通讯成本可忽略不计,但识别精度过低,仅为96.93%;主干单独推理的DDNN(T=0)参数量大,需要较大的计算资源,因边缘端计算资源有限,故将其布置在云端。与DDNN(T=0)相比,分支与主干协同推理的DDNN(T=0.2)在增加DDNN(T=0.5)的539×103个参数后,识别精度提高到了99.5%,推理速度提高了22%。灰度图像经padding=2的数据预处理后,输入尺寸变为32×32,输入通道数仍为1,由表2可知,数据预处理后的图像经共享块后的输出尺寸和通道数分别为32×32和1,其输出尺寸计算公式为

表8 DDNN模型协同推理与单独推理效果对比
f=⎣(i+2s-k)/s」+1
(13)
式中:f为输出尺寸;i为输入尺寸;s为步长;k为卷积核尺寸; ⎣>·>」为向下取整。
由表7可知,当DDNN阈值T分别为0和0.2时,分支退出率l分别为0和88.71%,根据式(10)可知,DDNN(T=0)通讯成本期望为4 096 B,而DDNN(T=0.2)通讯成本期望为462 B,仅占前者通讯成本期望的11.28%,明显降低了推理的通信成本。分支与主干的协同推理在融合分支与主干单独推理性能的同时,使不同难易程度的推理任务按需分配到边缘端和云端,使边缘端和云端计算资源有效利用率得到最大化,进一步提高了识别精度。
在机器学习领域中,混淆矩阵是一种用特定的矩阵来呈现算法性能的可视化效果,特别用于监督学习,其每一行代表预测类别,每一列代表实际类别,可以非常容易地表明多个类别是否有混淆。DDNN协同推理与单独推理混淆矩阵,如图11所示。在分支单独推理的DDNN(T=0.5)混淆矩阵中,标签0、标签5、标签6的识别精度均为100%,标签4识别精度仅为84%,最易被误识别,被误识别为标签3和标签5的个数分别为18和14。与DDNN(T=0.5)相比,在主干单独推理的DDNN(T=0)混淆矩阵中,除标签5的识别精度降低以外,其他标签的识别精度均有所提高,说明在边缘端未被识别出的复杂样本,在计算资源强大的云端得到了很好的识别,但也从侧面反映出云端为了识别少量复杂样本需要承担大量简单样本的计算任务,造成了云端计算资源的浪费;标签5中有7个简单样本在边缘端能够被识别,而在云端却未被识别,说明某些简单样本在云端复杂化,识别效果适得其反;在分支与主干协同推理的DDNN(T=0.2)分支混淆矩阵中,数据集88.71%的简单样本全部被识别出,其中,数据集标签0和标签2全部被识别出,DDNN(T=0.2)主干的混淆矩阵中,数据集剩余的11.29%复杂样本仅7个标签4被误识别为标签3,其余样本全部被识别出。由此可见,DDNN(T=0.2)将不同难易程度的样本在边缘端和云端进行了有效的分配。

图11 DDNN模型协同推理与单独推理混淆矩阵Fig.11 DDNN confusion matrix for cooperative inference and independent inference
t-分布邻域分布(t-distributed stochastic neighbor embedding,t-SNE)[22]是一种非线性降维算法,其将高维空间数据点之间的欧式距离转换为条件概率来表达点与点之间的相似度,使高维数据点映射到低维也具有同样的相似度,非常适用于将高维数据降维到二维或者三维进行可视化。DDNN协同推理与单独推理t-SNE可视化结果,如图12所示。

图12 DDNN模型协同推理与单独推理t-SNE可视化结果Fig.12 DDNN t-SNE visualization results for cooperative inference and independent inference
由图12可知,分支单独推理的DDNN(T=0.5)和主干单独推理的DDNN(T=0) t-SNE可视化结果中,存在某些标签决策边界不明显的问题,而分支与主干协同推理的DDNN(T=0.2)分支和主干t-SNE可视化结果中,均不存在标签间决策边界不明显的问题。可见,DDNN(T=0.2)分支和主干均能对分配样本的高维特征完成较好的分离和汇聚。
4.7 DDNN模型与传统神经网络模型对比分析
为了验证分布式深度神经网络在故障诊断当中相对于传统模型的优势,采用AlexNet、LeNet-5、InceptionV3传统模型在识别精度、参数量、推理速度和通讯成本4个方面进行对比试验,对比结果如表9所示。相比于传统神经网络模型,DDNN(T=0.2)识别精度最高,达到了99.50%;模型参数量仅次于参数量最少的InceptionV3,约超出后者参数量的1/4,但二者的推理速度基本持平;传统神经网络模型云端推理过程前,需将图像全部发送至云端,因传感器传输的数据类型为32位浮点数,且一个32位浮点数占据4 B,故发送一张28×28的浮点灰度图像至云端所需的通讯成本等于模型自身的通讯成本期望,均为3 136 B,而DDNN(T=0.2)因其边缘端提前退出机制,通讯成本期望仅占上述传统模型的14.7%;推理速度虽稍逊于AlexNet、LeNet-5,但其他方面均占较大优势。综上分析,DDNN(T=0.2)模型表现最优。

