元迁移学习在少样本跨域图像分类中的研究
2023-09-26杜彦东冯林陶鹏龚勋王俊
杜彦东,冯林*,陶鹏,龚勋,王俊
1.四川师范大学计算机科学学院,成都 610101;2.西南交通大学计算机与人工智能学院,成都 610031;3.四川师范大学商学院,成都 610101
0 引言
得益于强力的计算设备、丰富的数据及先进的模型与算法,深度学习在图像识别(He 等,2016;陈硕 等,2021)、目标跟踪(Bertinetto 等,2016;王蒙蒙等,2022)、自然语言处理(Ren 和Lu,2022)等领域取得了极大成功,同时也推动了人工智能的飞速发展。
深度学习模型要想获得最优效果,需要在大规模标注数据中进行训练。然而,在军事、医疗、金融等一些特定领域,由于涉及数据隐私和安全性等问题,数据获取困难且标注代价高昂。与机器相反,人类拥有从有限样本中快速学习的能力。受人类学习方式的启发,人们提出了少样本学习(few-shot learning,FSL)的概念,目的是使机器也能像人类一样,仅靠少量标注的样本通过一两次的示范,就可以学会一类问题的解决。
元学习是少样本学习的重要应用场景,目标是使机器学会学习。元学习通过多任务的学习范式积累多任务的“共性知识”,利用这些“共性知识”指导模型在新任务中快速学习(赵凯琳 等,2021)。同样,迁移学习也是解决少样本学习问题的另一种经典方法,基于迁移学习的方法旨在利用大量标注数据集进行预训练学习知识,并将这些知识迁移到监督信息有限的目标任务中以完成对少量标注样本的学习(张玲玲 等,2021)。
现有的少样本学习方法只考虑到训练阶段的源任务和测试阶段的目标任务服从相同或相似分布的情况,当源域任务与目标域任务数据分布相差较大时,传统的少样本图像分类模型在目标任务中表现较差。图1 为少样本跨域示例,在图1(a)—(d)中,用于训练的基类来自源域自然数据集mini-ImageNet,而测试的新类数据来自目标域医疗数据集Chest-X。为解决上述问题,少样本跨域学习引起了研究者的关注(Guo 等,2020)。少样本跨域学习旨在利用源域中大量标注样本训练模型,使模型能够快速、准确地泛化到与源域数据分布差异较大的目标域任务中。

图1 少样本跨域示例Fig.1 Cross-domain example with few-shot((a)training sample;(b)domain adaptation;(c)few-shot learning;(d)cross-domain few-shot learning)
对于少样本跨域学习的研究,起源于域适应学习,目的是将源域数据中的知识迁移到具有不同数据分布的目标域中。为解决域适应问题,研究者探索出基于域差异的方法(Long 等,2017;Sun 等,2016;Kang等,2019;Kumar等,2018),旨在对齐源域和目标域之间的边缘分布。基于对抗的方法(Tzeng等,2017;Ganin等,2016)主要思想是依靠生成器、鉴别器相互作用促进域相关特征的学习。基于重构的方法(Zhu 等,2017;Hoffman 等,2018)通常使用encoder-decoder 模型或生成对抗网络来重新构建目标域中的数据。但上述关于域适应的方法均只适用于目标域与源域类别有交集的情况(如图1(a)—(c))。而现实应用场景中,广泛存在源域和目标域的类别交集为空,且目标域中可用样本数量少的跨域学习问题,如罕见的皮肤病病理图像、失事飞机残骸图像、卫星遥感图像,而利用其他带标注数据充足的域信息(如自然数据集ImageNet)来解决这些域上的子任务是一种很有效的解决方法。因此,如何提升少样本跨域图像分类性能具有重大的理论研究意义和应用价值。
