结合环状原型空间优化的开放集目标检测
2023-09-26孙旭豪沈阳魏秀参安鹏
孙旭豪,沈阳,魏秀参*,安鹏
1.南京理工大学计算机科学与工程学院,南京 210094;2.高维信息智能感知与系统教育部重点实验室,南京 210094;3.社会安全图像与视频理解江苏省重点实验室,南京 210094;4.中国海洋石油集团有限公司信息技术中心,北京 100010
0 引言
目标检测任务旨在定位图像中的目标并为每个目标返回其类别。鉴于深度学习在视觉任务上的成功(Chen 等,2019;Zhou 等,2020;Wei 等,2021;Shen等,2022),近年来基于深度学习的检测模型出现了诸多改进(Ren 等,2015;Hu 等,2018;Kong 等,2020;Tan 等,2020;闫子旭 等,2021;贾可心 等,2022),并取得了显著进展。这些检测方法均基于同一个设定,即所有目标类别在训练阶段都是已知的。然而在实际检测任务中,这样的闭集设定往往不能满足需求,例如在自动驾驶任务中,未知的物体和场景会不断出现;在医学图像分析任务中,未知的疾病类型也会不断出现。因此,研究者们开始关注开放集环境下的目标检测任务(Dhamija 等,2020;Joseph 等,2021;Han 等,2022)。开放集问题最早由Scheirer 等人(2014)提出,他们还定义了一个基本的开放集识别问题(open-set recognition,OSR)。在开放集设定下,目标检测任务不仅需要返回训练集中包含类别的对应物体位置,还需要返回训练集中未出现的类别的检测结果。
在开放集目标检测任务下,基于封闭集设定下训练得到的目标检测器会错误地将待检测图片中未知类别的对象视为背景类,或是由于神经网络本身倾向于产生过于自信的预测结果的原因(Lakshminarayanan 等,2017),将未知类别预测为某种训练集中的已知类别。事实上,一般而言目标检测器容易产生两种类型的错误:第1 种是将感兴趣的目标识别为另一个对象或背景,即将已知类识别为背景类或未知类;第2 种是将背景样本或未知类别对象误识别为感兴趣的类别之一,即将背景类和未知类识别为已知类。一方面,虽然以往所有闭集条件下的检测方法在添加未知类阈值进行筛选后,都在一定程度上具有识别开放集环境下未知类与背景类的能力,但是很难在真实场景下精确调整这些阈值。另一方面,目前PASCAL VOC(pattern analysis,statistical modeling and computational learning visual object classes)(Everingham 等,2010)和MS COCO(Microsoft common objects in context)(Lin 等,2014)等常用的检测数据集使用的评估指标无法充分评价检测器对未知对象的鉴别能力。因此,Dhamija等人(2020)基于已有的目标检测任务,对开放集环境下的目标检测任务(open-set object detection,OSOD)进行了定义以进行开放集环境下检测任务的探索。
然而,如图1(a)所示,现有的OSOD 领域方法在训练过程中通常将背景类与未知类归纳为一个类别进行训练。一个最直观的例子是,现有的OSOD领域中的先进方法(Han 等,2022)设计了K+1 路分类器进行类别划分。其中,K路分类器代表K个已知类别,1 路分类器代表未知类别与背景类别的集合(即非已知类别)。而后,Han 等人(2022)在实验中通过采样与前景类别数量相同的背景类别进行模型训练,并通过最小化最大类别概率(min maxprobability)的方法筛选出背景类。该框架在检测任务中将背景类与未知类视为一个类别进行优化,虽然有更强的区分已知类别的能力,但是框架对未知类别的识别能力较差;同时,在进行未知类别与背景类别区分的过程中,框架还需要额外对背景类图像进行与前景类别图像数量相同的采样以重新训练区分未知类别与背景类别的模块,需额外的计算资源开销。