视觉—语义双重解纠缠的广义零样本学习
2023-09-26韩阿友杨关刘小明刘阳
韩阿友,杨关*,刘小明,刘阳
1.中原工学院计算机学院,郑州 450007;2.河南省网络舆情监测与智能分析重点实验室,郑州 450007;3.西安电子科技大学通信工程学院,西安 710071
0 引言
随着深度学习的蓬勃发展,许多端到端的深度学习模型已经在很多应用场景上效果斐然。虽然传统的深度学习模型非常成功,但是它们的成功是基于大量带标记的数据进行训练的。在现实生活中收集大量的标记样本是一个具有挑战性的问题。例如ImageNet(Deng 等,2009)是一个大型数据集,包含1 400 万幅图像,21 814 个类别,但是其中许多类只包含少数图像。此外传统的深度学习模型只能识别训练阶段已有的类别样本,不能处理来自不可见类的样本。这是一个非常具有挑战的问题,因为在现实场景中,可能有些类别是没有可训练样本的,比如濒危鸟类等。
人类可以根据先前学习到的经验来学习新的概念,而不必事先看到它们。例如一个人可以很容易地识别出斑马,如果他以前见过马,并且知道斑马看起来像是带有黑白条纹的马(冀中 等,2019)。零样本学习(zero-shot learning,ZSL)(Larochelle 等,2008)方法为解决这一挑战提供了一个很好的解决方案。
在零样本学习中,训练阶段出现的类别称为可见类,未出现的类别称为不可见类。它的目标是训练一个模型,学习语义空间和视觉空间之间的映射。通过语义信息将可见类学习到的知识迁移到不可见类,从而缩小可见类和不可见类之间的差距,然后对不可见类进行分类。但是传统的零样本学习是建立在测试集中只包含不可见类样本的假设之上,这种假设在现实场景中容易打破。因此出现了一种比零样本学习更有现实意义、更具挑战的广义零样本学习(generalized zero-shot learning,GZSL)(Chao 等,2016),也就是说,测试集的样本来自可见类和不可见类。
现有的广义零样本学习方法技术主要可以分为基于嵌入的方法(Frome 等,2013;Liu 等,2019;Jiang等,2019;Xian 等,2016)和基于生成的方法(Zhu 等,2018;Narayan 等,2020;Chen 等,2021a;Xian 等,2018;Keshari 等,2020)两大类。前者目标是学习一个映射函数,将可见类的视觉特征和其对应的语义向量映射到某一空间中进行后续分类;后者是学习一个生成模型为不可见类生成视觉特征。现在大多数的广义零样本学习方法是利用在ImageNet上预训练的深度模型来提取相应的视觉特征,比如残差网络(residual neural network,ResNet101)(He 等,2016)和VGG-16(Visual Geometry Group-16)(Simonyan 和Zisserman,2014)等。然而,现有的大多广义零样本学习方法中忽略了语义和视觉的相关性。因为在模型学习的过程中,原始特征和生成特征在维度上并不是都与预定义属性在语义上相关,这将导致视觉在维度上与语义产生偏见,并导致对不可见类的负迁移,如图1 所示,方框标注的“耳朵”维度与注释属性在语义上无关,从这些语义无关的视觉特征中学习可能会影响模型对不可见类的泛化。

图1 语义无关的视觉特征图示Fig.1 The illustration of visual features(boxes)that are not associated with the annotated attributes
此外,大多数方法在分类过程中都忽略了丰富的语义信息,并且在语义信息中也存在着与分类无关、特征无关的信息。这将会影响分类结果,如图2所示,划线部分语义是与视觉特征无关的,比如在注释属性中存在的“Ocean”语义对于“猫”的视觉特征是无关的,并且对于最终的视觉—语义联合分类也会产生不好的影响。

