基于图计算与知识匹配的事件分拨模型
2023-08-26陈健鹏
陈健鹏


关键词:事件分拨;图计算;信息传播;记忆网络;知识匹配
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0013-04
0 引言
近几年,数字政务领域快速发展,12345热线作为数字政务建设的重要成果,因其灵活、便捷的特点,成为政府与公众沟通的有效桥梁,在满足群众需求,解决群众问题等方面起到了极为重要的作用。然而,由于热线事件来源的广泛性与市民诉求的差异性,热线事件描述文本之间的理解难度往往也存在较大的差别,这就导致对接线员的要求较高,接线员往往难以在错综复杂的事件描述中迅速找出核心信息与关键要素,进而准确地决定事件的分拨部门。热线事件的分拨效率往往也因此受到影响。基于此,设计一种更为有效的事件分拨模型显得尤为重要。
传统的事件分拨模型一般基于先验知识[1]或统计学习[2]来进行,这类方法在一定的事件类型范围内能取得有效的分拨效果,但是先验知识的局限性使得对这类模型难以适应多样化的表达方式,提升也较为困难。为了解决这个问题,深度学习技术被应用在这类任务中[3-5] ,这类方法能有效提升对多样化表达方式的适应能力,但是缺乏对语义信息的准确挖掘。因此,基于海量语料库的预训练语言模型出现后,出现了一类基于预训练语言模型的方法[6-7],这类方法有效地增强了模型对文本中关键信息的识别能力。但是,由于部门职责具有一定的宽泛性,模型往往无法有效捕获这类“归属不同职能但由同一部门处置”的事件中潜在的关联关系,在部门较多的情况下,这类模型的分拨准确性往往较为有限。本文通过引入“三定”职能描述作为先验知识,结合文本图与键值对记忆网络等方法,通过细化事件分拨任务,挖掘事件与部门之间更多可能的关联性,进而提升对热线事件的分拨准确度,提高热线事件的处置效率。
1 方法
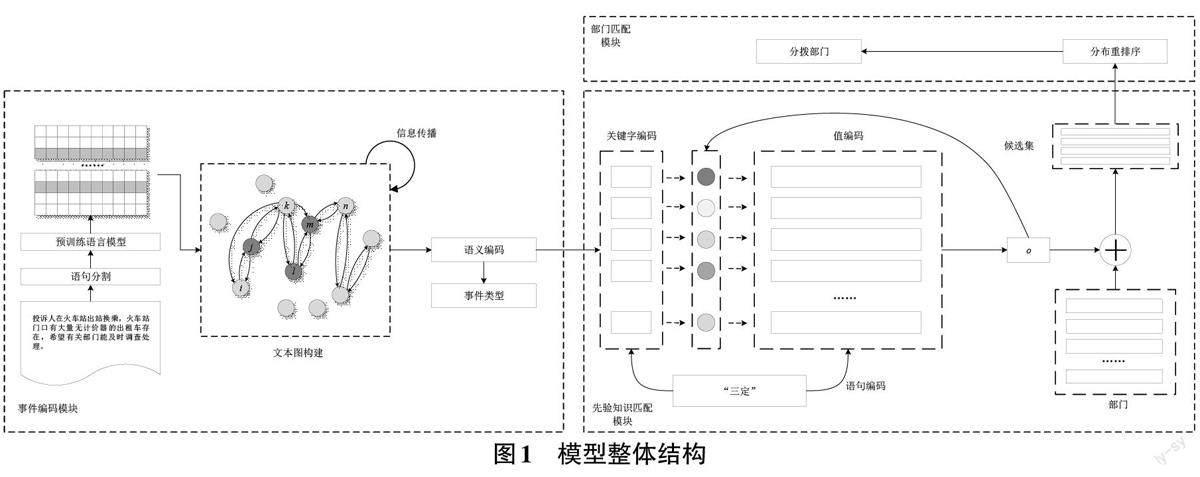
本文提出的事件分拨模型主要由事件编码模块、先验知识匹配模块与部门匹配模块三个部分构成,模型整体结构如图1所示。首先,将事件描述文本输入事件编码模块,通过构建文本图与消息广播的方式将事件描述文本映射为包含多层次语义关联信息的高维向量编码。然后将得到的语义编码输入先验知识匹配模块,利用基于记忆网络的知识选择模型,通过多次迭代,生成事件描述文本与“三定”之间的匹配度分布。最后,将得到的匹配度分布送入部门匹配模块,基于历史事件和“三定”职责描述中的关键信息等维度,对生成的匹配度分布进行整合与筛选,以获得最合适的事件处置部门。
1.1 事件编码模块
事件描述作为偏口语化表达的文本内容,其中一部分的语义信息往往与其上下文存在着紧密的关联关系,同时,这种关联关系涉及的跨度范围可能长短不一。为了能更好地将这类关联关系信息融入对事件描述文本的编码向量中,在事件编码模块中,本文通过构建文本图的方法,并结合信息广播算法,使得编码模块在对事件文本的某部分进行编码时,能关注到更广泛范围内的上下文信息。本文对事件的编码包括三个主要步骤,分别是预处理、建立文本图与信息传播。整体流程如图2所示。
1.1.1 预处理
考虑到政务事件所面向的实际场景,事件描述文本往往由多段较短的语句构成且表意较为直接,因此本文选择将字作为事件编码的基本处理单元,并通过编码矩阵对事件文本描述进行编码。
2 实验
2.1 数据集