因此,为了更好地区分开放集设定下重要的未知类目标,同时去除冗余的大批量背景类别采样步骤,本文提出了一种新的开放集检测框架。如图1(b)所示,一方面,通过环状原型空间优化分类器的设计,使分类器可以聚焦于已知类与未知类的识别;另一方面,通过随机覆盖已有推荐框的方式进行背景类别的筛选,在保留区域推荐RPN(region proposal network)层提供的带有目标候选框的优势的同时,提升了RPN层区分背景框的精准度,且无需额外进行背景类采样步骤。综上所述,本文的主要贡献总结如下:
1)提出一种新的开放集检测框架,使检测头在进行开放集类别识别的过程中,优先识别候选框属于背景类或是含待识别目标类别,而后进行已知类与未知类的判别。
2)提出基于环状原型空间优化的检测器,该检测器可以通过图像特征在高维空间中的稀疏程度对已知类、未知类与背景类进行分层,使得已知类目标的特征在高维空间中更加紧凑,而背景类特征则在高维空间中更加稀疏,提升模型的检测性能。
3)在RPN 层后设计了随机覆盖候选框的方式筛选相关的背景类训练框,避免了以往OSOD 工作中额外设计的背景类采样步骤。
1 相关工作
本节将分别介绍开放集图像识别、开放集目标检测、原型学习与估算不确定性这4 个方面的相关工作。
1.1 开放集图像识别
开放集图像识别任务最早由Scheirer 等人(2014)定义并启发了该领域的许多后续工作(Scheirer 等,2014;Ge 等,2017;Xu 等,2022)。Geng等人(2021)在后来的综述性工作中又将开放集图像识别任务中的相关样本概括为4 种类型:1)已有辅助信息的已知类(known known classes,KKCs):即具有明显标记的正训练样本的类(也可作为其他KKCs的负样本),甚至具有相应的语义/属性信息等;2)无辅助信息的已知类(known unknown classes,KUCs):KUCs包含带有标签信息的负样本,即属于目标识别范围外的已知类别,如背景类别(Dhamija 等,2018)或同域下的非目标类别(Weston 等,2006)等;3)有辅助信息的未知类(unknown known classes,UKCs):即在训练过程中没有任何标记样本的类别,但是在训练过程中样本本身的语义或属性信息可以被获得;4)无辅助信息的未知类(unknown unknown classes,UUCs):即在训练过程中没有任何标记的样本,且在训练过程中无法获得样本相关的辅助信息。
早期对于开放集图像识别问题的尝试(Scheirer等,2014;Jain 等,2014)通常利用传统的机器学习方法,例如支持向量机等方法。Bendale 和Boult(2016)引入了第1 种基于极值理论的开放集图像识别方法OpenMax,这是第1 种基于深度学习的开放集图像识别方法。其他开放集图像识别方法包括:1)基于生成式对抗网络的方法(Ge 等,2017;Neal等,2018),这些方法通过生成与训练集类别相似却不属于任何已知类别的图像来构成未知类并通过生成的图像额外训练一个开放集分类器;2)基于特征重构的方法(Yoshihashi 等,2019;Sun 等,2020),这些方法采用自编码器用以生成潜在图像特征,并通过重构误差来辨别未知特征与未知类别;3)基于原型学习的方法(Shu 等,2020;Chen 等,2020),这些方法通过学习到的类别原型表示已知的类别,并根据测试集图像的特征到不同类别原型的距离来识别开放集图像。
本文方法与通过原型学习解决开放集图像识别的方法(Shu等,2020;Chen等,2020)更相关。不同的是,在开放集目标检测的问题下,不能简单地将识别到的目标分为已知类和未知类,其中还有背景类等干扰类别,本文方法能有效地将包含目标的检测框与背景框相分离,同时区分出已知类别与未知类别。
1.2 开放集目标检测
