基于像素分配的文本检测方法研究
2023-08-03吉训生徐晓祥
吉训生,喻 智,徐晓祥
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.无锡市创凯电气控制设备有限公司,江苏 无锡 214400)
0 引言
场景文本检测在产品搜索、在线教育、即时翻译和电路板字符检测等有着广泛的应用,受到学术界和工业界的广泛关注。由于前景文本和背景物体差异很大,并且文本在形状、颜色、字体、方向和比例等方面也存在变化的多样性,文本检测仍然是一项具有挑战性的任务。传统方法中的特征都是人为设计的[1-2],需要大量的先验知识,且模型的鲁棒性差。基于回归[4-9]和分割[10-13]的深度学习的文本检测方法可以学习有效的特征来检测文本。文献[4]扩展了SSD (single shot MultiBox detector)算法[3]以解决不规则文本框呈现的不同长宽比的问题,通过修改卷积内核和锚框的大小来有效地捕获各种文本形状。文献[5]在Faster R-CNN[6](Faster Regions with CNN)引入RoI-Pooling(regions of interest pooling),以检测任意方向的场景文本。文献[7]使用全卷积网络FCN(fully convolutional networks)[8]直接预测像素级的四边形框,而不需要文本候选框和预设锚点。文献[9]提出了一种基于FCN的注意机制,从本质上抑制了特征图中的背景干扰,实现文本的精确检测。文献[10]先将文本区域当作若干组件,再将文本组件连接为文本区域以实现文本检测。文献[11]将文本实例与像素之间的连通性进行文本分割,再根据分割结果生成边界框。文献[12]设计文本中心线,通过文本中心线上多个圆环来预测任意形状文本区域。李敏等[14]先根据文本像素颜色进行聚类,再对文本检测。
为了提升网络性能,各种注意力模块广泛地应用于深度学习的中,文献 [15]计算特征图中各空间点之间的相关矩阵,利用非局部模块生成注意图,然后引导上下文信息聚合。文献[16]通过叠加两个交叉注意力模块,更有效地从所有像素中获取上下文信息,有效地增强了特征表示。文献[17]等提出SE(squeeze-and-excitation)模块,SE通过建模通道之间的相互依赖关系,利用网络的全局损失函数自适应地重新矫正通道之间的特征相应强度,实现各个通道的权重自动分配。文献[18]等为了解决通道注意和空间注意只能有效的捕获了局部信息,但不能捕获通道之间的长依赖关系的问题,提出一种有效利用不同尺度特征图中的空间信息的方法,在更细粒度水平上提取多尺度的空间信息。
