零部件光学影像精准定位的轻量化深度学习网络
2023-10-02牛小明何光辉
牛小明,曾 理*,杨 飞,何光辉
(1.重庆大学 数学与统计学院,重庆 401331;2.长春长光辰谱科技有限公司,吉林 长春 130000)
1 引言
机器视觉定位[1]是一种基于光学摄像头或其他传感器获取物体位置和姿态信息,并结合算法进行数据处理,最终实现对目标物体精确定位和跟踪的技术。该技术在工业4.0 中发挥着不可或缺的作用。在智能制造中,视觉定位技术可以用于产品或零部件的定位[2]、检测和识别,实现产线流水线的自动化和智能化,进而大幅提升生产效能,降低人工成本。在机器人自动化装配中[3],视觉定位技术可以帮助机器人定位和识别零部件,实现自动化装配。在智能物流中,视觉定位技术可以用于物品的识别[4]和追踪,提高物流效率和准确性;在智能仓储中,视觉定位技术可以用于物品的分类和存储,提高仓储效率和管理水平。
机器视觉定位技术通常包括以下几个步骤:图像采集、图像预处理、特征提取、目标匹配和坐标转换(图像的像素坐标转换为机器人的空间物理坐标)。在流水线自动安装时,机器视觉定位不精准对微型芯片、高灵敏零部件、易碎且价格昂贵的屏幕等产品的影响可能会更加严重。具体影响包括:(1)损坏产品,机器视觉定位不准确会导致机器在操作时未能正确识别产品位置,可能会对其进行错误的处理或施加过大的力量,从而导致产品损坏;(2)降低产品质量,机器视觉定位不准确可能会导致产品的安装不够精准或位置不正确,进而导致产品质量下滑,功能异常或者寿命缩减;(3)增加生产成本,由于机器视觉定位不准确,机器需要进行额外的处理或人工干预,从而增加生产成本;(4)安全隐患,机器视觉定位不准确还可能会导致产品被放置在不正确的位置,从而产生安全隐患。对于微型芯片和高灵敏零部件等产品,错误的操作可能会导致电路短路等严重问题。因此,在智能制造生产过程中,机器视觉的定位准确性和精度起到至为关键的作用。
随着人工智能的发展,深度学习方法在自动驾驶、智能安防、工业制造和医学影像等领域得到了广泛的应用。AlexNet[5]是深度学习在计算机视觉领域的开端,它使用深度卷积神经网络(Convolutional Neural Network,CNN)对大规模图像数据集ImageNet 进行分类,同时也在目标检测领域进行了尝试。2014 年,Girshickt[6]等提出了R-CNN(Region based Convolutional Neural Network)算法,它使用区域建议法取出候选目标区域,然后对单个区域采用CNN 进行特征提取,并利用支持向量机(SVM)实施分类,紧接着选用回归模型对目标框实施微调,R-CNN 在PASCAL VOC 数据集上获得了比较好的效果。SPP-Net[7]对R-CNN 算法进行了改进,引入了空间金字塔池化(Spatial Pyramid Pooling,SPP),促使网络可以对任意尺寸的输入图像进行分类和检测;对比R-CNN,SPP-Net 识别率更高且运行时间更短。Fast R-CNN[8]引入了ROI(Region of Interest Pooling)池化,使得网络可以在整张图像上进行前向传播,并对每个候选区域进行分类和定位;相比R-CNN 和SPP-Net,Fast R-CNN 更快、更准确。2015 年,Ren[9]等提出了Faster RCNN 网络,它引入区域建议网络(Region Proposal Network,RPN)来生成候选目标框,然后再将这些框输入到Fast R-CNN 中进行分类和定位。因其速度和准确率表现优秀,Faster R-CNN 是目前最常用的目标检测算法之一。2016 年,Redmon[10]等提出YOLO(You Only Look Once)算法,YOLO 是一种One-Stage 的实时目标检测算法,它将输入图像分成栅格,然后对每个栅格预测出多个目标框和类别概率,因此推理速度非常快。SSD[11](Single Shot Multi-Box Detector)也是一种One-Stage 的目标检测算法,它使用多尺度卷积特征图来检测不同尺度的目标,并在每个特征图位置上同时预测多个目标框和类别概率;SSD 在速度和准确率方面都有较好的表现。