图2 特征无关的语义注释属性图示Fig.2 The illustration of annotated attributes(lines)that are not associate with the visual features
为了解决上述问题,本文提出了视觉—语义双重解纠缠广义零样本学习(visual-semantic dualdisentangling generalized zero-shot learning,VSDGZSL)。通过视觉—语义解纠缠框架来提取出语义一致性特征和特征相关的语义信息,设计了一个总相关惩罚结构和一个语义一致性衡量网络。前者衡量分解的潜在变量之间的独立性;后者衡量分解出来的视觉特征的语义一致性。然后,将视觉特征分解的潜层输出和语义信息分解的潜层输出进行跨模态交叉重构。对视觉特征交叉重构输入的是语义信息分解输出中与特征相关的信息,并使用该操作来指导语义解纠缠框架分解出与特征相关的语义信息。最后,将语义一致性特征和特征相关的语义信息联合学习一个广义零样本学习分类器。在4 个公开数据集上的实验结果验证了本文方法的有效性。
本文贡献如下:1)发现在提取的视觉特征中并不是都与预定属性在语义上相关,这将会导致产生语义偏见,并且在语义信息中存在与分类无关以及特征无关的冗余信息。2)提出一个视觉—语义解纠缠框架,用来提取出视觉特征中语义一致性特征和预定义属性中特征相关的语义信息。设计了一个跨模态交叉重构模块来指导语义解纠缠能更好地分解出与特征相关的语义信息,采用关系网络来学习视觉解纠缠分解出语义一致性表示。最后将解纠缠模块分解后的特征和语义联合学习一个广义零样本学习分类器进行分类。3)在4 个公开的广义零样本学习数据集上进行多次实验,通过解纠缠框架学习到的语义一致性视觉特征和特征相关的语义信息能够提高分类性能并优于对比的基准方法,证明了所提视觉—语义解纠缠思想的有效性。
1 相关工作
1.1 广义零样本学习
广义零样本学习是比传统零样本学习更有现实意义、更具挑战的情况,即在测试集样本中既有可见类也有不可见类。由于在训练阶段不可见类的视觉样本不可用,这导致经验风险最小化变得不可靠(Wang等,2021b)。为了克服这些限制,利用语义作为不可见类的中间表示,这种语义通常是手动定义的属性(Lampert等,2014)。
广义零样本学习的方法有:f-CLSWGAN(Xian等,2018)中利用WGAN(Wasserstein GANs)(Arjovsky 等,2017)来合成逼真的视觉特征。CADA-VAE(cross-and distribution-aligned VAE)(Schönfeld 等,2019)利用两个对齐的变分自编码器(variational auto-encoder,VAE)来学习不同模式之间的共享潜在表示。TF-VAEGAN(Narayan 等,2020)将变分自编码器VAE 和生成对抗网络(generative adversarial networks,GAN)相结合来生成视觉特征,再通过一个语义解码器将视觉特征解码出语义属性,并且提出了一个反馈模块,将语义解码器的潜层表示作为输入反馈回生成器的潜层来提高生成特征的质量。CANZSL(cycle-consistent adversarial networks for zero-shot learning)(Chen 等,2020)提出了周期一致对抗网络,首先从有噪声的文本中合成视觉特征,然后采用逆对抗网络将生成特征转换为文本,以确保合成的视觉特征能够准确地反映语义表征。OTZSL(optimal transport-based zero-shot learning)(Wang等,2021a)利用一个条件生成模型从可见类属性生成可见类特征,并在生成特征分布和真实特征分布之间建立最优传输,利用基于属性的正则化器对生成模型和最优传输进行迭代优化,进一步增强了所生成特征的鉴别能力。