基于改进YOLOv5s 的大熊猫姿态识别
2023-10-07杨斌段昶陈鹏
杨斌,段昶 ,陈鹏
(1. 西南石油大学电气信息学院,成都 610500;2. 成都大熊猫繁育研究基地,四川省濒危野生动物保护生物学重点实验室,成都 610086)
大熊猫Ailuropoda melanoleuca是我国特有的珍稀物种,有“活化石”和“中国国宝”等美誉,其保育工作受到国家和公众的高度关注(王晓,张晋东,2019)。人们一直在探寻大熊猫行为模式,以增进对其的了解并制定对应的保护策略。大熊猫的姿态分析是行为模式研究的重要组成内容,识别大熊猫姿态是研究其行为的基础(侯金等,2020)。传统人眼直接观察大熊猫行为效率低下,且需要长期专业知识储备和经验累积(刘赫等,2022)。将目标检测技术用于自动识别大熊猫姿态和开展大熊猫行为研究,能更准确、及时掌握大熊猫状态,提高大熊猫种群饲养管理和保育水平。
动物姿态识别领域已经取得了丰硕的成果,薛月菊等(2018)提出一种改进的Faster RCNN(Renet al.,2017)基于哺乳母猪姿态的识别算法,对主干网络设计新的残差结构和引入中心损失函数,平均精度达到93.25%;刘龙申等(2022)提出一种围产期母猪姿态的识别方法,利用EfficientDet(Tanet al.,2020)网络进行识别,平均精度达93.97%;许成果等(2022)提出一种自注意力机制与无锚点的仔猪姿态识别方法,使用Swin Transformer(Liuet al.,2021)作为基础网络,提取仔猪图像的局部和全局特征,设计了一个特征增强模块进行多尺度特征融合,最后将融合后的特征图输入检测头进行仔猪的定位和姿态识别,识别精度达到95.68%;林梦翔等(2022)提出一种基于全局与随机局部特征融合的鸟类姿态识别模型,通过不同尺度的特征融合获取全局特征,裁剪图片获取局部特征,两者融合进行鸟类姿态识别。上述动物姿态识别方面的研究对本文大熊猫姿态识别具有借鉴意义。
本文以大熊猫为研究对象,提出一种基于改进YOLOv5s 的大熊猫姿态识别方法,可有效辅助后续的行为识别工作,为野外检测识别提供技术参考。
1 研究方法
1.1 YOLOv5s改进
以YOLOv5s(https://github. com/ultralytics/yolov5)作为基准大熊猫姿态识别方法,改进YOLOv5s 的主干网络与颈部网络以提高大熊猫姿态识别精度(图1),红色虚线框和加粗字体为本文改进部分。

图1 YOLOv5s改进后的网络结构Fig. 1 Improved network structure of YOLOv5s
YOLOv5s的主干网络提取特征主要通过C3模块实现。本文所使用的姿态数据集少量图片目标存在遮挡,对于存在遮挡的目标,位置信息特别重要,但C3模块未能有效利用目标的位置信息,以至于在特征提取阶段造成目标位置信息丢失,使得网络识别精度受限。故本文引入坐标注意力(coordinate attention,CA)(Houet al.,2021)改进C3模块:第一,CA 可以捕获跨通道信息,建立通道之间的依赖性,赋予权值比例,突出有效特征;第二,CA 还能捕获目标的方向与位置信息,进一步提高检测的准确率。改进后的模块命名为C3CA,上路分支为深度卷积继续加强特征的提取,扩大特征图的感受野,下路分支进行特征压缩,保留原始信息。2 路分支连接后,进行坐标注意力,对特征图坐标位置编码,最后通过卷积进行特征融合。输入残差征,同时进行特征X 方向全局平均池化和Y 方向全局平均池化。然后在空间维度上连接和卷积来压缩通道,其中,r为卷积中的通道下采样比例,通过批标准化和非线性来编码垂直方向和水平方向的空间信息。接着在通道维度上进行分割,再各自通过卷积进行通道转换,最终通过激活函数Sigmoid得到注意力权重,与输入特征相乘,得到方向感知和位置敏感的特征图(图2,图3)。
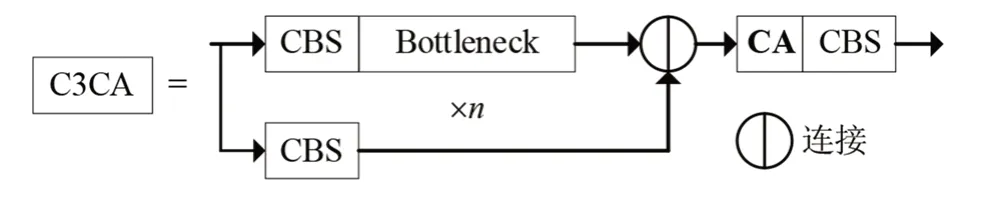
图2 C3CA结构Fig. 2 C3CA structure