2017 年,Lin[12]等提出RetinaNet 网络,RetinaNet是一种基于Focal Loss 的目标检测算法。Focal Loss 通过缩小易分类样本的权重,加强难分类样本的权重,解决了目标检测中正负样本不均衡的问题。相比较SSD 和YOLO,RetinaNet 的性能相对更好。Mask R-CNN[13]是对Faster R-CNN的改进,引入了Mask Head 进行实例分割,它能够同时检测物体的边界框和生成物体的掩模,是目前应用较广的实例分割算法之一。2018 年,Cai[14]等提出Cascade R-CNN 算法,它引入级联结构进一步提升目标检测准确率,每个级联层都是一个独立的分类器,用来筛选出更准确的目标框。2019 年,Zhou[15]等提出基于关键点检测的ExtremeNet 网络,它利用网络模型检测出目标物体上下左右方向的4 个极值点和一个中心点,并利用几何关系找到有效点组,一组极点代表一个检测结果,该模型有着较快的检测速度。Li[16]等提出了多尺度目标检测网络TridentNet,它采用空洞卷积并设计了3 种不同尺寸感受野的并行分支,可以处理不同尺寸的物体;训练时使用3 个分支,测试时使用1 个分支,有效解决了目标尺寸变化的问题。Zhu[17]等提出了可以根据目标尺寸自由选择特征层的FSAF(Feature Selective Anchor-Free),针对每一个特征层,计算其损失值,使用损失值最小的特征层当作最好的特征层进行检测,该模型较好地解决了目标尺寸变化的问题。2020 年,Tan[18]等提出了EfficientDet 网络,它引入BiFPN(Bi-directional Feature Pyramid Network)进行多尺度特征融合,同时使用Compound Scaling 进行模型结构优化,EfficientDet 在速度和准确率方面都有很好的表现。YOLOv4[19]是在YOLOv3 的基础上进行技术升级和迭代,包括利用SAM(Spatial Attention Module)来提升感受野响应,使用SPP(Spatial Pyramid Pooling)来增加网络对目标的表达能力等,在COCO 数据集上的mAP50为43.5%。Sparse RCNN[20]采用一种稀疏注意力机制,目的是减少冗余计算和加速推理,在COCO 数据集上,Sparse R-CNN 在mAP50方面比Faster R-CNN 高2.5%,速度比它快5 倍以上。Beal[21]等提出了ViTFRCNN 网络,它使用Transformer 替换骨干网络,借助注意力机制对图像全局特征进行编码,基于Transformer 的ViT-FRCNN 网络在标准数据集上获得了出色的性能。另外,Qiu[22]等提出了BoderDet 网络,它使用边界对齐自适应地进行边界特征提取,并将边界对齐操作封装成对齐模块集成到FCOS(Fully Convolutional One-Stage)网络,使用高效的边界特征提高了重叠目标的检测精度。Yang[23]等提出了基于边界圆的无锚框检测方法CircleNet,只需要学习边界圆的半径就可以实现目标检测,与边界框相比,具有优越的检测性能和较好的旋转一致性。2021 年,Chen[24]等提出RepPoints v2 算法,它基于Anchor-Free 的思想,利用学习目标的重心和特征点进行检测;相比较RepPoints v1,RepPoints v2,它对网络结构、特征提取和损失函数等实施了改进,进而提升了检测精度和速度;在COCO 数据集上测试,RepPoints v2 的mAP50比RepPoints v1 高1.6%。Yao[25]等提出了一种端到端的检测算法Efficient DETR,该算法利用密集先验知识初始化检测网络,仅用3 个编码器和1 个解码器就达到了较高的检测精度,而且提高了收敛速度。Lang[26]提出了无锚框检测网络DAFNe,结合中心点和角点间距预测边界框,并将中心度感知函数扩展到任意四边形,从而提高目标定位精度,对于旋转目标效果更好。Ge[27]等提出了基于无锚机制的检测方法YOLOX,它利用解耦头将分类和回归任务进行解耦,改善模型收敛速度的同时提高了检测性能。