融合双重注意力机制的多源深度推荐模型
2023-09-18刘笑笑续欣莹潘华莉
刘笑笑,谢 珺*,续欣莹,潘华莉
(1 太原理工大学 信息与计算机学院,山西 晋中 030600;2 太原理工大学 电气与动力工程学院,山西 太原 030000)
随着互联网的迅猛发展,人们进入了信息爆炸的大数据时代,推荐系统作为缓解信息过载问题的重要技术,已被广泛应用于各个领域,而推荐系统的成功应用离不开高精度推荐算法的支持。目前,主流的推荐算法是协同过滤技术,其假设行为相似的用户具有相似的偏好且未来会做出相似的选择,主要依赖于用户对物品的历史评分数据进行相似度判别,进而产生推荐。
虽然协同过滤算法具有较高的推荐精度,但只有当用户的评分数据充足时,它才能表现出良好的推荐性能。然而在实际应用中,大多数真实的数据集都是极其稀疏的,这使得推荐系统无法依据评分数据进行准确的相似度计算,产生理想的推荐结果。因此,如何有效解决数据稀疏性问题对于提高推荐性能具有重要的研究意义。
而评分数据稀疏性问题其实是信息匮乏的一种表现[1],它表明用户没有及时给予商品反馈信息,因而不利于了解用户的兴趣偏好。在用户反馈信息中非常具有价值的一类是评论文本,它描述了用户对商品的评价,包含大量可以反映用户偏好和商品属性的信息。因此,近年来研究者们提出利用评论文本信息来缓解评分数据的稀疏性问题。本文将研究如何充分挖掘评论文本来优化推荐模型,并提出一种融合双重注意力机制的多源深度推荐模型(multi source recommendation model of fusion dual attention mechanism,MSDA)。
1 相关工作
1.1 基于评分矩阵的推荐方法
评分矩阵作为一种直接反映用户兴趣偏好的显式反馈数据,在推荐系统中常被用于评分预测。基于评分矩阵的推荐方法主要分为两类:基于模型的协同过滤和基于邻域的协同过滤[2]。由于基于邻域的协同过滤算法依赖复杂的相似度计算,且在稀疏数据集上的表现往往较差,因此目前广为流行的是基于模型的协同过滤方法,其中矩阵分解模型(matrix factorization,MF)[3]应用最为成功。MF的基本思想是首先将用户偏好和商品属性特征分别映射成两个潜在因子向量,然后以这两个向量的内积作为用户对商品的预测评分值。随后,为提升推荐性能,Salakhutdinov等[4]通过添加用户和商品特征的高斯概率分布来进一步改进MF算法,提出了一种概率矩阵分解模型(probabilistic matrix factorization,PMF)。近年来随着深度学习的发展,He等[5]将传统矩阵分解和多层感知机相结合,提出一种基于神经网络的协同过滤算法(neural matrix factorization,NeuMF)。Wang等[6]将图神经网络应用于协同过滤模型中,利用二部图神经网络将用户-商品的历史交互信息编码进嵌入中,来提升嵌入的表示能力,进而提升推荐效果。
尽管基于矩阵分解的协同过滤方法可获得较好的推荐性能,但其依赖于评分数据进行推荐,而大部分真实的数据集是极其稀疏的,因此评分数据的稀疏性问题依然存在,且是该类模型面临的重大难点。为缓解评分数据稀疏性带来的影响,近年来的研究热点是通过挖掘评论信息来提高用户偏好和商品属性潜在因子的建模质量,进而提高推荐精度。
1.2 融合评论文本的推荐方法
早期融合评论文本的研究工作主要是基于主题模型的方法,如CTR[7]、HFT[8]、DTMF[9]、TMF[10]等模型,它们利用主题模型从评论文本中挖掘用户或商品的潜在主题分布来构建隐因子特征,并将其融合到基于评分数据的推荐模型中以提升推荐性能,CTR、HFT等方法所表现出的优越性能证明了使用评论文本信息进行推荐的有效性。但是基于词袋进行文本表示的主题模型使其无法保留词序信息,从而忽略了评论文本中重要的局部上下文语义信息[11],不利于全面捕捉用户的偏好。