已有的少样本跨域相关研究表明,当目标域任务与源域任务的数据分布相差较小时,元学习方法表现更好。反之,迁移学习方法表现更好(Chen 等,2019)。因此,融合迁移学习和元学习的思想,本文提出一种简洁的元迁移学习模型(compressed meta transfer learning,CMTL),以解决少样本学习中源域与目标域之间分布差异大的跨域分类问题。
本文主要贡献如下:1)在模型预训练和微调阶段,使用Wang 等人(2020)提出的自压缩损失函数(self-compression softmax loss,SSL),通过最小化自压缩损失函数,调整基类数据原型之间的分布位置,促使基类样本在嵌入空间中更为集中,为新类样本预留部分嵌入空间,有效提升了模型的特征提取能力。2)提出一种数据增强策略,利用现有目标任务中有限的支持集样本构建新的辅助任务,微调模型参数,以获取适应当前测试任务的网络参数,解决当源任务与目标任务数据分布差异较大时,“元知识”的普适性不佳、泛化能力弱的问题。3)融合迁移学习和元学习策略提升跨域分类精度。以mini-ImageNet 作为源域数据集训练,并在4 个少样本跨域学习标准评估数据集 EuroSAT(European Satellite)、ISIC(International Skin Imaging Collaboration)、CropDiseas(Crop Diseases)和Chest-X(Chest X-Ray)上验证了CMTL方法的有效性。
1 相关研究
1.1 少样本学习
少样本学习方法主要分为基于梯度优化的方法、基于度量学习的方法和基于迁移学习的方法3类。
1.1.1 基于梯度优化的方法
基于梯度优化的方法通常包括内外两个循环阶段,内循环阶段基模型学习器快速适应于只有少量样本的新任务,外循环阶段元模型学习器学习跨任务的知识以得到好的泛化性能。Finn等人(2017)提出的模型无关元学习方法,通过在多个任务中学习,以找到最适合模型的一组初始化参数,使模型在新的任务上能够快速泛化。Nichol 等人(2018)提出Reptile方法,使用一阶梯度优化,从而简化模型无关元学习方法的微分计算。Ravi 和Larochelle(2017)提出基于长短期记忆网络的元学习器模型,通过学习模型参数的更新规则来调整不同训练任务之间的差异,促使模型拥有更好的性能。
1.1.2 基于度量的方法
基于度量的方法通常分为基于欧氏空间度量和非欧氏空间度量两种。其中,基于欧氏空间经典的度量方法有如下几种:由Vinyals 等人(2016)提出的匹配网络引入注意力机制和记忆机制,将样本映射到高维空间,使用余弦相似度衡量相似性。Snell 等人(2017)提出的原型网络通过计算待分类样本与类原型之间的欧氏距离完成分类。Sung 等人(2018)提出的关系网络也是基于欧氏空间的自适应的关系度量模块,将支持集和查询集的特征向量拼接输入可计算关系得分完成分类。余游等人(2019)在关系网络的基础上,利用半监督学习方法生成伪标签的策略参与训练。Garcia 和Bruna(2018)提出的图神经网络(graph neural network,GNN)应用于少样本学习问题,首次关注非欧氏空间在度量模型中的运用,利用向量拼接嵌入的方式完成图像数据到图结构数据的转换,继而在图神经网络模块中进行距离度量和关系推导。
