基于深度动态密度估计的轴承异常检测*
2023-08-02刘华杰雷文平王军辉陈新财董辛旻
刘华杰,雷文平,王军辉,陈新财,董辛旻
(郑州大学机械与动力工程学院,郑州 450001)
0 引言
随着从工业过程中收集到的传感器数据越来越多,机械工业检测已经进入“大数据时代”,这些数据可被视为行业所用设备运行状态检查的关键资产[1]。滚动轴承是重要的工业机械基础件,根据统计由于滚动轴承故障引起的故障占40%~70%[2],因此开发出一种滚动轴承轴承异常检测算法具有重要意义。
人工智能算法作为强大的模式识别工具已经受到工业领域的广泛关注,如贝叶斯网络[3]用于铁路牵引系统故障检测,基于支持向量机[4]的方法用于石油工业故障检测,基于自动编码器和支持向量机(SVM)[5]的方法用于轴承故障诊断领域。普通的机器学习方法都是基于数据类平衡的假设,但在面对不平衡数据时模型它们的分类器有可能通过牺牲少数类来确保多数类的准确性[6]。由于在工业过程中系统通常在正常状态下运行,导致在实践中诊断系统收集到的一批数据中包含大量正常状态的轴承信号样本和少量的故障样本。因此,工业系统的异常检测任务可以建模为数据不平衡问题[3]。
异常检测表明原始信号的降维特征和重建误差对于异常检测均有重要作用[7-8]。ZONG等[9]提出的一种用于无监督异常检测的密度估计模型(DAGMM)提取原始信号的降维特征在并在高斯混合模型(GMM)[10]框架下学习正常数据低维表示的概率分布,以此来区分正常异常。这种方法表明只学习正常样本的模型应对不平衡数据集是有效的。
受到以上研究的启发,特别是针对于不平衡的工业数据,本文提出了一种基于深度动态密度估计的方法(DCEN)来解决轴承信号异常检测问题。模型整体分为压缩网络和估计网络两部分并采取端到端方式进行联合训练。压缩网络由编码器-解码器-编码器3个子网络组成,提取原始信号的低维特征和重构误差组合为低维表示。估计网络为多层神经网络,学习模拟原始信号的概率分布。在凯斯西储大学(CWRU)、江南大学(JNU)和帕德博恩大学(PU)的3个滚动轴承数据集上进行了实验,验证了该方法的有效性和可行性。根据对比实验结果本文所用方法具有优越的异常检测性能。
本文方法的主要特点如下:①针对工业领域中的轴承不平衡数据,提出了一种新的异常检测方法,为轴承异常检测提供了一种新的方案;②本文的网络模型只需要正常样本。在实际工业场景中,异常样本的数量往往不够,因此这是一个更具有现实意义的网络;③本文方法在3个公开的轴承数据集上均表现出具有竞争力的异常检测性能,验证了模型的有效性和泛化性。
1 密度估计异常检测模型
1.1 模型概述
本文的深度动态密度估计异常检测模型(DCEN)将深度自编码与高斯混合模型联合,由两部分组成,如图1所示模型由1个压缩子网络和1个估计子网络组成(deep compression network and estimation network,DCEN),该压缩网络通过深度自动编码器对输入样本进行降维,将降维特征和重建误差特征作为它们的低维表示,并将低维表示提供给后续的估计网络;该估计子网络根据每个数据样本的低维表示进行混合隶属度预测,并利用这些预测的隶属度值,在高斯混合模型框架内预测其能量值,最后根据能量值区分异常。

图1 模型框架
1.2 压缩网络
如图1所示,压缩网络为具有“编码器(Ce)-解码器(Cd)-编码器(Ce′)”3个子网络。给定一个样本X压缩网络为估计网络提供由原始输入的低维特征和重构误差组成的低维表示,并且在训练过程中为损失函数提供压缩损失。整个过程为:
步骤1:Ce由批次标准化层、全连接层和ReLU激活层组成。Ce将计算出X的低维特征Zc;
Zc=h(X;θe)
(1)
步骤2:Cd由批次标准化层、全连接层和ReLU激活层组成。Cd使用Zc来重建X′;
X′=g(Zc;θd)
(2)
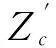
(3)
压缩网络提供的低维表示为:
Zr=f(X,X′)
(4)
Z=[Zc,Zr]
(5)
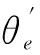
1.3 估计网络
估计网络对来自压缩网络的输出z进行密度估计。估计网络在训练阶段使用多层神经网络来预测每个样本的混合隶属度直接估计高斯混合模型(GMM)的参数,而无需采用GMM模型常用的期望最大化(EM)迭代算法。给定低维表示Z和整数k作为混合成分的数量,估计网络进行成员预测如下:
p=MLN(z;θm)
(6)
(7)