基于某市现有的政务热线数据,构建了一个非公开的实验数据集。这个数据集包括两部分:“事件-部门”数据集与“事件-‘三定”数据集。其中“事件-部门”数据集基于政府热线真实事件分拨结果构建,包含30个事件处置部门的30 000条历史事件数据。“事件-‘三定”数据集则由专家根据“事件-部门”数据集中涉及的30 000条事件对应的处置结果进行标注得到,包含30 000条匹配正确的“事件-‘三定”文本对,以及60 000条匹配错误的“事件-‘三定”文本对。
2.2 实验设置
在对两个数据集中的文本长度进行统计分析后,90%的事件文本都在260个字以内,而90%的“三定”描述文本长度则在180个字以内。因此,在对数据集进行预处理时,本文固定事件描述文本最大长度为300字,“三定”文本最大长度为200个字,对二者中长度不足的部分使用[BLK]标识符加以填充,超过此长度的予以截断,并在事件描述文本的开头与结尾添加[CLS]标识符。模型训练过程中,整体模型训练的批大小设置为16,且使用学习率为10-5的Adam优化器作为模型的优化器。
为了验证本文所提出的模型性能,将本文模型与bAaBsCedN[4N]与-b分as层edC[5]、NBNE[8]R等T多-B个iG基RU线-模bas型ed进[6]、行LD对A比-B,i从GR前U-5 结果准确度(P@5) 、平均精度均值(MAP) 、平均倒数排名(MRR) 、精确率(Precision) 、召回率(Recall) 、F1得分(F1-score) 六个指标对事件分拨模型性能做出评价。
2.3 对比实验与分析
与基线模型的对比实验结果如表1所示,由表2 中数据可以得知,相较于LDA-BiGRU这类直接基于事件描述文本信息进行分拨的方法,本文所描述的方法在Precision、Recall、F1-score等事件分拨评价指标上有4%~5%的提升,而在P@5、MAP、MRR等事件分类结果评价指标上有2%~3%的提升,对这一结果的一个解释是:基于LDA-BiGRU、分层CNN等方法能从事件描述文本中提取关键信息,但是由于关键信息的距离问题,模型的整体预测效果会受到这类距离差异的影响。本文模型中通过文本图的方式更有效地建立关键信息之间的关联关系,能在对事件描述文本进行编码时,更有效地利用这些关键信息,进而取得了较好的模型效果。
而对比ABCNN-based、BERT-BiGRU-based等包含有结果重排序方法的模型,本文模型在事件分拨指标上有大约3%的提升,而在事件分类结果评价指标上存在持平或有一定程度提升的情况。对这种结果的一个解释是:通过预训练语言模型与结果重排序等方法能对事件描述文本和额外的先验知识中的关键信息做出一定程度的提取,但是僅提取关键信息的方法难以关注到“事件-‘三定-部门”之间的关联关系,而通过键值对网络的方式,可以对这类关联关系做出更有效的捕捉,从而提升模型整体的分拨效果。
3 结论
本文设计了一种基于文本图与键值对记忆网络的事件分拨方法,通过联合事件分类与事件分拨两个任务,并引入“三定”这类先验知识信息,通过信息传播机制,对事件描述文本中的关键信息建立更有效的关联关系,并基于此提高对文本描述信息中潜在的关键信息的利用效率。同时,使用基于键值对的记忆网络结构,以“三定”职能描述为桥梁,提升事件分拨任务的颗粒度,进一步挖掘“三定”职能描述与事件描述之间的关联关系,从而提升模型的整体效果。经过与多个基线模型的对比结果,也进一步证明了本文模型提升效果的有效性。