2022 年,Yu[28]等使用三段级联设计完善了目标检测和重识别,实现每个阶段注意力结构紧密特征交叉,进而使网络从粗到细进行目标特征学习,能够更加清晰地区分目标和背景特征。Cheng[29]等提出了AOPG(Anchor-Free Oriented Proposal Generator)网络,它将特征图映射到图像上,把位于真实框中心区域的顶点作为正样本,构建新的区域标签分配模块,缓解了正样本所占比例小的问题,并且使用对齐卷积消除了特征和旋转框之间的不对齐。Huang[30]等提出了一种无锚框自适应标签分配策略,能够从热力图中获取任意方向和形状的特征,自适应调整高斯权重来适配不同的目标特征,使用联合优化损失完善非对齐优化任务,使检测速度和检测精度得到大幅提升。
深度学习目标检测算法目前已初步应用在工业机器视觉中,比如制造过程中的产品缺陷检测、工厂的异常行为检测、工厂的安全隐患监测,指导机器人进行自动化加工、装配等。然而,将它直接应用于零部件精准定位时存在一定的局限性:(1)经典的深度学习算法需要海量训练数据,通常需要大量的标注数据,这对于工业零部件视觉精准定位数据采集来说是一个挑战;(2)模型参数量大、对硬件资源要求高,经典的深度学习算法模型参数量偏大,如YOLOv3 模型参数量为162 MB,大模型意味着对硬件资源的占用也相对较多,从而需要大量的计算资源来进行训练和推理,这对于一些小型或中小型企业来说是一个负担;(3)稳定性问题,工业环境中极易存在噪声和干扰,在复杂的光线和噪声环境条件下,深度学习算法可能会出现性能下降或无法工作的情况;(4)工业零部件视觉定位精度要求高,针对零部件定位或插件、精密部件的螺孔定位等,有的定位精度要求在毫米量级,有的定位精度要求在百分之一毫米量级,在机器人、相机作用距离和相机分辨率固定的情况下对图像的定位算法精度要求极高(2~5 pixel),而经典的深度学习算法会出现检测框冗余及不精确,可能会导致其不能直接应用于工业零部件像素级精准定位。针对以上问题,本文构建了一种工业零部件精准定位的轻量化深度学习网络(Industry Light Weight Localization Network,ILWLNet)。网络整体结构采用Encoder-Decoder 架构,Encoder 采用多级bottleneck 模块[31],内部融入非对称卷积和空洞卷积,可以有效降低特征提取参数,增大感受野;Decoder 中的上采样卷积同样融入和非对称卷积和空洞卷积,恢复图像的同时进一步降低模型参数;Encoder 与Decoder 对应特征层实施融合拼接,促使Encoder 在上采样卷积时可以获得更多的高分辨率信息,进而更完备地重建出原始图像细节信息。最后,利用加权的Hausdorff距离构建了Decoder 输出层与定位坐标点的关系。该轻量化深度学习定位网络具有定位精度高、准确率高和抗干扰能力强等特性,基本满足工业零部件精准定位的需求。
2 原理
2.1 零部件光学影像定位系统的硬件构成
图1 为零部件光学影像定位系统的硬件组成。它主要由照明子系统、图像采集子系统、机械运动子系统、机器人以及计算机组成。照明子系统由光源和光源控制器构成;图像采集子系统由镜头、CCD 相机和图像采集卡等构成;机械运动子系统由传送带、卡槽、支撑座和伺服运动系统等构成。
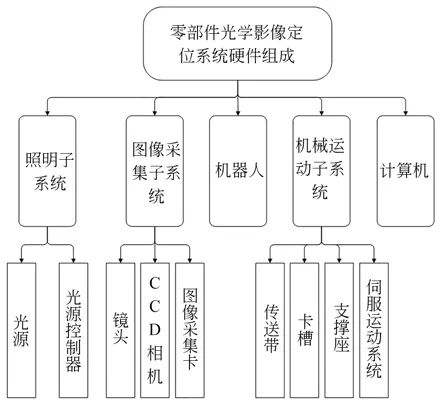
图1 定位系统硬件组成Fig.1 Hardware components of localization system
2.2 工作原理
精准定位系统的基本工作原理如下:由运动控制系统对物件进行运动控制,配合卡槽位完成对物件的粗定位;光学子系统负责打光、由成像系统获取图像数据,经过图像采集卡进行A/D 转换,转换成数字信号、送入至计算机进行零部件的像素级精准定位;将定位后的精准像素坐标经过坐标转换为机器人的空间物理坐标,控制机器人进行精准打孔、插件等,如图2 所示。

图2 零部件光学影像定位系统Fig.2 Optical image localization system for industry component
3 轻量化深度学习定位网络
3.1 网络架构
