边缘计算环境下基于深度学习的DDos检测
2023-08-03虞延坤牛新征
田 婷,虞延坤,牛新征
(1.四川省公安科研中心,成都 610000;2.西南石油大学 计算机科学学院,成都 610500;3.电子科技大学 计算机科学与工程学院,成都 611731)
0 引言
随着物联网技术和云端理念愈发成熟,以往的云计算和雾计算不能满足日益增长的计算业务下沉需求,为了减小中心节点的计算压力并且更多地利用边缘节点的算力和存储资源,边缘计算架构应孕而生。边缘计算无限接近终端设备,能够实时地接收来自数据源头的信息,是一种解决计算、存储卸载问题的计算范式。它作为云计算的扩展,弥补了中心化后产生的一系列缺点,实现了高连续性和低时延性,更适合部署实时性高的智能化任务。随着边缘计算的应用部署,随之衍生出了与之相关的网络安全领域课题,其中针对边缘节点的攻击防御问题备受关注。分布式拒绝服务攻击(DDos)是一种隐蔽性高的大型分布式网络攻击,攻击者可以组建分布式僵尸网络向边缘节点发起洪水般的拒绝服务攻击。通常情况下,攻击者会伪造源IP,这使得攻击源头极具隐蔽性,检测攻击来源地址也变得极其困难。边缘计算环境下的物联网设备结构简单脆弱,往往难以防御DDos攻击,列举近期的一些典型DDos攻击案例,比如Mirai僵尸网络对KrebsOnSecurity的攻击[1]和Dyn攻击[2],大都产生了巨大的经济损失和安全威胁。由于物联网设施的连通性和开放性增加,整个物联网的受攻击面也因此扩展,使得DDos攻击的危害性也随之上升。边缘节点计算能力和存储空间受限且缺乏有效的安全保护,从而非常容易受到DDos攻击。
传统的防御和检测技术难以运用在边缘节点上,虽然边缘节点能够隔绝大部分来自于网络边缘的数据且能在第一时间检测到并拦截最近的DDos攻击,但是部署现有的集中式DDos检验方式或框架难以满足边缘节点的需求,这种解决方案通常没有考虑到边缘节点算力受限、存储空间小、网络波动大等特点。所以有必要设计一种基于边缘计算环境下的轻量级DDos攻击检测方案[3],以此来克服检测准确率低、误报率高、时延长、算力和存储能力不足等问题。
最近,网络安全领域也开始采用在图像、语言领域大放异彩的深度学习来解决一些棘手的安全问题,深度学习为解决DDos攻击的威胁提供了新思路。He等人[4]基于机器学习技术提出了云端服务器的DDos检测方法,He等人采用的方法分别有线性回归、支持向量机、决策树、朴素贝叶斯、随机森林、无监督K均值和高斯期望最大化等方法,每种方法都在一组自主生成的包含4种攻击的数据上进行测试并比较这些方法之间的得分,得分最高的是随机森林法,这些机器学习算法能大致满足DDos的检测要求,但是检测结果的指标得分并不高,存在较大的提高空间。