基于多注意力和变分编码时序网络的发动机剩余使用寿命预测方法
2023-08-03杨凯旋赵书健魏佳隆苏本淦
杨凯旋,赵书健,魏佳隆,李 良,苏本淦,刘 扬,赵 振
(1.青岛科技大学 信息科学技术学院,山东 青岛 266061;2.青岛淄柴博洋柴油机股份有限公司,山东 青岛 266701)
关键字:剩余使用寿命;多注意力;变分编码;时序预测;深度学习
0 引言
预测与健康管理(PHM,prognostics and health management)可以根据各种传感器采集的监测数据提供机械系统的健康信息,并有助于制定合理的维修计划[1],确保机械系统可靠性和安全性。剩余使用寿命 (RUL,remaining useful life)估计是PHM的主要任务之一,准确地预测剩余使用寿命可为预知维护决策提供依据,减少冗余维护操作和成本,对于评估健康状态和避免灾难性故障[2]至关重要。
一般而言,RUL估计方法大致可以分为基于模型方法和数据驱动方法[3]。基于模型的方法利用机械系统的先验知识,建立数学模型来描述机械设备的退化过程,然后利用实时监测数据更新模型参数实现RUL估计。常见的基于模型的方法包括Wiener过程模型[4],Gamma模型[5],Weibull分布[6]等。然而,该类方法需要充分的先验知识来描述退化过程,但在复杂的系统中很难获得准确的失效信息。数据驱动的预测方法基于历史监测数据,与对应系统的健康状态之间建立一个非线性的映射关系。经典的数据驱动模型,如支持向量回归[7]、人工神经网络[8]、马尔科夫模型[9]等,主要包含人工特征设计和退化行为学习两个步骤。然而,这些方法需要过多的人工干预,且忽略了人工特征设计与退化行为学习之间的联系,从而限制了估计精度。
随着人工智能的快速发展,深度学习具有良好的非线性映射效果和自主的特征提取能力,可以通过多层连接从大量数据中提取高效的特征,已成功应用于许多领域。在RUL估计中,可以通过建立一种多层网络连接组合的模型,在已获取的原始数据序列上独立地学习层次化的特性,而无需人工设计特征。如深度神经网络(DNN,deep neural networks)[10]、深度置信网络(DBN,deep belief networks)[11]、卷积神经网络(CNN,convolutional neural networks)[12]、循环神经网络(RNN,recurrent neural network)[13]、长短时记忆网络(LSTM,long short term memory networks)[14]等,已被应用于RUL预测,并取得了较好的预测结果。但是现有深度学习方法通常假设不同传感器采集的监测数据对RUL估计的贡献相等。但实际上,不同时间步长的监测数据往往包含不同程度的退化信息,且它们对RUL预测的贡献是不等的。