ILWLNet 网络结构如图3 所示。网络总体设计选用Encoder-Decoder 架构,Encoder 和Decoder 分别由三级Down_Block 和三级Up_Block级联而成。每级Down_Block 由4 个配置不同的bottleneck 模块串联构成;每级Up_Block 对输入数据进行上采样卷积后与对应的Down_Block 输出数据进行padding,并送入至conv_async 模块,促使Encoder 在进行上采样卷积时可以获得更多的高分辨率信息,进而更完整地重建出原始图像的细节信息。目标点的个数由Encoder 输出特征图与Decoder 输出语义层经过全连接、拼接、全连接回归获得。最后,利用加权的Hausdorff 距离建立Decoder 输出语义层与定位坐标点的关系,并结合回归的目标点数量偏差构建最终的损失函数形成闭环训练;推理阶段,Decoder 输出语义层经过Otsu 分割即可得到最终的零部件精准定位坐标。

图3 轻量化深度学习定位网络结构Fig.3 Lightweight deep learning localization network architecture
ILWLNet 网络算法流程如图4 所示,包括Encoder、Decoder、目标点数量回归和目标点位置回归。
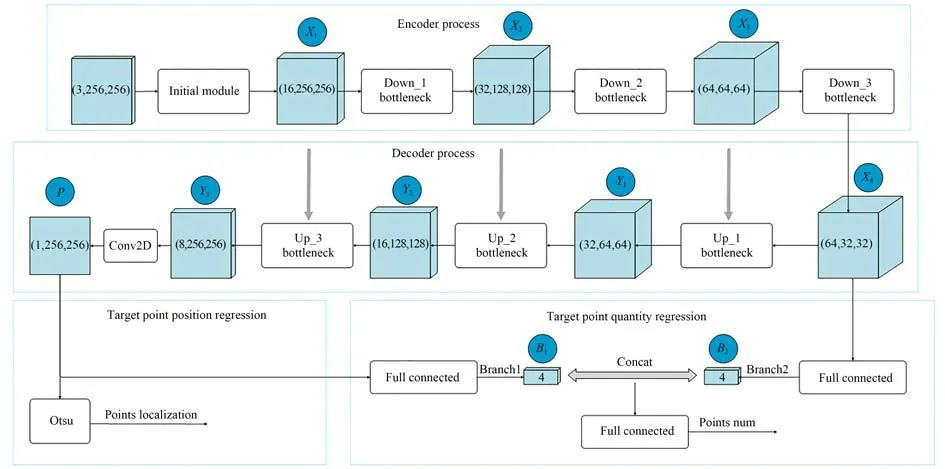
图4 轻量化深度学习定位网络算法流程Fig.4 Flowchart lightweight deep learning localization network algorithm
Encoder 流程如下:输入的图像首先归一化成3×256×256,经过conv_async 输出16×256×256 的特征图,记为X1,其中conv_async 内部进行了1×1 的投影卷积和3×1,1×3 的非对称卷积,得到初级特征图的同时,降低了直接卷积的运算量和模型参数;其次,经过Down_Block_1 模块得到32×128×128 的特征图,实现下采样和进一步的深度特征提取,记为X2,其中Down_Block_1 内部包含bottleneck_1_0,bottleneck_1_1,bottleneck_1_2 和bottleneck_1_3 四个模块,具备降采样、低卷积运算量和拓展感受野的能力,多级串联也提升了网络整体的非线性拟合能力;再次经过Down_Block_2 模块得到64×64×64 的特征图,记为X3,其中Down_Block_2 内部包含bottleneck_2_0,bottleneck_2_1,bottleneck_2_2 和bottleneck_2_3 四个模块,功能同Down_Block_1;最后,经过Down_Block_3 模块得到64×32×32 的特征图,记为X4,其中Down_Block_3 内部包含bottleneck_3_0,bottleneck_3_1,bottleneck_3_2 和bottleneck_3_3 四个模块,功能同Down_Block_1。
Decoder 流程如下:首先,特征图X4和X3作为参变量进入至Up_Block_1 模块,得到32×64×64 的语义图Y1,其中Up_Block_1 内部实现X4上采样并与X3特征拼接、拼接后的特征图进入conv_async 模块,Up_Block_1 具备上采样、低卷积运算和多特征融合能力,促使Encoder 在进行上采样卷积时可以获得更多的高分辨率信息;其次,语义图Y1和特征图X2作为参变量进入Up_Block_2 模块,得到16×128×128 的语义图Y2,功能实现同Up_Block_1;最后,语义图Y2和特征图X1作为参变量进入至Up_Block_3 模块,得到8×256×256 的语义图Y3。
目标点数量回归:特征图X4与语义图P分别经过全连接得到Branch2 的B2和Branch1 的B1,经过特征拼接及全连接回归得到最终的定位目标点数量。
目标点位置回归:Decoder 得到的最终语义图P可以体现每个坐标点的激活概率值,但是并不能直接返回预测目标点坐标;通过3.3 节构建的加权Hausdorff 距离损失函数,将预测点坐标与语义图P进行关联,再次融合目标点数量预测误差,利用3.4 节构建的最终损失函数进行闭环训练。模型闭环训练收敛且达到指定误差后,推理阶段将语义图P经过Otsu 分割即可得到最终的目标点位置。
3.2 模块结构
