基于改进YOLOv5s的复杂装配场景多尺度零件识别*
2023-08-02郑亮亮周海浪齐健文
郑亮亮,郭 宇,蒲 俊,周海浪,齐健文
(南京航空航天大学机电学院,南京 210016)
0 引言
当前复杂装配场景中零件数量种类多,尺寸多样,既包含大零件也存在螺钉、螺栓等细小零件,尺寸往往相差几十甚至几百倍;零件摆放过程中存在遮挡现象,包括零件与零件之间的遮挡以及其他物体对零件的遮挡等问题。基于机器视觉的零件识别技术中相机在同一位置往往只能检测到大尺寸零件,而忽视细小零件和被遮挡的零件。AR装配能够对生产装配过程进行可视化引导[1],而对零件的精准识别是实现装配智能引导的基础。因此提高复杂装配场景下零件识别的精度对于提高AR装配引导系统的场景感知能力具有重要意义。
在对提高复杂装配场景零件的检测性能问题上,许多学者对此进行了研究,主要包括基于机器视觉的图像特征检测方法及基于深度学习的目标检测算法。ZHENG等[2]设计了一种基于ORB特征匹配的自动定位抓取方法,用于解决机械臂对工业零件的定位和抓取问题;陈小佳[3]为解决零件表面的反光问题,采用机器视觉检测方法,一定程度上排除了噪声干扰;SUN等[4]针对小样本零件的识别问题,提出了一种基于相对熵的零件识别与定位方法;田中可等[5]提出一种利用随机森林分类器对提取的深度图像差分特征进行分类的方法,用于对圆锥圆柱减速器装配体及零件的识别;王一等[6]针对零件在复杂光照、遮挡、位姿变换、小零件漏检等情况下的识别精度不佳问题,提出了一种改进Faster RCNN算法;宋栓军等[7]通过对YOLOv3模型改进以及锚框聚类,提高了对小零件的检测精度;LI等[8]针对工业机械零件缺乏数据样本问题,建立了一个基于InceptionNet-V3预训练模型的卷积神经网络模型;杨琳等[9]针对零件定位精度差的问题,提出了一种改进YOLOv4算法的零件识别方法,通过改进优化算法和预测边界框,提高定位准确性;SHEU等[10]设计了一套基于IDS-DLA深度学习算法的钣金零件识别系统,用于解决钣金件的自动化识别问题。王向周等[11]针对紧固机器人对螺栓的检测问题,利用深度相机获取点云并与YOLOv5s-T结合实现对螺栓的三维定位和排序。