为了克服词袋表示的缺点,近些年的相关研究主要集中在利用卷积神经网络(convolutional neural network,CNN)从评论文本中获得更好的潜在语义表示,这主要归因于CNN能有效保留词序信息。Kim等[12]提出的ConvMF(convolutional matrix factorization)首次利用CNN来提取评论文本的非线性特征,并将其整合到PMF中进行评分预测,推荐性能得到了明显提升。然而,ConvMF只考虑了商品评论文本信息,却忽略了用户评论文本信息对用户偏好建模的重要性。针对该问题,Zheng等[13]提出了DeepCoNN(deep cooperative neural networks),该模型同时考虑了用户和商品评论文本信息,并首创采用2个并行的CNN网络来分别处理用户评论集和商品评论集的研究思路。受此启发,Catherine等[14]通过引入一个额外的转换层,对DeepCoNN进行了扩展,该转换层用来模拟目标评论的近似表示,解决了评论文本在测试时对目标项目不可用的问题。Wu等[15]通过将CNN与双向GRU网络结合来提高推荐性能。类似地,如D-Atnn(CNNs with dual local and global attention)[16]和 CARL(context-aware user-item representation learning model)[17]在双CNN结构的基础上,通过结合不同的注意力机制来提高评论特征的提取和表达质量,进而提升推荐的准确性。
但上述方法都将每条评论对用户或商品建模的贡献视为同等重要,这在实际情况中并不可靠,因为有些评论的内容可能与商品不相关或参考价值较小。针对该问题,Chen等[18]提出的NARRE(neural attentional regression model with review level explanation)通过引入评论级别的注意力机制学习每条评论的权重,识别有用性评论,使得推荐性能得到显著提升。NARRE是目前理论和实验效果都比较杰出的融合模型,但它存在以下3点不足:1)该模型得到每条评论的注意权重后,通过简单的线性加权方法来获得用户偏好和商品属性的潜在表示,这将会引入较多的噪声信息,因为无用性评论可能占很大比例;2)该模型以独立的方式学习用户偏好和商品属性表示,忽略了用户和商品特征之间的相关性和交互影响;3)该模型基于隐因子模型(latent factor model,LFM)[3]进行评分预测,但是基于点积运算的LFM只支持线性方式学习特征的低阶交互,忽略了复杂的高阶非线性交互信息。
针对以上不足,本文对NARRE进行了改进:为减少噪声影响,构建特征抽象层,提取更高级别的抽象语义特征;引入共同注意力网络,学习用户评论文本和商品评论文本之间的相关语义信息,实现用户和商品的动态交互;采用统一的神经网络模型融合评分和评论潜在特征,通过神经因子分解机(neural factorization machine,NFM)[19]实现特征的高阶非线性交互,最终完成评分预测。本文提出一种融合双重注意力机制的多源深度推荐模型MSDA,3组公开Amazon数据集上的实验结果表明,MSDA能有效利用评论文本信息提升推荐质量,且相对于NARRE模型,评分预测性能最大提升了6.53%。
2 模型设计
MSDA模型的结构如图1所示,该模型首先利用3个信息源:评分数据、用户评论文本集和商品评论文本集来共同学习用户偏好和商品属性潜在特征,然后通过特征间的交互实现评分预测。因此,MSDA模型主要由特征学习模块和特征交互模块组成,其中特征学习模块又根据信息源数据类型的不同分为基于评分矩阵的学习和基于评论文本的学习,下面将主要对这3个模块进行详细介绍。
2.1 符号标识与描述
本文使用的主要符号的描述如表1所示。