1.1.3 基于迁移学习的方法
基于迁移学习的方法首先利用大量标注数据的基类预训练一个优质的特征嵌入网络,然后迁移到新类任务中,微调预训练阶段的分类器,使模型适用于当前任务。Chen 等人(2019)提出了baseline 及其变体baseline++,多组对照实验发现,在相同的实验参数设定上,baseline 和baseline++方法明显优于基于元学习的少样本学习方法。Wang 等人(2020)证明了迁移学习中使用自压缩损失函数训练模型能够获得性能较好的特征嵌入网络。Rajasegaran 等人(2021)提出自监督学习结合知识蒸馏最小化原始增强对距离,通过教师学生网络约束模型,提升基于迁移学习方法的少样本分类性能。
1.2 少样本跨域学习
少样本跨域学习包括基于元学习的方法和基于迁移学习的方法。
1.2.1 基于元学习的方法
为解决少样本跨域问题,Yeh 等人(2020)提出在测试任务中构建伪查询集的方法对元学习模型进行微调,提升少样本跨域分类能力。Wang 和Deng(2021)直接以参与训练的任务为研究对象,利用随机卷积方法构造更具“挑战性”的任务,从而在源域上模拟分布相对复杂的目标域任务。Tseng 等人(2020)引入特征变化层对卷积网络获取的特征进行仿射变换,以提高模型对不同域的适配性。Sun 等人(2021)提出基于层相关性传播的解释方法,能够知悉样本中对分类结果有贡献的区域,适当增大这些区域的权重系数,以提取更好的样本特征。
1.2.2 基于迁移学习的方法
Phoo 和Hariharan(2021)提出利用源域数据训练获取的教师学生网络对部分目标域无标签数据集构造伪标签、结合源域数据共同训练教师学生网络,以提升跨域分类精度。Fu 等人(2021)通过mix-up算法构造辅助数据集,并使用编码器学习与域无关的特征,以指导网络能快速泛化到域跨度较大的目标任务。Li 等人(2021)提出将源域、目标域各自特定领域的特征映射到相同的共享空间,从而实现与领域无关的通用特征表示。
综上所述,以上方法只是单独地从元学习、迁移学习层面分析并解决少样本跨域图像分类问题,却没有考虑到在跨域任务上元学习与迁移学习方法各自的优势。现有方法缺乏有效融合元学习、迁移学习策略提升跨域分类精度的模型与方法。所以本文提出了CMTL 模型,以完成对少样本跨域任务的推理分类。
2 少样本跨域学习定义
目前,少样本跨域学习多是基于元学习架构。架构通常将任务作为训练和测试的基本单元。元学习通过学习大量源域训练任务,使模型获得“元知识”,具有快速适应少样本目标任务的能力,完成对目标任务的分类。其学习过程如下:
2)测试阶段。在目标域测试任务集中随机抽取一个元测试任务Te∈Tte,利用测试任务的支持集St,生成样本级分类函数(λ)=F*(θ*;St),然后使用测试任务查询集Qt完成对(λ)分类效果的评估。
3 CMTL模型
3.1 基本思路和总体分析
首先,将源域数据集分别以批次、任务作为训练数据的基本单元进行划分。然后,在预训练阶段,将源域数据输入特征嵌入网络,先后以元学习和传统的深度学习方式在源域任务上预训练模型;在微调阶段,对目标域中的同一测试任务,分别利用元学习方法、迁移学习方法获取其对应模型的预测分数。最后,将两者模型的预测分数融合。利用迁移学习和元学习方法各自在跨域任务上的优势,完成少样本跨域任务的推理分类。