图5 介绍了ILWLNet 网络的通用网络模块和外层网络模块。通用网络模块:conv_async 包含1×1 投影卷积、3×1 与1×3 的非对称卷积(内置空洞卷积),实现浅层特征提取同时降低了直接卷积的运算量。外层网络模块:Down_Block_i包含bottleneck_i_0,bottleneck_i_1,bottleneck_i_2 和bottleneck_i_3 四部分,具备降采样、低卷积运算量和拓展感受野的能力,多级串联可提升网络整体的非线性拟合能力;Up_Block_i 内部包含上采样、特征拼接和conv_async 模块,具备特征尺寸扩张、低卷积运算和多特征融合能力。

图5 外层网络模块结构Fig.5 Structure of outer network module
图6 介绍了ILWLNet 网络的内层网络模块。bottleneck_i_0:左链路包括MaxPooling2D 和Padding 模块,右链路包含2×2 卷积(步长为2)、3×3 卷积、1×1 扩张卷积和Dropout2d,两条链路特征相加并经过PReLU 输出,各个卷积模块后面都追加BatchNorm 和PReLU 模块用于提升非线性能力和降低过拟合风险。bottleneck_i_1:右链路包括1×1 投影卷积、3×3 卷积、1×1 扩张卷积和Dropout2d,直通的左链路与右链路特征相加并经过PReLU 输出;各个卷积模块后面都追加BatchNorm 和PReLU。bottleneck_i_2:右 边链路包括1×1 投影卷积、3×3 空洞卷积、1×1 扩张卷积和Dropout2d,直通的左链路与右边链路特征相加并经过PReLU 输出;各个卷积模块后面都追加BatchNorm 和PReLU。bottleneck_i_3:右链路包括1×1 投影卷积、5×1 和1×5 的非对称卷积、1×1 扩张卷积和Dropout2d,直通的左链路与右链路特征相加并经过PReLU 输出;各个卷积模块后面都追加BatchNorm 和PReLU。
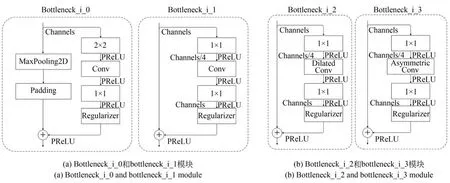
图6 内层网络模块结构Fig.6 Structure of inner network modules
3.3 加权Hausdorff 距离
本文的损失函数构建来源于Hausdorff 距离[32]。X,Y是两个无序的点集,d(x,y)表示两个点集X,Y之间的距离,其中,x∈X,y∈Y,本文采用欧氏距离。X,Y拥有的点的数量可以不同Ω⊂R2表示包含所有可能点的空间,则集合X⊂R 与集合Y⊂R 的Hausdorff 距离定义为:
其中:
Hausdorff 距离的最大短板是对轮廓上的点的距离计算相对敏感[33]。为了优化这个问题,通常采用加权的Hausdorff 距离,如下:
其中:|X|,|Y|分别为集合X,Y点的数量,在本文中,Y表示图像目标定位点坐标标签集合,X表示预测的图像目标定位点坐标集合。
语义图P可以得到每个点的激活概率值,但是并不能返回预测点的坐标。为了建立语义结果与坐标点最终的联系,采用加权Hausdorff 距离(Weighted Hausdorff Distance,WHD)函数进行构建,即:
这里ε设定 为10-6,Mα为广义均值函数,px∈[0,1]为语义图P中每个坐标对应的概率值。
3.4 损失函数
为了训练整个ILWLNet,结合加权Hausdorff 距离函数和回归的点的数量差,构建ILWLNet 整体损失函数如下:
其中:G为图像的标签包含目标点的坐标和目标数量,C=|G|,为预测的目标点数量。
Lreg(x)为回归项,这里采用L1平滑函数。
4 实验与结果分析
4.1 实验数据集与训练策略
为了充分验证ILWLNet 的性能,本文选用3 组数据集。数据集一:笔记本螺孔定位数据集,原始数据共358 张,原图与中心点坐标融合后的示例图见图7 的第一行。数据集二:笔记本螺孔定位数据集,原始数据共318 张,原图与中心点坐标融合后的示例图见图7 的第二行。数据集三:纱车机定位数据集,原始数据共529 张,原图与中心点坐标融合后的示例图见图7 的第三行。

图7 数据集示例Fig.7 Dataset sample