2.2 基于评分矩阵的特征学习模块
该模块采用矩阵分解模型MF来学习评分矩阵中的用户偏好和商品属性潜在因子。假设用户-商品空间中,共有M个用户,N个商品,则用户-商品评分矩阵的维度为M×N,MF的目标是将R近似分解成2个隐含因子矩阵PM×K和QN×K的乘积,即R≈PQT。
因此,通过MF,评分矩阵中的每个用户u和商品i可以分别用1个K维的潜在因子向量pu和qi表示,其中pu表征用户的偏好特征,qi表征商品属性特征。则用户u对商品i的预测评分值为
(1)
2.3 基于评论文本的特征学习模块
对于评论文本信息,MSDA模型首先采用2个并行的Netu和Neti网络分别提取用户评论集和商品评论集中的潜在语义特征,然后将2个网络的输出传递到共同注意力网络层来进一步考虑用户和商品潜在特征之间的相关性和复杂交互。此外,为能充分考虑每条评论的语义信息,本文选择分别处理用户/商品评论集中的每一条评论,最后在共同注意力网络的汇聚层聚集所有评论的特征来表示用户偏好和商品属性。由于Netu和Neti网络结构相似,因此本节主要详细介绍对用户评论建模的Netu网络,而Neti同理。
2.3.1 嵌入层
Netu网络的第一层是词嵌入层,在该层每条评论通过Word2vec映射为1个具有固定维度的词向量矩阵Wlu×d,而用户u的所有评论将被表示为Wu1、Wu2、…、Wunu,其中Wuk(k=1,2,…,nu)为用户u的第k条评论经嵌入后得到的词向量矩阵,lu为用户u评论集中的最大评论长度,d为单词嵌入的维度,nu为用户u评论集中的评论总数。此外,MSDA模型采取不足补零、超过截断的方法,以lu为基准,将任意长度的评论映射到相同维度的词向量空间,并使用GoogleNews语料库对Word2vec模型进行预训练,把训练好的300维词向量作为嵌入。所有评论经嵌入层后被转换成词向量矩阵,然后再输入到CNN层中挖掘语义信息。
2.3.2 卷积神经网络
Netu网络的第二层是CNN,用于提取评论词向量矩阵的局部上下文特征。假设卷积层共有m个神经元,每个神经元使用1个词窗口大小为t的卷积核Kj,对于词向量矩阵Wuk,每个卷积核Kj的卷积运算公式为
Zj=δ(Wuk*Kj+bj)。
(2)
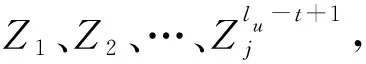
(3)
卷积层的最终输出是其m个神经元输出的级联,则用户u的第k条评论经过卷积层后得到的特征向量可表示为
Ouk=[O1,O2,…,Om]。
(4)
而用户u的所有评论词向量矩阵经过CNN层处理后,得到的特征向量分别表示为Ou1、Ou2、…、Ounu。
2.3.3 评论级别的注意力网络
用户评论集中,每条评论对用户偏好的建模贡献并非全部相同,为了区分每条评论的重要度,选择有代表性的评论,在Netu网络的第3层引入了评论级别的注意力机制来学习每条评论的权重。该注意力层的输入为评论特征向量Ouk和该评论所描述的商品ID嵌入iuk。添加商品ID是为了识别有用评论,用户撰写的评论信息一般是和所描述商品有关的,因此注意力权重越大,说明评论内容与商品越相关,该评论越具有代表性。在形式上,评论级别的注意力网络被定义为
guk=hTδ(WuOuk+Wiiuk+b1)+b2。
(5)
式中:guk是用户u撰写的第k条评论的注意力分值;h是权重向量;Wu、Wi是权重矩阵;b1、b2是偏置项。
利用softmax函数对上述注意力得分guk进行归一化处理,从而获得每条评论的最终权重
(6)
2.3.4 抽象层
Netu网络的最后一层是抽象层。基于注意力权重auk,可获得每个评论的加权特征向量
(7)
至此,NARRE模型通过汇集所有加权的评论特征向量来获得用户u的偏好表示
(8)

U=[hu1,hu2,…,hunu]T。
(9)
同理,可得到商品i的特征向量矩阵V∈Rni×m,
V=[hi1,hi2,…,hini]T。