图3 坐标注意力编码注意过程Fig. 3 Coordinate attention coding attention process
在颈部网络特征融合时,来自不同阶段的残差(Residual)特征图直接连接会导致特征冗余(图4:a)。Tan 等(2020)针对不同阶段特征图对识别结果的重要程度不同,提出双向特征金字塔网络(bidirectional feature pyramid network,BiFPN),该网络结构特征融合过程中采用了加权求和的操作,给不同阶段特征图赋予权重比例,学习特征的重要性。不同阶段的残差特征图乘以初始化参数w0、w1学习特征图的重要性,然后进行特征相加,再通过1×1 卷积进行特征融合(图4:b)。本文引入BiFPN 中的加权求和操作替换YOLOv5s 颈部网络特征融合的直接连接操作。

图4 特征融合(a)原连接(b)加权求和Fig. 4 Feature fusion (a) concatenation (b) weighted sum
在颈部网络特征输出时,采用传统的卷积对于不规则目标的特征信息提取能力不足。本文所使用的大熊猫姿态数据集,图片中的目标姿态多变,为不规则目标,为了适应不规则目标采用可变形卷积作为颈部网络输出阶段的特征提取,不仅可以对规则目标的特征信息提取,还可以充分提取不规则目标的特征信息。Zhu 等(2019)提出可变形卷积,在传统卷积的基础上调整卷积核的方向向量,使得卷积核跟随目标形状自适应采样。因此,为了适应各种形式的物体,本文引入了可变形卷积对采样位置进行自由采样,而不局限于方正的格点。传统卷积神经网络定位采样方法难以适应物体的变形。该过程模型公式如下:
式中,x表示输入特征图,卷积核按照方正的网格点对其进行采样。w表示权重,对于输出y上的位置p0,输出特征映射等于w赋予的采样值之和。其中,R为位置信息,计算公式如下:
可变形卷积的主要特点是能够对特征自适应采样,具有学习空间几何变形的能力。这非常适合于检测不同大小和形状的物体,而该方法只是在一定程度上增加了计算时间。对于每个采样点具有额外学习目标偏移的可变形卷积公式如下:
对于每个采样位置赋予偏置量Δpn后,采样变得不规则,这使得新方法的变换建模能力优于传统卷积神经网络(图5)。

图5 标准卷积与可变形卷积Fig. 5 Standard and deformable convolution
1.2 数据集
姿态数据来源包含:成都大熊猫繁育研究基地、网络爬虫。成都大熊猫繁育研究基地采集的原始视频,视频总时长超过1 700 h,对原始视频进行筛选,剔除遮挡严重、视野模糊的视频,对视频分帧处理获得图片,选取了12 235 张图片;通过网络爬虫挑选出样本较少的姿态图片,共780张。这些照片包含6 类大熊猫姿态:站、立、坐、趴、躺卧、侧卧(图6)。使用LabelImg 标注大熊猫姿态。按照4∶1 将数据集分为训练集和测试集,训练集10 413张图片,测试集2 602张图片(表1)。

表1 大熊猫姿态数据集样本数量Table 1 Sample number of giant panda pose dataset
1.3 实验运行环境
本文所使用的实验环境如表2所示。

表2 实验环境Table 2 Experimental environment
1.4 评价指标与训练参数设置
实验以平均精度均值(mean average precision,mAP)、模型每秒检测的图像数量(frames per second,FPS)、网络模型的参数及网络模型权重的大小评价指标对模型进行评价。mAP(0.5)主要用于体现模型的识别能力,其中,(0.5)表示交并比(intersection over union,IOU)等于0.5,mAP(0.5∶0.95)由于要求的IOU阈值更高,主要用于体现定位效果及边界回归能力;FPS 是衡量运行速度,其值越大,实时性越高;模型参数量和模型权重大小是边缘端部署的重要指标,在不损失精度的情况下,越小越好。
输入图像大小为640×640,采用SGD 优化器进行训练,初始学习率设置为0.01,训练总次数设置为100,批量大小设置为16。
1.5 姿态识别方法
为评估本文改进方法的性能,实验中还与以下8 种方法在使用相同大熊猫姿态数据集训练后进行对比:YOLOv3(Redmon & Farhadi,2018)、YOLOv3-tiny、YOLOv3-spp、YOLOv4-csp-s、YOLOv5s、YOLOv5m、YOLOv6-tiny(Liet al.,2022)、YOLOv7-tiny(Wanget al.,2022)。
2 实验结果
本文改进模型相较于原生YOLOv5s,在mAP(0.5)、mAP(0.5∶0.95)、参数量、权重大小、FPS指标上均占优势。相比YOLOv5s,3 个改进点结合形成的YOLOv5s+C3CA+BiFPN+DConv,其mAP(0.5)/mAP(0.5∶0.95)提高到3.12%/3.96%,模型参数减少8.6%(表3)。