R.C.Staudemeyer等人[5]尝试将网络流量异常检测领域和LSTM算法结合起来,实验结果表明LSTM具备良好的检测异常流量能力,证明了循环神经网络在流量分析领域具有极大的可研价值,但本文使用的数据集发布时间较早,缺少一些现代的DDos攻击类型,使得实验结果缺少说服力。Elyased等人[6]针对CIC-DDos-2019[7]数据集实现了一种基于深度学习的DDos检测方法,该方法由循环神经网络和自动编码器组成,经过一个数据预处理阶段后,在训练阶段得到一个二分类模型,以此判断网络流量是恶意攻击还是良性的。Can等人[8]增强了CIC-DDos-2019的不平衡数据集,使用了自动特征选择来解决数据集存在的不均衡问题。Ferrag等人[9]针对CIC-DDos-2019数据集使用深度学习的经典网络进行训练,但未针对性地做出结构优化。Chartuni A等人[10]针对CIC-DDos-2019数据集进行了预处理和标签处理,并基于DNN网络训练了一个DDos多分类器,为DDos的检测提供了一个可参考的范式。
1 模型设计
1.1 边缘计算环境下的DDos检测模型
本文结合一维卷积和BiLSTM等深度学习理论,设计了一种适合边缘计算环境下的轻量级DDos检测模型,通过剪枝操作得到最佳的模型结构。将网络流量数据送入三层一维卷积构成的卷积层以提取空间特征,随后展平送入BiLSTM层以提取时间特征,最后通过全连接层和Softmax层输出。本文提出的这种模型不仅可以有效提取和学习网络流量数据的空间特征和时间特征,且通过剪枝操作调整参数量从而对模型进行了轻量化处理。实验证明,本模型能够更好地在边缘计算环境中算力受限、存储空间受限情况下完成防御和检测DDos攻击的任务。该网络结构模型如图1所示。
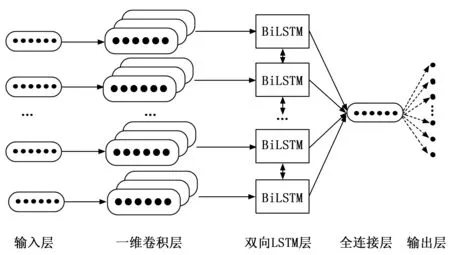
图1 网络结构模型
1.2 一维卷积层
卷积层是深度学习中用于提取局部特征的有效方法,一维卷积常用于处理序列数据[13]。网络流量数据的属性通常是序列化的数值串。对比常用的二维卷积,使用一维卷积进行特征提取后,实验准确率提到了有效提升,故本文没有采用常见的二维卷积法来提取特征。提取此类数据的局部特征图。一维卷积层效果更佳,将提取后的特征图作为下一层网络的输入,随着卷积层深度的增加,神经网络将学习到不同维度的特征。一维卷积运算公式如式(1)所示:
(1)
式(1)中,xj为第j个输入特征图,i为一维卷积的层数,kij为所使用的卷积核,*代表卷积运算且采用“same”填充方式,f()为激活函数,本文采用ReLU来进行非线性化处理,卷积层不填加偏置。
每个卷积激活层后接一个BN(batch normalization)层[16],通过BN层的处理,可以使该层的特征值符合标准正态分布,减小了训练过程中发生梯度相关问题(消失或爆炸)的可能性,加快了模型收敛的速度。BN层的运算公式如式(2)所示:
(2)