(10)
2.3.5 共同注意力网络
目前,大多数基于评论文本的推荐方法[18,20-22]采用独立的方式分别学习用户偏好和商品属性的潜在表示,从而忽略了两者之间的相关性和复杂交互。为此,本文利用共同注意力机制来学习用户和商品特征之间的相关性,以捕获它们的交互作用。具体来说,首先将Netu和Neti网络的输出向量矩阵U和V投影到相同的潜在空间中,利用1个可学习的权重矩阵T∈Rm×m计算每对用户-商品特征之间的相关性,即
S=ReLU(UTVT)。
(11)
式中S∈Rnu×ni是计算所得到的共同注意矩阵,它实际上也是1个相似度矩阵,矩阵中的每个元素表示每对用户-商品特征之间的相关性。
然后,分别对矩阵S的每一行进行平均池化运算,将计算的平均相关度作为每个用户特征在空间U中的重要性,而每个商品特征的重要性通过对S的每一列求平均得到。平均池化运算定义如下:
(12)
(13)
(14)
(15)
最后,用户u的偏好特征向量和商品i的属性特征向量为
(16)
(17)
2.3.6 全连接层
为了与MF得到的潜在评分特征融合,将共同注意力网络的输出向量xu和yi输入到带有非线性激活函数的全连接层来获得1个K维向量,则用户u和商品i的潜在评论特征表示为
Xu=δ(w0xu+b1),
(18)
Yi=δ(w0yi+b1)。
(19)
式中:w0和b1分别为全连接层的权重矩阵和偏置项;Xu和Yi表示MSDA模型基于评论文本所学习到的用户偏好和商品属性特征。
2.4 特征交互模块
评分数据和评论信息具有互补性,当评分数据过于稀疏时,融入评论文本信息可以增强潜在评分特征的建模质量,从而提升推荐精度。因此,在特征交互模块中,首先对评分数据处理模块和评论文本处理模块得到的用户偏好特征和商品属性特征进行融合,融合后的用户特征fu和商品特征fi可以表示为
fu=Xu+pu,
(20)
fi=Yi+qi。
(21)

(22)
式中:m0为全局偏差;mj是向量z中第j个特征值zj的权重;f(z)是NFM用于建模高阶特征非线性交互的核心部分,具体表示为
(23)
式中:zj、zk∈z表示向量z的第j和第k个特征值;vj、vk∈R2K表示zj和zk的嵌入向量。根据文献[19],可通过堆叠多层全连接层来捕获特征之间的高阶非线性交互作用,最终NFM的评分预测函数为
hTδL(WL(…δ1(W1f(z)+b1)…)bL)。
(24)
式中:L表示隐藏层的数量;WL、bL和δL分别表示第L层的权重矩阵、偏置项和激活函数。通过指定非线性激活函数可允许模型以非线性方式学习高阶特征交互。
此外,为了研究潜在特征交互对模型评分预测性能的影响,后文对MSDA模型尝试了其他常用的评分预测方法,然而实验结果表明,NFM产生了更好的评分预测结果。
2.5 模型学习
为了学习MSDA模型的参数,本文使用平方损失作为目标函数
(25)
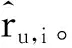
对于参数更新,本模型通过Adam优化器最小化目标函数来更新网络参数。Adam的主要优点是学习速率可以在训练阶段自适应,这使模型更快收敛的同时又减轻了人工选择学习速率的负担。
2.6 复杂度分析
本文提出的MSDA模型大部分计算量集中在评论文本处理模块的卷积层、抽象层和特征交互模块的评分预测层。在CNN中,单个卷积层执行卷积运算的计算量为
Fs=2MhMw(CinKhKW+1)Cout。
(26)

3 实验
本节主要围绕以下3个研究问题展开实验。
1)提出的MSDA模型在稀疏数据集上的表现如何?是否优于其他同样融合评论文本的推荐方法?
2)基于评论文本的学习模块中,抽象层所提取的更高级别的语义特征和共同注意力网络捕捉到的用户-商品特征对之间的相关性是否有助于提升推荐质量?
3)不同特征交互方式对于模型建模复杂的用户-商品评分行为有什么影响?