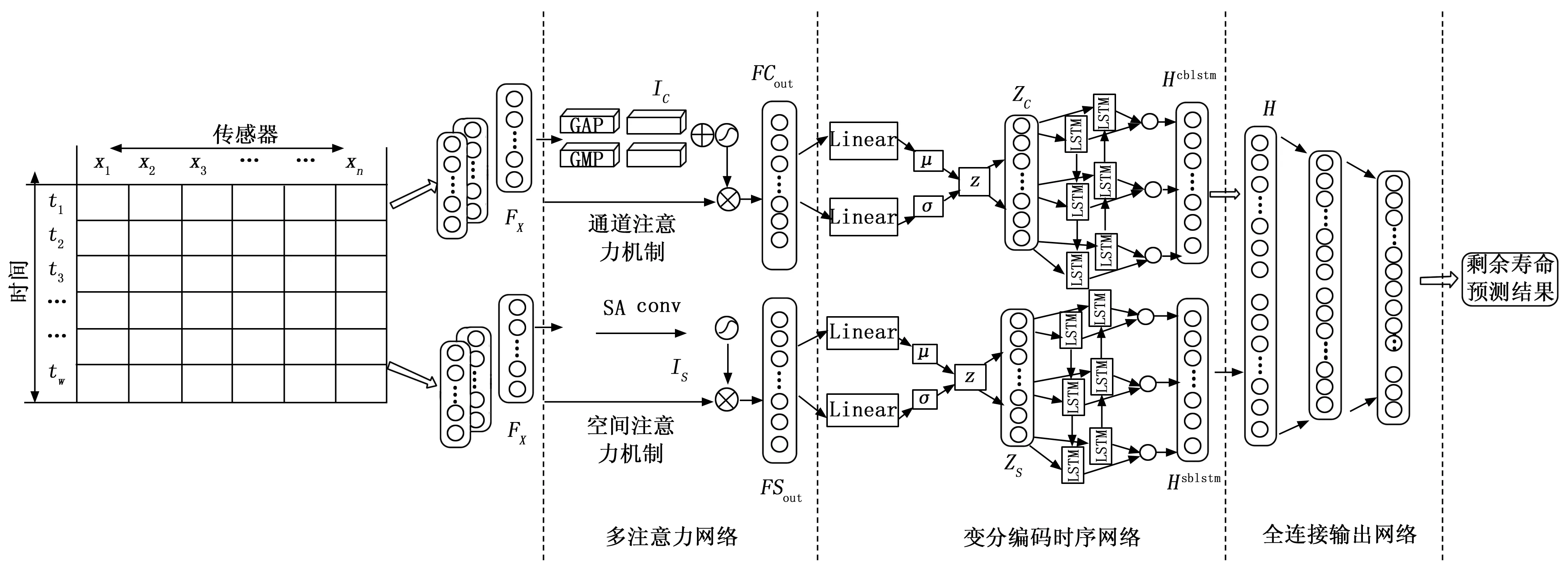
图1 MA-VBLSTM模型结构图
注意力机制广泛应用于各种任务中,例如机器翻译和视觉识别等,注意力机制通过计算不同特征的注意力概率,对模型中的不同特征赋予不同权重,有效地提高网络的表达能力。王欣等[15]使用长短时记忆神经网络提取序列特征,然后使用注意力网络学习不同时域蕴含的退化信息,以提高估计效果。赵志宏等[16]提出直接将原始振动信号输入双向长短期记忆网络(BiLSTM,bidirectional long short-term memory)提取特征,并使用注意力机制对特征分配不同的权重以提升预测精度。张加劲[17]采用卷积神经网络提取特征和双向长短期记忆网络获取特征中的长短期依赖关系,并使用注意力机制来突出特征中的重要部分,提高模型预测的准确率。但上述方法只是考虑运行数据随时间变化趋势蕴含着的退化信息,未考虑同一时间窗内多维时域指标数据蕴含的反映指标间关联性的空间信息以及同一时间窗内不同的时域指标数据对RUL预测的不同重要性,导致深度学习网络的预测结果不能更加精确。
为解决发动机退化数据中信息无法被充分发掘的问题,提出了一种融合多注意力(MA,multi-attention)和变分编码时序网络(VBLSTM,variational coding bidirectional long short-term memory networks)的剩余寿命预测方法。首先,空间注意力通过自注意力(SA,self-Attention)和卷积神经网络提取多维时域指标间的空间信息并分配注意力权重。通道注意力通过池化层和多层感知机赋予不同时域指标以不同的注意力权重,使模型高效的关注与剩余寿命关系密切的指标;然后,通过变分自编码器(VAE,variational auto-encoder)的潜在分布映射能力进行低维深度隐藏特征提取,再利用双向长短时记忆网络双向学习复杂的时间前后关联信息,捕获时间序列中长短期的时序特征;最终,通过全连接层融合通道维度时序特征和空间维度时序特征进行剩余使用寿命的预测。实验结果表明,提出的MA-VBLSTM模型在发动机CMAPSS数据集的FD001、FD002、FD003、FD004子数据集上RMSE 和Score值相比现有方法分别平均降低5.27%和10.70%、1.37%和1.68%、6.37%和26.94%、3.02%和2.06%。
1 MA-VBLSTM算法
