一种增强的3D人脸替换方法
2023-09-18谭晓阳
蒋 珂,谭晓阳,2*
(1 南京航空航天大学 计算机科学与技术学院, 江苏 南京 210000;2 模式分析与机器智能工业和信息化部重点实验室(南京航空航天大学), 江苏 南京 210000)
近年来随着计算机性能的提升,以及各种大型数据库的公开,人脸相关的计算机视觉领域获得了前所未有的飞跃,尤其是随着生成对抗网络的应用,人脸编辑(facial attribute editing)[1]领域得到了进一步发展。人脸替换可以看作是一类特殊的人脸编辑问题,它通过某种算法将源人像中的人物身份嵌入目标人像中,替换目标人像的身份信息。人脸替换方法需要兼顾生成结果的质量和效率问题。
高质量的人脸替换方法需要解决以下问题:姿态是否对齐、伪造区域的纹理质量、嵌入部分与背景是否融合以及结果是否保持了源身份。Deepfakes算法是解决上述问题的一种典型方案[2],它可以通过一对自编码器结构[3]生成高质量的人脸替换结果。但是,Deepfakes模型需要大量相同身份的人像作为训练集,并且每次训练只能生成一种身份的人脸替换结果。因此,Deepfakes算法是繁琐而低效的。
3D人脸重建方法应用于人脸替换而衍生出的3D人脸替换方法可以解决Deepfakes方法针对不同身份需要新数据重新训练模型的问题。这种方法根据一张源人像构造3D面部点阵以及纹理图,将3D面部点阵与目标人像的面部姿态进行对齐,再将纹理图进行贴图操作。这个过程不依赖于特定的人像,因此可以对任意身份进行人脸替换操作。这种方法的贴图过程往往包括仿射变换和插值两部分,即利用仿射变换为UV空间[4]的点模型贴图,再利用插值法来填充仿射变换造成的像素间隔。但是仿射变换往往会对图像的高频分量造成破坏,同时过于简单的插值方法(如双线性插值法)会使图像产生异常的灰度不连续现象[5]。这些问题会导致整个模型生成模糊的伪造图像并且有局部色块不均匀的现象。除了对视觉效果有影响,这些问题也会使人脸替换的结果更容易被人脸伪造检测器(face forgery detector)所捕获[6]。
现有的3D人脸替换方法往往具有一些轻微的纹理畸变,以及在特定情况下产生的较为严重的纹理缺失问题。以方位回归网络(position mapping regression network,PRN)[7]为例,PRN的纹理失真包括两个方面:1)仿射-插值贴图算法造成的高频分量丢失以及异常的灰度不连续问题;2)当源人像的嘴部闭合而目标人像的嘴部张开,仿射变换无法构建嘴部的细节,导致结果的嘴部纹理缺失。
针对这些问题,提出一种基于重建-生成的3D人脸替换方法(generative reconstructed face swapping,GRFS)。GRFS可以在仅有一对源、目标人像的情况下生成高质量的人脸替换结果。GRFS包括3个子网络:1)PRN网络;2)嘴部修复网络(mouth restoration network,MRN);3)局部修复生成网络(generative local restoration network,GLRN)。首先,利用PRN网络对源人像进行3D建模并对齐人物姿态,再进行贴图,生成原始结果。然后,对原始结果的嘴部进行姿态提取,利用MRN进行嘴部细节的生成并还原至图像上。最后,GLRN是一个自监督学习的网络,它用于对图像进行局部区域的改善,修复损失的高频分量并且光滑异常的不连续灰度。此外,为GLRN专门设计了一个翻译器(translator)模块,用于帮助GLRN捕获更多人脸结构信息,使得生成的结果图像更为细腻和逼真;并设计了一套全面的、专用于评价人脸替换方法的指标。
1 相关工作
Deepfakes[8]算法主要基于一对多的自编码器结构,即编码器提取人像背景部分的表征,再由解码器对面部进行伪造。在这种结构下,Deepfakes算法的训练过程是自监督的,即源、目标人像为同一种人像时,生成的人脸替换结果应该与目标人像一模一样。自监督过程极大降低了人脸替换对数据集的要求,但是也由于其自监督的训练过程,Deepfakes算法在添加新人物身份时需要重新训练。此外,受硬件资源限制,Deepfakes算法很难生成细腻的高分辨率结果。在此基础上,GAN结构的DeepFaceLab[9]算法,可以生成细节更好的人脸替换结果。
3D人脸替换指的是基于3D人脸重建方法的一类人脸替换方法。Face2Face[10]是一种早期的3D人脸替换算法,它的3D重建过程中特征点的定位并不精确,因而结果质量较低。另一种算法如文献[11]所述,称为Nirkin et al.方法(NM),作为一种改进的3D人脸替换算法,它可以在有遮挡条件下进行精确的3D人脸重建。这类方法都存在一个问题,即在贴图后缺少对纹理的进一步处理,导致生成的图像都不够细腻和逼真。
方位回归网络是一种典型的3D人脸重建方法,可以应用于人脸替换工作。方位指的是特征点的UV坐标方位。PRN可以将一组人脸特征从一个UV坐标映射到另一个UV坐标。PRN是一种单图3D人脸重建方法,在此基础上衍生的3D人脸替换方法也只需要一对源、目标人像。
2 基于重建和生成网络的人脸替换
方法GRFS
本节主要介绍GRFS方法以及2个纹理修复子网络MRN和GLRN,并详细介绍GLRN的自监督训练过程。GRFS的结构如图1所示。首先对源人像进行3D人脸重建,将其人物面部姿态调整至与目标人像一致,获得原始结果;然后提取原始结果人脸的嘴部姿态,通过MRN进行嘴部纹理的重建;最后通过GLRN对整张人脸的不同局部区域进行修复,产生逼真的最终结果。