3.1 实验设置
3.1.1 数据集
本文采用亚马逊公共数据集Amazon 5-cores中的3个子类别数据集:Musical Instruments、Grocery and Gourmet Food、Sports and Outdoors来对MSDA模型进行性能评估。所选数据集的主要特点为:1) 数据集的内容包括用户ID、商品ID、用户对商品的评分(1~5分)、用户对商品的评论文本,符合模型所需实验要求;2) 都具有不同程度的高稀疏性,可用于验证本文所提方法在缓解评分数据稀疏问题上的有效性;3) 3个数据集来自不同的领域,具有不同的评论主题和大小,可验证MSDA模型的泛化能力。数据集的特征统计信息如表2所示。

表2 数据集统计信息Tab.2 Statistical information of data sets
在实验中,随机将每个数据集分为3部分:训练集(80%)、验证集(10%)和测试集(10%),最终的性能评估结果来自测试集。
3.1.2 评价指标
实验采用平均绝对误差(mean absolute error,MAE,记作EMA)指标来评估MSDA模型与所有基准方法的评分预测性能,MAE的值越小,表明评分预测性能越好,计算公式为
(27)
式中N表示测试集样本数。
3.1.3 对比模型
为了验证本文提出的MSDA模型的评分预测性能,以及评论文本信息能否有效缓解评分数据稀疏问题带来的影响,本节选取以下3种类型的基准方法进行对比实验。
1)基于评分数据的协同过滤方法。
PMF[4]模型是一个标准的矩阵分解模型,只使用评分数据作为输入进行评分预测。
NeuMF[5]模型将传统矩阵分解和多层感知机相结合,通过建模用户和商品特征间的非线性交互来进行评分预测。
2)基于评论文本的推荐方法。
DeepCoNN[12]模型相比于ConvMF模型,同时考虑了用户和商品评论文本信息,并首次提出利用双CNN结构来分别处理用户评论集和商品评论集的研究思路,其只使用评论文本进行评分预测。
D-Attn[15]模型在DeepCoNN的基础上引入局部和全局双重注意力机制来捕获有用的信息词以及评论文本的语义,从而增强推荐结果的可解释性。
3)融合评分数据和评论文本的推荐方法。
ConvMF[11]模型首次引入CNN来提取评论文本特征,并将其整合到PMF中进行评分预测,但该模型只考虑了商品评论文本信息。
CARL[16]模型首先提出以联合的方式学习用户和商品的潜在评论表示,并在评分预测层通过动态线性融合机制将评分数据和评论文本进行融合。
NARRE[17]模型首先考虑了评论的有用性,通过引入评论级别的注意力机制来识别有用性评论,使得评分预测性能得到显著提升。该模型还提出了神经形式的LFM用于评分预测。
HRDR[20]、RMRT[21]模型为最新的推荐方法,加强了对评分数据的深度建模,同样采用独立的双CNN结构处理评论文本,评分预测方式为LFM。
3.1.4 参数设置
对于所有基准模型的参数设置,本文首先根据对应的文献进行参数初始化,然后使用网格搜索法进行参数微调,使其达到最佳性能,且所有模型取5次的平均测试结果作为最终的实验对比数据。