在文本实例中两个字符间距很大或很小时,像素的预测比较模糊,容易产生误判。对于基于锚框的检测方法而言,待检测的文本长度未知,且文本行的长宽比也未知,无法确定锚框的尺寸,这一定程度上加大了检测的难度。不仅如此,由于缺乏全局上下文信息,在分割两个紧密相连的文本实例时,难以通过语义分割的方法来分离,对于长文本的检测又容易被切分成不同的文本实例。
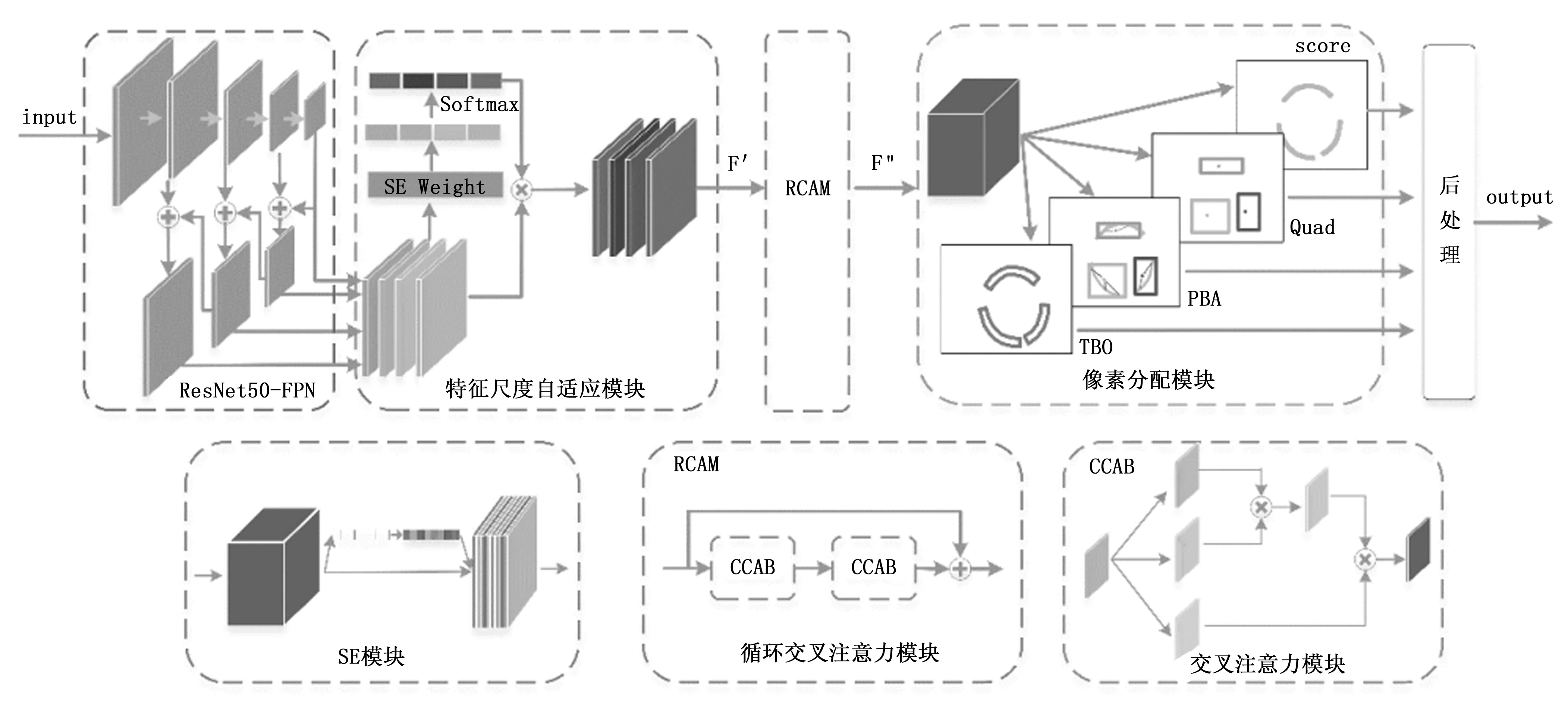
图1 网络结构图
为了解决上述问题,本文提出一种像素分配的场景文本检测方法,采用循环交叉注意力模块可以有效聚合上下文信息,像素到文本框的分配可以完成文本实例的检测。交叉注意力模块(CCAB,criss-cross attention block)收集每个像素所在的水平路径和垂直路径上的信息,进一步通过循环操作整合全图范围内的上下文信息。由于不同尺度的特征感受野不一样,进而侧重描述的信息也不同,为了得到更丰富的多尺度特征,对多尺度特征进行自动分配权重。本文使用FCN模型和多任务学习机制,将高级对象信息和低级像素信息进行整合,完成任意形状文本的检测。其中多任务学习包括文本中心区域得分(Score),像素到文本框的4个顶点的偏移(Quad),像素到文本框的分配(PBA,pixel to box assignment),像素到文本上下边界的偏移(TBO,text border offset)。结合Score的二值化图和Quad确定文本候选框,通过PBA可以有效地解决长文本被分割成不同文本实例片段以及相邻较近的文本实例无法区分的问题。在像素分配过程中,为了更有效地区分不同的文本实例所属的文本框,针对候选框外的像素添加一个惩罚来抑制其分配到文本候选框中,最后通过TBO细化多边形文本框,输出预测的文本框的多边形框。
1 交叉注意力和像素分配的文本检测方法
1.1 整体结构
本文所使用的深度学习的网络结构结构如图1所示,采用全卷积网络的多任务学习框架来重建文本区域的各种几何特性,通过循环CCAB模块聚合上下文信息,采用像素到文本框分配的方法完成文本实例分割。输入图像经过主干神经网络提取特征,本文的主干神经网络采用ResNet50-FPN结构,并采用多尺度自适应模块MFA(multi-scale feature adaptive module)来融合不同尺度的特征。融合特征F通过循环CCAB来整合像素的全局依赖性,以获取更具代表性的特征F″。在特征F″上多任务学习,获取Score、Quad、像素到PBA以及TBO,结合4个任务的结果后并经过后处理得到多边形文本框。通过Score和Quad先确定粗矩形框,PBA将相邻的矩形框内的像素分配到其对应的矩形框中,最后通过TBO对Score图中的像素进行上下边框的预测,根据每一个像素点到文本框的上下边界的距离来推导文本框。本文的方法是一种端到端的场景文本检测方法,输入场景文本图像,直接输出文本区域的文本框预测。