基于上述思路,CMTL 的总体结构如图2 所示。主要包括特征提取模块、BL-SSL(baseline-selfcompression softmax loss)模块、度量模块和分类策略融合模块。

图2 CMTL模型Fig.2 CMTL model
3.1.1 特征提取模块
在少样本跨域学习中常采用卷积神经网络(convolutional neural network,CNN)中的残差网络ResNet10(residual network10)和ResNet18(residual network18)作为特征提取网络。对于图像样本xi,经特征提取网络后获得样本特征fθ(xi)∈RC×H×W,其中,C、H和W分别代表图像通道数、样本特征高度和宽度。本文使用的ResNet10 如图3 所示,由初始的1 个64 通道的7 × 7 卷积层、批归一化层、3 × 3 最大池化层和之后4个卷积块组成。其中,第1个卷积块包含2 个3 × 3 卷积层、2 个批归一化层和2 个ReLU(rectified linear unit)激活层,后续3 个卷积块中每个卷积块中包含2 个3 × 3 卷积层,2 个批归一化层,2 个ReLU 激活层,2 个下采样层。每个卷积块之间的差别在于卷积层的通道数不同,依次为64、128、256、520。

图3 ResNet10网络结构Fig.3 ResNet10 network backbone
3.1.2 BL-SSL模块
由于传统监督学习没有考虑到少样本学习中训练测试阶段样本类别不一致的问题,未能为新类样本留下足够的特征嵌入空间。本文使用SSL 损失函数代替传统的SL(softmax loss)损失函数,能够保证在基类可分的情况下,尽可能拉近基类之间的距离,为新类样本预留更多的嵌入空间。受此启发,为提升迁移学习方法跨域分类性能,本文将SSL 损失函数应用于迁移学习的训练测试过程。
在训练阶段,SSL 损失函数在保证基类可分、拉近类原型之间距离的双重优化目标下,模型尽可能压缩来自源域的基类数据所占据的嵌入空间,便于测试阶段对来自目标域的新类数据的特征提取。
BL-SSL 模块中,通过计算样本经特征嵌入网络获取的高维特征向量与基类类原型向量在嵌入空间中的余弦相似性,调整基类类原型在嵌入空间中的分布位置。
调整基类类原型的过程如图4 所示,根据向量加法的平行四边形法则,完成类原型向量wc与wi的相加操作,以遍历调整非c类样本的类原型在嵌入空间中的分布位置。调整过后的非c类样本原型向量可表示为
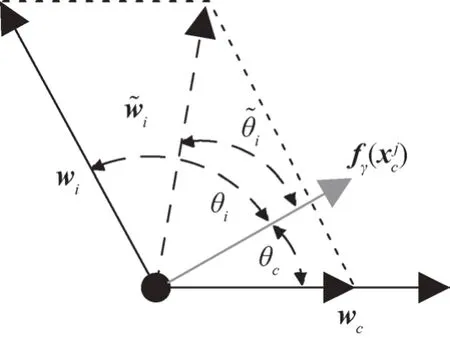
图4 类原型调整过程Fig.4 Adjust the class prototype
利用调整后的类原型向量与样本特征向量计算当前样本属于i类的概率,记为p=i|xj),具体为
式中,γ为特征嵌入网络参数,C为基类的样本类别总数为当前样本xj的预测值为调整过后的类原型向量。
通过计算当前样本属于c类的概率,SSL 损失函数可表示为
式中,C为基类的样本类别总数,γ为特征嵌入网络参数,Nc为第c类中的样本数量为当前样本xj的预测值。
通过不断压缩基类类原型之间的距离,促使嵌入空间中基类数据的特征分布更为集中。通过最小化式(3)损失函数,采用随机梯度下降(stochastic gradient descent,SGD)的方法反向传播更新参数。
3.1.3 度量模块