如图1所示,本文提出的MA-VBLSTM模型由多注意力网络、变分编码时序网络和全连接输出网络组成。首先,通过标准化及数据分割等操作将原始发动机运行数据转化为网络的标准输入数据;然后,通过多注意力网络有效地进行输入数据中的空间特征和时间特征的权重配比,过滤或弱化冗余特征和抽取更加重要和关键的退化特征信息;然后,通过VAE建模两个复杂的条件概率密度函数输出服从一定分布的隐藏变量并使用BILSTM综合考虑序列信息的历史数据和未来数据进行有效地捕获时间序列中长距离相关特征。最后,通过多层全连接网络将加权后的空间时序特征和通道时序特征输出结果进行转换和整合,借助其非线性拟合能力将维度逐层降低到与输出标签一致后,输出整个模型的剩余寿命预测结果。
1.1 多注意力网络
发动机退化数据是高维度且复杂、大数据量、含有信息冗余的时序信息,其中的噪声和无关信号会影响剩余使用寿命预测的精准度[18],因此构建注意力模块突出输入数据中与设备退化关联性更大的特征,充分提取出与发动机故障的相关信息,进而输入到模型中进行剩余使用寿命预测。
为了挖掘出具有显著的退化特征数据和区分故障时刻的关键信息,本文所提的通道注意力机制对通道间信息关系进行建模,区分不同通道特征的重要性;空间注意力机制利用自注意力进行权重配比,结合卷积结构进行达到空间上的关键退化信息捕捉。
通道注意力:如图2所示,通道注意力通过压缩和聚合操作,对各通道的时间维度上下关系进行独立编码进而捕获关键的退化特征。
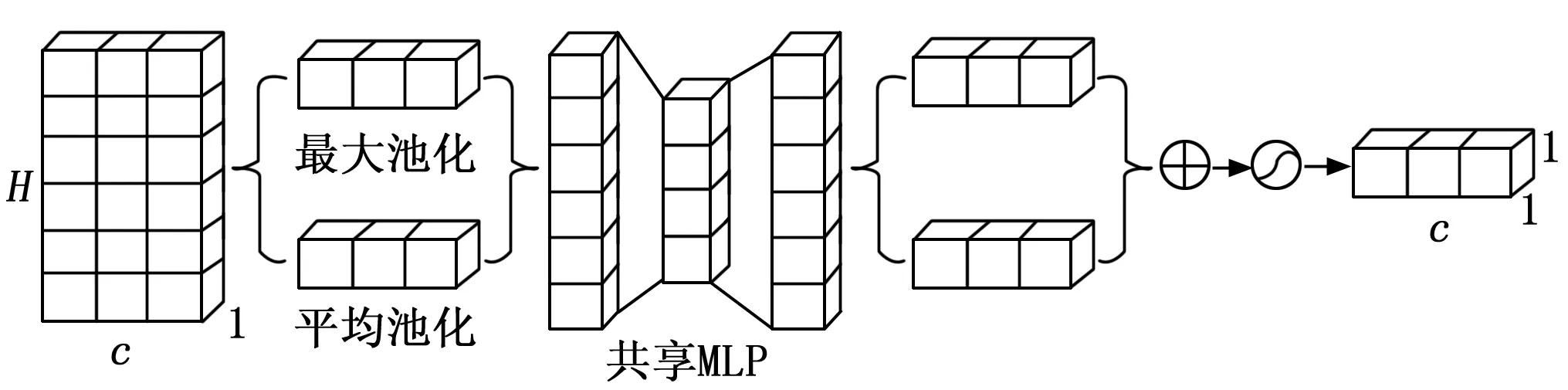
图2 通道注意力网络结构图
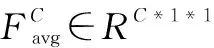
IC=fsm(W1(W0·GAP(Fx))+W1(W0·GMP(Fx)))=
(1)
式中,fsm为sigmoid函数,W0和W1∈RC*C为权重参数。最终,通道注意力的输出表示如下:
FCout=IC*Fx
(2)
空间注意力:如图3所示,空间注意力使用自注意力替代双池化的聚焦操作。相对比池化操作,自注意力机制具备全局的感受野,卷积结构经自注意力加权后的输出考虑了所有特征的信息,能够实现不同位置特征间的直接点乘融合、不受特征间距离的影响,从而得到更全局的特征提取效果。
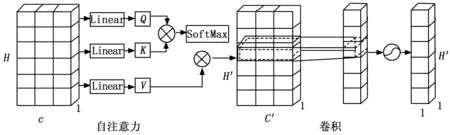
图3 空间注意力网络结构图
首先,将输入数据Fx分别通过3个线性层(Linear,linear layer),依次得到查询矩阵Q、键矩阵K和值矩阵V;随后,将将Q与K的转置相乘并除以缩放因子后经Softmax函数得到自注意力权重矩阵A;然后将V和自注意力权重矩阵A相乘,得到自注意力加权后的结果attn(Fx);然后,对attn(Fx)采用卷积核大小为7×1进行卷积计算生成空间特征描述符。最后,通过sigmoid函数处理获得空间特征权重Is∈R1*H*1。空间注意力的计算方法如下:
Is=fsm(conv7×1(attn·(Fx)))=
(3)
式中,fsm为sigmoid函数,dk是缩放因子,conv7×1表示与滤波器大小为7×1的卷积操作。最终,空间注意力的输出表示如下:
FSout=Is*Fx
(4)
1.2 变分编码时序网络
如图4所示,变分编码时序网络一方面结合VAE,通过变分推理学习机械设备健康状态的分布并映射到隐空间中,借助隐空间学习到的连续概率分布重建去干扰的深层低维高质量数据,另一方面通过引入BiLSTM对发动机运行数据建立时间序列的依赖关系,充分挖掘运行数据中的长短期时序特征,对运行工况、设备差异等因素引起的噪声具有一定的容忍性和鲁棒性[19]。
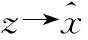
VAE基于输入数据不断训练编码器生成隐变量z的均值μ和标准差σ,结合标准正态分布随机采样参数ε,经过重采样生成z,见式(5)所示,避免了神经网络训练中反向梯度断裂的问题。
z=μ+ε*σ
(5)
VAE的损失函数有两个部分组成,公式如下:
(6)
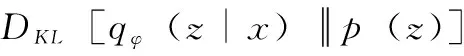

图5 VAE网络结构图
双向长短时记忆网络(BILSTM):长短时记忆网络是一种循环神经网络,更好的捕捉到较长距离的依赖关系,适用于处理时序数据。它的基本思路是引入了门控装置来处理记忆单元的记忆、遗忘、输入程度、输出程度的问题。通过训练,可以自主适应调整各个门的开启程度,并通过门控中神经网络参数控制信息的记忆。LSTM的计算公式为:
(7)
ft=fsm(Wz·[ht-1,zt]+bf)
(8)
(9)
(10)
式(7)~(10)分别为输入门、遗忘门、记忆门,以及输出门。Ct为LSTM细胞单元状态;zt和ht为细胞单元输入和隐藏层输出;fsm为sigmoid激活层,Wi,Wc,Wz,Wo表示属于不同门或状态的权重矩阵;bi,bc,bz,bo表示对应权重的偏置向量;⊗为2个矩阵对应元素逐个相乘方法。
如图6所示,BiLSTM是将结构相同但信息流方向相反的两个LSTM叠加而成。因此可以在前向和后向两个方向上处理序列,每个隐藏层在一个特定的时间步长可以同时获得过去(前向)和未来(后向)的信息,可以提取更全面的发动机退化特征,提高网络的预测性能。