1.3 BiLSTM层
通过卷积层提取到网络流量数据的各维度特征图后,变换形状以适应性输入BiLSTM层。BiLSTM层[17](双向长短时记忆层)是一种特殊的循环神经网络结构,相比一般的RNN,它能够兼顾在前向和后向两个方向输入的网络流量数据信息,此种双向信息收集的性质极大地加强了全局性,使它能对数据的时间特征进行有效的提取。BiLSTM模型的网络体系结构如图2所示。

图2 BiLSTM网络体系结构
BiLSTM单元设置有输入门i、遗忘门f和输出门o,当前时刻数据xt进入时,结合内部存储单元ct-1和输出ht-1进行计算得出当前输出ht,然后及时更新内部存储单元ct[18]。遗忘门的运算公式如式(3)所示:
ft=sigmoid(Wxfxt+Whfht-1+bf)
(3)

(4)
it=sigmoid(Wxixt+Whiht-1+bt)
(5)
(6)
i用于筛选当前单元状态的数量,可以表示为式(7):
ot=sigmoid(Wxoxt+Whoht-1+bo)
(7)

(8)
(9)
(10)
x代表输入,W代表单元之间的连接权重,b是偏置向量,“·”代表点积运算。
1.4 Softmax层
数据经过BiLSTM后,进入全连接层和Softmax层。该层是一种多分类器,表达式如式(11)所示:
(11)
该层能转化实数范围内的分类结果数值,然后通过交叉熵损失函数来评测本文模型的检测结果。
2 实验结果与分析
2.1 数据集的选择
为了更真实地模拟边缘计算场景下遭受DDos攻击下的网络流量数据,本文调研了多个不同场景下的数据集,最后筛选出3个数据集来源:NSL-KDD数据集[12],由加拿大网络安全研究所(CIC)公开提供的CIC-IDS-2017数据集[11]和CIC-DDos-2019数据集[7]。
3个数据集的内容都是针对被攻击情况下捕获的完整的网络流量信息,数据量充足,适合进行深度学习模型训练。但是NSL-KDD数据集缺乏NTP、TFTP和NetBIOS等现代DDos攻击方式,且训练集和测试集的攻击种类不相等。CIC-IDS-2017数据集加入了以往数据集缺乏现代攻击方式,其中包含DDos攻击,但是并没有针对DDos攻击进行细粒度划分,该数据集主要包含漏洞Web攻击,且存在类别不均衡的问题。基于对所研究数据集的评估和分析,本文决定使用CIC-DDos-2019数据集对所用模型进行训练和验证。
CIC-DDos-2019数据集的内容是由CIC机构在两天内不同时间段采用不同的DDos攻击方式进行攻击测试,数据集中的部分时段加入了网络受限和网络波动等干扰因素,能够更贴近边缘计算环境下的网络流量数据,记录整理得出的具体分类如图3所示[7]。该数据集针对性地克服了过往数据集的缺点,提出了一种新的 DDoS 攻击分类法[7],主要分为两个主类:基于反射的DDos攻击和基于漏洞利用的DDos攻击。
1)基于反射的DDos,指的是那些利用合法的第三方组件且执行过程中隐藏攻击者身份的攻击。攻击者伪装IP地址,使用反射服务器发送响应数据包,使被攻击者发生过载。在该数据集中根据使用协议,进一步细分为了基于TCP的攻击包括MSSQL、SSDP,基于UDP的攻击包括CharGen、NTP、TFTP,以及使用TCP或UDP的攻击包括DNS、LDAP、NETBIOS和SNMP。
2)基于漏洞利用的DDos攻击,与基于反射的DDos攻击相似,不同点在于这些攻击可以通过使用传输层协议的应用层协议进行。具体可细分为基于TCP的攻击SYN Flood,基于UDP的攻击包括UDP Flood和UDP Lag。
图3 CIC-DDos-2019数据集中的DDos攻击分类
2.2 数据集的预处理
原始的CIC-DDos-2019数据集中存在NaN值和Infinite值不利于模型的训练,因此在合并了所有CSV文件后需要清理脏数据。因为数据量较大,所以本文将包含NaN和Infinite的数据作为脏数据整行删除。
目前数据集中存在87种属性,属性中存在两个名为“Fwd Header Length.1”的冗余属性,一列名为“Unnamed”的匿名属性以及“Source Port”、“Destination Port”、“Source IP”、“Destination IP”、“Flow ID”、“Timestamp”、“SimilarHTTP”等不能用于分类的套接字属性都进行舍弃以减少实验数据的特征维数。实际场景中IP地址等属性真实性很低,而且,使用套接字信息训练模型,会使模型依赖于使用套接字信息来分类,导致过拟合问题。最后本文保留了78种属性。
针对属性值存在分布不均匀、分布区间过大等问题,预处理需要对数据进行归一化处理。针对每一列数据(即每一种特征)进行L2范数归一化,L2归一化的公式如式(13)所示:
(12)
特征值归一化后,对数据进行分位数映射处理,该方法变换每条数据的属性值,使属性值映射到正态分布。服从正态分布的属性值能有效缩短训练收敛时间。
接下来,分析数据集中攻击类型的分布情况,结果如图4所示。结果显示,数据集存在类别不均衡的情况:TFTP类别在数据集中占比很高而Portmap、良性和UDPLag占比极少。这会导致模型训练出现长尾效应,使分类结果偏向数量多的那些类,训练得到的模型对少数类不敏感,分类能力差。因此,对TFTP稠密类进行下采样操作,以均衡其对整体模型的影响力;使用过采样技术SMOTE[19-20]生成稀疏类的合成数据,以增强稀疏类数据对整体模型的影响力。这一系列操作均有利于数据集实现类平衡。