1.2 特征尺度自适应模块
不同尺度的特征具有不一样的感受野,它们所侧重描述了不同尺度的信息。对于视觉任务而言,有效地提取多尺度特征能够大大提升特征的表示能力。通道注意力机制自提出以来,被广泛应用到深度学习网络中,在视觉任务中其对网络性能的提升起到了不可忽视的作用。通道注意力机制允许网络有选择的对各个通道的重要性进行加权,从而有更多的信息输出。多数方法中采用了SE模块来对特征图的各个通道进行权重自动分配,但是SE模块只引入了通道注意力而忽略了全局的空间信息。为了丰富多尺度特征,本文采用多尺度特征自适应模块MFA来加强特征表示。如图1中主干神经网络ResNet50-FPN所示,ResNet50-FPN输出有4个尺度的特征,MFA模块将对这4个不同尺度的特征进行自适应融合。如图1中多尺度特征自适应模块所示,对每个尺度的特征采用SE模块提取不同尺度特征图的注意力,获取通道方向的注意力向量,通过softmax重新校准通道方向的注意力向量,获得多尺度通道的权重分配。将获取到的多尺度特征注意力向量逐个对多尺度特征进行加权。利用MFA模块获取到的多尺度特征信息更加细化。
1.3 循环交叉注意力模块
注意力模块广泛应用于各种任务中,本文采用循环交叉注意力模块更有效地获取上下文信息。将通过特征提取模块获取到的特征F输入交叉注意力模块中,生成新的特征图F′,将纵横路径中每个像素的上下文信息结合。如图2(a)中灰色路径所示,特征图F′仅在水平方向和垂直方向获取上下文信息,难以获得更加丰富和密集的上下文信息。因此,将特征图F′再次输入交错注意力模块,对于图2(a)中灰色路径上的所有像素的水平方向和垂直方向再次获取上下文信息,输出特征图F″。本文中的2个交叉注意力模块共享参数,只增加了一小部分计算开销,使得网络的性能更高。

图2 交叉注意力模块的信息示意图
交叉注意力模块如图3所示,特征图F∈C×H×W经过2个1*1的卷积运算分别得到Q∈C′×H×W和K∈C′×H×W,为了减少运算,本文中取C′=C/8。计算Q和K的相似性并获取到注意力图。

图3 交叉注意力模块细节图
A∈(H+W-1)×H×W。计算过程如式(1)所示:
di,u=QuKi,uT
(1)
其中:Qu∈C′是Q在空间维度上位置为u的像素向量,Ku∈(H+W-1)×C′是K在空间维度上位置为u的像素所在水平方向和竖直方向的像素向量,Ki,u∈C′是Ku的第i个元素,di,u是D∈(H+W-1)×H×W在空间维度上位置为u的第i个元素,对D∈(H+W-1)×H×W进行softmax运算得到注意力图A。
特征图F∈C×H×W经过1个1*1的卷积运算得到V∈C×H×W,将特征图V在注意力图A上聚集得到新的特征图F,计算过程如式(2)所示:
(2)
其中:Ai,u是注意力图A在空间维度上位置为u的第i个通道上的标量值,Vu∈(H+W-1)×C是特征图V在空间维度上位置为u的像素所在水平方向和垂直方向的像素向量,Vi,u∈C是Vu中的第i个元素,Fu∈C是F在空间维度上位置为u的像素向量,C是F′在空间维度上位置为u的像素向量。将获取到的上下文信息添加到原始的特征图F中,来聚合上下文信息以及增强特征的表示。交叉注意力模块的运算通过矩阵的运算来完成运算的加速。
1.4 像素分配
在本文中,通过在增强的特征F″上多任务训练来获取Score、QUAD、PBA和TBO,Score如图4所示,
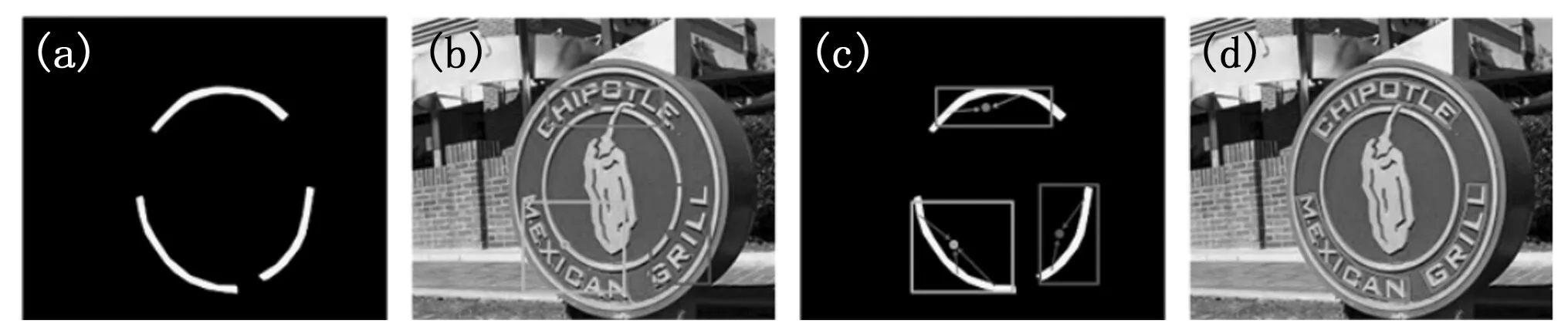
图4 多任务学习结果
再经过后处理得到文本的实例分割。将图像送入 FCN网络中,先获取Score和QUAD,其中Score是像素在[0,1]内的得分图,分数代表了该像素预测的几何形状的置信度,而Quad表示的是文本区域的像素到4个顶点的偏移量。Score只有1个通道,Quad中的矩形框有4个顶点以及每个顶点的偏移量包含水平偏移量和竖直偏移量,因此,Quad的输出包含8个通道。根据文本中心区域得分图和给定阈值进行二值化,以及几何输出Quad来获取四边形文本候选框,用NMS来抑制重叠的文本候选框,文本候选框如图4(b)所示。通过PAB将文本中心区域内的像素分配到对应的文本框中来区分不同的文本实例,如图4(c)所示。先计算四边形文本候选框的中心点位置,再根据像素到文本中心点预测的偏移量来分配到对应的文本框,像素的文本中心预测到候选框的中心有水平偏移量和垂直偏移量。
图4 多任务学习结果
像素到不同候选框的分配如图5所示,C1和C2分别表示不同文本候选框的中心点,像素P1和像素P2分别属于C1和C2的候选框,用一个向量来表示像素P2到文本框中心C1的预测,其中doff表示预测的中心到文本框中心C1的偏移量。为了更加有效地区别不是该文本框中的像素,针对文本框以外的像素添加一个惩罚,P2属于文本框C1外的像素,由于P2对文本框中心点C1的预测向量和文本框的边界有相交,定义P2到交点的距离dout作为惩罚以抑制像素P2对文本中心点C1的预测。本文方法结合高级的对象信息和底层的像素信息,可以有效地将文本中心区域中的像素分配到对应的文本候选框中,并且能够解决长文本实例在分割时被切割成多个不同文本实例的问题。惩罚dout可以很好地区分相邻较近的文本实例。

图5 像素分配示意图
通过TBO细化每一个文本实例的文本边界框,对文本中心区域的每个像素预测上下边界的偏移量重建文本实例的边界框。如图6所示,像素P到文本候选框的边界有水平偏移量和垂直偏移量,而边界有上下2个边界,因此TBO的预测输出有4个通道。