将zt输入前向层,从0时刻到t时刻正向计算出向前隐含层的输出向量hf;输入至反向层,从t时刻到0时刻反向计算出向后隐含层的输出hb。最后,将前向层和反向层的输出结果输入至全连接层,得到最终输出h。
h=f(hf+hb)
(11)
式中,f(·)是全连接层的映射函数。
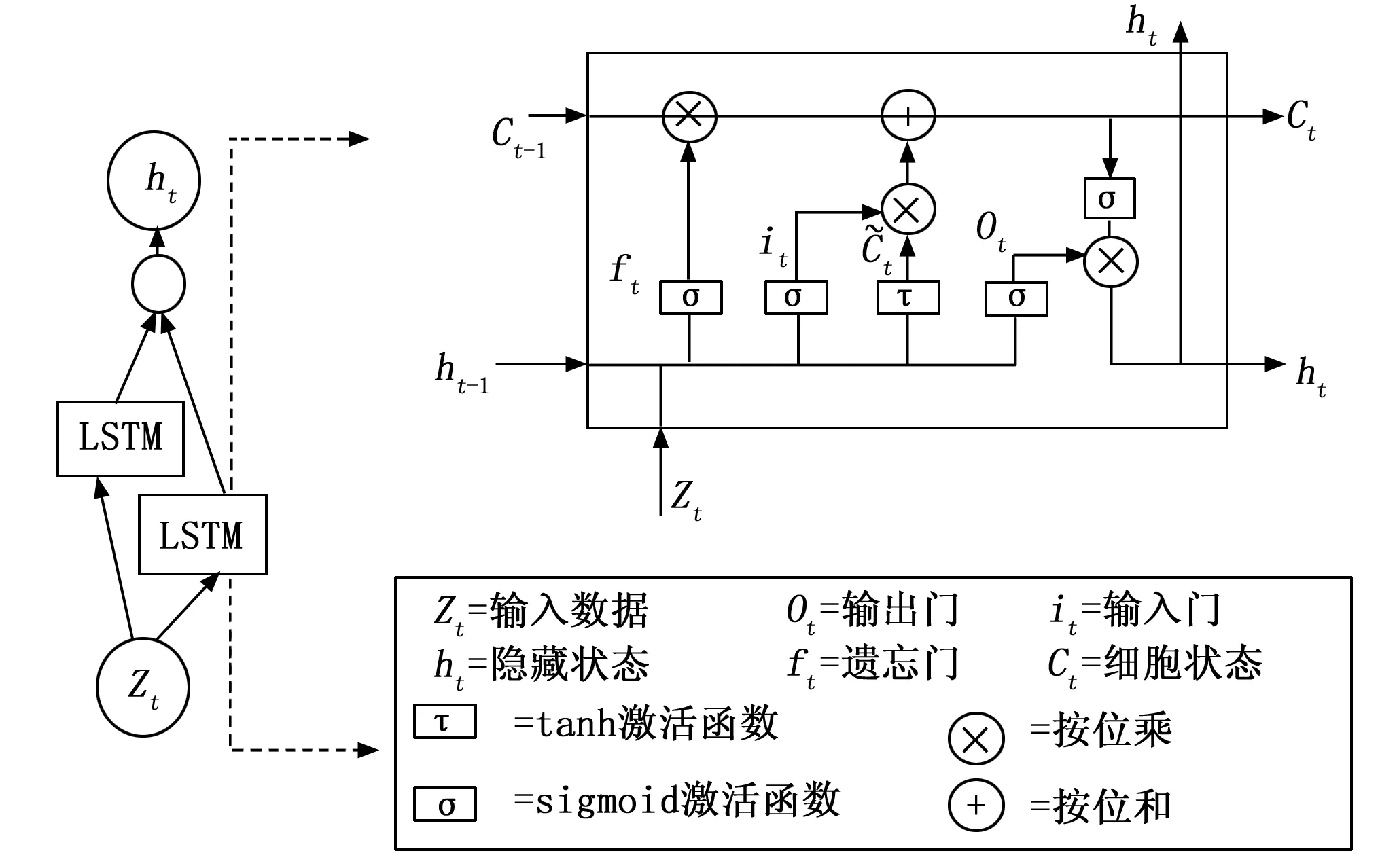
图6 BiLSTM网络结构图
1.3 全连接输出网络
全连接输出网络包含两个全连接层,全连接层的作用是把并行的变分编码时序网络得到的时间维度特征向量和空间维度进行重新展平组装拟合,并将其作为全连接层的输入,并通过ReLU激活函数实现设备剩余寿命的预测。
H=Concat(Hcblstm,Hsblstm)
(12)
y=fre(WrH+br)
(13)
式中,Hcblstm为通道时序输出特征向量;Hsblstm为空间时序输出特征向量fre为ReLU激活函数;Wr为权重矩阵;br为偏差参数。
2 实验设置
2.1 实验数据介绍
本研究使用的CMAPSS数据集是美国宇航局通过商用模块化航空航天推进系统仿真生成的涡扇发动机退化数据。它由4个子数据集组成,具有不同的故障模式和运行条件。每个子数据集包含若干个涡扇发动机退化数据,其中包括从涡扇发动机不同部件采集到的21个包含退化信息的传感器信号,如温度、压力、速度等,如表1所示。在本实验中,使用多台涡扇发动机从启动到故障的退化传感器数据的训练数据集对MA-VBLSTM模型进行离线训练。然后,采用退化数据的测试数据集实现在线RUL预测。
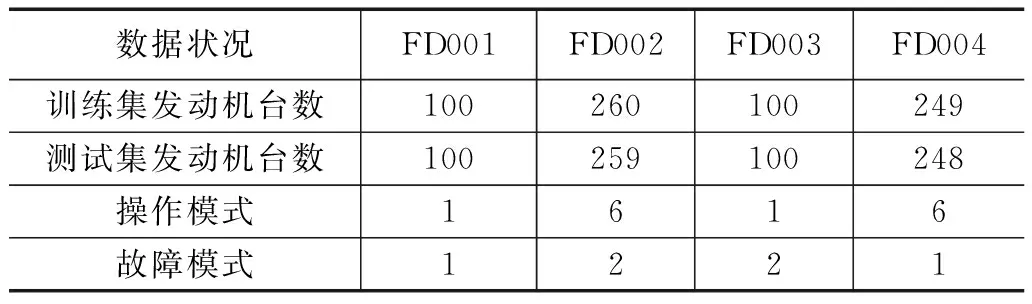
表1 航空发动机数据集
2.2 剩余使用寿命标注
发动机在工作初期运行状态良好,性能退化可忽略不计,但到工作末期,发动机的性能会随着时间大幅度降低。若发动机性能快速劣化,将运行数据的标签设定为总运行周期数和现运行周期数之差,会加大RUL预测结果的滞后性。
因此通常采用分段线性退化模型设置RUL标签,该方法在C-MAPSS数据集上已被验证是可行的[20]。在初始阶段,发动机稳定运行,RUL值保持不变,即为训练集的RUL标签设置阈值,而在退化阶段,RUL值线性下降。研究表明,将训练集RUL标签阈值设置为130个运行周期的预测效果较好,RUL标签设置结果如图7所示。
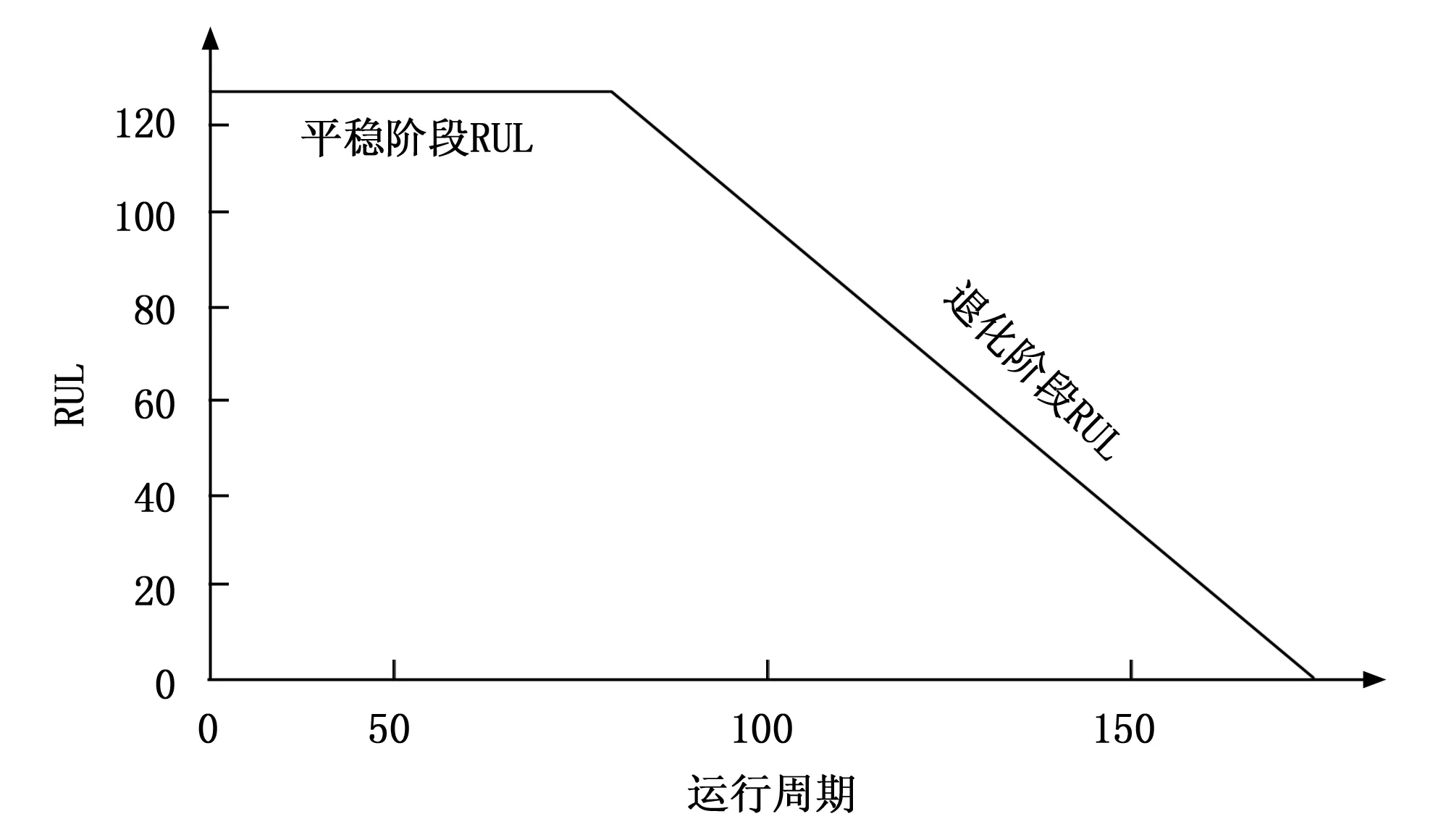
图7 RUL标签设置
2.3 数据增强
Mixup是基于邻域风险最小化(VRM,vicinal risk minimization)原则的数据增强方法,使用线性插值得到新样本数据,对离散样本空间进行连续化,提高邻域内的平滑性,提升深度学习模型的泛化性。