对于本文提出的MSDA模型,卷积核的大小为3,卷积核数量为100,单词的嵌入维数为300。而对于其他超参数的设置,由于模型在不同数据集上取得最佳表现的对应参数都不同,因此本文在3个数据集上做了参数灵敏度分析实验,以研究不同参数值对MSDA模型推荐性能的影响。实验中,潜在因子维数在[8, 16, 32, 64]中测试分析,Dropout在[0.1, 0.2, 0.3,…, 0.9]中测试分析,batch size则在[25, 50, 75, 100, 125]中选择,学习速率在[0.001, 0.002, 0.005, 0.01, 0.02]中选择。根据最佳实验结果,MSDA模型的潜在因子维数被设置为32,学习率为0.002,3个数据集上的batch size分别为25、100、125,Dropout比率分别为0.4、0.6、0.6。此外,MSDA模型的实现基于Python 3.6和Tensorflow 1.14编译环境,并使用GPU对训练进行加速。
3.2 实验结果与分析
3.2.1 模型整体性能对比
本文提出的MSDA模型和其他9个对比模型在Musical Instruments、Grocery and Gourmet Food和Sports and Outdoors数据集上的平均绝对误差(MAE)实验结果如表3所示。通过对比分析实验结果,可以得出如下结论。
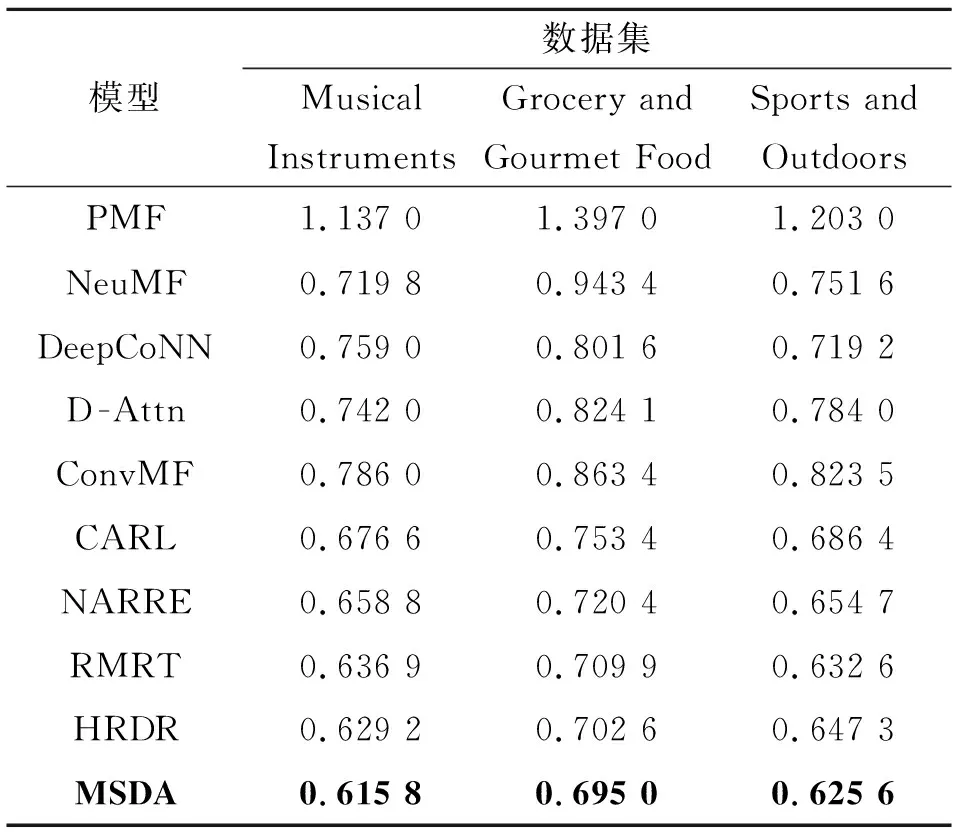
表3 不同推荐模型的MAE对比Tab.3 The MAE comparison of different recommendation models
1)MSDA模型在3个数据集上的表现均优于所有的基准模型。由表2统计信息可知,3个数据集的稀疏度都高达99%,在这种极端稀疏场景下,MSDA相比于最佳基准模型HRDR评分预测性能平均提升了2.18%。这一方面证实了MSDA模型在缓解评分数据稀疏问题上的有效性与优异性,另一方面也证明了共同注意力网络层和NFM对于提升推荐性能的有效性。
2)同时考虑评分数据和评论文本的融合模型(NARRE、HRDR、MSDA等)通常比仅使用单一评分数据(PMF、NeuMF)或评论文本的推荐方法(DeepCoNN、D-Attn)表现更好,这说明评分数据和评论文本具有互补作用,两者的融合有助于提高用户偏好和商品特征的建模质量,从而得到更好的评分预测性能。
3)融入注意力机制的推荐模型(CARL、NARRE、MSDA)往往能够获得更好的推荐性能。这是因为注意力机制能够根据任务目标,自动提取与任务最相关的信息,起到抑制噪声信息、提高相关信息的作用。因此,MSDA模型能够取得最佳表现,离不开本文所设计的双重注意力机制。首先评论级别的注意力机制有助于识别重要性评论,其次共同注意力网络所捕捉到的用户-商品特征之间的相关性能帮助模型提升用户偏好和商品属性特征的表达质量,从而使得推荐性能得到了进一步的提升。
3.2.2 参数敏感性分析
本节在3个数据集上探索了潜在因子维数和Dropout对MSDA模型推荐性能的影响。实验中潜在因子维数在[8, 16, 32, 64]中测试,Dropout在[0.1, 0.2, 0.3,…, 0.9]中测试,而其他超参数取最佳性能对应的参数值,并保持不变。实验结果如图2所示。
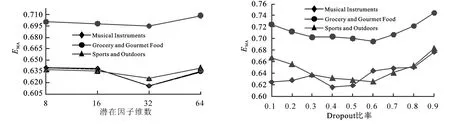
a.潜在因子维数对MSDA模型性能的影响 b.Dropout对MSDA模型性能的影响