FREE(feature refinement)(Chen 等,2021a)指出在ImageNet 上训练的特征提取器忽略了ImageNet和GZSL数据集之间的偏差,这种偏差会导致广义零样本学习任务的视觉特征质量低下,因此提出了一种特征细化的方法,采用一种自适应边缘中心损失,它与语义循环一致性损失相结合,引导特征细化模块学习类和语义相关的表示。赵鹏等人(2021)提出了一种基于子空间学习和重构的零样本分类方法来解决知识迁移过程中的信息损失和域偏移问题。在人体行为识别领域中,吕露露等人(2021)为了研究多种模态数据对零样本人体动作识别的影响,提出了一种基于多模态融合的零样本人体动作识别ZSAR-MF(zero-shot human action recognition framework based on multimodal fusion)框架,该框架能有效地融合传感器特征和视频特征。
1.2 生成模型
最近的广义零样本学习中使用生成模型的方法取得了先进的性能。生成模型可以为不可见类合成大量的视觉特征,一旦为不可见类生成了视觉特征,那么零样本学习的问题就变成了一个相对简单的监督分类问题。两种常用的生成模型是生成对抗网络(GAN)(Goodfellow 等,2014)和变分自编码器(VAE)(Kingma 和Welling,2014),这两种模型在基于生成方法的广义零样本学习任务中广泛使用。其中,Xian 等人(2018)设计了一个带有分类损失的条件WGAN 模型,称为f-CLSWGAN,将语义特征集成到生成器和鉴别器中。SPGAN(similarity preserving GAN)(Ma 等,2020)设计了一种保持相似性的生成对抗网络来生成尽可能真实的视觉特征。SR-GAN(semantic rectifying generative adversarial network)(Ye 等,2019)使用语义矫正网络来矫正特征。CVAE-ZSL(Mishra 等,2018)采用神经网络对编码器进行建模,SE-GZSL(synthesized examples for generalized zero-shot learning)(Verma 等,2018)设计了一个循环一致性损失函数,配备了鉴别器驱动的反馈机制,将真实样本或生成的样本映射回相应的语义表示。在这些方法中,使用的原始特征和生成特征中存在着与预定义属性不相关的特征,并且在分类阶段要么忽略了丰富的语义信息,要么在使用语义信息时没有解耦出语义信息中与特征相关的部分。如何使模型提取它们是关键问题。
1.3 解纠缠表示
解纠缠指的是一种表示特征之间的独立性。总相关性(total correlation,TC)(Kim 和Mnih,2018)是对多个随机变量独立性的测量。在信息论中,总相关是互信息对随机变量的许多推广之一,它是最近解纠缠方法的一个关键组成部分。FactorVAE(Kim和Mnih,2018)提出了一种将表征的分布进行阶乘的方法来分离特征,从而实现跨维度的独立性。Higgins 等人(2017)提出的beta-VAE 是一种无监督的视觉解纠缠表示学习方法,通过调整KL(Kullback-Leibler)项的权重来平衡解纠缠因子的独立性和重构性能。Chen 等人(2016)提出的InfoGAN通过最大化潜层变量与原始变量之间的互信息来实现解纠缠。DLFZRL(discriminative latent features for zero-shot learning)(Tong 等,2019)提出了一种分层分解方法来学习有区别的潜在特征。
2 问题定义
在零样本学习中,数据集类别分为可见类s和不可见类u,标签分别为ys和yu,ys∩yu=∅。假设训练数据集={(xs,as,ys)},仅由可见类中标记的样本组成,其中xs∈Xs表示可见类视觉特征,as∈As是可见类相关的语义描述符(如语义属性),ys∈Ys表示可见类的类标签。测试集={xu,au,yu},其中在训练期间不可见类的视觉特征xu不可用。传统的零样本学习旨在学习测试集Dte={xu}上评估的分类器fZSL:Xu→Yu。然而在广义零样本学习中,测试集Dte由可见类和不可见类共同组成,即学习在所有的特征上评估的分类器fGZSL:X→Ys∪Yu,本文主要研究的是广义零样本学习的分类问题。