开放集目标检测任务是开放集图像识别任务(Scheirer 等,2014)在目标检测领域的扩展。Dhamija 等人(2020)首先对开放集目标检测问题进行定义,并对一些具有代表性的目标检测方法在开放集的设定下进行基准实验测试。Dhamija 等人(2020)还提供了一种用于评估开集条件下目标检测器性能的指标。
Miller 等人(2018)在训练过程中采用丢弃若干样本的方式以估计目标检测的不确定性(DeVries 和Taylor,2018),以此减少开放集环境下的误差。Joseph 等人(2021)通过拟合已知类和未知类的能量分布提出了一种基于能量的未知标识符。使用额外的内存空间来模拟神经网络的记忆缓存,不仅实现了对未知类物体的坐标回归,还挖掘了未知类物体潜在的类别。但是该方法需要额外的未知类数据集,这与开放集目标检测问题的定义相违背。最新的开放集目标检测方法(Han 等,2022)通过对比特征学习器使已知类的特征更加紧凑,通过未知类概率学习器解决开放集识别问题。然而这种方法将未知类和背景类统一归纳成其他类别(即开放集类别)并进行分类器的优化,无法更清晰地划分背景类与未知类的边界。与该框架不同,本文框架将未知类与已知类归纳为包含物体的类别,将背景归纳为物体无关的类别。方法首先通过目标随机遮挡的方式检测框中是否包含待检测物体,而后通过原型学习识别物体是否属于目标类别。
1.3 原型学习
在传统机器学习中,原型学习仅包含原型选择与原型生成,其旨在从源集中寻找一个原型子集,该子集能够最大程度保持目标集所含信息,且所有元素具有最少的重叠信息。而深度学习中的原型学习一般还包括了在获得类别原型后网络对其利用与开发的方式。深度学习中的原型学习(Snell 等,2017)最早应用于少样本学习,Snell 等人(2017)还提出了原型网络ProtoNet 以解决少样本分类问题。原型网络(Wang 等,2019;Shang 等,2021)主要通过计算测试图像和每个类别原型之间的距离来学习一个度量空间。在处理开放集识别问题(Yang 等,2018)、分布外样本问题(Arik 和Pfister,2020)、少样本学习问题(Snell 等,2017;Gao 等,2019)和零样本学习问题(Wang 等,2021)时,原型学习具有更强的稳健性(Yang 等,2018)。在开放集目标检测问题中,基于原型学习的深度学习方法(Xiong等,2021)目前只是利用类别原型和测试图像的特征来计算识别过程中的分类距离。本文方法不仅可以将包含目标的检测框与背景框分离,而且可以区分出已知类别与未知类别。
1.4 估算不确定性
神经网络倾向于产生过于自信的预测结果(Lakshminarayanan 等,2017)。评估物体检测器的一个核心是避免错误检测的能力。尽管现有方法在训练过程中让模型拒绝已知类别之外的其他类别,但来自开放世界的未知物体最终会被模型错误地检测为已知类别,并且模型往往会给出很高的置信度(Dhamija 等,2020)。因此,对模型预测的不确定性进行估计对于实际应用很重要。目前,不确定度估计方法可分为基于采样和无采样两个方向。基于采样的方法(Lakshminarayanan 等,2017;Gal和Ghahramani,2016)通过集成的方式增加预测准确度。而无采样的方法通过学习一个额外的、平行的置信度评估分支(DeVries 和Taylor,2018)来估计不确定性。由于样本采样的方法需要成倍的时间进行结果估计,不适用于有速度要求的目标检测任务,因此本文方法属于后者,方法学习到的未知概率不仅可以反映未知类别的预测不确定性,还可以反映是否物体无关(即属于背景类)的不确定性。
2 方 法
2.1 问题描述