图6 像素到上下边界偏移量示意图
1.5 损失函数
本文的损失函数分为4个部分,分别是得分图损失Lscore,四边形回归损失Lquad,像素到文本中心偏移损失Lpba,文本到上下边界便宜损失Ltbo。多任务学习总损失L的计算如式(3)所示,
L=λ1Lscore+λ2Lquad+λ3Lpba+λ4Ltbo
(3)
其中:λ1,λ2,λ3,λ4用于权衡4个损失之间的重要性,本文中分别设置为1,1.5,1.5,1 。在多任务训练中Lscore为二分类损失,其他3个损失都是回归损失。
为了简化计算过程,文本使用EAST[7](efficient and accurate scene text)中介绍的得分图损失Lscore和四边形回归损失Lquad。采用类平衡交叉熵作为Lscore损失,Lscore计算如式(4)和 (5)所示,
(4)
(5)

本文的回归损失函数采用smoothedL1和Lquad,计算如式(6)和式(7)所示,
(6)
(7)
其中:CQ={x1,y1, ,x4,y4}是4个顶点的坐标值,NQ*为四边形中的最小边长,PQ*为不同顶点顺序的几何。本文规定点的顺序为左上角为第一个顶点,左下角为最后一个顶点,顶点按顺时针方向排列。而Lpba损失和Ltbo损失直接使用smoothedL1损失计算。
2 实验结果与分析
2.1 数据集介绍
本文主要采用Total-text[19]和ICDAR2015[20]两个公共数据集作为训练与测试数据集。Total-text是一个具有挑战性的任意形状文本检测数据集,它由1 255张训练图片和300张测试图片组成,这些图像具有多种不同的文本形态:水平、任意方向和弯曲形状,其文本实例的标签由字符级别的标注组成。ICDAR2015 是针对多方向文本检测的数据集,该数据集包括1 000 张训练图片和500 张测试图片,而且图像中的文本以英文和数字为主,这些图像的文本实例标签也是字符级别的标签。
2.2 标签的生成
数据集的标签采用14点标注,左上角的坐标为第一个点,按顺时针方向依次标注,左下角的坐标点为最后一个点。如图7(a)所示,文本区域的原始标签为外围橙色虚线框,本文中心区域为红色实线框,按0.5的缩减比例在原始签上缩减得到文本中心区域标签。如图7(b)所示,QUAD的标签为文本中心区域的像素点到四边形文本框的4个顶点的偏移,如图7(c)所示,在文本框内的像素点的PBA的标签为像素到四边形文本框中心的偏移,若像素在文本框外部时,需要额外加上惩罚dout。如图7(d)所示,TBO的标签为文本中心区域的像素到边界框的偏移,其中线段K1K2的斜率为线段P1P2斜率与线段P4P3斜率的平均值。通过线段K1P0与线段K1K2的长度之比,在线段P1P2上确定像素P0的上边界偏移点,同理可确定下边界偏移点。