表3 YOLOv5s改进前后实验对比结果Table 3 Comparison of experimental results before and after YOLOv5s improvement
本文改进模型相较于其他姿态识别方法,综合识别性能最佳(表4)。

表4 大熊猫姿态数据集对比实验结果Table 4 Comparison of experimental results of giant panda pose datasets
各类方法在“站、立、坐”姿态的识别率较高,本文改进模型在“站”姿态AP(0.5)值为97.87%,达到 最 优;YOLOv5m 在“立”姿 态AP(0.5)值 为96.72%,达到最优;YOLOv4-csp-s 在“坐”姿态AP(0.5)值为93.89%,达到最优。在“趴、躺卧、侧卧”姿态中,YOLOv6-tiny 在“趴”姿态AP(0.5)值为87.64%,提升较大;本文改进模型在“躺卧”姿态AP(0.5)值为89.73%,有明显提升;YOLOv6-tiny 在“侧卧”姿态AP(0.5)值为86.98%,提升较大。本文改进模型比改进前的YOLOv5s 模型在识别率较低的“趴、躺卧、侧卧”姿态,分别提升了4.45%、7.44%、7.79%(表5)。

表5 基于不同模型的6类大熊猫姿态识别精度Table 5 Recognition accuracy of 6 pose types of giant pandas based on different models
为了更好地验证本文提出改进后算法的可行性,在姿态测试集中选取部分数据进行测试,YOLOv5s 与YOLOv5s+C3CA+BiFPN+DConv 算法 在 不同图片下的检测结果对比显示:YOLOv5s 识别结果中真值分别为“站(图7:a)、站(图7:c)、立(图7:e)、躺卧(图7:g)、侧卧(图7:i)”;但网络出现了漏检(图7:a)、“站”被误识别为“坐”(图7:c)、“立”被误识别为“坐”(图7:e)、“躺卧”被误识别为“坐”(图7:g)、“侧卧”被误识别为“趴”(图7:i)等问题。网络出现这种结果的可能原因是:特征图目标位置信息利用不足,对不规则目标识别难度较大。通过对网络模型的改进,形成YOLOv5s+C3CA+BiFPN+DConv,改进后算法的识别结果均正确识别出“站、站、立、躺卧、侧卧”(图7:b、d、f、h、j),在遮挡物严重的情况下也能做出正确的识别。

图7 改进前后识别效果对比Fig. 7 Comparison of recognition effect before and after improvement
3 讨论与结论
本文聚焦于大熊猫姿态识别问题,提出一种改进YOLOv5s 大熊猫姿态识别方法,改进了包含主干网络与颈部网络,原YOLOv5s 主干网络未能有效利用目标的位置信息,利用CA 设计C3CA 以改进主干网络,提高对目标位置信息提取的能力;还采用BiFPN 中加权求和操作替换原颈部网络特征融合采用的直连方式;在颈部网络输出阶段采用可变形卷积,提高对不规则目标的识别能力。实验结果表明,所有改进点相结合,大熊猫姿态识别精度最佳,实现了高精度自动化识别目标姿态,降低人力物力,为大熊猫行为分析奠定了基础。
本文改进了YOLOv5s 大熊猫姿态识别方法,通过此方法训练生成的模型与YOLOv5s 相比识别精度与检测速度达到了较高的水平。该方法可以推广到其他珍稀保护动物的姿态识别问题上,并且对实验训练环境要求较低。
此方法存在一定的局限性。在输入图像中,对于环境较暗的兽舍、目标不清晰的情况下,模型出现误检、漏检现象。下一步将对YOLOv6、YOLOv7进行改进,提升大熊猫姿态识别的精度,并且通过姿态的识别对其行为进行分析。
致谢:感谢成都大熊猫繁育研究基地提供并授权使用大熊猫监控视频数据。