在邻域风险最小化原则下,根据特征向量线性插值将导致相关目标线性插值的先验知识,可得出简单且与数据无关的Mixup公式:
xn=λxi+(1-λ)xj
(14)
yn=λyi+(1-λ)yj
(15)
其中:xi,yi是从训练集中随机挑选的时序数据,xj,yj是对应的独热编码标签,通过先验知识确定特征向量的线性插值和对应目标的线性插值,插值生成新数据样本xn,yn。其中λ通过贝塔分布获得,取值范围介于0到1。该算法利用线性插值法,在一定程度上扩展了训练数据的分布空间,提高了模型的泛化性。
2.4 评价指标
本文采用RMSE(root mean square error)和非对称评分函数(score)两个指标客观地评价了所提出的MA-VBLSTM算法的估计性能。RMSE在回归任务中应用广泛,其定义如下:
(16)
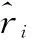
(17)
与RMSE一样,性能越好的RUL预测方法所产生的score分值越低。但与RMSE不同的是,score函数的早期预测的罚分函数和后期预测是不对称的,由于较晚的预测更有可能造成严重的灾难和重大的经济损失,需要比早期预测更严厉的惩罚。因此,评分函数会对较大的误差进行严厉的惩罚。
3 实验结果与讨论
在本节中,利用C-MAPSS数据集验证MA-VBLSTM方法的RUL预测准确性。首先,采用CMPASS数据集验证MA-VBLSTM方法有效性并分析预测结果。然后,设计对比实验分析多注意力机制和变分编码时序网络带来的预测效果提升。最后,将所提的MA-VBLSTM方法与现有RUL预测方法进行了比较。
3.1 模型预测与结果分析
为验证MA-VBLSTM方法可以更加充分地挖掘退化数据以提高RUL预测准确性的有效性,通过CMPASS数据进行MA-VBLSTM模型的训练并分析预测结果。CMPASS数据集的训练集和测试集记录了发动机在若干运行周期下3个操作设置值和21个传感器监测数据。为减少噪声提高计算的稳定性,剔除在发动机退化过程中从未变化的操作设置和传感器数据,使用有效的原始数据进行训练。在训练过程中,对原始训练集数据按8:2的比例划分训练集和验证集,并采用提前终止训练(early stooping)的正则化方法避免模型出现过拟合现象。将MA-VBLSTM方法训练得到的模型应用于测试集,测试集的预测结果如图8所示。