(8)
(9)
(10)

根据估计的参数,可以通过式(11)进一步推断样本能量。
(11)
在测试阶段模型具有学习之后的参数,可以直接估计样本能量,并样本能量高于阈值的样本标记为异常。
1.4 目标函数
在给定一个包含N个样本的数据集时,指导DCEN训练的目标函数构造如下:
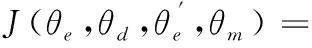
(12)
该目标函数包括3个部分。
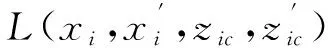
②E(zi)表示输入样本zi的能量。通过最小化样本能量,我们寻找压缩和估计网络的最佳组合。

2 实验设置
为了评估本文DCEN的可行性和有效性,在凯斯西储大学(CWRU)轴承数据集、江南大学(JNU)轴承数据集和帕德博恩大学(PU)轴承数据集上进行了对比试验。
2.1 数据集描述
凯斯西储大学(CWRU)数据集由凯斯西储大学轴承数据中心提供[11]。人为在滚动体(B)、内圈(IR)和外圈(OR)加工出损坏点作为故障轴承。以12 kHz或48 kHz在试验台上利用加速度传感器在驱动端、风扇端和基座上采集正常轴承和具有损坏点的轴承振动信号。
江南大学(JNU)数据集[12]由3个不同转速的轴承振动数据集组成,数据采样频率为50 kHz。如表1所示,JNU数据集包含一种健康状态(N)和3种故障模式,包括内圈故障(IR)、外圈故障(OR)和滚动体故障(B)。

表1 JNU数据集参数
帕德博恩大学(PU)数据集由帕德伯恩大学轴承数据中心提供[13]。数据中心人员通过实验台获取电流信号和采样频率为64 kHz的振动信号。数据集包含的轴承状态分为3类:①6个未损坏的轴承;②12个人为损坏的轴承;③14个轴承因加速寿命试验造成实际损坏。
2.2 数据集处理