由图2a可以看出,随着潜在因子维数的增加,MSDA模型在3个数据集上的评分预测性能都逐渐上升(MAE越小越好),这是由于维度的增加可使得潜在特征向量编码获得更多有用的信息,但同时也会增加模型训练的时间和空间复杂度,且维数过多时,易发生过拟合,所以当潜在因子维数大于32时,MSDA模型在3个数据集上的性能有所下降。因此经过综合考虑,将MSDA模型的潜在因子维数设置为32。
由图2b可以看出,当Dropout比率过小或过大时,MSDA在3个数据集上的表现都不理想,这是因为Dropout比率过大将会丢失太多的神经元,可能导致欠拟合,而比率过小时又不能有效缓解数据过拟合问题,因此只有设置一个合适的Dropout值,才能使得模型的性能得到显著提升。根据3个数据集上的性能最佳实验结果,MSDA模型在相应数据集上的Dropout比率分别设置为0.4、0.6、0.6。
3.2.3 消融实验
对MSDA模型结构进行了修改,得到以下3个变体模型,以研究评论文本特征学习模块中抽象层和共同注意力网络的引入对模型推荐性能的影响,并与NARRE进行对比实验,从而验证本文改进工作的有效性。为保证实验的公平性,以下3个变体模型均采用NARRE模型所提出的神经形式的LFM方法进行评分预测。实验结果如图3所示。

图3 消融实验结果Fig.3 Ablation results
MSDA-LFM模型仅改变MSDA的评分预测方式,与NARRE模型相比,增加了抽象层和共同注意力网络层。
MSDA-C模型在MSDA-LFM模型的基础上,舍弃共同注意力网络,即直接将共同注意力权重设为1,以研究抽象层对模型性能的影响。
MSDA-MA模型在MSDA-LFM模型的基础上,舍弃抽象层,以研究共同注意力网络对模型性能的影响。
由图3可以看出,与NARRE相比,3个变体模型MSDA-C、MSDA-MA、MSDA-LFM在3个数据集上的评分预测性能均得到了提升。MSDA-C性能的提升应归因于CNN,它确保了抽象层能够从加权的上下文特征中提取更高级别的语义特征,且实验结果证实了该语义特征的重要性;而MSDA-MA模型引入的共同注意力网络能捕捉用户-商品特征之间的相关性,这种相关性也被证实有助于增强潜在因子的建模质量,进而获得更好的推荐性能;MSDA-LFM取得的最佳性能也进一步验证了抽象层和共同注意力网络层的有效性。
3.2.4 潜在特征交互的影响分析
对MSDA模型尝试了以下3种评分预测方法,以研究潜在特征交互对模型评分预测性能的影响,3个数据集上的实验结果如图4所示。
FM为因子分解机,是推荐系统中常用的一种评分预测方法,只考虑了二阶特征交互。
LFM为隐因子模型,本文采用的是NARRE所提出的神经形式的LFM,但是特征交互方式未改变,依旧是基于点积运算进行特征的线性交互。
NFM为神经因子分解机,在FM的基础上引入DNN,使用神经网络来学习特征的高阶非线性交互。MSDA模型使用的是该方法。
由图4可以看出,基于NFM进行评分预测的MSDA模型在3个数据集上均获得了最低的MAE,其评分预测性能明显优于支持低阶线性特征交互的MSDA-FM和MSDA-LFM模型。这表明,相比于潜在特征之间的低阶线性交互,高阶非线性交互作用更有助于模型学习复杂的用户-商品评分行为,从而获得更好的推荐性能。
3.3 统计分析