图7 标签生成细节图
2.3 评价指标
本文实验中的评价指标主要是精确率Precision、召回率Recall 以及二者的综合评价F-measure,计算公式如式(8)~(10)所示,
(8)
(9)
(10)
其中:TP、FP、FN分别为混淆矩阵中的真阳值、 假阳值、假阴值。
2.4 消融实验
本次所有实验的训练和测试都是在同一配置下完成,CPU:Intel(R)Xeon(R)Gold 6 278C CPU @ 2.60 GHz*16,GPU:NVIDIA Tesla V100 16 GB,RAM:32G。本文实验的优化器使用Adam优化器,其中β1=0.9,β2=0.999,学习率为0.001,每个批次设置为12。为了提高模型在数据集上的性能,对数据进行随机缩放和随机旋转进行数据增强,最后将数据调整和填充到512*512的大小。
为了验证交叉注意力模块在网络中发挥的作用,在Total-text数据集上进行消融实验对比,为了保持单一控制变量原则,上述的参数设置均相同。在消融实验中R=0表示没有交叉注意力模块,R=1表示只有一个交叉注意力模块,R=2表示对交叉注意力模块进行2次循环操作,R=3表示对交叉注意力模块三次循环操作,实验结果如表1所示。

表1 Total-text数据集上交叉注意力模块的消融实验结果
根据表1可以看出,在加入交叉注意力模块后,精确率Precision和综合指标F-measure都有所提升。当R=1时的精确率Precision比没有交叉注意力模块的结果提高3.6%,F-measure指标提升了0.77%,表明了交叉注意力模块在横纵路径上聚合上下文信息。R=2时的精确率Precision提高6.23%,F-measure指标提升了1.37%。证明2个交叉注意力模块可以提取全图的上下文信息。R=3时的精确率Precision只提高了6.32%,F-measure指标提升了1.39%。同时,随着注意力模块的增加,网络的实时性有小幅度下降,且随着R的增加,FPS逐步减少。
为进一步验证交叉注意力的有效性在ICADR2015数据集上进行相同的消融实验对比,上述的参数设置同Total-text数据集保持一致。实验结果如表2所示。
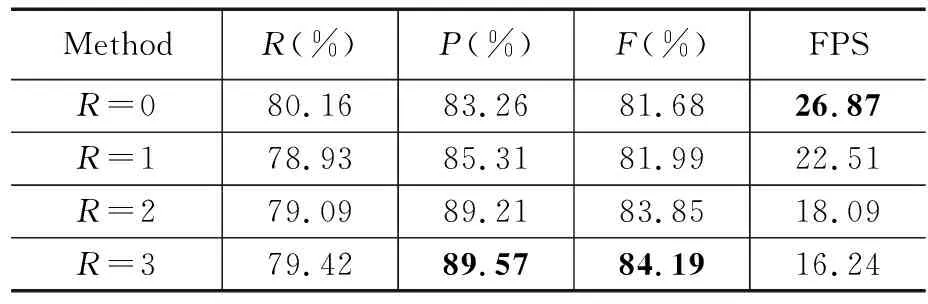
表2 ICADR2015数据集上交叉注意力模块的消融实验结果