根据以往工作(Dhamija 等,2020;Han 等,2022)对本文研究的开放集检测问题(OSOD)做出定义。首先,定义集合D={(x,y),x∈X,y∈Y}作为目标检测的数据集。其中,x代表待检测图像,X代表待检测图像的集合,y=代表其对应待检测图像中包含的N个目标的类别与标注框。其中ci∈C代表第i个目标的类别,C代表所有标注数据的类别集合,bi代表第i个目标的标注框。定义训练集为Dtrain,测试集为Dtest。训练集Dtrain共包含K个已知类别CK={1,2,…,K},CK∈C。测试集Dtest包含训练集中的K个已知类别CK以及U个未知类别CU,CU∈C。在测试过程中,由于无法得知CU具体代表何种类别,因此统一命名为未知,即CU中所有的类别构成该任务中的第K+1 个类别。与开放集识别任务(OSR)不同的是,OSOD 任务还包含背景类,即在测试过程中,模型预测得到的检测框中既不包含已知类物体,也不包含未知类物体。一般地,将这种背景类定义为CBG,CBG∉C。与以往的OSOD 任务不同的是,在检测过程中,不会将CU与CBG统一归结为未知类进行优化,然后采取额外的后处理进行区分。
2.2 网络架构
网络的主体架构如图2 所示。具体而言,本文采用Faster region-CNN(Ren 等,2015)作为方法的骨干网络,其中包括一个特征金字塔网络(feature pyramid network,FPN)层,一个区域推荐网络(region proposal network,RPN)层以及一个R-CNN 层。对于给定的输入图像,FPN 层可以将多个阶段的特征图融合在一起,在提取高层特征图的语义特征的同时提取低层的轮廓特征。RPN层则可以定位图像中所有对象的可能位置。此阶段将输出所有对象可能位置的边界框列表。R-CNN 层则对RPN 层推荐的候选框进行对齐与特征提取,并进行相应的分类与回归任务。一个标准的R-CNN 层包含一个共享的全连接层与两个独立的、用于分类和回归的全连接层。不同于以往的开放集检测工作,本文的分类层主要用于区分前景类中的已知类与未知类,背景类的区分工作则通过额外设计的候选框覆盖采样以及环状原型空间进行划分。值得注意的是,本文改进的部分结构并没有提升模型在闭集问题上的精度,因此与其他方法的对比实验是公平的。

图2 基于环状原型空间优化的开放集环境下目标检测框架图Fig.2 Framework of open-set object detection based on annular prototype space optimization
2.3 环状原型空间
在开放集设定的目标检测任务下,训练过程中只能获得各训练样本的已知类别目标的标注框以及类别标签,无法获得任何未知类别的标注信息与标签信息。因此,开放集设定下的目标检测任务的首要目标就是使模型具有更强的划分已知类与未知类的能力。
一般而言,已知物体的特征易在潜在空间中聚集形成高密度区域,而未知物体或是背景框的特征则会分布在低密度区域(Grandvalet 和Bengio,2004;Ren 等,2018)。因此,在没有未知类别与背景类别定义以及样本信息的情况下,很难通过分类器进行区分,现有的划分方式一般是通过直接设定不同的置信度阈值进行背景类与未知类别的划分。本文通过设计环状原型空间来缓解未知类与背景类的特征在潜在空间中密度相似的问题,而分类器则着重用于关注已知类与未知类的划分。
在训练过程中通过原型学习将具有已知类目标的样本约束到所属类别原型的附近,同时增大背景类样本与各个原型的距离,为其余含有未知类目标的样本留出了一个介于这两种样本之间的环状空间。具体而言,经过RPN 层筛选出候选框后,由于候选框大小不同,因此各候选框需要通过式(1)的对齐方式进行计算,得到对应大小的特征图
式中,P=与P12分别代表待对齐候选框的左上像素的横坐标与纵坐标,P21与P22分别代表待对齐候选框的右下像素的横坐标与纵坐标。代表向上取整计算,代表向下取整计算。wi,j代表待计算像素点的实值,out代表输出像素的实值。而后将这些对齐后的特征经过box head 层映射为一维特征后作为环状原型空间中相应特征的输入,并将这些特征构成已知类的原型空间。