上述针对零件检测的方法中,基于特征的检测方法要求零件具有复杂的纹理结构,不同零件间有较大的对比度[12];基于深度学习方法对于同一角度距离下的多尺度及遮挡问题的检测性能较差。综合考虑模型大小、检测实时性以及准确性,本文提出了一种基于改进YOLOv5s的零件检测算法,用于对复杂装配场景中的多尺度零件进行检测。
1 YOLOv5s算法及改进
1.1 YOLOv5算法
YOLO算法主要思想是利用同一个网络同时输出位置信息和类别信息[13-16],到2020年YOLO算法发展到了第五代。YOLOv5算法与原有相比在输入端增加了自适应图片缩放,Mosaic数据增强,自适应锚框计算;采用CSPDarknet53为主干网络;特征金字塔网络(feature pyramid network,FPN)与路径聚合网络(path aggregation network,PAN)相结合为特征提取网络,将浅层信息与深层信息融合提高检测性能。YOLOv5系列根据通道数及模型大小分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,模型大小依次增加[17]。
原始的YOLOv5s算法输出端包含3个预测层,用于预测大、中、小3种尺寸目标,而过多的下采样导致目标的位置信息缺失,不利于对小目标的检测,对多尺寸零件检测效果较差且抗遮挡能力弱。
1.2 改进的YOLOv5s算法
本文对YOLOv5s算法进行改进,在自制的零件数据集上进行训练,利用训练好的模型对真实零件进行检测,实验流程如图1所示。
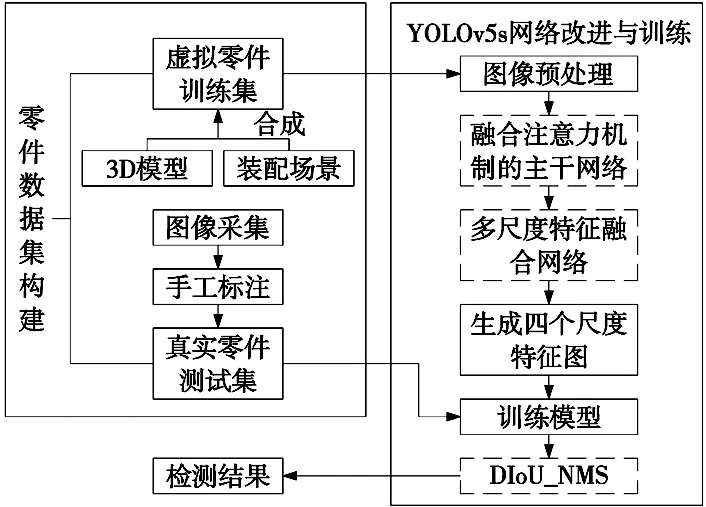
图1 实验流程图
其中YOLOv5s网络主要从以下3个方面进行改进:①将注意力机制模块融合到主干网络中,提高在杂乱背景下的检测性能;②为提高对于细小零件的检测能力,在特征融合网络增加浅层特征图,防止小目标特征消失;③采用CIoU作为边界框损失函数,DIoU作为非极大值抑制(non-maximum suppression,NMS)计算指标,减少因零件遮挡而导致漏检问题。改进后网络结构如图2所示。
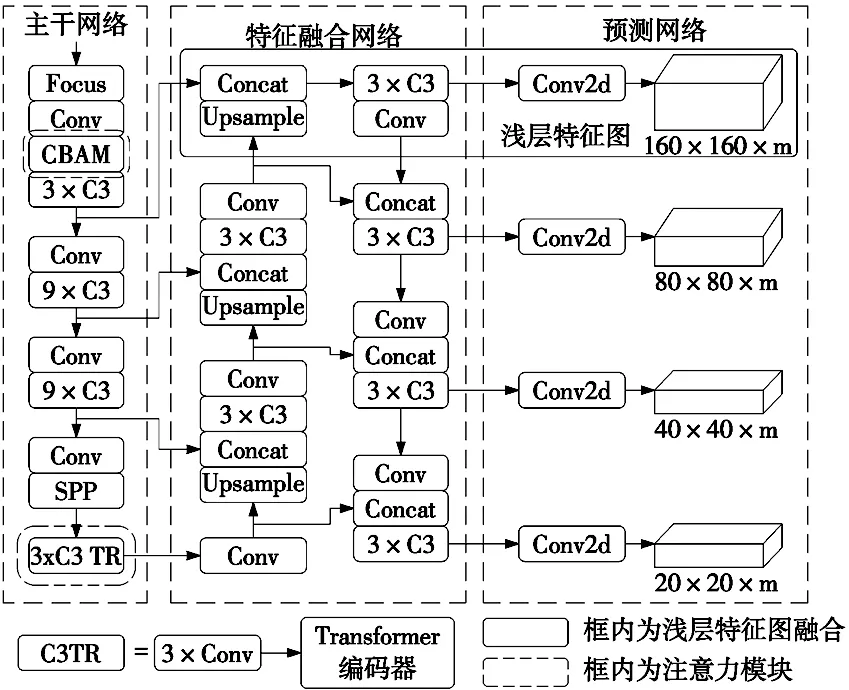
图2 改进后的YOLOv5s网络结构
1.2.1 融合注意力机制