度量学习中,根据度量方式的不同,主要以欧氏空间、马氏距离、余弦相似度和非欧氏空间的图神经网络作为度量策略。为简化实验,本文从以原型网络为代表的欧氏空间度量和图神经网络为代表的非欧氏空间度量的两种网络模型出发,仅探索两种度量方式对少样本跨域模型的影响。
基于欧氏空间度量的原型网络假设每个类别在向量空间都有一个类原型,通过计算待分类样本与每个类的类原型之间的欧氏空间,根据距离衡量待分类样本与各类的类原型之间的相似性,完成对待分类样本的正确分类。
由于基于欧氏空间的少样本度量学习方法不能有效捕捉到样本特征和样本标签之间的联系,严重限制了少样本跨域学习模型的表达能力。针对这一问题,Garcia 和Bruna(2018)提出利用图神经网络来构建少样本分类模型,结构如图5 所示。GNN 由两阶段构成,第1 阶段是图像数据场到图结构数据场的转换,为利用图神经网络创造前提;第2 阶段是将图结构数据输入到以基于空间的图卷积网络(graph convolutional network,GCN)为基础架构的信息传递网络训练,以指导生成最优模型完成对未知类别图像进行推理判断,进而达到分类的目的。
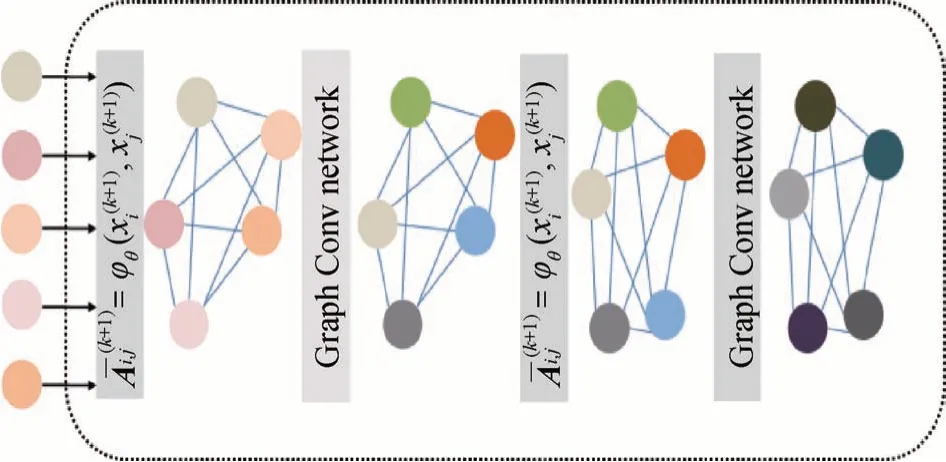
图5 图神经网络Fig.5 Graph neural network
3.1.4 分类策略融合模块
元学习通常将任务作为训练和测试的基本单元。为适应元学习的学习过程,使模型适用于当前任务,本文对测试任务中的支持集进行颜色变换、随机裁剪等一系列数据增强操作,如图6所示。

图6 数据增强Fig.6 Data augmentation((a)original image;(b)gamma transform;(c)random cutting;(d)color change)
经过数据增强后获取的辅助任务记为Taux,具体为
辅助任务生成的流程如算法1所示。
算法1:辅助任务Taux的生成。
利用生成的辅助任务Taux进行微调,使得微调后的度量模块参数更加适应于当前任务。
式中,θm代表训练阶段度量模块的网络参数,α为训练期间的学习率,Lm(Taux;θm)代表度量模块在辅助任务上的交叉熵损失函数。
在测试阶段,将目标域任务中有限的支持集通过上述算法构建辅助任务,以元训练方式继续微调度量网络Metric。其中,本文选用基于非欧氏空间度量的图神经网络和基于欧氏空间的原型网络分别作为Metric 网络,最后使用微调过的度量网络Metric 对查询级推理获取其对应预测分数。具体为
在迁移学习中,为简化运算,对任务中的样本不做任何数据增强操作。由于预训练阶段,使用自压缩损失函数,源域基类样本占据的空间得以压缩,此时目标域新类样本特征嵌入空间相对充裕。所以,固定BL-SSL 模块中预训练阶段的特征提取网络fθ,仅利用同一目标域任务中的支持集微调线性分类器SSL,以获取适应当前测试任务的分类器参数θssl,最后通过分类器SSL 对查询级分类并获取其对应预测分数,具体为
在测试阶段,将目标域的同一任务中样本分别喂入BL-SSL 模块和度量模块,得到其对应预测分数Sb和Sm,将两者预测分数分别通过softmax 函数进行归一化,确保在预测中两者的模型能被赋予相同的权重,最后将同一目标域测试任务经两种模块推理预测分数融合作为最终预测分数。
3.2 算法流程
根据上述讨论,在预训练阶段将源域数据输入特征嵌入网络,先后以元学习和迁移学习方法预训练模型。在微调阶段,基于预训练模型,联合迁移学习和元学习方法共同对目标域测试任务进行分类预测。微调阶段流程如算法2所示。
算法2:CMTL学习算法。
4 实 验
