融合MS-IRB与CAM的入侵检测模型
2023-07-15王禹贺卓德志李世明
黄 博,王禹贺,赵 艳,于 丹,周 英,卓德志,李世明,3
1(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150025) 2(洛阳师范学院 信息技术学院,河南 洛阳 471934) 3(上海市信息安全综合管理技术研究重点实验室,上海 200240)
1 引 言
在互联网技术得到广泛应用的同时,恶意程序和基于漏洞的网络攻击也在不断滋生,侵扰人们对于互联网的正常使用,网络安全问题已成为亟待解决的关键问题.
在网络安全防护领域,入侵检测[1]是一项重要的技术,它能够识别已存在的异常行为或是正在发生的攻击行为[2].自1990年网络入侵检测系统(NIDS)诞生以来一直面临诸多挑战,如愈发复杂的网络攻击行为、海量数据的入侵检测挑战[3]等.NIDS能够提供有效的防御体系,在防御的过程中进行实时动态分析、收集关键数据,不断增强检测模型的泛化能力.
近年来,机器学习和深度学习的快速发展以及硬件水平的综合提升使得将人工智能技术应用于入侵检测系统[4]成为一种趋势.Al-Yaseen等人提出了一种基于SVM分类器与极限学习机的多级混合入侵检测模型[5],该模型融合SVM和极限学习机的优势,提高了检测准确率;N-Farnaaz等人建立了一个使用随机森林分类器的入侵检测模型[6],与传统分类器相比,该模型在检测攻击数据的有效性方面取得了一定的效果.但是,由于机器学习模型在处理维度高、数量大的网络流量数据时效果不佳,因此有必要研究新的模型来满足使用需求.
相比之下,具备卓越学习能力与高效特征表达能力的深度学习模型在入侵检测领域[7]能够展现出更多优势.常被用于入侵检测的深度学习技术有卷积神经网络(CNN)[8,9]、循环神经网络(RNN)[10,11]、深度信念网络(DBN)[12]等.部分研究成果表明,深度学习模型的检测能力较机器学习方法和传统方法有很大提升,如一种基于改进卷积神经网络的入侵检测模型[13],该模型具有良好的检测准确率,但模型对特征双层并行提取,增加了模型的复杂度,并存在模型优化过程中参数值难以调优的问题;再如刘月峰等人提出将CNN与BiLSTM进行融合的入侵检测方法[14],该方法体现了融合模型的性能优势,但其结构较为复杂,模型收敛速度有待提升.鉴于卷积神经网络对于特征提取的独特优势,近年来CNN被广泛应用于各个领域,并且研究人员热衷于对其结构进行改进,其中残差网络[15]有效地解决了当神经网络层数加深时产生的退化问题,提升了模型性能.文献[16]基于残差网络进行改进,提出了S-Resnet模型,该模型在一定程度上减少了残差网络的模型复杂度并提高了检测准确率.
综上所述,目前入侵检测方法涉及多种解决问题的思路:1)从数据特征角度分析,提出了结合CNN与RNN的检测模型,分别提取数据的空间和时间特征,提高了检测准确率;2)从模型结构分析,通过增加模型深度来强化对数据的特征提取,从而得到更优的分类结果等.
但其中还存在一些问题:1)多数模型选择将一维网络流量数据转化成二维数据进行使用,而二维数据使用效果劣于三通道数据;2)浅层机器学习模型的训练速度快,模型收敛速度也要优于复杂模型,但分类效果较差;3)深度学习模型分类准确率较高,但其模型参数数量大、计算量高、收敛速度慢.
针对上述问题,本文提出了一种融合多尺度倒残差块(Multiscale-Inverted Residual Block,MS-IRB)与通道注意力机制(Channel Attention Mechanism,CAM)的入侵检测模型.该模型将一维网络流量数据转化成三维图像数据作为模型输入,相比二维数据,三维图像数据能够提升模型的分类效果;使用深度可分离卷积替代普通卷积,减少了模型对网络流量数据进行特征提取时的运算参数数量;改进倒残差块,并进行多尺度特征提取,结合通道注意力机制为特征矩阵的不同通道分配相应权重,进而提升模型的准确率.
2 相关工作
2.1 深度可分离卷积
深度可分离卷积[17]的核心思想是将标准卷积运算分成逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两步进行.标准卷积运算使用多个卷积核对输入特征矩阵进行卷积运算,所使用的卷积核的通道数和输入特征矩阵通道数一致;而逐通道卷积对输入特征矩阵的每个通道单独进行特征提取,所涉及的卷积核个数与输入特征矩阵的通道数相同,操作后得到的输出特征矩阵数也相同.由于提取后的结果特征矩阵没有将不同通道的信息进行融合,因此需要通过逐点卷积运算将上述操作的结果进行融合得到新的输出.逐点卷积的运算的步骤与普通卷积极为相似,区别在于逐点卷积运算使用的卷积核尺寸为1×1,卷积核通道数等于逐通道卷积的输出特征矩阵通道数,其运算得出的输出特征矩阵个数与所使用的卷积核个数相同.综上所述,通过深度可分离卷积可以在保留卷积运算优秀特征提取能力的同时减少参数数量和计算量,从而优化模型结构、降低模型复杂度.