图1 基于重建和生成网络的人脸替换方法(GRFS)的结构,包括PRN、嘴部修复网络MRN、局部修复网络GLRNFig.1 The structure of GRFS, including three sub-networks: PRN, MRN, GLRN
2.1 嘴部修复网络MRN
MRN是一个最小二乘生成对抗网络(LSGAN)[12]结构,用于生成与PRN生成的人脸替换原始结果姿态一致的嘴部图像。MRN的输入为从原始结果提取的嘴部姿态,损失函数如下:
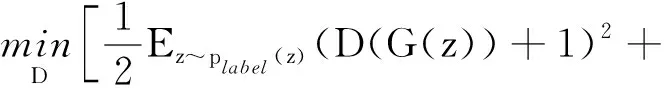

(1)
式中:z表示嘴部姿态;x表示对应的嘴部图像;V(x)用于计算x的内容特征。
2.2 局部修复生成网络GLRN
GLRN网络的主干也是LSGAN结构。相比于传统的生成对抗网络(GAN)[13],LSGAN的训练过程更为稳定,且可以缓解模式坍塌问题。但是,LSGAN这类生成网络的生成结果具有较大的随机性,可能会破坏图像原有的、有价值的信息。因此,引入2个预训练辅助模块:提取器(extractor)和翻译器(translator)。GLRN的结构如图2所示。
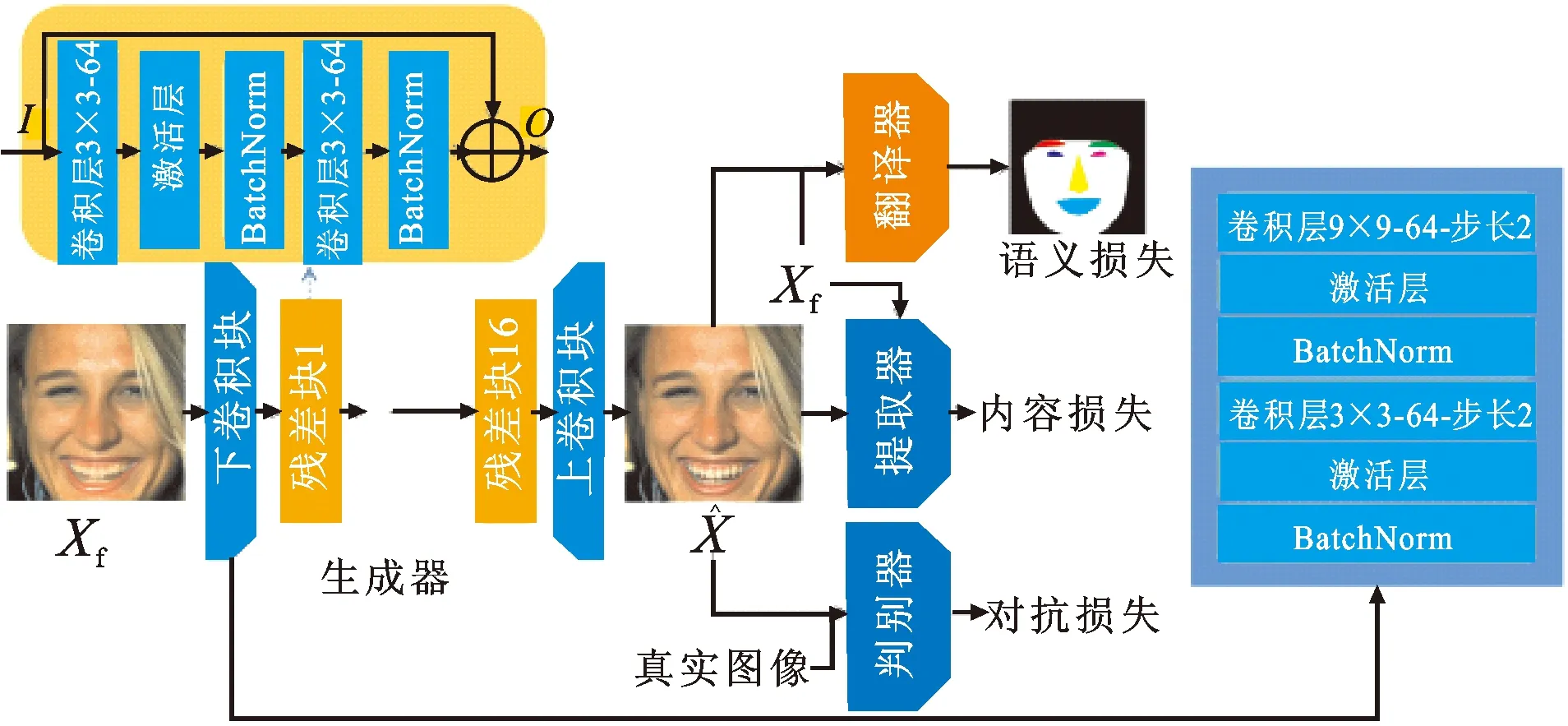
图2 GLRN子网络的结构,包括生成器、判别器、提取器、翻译器Fig.2 The structure of GLRN, including generator,discriminator,extractor and translator
提取器是一个预训练的VGG[14]模型,用于提取图像的内容特征,并计算图像间的内容损失(content loss)作为GLRN的重建损失,其预训练时的损失函数为