4.1 数据集和实验细节
本文在5 个经典的少样本跨域图像分类数据集上进行跨域分类测试,验证CMTL模型的有效性。
1)mini-ImageNet。是用于训练的源域数据集,是ImageNet 数据集(Russakovsky 等,2015)中抽离的子数据集,涵盖动物、植物等生活中常见的100 个类别,每个类包含600 幅图像,为了满足少样本跨域学习任务的需要,通常将100个类划分为64个训练类、16 个验证类和20 个测试类,图像规格为224 × 224像素。
2)EuroSAT(Helber等,2019)。是用于测试的目标域数据集,为卫星遥感图像,涵盖高速公路、农田等10 个类,共20 000 幅图像,图像规格为224 × 224像素。
3)CropDiseas(Mohanty 等,2016)。是用于测试的目标域数据集,为农作物病害数据集,包含38 个类,共54 300幅图像,图像规格为224 × 224像素。
4)ISIC(Codella 等,2019)。是用于测试的目标域数据集,为皮肤病黑色素瘤相关数据集,包含9 个类,共23 000幅图像,图像规格为224 × 224像素。
5)Chest-X(Wang 等,2017)。是用于测试的目标域数据集,为胸部X光图像,包含14个类,共112 120幅图像,图像规格为224 × 224像素。
在实验中,元学习方法的训练过程采用Adam优化器,学习率α=0.001;在迁移学习BL-SSL 模块的训练、微调过程采用SGD 优化器,学习率β=0.01。本文采用少样本跨域标准评估5-way 1-shot 及5-way 5-shot,同时从每一类采样15 幅图像样本作为查询集。在训练阶段,元学习以任务为基本单元参与训练,从源域数据集中随机采样100 个任务作为一个epoch,共训练400 次。迁移学习以监督学习的方式参与训练,从源域数据集中每一次随机抽取64幅图像作为一个epoch,共训练400次。在测试阶段,随机从目标域数据中抽取2 000个任务参与测试,其中,在BL-SSL 模块的微调阶段,使用任务中的支持集微调分类器,微调次数为100,每次微调图像样本批次大小为4,而在元微调阶段利用任务中的支持集生成辅助任务,微调模型的过程中,超参数λ1为0.5,λ2为0.8。训练次数为20,生成新的样本数量为25。最终,取全部测试任务的平均Top-1 准确率作为最终准确率。
本文采用的硬件环境为 NVIDIA RTX 3090 GPU 平台;操作系统为ubuntu 20.0.3、Pytorch框架。
4.2 实验结果与分析
为测试CMTL 方法的性能,选择mini-ImageNet作为源域,分别以EuroSAT、CropDiseas、ISIC 和Chest-X 作为目标域完成跨域分类测试。其中,选择原型网络作为度量模块记为CMTL(PRO),选择图神经网络作为度量模块记为CMTL(GNN)。实验结果如表1所示。

表1 与不同跨域分类算法对比实验结果Table 1 Compare with the different cross-domain classification algorithms
4.2.1 定量评估