针对复杂装配场景中包含装配零件、工具等物体及杂乱背景,导致非目标零件的误识别问题,本文将CBAM[18]、Transformer[19]模块集成到主干网络中,用于提高网络性能,如图3所示。输入图像在经过CBAM模块后得到4倍下采样特征图,再经过两次下采样后传到Transformer编码模块,得到32倍下采样特征图。
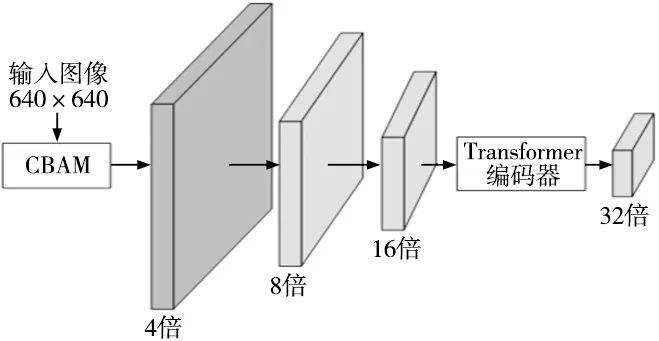
图3 融合注意力机制的主干网络
(1)CBAM模块。CBAM模块是一种简单高效的注意力机制,用于提高模型的表征能力,其结构如图4所示,包含2个独立的子模块:通道注意力模块和空间注意力模块。本文将CBAM模块集成到主干网络中,在经过通道注意力及空间注意力后将输出结果传递到下一层及特征提取网络中,以提高零件检测性能。
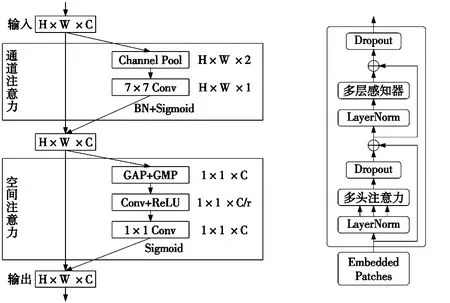
图4 CBAM模块结构 图5 Transformer编码部分结构图
(2)Transformer模块。Transformer模型是一个用纯注意力机制搭建的模型,广泛应用于图像处理中。Transformer模块包含编码器和解码器两部分,编码部分结构如图5所示,利用编码器进行特征提取,Transformer编码器增加了捕获不同信息的能力,可以利用自注意机制来挖掘潜在特征,在高密度遮挡对象上具有更好的性能[20],可提升零件在被遮挡时的检测性能,提高模型抗遮挡能力。
1.2.2 多尺度特征融合
针对原始网络对螺栓螺母等小零件的漏检问题,对特征融合网络进行改进。原始的YOLOv5s算法中输入图像在主干网络中将3次下采样特征图输入到特征融合网络中,如图6a所示。而过多的下采样会导致目标的位置信息缺失,不利于对小目标的检测,因此将下采样4倍后的特征图输入到FPN中与深层语义信息结合后输入到PAN中,自底向上传递目标位置信息。如图6b所示。新增的特征图分辨率高,拥有更加丰富的位置信息,将主干网络中更多的小零件信息输入到特征提取网络中,从而提高对小零件的检测效果。
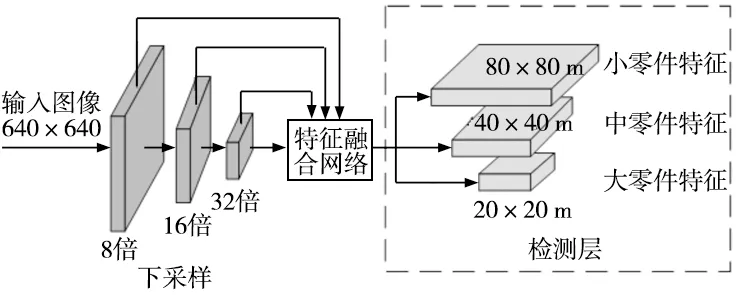
(a) 原始特征提取模型
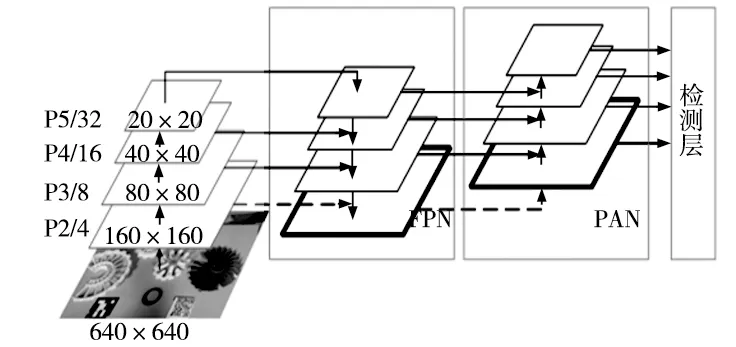
(b) 改进后的特征融合网络图6 多尺度特征融合网络对比
1.2.3 损失函数与NMS优化
(1)CIoU。YOLOv5s算法中损失函数包括边界框损失、分类损失和置信度预测损失[21],其中边界框损失采用GIOU作为损失函数[22],计算公式如下:
LGIoU=1-GIoU
(1)
(2)
(3)
式中:A、B为预测框和真实框,C为能够包围两框的最小矩形框。
针对GIoU损失当预测框在真实框内部时,无法确定预测框的位置状态,此时GIOU计算值与IOU相同的问题,采用CIoU损失[23]作为边界框损失函数,CIoU可以反映检测框的长宽比以及衡量锚框与真实框之间的比例一致性,可以在预测框与真实框没有重叠时向重叠区域增加的方向进行优化,计算公式为:
(4)
(5)
(6)
式中:ρ为预测框与真实框两中心点之间的距离,c为能包含两矩形框的最小矩形的对角线的长度,wgt、hgt为真实框的宽和高,w、h为预测框的宽和高。
(2)DIoU_NMS。针对YOLOv5s算法中采用IoU作为NMS计算指标,当零件相互遮挡时,容易将正确预测框抑制的问题,对NMS算法进行改进,改进后算法流程如表1所示。

表1 DIoU_NMS算法
采用DIoU作为NMS的计算指标,计算公式如式(7)所示。
(7)
在计算时不仅考虑两框的重叠区域,同时两者中心点间的距离也作为影响因素,一定程度上减少了因零件之间相互遮挡造成的漏检问题。
2 实验结果与分析
2.1 实验平台
本实验以某型航空发动机装配场景为研究对象,包含12种装配零件,如图7所示将Kinect相机布置于距离操作台平面600 mm的高度上,对装配现场进行采集,如图8所示。

图7 实验零件

图8 装配场景
本实验配置环境如表2所示。

表2 实验配置环境
2.2 数据集与实验参数
2.2.1 零件数据集
为减少手工标注时间,采用基于三维模型的虚拟训练集与手工标注真实测试集相结合的方法[24]。
(1)虚拟训练集构建。虚拟训练集制作过程如图9所示,主要流程为:将原始3D模型导入到Unity3D软件中对零件位姿进行随机调整并拍照后对零件照片裁剪并提取,随机粘贴在装配背景照片上,获得含有零件的合成后照片及零件位置类别信息的XML文件。
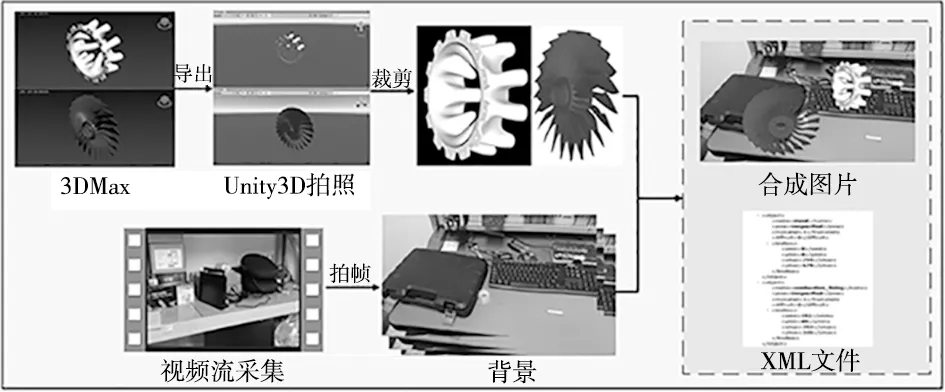
图9 虚拟数据集制作流程图
(2)真实测试集采集。利用Kinect相机采集真实零件图像作为测试集,如图8所示,调节零件与非目标零件位置和角度,从而获取不同状态下的零件图像,在LabelImg工具上进行手工标注。