图4 攻击标签分布图
SMOTE算法是由Bowyer等人[19]提出一种通过生成合成数据来实现类平衡的方法。SMOTE在特征空间进行采样生成合成数据,所以生成数据的真实性高于传统采样方法。SMOTE算法的内容为:针对少数类中的每一个样本s求到同类样本的欧式距离,得到该少数类的K近邻。合成数据so是由样本s和最近邻sn的距离差值,并将差值乘以一个0到1范围内的随机数r,最后添加到s的向量中生成的。SMOTE算法公式[19-20]如式(12)所示:
SS=S+r×(S-Sn)
(13)
采样操作后,包括所有攻击类型以及良性在内的13个类的数据数量达到平衡,平衡的数据集能够有效地避免训练过程产生长尾效应,以此增加模型对于数据数量少的类别的分类准确率。
本文在利用预处理后的数据集进行包括攻击和良性标签的13分类任务时,存在个别类混淆严重的情况。
攻击标签对应的数据由于攻击类型和攻击特征的相似性高,导致网络监控软件捕获到的信息总是具有相似性[7]。比如目前比较严重的泛洪攻击,其包括 DNS 泛洪攻击、UDP 泛洪攻击和 Syn 泛洪攻击共3种。因此数据集中对应的不同攻击种类的同一种属性的值也具有相似性,所以直接进行13分类容易产生标签的混淆,影响到模型的准确率。
统计12种攻击类型(不包含良性类)在属性空间中具有强相似性的类别的子集概要情况,结果如表1所示。

表1 强相似性标签的子集概要
表1中划分了4个子集,其他攻击标签保持独立,表中ACV是指具有恒定值的属性,AFR0表示零值高频的属性,ASAH指的是由于属性值具有很强的同质性而导致偏差的属性。因此将对应具有强相似性的子集进行标签融合操作。
对应的攻击标签融合成“DNS/LDAP/SNMP”、“NetBIOS/Portmap”、“SSDP/UDP”、“UDPLag/Syn”。标签融合后,存在8种包括各类DDos攻击和良性的类别。故实验过程可简化为进行一个DDos攻击下的网络流量八分类任务,此种情况作为实验场景一。
本文也将所有的攻击标签融合成“DDos”标签结合良性标签,进行一个DDos攻击下的网络流量二分类任务,此种情况作为实验场景二。
最后,数据集依次进行:数字编码和独热编码,该操作为每一类标签分配一个新列,如果该条记录属于这一类则为1,否则为0。
从预处理后的数据中按每种攻击以及良性等比例抽样提取数据,合成共200 000条训练数据的总数据集用作模型训练。
对总数据集进行8:2的划分得到训练集和测试集,训练集采取四折交叉验证的方式划分验证集,用来验证模型精度和调整模型超参数。
2.3 模型的评价指标
本文采用的模型评估指标为准确率、精确率、召回率和F1-score,并绘制混淆矩阵来分析每个类别的分类结果,公式如式(14)~(17)所示:

(14)