从表1 可以看出,CMTL 方法在5-way 1-shot 和5-way 5-shot 跨域图像分类任务设定上都有较好的表现,并且与现阶段经典的少样本跨域图像分类模型比较,本文提出的CMTL 方法更具有优势。其中,基于5-way 1-shot 的任务设定,与最新的少样本跨域图像分类GNN+ATA 方法相比较,本文提出的CMTL方法在EuroSAT、ISIC、CropDiseas 和Chest-X 数据集上分别提升了7.52%、1.26%、7.45%和0.12%。相较于最新的迁移学习STARTUP 方法,除了在Chest-X 数据集上表现稍落后前者,CMTL 方法分别在EuroSAT、ISIC 和CropDiseas 数据集上提升了5.97%、2.13%和1.62%。而基于5-way 5-shot 的任务设定,与少样本跨域GNN+ATA 方法相比,本文方法在EuroSAT、ISIC、CropDiseas 和Chest-X 数据集上分别提升了4%、4.8%、2.78%和1.08%。与最新的迁移学习STARTUP 方法比较,除了在Chest-X 数据集上表现稍落后前者,CMTL 方法在EuroSAT、ISIC和CropDiseas 数据集上分别提升了5.93%、3.23%和1.68%。实验结果表明提出的CMTL 方法的有效性。
4.2.2 定性评估
从表1的跨域分类结果可以看出,提出的CMTL方法能很好地解决少样本跨域图像分类问题,其中BL-SSL 模块中的特征嵌入网络能充分提取更为丰富的特征信息。对于元学习,提出数据增强的策略生成辅助任务,能够进一步微调模型,以捕获到适合当前任务的合适参数。将二者对于相同任务的预测分数融合,可以使模型结合迁移学习和元学习方法各自的优点,促使少样本跨域图像分类更加准确。另外,除了在Chest-X上的跨域分类表现欠佳,CMTL(GNN)模型总体的跨域分类性能高于CMTL(PRO)模型。这是由于在跨域图像分类任务中,非欧氏空间的度量方式有效利用了样本特征与样本标签之间的联系,而欧氏空间度量的方法仅关注查询集样本与支持集样本的相似性,未考虑标签间的联系。由此可以看出,基于非欧氏空间的度量方式更适用于少样本跨域图像分类任务。
4.3 消融实验
为了研究CMTL 方法中多种因素对于少样本跨域分类准确率的影响,消融实验采用控制变量法的研究方法。
4.3.1 SSL使用阶段对跨域分类准确率的影响
为了研究BL-SSL 模块中SSL 使用阶段对于实验分类准确率的影响,分别在5-way 1-shot 和5-way 5-shot任务上,以4个标准数据集上平均跨域分类准确率作为评估标准,进行消融实验,结果如图7所示,其中SL代表使用softmax loss,SSL代表使用自压缩损失函数。SL+SSL 代表预训练阶段使用softmax loss,微调阶段使用自压缩损失函数,在5-way 1-shot 和5-way 5-shot 任务设定下,在EuroSAT、ISIC、CropDiseas 和Chest-X 数据集上的平均跨域分类准确率为42.5%和56.3%。实验结果表明,在预训练阶段和微调阶段均使用SSL能达到最好跨域分类准确率。
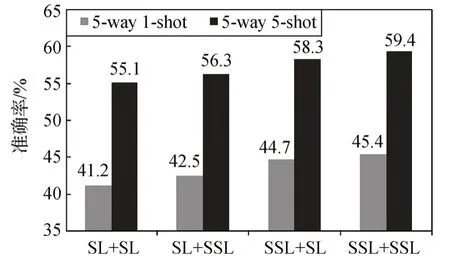
图7 SSL使用阶段平均跨域分类准确率Fig.7 Average accuracy at different stages of the SSL
另外,从EuroSAT 中随机选择5 个类别的数据特征进行T-SNE(T-distributed stochastic neighbor embedding)可视化,结果如图8所示。T-SNE 可视化表明,使用SSL 后更有利于新类样本的特征提取,提取的新类样本特征在保证类间可分的前提下,拉近了类间的距离,同样证明了基于迁移学习的少样本模型中引入SSL 损失函数能有效提升模型的跨域图像分类能力。