2.2.2 实验参数
实验包含虚拟训练集2800张,真实测试集700张。含12种不同尺度的零件,大部零件为中等尺寸零件,以及螺栓、螺母两种细小零件,具体尺寸规格如表3所示。

表3 零件名称及规格
本文训练模型参数设置如下:采用SGD优化算法,初始学习率为0.01;训练批次为300次,每个训练批次中一次传入16张图片进行训练;输入图片尺寸为640×640,储存最后一次迭代模型权重及最佳性能模型权重。
2.3 评价指标
本实验采用参数量M、浮点运算数(floating point operations,FLOPs)、mAP作为模型性能的评价指标,其中mAP表示所有类别AP值的平均值,mAP计算公式如下:
(8)

(9)
(10)
(11)
式中:TP表示正确预测的数量,FN表示将正样本预测为负样本的数量,FP表示将负样本预测为正样本的数量,R表示查全率,表示将多少正样本正确预测;P为查准率,表示预测为正的样本中有多少被正确预测。TP、FP的值根据设定的IoU阈值确定,通常为0.5,计算mAP值作为评估指标。
2.4 消融实验
为验证各模块在改进YOLOv5s算法中的作用,进行消融实验[25]观察各模块对于网络性能的影响。本文设置了4组对比实验,在依次加入3组改进模块后在零件数据集上进行测试,如表4所示,“√”表示使用改进的模块。由实验结果可以看出,对比于原有的YOLOv5s网络,在依次增加多尺度特征融合、注意力机制模块、优化损失函数与NMS后,模型精度提高。在对多尺度特征融合后,mAP提高了1.2%,提高了对于小零件的检测精度;在主干网络中融合注意力机制后,由于Transformer模块替换掉原始模型中的Bottleneck模块,参数量减少,强化特征提取,mAP提高了0.7%;在优化损失函数与NMS后,在没有大量提高计算参数的情况下,精度提高了1.0%,一定程度上提高了对于零件被遮挡时的检测性能。综上所述,改进后的检测算法对比原有算法有了明显的提升,且参数量减少。

表4 基于YOLOv5s的消融实验