3 方 法
为了同时得到语义一致性的视觉特征和特征相关的语义属性,本文提出了一种基于总相关惩罚的视觉—语义解纠缠框架。分解的视觉特征通过一个关系网络来保证语义一致性,分解的语义信息通过视觉交叉重构来保证特征相关性。最后通过语义一致性视觉特征和特征相关的语义信息结合进行广义零样本学习的分类。
3.1 模型架构
所提模型架构如图3 所示,主要由条件变分自编码器、视觉—语义解纠缠模块、语义一致性特征衡量网络、总相关惩罚和视觉—语义跨模态重构组成。框架的视觉输入是由预训练的ResNet101(He等,2016)提取的图像特征,语义输入是人工定义的属性。

图3 模型架构Fig.3 Model architecture
3.2 视觉特征生成
为了通过语义信息来生成视觉特征,使用条件变分自编码器(conditional variational auto-encoder,cVAE)(Sohn 等,2015)为不可见类生成相应的视觉特征。cVAE 学习数据和潜在表示的分布之间的关系,它由编码器和解码器组成。其中,编码器将特征空间映射到潜在空间,解码器将潜在空间映射回特征空间,它们分别将类的描述符作为条件。cVAE的目标函数可以表示为
式中,x表示视觉特征,a表示语义信息,z表示编码器生成的潜在变量。式中第1 项为q(z|x,a) 和p(z|a)两个分布之间的KL散度,用来约束编码器匹配分解后的先验分布,例如高斯分布。第2 项为重构特征和原始特征之间的重构误差。
为了获得变分下界的可微估计量,使用一种称为重参数化的技巧,具体为
式中,μ(x)和σ(x)是编码器的输出,分别代表后验分布的均值和方差。⊙表示两个张量对应元素的乘积,ε~ N(0,I)是一个服从高斯分布的辅助噪声变量。
3.3 解纠缠模块
对于广义零样本学习的数据集来说,通过预训练的深层模型(如ResNet101)提取的视觉特征并不完美,因为视觉特征并不是在所有的维度上都与预定义属性在语义上相关。在这些数据集中,类别通常是相关的(如CUB 数据集都对应于鸟类),因此提取的特征可能包含冗余信息。这里将视觉特征分解成语义一致性特征s和语义无关特征n,使用一个关系网络来衡量语义一致性。在语义信息中也存在着与特征相关的信息,将语义信息分解成特征相关语义h和特征无关语义n,使用视觉特征交叉重构来保证分解的语义和视觉特征相关。为了加强分解后两个分量的独立性,使用总相关性来衡量。
3.4 视觉—语义跨模态重构
解纠缠模型使用与cVAE 相同的编码器—解码器结构,分别对两个解纠缠结构的解码器输出特征和编码器输入特征计算重构损失。在视觉和语义两个解纠缠中,提出了一个跨模态重构损失,将视觉解纠缠的编码器E1的输出送入到语义解纠缠的解码器D2中来重构语义信息,然后将语义解纠缠的编码器E2的输出中与特征相关的分量送入到视觉解纠缠的解码器D1中来重构视觉特征。
两个解纠缠模块的重构损失分别为
视觉—语义跨模态交叉重构损失为
式中,对于特征解纠缠编码器输出s和n中,s是语义一致性特征,n是语义无关特征;对于语义解纠缠编码器输出h和n中,h是特征相关的语义向量,n是特征无关的语义向量。
解纠缠模块总的重构损失为
式中,使用均方误差(mean square error,MSE)来计算原始视觉特征和重构视觉特征、原始语义向量和重构语义向量之间的重构损失。
3.5 语义一致性特征