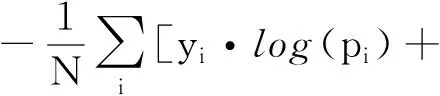
(1-yi)·log(1-pi)]。
(2)
式中:i是样本下标;p是提取器的预测值;y是样本的标记。
翻译器用于加强GLRN捕捉人脸结构特征的能力,使得网络更关注于具有人脸特征细节的生成。翻译器的输入是一张人脸图像,翻译器将其进行图像分割,分割为8个部分:左右眉毛、左右眼睛、鼻子、嘴巴、脸部和背景。翻译器采用VGG19结构进行特征提取,并进行解码重构,生成8标记图。翻译器的损失函数为

(1-yij)·log(1-pij)]。
(3)
式中:i是样本下标;j是标记类别下标;p是提取器的预测值;y是样本的标记。
GLRN的损失函数如下:
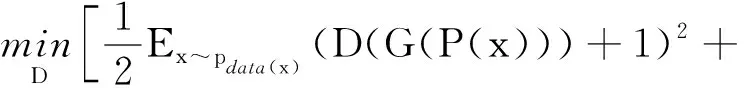
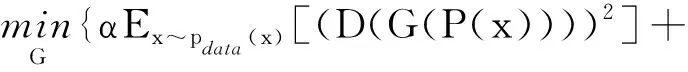
βδV+δT},
δV=Ex~pdata(x)[(V(G(P(x))-V(x))2],
δT=Ex~ptata(x)[(T(G(P(x))-T(x))2]。
(4)
式中:P表示PRN的输出;V表示提取器的输出;T表示翻译器的输出;α、β分别为对抗损失和内容损失的系数。
2.3 GLRN的自监督训练过程
首先,分别在Imagenet[15]和FFHQ[16]数据集上预训练提取器和翻译器。然后,在源、目标人像相同的条件下,通过PRN生成一个原始图像集合{Xf},并在这个集合以及真实图像集合{Xr}上训练GLRN,训练过程如算法1所示。