ILWLNet 训练和测试的模型均运行在Ubuntu16.04 操作系统的工作站上。硬件的具体配置如下:CPU,Intel Xeon(R)CPU E5-1650 V4 3.6 GHz 12 核;内存,32 GB,显卡,Nvidia Ge-Force 1080Ti;软件配置如下:CUDA,10.0;cuDNN,7.6.1.34;深度学习框架,PyTorch 1.0.0;Python,3.6 版本。选择Loss 值最小的模型作为单次测试验证的最优模型,实验模型超参数配置如表1 所示。

表1 模型超参数设置Tab.1 Model super parameter setting
4.2 评价指标
为了充分验证ILWLNet 的性能,本文利用Precision,Root Mean Squared Error(RMSE)和Mean Average Hausdorff Distance(MAHD)进行衡量。其计算公式如下:
其中:TP(True Positive)表示预测正确,实际为真;FP(False Positive)表示预测错误,实际为真;FN 表示预测错误,实际为假;TN 表示预测正确,实际为假;N表示测试集的数量,Ci表示第i 张图片中实际目标的个数,表示预测的第i张图片目标个数。
4.3 实验结果与分析
4.3.1 对比分析
在本次实验中,综合考虑不同配比的训练数据对模型定位性能的影响,对训练数据、验证数据和测试数据选用以下配比进行实验,Train∶Val∶Test 分别设置为10%∶10%∶80%,20%∶10%∶70%,30%∶10%∶60%,40%∶10%∶50%,50%∶10%∶40%,60%∶10%∶30%,70%∶10%∶20%,80%∶10%∶10%,在图8 和图9 的Loss 曲线图中分别对应loss_1~loss_9。使用ILWLNet 算法训练,对8 种不同配比的数据训练并将训练过程Loss 值作可视化处理,以利于分析训练过程中损失函数Loss 值的变化情况。

图8 数据一训练的loss 曲线Fig.8 Trainning loss curves of dataset one

图9 数据二训练的loss 曲线Fig.9 Trainning loss curves of dataset two
如图8 和图9 所示,两种数据集在训练中Loss 值的整体变化趋势一致,随着训练数据量的增加,收敛速度越快。其中,训练数据大于等于40%,200 次迭代后基本收敛,然后逐渐趋于稳定,但依然出现小幅震荡;训练数据大于等于20%且小于等于40%,600 次迭代后基本收敛,然后逐渐趋于稳定;训练数据占比10%,1 000 次训练后仍会收敛。结合表3 和表4,虽然训练样本集在20%比例时,推理结果可以得到98%以上,但是为了达到定位精度小于等于5 pixel 的识别率大于等于99.5%,训练样本比例建议大于等于50%。与深度学习所需要的海量数据相比,ILWLNet 只需要150 张左右相对较少的数据即可收敛到很好的效果,更适用于工业智能制造的实际应用场景。
本文以Precision,MSE 和MAHD 作为评价指标,计算不同配比的训练数据在1 000 迭代后得到最优的收敛模型用于ILWLNet 推理,推理计算得到测试集的Precision 和RMSE 值;其中,训练集、验证集和测试集数据三者无交集。判定为定位准确的参数条件为:推理得到的中心点坐标与标签的中心点坐标均方差误差小于等于5,结果如表2 和表3 所示。
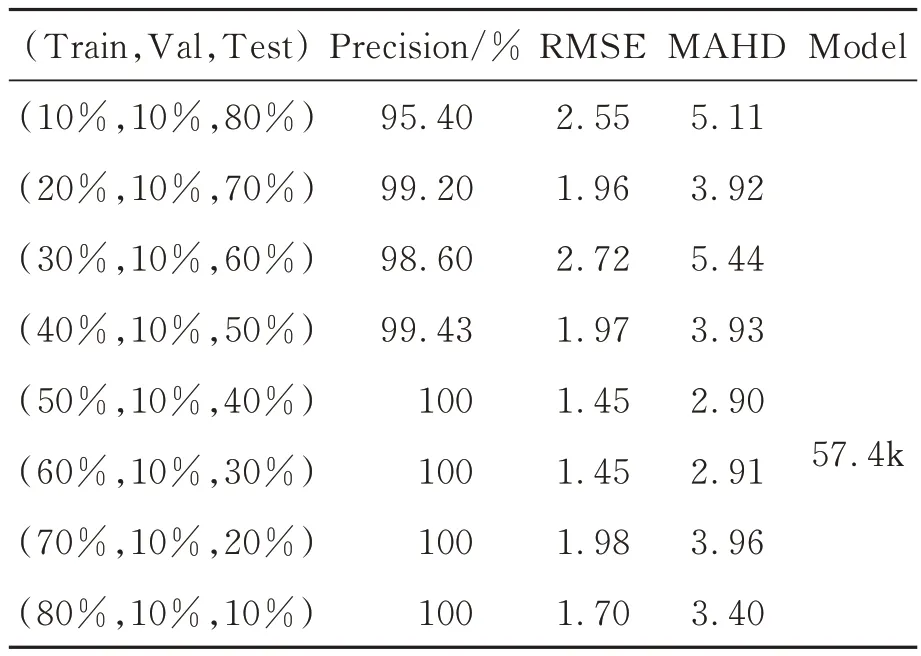
表2 ILWLNet 在数据集一中的定位测试结果Tab.2 ILWLNet localization test results on dataset one

表3 ILWLNet 在数据集二中的定位测试结果Tab.3 ILWLNet localization test results on dataset two
