基于XGBoost算法构建颈动脉粥样硬化患病风险初筛模型
2023-08-31张富颜玉云福建中医药大学附属人民医院福建福州350004
张富 颜玉云 福建中医药大学附属人民医院 (福建 福州 350004)
内容提要: 目的:分析颈动脉粥样硬化(Carotid Atherosclerosis,CAS)人群的临床指标特征,筛选CAS的最佳预测指标,建立简便有效的CAS患病风险预测模型,为普通人群CAS的早期识别及拟定筛查指标提供依据。方法:回顾性分析2017年~2018年福建省人民医院健康体检中心的9405份体检数据,选取其中行颈部血管彩超等检查的870位体检者为研究对象,分为CAS组和非CAS组,分析两组人群的一般临床资料和实验室检查资料。采用特异性、灵敏度、F1值、曲线下面积、查准率-查全率曲线下面积作为评价指标,对比逻辑回归、随机森林和XGBoost算法预测模型评估CAS患病风险的优劣。结果:①XGBoost模型在测试集上的评价指标均最高。②对于识别CAS,临床特征中贡献度最大的是年龄,其次是收缩压、肌酐。结论:基于XGBoost模型识别CAS的患病风险效果最佳,该模型能较好的CAS患病风险并对普通人群进行CAS患病风险的初筛。
目前动脉粥样硬化性心血管疾病的治疗与预防已取得重大进展,但它仍是最主要的死亡原因。《中国心血管健康与疾病报告2020》[1]显示,中国动脉粥样硬化性心血管疾病患病率仍处于持续上升阶段,其带来的医疗系统负担日渐加重。动脉粥样硬化是动脉粥样硬化性心脑血管疾病的共同病理基础,颈动脉粥样硬化(Carotid Atherosclerosis,CAS)可作为早期反映全身动脉粥样硬化性疾病病变程度的一个“窗口”,早期实施干预可以有效调节该疾病进程[2,3]。尽管超声检测颈动脉内膜中层厚度(Intima-Media Thickness,IMT)是目前判断CAS硬化程度的可靠指标,但由于仪器设备成本高、操作专业性强、测量标准不统一等原因,许多专家并不推荐在普通人群的常规筛查中进行颈动脉超声检查[4]。因此有必要进一步探索更简便有效的CAS辅助诊断手段及早期识别策略。随着计算机技术的迅速发展,各类机器学习算法已被广泛应用于挖掘海量临床数据中潜在的、有价值的信息,尤其是在心血管疾病风险管理、预测等各领域[5]。
1.资料与方法
1.1 临床资料