在视觉解纠缠框架中,采用一个关系网络(relation network,RN)(Sung 等,2018)作为语义一致性衡量网络,网络结构如图4 所示,通过将视觉特征解纠缠模块分解的潜在表示s与语义a连接,关系网络将匹配的(s,a)对和不匹配的(s,a)对分开,从而迫使s在语义上相关。该网络最大化潜在表示s和相对应的语义a之间的相容性得分(compatibility score,CS)来学习语义一致性特征s,关系网络学习潜在表示s和语义a之间的成对关系。RN 的输入是潜在表示s和对应唯一语义向量a组成的对。组成的对如果匹配成功,CS值为1;如果不匹配,CS为0。结构表示为
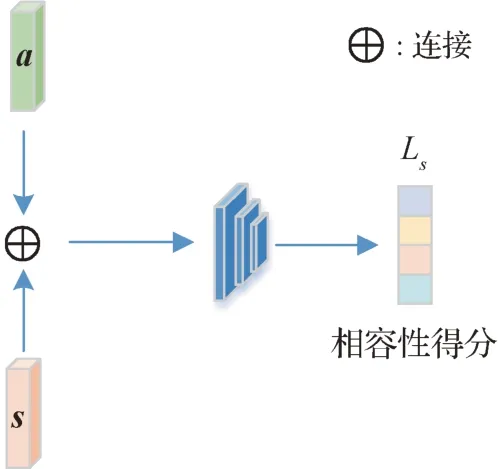
图4 语义一致性衡量网络Fig.4 Semantic consistent measurement network
式中,t和c表示一个训练批次中第t个语义一致性表示和第c个唯一语义向量,y(t)和y(c)表示s(t)和a(c)的类标签。
利用式(8)中定义的CS,使用带有sigmoid 激活函数的关系网络为每一对(s,a)学习一个0—1的相容性得分,然后使用损失函数来优化s,具体为
式中,B为批次大小,N为一个批次中唯一语义向量的数量。使用均方误差来优化该损失,保证视觉解纠缠分解出语义一致性特征。
3.6 总相关惩罚
为了促进视觉特征和语义信息解纠缠模块能更好地分离特征和语义,设计了一个总相关惩罚来鼓励视觉解纠缠模块分离出的语义一致性和语义无关特征之间的独立性,语义解纠缠模块分离出特征相关和特征无关语义之间的独立性。这里使用语义解纠缠来对总相关惩罚进行展开解释。对于语义信息的解纠缠分解出的两个分量,可看做是独立的,并且来自不同的条件分布,语义向量的潜在分量的条件分布分别为
式中,h为语义解纠缠模块分解出的与特征相关的语义信息,Φ1为h的条件分布。n为分解出的与特征无关的语义信息,Φ2为n的条件分布。a为需要被分解的语义属性。总相关性可表示为
式中,Φ:=Φ(h,n|a)是语义解纠缠中分解出两个分量h和n的联合条件概率。KL表示KL 散度。为了更好地逼近总相关性,使用密度比估计以对抗的方式区分两个分布中的样本(Chen 等,2021b),使用一个鉴别器Dis的输出估计独立分量的概率,鉴别器模型如图5 所示,解纠缠编码器分离出两个分量后,再经过随机重组排列得到重组后的表示,最后将变换前和变换后的表示输入到鉴别器中计算总相关损失。利用总相关惩罚来强调分解出的两个分量之间的独立性,这里训练鉴别器以最大限度地将正确标签分配给变换前和变换后的表示。具体为

图5 总相关惩罚鉴别器Fig.5 Total correlation penalty discriminator
式中,t=[h,n]。鉴别器损失为
3.7 模型算法
本文所提VSD-GZSL方法训练算法如下:
输入:可见类视觉特征Xs、语义向量As及其标签Ys。
输出:训练好的生成网络和解纠缠网络。
4 实 验
为了验证本文方法对广义零样本学习的图像分类任务的有效性,在4 个公开数据集上进行实验,从参数分析、消融实验和方法适应性3 个方面进行实验分析并展示实验效果。
4.1 实验数据
实验使用4 个基准数据集评估所提模型的性能,分别是AwA2(animals with attributes2)(Lampert等,2014)、CUB(caltech-UCSD birds-200-2011)(Wah等,2011)、FLO(Oxford flowers)(Nilsback 和Zisserman,2008)和SUN(SUN attribute)(Patterson 和Hays,2012)。CUB 数据集包含200种鸟类,其中,150种是可见类,50种是不可见类,每个类别有312个属性的注释;AwA2数据集常用于动物分类,由40个可见类和10个不可见类组成,每个类别都有85个属性的注释;SUN 是一个大型场景风格的数据集,包含645 个可见类和72 个不可见类,每个类别有102 个属性的注释;FLO 数据集包含102 个花卉类别,82 个可见类和20 个不可见类,注释属性有1 024 维。各数据集的详细信息如表1所示。
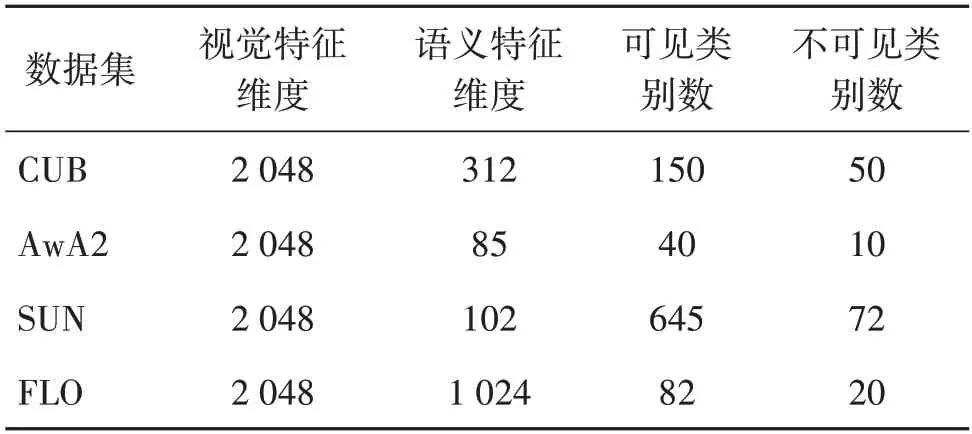