从FD001、FD002、FD003、FD004的测试集中分别选取64、11、71和37号测试样本,得到的样本预测结果如图9所示。可以观察到,在4个测试样本的早期阶段,因引擎开始运转初期时缺少历史数据支持,导致RUL估计偏差相对大,同时变化较为剧烈且具有显著的滞后性。但运行一段时间后,预测RUL逐渐收敛到了实际RUL左右,预测性能比在运行初期明显提升。由于在运行阶段的后期阶段是健康管理的重要时期,这个阶段对故障状况的正确判断能大大提高运行的可靠性和安全性程度,减少维修成本[22]。所以本文所提模型可以更充分地挖掘深度退化特征并具有较长时序特征的记忆能力,有效提升RUL预测精度。
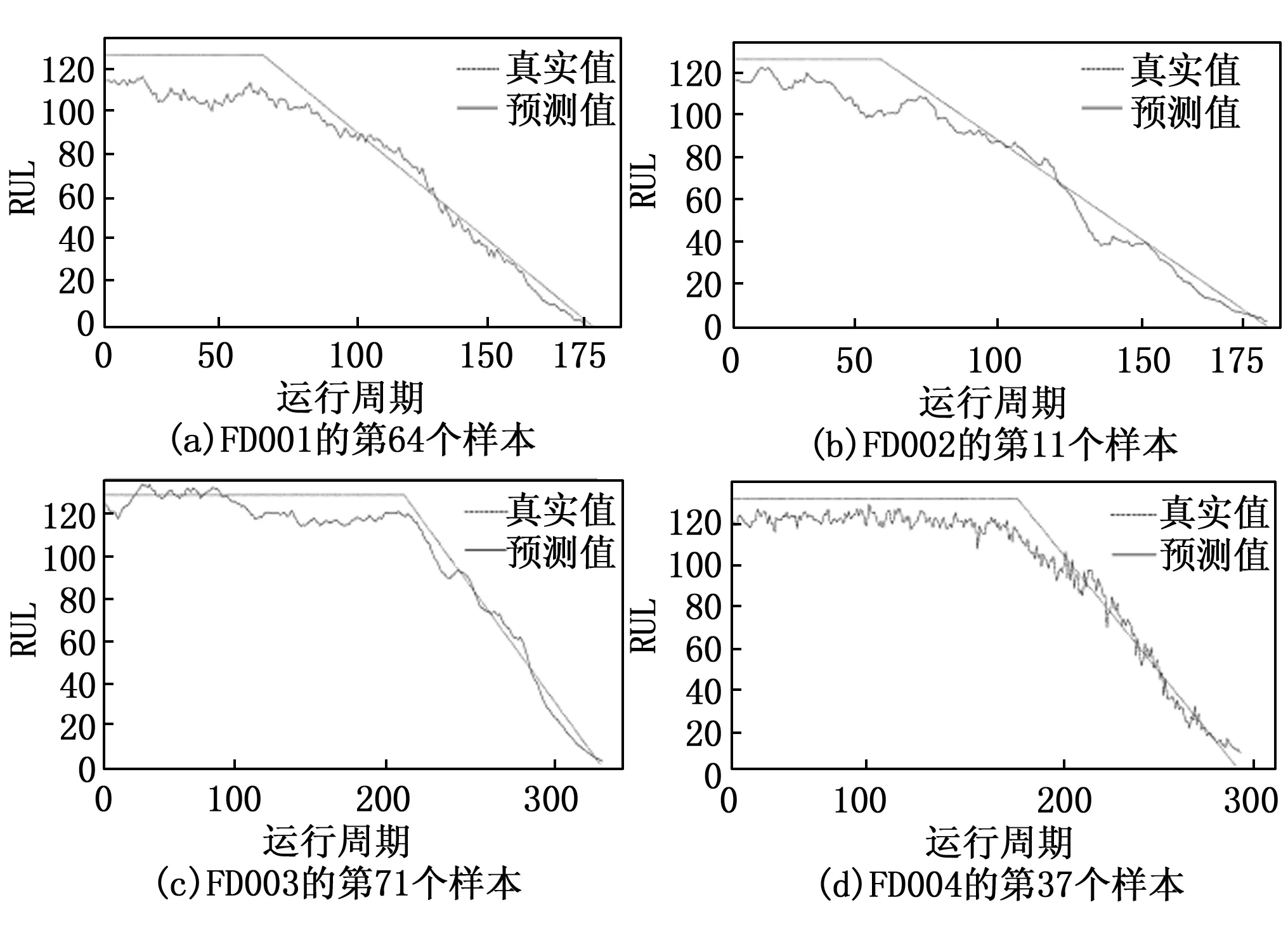
图9 单个引擎RUL预测结果
3.2 变分编码时序网络影响分析
本文利用VAE的编码器对数据进行编码并学习数据间深度隐藏的信息,输出编码优化处理的高效数据作为输入数据训练BiLSTM网络。为了验证VAE编码器降低训练阶段输入数据的过拟合性和解决数据特征丢失问题的有效性,在使用相同的CMPSS数据进行训练后,利用相同测试数据对MA-VBILSTM、MA-BLSTM网络(去除变分编码器)、MA-EBILSTM网络(使用自编码器代替变分编码器)进行对比测试。对比实验结果如表2所示,MA-VBILSTM方法与MA-BLSTM方法相比,分别在FD001、FD002、FD003、FD004数据集上RMSE和Score评估值降低5.43%和9.61%、8.02%和33.5%、8.69%和28.4%、9.41%和16.08%。与MA-EBLSTM方法相比,MA-VBILSTM方法分别在FD001、FD002、FD003、FD004数据集上RMSE和Score评估值降低6.73%和12.60%、0.53%和9.65%、2.84%和14.44%、5.48%和9.47%。因此本文所提方法MA-VBLSTM方法结合VAE将输入数据及各数据维度之间关联性映射到隐空间中,可以有效降低数据的过拟合性;同时引入BiLSTM网络双向提取数据的长短期时间依赖,有效地提升剩余寿命预测的准确率。
3.3 多注意力网络影响分析
为验证本文提出的基于多注意力机制从通道维度和空间维度中自适应选取性能退化关键特征的重要性。本节构建对比实验,以清楚地说明多注意力特征提取的优势:(1)仅通道特征作为输入的单流通道注意神经网络,记作CA-VBLSTM;(2)仅空间特征作为输入的单流空间注意神经网络,记作SA-VBLSTM。对比实验结果如表3所示,可以观察到本文所提出的MA-VBLSTM方法相比SA-VBLSTM方法在RMSE和Score评估值分别在FD001、FD002、FD003、FD004数据集上降低4.74%和11.9%、0.88%和21.9%、3.45%和10.79%、1.29%和14.06%。