严格按照选择标准筛选样本,共收集870份体检报告,年龄29~88岁,平均(58.73±9.75)岁,其中男性263名(57.3%),以颈动脉IMT为依据划分为CAS组459份(IMT≥1.0mm),Non-CAS组411份(IMT<1.0mm)。本研究已通过福建省人民医院伦理委员会批准,受试者及家属均自愿参与本研究,并签署知情同意书。
纳入标准:年龄≥18周岁且完成本研究所需的人口特征、体格检查、实验室检验结果、中医证素积分、颈部血管彩超检查。排除标准:合并恶性肿瘤,自身免疫性疾病,结缔组织疾病,血液系统疾病,骨质疏松,严重感染性疾病,严重肝肾损害者;妊娠或哺乳期女性;存在严重精神疾病或认知障碍不能配合问卷调查者。
1.2 方法
1.2.1 CAS诊断标准
参考《超声医学》[6]及2015年《中国健康体检人群颈动脉超声检查规范》[7]并结合临床医师和超声医师意见确定CAS诊断标准如下:颈动脉内中膜增厚伴或不伴CAS斑块。二维超声显像下测量颈动脉IMT≥1.0mm(颈总动脉、颈内动脉处IMT≥1.0mm,颈总动脉膨大部≥1.2mm)为颈动脉内中膜增厚;颈动脉IMT≥1.5mm,或大于周围正常IMT值至少50%且具有凸向管腔的局部结构变化定义为CAS斑块形成。
1.2.2 数据采集和预处理
共纳入870份数据,无缺失值和异常值,其中颈动脉IMT为因变量,年龄、性别、体重指数、脉搏、收缩压、舒张压、血常规检验结果、生化检验结果共94个临床变量为自变量。以变量名为首行,样本序号为首列录入数据,建立Excel原始数据表,其中计量资料以数值形式录入,连续型变量保留小数点后三位,计数资料按二分类结果录入。
1.3 统计学分析
预处理后的数据使用IBM SPSS Statistics 26.0软件进行统计学分析,显著性检验水准取双侧界值,当P<0.05时,差异有统计学意义。定量数据经正态性检验后,符合正态分布(P>0.05)的总蛋白、球蛋白、白细胞计数、红细胞压积、中性粒细胞水平采用±s表示,组间比较采用两样本t检验;不符合正态分布(P<0.05)的其他定量数据采用中位数(下四分位数,上四分位数)[M(P25,P75)]表示,组间比较采用Kruskal-Wallis秩和检验;定性数据用n、%表示,例数>40和(或)最小理论频数≥5时,采用χ2检验,当例数<40或至少1个最小理论频数<1时,采用Fisher精确检验。
1.4 建模与验证