表1 数据集统计Table 1 Statistics of datasets
4.2 评估方法
在广义零样本学习任务上,使用调和平均值评估精度,它计算的是可见类与不可见类的联合精度,具体为
式中,U表示在不可见类图像上每个类别的平均精度,衡量不可见类样本的分类能力。S表示在可见类图像上每个类别的平均精度,衡量可见类样本的分类能力。H是调和平均值,衡量GZSL 任务的性能。
4.3 实验设置
按照大部分方法的设置,首先利用预训练的ResNet101来提取维度为2 048的图像特征。语义特征是由人工注释的每个类别的描述。cVAE 和解纠缠模块的编码器和解码器都是由多层感知机(multilayer perceptron,MLP)组成。在cVAE 中,隐藏层维度为2 048,生成的潜在表示维度为20。解纠缠模块的隐藏层维度是可以调节的参数。关系网络的隐藏层维度为2 048。鉴别器模块是带有sigmoid 激活函数的单层感知机。
所提方法由PyTorch 实现,并采用Adam(Kingma 和Ba,2015)优化器进行优化。学习率是一个可调节的超参数,批次大小设置为64。当cVAE和解纠缠训练好后,使用cVAE 中的生成器来为不可见类生成大量样本。之后,将可见类的训练特征和不可见类的生成特征送入到视觉解纠缠模块中提取语义一致性特征,将语义信息送入语义解纠缠模块提取特征相关的语义向量。最后,将分解出来的语义一致性特征和特征相关语义信息联合共同学习一个广义零样本学习分类器,然后计算相应的指标。分类过程如图6所示。
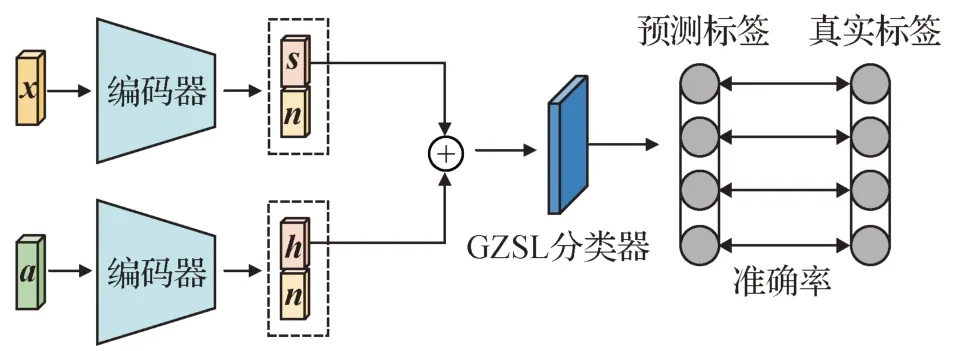
图6 分类结构Fig.6 Classifier architecture
4.4 对比相关方法
为了证明所提方法的有效性,选择了10 种不同的方法进行实验对比。对比方法如下:
f-CLSWGAN(Xian 等,2018)提出了一种使用GAN 在特征空间上生成数据,并添加一个辅助分类器提高生成器性能的方法来解决零样本学习问题,相比于直接生成图像,该方法能取得更好的性能。
CANZSL(Chen 等,2020)提出了一个基于自然语言语义空间的循环一致性对抗网络。该网络使用带有不相关词的自然语言来生成视觉特征,而不是使用以往人工注释的语义信息,然后由语义特征生成器将合成的视觉特征映射回相应的语义空间。
Cycle-CLSWGAN(Felix 等,2018)提出使用cycle-consistent loss 作为正则化项来训练GAN,使得生成的视觉特征能够重构它的原始语义特征,解决了基于生成方法的GZSL 模型中存在从语义到视觉特征的生成过程没有约束的问题。
FREE(Chen 等,2021a)提出一种自适应边缘中心损失,与语义循环一致性损失相结合,对视觉特征进行细化,减轻了ImageNet和GZSL基准数据集之间的跨数据集偏差。
LisGAN(leveraging invariant side GAN)(Li 等,2019)提出在GAN 生成器中引入灵魂样本正则化方法来解决视觉对象的多视图质量问题,并在分类阶段提出使用级联分类器来微调精度。
CADA-VAE(Schönfeld 等,2019)使用VAE 对视觉特征和类别描述进行编码解码,对这两个模态进行对齐,在隐空间中使用这两个模态共同构建分类器。
f-VAEGAN-D2(Xian 等,2019)提出了一个直推式特征生成网络,使用VAE 与WGAN 结合进行信息互补来生成更鲁棒的特征,额外使用一个非条件的鉴别器来学习不可见类的流形。
SDGZSL(Chen 等,2021b)指出现有方法使用的可视化特征会包含与语义无关的冗余信息,并提出了一个解纠缠自编码器的结构,提取出视觉特征中语义相关的特征。
TDCSS(task-correlated disentanglement and controllable samples synthesis)(Feng 等,2022)指出目前的方法仍然存在特征混淆和分布不确定的问题,并提出了任务相关特征解纠缠和可控伪样本合成两个模块来解决这两个问题。