假设输入层的特征矩阵为I,大小为DI×DI×M,输入特征矩阵的宽、高均为DI,输入通道数为M;输出特征矩阵为O,大小为DO×DO×N,输出特征矩阵的宽、高均为DO,输出通道数为N;卷积核为K,大小为DK×DK×M×N,卷积核的宽、高均为Dk.
根据卷积运算的定义,假定步距为1且默认填充的情况下可以得到输出特征矩阵的运算方式,如公式(1)所示:
(1)
标准卷积的计算量可由公式(2)计算得出:
DK×DK×M×N×DO×DO
(2)
与普通卷积不同,逐通道卷积每一个单通道卷积核对应输入特征矩阵的一个通道,其运算方式如公式(3)所示:
(3)
逐通道卷积的计算量可由公式(4)计算得出:
DK×DK×M×DO×DO
(4)
由于需要进行特征融合,在进行逐通道卷积之后需要使用逐点卷积运算,所以逐通道卷积和逐点卷积的结合称为深度可分离卷积,其计可由公式(5)计算得出:
DK×DK×M×DO×DO+M×N×DO×DO
(5)
使用深度可分离卷积来替代普通卷积运算,可以减少模型的参数数量和计算量,二者计算量之比如公式(6)所示:
(6)
不难看出,当卷积核大小为3×3时,普通卷积的计算量比深度可分离卷积的计算量高出8~9倍,且深度可分离卷积的特征提取效果并不弱于普通卷积.
普通卷积与深度可分离卷积如图1所示.
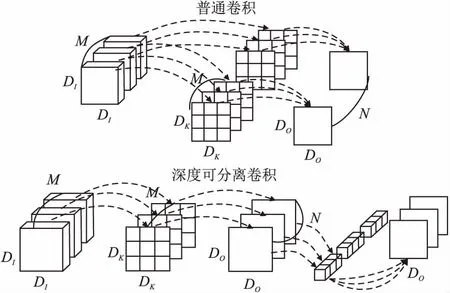
图1 普通卷积与深度可分离示意图Fig.1 Common convolution and depthwise convolution diagram
2.2 通道注意力机制
注意力机制是人类视觉系统中的一种现象,在观察事物的时候人眼会重点关注视线中的关键信息并选择性地忽略另一部分信息.计算机中的注意力机制就是对该行为进行仿生,其核心在于对所有资源根据重要性进行正比例非均衡分配,与均衡分配情况相比,该种分配方式可以提高分类的准确率.本文模型使用的压缩激发(Squeeze Excitation,SE)模块[18]属于通道注意力机制.在卷积过程中,默认情况下每个特征矩阵所包含通道的权重相等,在加入通道注意力机制后,SE模块会根据各个通道对模型的重要程度为其分配权重,这些加权后的特征矩阵将作为模型下一层的输入.SE模块核心操作是压缩(Squeeze)和激发(Excitation):压缩操作是对特征矩阵进行平均池化下采样,并得到当前特征矩阵的全局压缩信息;激发操作使用两层全连接和两层激活函数得到特征矩阵中每个通道的权值,将激活函数输出的权重与对应通道相乘,得到加权后的特征矩阵.
2.3 多尺度倒残差块
倒残差块[19]是由残差块演变而来,两者之间存在以下差异:在残差结构中,模型对输入层依此进行1×1卷积降维、3×3卷积计算、1×1卷积升维,最后在模块底部处进行输出;而倒残差结构正好与之相反,因此该结构被命名为倒残差块.
因为不同尺寸卷积核所拥有的感受野不同,所以当使用不同尺寸卷积核对同一输入进行特征提取时所生成的结果也不同.为了更加有效地提取信息,Thomas Serre等[20]在动物视觉皮层感知策略的启发下尝试使用不同尺寸的卷积核进行特征提取,该策略即多尺度提取.GoogLeNet[21]网络结构中应用了多尺度特征提取,通过融合由不同尺寸卷积核提取到的信息能够得到包含更多有效信息的新结果.本文模型对多尺度特征提取策略进行了一些调整,并将其应用于倒残差块中,改进后的多尺度倒残差块结构如图2所示.