3 评价指标
本节介绍用于评价人脸替换方法的一般性指标,包括结构相似性(SSIM)、姿态误差(PE)、肤色误差(SE)以及身份距离(ID)。
SSIM用于衡量2张图像的相似度。在人脸替换中,SSIM可以用于评价结果图像和目标图像的相似度,即衡量人脸替换结果图像整体结构的失真程度。
姿态误差PE用于衡量目标图像和人脸替换结果图像中人脸姿态的误差,即用于检验人脸替换结果中的人脸是否与背景对齐。其定义为
D(I1,I2)=‖γ|δv|+|δh|‖2。
(5)
式中:I1和I2是2张图像;δv和δh分别为2张图像的特征点在垂直和水平方向的距离;γ是用于调节二者权值的参数。
肤色误差SE用于衡量人脸替换结果的伪造部分和背景的肤色差异,定义为
θ=N(F)-N(T)。
(6)
式中:N表示归一化函数;F表示从伪造区域采样的肤色像素点均值;T表示从伪造区域外采样的肤色像素点均值。
身份距离ID用于衡量两张人像在隐空间中的距离。通过Face-Net[17]学习从人像到特征隐空间的映射函数。该隐空间满足:若两张脸属于同一个人,那么它们的特征向量在隐空间应该尽可能接近;若不属同一个人,则应该尽可能远离。损失函数为
(7)
式中:θ*为该深度网络的目标参数;D为所有人脸图像构成的分布;而Dn表示某一个身份人脸图像的分布;x和y均为人脸图像的样本;γ为用于调节2个侧重的参数。由此,训练好的深度网络就可以度量人脸替换的结果和源人像的身份距离。实验中,该网络为在VGGFace2[18]上训练的模型。
4 实验
本节利用不同的测试环节对GRFS进行评价。首先是对比实验,将GRFS与主流的人脸替换方法进行对比;然后是局部分析和人脸伪造检测测试,对GLRN的结果进行细节上的分析,并在主流模型上对其进行人脸伪造检测测试,检验GLRN对伪造结果的欺骗性是否有促进作用;最后是消融实验,用于检验翻译器对于GLRN的促进作用。
4.1 数据集以及超参数的设定
LFW[19]数据集包含超过13 000张从互联网选取的、自然状态下的人脸图像。这些人脸图像的限制很少,仅仅满足可以被Viola-Jones[20]人脸检测器检测到的要求。
FFHQ数据集包含超过70 000张高质量的PNG人脸图像,包括各个年龄段、性别以及背景。人物的配饰可能包括眼镜、墨镜、帽子等。
FaceForensics++[21]数据集是一个人脸伪造数据集,包括超过1 000段人脸伪造视频。
超参数:在实验过程中,我们设置学习率α为0.002,损失项系数γ、β分别为0.1和0.01。
4.2 对比实验
我们将GRFS与其他人脸替换算法进行比较。实验环境包括2种:实验环境1(Env.Single)中每种人脸替换算法都将在单对源、目标人像上进行人脸替换;实验环境2(Env.Multi)中每种人脸替换算法都可以在多对源、目标人像上进行人脸替换,即有利于Deepfakes算法的实验环境。为了便于实验,Env.Single的实验主要在LFW数据集上进行,而Env.Multi的实验主要在FaceForensics++上进行。
在Env.Single上的测试,除了GRFS,还包括以下主流人脸替换算法:AI-Face Swap(AI-FS)、FaceSwapLite(FS-Lite)、Deepfakes(DF)。部分结果如图3所示,结果选取了不同年龄、肤色的目标图像。选取这些方法的原因是,除了DF算法外,其他人脸替换算法只需要一对源、目标人像即可达到这些算法的最好效果。

图3 Env.Single的定性结果: 实验将源人像身份嵌入目标人像Fig.3 The qualitative results on Env.Single:source identity would be transformed into target image注:网络版为彩图。
在Env.Multi上的测试,除了GRFS,还包括以下主流人脸替换算法:Deepfakes(DF)、Nirkin et al.(NM)。部分结果如图4所示,结果选取了不同年龄、性别、角度的源、目标图像。选取这2种方法的原因是,这2种方法是目前主流人脸替换算法中性能最好的,近期的人脸替换研究[9]常用这些方法作为基线进行比较。