为了对比本文提出的MSDA方法相较于其他推荐算法在性能上是否具有显著性差异,本文采用Friedman检验和Nemenyi后续检验进行分析。首先,根据表3的对比实验结果,将各个算法按照MAE值从低到高的顺序进行排序,得到不同推荐算法在3个数据集上的排序表,结果如表4所示。

表4 不同推荐算法在3个数据集上的MAE排序表Tab.4 MAE ranking table of different recommendation algorithms on three datasets
然后,使用Friedman检验来判断这些算法是否性能相同,同时建立“所有算法性能相同”的检验假设。变量τF服从自由度为(k-1)和(k-1)(N-1)的F分布,计算方法如(28)、(29)式所示:
(28)
(29)
式中:数据集个数N=3;算法个数k=10;查表得在α=0.05的水平下,临界值Fα=2.456,qα=3.164。经计算τF=47.587>2.456,因此否定“所有算法性能相同”这个假设。
为进一步区分各算法之间的性能差异,需进行“后续检验”,本文采用Nemenyi后续检验方法,将2种算法的平均序值之差与临界值域CD(记作DC)进行对比,若差值大于DC则说明2种算法存在显著差异,反之两者无显著差别。
(30)
根据(30)式计算出临界值域DC=7.822,结合表4可知,算法NeuMF、DeepCoNN、D-Attn、ConvMF、CARL、NARRE、RMRT、HRDR和MSDA两两之间的平均序值之差均小于DC,而算法MSDA与PMF的差值大于DC。因此,检验结果认为算法MSDA与PMF的性能显著不同,而其他算法两两之间在统计上没有显著差别。这一检验比较可以直观地用Friedman检验图(图5)显示,图中黑色圆点表示每个算法的平均序值,而以圆点为中心的横线段表示临界值域的大小;此外,2种算法的横线段重叠部分越多,说明这2种算法的差异性越小,反之说明两者差异性显著。

图5 Friedman检验结果图Fig.5 Results of Friedman test
从图5可以直观地看出,算法D-Attn与NeuMF的横线段重叠部分比例最高,说明这2种算法没有显著差别;而算法MSDA的横线段与HRDR、RMRT、NARRE、CARL有较多重叠区域,与DeepCoNN、D-Attn、NeuMF有较少的重叠区域,与ConvMF、PMF基本无或者无重叠区域,这说明本文所提算法MSDA虽然与其他算法差异性较小,但仍然优于其他9种推荐算法,且显著优于ConvMF和PMF算法。
4 结语
本文提出了融合双重注意力机制的多源深度推荐模型,在该模型中评分数据和评论文本得到了有效利用。同时,为提升推荐性能,引入评论级别的注意机制识别有用性评论,以增强评论特征的提取质量;引入共同注意力机制捕捉用户评论文本和商品评论文本间的相关语义信息,以增强潜在因子的表达质量。此外,为帮助模型建模复杂的用户-商品评分行为,本文在特征交互模块利用NFM学习特征的高阶非线性交互作用。MSDA模型在3组高稀疏数据集上获得的优越推荐性能表明,本文所提方法能有效缓解评分数据稀疏问题,提升推荐精度。未来工作中,将考虑利用软计算方法处理稀疏的评分矩阵,并将得到的稠密评分矩阵用于MSDA的评分预测任务,从而进一步提升模型的推荐准确度。