在训练过程中,首先筛选出包含待检测物体的候选框构成含待检测目标类别,根据训练过程中的真实标签将它们划分为已知类别候选框与未知类别候选框;其余候选框构成背景类别。背景类的判别方式具体在2.4小节提出。将未知类按RPN 层输出的置信度进行升序排序,筛选其中最高的L项作为未知类特征;将背景类候选框同样按RPN 层输出的置信度进行升序排序,其中最低的I项作为背景类特征。对于L项未知类特征,将其输入到分类层进行优化,最大化其在未知类CU中的logit 值,最小化其在已知类CK中的logit值。由于该L项均为未知类特征,所以在训练过程中添加同一批处理下的已知类特征进行二分类损失优化即可,记损失函数为Lbce。
在训练过程中,标签为背景的候选框可以分为非目标类以及无实例样本,希望在背景类中选取的I个样本能包含尽可能多的无实例样本。但模型本身并不对非目标类负责,仅仅是在目标类监督训练的过程中对非目标类有了一定的感知能力。因此背景类中无实例样本占大多数,对无实例样本的选取策略也可以更加激进。选取L个样本的目的是让模型学习到不同于目标类的实例特征,但由于上述原因,很难在背景类候选框中获得大量非目标类样本。所以本文选择通过目标类候选框中置信度较低的部分样本来学习非目标类特征,如果选取策略过于激进就会导致目标类与非目标类的特征混淆,反而降低了模型对于已知目标的检测精度。
在每一次批处理中,对于所有被选取的已知类特征、L项未知类以及I项背景类特征,将它们作为环状原型空间的输入。环状原型空间的优化策略为:对于每一个已知类别CK,按下式为其单独生成一个类别原型
式中,xtrain代表训练图像,fDNN(·)代表候选框生成模型,该模型由FPN 层与RPN 层组成,Θ1代表该模型的参数。fbox_head(·)代表用于生成特征的全连接层,Θ2代表该全连接层的参数。Fx代表从样本x筛选出的所有候选框的特征集合,包括已知类、未知类与背景类的特征。B代表一次批处理的图像数量,Bk代表一次批处理中属于已知类别k的特征向量的数量。I(·)代表指示函数,若Fx中的特征属于类别k,则输出为1,否则输出为0。得到类别原型后,算法将最小化每个已知类特征向量与其对应的类别原型的距离,即将环内的高密度空间作为每个类别的特征空间,K个类别也依次对应了K个原型环集合H。对于极低密度的环外空间,本文将其作为背景类的特征空间。在算法优化过程中,需要最大化背景特征向量与各原型环的最小距离以形成环的外边界,每个类别原型环的外边界各不相同。而环内的较低密度空间则作为未知类的特征空间。环状原型空间的优化损失函数为
2.4 随机覆盖采样
本小节主要给出方法判断未知类与背景类候选框的具体方案。事实上,区域推荐层(RPN 层)的作用即筛选出包含有待检测目标的候选框。因此,通过RPN 层后,模型会返回所有候选框以及其属于前景类的置信度。然而在开放集环境下,由于训练过程中只能获得已知类的标签信息,因此,只能在训练过程约束已知类别的候选框。而开放集目标检测问题要求在识别已知类的基础上严格区分背景类与未知类。由于已知类与未知类都包含具体待检测目标,其在RPN 层筛选过程中没有差异,因此,额外设计了随机覆盖采样的方式用以提高RPN 层区分背景类与含目标类别的能力。
如图3 所示,随机覆盖采样的核心思想是:属于未知类别的候选框进行较小范围的随机覆盖采样后,其对应生成的特征向量对比原候选框有较大幅度的变化;而属于背景类别的候选框经过较小范围的随机覆盖采样后,其生成的特征向量不会有较大的改变。具体而言,待检测图像在经过区域推荐网络(RPN层)得到候选框后,对于所有的候选框,方法会对其进行N次幅度较小的随机覆盖,而后对原候选框和N次随机覆盖后的候选框通过特征提取网络生成对应的N+1 个特征向量,将原候选框对应的特征向量作为判别中心,将N次随机覆盖所得候选框的特征向量与判别中心的余弦相似度之和作为其属于未知类别的置信度,置信度越高说明候选框中包含未知物体的概率越大,反之则说明候选框为背景框的概率越大。
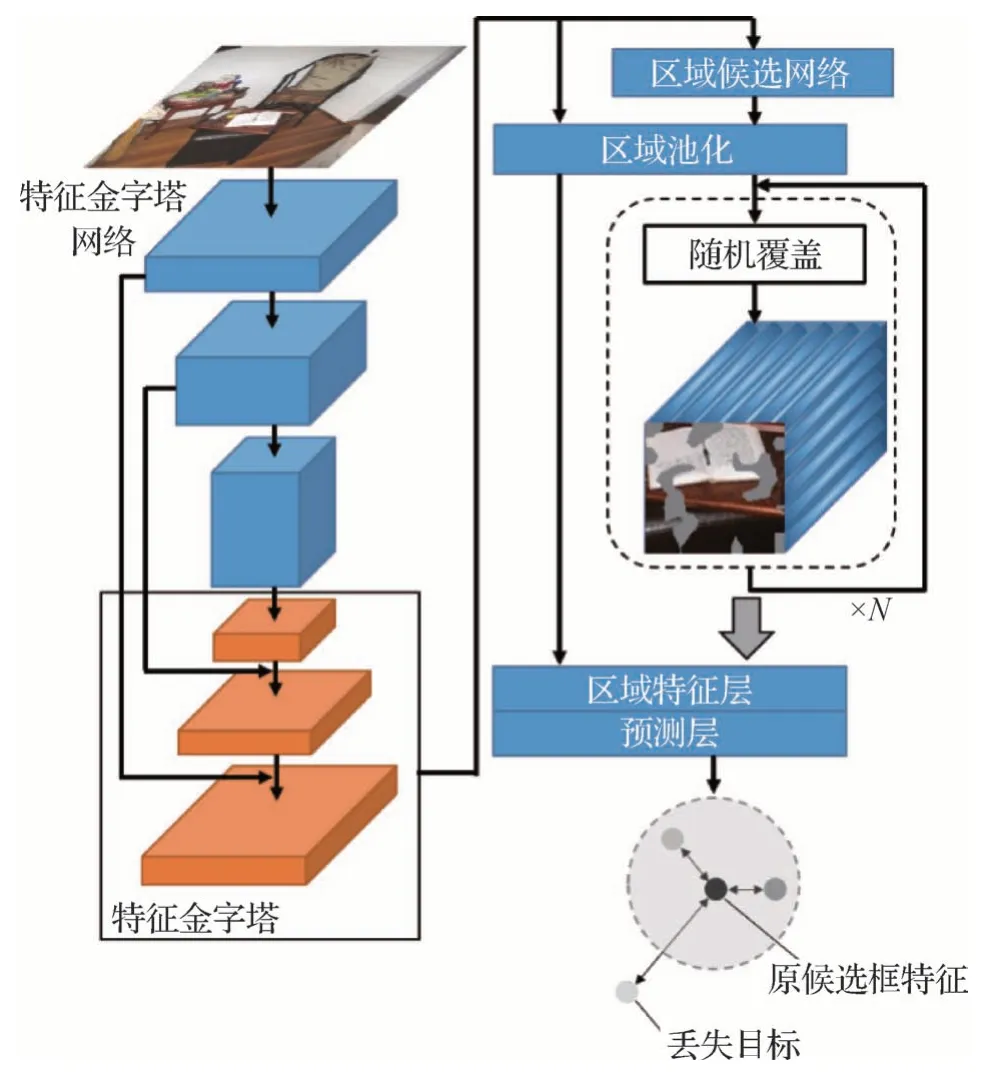