图4 Env.Multi的定性结果: 实验将源人像身份嵌入目标人像Fig.4 The qualitative results on Env.Multi:source identity would be transformed into target image注:网络版为彩图。
从实验的定性结果(图3、图4)可以看出,在Env.Single中AI-FS、FS-lite算法对于人脸的对齐性能很差,导致人脸替换结果的拼接痕迹明显,质量较低,而DF算法显然不适合该环境。而在Env.Single中,DF算法受到硬件性能限制无法生成高分辨率的图像,因此存在与背景分辨率不统一的问题;NM算法由于缺乏对贴图的处理,导致其生成图像的拼接痕迹较为明显。相比之下,由于对上述方法的这些缺陷进行了针对性处理,本文的GRFS在2种环境下都可以达到较好的性能。
此外,我们还在Env.Multi上利用第3节介绍的实验指标,对GRFS、DF和NM分别进行定量实验,指标结果如表1所示,其中“↑”表示该指标数值越大结果越好,“↓”表示该指标数值越小结果越好。
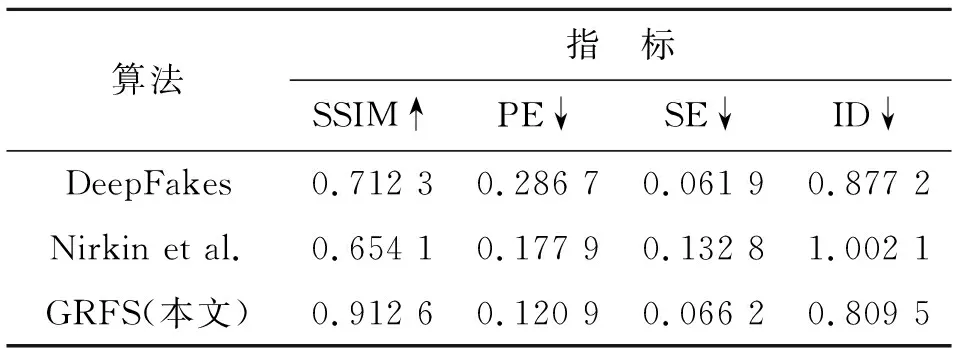
表1 Env.multi上的定量实验结果Tab.1 The quantitative results on Env.multi
定量实验结果表明,GRFS在大多情况下都具有较好的表现。GRFS在图像失真的处理、姿态对齐以及人物身份的保持程度上都要领先于主流的方法;而在肤色处理方面,GRFS的性能与Deepfakes算法相当。
4.3 人脸伪造检测测试
我们还对PRN的原始结果和GLRN的结果分别进行人脸伪造检测测试,这些模型包括:AlexNet、VGG19、Simple-ResNet(SRN)[22]、ResNet50、Inception[23]、Xception[24]。训练集分别为原始结果和真实图像的混合(Original)以及GLRN结果和真实图像的混合(w.GLRN)。各个模型训练时的验证集准确率如表2所示。这些实验结果表明,一些相对简单的模型,如AlexNet、VGG19和SRN,在w.GLRN集合上的表现(表中加粗部分)明显低于Original集合,表明GLRN对原始图像的质量具有促进作用,使其更接近于真实图像的分布。但是,相对复杂的模型,如ResNet50,还是能够以很高的性能识别出GLRN的结果。

表2 2种训练集、不同模型在人脸伪造检测测试中的验证集准确率Tab.2 The validation accuracy of different models in face forgery detection test on two training sets 单位:%
进一步对复杂模型的结果进行分析,以ResNet50模型为例,提取ResNet50的热力图[25],即类激活映射,如图5所示(图5a为PRN的原始结果,图5b为GLRN的结果)。热力图表明,对于PRN的原始图像,模型主要关注插值处理较多的部分,如鼻子附近;而对于GLRN的结果图像,网络权重较大的区域并不集中,甚至可能扩散到人脸以外的区域。这可能是由于复杂模型可以检测到GLRN生成网络产生的一些不可避免的噪声,相较于插值处理造成的灰度不连续以及高频分量损失,这些噪声更难检测。这表明对GLRN的结果图像的检测难度加大。