通过表3 和表4 可以看出,ILWLNet 网络可以进行零部件的精准定位。当训练数据占比在20%以上时,定位误差小于等于5 pixel 可以取得至少98%的准确率,平均准确率高于99%;当训练数据集在50%及其以上时,定位误差小于等于5 pixel 的准确率可以达到100%。随着训练数据的增加,测试推理得到的RMSE 和MAHD 误差值呈整体变小的趋势。相比较经典的深度学习网络(YOLO3,162 MB),ILWLNet 模型的参数量非常少,只有57.4 kB。这是由于ILWLNet 网络的Decoder 和Encoder 的层级较少,均为3 层,利用Bottleneck 技术代替直接的卷积方式且内部融入了非对称卷积和空洞卷积,因此模型参数量非常小。利用构建的加权Hausdorff 距离将输出的语义概率图与定位坐标点进行关联并构建Loss 函数进行闭环回归,ILWLNet 能够用于零部件的精准定位。另外,ILWLNet 网络采用Up_Block 与Down_Block 的对应特征层融合以及多级Bottleneck 级联,不仅提升了整体网络的非线性而且较好地恢复了原始图像的细节信息,配合构建的加权Hausdorff 距离,表明ILWLNet得到了非常理想的定位精度。由于构建的ILWLNet 模型参数较小,仅需相对较少的样本训练即可取得比较好的结果,通过表2 和表3 的不同配比实验定位结果得到证实;因此,ILWLNet 亦可适用于小样本训练,进而满足工业光学影像定位的小样本实际需求。

表4 ILWLNet 推理时间测试结果Tab.4 Test results of ILWLNet inference time(ms)
表4 展示了ILWLNet 推理时间测试结果,测试图片共100 张;其中,ILWLNet 网络前向推理平均时间为8.34 ms/frame,阈值分割的平均时间为86.58 ms/frame,ILWLNet 的整体运行时间平均为94.92 ms/frame,满足工业光学影像精准定位的200 ms/frame 需求。
4.3.2 测试集定位结果与分析
在闭环1 000 次迭代训练过程中,最小loss值对应的模型记为ILWLNet 在该次训练过程的最优模型。为了检验ILWLNet 网络的实际定位效果,利用3 组测试集数据进行验证。图10~图12 分别显示了数据集一、数据集二和数据集三的定位结果。其中,第一行显示的是原始图、第二行显示的是语义概率图P 经过归一化得到的结果、第三行显示的是语义概率图P 经过Otsu 阈值分割后的二值图、第四行显示的是原图加载预测中心点后的融合图。

图10 数据集一的测试定位结果Fig.10 Localization test results on dataset one
从第二行可以看出,ILWLNet 通过Encoder-Decoder 架构可以还原出原图(图像复原,用于缺陷检测[34])及其语义信息(语义分割[35]),Decoder的输出语义概率图P 呈现了完整的原图信息;另外,ILWLNet 将预测语义概率图P 与定位中心点坐标通过加权Hausdorff 距离进行了有效关联,因此,概率图中的螺孔中心点区域灰度明显高于图片中的任何其他区域,从而可以通过Otsu 自适应分割方法将中心点区域精准分割出来。第三行呈现了语义概率图P 经过Otsu 自适应分割后的结果,可以看出除中心点区域为白外,图片中的其他区域均为黑,因此得到的中心点坐标不会发散。
图10 左一的螺孔内部受到光照(拍摄角度和光线)的影响,小部分区域呈现黑色;左二的外壳的最左边没有拍摄清楚,整体呈现黑色,与其他图相差较大。图11 右一和右二的螺孔最里面白色内圈明显不圆(拍摄角度影响)。此类图片如果采用传统的圆拟合、模板匹配等方法,定位结果会大打折扣。仿真及实测结果表明,ILWLNet算法不仅可以对正常的零部件样本进行精准定位,而且对受到光线干扰、部分缺损的零部件图片的定位效果仍然很好。

图11 数据集二的测试定位结果Fig.11 Localization test results on dataset two
图12 为纱车机图像定位结果。此组图像受光照影响较为严重,四组图像均出现明显的反光,右二和右一的矩形中心孔周围受到了强光干扰;另外,图片中的矩形孔并不唯一,利用传统模板匹配方法可能会出现误匹配,再叠加光照的影响,传统定位算法性能会受到严重影响。通过仿真及实测的结果可以看出,ILWLNet 算法不仅适用于圆形的零部件定位,而且适用于其他样式的零部件精准定位,同时兼顾较好的抗干扰效果。

图12 数据集三的测试定位结果Fig.12 Localization test results on dataset three