(15)
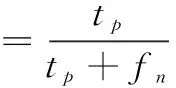
(16)
(17)
2.4 模型的参数
本文基于TensorFlow框架实现本文的DDos检测模型,将多分类交叉熵作为损失函数,实例化的优化器使用Adam[21]。
本文对比实验了各种结构,并对实验模型在保证实验准确率基础上针对不必要结构进行了剪枝操作,一是为了减少工作时延,二是为了便于网络移植到计算能力较弱的边缘节点上,将模型优化缩减为本文最终呈现的形式:其中一维卷积中输出滤波器的数量分别为20、40、60,卷积核的尺寸为4*1,填充方式为“same”;一维卷积后使用Relu作为激活函数,并接入BN层,构成复合一维卷积层结构。Bilstm层由一层输出空间的维数为80的BiLSTM模块接BN处理来担任时间特征提取任务。
本文利用粒子群优化算法进行超参数寻优实验,寻找到适合本模型的最佳超参数序列,学习率寻优曲线如图5所示。
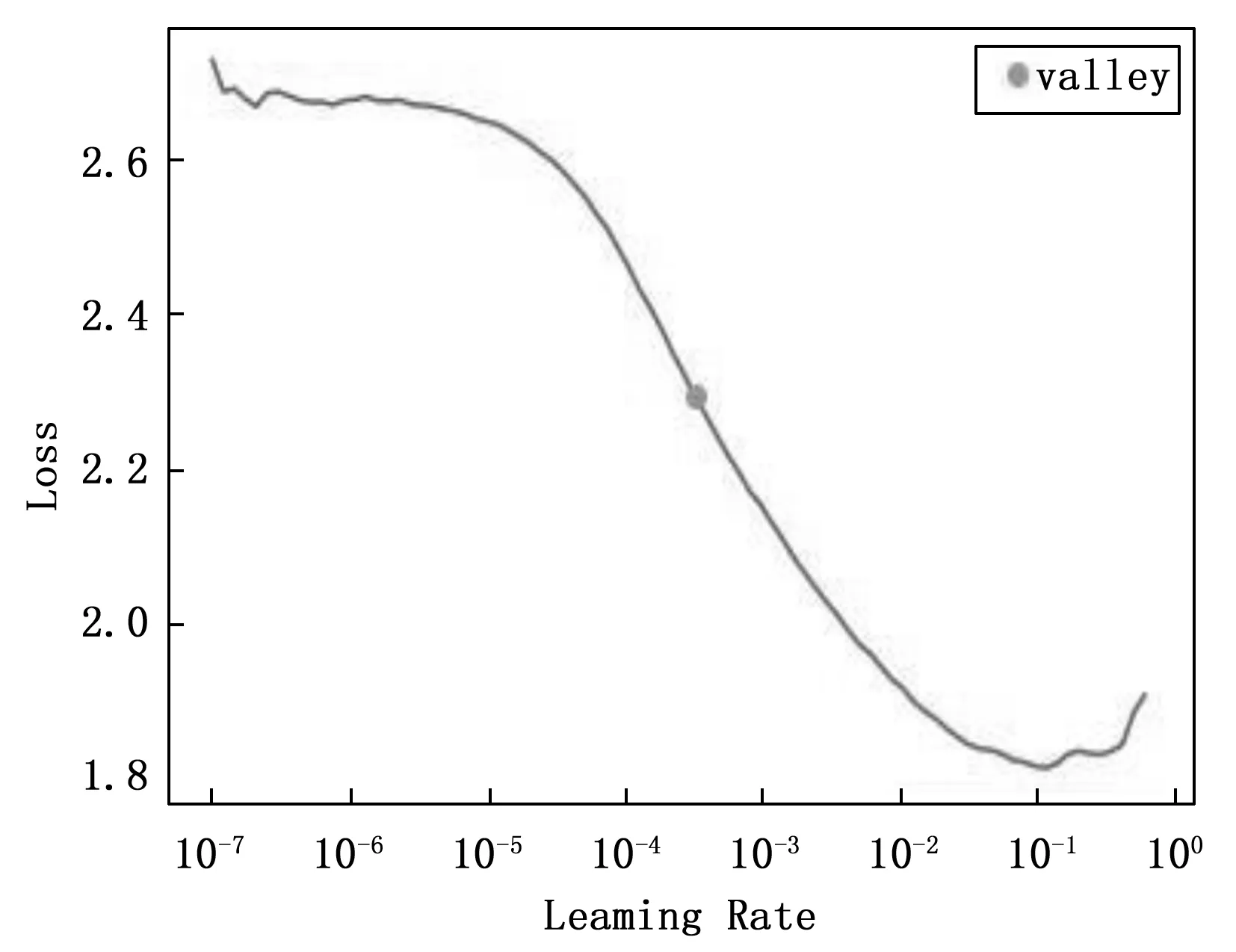
图5 学习率寻优曲线
当学习率为2×10-4,批大小为128,练轮数设置为100轮时模型的训练速度有效提升且提升了模型准确率,总结以上操作,列出参数列表如表2所示。

表2 模型的参数列表
2.5 实验结果
本实验的模型训练流程图整体描述如图6所示,实验整体流程可简化为:数据样本提取输入、数据预处理、模型搭建与初始化、模型训练、模型剪枝、模型指标评估、模型部署等步骤。

图6 模型训练流程图
在实验场景一中,通过模型训练得到一个能有效检测DDos攻击的模型,可以对包括攻击标签和良性标签的网络流量数据进行八分类,检测出可能正在遭受的DDos攻击。训练过程中,以训练轮数为横轴,损失和准确率的变化为纵轴,绘制折线图如图7所示,模型分类结果的指标参数如表3所示。

图7 损失变化曲线和准确率变化曲线

表3 实验场景一的分类结果
对每一类攻击标签的检测情况进行指标参数统计分析,结果如图11所示,模型对于MSSQL的检测能力相对较弱,分析可能是因为用于分辨MSSQL攻击类的特征属性较少,根据文献[7]显示,影响MSSQL检测的强相关属性为端口号,但端口号属性不能用于模型分类任务的训练中而进行了舍弃,故有所影响。
结果绘制混淆矩阵如图8所示。