Disentangled-VAE(Li等,2021)指出在可视化特征中不可避免地包含与识别分类无关的信息,给性能带来负面影响,因此提出了一种基于潜在特征批量重组策略的解纠缠方法来分离出类别相关和类别无关的因素。
4.5 实验结果
在4 个公开数据集上与Baseline 和其他10 种方法进行多次实验对比。表2 展示了VSD-GZSL 与其他相关方法之间的对比实验结果。除了FLO数据集外,所提方法都优于对比方法,并且在4 个数据集上比Baseline方法结果更好。
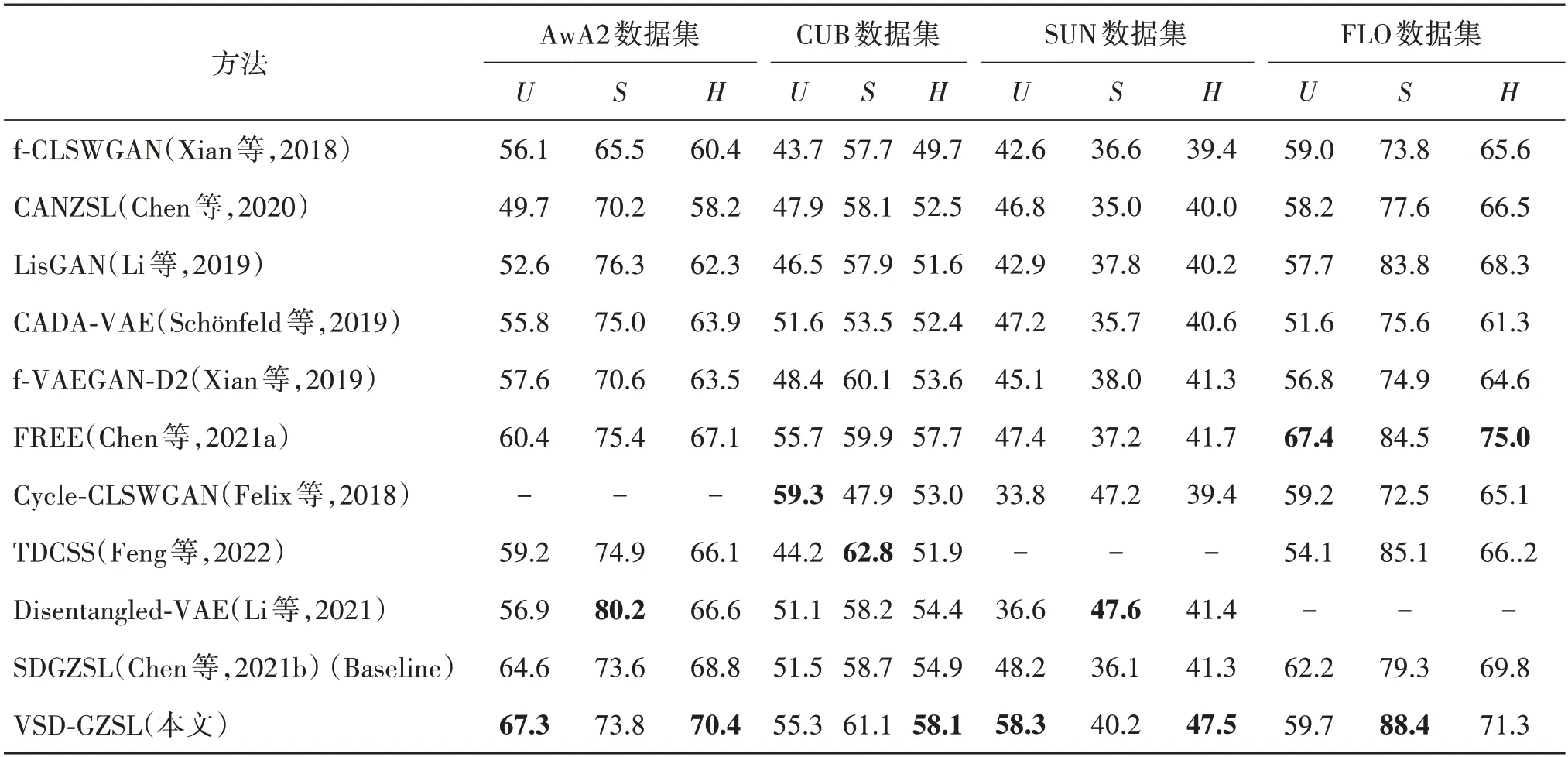
表2 不同方法在4个数据集上的结果对比Table 2 Comparison of results of different methods on four datasets/%
VSD-GZSL 相对于CANZSL(Chen 等,2020)在数据集AwA2 上的U、S和H分别提高了17.6%、3.6%和12.2%,在CUB 上的U、S和H分别提高了7.4%、3% 和5.6%,在SUN 上 的U、S和H分别提高了11.5%、5.2%和7.5%,在FLO 上的U、S和H分别提高了1.5%、10.8%和4.8%。因为CANZSL 并没有将视觉特征中存在的语义无关特征进行分离,这会产生语义偏见,并且在分类时该方法使用一个k-最近邻算法进行分类,这也忽略了语义信息对分类结果的影响。因此VSD-GZSL 方法比之性能更好。
相对参照的Baseline 方法,所提方法VSD-GZSL在AwA2 数据集上,U、S、H分别提高了2.7%、0.2%和1.6%,在CUB 上,U、S、H分别提高了3.8%、2.4%和3.2%,在SUN 上,U、S、H分别提高了10.1%、4.1%和6.2%,在FLO 上,S和H分别提高了9.1%和1.5%。由于Baseline 只考虑对视觉特征的解纠缠,忽略了在语义信息中与分类特征相关的信息,而VSD-GZSL 正是发现了这个问题并解决了这个不足,从而提高了Baseline的性能。
从实验结果看,所提的视觉—语义解纠缠方法可以学习到视觉空间中语义一致性特征和语义空间中特征相关的语义,并且能够提高广义零样本学习分类性能,由此结果可以验证所提方法的有效性。
4.6 实验分析
本文从参数分析、消融实验和方法适用性3 个方面对提出的方法进行实验分析。
4.6.1 参数分析
为了讨论参数对解纠缠模块的影响,选择在AwA2 数据集上对解纠缠模块中关系网络损失Ls的权重λ1、总相关惩罚损失TC的权重λ2和鉴别器损失Ldis的权重λ3,设置不同的值进行多次实验。图7 展示了3 个参数对广义零样本学习性能的影响。图7(a)是固定其他两个参数为λ2=1.0,λ3=0.5的情况下,关系网络权重λ1对广义零样本学习性能影响图,可见,在λ1=0.7 时性能最好。图7(b)为固定λ1=0.7,λ3=0.5 的情况下,总相关惩罚的权重λ2对广义零样本学习性能影响图,可见,在λ2=0.9时性能最好。图7(c)为固定λ1=0.7,λ2=0.9的情况下,鉴别器损失的权重λ3的值对GZSL 性能影响图,可见,在λ3=0.5时性能最好。综合这3组参数分析实验,找到了在AwA2 数据集上3个参数最优的组合。即当λ1=0.7,λ2=0.9,λ3=0.5的情况下,广义零样本学习性能达到了最优,调和平均值超过了所有对比方法。

图7 参数分析Fig.7 Parameters analysis((a)relation network weight λ1;(b)TC weight λ2;(c)discriminator weight λ3)
4.6.2 消融实验
为了验证视觉特征和语义信息联合分类、语义解纠缠和跨模态重构的有效性,分别在4 个数据集上进行消融实验,结果如表3所示。