4.4 消融实验
为了验证 conv_async,Down_Block_1,Down_Block_2,Down_Block_3,Up_Block_1,Up_Block_2,Up_Block_3,特征拼接融合(Encoder 与Decoder 对应层padding 及融合,记为Fusion)以及WHD 对模型性能的影响,对ILWLNet进行消融研究,实验结果如表6 所示。测试数据选用数据集一,其Train∶Val∶Test 数据集比例选用50%∶10%∶40%。
通过表5 可以看出:不包含WHD 模块,ILWLNet 算法不收敛,表明WHD 模块可以有效关联输出语义概率图P 与定位坐标点的关系。配置一:只配置WHD 模块,其他模块中的卷积均采用经典的3×3 卷积,此时模型大小为85.1 kB,识别率为87.94%,说明本文架构不采用多级bottleneck 级联仍可以收敛,不过相比较ILWL-Net,模型参数量增加了27.7 kB,定位准确率降低了12.06%。配置二:只配置Fusion 以及WHD 模块,其他模块同配置一,模型大小为109 kB,识别率为93.62%;相比较配置一,通过Encoder 与Decoder 对应层的融合使得识别率提升约5.68%,但是模型参数增加了接近24 kB,表明相对较大的模型在充分训练后一定程度上可以取得相对较好的识别效果。配置三:配置conv_async,Down_Block_1,Down_Block_2,Down_Block_3,Fusion 和WHD 模块,相比较配置一准确率提升4.97%,模型大小减小7.1 kB,表明bottleneck_i 模块可降低模型参数量,同时多级bottleneck_i 模块级联增加了网络的非线性,可提升识别率。配置四:采用conv_async,Up_Block_1,Up_Block_2,Up_Block_3,Fusion和WHD 模块,准确率基本不变,略微下降,模型参数减小9.4 kB,表明Up_Block 中的非对称卷积和空洞卷积起到了降低模型参数量的作用,但是没有与Encoder 的对应层融合,对识别率提升没有太大影响。配置五:ILWLNet 算法中去掉Fusion 模块,其他模块同配置一,模型参数量相比配置一降低了30.3 kB,但是识别率却降低了2% 左右,表明Down_Block 的bottleneck_i 模块以及Up_Block 融合的conv_async 模块可有效降低模型参数量,Fusion 模块对于网络整体性能的提升起到了很大的作用;通过配置一和配置二的比较,Fusion 模块提升4.97%的识别率(各模块内部卷积均为常用的3×3 卷积),而相比较ILWLNet,配置五的识别率却降低了14.2%左右,表明conv_async、Down_Block、Up_Block 和Fusion 模块的级联进一步提升了整体ILWLNet 的非线性及识别性能。
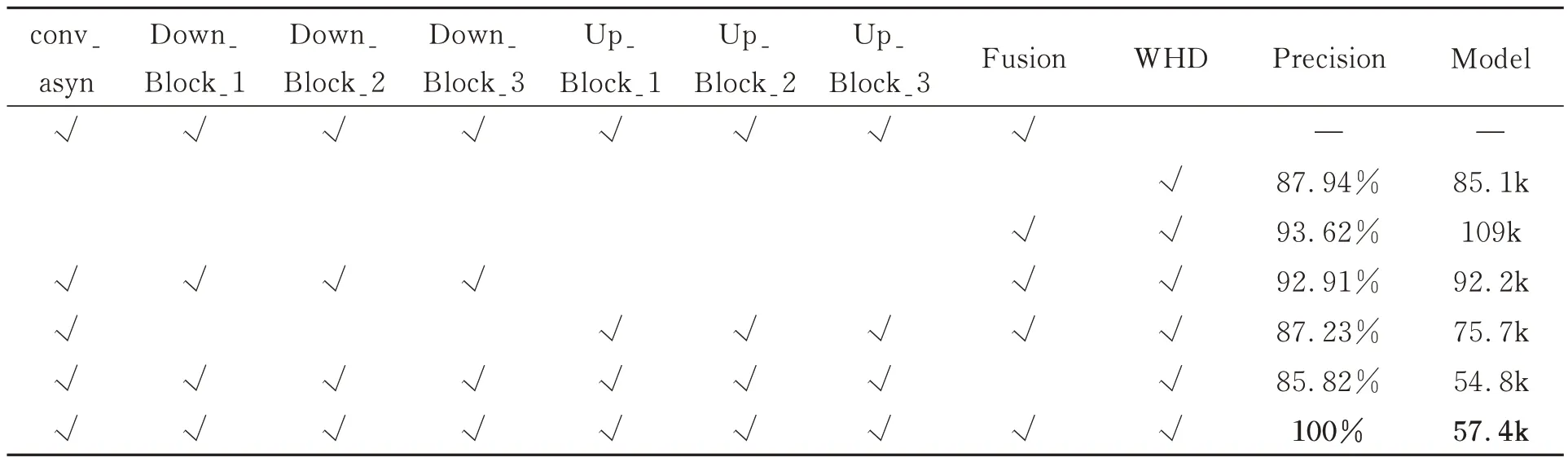
表5 不同策略对模型性能的影响对比Tab.5 Comparison of impact of different strategies on model performance
5 结论
本文根据现代工业光学影像定位精度高、占用资源小、抗干扰好、速度快的要求,构建了零部件视觉精准定位的轻量化深度学习网络,并介绍了零部件光学影像定位系统的硬件结构和工作原理。然后,阐述了轻量化深度学习定位网络的架构、模块结构、加权Hausdorff 距离及其损失函数。实验结果表明:轻量化深度学习定位网络模型参数为57.4k;通过实际产线数据仿真,训练数据集多于150 张,定位精度小于等于5 pixel 的识别率不小于99.5%,基本满足工业零部件定位的精度高、准确率高和抗干扰能力强等要求。仿真测试表明,ILWLNet 已经在笔记本螺孔和纱车机实际工业产线数据中取得了较好的识别率和定位精度,可是后续将ILWLNet 进行产线实际应用,需要考虑数据的泛化性,即需要更多不同种类的产线定位数据集进行验证以及上线测试。此外,ILWLNet 的推理时间大多消耗在Encoder-Decoder 阶段后的Otsu 自适应分割流程中,因此后续会对其进行进一步优化,提升推理速度。