图3 候选框随机覆盖采样Fig.3 Random overlay sampling for proposal regions
当候选框中不存在目标时,框内所有像素都属于背景类,屏蔽部分像素并不会对模型预测产生较大影响。而当候选框中存在目标时,框内像素可以被分为2 类或更多,屏蔽像素对原有语义分布的扰动也就更加明显。例如,某个候选框的内容是一个人站在一堵墙前面。如果屏蔽了部分属于墙的像素,那么属于人的像素占比就会增加,导致模型的预测更偏向于人。反之则更偏向于墙。而且如果屏蔽区域属于前景的关键部分,则会破坏原有语义,进一步增加对模型输出的扰动。综上,该模块完成了含目标类别与背景类别的区分任务。
2.5 模型训练
本文方法可以通过以下多任务损失进行端到端的训练
其中,Lce代表分类器损失,Lrpn代表RPN 层的总损失,Lreg代表候选框回归的平滑损失,Lapro代表环状原型空间损失,Lbce代表二分类损失。α与β为相关损失的权重系数。
3 实 验
3.1 数据集与数据划分
本文所用的开放集目标检测数据集VOCCOCO(Visual Object Classes-Common Objects in Context)由PASCAL VOC(Everingham 等,2010)和MS COCO(Lin等,2014)构成。
1)PASCAL VOC数据集。PASCAL VOC包含20个目标类,其中常用的有VOC 2007 以及VOC 2012。VOC 2007 包含2 501 张训练图片、2 510 张验证图片、4 952 张测试图片以及总计2.4 万个标注目标。VOC 2012 包含5 717 张训练图片、5 823 张验证图片以及总计2.7万个标注目标。
2)MS COCO 数据集。MS COCO 于2014 年由微软发布,包含8.3 万张训练图片、4.1 万张验证图片和4.1 万张测试图片。2015 年新增4 万张测试图片。2017 年训练集和验证集的数量更改为11.8 万以及0.5 万。其中目标标注分为80 个类别,并且完全包含PASCAL VOC的20个类别。
为了公平进行实验对比,本文实验使用VOC 2007 的训练集以及VOC 2012 的训练验证集,共14 041张图片和39 405个标注目标进行封闭集环境下的模型训练。同时,参照Han等人(2022)的工作,本文使用相同的两个实验设置对开放集环境下模型的检测性能进行评估。
设置1:逐步增加开放集类别数量,并以此构建了3 个测试数据集。其中,VOC-COCO-20 包含VOC 2007的4 952张测试图片以及MS COCO 的训练验证集中20 个VOC 类、20 个非VOC 类的5 000 张图片。VOC-COCO-40 在此基础上增加了MS COCO 中另外20 个非VOC 类的4 332 张训练验证集图片。VOCCOCO-60 则又增加了MS COCO 中最后20 个非VOC类的5 668张训练验证集图片。
设置2:逐步增加包含未知类目标的图片数量与包含已知类目标的图片数量的比值WR(wilderness ratio)(Dhamija等,2020)。具体而言,在4 952张VOC 2007 测试图片的基础上分别加入2 500、5 000 以及20 000 张MS COCO 的训练集与验证集图片,以此构建了3 个测试数据集VOC-COCO-0.5n、VOC-COCO-n与VOC-COCO-4n。
3.2 评价指标
对于一个理想的目标检测器,开放集数据的加入不会对封闭集数据上的精度产生影响,因此本文在固定召回率后,计算未知目标对检测器的已知目标准确率产生的影响wilderness impact(WI)来衡量方法的开放集检测性能
式中,PK为封闭集环境下的识别准确率,PK∪U为开放集环境下的识别准确率。同时还使用开放集中已知类AP(average precision)的平均值(mean average precision,mAP)来比较不同方法对已知类目标的检测性能。