相比CA-VBLSTM方法,MA-VBLSTM方法在RMSE和Score评估值分别在FD001、FD002、FD003、FD004数据集上降低3.63%和5.57%、1.40%和18.8%、0.48%和6.06%、0.38%和1.94%。因此多注意力网络可在通道维度和空间维度分别进行重要退化特征提取,更好地在每个时间步长挖掘高维变量之间的空间相关性以及在所有时间步长上自适应挖掘与退化信号关联性更大的关键的特征,进而更加精准地预测发动机剩余使用寿命。
3.4 现有方法的对比实验
为了说明MA-VBLSTM网络的有效性和优越性,将本文方法与CNN[12]、LSTM[14]、基于注意力的LSTM模型(LSTM-A)[15]、基于注意力的BiLSTM模型(BiLSTM-A)[16]、基于注意力的CNN-GRU模型(AGCNN)[18]、基于注意力和残差卷积的BiLSTM模型(RCNN-ABiLSTM)[20]、时间卷积网络(TCN)[21]进行了对比。对比实验结果如表4所示,本文提出的MA-VBLSTM FD001、FD002、FD003、FD004子数据集上RMSE 和Score值相比现有方法分别平均降低5.27%和10.70%、1.37%和1.68%、6.37%和26.94%、3.02%和2.06%。因此本文提出的MA-VBLSTM方法的整体性能优于其他方法,利用多注意力机制自适应学习发动机运行数据存在的通道特征和空间特征,并对表现明显的退化特征数据和可区分故障时刻的关键信息进行动态加权,然后利用变分编码时序网络进行退化信息编码学习并强化全局上下时序特征的相关性,实现精准地反映健康趋势。

表2 变分编码对比结果

表3 双注意力并行对比实验
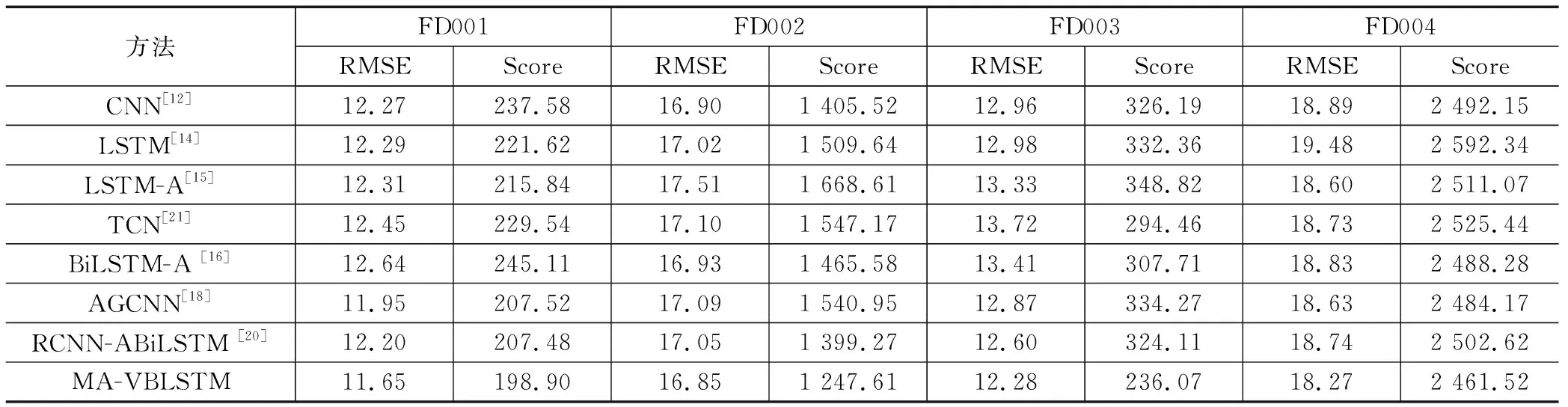
表4 现有方法对比实验结果
4 结束语
本文提出了一种融合多注意力和变分编码的时序网络进行设备剩余使用寿命预测。首先,使用通道注意力和空间注意力分别选取通道维度和空间维度的关键退化特征;然后,融合空间和通道特征学习的优势,通过自动编码器提取高维运行数据的深层低维特征,并利用BILSTM网络双向捕捉长短期的时序数据特征;最后,通过全连接输出网络进行双维度特征的融合并实现RUL估计。将所提出的MA-VBLSTM模型应用于C-MAPSS数据集,并将实验结果与多种主流方法进行对比,实验结果验证了所提出的MA-VBLSTM算法能够获得更准确的RUL估计。
在未来的研究中,RUL方法还可以考虑多种失效模式和复杂工况,以增强对更复杂问题的预测能力。此外,未来将进一步剖析机械系统的健康状态和退化状态的特征处理方式,这有助于获得复杂多变运行条件下运行数据的高效内部差异表示。