图5 ResNet50模型中提取出的热力图表示卷积网络的权值分布,反映网络对图像的关注区域Fig.5 The heatmaps extracted from ResNet50, which represents the distribution of CNN to mark the regions of interest注:网络版为彩图。
接下来,对3个复杂模型的训练过程进行分析。为了让3个模型具有相近的初始化点,模型均采用在Imagenet上预训练的权重。3个模型在Original和w.GLRN训练集上的训练过程如图6所示。其中图6a表示ResNet50的训练过程,图6b表示Inception的训练过程,图6c表示Xception的训练过程;而蓝线表示在Original训练集上的训练,黄线表示在w.GLRN训练集上的表现;准确率指的是样本准确率。结果显示,在w.GLRN训练集上,模型的收敛速度要低于Original训练集,表明解空间的收敛位置距离初始点更远。训练时样本准确率的方差如表3所示。结果表明,模型在w.GLRN上的训练更为振荡(表中加粗部分),说明解空间的结构更为复杂。
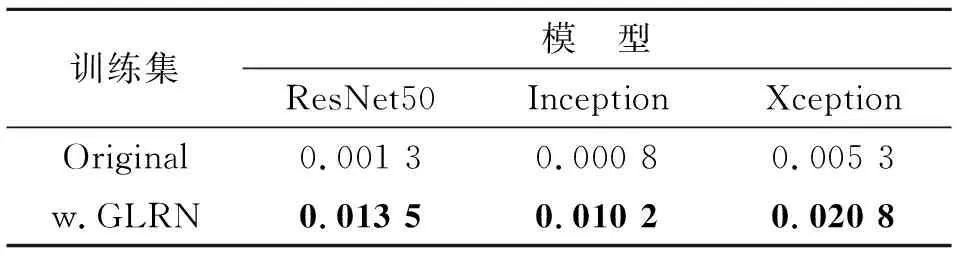
表3 不同复杂模型上训练过程中样本准确率的方差Tab.3 The variances of sample accuracy on different models in training process

图6 不同复杂模型的训练过程Fig.6 The training processes of different complex models.注:网络版为彩图。
综上所述,相较于PRN的原始结果,GLRN的结果具有更好的局部细节,同时也更难被人脸伪造检测算法检测。
4.4 消融实验
本部分重点对GLRN以及GLRN的翻译器模块进行消融实验。首先对GLRN进行消融实验,GLRN主要用于改善伪造区域的局部质量,其消融实验结果如图7所示(图7a是PRN的原始人脸替换结果,图7c是GLRN处理过的结果,图7b是图7a和图7c的局部特写的截取)。相较于原始结果,GLRN的结果图像更为清晰,具有更为丰富的高频分量,同时一些异常的灰度不连续现象也得到了改善。

图7 PRN的原始结果(a)、GLRN结果(c)以及它们对应的局部特写(b)Fig.7 Original results of PRN(a), results of GLRN(c) and their local close-ups(b)注:网络版为彩图。
接下来,进行图像质量相关的定性分析,实验结果如图8所示(其中图8a为不含翻译器模块的GLRN(GLRN wo.T.)生成的图像,图8c为含有翻译器模块的完整GLRN(GLRN w.T.)生成的图像,图8b上下分别为从图8a、图8c图像中截取的局部细节特写)。定性分析的结果如表4所示。引入指标峰值信噪比(peak signal to noise ratio,PSNR),用于衡量图像的失真情况。结果表明,带有翻译器的GLRN生成图像带有更少的失真,达到了像素级的细腻度。

表4 关于翻译器模块消融实验的定量结果Tab.4 quantitative ablation results of translator module

图8 不带翻译器的GLRN结果(a)、带翻译器的GLRN结果(c),以及它们对应的局部特写(b)Fig.8 Results of GLRN wo.T.(a), results of GLRN w.T.(c) and their local close-ups(b)注:网络版为彩图。
5 结语
本文提出了一种基于重建和生成的人脸替换框架GRFS。GRFS可以在只有单对源、目标图像的情况下生成逼真、细腻的人脸替换,且不需要对新的身份进行重新训练。实验表明,GRFS在大多数指标下的表现都要优于主流的人脸替换算法。GLRN模块不仅增强了GRFS结果的视觉效果,也保证了GRFS的结果更难被人脸伪造检测器检测。但是,GRFS在伪造视频时会受到PRN特征点定位帧间不稳定性的影响,影响结果的质量,该局限将会作为今后的研究方向。总之,本文提出的GRFS方法为人脸替换工作提供了一种新的思路。