运用Holdout验证方法随机划分原始样本,一般来说,选择少于原始样本三分之一的数据作为验证集,因此,将870份数据按7:3的比例随机划分为两个部分,70%的数据集用于训练模型,为了消除随机性,采用5折交叉验证来调整模型的超参数,这一过程使用NumPy和pandas实现。30%的数据集用于验证模型,通过seaborn和Matplotlib绘制受试者操作特征曲线(Receiver Operating Characteristic curve,ROC curve)和查准率-查全率曲线(Precision-Recall Curve,PR curve),计算准确率、特异性、精确率、灵敏度、F1值、ROC曲线下面积(Area Under the Curve,AUC)及查准率-查全率曲线下面积(Area Under the Precision-Recall Curve,AUPRC)对比评价模型预测性能,数值越大表明模型的性能越好。在训练集中,以差异有统计学意义的临床特征为输入变量,构建带L2正则化逻辑(Logistic Regression,LR)回归模型和随机森林(Random Forest,RF)模型与XGBoost模型对比,比较不同模型预测CAS的评价指标,得出最佳预测模型。采用scikit-learn package来进行模型的构建、对比评估以及对模型的解释。以上过程均通过Python的机器学习库实现。
2.结果
2.1 两组基线资料对比
见表1、表2。
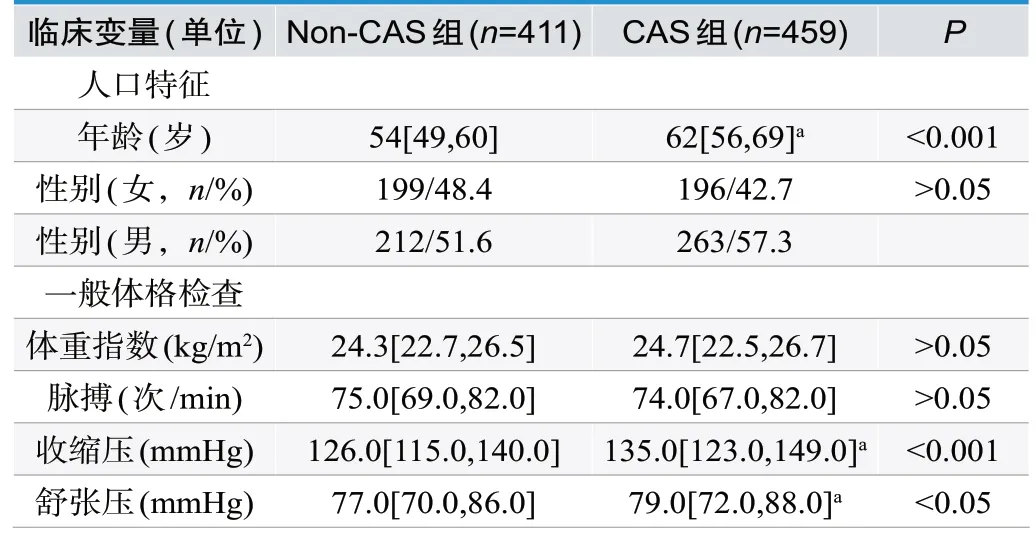
表1.两组人群一般临床资料的比较
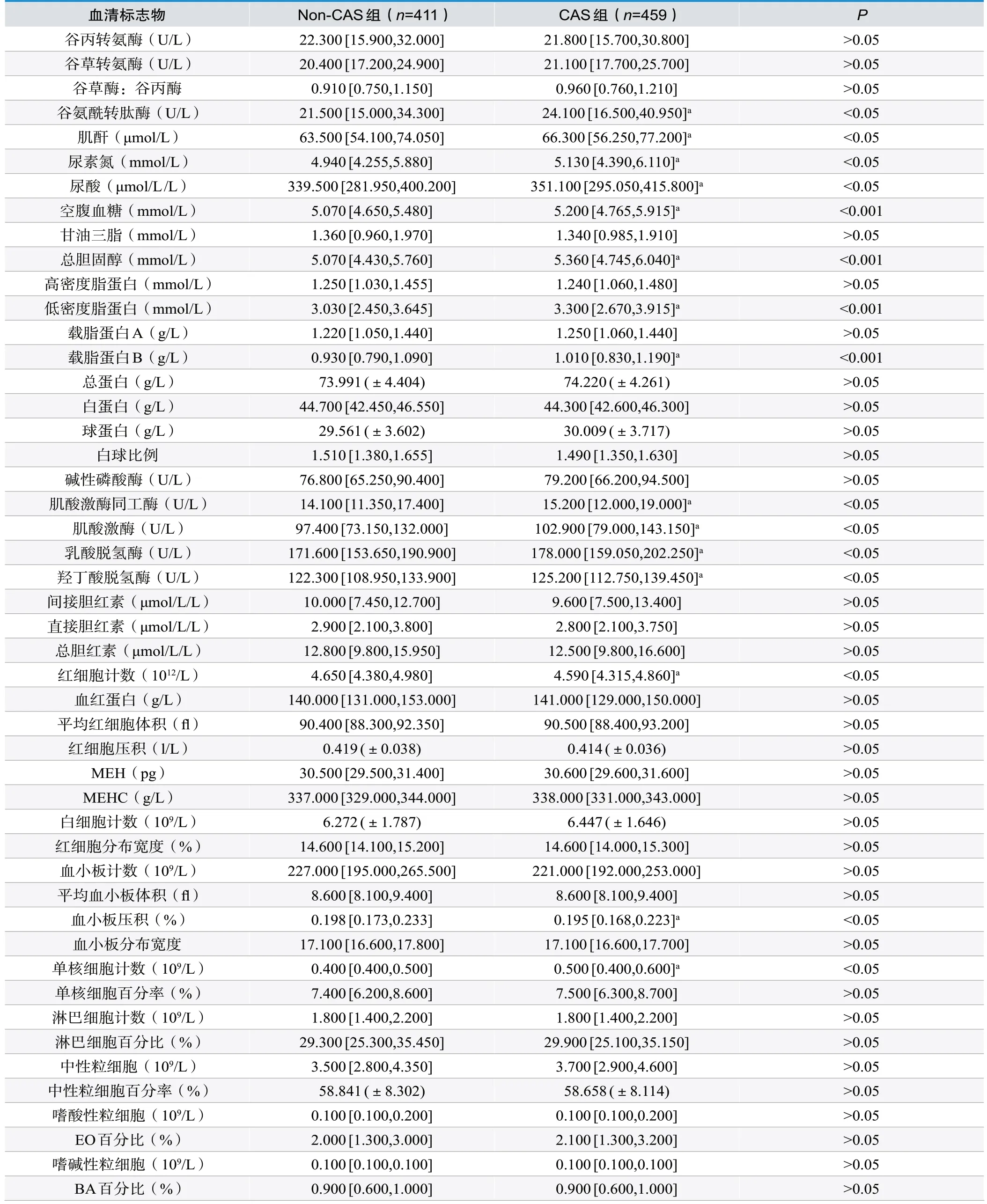
表2.两组人群血清标志物的比较
由上表可得,经统计学分析,与CAS具有显著性差异的变量特征共有18项,分别是年龄、收缩压、舒张压、总胆固醇、低密度脂蛋白、载脂蛋白B、空腹血糖、谷氨酰转肽酶、尿素氮、尿酸、肌酐、肌酸激酶、肌酸激酶同工酶、羟丁酸脱氢酶、乳酸脱氢酶、单核细胞计数、红细胞计数、血小板压积。差异有统计学意义(P<0.05)。
2.2 预测模型的训练与评价
2.2.1 模型的超参数
以差异有统计学意义的临床特征为输入变量,调整每个分类器的参数使其达到最佳(详见表3)。

表3.预测模型的超参数
LR是机器学习中一种虽然基础但非常重要的算法,适用于分类问题的解决。LR模型训练后的超参数取值如表3所示,penalty指惩罚项,主要目的是为了防止模型过拟合,一般默认选择L2正则化;solver代表优化方法,本研究选择的lbfgs是一种迭代优化损失函数方法,即通过损失函数的二阶导数矩阵(海森矩阵)实现优化。C是惩罚系数,即对误差的宽容度,也指泛化能力的优劣,一般可以选择0.0001~10000之间的数值,C越高,说明越不能容忍出现误差,越容易过拟合,C越小则越容易欠拟合。