图8 实验场景一混淆矩阵
混淆矩阵的分类结果显示,模型在分类MSSQL和DNS/LDAP/SNMP时发生了混淆,在分类UDPLag/Syn和SSDP/UDP时发生了混淆,针对发生混淆的两类可继续着手进行改进,进一步提高模型检测DDos攻击的准确率,其他类均表现良好,由于模型的参数量和计算量较小,对分类DDos攻击有良好的性能,故本文的模型适合部署在边缘计算环境下进行DDos攻击的检测任务。
在实验场景二中,通过模型训练得到一个能有效检测DDos攻击的模型,可以对DDos攻击标签和良性标签的网络流量数据进行二分类,检测出可能正在遭受的DDos攻击。实验场景二的检测结果的指标参数如表4所示。

表4 实验场景二分类结果
验证训练后模型的检测能力,据结果绘制混淆矩阵如图9所示。
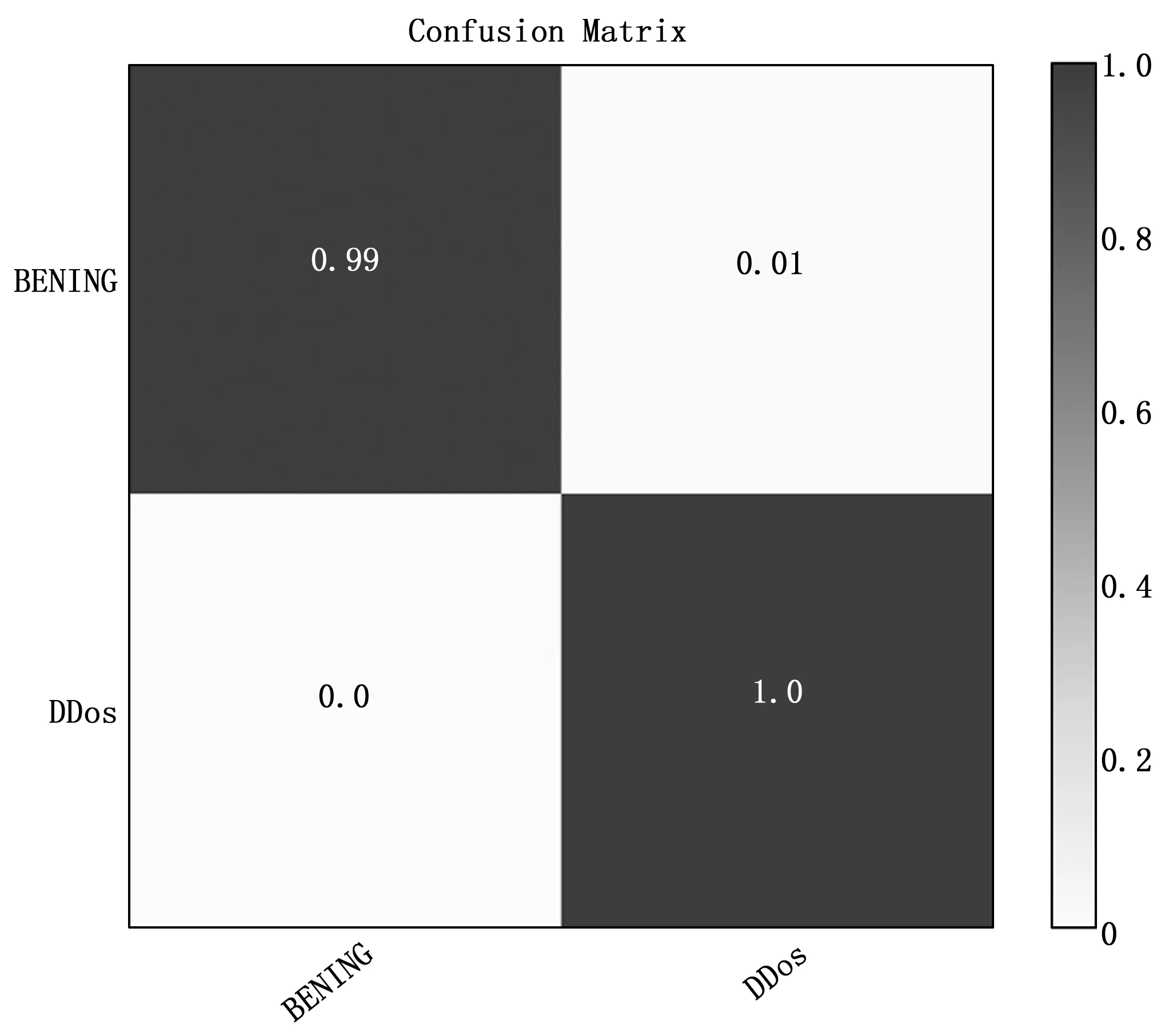
图9 实验场景二混淆矩阵
混淆矩阵的分类结果显示,模型对于DDos类和良性类有极佳的分类能力,本文的模型能够完美解决DDos和良性标签的网络流量二分类问题,由于模型的参数量和计算量相对较小且具备极佳的检测DDos攻击能力,表明这一模型适合部署在边缘计算环境下进行DDos检测任务。
对每一类攻击标签的检测情况进行指标参数统计分析,结果如图10所示,证明模型在实验场景二中具备优秀的检测能力。