将各模型训练中的精度和损失值进行对比,如图10a、图10b所示分别为各模型的mAP曲线和损失曲线,横坐标代表训练批次,纵坐标分别代表mAP和损失值,当训练次数增加时,损失值下降,精度提升,原有算法在40个epoch前损失值快速下降,精度达到93%左右,后续随着训练次数的增加,损失值下降平缓,网络不断拟合,最终精度为93.3%;加入各模块后,模型的精度依次提高,初始及最终损失值减小,收敛性提高;改进后的算法在20个epoch时精度即达到93%,最终损失值下降到0.018左右,精度达到96.2%。与未改进的算法相比,改进之后的算法损失值下降更快,最终损失值更小,且mAP值更高,说明网络拟合程度及模型识别性能更好。
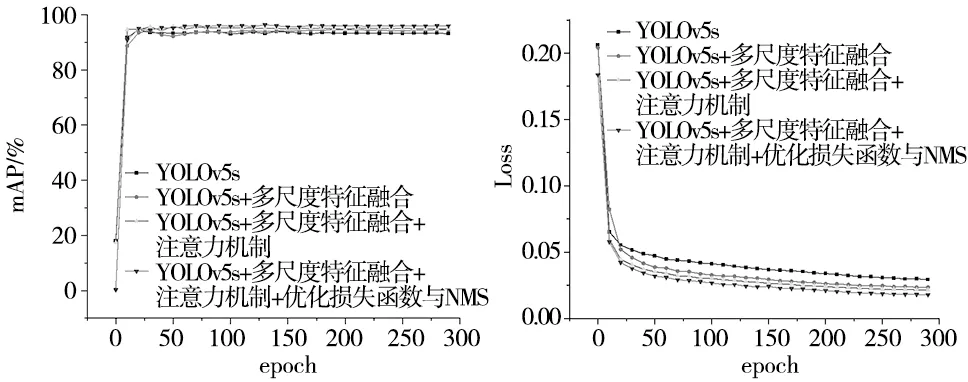
(a) mAP曲线 (b) 损失曲线图10 模型mAP及损失曲线
2.5 检测结果分析
将YOLOv5s算法与改进的YOLOv5s算法对不同的零件的检测精度进行对比,如表5所示。由表可得,与YOLOv5s算法相比,改进后的算法对于大、中尺寸零件mAP值变化较小,在对细小螺栓、螺母零件的检测上效果提升显著,分别提高了12.6%、19.6%。
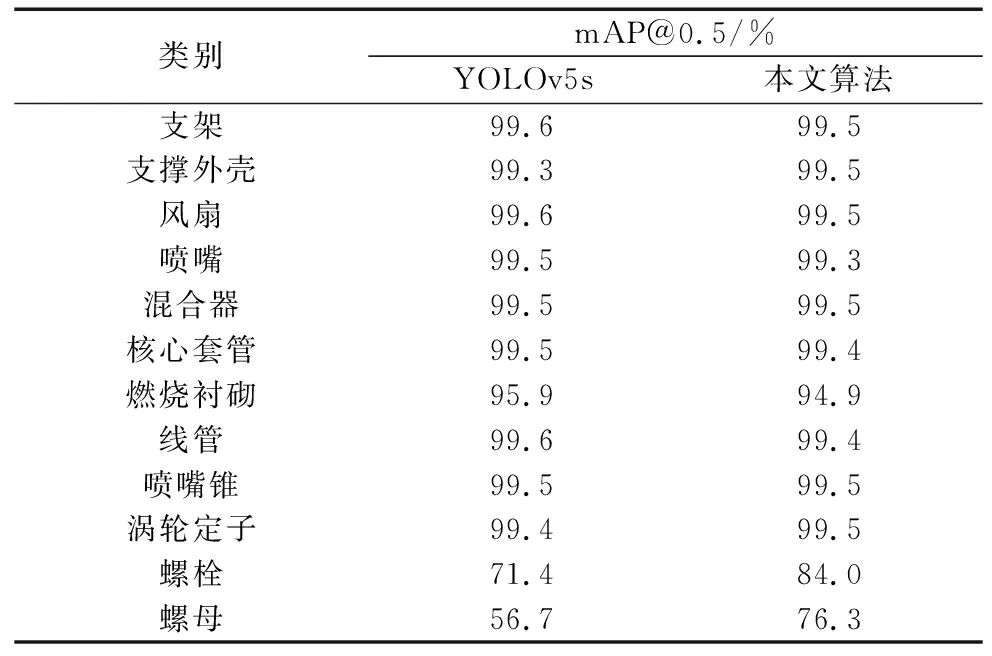
表5 两种算法对不同零件的mAP/%(IoU=0.5)对比
将改进前后算法得到的训练模型同时在验证集上进行测试,如图11所示,其中图11a为YOLOv5s算法,图11b为改进后的算法。

(a) YOLOv5s算法 (b) 改进后算法图11 零件识别结果对比
根据识别结果可得,改进后的算法在对零件检测置信度上有部分提高,且对于小零件的漏检现象减少;当装配场景复杂含有其他物体时,错检漏检率下降,如原算法将机械手误识别为零件而漏检了涡轮定子;当零件被遮挡时,改进后算法也能够准确检测出被遮挡零件。综上表明改进后的算法提高了对于螺栓、螺母等小零件的识别准确性;零件被遮挡时的漏检问题及装配场景杂乱时的错检问题能够得到一定的改善,证明了本文算法的有效性,且每张图片检测时间都在0.02 s左右,每秒传输帧数可达到50,满足实时性要求。
3 结束语
针对增强装配引导系统中场景感知过程中对于复杂装配场景中小零件以及零件被其它物体遮挡造成的错检、漏检问题,提出一种改进YOLOv5s的零件检测算法,通过融合注意力机制,增加浅层特征信息并对损失函数与NMS进行优化,实验表明改进后的算法一定程度上提高了模型在复杂装配场景下对多尺度零件及零件被遮挡时的检测性能,但当零件被大面积遮挡时检测效果仍不佳,因此未来将在此基础上进行进一步研究。