检测器还应当对未知类目标具有一定的检测能力。本文使用未知类目标被错误分类的数量AOSE(absolute open-set error)以及未知类目标的AP(APU)来比较方法对未知目标的检测性能。
3.3 基线方法与实验设置
3.3.1 基线方法
为了验证本文方法的开放集检测性能,在3.1节描述的两个开放集设置下,对共计6 个测试集进行实验,并将本文方法与目前最具代表性的5 个开放集检测方法进行对比。对比方法包括FR-CNN(Faster-CNN)(Ren 等,2015)、PROSER(placeholders for open-set recognition)(Zhou 等,2021)、Open ORE(world object detector)(Joseph 等,2021)、DS(dropout sampling)(Miller 等,2018)和OpenDet(open-set detector)(Han 等,2022)。FR-CNN 是二阶段目标检测的基础方法,FR-CNN*则在此基础上采用了更高的测试分数阈值。PROSER 在训练过程中将所有非已知目标检测框都作为未知目标。ORE采用基于能量的判别器识别潜在的未知目标。DS对原特征进行多次dropout,以dropout对预测结果的影响大小判断未知目标。OpenDet 扩展低密度特征空间,并鼓励紧凑的提议特征,一次区分已知和未知目标。
3.3.2 实验设置与细节
实验的软硬件配置为Intel(R)Xeon(R)Silver 4210R CPU @ 2.40 GHz,256 GB内存,GeForce RTX™3090 GPU,Ubuntu 18.04.6 LTS(64 位)。深度学习框架为PyTorch 1.10.0和Detectron2 0.6。
为了公平地进行方法对比,将改进的方法应用于Faster R-CNN的骨干网络中,在PASCAL VOC上共训练了32 000个step,batch-size大小为16。使用随机梯度下降(stochastic gradient descent,SGD)优化器,动量设置为0.9,权值衰减为10-4。学习率先从2 × 10-4经过100 次学习线性增长到2×10-2,然后分别在第21 000和29 000次学习时衰减为原来的1/10。非已知类划分的超参数I与L分别为200与6,随机覆盖次数N为3,损失函数的权重系数α与β分别为0.1与1。
3.4 实验结果
如表1所示,首先在3.1节描述的实验设置下验证本文方法在开放集设定下的检测性能。在拥有几乎相同封闭集检测能力的模型下(VOC 数据集下,mAPK相似),在逐渐增加未知类的VOC-COCO-20,VOC-COCO-40 以及VOC-COCO-60 三个测试集的4个指标上均领先于现有方法。与FR-CNN 相比,设置了较高的测试阈值(0.05→0.1)的FR-CNN*并没有降低WI 指标,但导致mAPK下降。PROSER 在一定程度上改善了AOSE 和APU的得分,但在WI 和mAPK上的表现相比于FR-CNN 更差。ORE 和DS 对开放集度量的效果有限,而本文方法在较小的已知类AP 均值(mAPK)提升下,在各个开放集指标中都有大幅提升。以VOC-COCO-20 为例,虽然mAPK仅有0.1%的提升,但是WI 有约0.7%的提升,AOSE指标降低了约1 000,未知类AP(APU)也有约1%的得分提升。
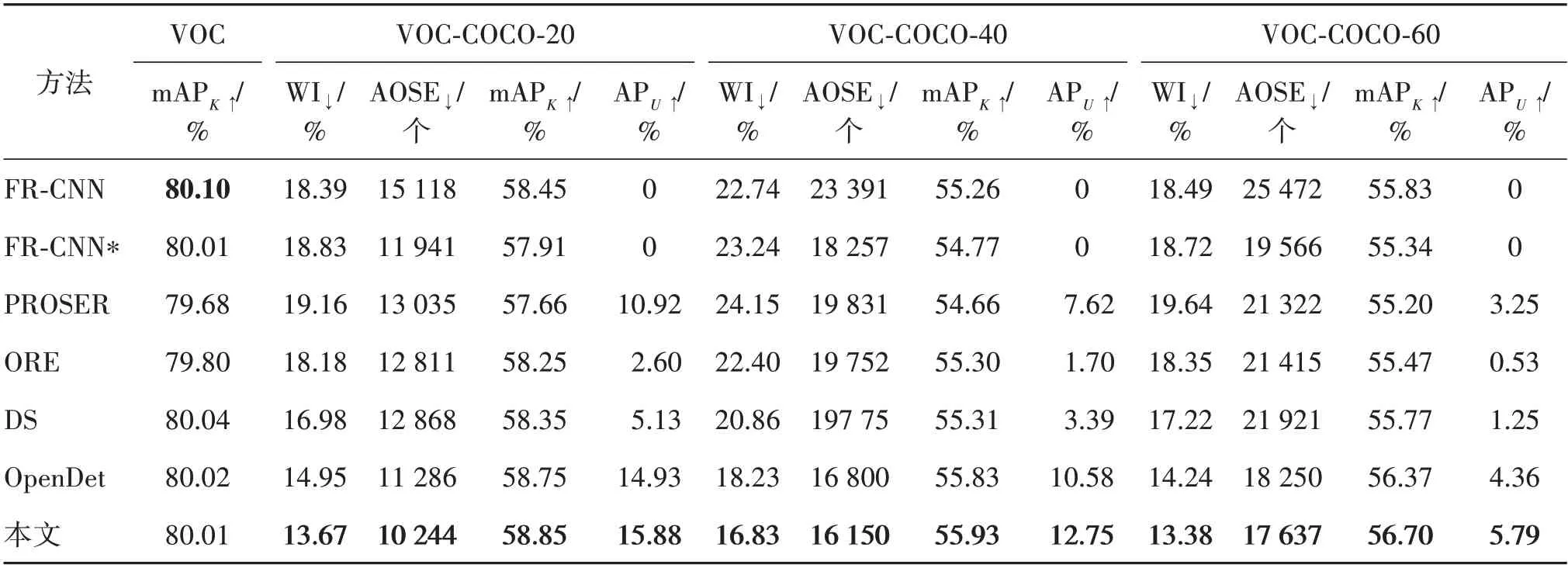
表1 本文方法在VOC与VOC-COCO-设置1数据集中的实验对比Table 1 Comparison with other methods on VOC and VOC-COCO-T1
另外,还通过增加未知类目标的图片数量与包含已知类目标的图片数量的比值WR,将本文方法与其他方法进行了比较,结果如表2 所示,可以得到与表1 类似的结论。随着WR 的增加,本文方法在大部分实验中得到了更好的性能。