图10 实验场景二分类情况统计图
将训练好的模型部署到边缘节点中,搜集节点中的网络流量数据,使用CICFlowMeter-V3插件来对流量数据进行量化提取,放入预处理阶段进行数据清理后,流量数据删除了脏数据且进行了特征降维,随后送入部署的训练模型进行实时DDos预测。

图11 实验场景一分类情况统计图
3 模型与相关工作对比
表5、表6展示了本文提出的模型在上述两种实验场景下的结果指标和其他相关工作的结果对比。

表5 实验场景一下本文与相关工作的结果比较

表6 实验场景二下本文与相关工作的结果比较
可以看出本文提出的模型在结果指标上明显优于相关工作提出的方法,本模型获得的指标提升应该归因于一个更适合的新模型框架,以及研究的预处理阶段和之前提出的标签融合。但是,本文的模型受到训练阶段使用的标签的限制,那么在实际部署后检测到新攻击带来的恶意网络流量时,如果新攻击的流量特征和之前学习到的攻击有相似,模型将会把其归类为DDos攻击,但会错误归类到已存在的攻击类型。为应对这一情况,可以在后续模型训练阶段增加新标签以定义新的攻击类型,此法可有效减少输出的模糊性。轻量化后的模型,其总参数量适当,能够适应边缘计算环境下边缘节点算力受限、存储受限的实际场景。
4 结束语
随着边缘计算的蓬勃发展,边缘计算环境下所面临的网络安全攻击危害也日益严重,DDos攻击作为边缘计算环境遭受的一种最主要的网络攻击带来了巨大的威胁。由于边缘计算环境下的边缘节点存在算力受限、储存受限的情况,传统的DDos防御和检测手段很难适应,所以,本文基于深度学习提出了一种检测模型,并对模型进行了剪枝轻量化,用以在该场景下防御DDos攻击。本文采用了CIC-DDos-2019[7]数据集来模拟遭受DDos攻击时的,存在网络波动大、条件受限情况下的网络流量数据。针对数据集存在脏数据、属性值区间大、类别不平衡等情况,通过实验提出了针对性强的数据预处理解决方案。对于数据标签存在强相似性使标签混淆的问题,本文对数据的属性进行了相似性分析,提出了一种针对性强的标签融合方案,得到了两种合理性强的实验场景。本文设计了一种基于Bilstm和一维卷积的模型结构,并通过剪枝操作实现了模型的轻量化,以此来达到在边缘计算环境下检测DDos攻击的目标,实验场景一进行DDos攻击八分类任务准确率达到了96.8%,实验场景二进行DDos攻击二分类任务准确率达到了99.8%。
未来的工作中,对于个别类还存在混淆情况,可以对数据属性进行更深入的分析或是调整模型框架来解决。本文的模型分类结果可解释性较差,后续可考虑增强可解释性。下一步将在实际边缘计算场景下训练和调整本文的模型,增加新攻击类型标签,降低可能存在的预测模糊性。