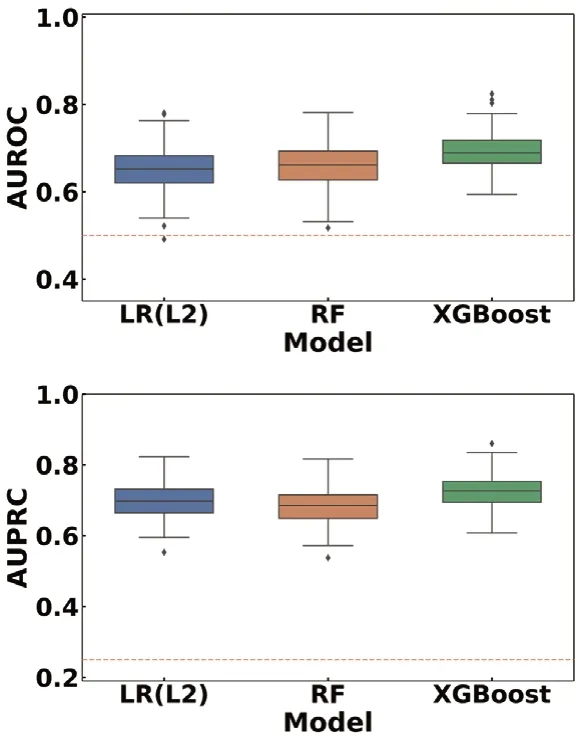
图1.50 轮5 折交叉验证期间三个模型的性能比较
RF是以决策树为基础的一种集成机器学习方法,能解决模型过拟合的问题,分类效果优于传统的分类算法。RF模型的超参数取值如表3所示,oob_score表示是否采用袋外样本,推荐设置为True,可检测一个模型拟合后的泛化能力,评估模型的好坏。
表3显示模型训练过程中XGBoost模型的最佳参数取值。nestimators指迭代次数,用于控制模型计算过程中使用的树的数量,取值太小容易导致模型欠拟合,取值过大会增加占用的内存以及延长训练和预测的时间;learning_rate指学习率,取值通常在0.01~0.2,通过减少每一步的权重来增加模型的鲁棒性;max_depth是指树的最大深度,推荐取值在5~20,如果树的深度过大,将导致模型只学习到特定样本间的关系,故为了有效防止模型过拟合需合理控制树的深度;subsample指样本采样比例,一般取值在0.6~0.9,合理调试可一定程度上防止模型过拟合。
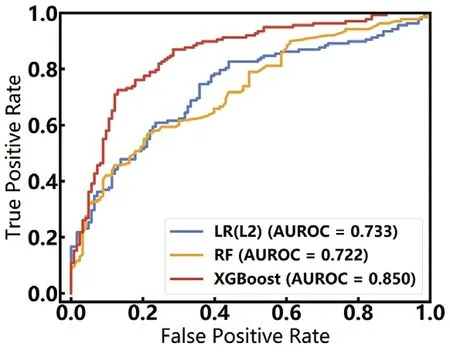
图2.三种预测模型的AUC 曲线图
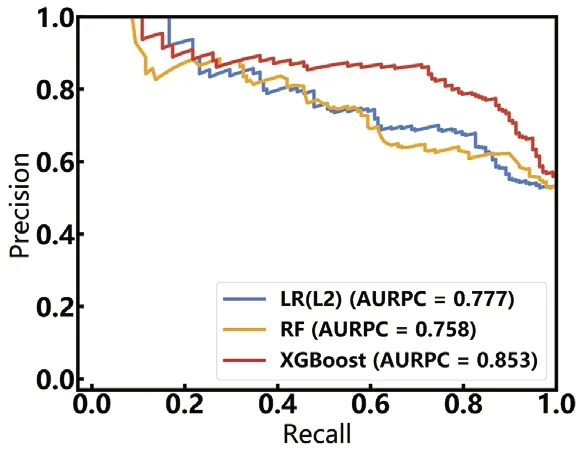
图3.三种预测模型的AUPRC 曲线图
2.2.2 模型的训练
如图1所显示50轮5折交叉验证期间,基于具有显著性差异变量的三个模型CAS预测结果的AUC和AUPRC分布情况。LR(L2)、RF和XGBoost模型预测CAS患病风险的所有AUC均>0.5,AUPRC均>0.25。从箱型图上可以进一步看出,XGBoost模型AUC和AUPRC中位数均大于其他两个模型,预测效果最佳。
2.2.3模型的验证
在验证集上进行测试,计算模型评价指标如图2、图3及表4所示。结果显示XGBoost模型综合预测效果更好,在验证集上的AUC为0.85,较LR(L2)模型高出0.117个百分点,较RF模型高出0.128个百分点;从三个模型在测试集上的对比可以看出,XGBoost模型的特异性、灵敏度、F1值、AUPRC最高,分别为0.756、0.804、0.796、0.853。

表4.模型的评估指标比较
2.2.4 特征重要性分析
对各变量的特征重要性进行排序,明确各变量对CAS的影响程度。在最佳预测模型基于具有显著性差异变量特征的XGBoost模型中,通过信息增益计算了各变量特征对识别CAS的重要性得分,图4显示了排名前10的特征,由图可得对于识别CAS,临床特征中贡献度最大的是年龄,其次是收缩压、肌酐。