在凯斯西储大学数据集上选取采样频率为12 kHz的信号作为实验样本。在正常运行条件下使用b=2531个正常样本作为训练集来训练模型。使用v=588和u=2598个无标签样本组成测试集。
在江南大学数据集上使用b=8788个正常样本作为训练集来训练模型。使用v=2198和u=10 926个无标签样本组成测试集。
在帕德博恩大学数据集上采用正常轴承振动数据和真实故障轴承振动数据。使用b=47 645个正常样本作为训练集来训练模型。使用v=11 912和u=59 609个无标签样本组成测试集。
2.3 实施细节
在实验中用于单个数据集的深度动态密度估计网络(DCEN)的结构总结如下。
凯斯西储大学(CWRU)数据集:对于该数据集,其压缩网络向估计网络提供34维输入,其中32个维度是降维特征,另两个维度来自重建误差。为获得最佳性能该估计网络采用了具有3个混合分量的GMM。具体而言,压缩网络以BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,128,relu)-BN(128)-FC(128,32,None)-BN(32)-FC(32,128,relu)-BN(128)-FC(128,256,relu)-BN(256)-FC(256,4096,None)-BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,128,relu)-BN(128)-FC(128,32,None)运行,并且估计网络以BN(34)-FC(34,100,tanh)-BN(100)-DP(0.5)-FC(10,3,softmax)执行。
江南大学(JNU)数据集:对于该数据集,其压缩网络向估计网络提供34维输入,其中32个维度是降维特征,另两个维度来自重建误差。为获得最佳性能该估计网络采用了具有3个混合分量的GMM。具体而言,压缩网络以BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,128,relu)-BN(128)-FC(128,32,None)-BN(32)-FC(32,128,relu)-BN(128)-FC(128,256,relu)-BN(256)-FC(256,4096,None)-BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,128,relu)-BN(128)-FC(128,32,None)运行,并且估计网络以BN(34)-FC(34,100,tanh)-BN(100)-FC(100,10,tanh)-BN(10)-DP(0.5)-FC(10,3,softmax)执行。
帕德博恩大学(PU)数据集:对于该数据集,其压缩网络向估计网络提供34维输入,其中32个维度是降维特征,另两个维度来自重建误差。为获得最佳性能该估计网络采用了具有6个混合分量的GMM。具体而言,压缩网络以BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,32,None)-BN(32)-FC(32,256,relu)-BN(256)-FC(256,4096,None)-BN(4096)-FC(4096,256,relu)-BN(256)-FC(256,32,None)运行,并且估计网络以BN(34)-FC(34,10,tanh)-BN(10)-DP(0.5)-FC(10,6,softmax)执行。
其中,FC(a,b,f)表示一个全连接结构,其中a输入神经元和b输出神经元由函数f激活(None表示不使用激活函数),BN(d)表示数据维度为d的批次标准化操作,DP(p)表示训练期间保持概率为p的丢弃层。
所有DCEN模型实例均由tensorflow2.5实现,并由Adam优化网络来优化算法训练。训练时学习率设置为0.000 1,λ1设置为0.1,将λ2设置为0.005。对于凯斯西储大学(CWRU)数据集、江南大学(JNU)数据集和帕德博恩大学(PU)数据集,epochs数分别为200,300和20。batch-size的大小,均设置为256。
本实验在3个不同数据源上将DCEN模型与具有径向基函数核(RBF)的一类支持向量机(OC-SVM)和局部离群因子(LOF)两种经典无监督异常检测方法进行比较。
3 实验
3.1 评价指标
在实验中DCEN模型计算训练集和测试集的异常分数,并将训练集样本异常分数降序排列并且以99.5%分位点的异常分数作为判别阈值。在测试集中异常得分大于阈值的将被认定为异常值。为了评判模型性能,采用准确率A(Accuracy)、精确率P(Precision),召回率R(Recall),和F1分数(F1_score)作为展示模型异常检测性能的指标。表达式为:
(13)
(14)
(15)
(16)
式中:TP是预测为正例的正例样本数,FN是预测为反例的正例样本数,FP是预测为正例的反例样本数,TN是预测为反例的反例样本数(本文测试阶段异常值为正例)。
3.2 实验结果
表2总结了深度动态密度估计异常检测模型(DCEN)、一类支持向量机(OC-SVM)和局部离群因子(LOF)模型分别在凯斯西储大学(CWRU)滚动轴承数据集、江南大学(JNU)轴承数据集和帕德博恩大学(PU)滚动轴承数据集上的结果(最优结果已加粗)。根据准确率(Accuracy)、精确率(Precision),召回率(Recall),和F1分数(F1_score)指标,3个模型在凯斯西储大学(CWRU)数据集上均有优秀的异常检测性能且性能差距不大,其中一类支持向量机(OC-SVM)在凯斯西储大学数据集上的表现(CWRU)是3个模型中最优的,但是在另外两个数据集上一类支持向量机(OC-SVM)和局部离群因子(LOF)模型的性能有着明显的下降。而深度动态密度估计异常检测模型(DCEN)在3个数据集上均表现出优秀的异常检测性能,召回率均达到100%。
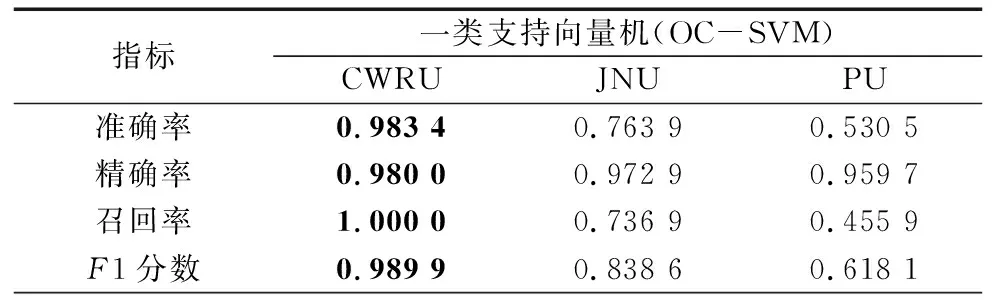
表2 实验结果对比