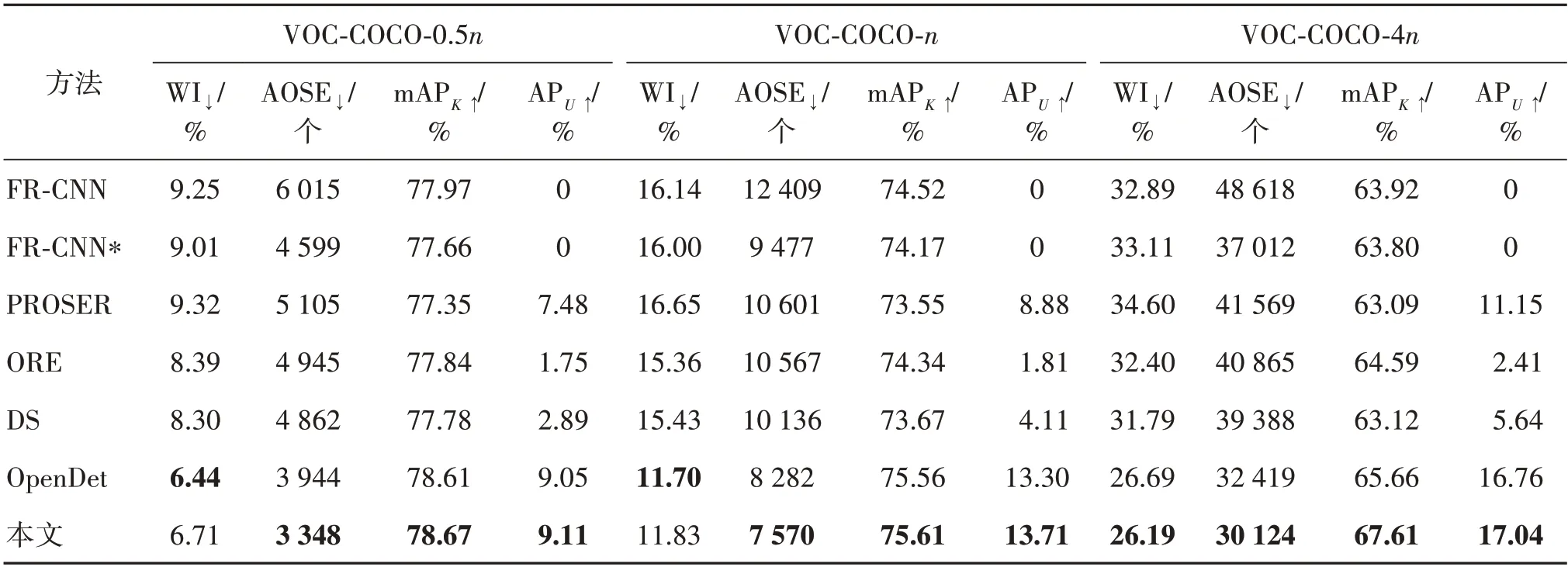
表2 本文方法在VOC与VOC-COCO-设置2数据集中的实验对比Table 2 Comparison with other methods on VOC and VOC-COCO-T2
3.5 消融实验
为了验证本文方法的主要结构在开放集目标检测中的有效性,在VOC-COCO-20数据集上进行了消融实验。如表3 所示,首先分析本文提出的两种结构对开放集目标检测的性能影响。可以看到,在引入环状原型空间后,模型在已知类与非已知类中的检测能力得到较大提升,而在单独引入随机覆盖模块时,模型对未知类的检测能力得到较大提升。在同时引入环状原型空间与随机覆盖模块后,模型在已知类的精度(mAPK)上只降低了0.04%,证明随机覆盖模块不会对原有模型对已知类与非已知类的检测能力带来影响,且有更强的区分非已知类中的背景类与未知类的能力。同时,在APU指标上获得2.5%的提升也证明了两个模块之间有相互促进作用。
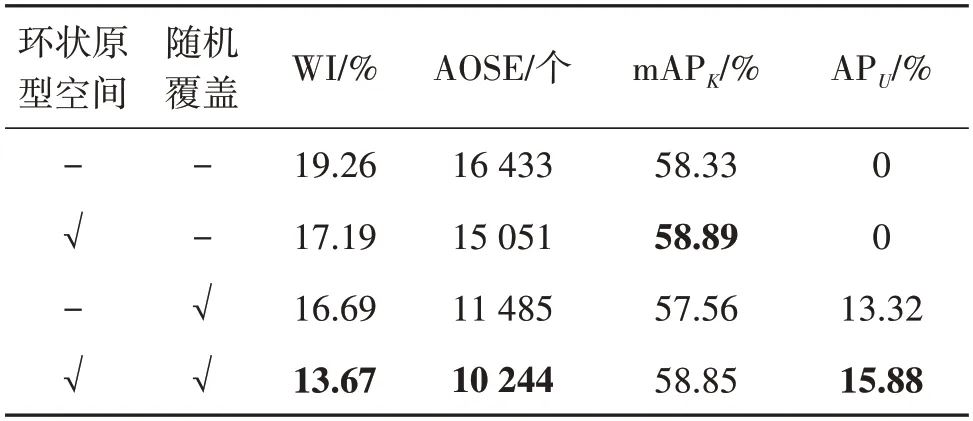
表3 本文方法在VOC-COCO-20数据集上的有效性Table 3 Effect of different components on VOC-COCO-20
而后研究了超参数I与L对实验结果产生的影响。如表4 所示,首先固定L的大小为6 并改变I的大小进行消融实验。其中,|bx|代表对于每个样本x,模型提供的候选框的数量,与大部分检测任务(Ren等,2015;Zhou 等,2021;Han 等,2022)相同,其值恒等于512。随着I的提升,模型对未知类与背景类的划分能力稳步上升,并在100与200时达到峰值。最后固定I的大小为200 并改变L的大小进行消融实验。如表5 所示,当L等于6 与12 时,模型检测能力达到峰值。
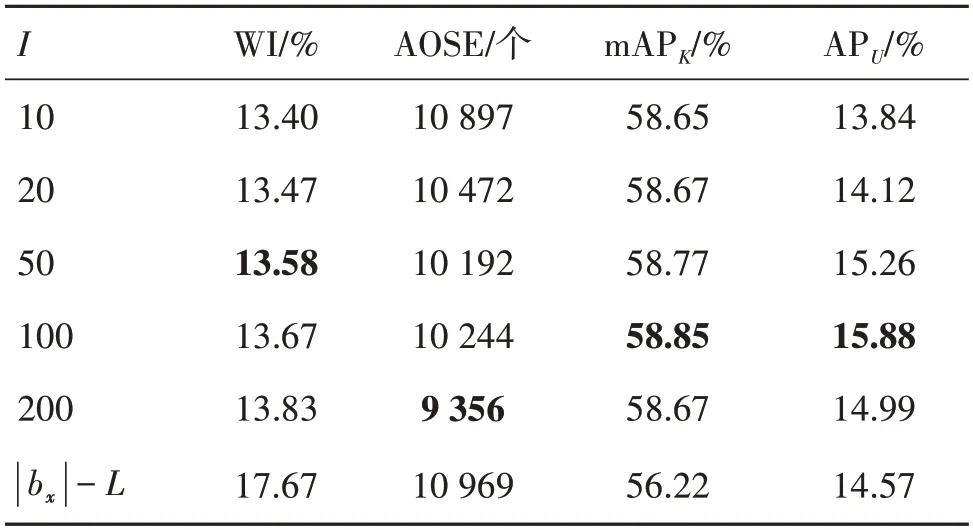
表4 超参数I在VOC-COCO-20数据集上的消融实验Table 4 Ablation study for I on VOC-COCO-20
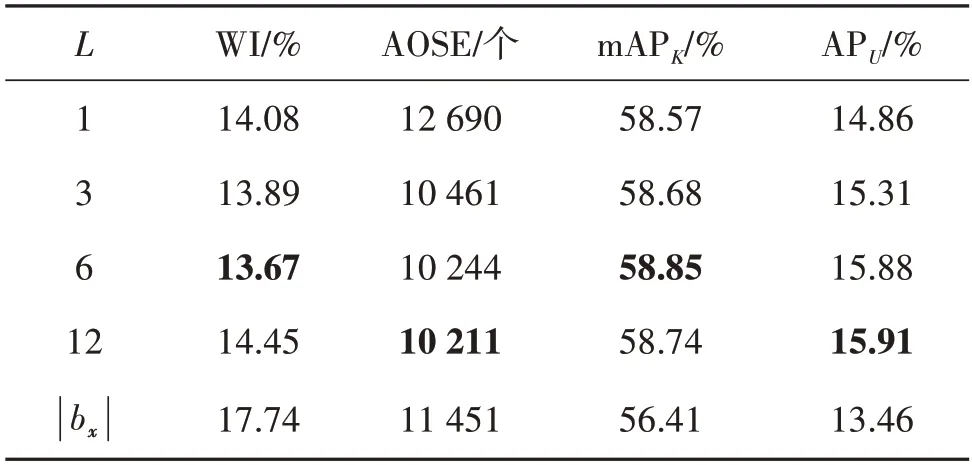
表5 超参数L在VOC-COCO-20数据集上的消融实验Table 5 Ablation study for L on VOC-COCO-20
如图4所示,比较了基线方法FR-CNN与本文方法在PASCAL VOC 上训练后在MS COCO 上的检测效果。“熊”、“斑马”、“手提箱”等标签没有被引入模型,因此被本文方法标记为“未知”,而基线方法将它们分类为“狗”、“马”、“巴士”等已知类。

图4 基线方法与本文方法在检测结果中的对比Fig.4 Qualitative comparison between the baseline and our method
4 结论
本文提出了一种新的开放集目标检测框架,使检测头在进行开放集类别识别的过程中,优先识别候选框属于背景类或是含识别目标类别,而后进行已知类与未知类的判别;接着提出基于环状原型空间优化的检测器,用以对已知类、未知类与背景类进行分层;最后在区域推荐层后设计了随机覆盖候选框的方式筛选相关的背景类训练框,避免了以往OSOD 工作中烦琐的背景类采样步骤,同时提高模型对背景类与未知类的判别能力。本文在开放集检测的基准数据集上对提出的方法进行了评估。在2 个不同的实验设置、6 个数据集下,大部分数据指标相较于对比方法取得了不同程度的提升,证明了方法有较强的区分已知类、未知类与背景类的能力,消融实验也证明了本文方法中每一个模块的有效性。在未来工作中,希望进一步研究已知类检测性能与未知类检测性能间的相关性,同时希望将待检测类别扩展到少样本(贺小箭和林金福,2022)、细粒度(魏秀参 等,2022)等研究情形。