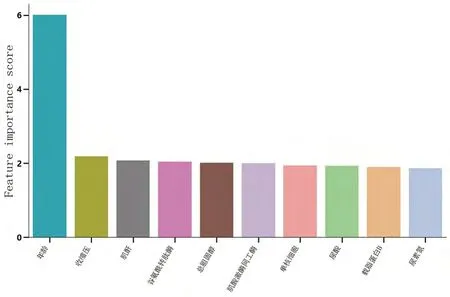
图4.特征重要性分值
3.讨论
本研究通过对体检人群的一般临床资料、常见血液检验指标进行统计学检验,筛选了具有显著性差异特征的变量,从不同输入变量和机器学习方法两个角度进行模型预测性能对比,可能更适用于普通人群的CAS风险初筛和早期识别。
本研究表明,脂质复合物随着年龄的增长逐渐累积,年龄是CAS的主要影响因素,这与当下流行病学调查结果一致[8,9]。研究发现,收缩压水平的升高可引起体内血液动力学改变,随着血管腔内压力的逐渐增大,血管内中膜进一步增厚,脂质在此沉积,进而使血管弹性减退,最终加速粥样斑块的形成[10]。血脂异常是动脉粥样硬化的主要危险因素,脂质和炎性细胞浸润动脉下膜层构成动脉粥样硬化连续体的早期过程,增厚的内膜-介质复合物和颈动脉斑块作为其极端表现,是全身性动脉粥样硬化的代表[11]。谭展飞等[12]研究得出CAS患者血脂水平表达水平与健康人存在差异表达,与本研究结果一致。空腹血糖是CAS的可控危险因素之一,一项10年ASCVD风险研究报道,空腹血糖水平的升高促进了颈动脉硬化的进展及斑块的形成,在空腹血糖调节受损开始阶段,动脉血管结构和功能的损害已经出现,随着空腹血糖水平进一步升高,损害也进一步加重[13]。罗燕等[14]研究发现谷氨酰转肽酶参与人体氧化应激反应,增加氧自由基的产生,其水平的升高,与血脂异常等代谢综合征重要组成部分的发生、发展呈正相关,可能与CAS发生、发展也具有一定的相关性。血清肌酐、尿素氮、尿酸水平的升高是AS的危险因素,一项关于2型糖尿病肾功能与CAS相关性研究表明良好的肾功能水平,CAS发生率较低[15,16]。一项荟萃分析发现,血清尿酸水平与颈动脉内膜介质厚度之间存在显著相关性,其水平的升高可促进斑块中低密度脂蛋白氧化及脂质的过氧化,可能也是影响CAS进展的机制[17]。高浓度的血清尿酸与颈动脉内膜介质厚度相关常规降脂可为肾功能带来良好的保护作用[18]。单核细胞计数在斑块形成的各个过程起促氧化促炎作用,是颈动脉斑块形成的新型预测指标[19]。聂凤英等[20]一项相关性研究结果也表明颈动脉斑块组单核细胞计数高于无颈动脉斑块组。血清心肌酶谱水平的升高对ASCVD具有预测价值,是辅助急性心肌梗死的诊断和溶栓后效果的评价的检测指标[21]。一项汉族人群高原脑卒中高危相关指标研究结果显示,在高海拔环境下,红细胞计数是颈动脉斑块发生的危险因素[22]。有研究指出,血小板参数升高时,动脉粥样硬化性血栓形成所致的急性脑梗死的发生风险增加[23]。