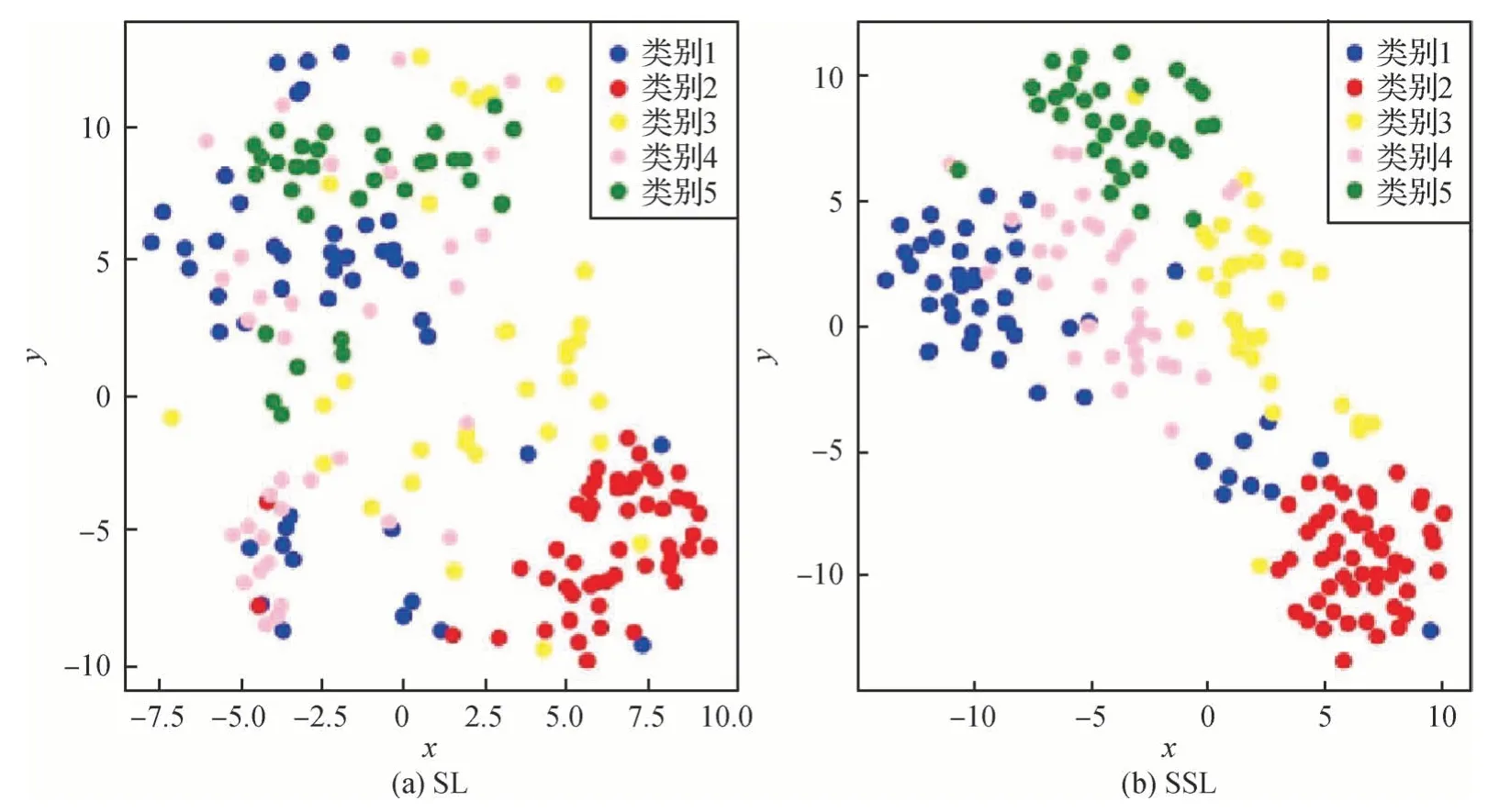
图8 EuroSAT数据集的T-SNE可视化Fig.8 T-SNE plot of EuroSAT((a)SL;(b)SSL)
4.3.2 单个模块对跨域分类准确率的影响
为了证明本文使用分类模块融合的有效性,分别使用图神经网络微调模块(GNN-FT)、BL-SSL 模块以及将两者分类预测结果的融合完成跨域图像分类实验,结果如表2 所示。可以看出,目标域与源域跨度较小,目标域数据集为EuroSAT 和CropDiseas时,GNN-FT 模块的跨域分类准确率优于BL-SSL 模块,反之BL-SSL 模块的跨域分类准确率优于GNNFT模块。两个模块分类融合的方法在4个标准数据集的平均分类准确率在5-way 1-shot 任务中,相较BL-SSL 和GNN-FT 模块分别高出4.2%和1.8%;在5-way 5-shot 任务中,跨域分类准确率最高,相较BLSSL 和GNN-FT 模块分别高出4.3%和2.1%。实验结果表明,融合两者分类预测结果是提升少样本跨域图像分类准确率的有效方法。

表2 消融实验:单个模型对于分类准确率的影响Table 2 Ablation experiment:a single model on experimental classification
4.3.3 辅助任务对跨域分类的影响
为了测试微调过程中产生新的辅助任务是否必要,并进一步探索不同数据增强策略对于跨域分类实验的影响,本文对目标域测试任务利用随机裁剪、颜色变换和伽马变换操作,两两随机组合形成辅助任务。实验中,将图神经网络和BL-SSL 模块两者分类结果的融合视为最终的预测分类结果。其中,None表示不使用辅助任务参与微调,仅利用BL-SSL模块和图神经网络推理;CC+RC 表示辅助任务经颜色变换和随机裁剪策略生成;CC+GT表示辅助任务经颜色变换和伽马变换策略生成;RC+GT表示辅助任务经随机裁剪和伽马变换策略生成;本文算法1表示辅助任务由本文算法1 中提出的方法生成。实验结果如表3 所示,实验结果表明,相较于本文算法1 提出的辅助任务生成方法,随机裁剪、颜色变换和伽马变换任意两种数据增强策略组合形成的辅助任务对最终的跨域分类准确率并无显著提升,实验结果进一步凸显了本文方法对于跨域图像分类的有效性。

表3 消融实验:辅助任务对于分类准确率的影响Table 3 Ablation experiment:auxiliary tasks on experimental classification
5 结论
元学习、迁移学习是解决少样本跨域问题的两项前沿理论和方法,为提升模型在有限标注样本困境下的跨域图像分类能力,本文提出了CMTL 方法,并通过大量实验证实了本文方法的有效性。
本文的主要工作分为3 个方面:1)基于元学习,通过构建辅助任务,用于微调模型参数;2)基于迁移学习,提出的BL-SSL 模块更利于目标任务的特征提取;3)融合迁移学习和元学习预测分数的方法能有效处理跨域图像分类任务。
本文提出的CMTL 方法虽然能极大缓解少样本跨域图像分类精度差等困境,但对构建辅助任务阶段的探索还不够全面,融合两者模块预测分数的研究也不够深入。未来工作将会继续围绕如何生成更为合适的辅助任务、如何有效融合两者模块预测分数这两大重点展开研究,促使少样本跨域图像分类模型具有更好的泛化能力。