表9 DDNN模型与传统模型对比结果
4.8 模型泛用性验证
采用公开的西储大学轴承数据集[23]对DDNN模型的泛用性进行验证,因轴承在实际工作场景中负载和噪声不断变化,故选取各类负载(0,0.75 kW,1.50 kW,2.25 kW)条件下的振动信号,并在其基础上添加信噪比分别为-3 dB,0,3 dB,6 dB,9 dB的高斯白噪声,且各信噪比噪声的样本数量与未添加噪声的样本数量相同,数据集处理方式与刮板输送机启停工况时域信号的处理方式相同,其样本具体组成信息如表10所示。

表10 样本具体组成信息Tab.10 Sample specific composition information
4.8.1 模型抗噪及泛化能力分析
DDNN模型在负载及噪声混合场景中的测试结果,如表11所示。与无噪声混合负载场景中DDNN测试结果相比,虽然在负载和噪声混合噪声场景中,噪声的干扰使一部分样本复杂化,导致分支样本退出率减少,通讯成本增加了50%,模型推理时间略微增加,但主干模型依然能够达到98.60%的识别精度,模型整体精度更是达到99.27%,表现出一定的抗噪能力。由3.6节可知,与集中式云计算神经网络相比,DDNN模型在保持高精度的同时,依然可以降低32%的通讯成本。
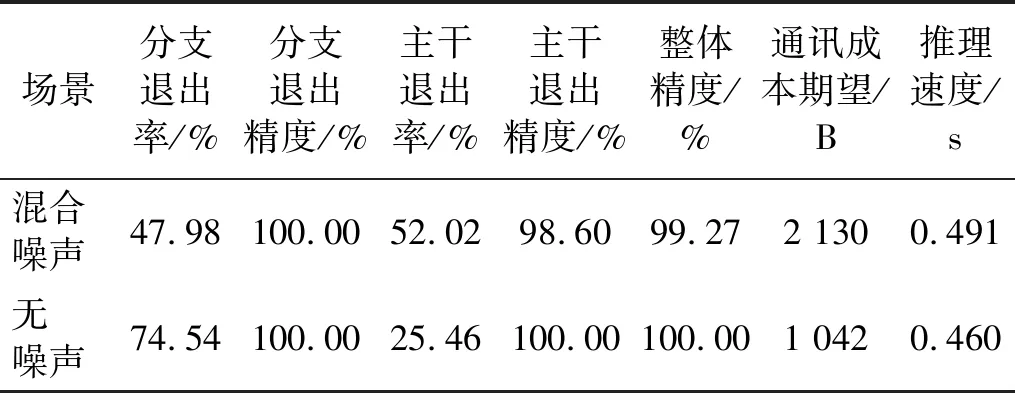
表11 DDNN模型在负载和噪声混合场景中的测试结果
DDNN模型在单一噪声混合负载场景中的测试结果,如表12所示。可以看出信噪比大小与其对振动信号的干扰强度大致成正比关系,虽然各信噪比场景中模型分支退出样本的数量有所差异,但均达到了100%的识别精度,其中,当信噪比为-3 dB时的噪声对振动信号的干扰最大,但主干模型依然能够达到94.67%的识别精度,模型的整体识别精度则达到了96%以上,当信噪比分别为3 dB,6 dB,9 dB时,模型的整体精度均在99.5%以上,表现出一定的泛化能力。由3.6节可知,相比于集中式云计算的神经网络模型,DDNN模型在各信噪比下的通讯成本均少于前者。