在训练出最佳模型后,需要再验证集中进行验证,选择评价指标来度量和评估各模型泛化能力。敏感性指的是CAS被正确识别的比率,特异性则是指非CAS的人群被正确识别的比率。F1值在统计学中常用来衡量二分类模型的分类效果是否精确,F1值是对模型准确率和召回率的加权平均,数值波动于0~1,数值越大代表模型分类效果越好。AUC是一个介于0~1的数值,当AUC值接近于1,表示分类器可以较好地分类正负样本。本研究中所有模型的AUC均>0.7,其中基于具有显著性差异变量特征的XGboost模型AUC和AUPRC最高,分别为0.850和0.85,特异性、敏感性和F1值均在0.7以上,说明在三个预测模型中,XGboost模型的综合预测性能最佳。
XGBoost模型以其在不同基准测试中获得最佳结果的能力而著称,并且是用于计算并行化领域中的最佳优化算法之一,相比其他机器学习模型对多方面性能进行了优化,首先是自身的优化,采用无放回的抽样方法,模型的输出结果由决策树中的所有结果进行累加或者加权累加计算得出。其次是算法过程的优化,对于损失函数,除了自身的损失,还加入正则项防止过拟合;在对误差部分做一阶泰勒展开基础上,又进行了二阶泰勒展开,这令预测结果更加准确;支持特征并行处理,在每次的迭代中重复使用特征列排序后的结构,该结构在内存中以块的形式存储,从而优化了运行效率。最后是鲁棒性的优化,对于每个特征,都进行了增益计算,最终选择增益最大的特征进行节点分裂,并且各个特征的增益计算可以多线程进行。因此,与其他模型相比,XGBoost不仅提高其泛化能力、运行效率和鲁棒性,还具有更好的识别能力和拟合优度。
本研究基于具有显著性差异变量特征的XGboost模型,与其他输入变量和其他模型分别相比,均具有最好的分类识别能力,能较好地区分CAS,可应用于基层社区医院对普通人群进行CAS患病风险的初筛,支持提高效率和有限资源分配的策略制定,可为院前预防、早期诊治CAS提供技术手段支持。
4.局限和展望
研究结果中心肌酶谱、红细胞计数、血小板压积等常见临床变量预测CAS发病的机制尚不明确,其作为CAS新型生物标志物的预测价值需进一步研究探讨。本研究中的机器学习方法为实现和改进更具个性化的CAS风险评估提供了令人兴奋的前景,这可能有助于推动CAS个性化医疗,更好地为个体患者量身定制风险管理。