在ICADR2015数据集上的交叉注意力模块的消融实验结果中精确率Precision和综合指标F-measure都有所提升。当R=1时的精确率Precision比没有交叉注意力模块的结果提高2.05%,F-measure指标提升了0.31%,表明了交叉注意力模块在横纵路径上聚合上下文信息的有效性。R=2时的精确率Precision提高5.95%,F-measure指标提升了2.17%。R=3时的精确率Precision提高了5.95%,F-measure指标提升了2.17%。将R=2与R=3进行对比,R=3时的精确率Precision只提高了0.36%,F-measure只提升了0.34%,但是网络每秒处理的帧数却减少了10.63 FPS。
在ICADR2015数据集和Total-text数据集上的交叉注意力模块消融实验可知,交叉注意力模块能够显著提升网络性能。当只有一个交叉注意力模块时只能聚合单一路径上的上下文信息,对网络的提升效果还能进一步加强。通过循环操作,将单一路径扩增到了横纵2个路径,根据实验结果显示,对交叉注意力模块进行2次循环操作,更进一步提升了网络性能。继续加入循环操作,虽然网络性能提升了,但是提升效果不明显,且随着循环操作的堆叠,网络的实时性下降严重,因此进行2次循环操作能够兼顾网络性能与网络的实时性。
2.5 对比实验
为了进一步验证本文方法的有效性,分别在Total-text和ICDAR2015数据集上对本文方法和近年出现的其他方法进行对比。实验结果如表3和4所示。从表3、表4中的实验结果表明,本文方法在弯曲文本数据集Total-text上取得了75.71%的召回率、89.15%的精确率和81.89%的F-measure值。
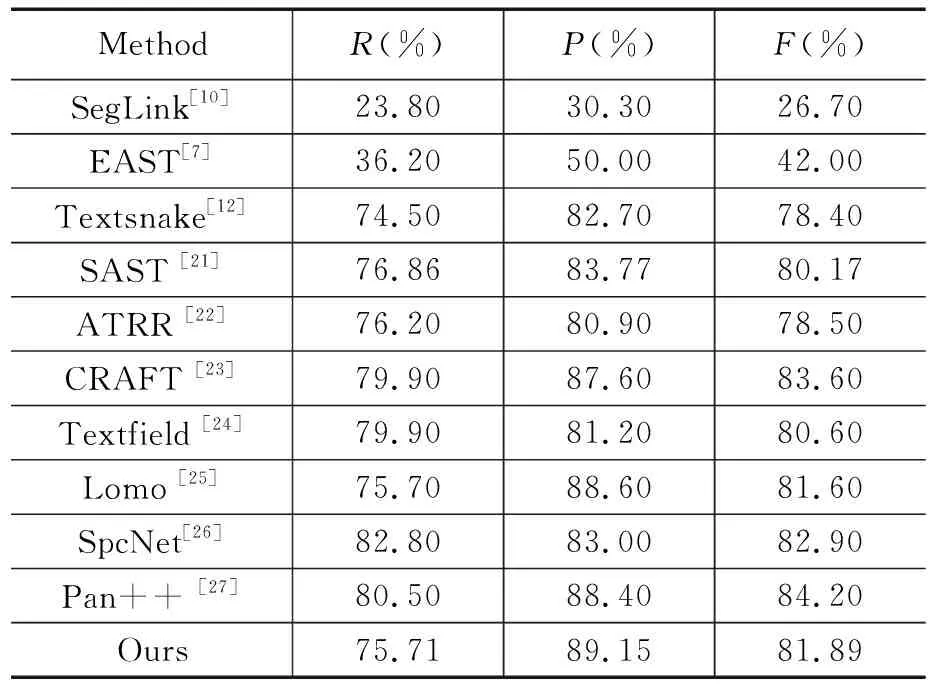
表3 不同算法在Total-text数据集上的比较
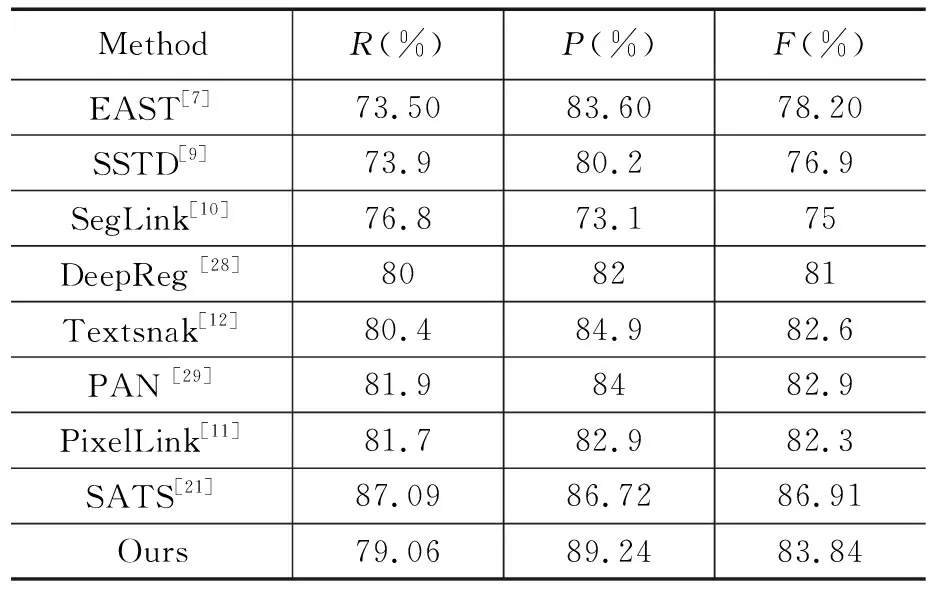
表4 不同算法在ICADR2015数据集上的比较
其中精确率相较其他算法提升较大。在多方向文本数据集ICADR2015上也取得了较好的结果,其中召回率,精确率,以及F1值分别为79.06%、89.24%、 83.84%。ICADR2015数据集与Total-text数据集的实验结果中精确率均在所有的对比实验中取得了最好的成绩。部分任意文本检测的实验结果可视化如图8所示,可以看出本文方法对包含密集文本、长文本以及相邻较近的文本的图像有较好的检测结果。

图8 部分实验结果图
3 结束语
本文提出一种基于像素分配的场景文本检测方法。该方法采用多任务学习机制对文本中心区域的分割,像素到文本框顶点的偏移,像素到文本框的分配和像素到上下边界的偏移4个任务进行训练,通过像素到文本框的分配,能够有效解决长文本被分割成不同文本实例和相邻很近的文本无法区分的问题。通过多尺度特征自适应分配权重,丰富了多尺度特征,结合交叉注意力模块,在空间和通道上细化了特征的表示,在ICADR2015数据集和Total-text数据集上进行实验,实验结果证明了本文方法的有效性。