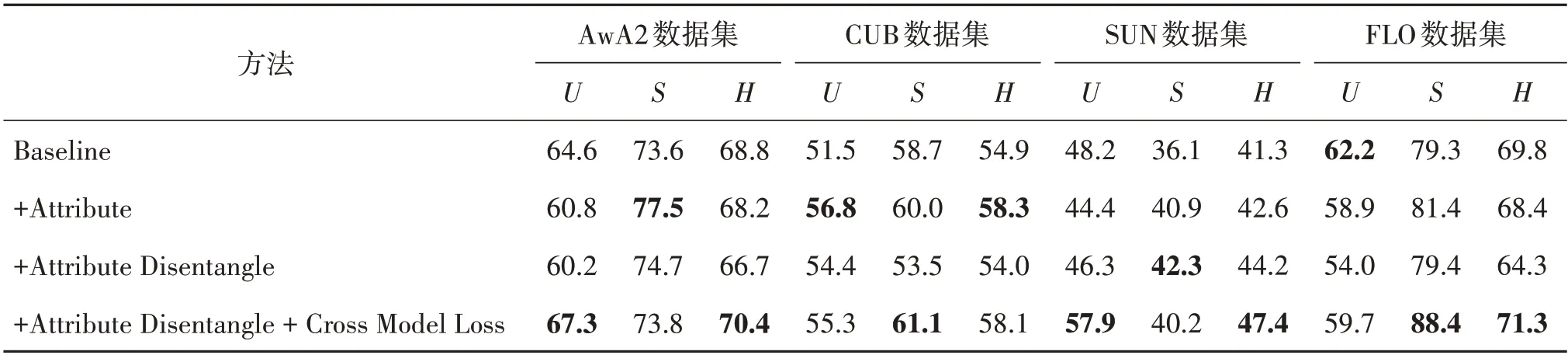
表3 消融实验Table 3 Ablation experiments/%
第1 个消融实验(+Attribute)是在Baseline 中将分离的语义一致性特征和未分离的语义信息联合学习一个分类器得到的结果,在CUB 和SUN 上的调和平均值H都得到了提升,AwA2 和FLO 上的S指标都得到提升,调和平均值也取得了相当的结果,这表示加入语义信息进行联合学习对分类有着很大的作用。
第2 个消融实验(+Attribute Disentangle)是在Baseline中只添加语义解纠缠模块,这只是单纯地分离出两个独立的语义分量,并没有对分离出的分量施加约束。可以发现在SUN 数据集上性能得到了提升,但是在其他数据集上效果变差,这是因为没有对分解出的语义信息施加约束。
第3 个消融实验(+Attribute Disentangle+Cross Model Loss)在加入语义解纠缠模块后的基础上再添加跨模态重构损失,即本文方法。可以看出,在4 个数据集上几乎所有评估指标都取得了显著提升,因为添加的损失会对语义解纠缠模块进行指导,约束语义解纠缠模块分离出特征相关和特征不相关的两个独立分量,有了丰富的特征相关的语义向量后,将语义一致性特征和特征相关的语义信息联合学习广义零样本学习分类器。
消融实验进一步证实所提方法能够提高Baseline 在多个数据集上的性能,并且优于大多数相关方法的性能,更加充分证明了方法的有效性。
4.6.3 方法适用性
为了验证所提方法的适用性,在CUB 数据集上使用3 种不同backbone 提取的视觉特征进行实验对比,分别为GoogLeNet(Szegedy 等,2015)、VGG16(Simonyan 和Zisserman,2014)和ViT(vision Transformer)(Dosovitskiy等,2021),实验结果如表4所示。可以看出,所提方法在3 个不同backbone 下的实验结果均比baseline更好,进一步证明了所提方法的适用性。
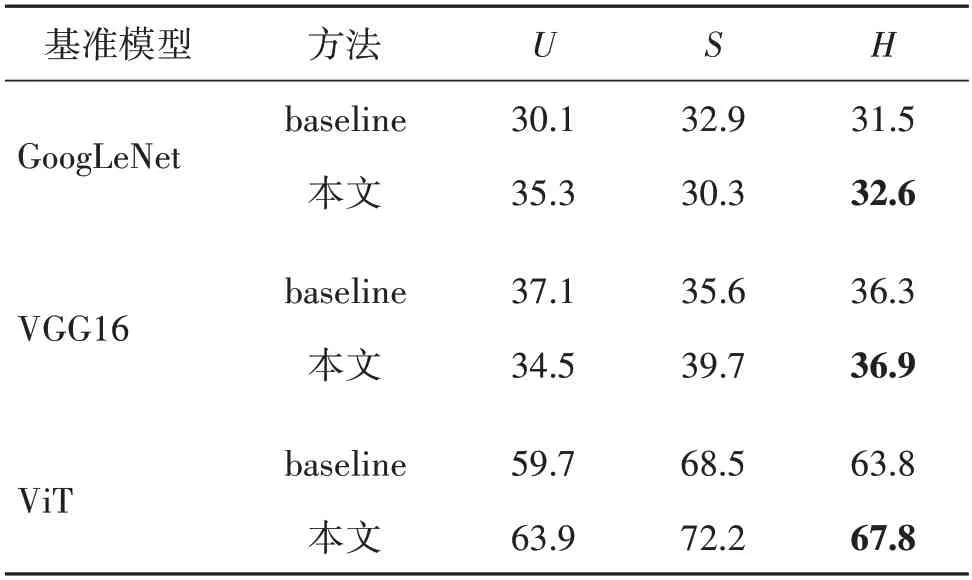
表4 在CUB数据集上不同backbone下的方法结果对比Table 4 Comparison of method results of different backbone on CUB dataset/%
5 结论
在使用解纠缠表示的零样本学习方法中忽略了语义信息,对此本文提出了视觉—语义双重解纠缠的广义零样本学习分类方法。具体而言,从视觉特征中分解出语义一致性特征和语义无关特征,从人工注释的类别描述(语义属性)中进一步分解出特征相关和特征无关的语义信息。本文设计了一个总相关惩罚来鼓励两个解纠缠框架分离出来的潜在变量之间的独立性,采用关系网络来衡量分解出视觉特征的语义一致性,并设计了一个跨模态交叉重构的方式保证分解出来的语义信息与特征相关。最后,将分解出来的特征相关语义分量和语义一致性视觉特征分量相结合,训练一个分类器进行广义零样本学习分类。将解纠缠模块与条件变分自编码器结合,以端到端的方式进行训练。在4 个公开数据集上对所提方法进行评估,大量实验证明,本文方法取得了比基准模型更好的效果,并优于大多相关方法。
相比于同类型的方法,本文方法的效果得到了明显提升,然而其性能受限于预训练神经网络提取的视觉特征的好坏,这是因为不同的深度模型提取视觉特征的能力和质量也不一样。并且所提方法是在特征表示层面上进行的,如何在图像级别上通过注意力机制来挖掘图像和语义之间的一致性是一个有意义的研究方向。此外,现有方法的性能和人工注释的语义信息紧密相关,这种强先验的外部知识在现实场景中很难获取,如何突破这种外部语义知识的制约,只利用可见类图像训练模型来对不可见类图像进行识别是一个重要的研究方向。未来,将利用Transformer挖掘图像和语义之间的多模态关系来进行零样本识别任务。