续表
3.3 模型分析
通过对比实验得到了深度动态密度估计模型(DCEN)在不同数据集的异常检测效果,验证了DCEN的有效性和更广泛的适用性。
为了进一步的分析模型特征提取能力,将正常数据和异常数据输入到训练之后的深度动态密度估计模型(DCEN)中,利用t-SNE算法对压缩网络提供的低维表示降维至三维空间进行分析。
图3~图5从不同角度展示了3个数据集中正常数据和异常数据(黑色:正常数据,灰色:异常数据)的低维表示经过t-SNE降维之后的可视化效果。可以看出正常数据和异常数据的低维表示具有不同的分布,说明经过训练,模型能够有效的提取出正常样本和异常样本的特征进而利用特征分布的不同进行异常检测。估计网络引入的正则化有助于深度自动编码器获得具备原始数据特征的低维表示,而压缩网络为密度估计网络提供更有意义的低维表示。
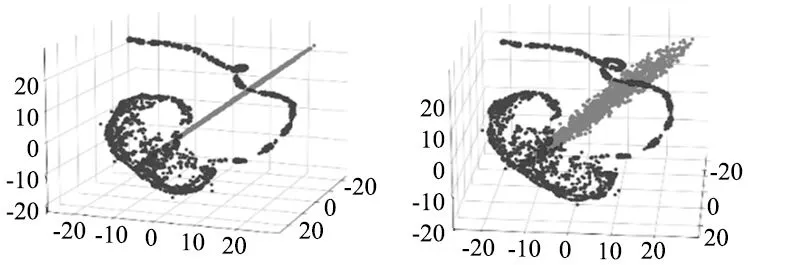
图3 凯斯西储大学数据集
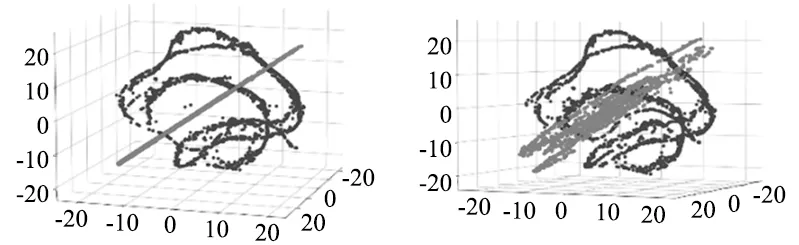
图4 江南大学数据集
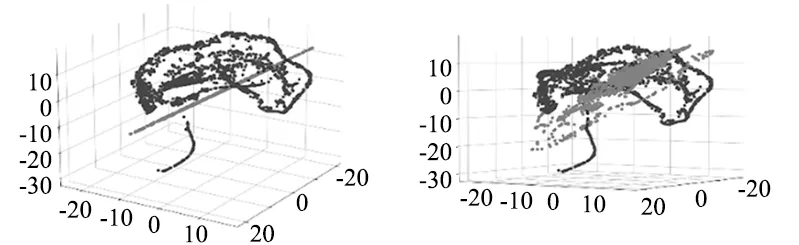
图5 帕德博恩大学数据集
4 结论
本文提出了一种基于深度动态密度估计的方法(DCEN)用于轴承信号异常检测,解决了在实际工程领域中数据样本不平衡的情况下,实现对异常信号样本高质量检测的问题,并得出以下结论:
(1)提出一种基于深度动态密度估计模型,融合深度自编码器的特征提取能力和GMM框架的密度估计能力,同时考虑原始输入的低维特征和重构误差,模拟正常数据的特征分布,实现轴承信号的异常检测。
(2)将提出的方法应用于不同的异常检测任务中,并与已有的传统的机器学习方法进行对比,结果表明本文所提方法具有更好的泛化能力和异常检测性能。