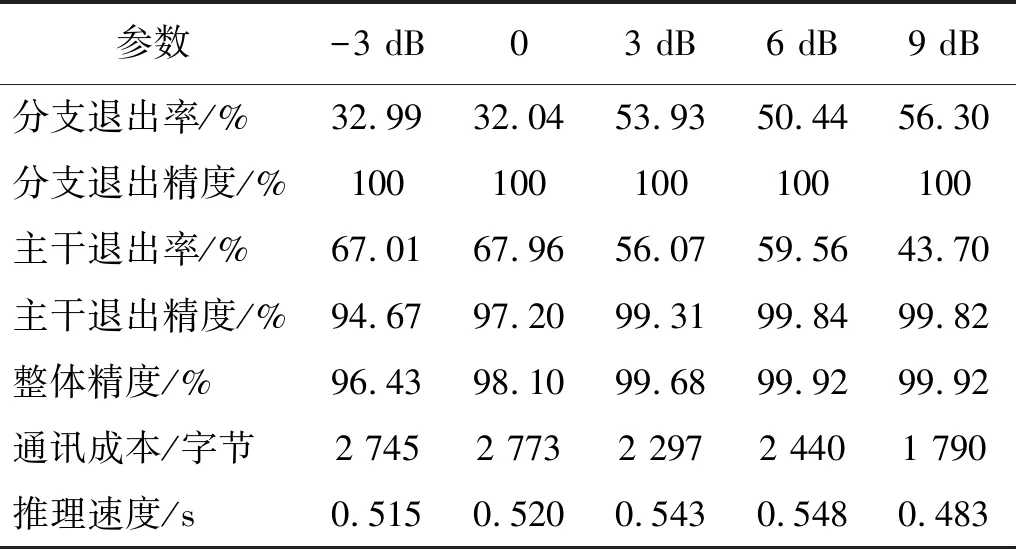
表12 DDNN模型在单一噪声混合负载场景中的测试结果Tab.12 Results of DDNN in a single noise mixed load scenario
4.8.2 模型泛用能力分析
在负载和噪声混合噪声场景的轴承数据集中,DDNN协同推理与单独推理效果对比,如表13所示。根据对比结果,分支单独推理的DDNN(T=0.7)在参数量、推理速度、通讯成本依然存在优势,但识别精度过低,仅为97.13%;与主干单独推理的DDNN(T=0)相比,分支与主干协同推理的DDNN(T=0.2)在增加DDNN(T=0.7)的560 k个参数后,识别精度提高到了99.27%,推理速度提高了20%,通讯成本降低了48%。可见DDNN不仅可以在刮板输送机电流转速信号数据集中实现边缘端和云端计算资源的有效利用、通讯成本的降低和识别精度的提高,而且在轴承振动信号数据集中也同样适用,试验论证了DDNN模型具有一定的泛用性。
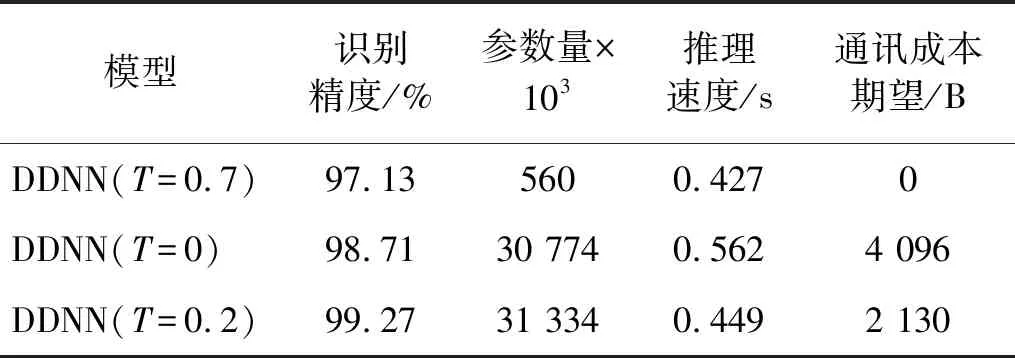
表13 DDNN模型协同推理与单独推理效果对比
5 结 论
(1) 基于分布式深度神经网络的刮板输送机启停工况故障诊断方法,通过边缘端与云端模型的协同推理,实现了刮板输送机高精度、低通讯、低时延的启停工况故障诊断,提高了设备监测维护的智能化水平。
(2) DDNN模型将简单和复杂计算任务按需分配到边缘端和云端,使边缘端和云端计算资源利用率得到最大化,与传统的故障诊断模型相比,DDNN在识别精度、模型参数量、推理速度和通讯成本4个方面表现出了显著的优势。
(3) 所提方法具有一定的泛用性能,在不同对象、不同类型的数据集中仍然有较好的表现,为其他矿山设备关键零部件的故障诊断提供了借鉴和参考。