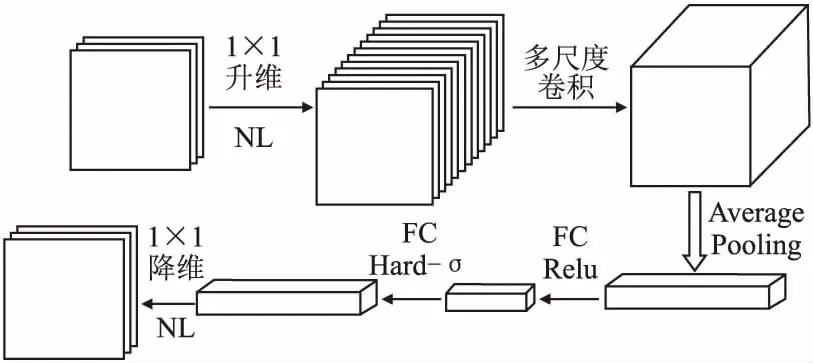
图2 多尺度倒残差块Fig.2 Multiscale-inverted residual block
结构中多尺度卷积部分使用深度可分离卷积运算替代卷积运算,在三组倒残差块中分别使用尺寸为1×1、2×2、3×3的卷积核进行特征提取,并将提取后的结果输入SE模块中处理,输出特征矩阵会被传入下一组倒残差模块中.总的来说,加入多尺度提取能够更加有效地获取不同位置网络流量数据的信息,而不使用5×5卷积核的主要原因是网络流量的数据尺寸过小,5×5卷积核无法对其进行有效提取,因此本文使用了3个尺寸较小的卷积核进行特征提取.
3 融合MS-IRB与CAM的入侵检测方法
3.1 方法流程
首先将数据集中的原始数据进行预处理,使其转化为三通道数据;其次,将处理好的三通道数据输入融合通道注意力机制的MS-IRB模型中进行多尺度特征提取;最后将模型输出的数据进行全连接处理,并使用Softmax函数得出分类结果.融合MS-IRB与CAM的入侵检测方法的原理如图3所示.
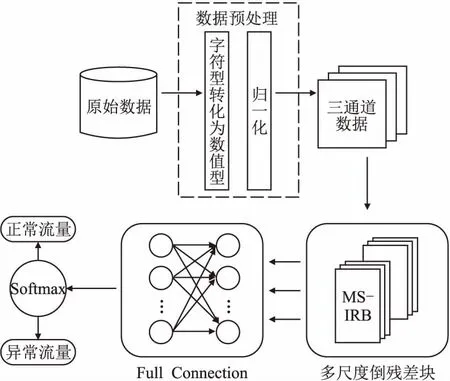
图3 融合MS-IRB与CAM的入侵检测方法Fig.3 Intrusion detection method incorporating MS-IRB and CAM
3.2 数据预处理
为满足深度学习模型的输入数据格式,需要对数据集进行预处理,处理方法有数值化、标准化、归一化等.卷积神经网络对图片数据有很好的处理能力,通过将入侵检测问题转化为图像分类问题[22],可以充分发挥模型优势.预处理过程分为如下几步:
1)数值化:本文选用了独热编码对数据进行数值化处理,并将处理前数据集中的列替换为编码后的列,处理后得到的列均为数值型.该操作不仅解决了数据属性不适配的问题,而且在一定程度上起到了扩充特征维度的作用.
2)归一化:数值化后的数据集虽然可用,但数值过大或者过小的数据都会影响模型的训练速度和准确率,因此数值化处理后的数据集仍需进行归一化处理.本文采用了Min-Max方法对原始数据进行线性变换,将结果值映射在0~1之间,其转换函数如公式(7)所示:
(7)
3)图像化:数据集中每一条数据均以一维数组的形式存在,此时的数据仍然不能作为卷积神经网络的输入数据.对此,本文尝试了两种思路对数据进行格式转换:
(1)二维图像化:将一维数组转换成二维数组,再将其转化成二维灰度图像,此时的数据满足模型输入要求.
(2)三维图像化:卷积神经网络的输入数据格式通常为RGB三通道彩图,每个通道均有不同矩阵格式的像素值,网络流量的特征值能够对应3个通道的像素值.将一维数组转化换三维数组,再将其更改为三通道图像作为模型输入.
3.3 融合通道注意力机制的MS-IRB模型
若特征矩阵中不同通道的权重一致,则无法实现加强卷积核对包含更多有效信息的通道进行特征提取的目的.为解决该问题,选用SE模块为通道分配权重,提高包含更多有效信息通道的权重.本文模型在多尺度倒残差结构中加入了通道注意力机制,为深度可分离卷积后得到的输出特征矩阵内部通道分配权重,提升模型对高权重通道的关注度,从而提高分类的准确率.融合通道注意力机制的MS-IRB模型结构如图4所示.
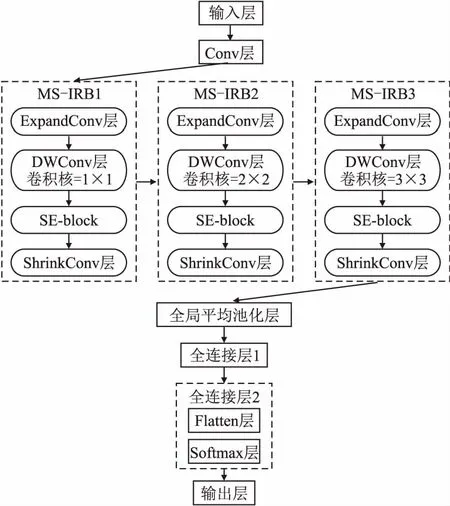
图4 融合MS-IRB与CAM模型结构图Fig.4 Structural diagram of the incorporating MS-IRB and CAM model
每次卷积操作后都使用了Batch Normalization层[23]对数据进行处理.若数据没有经过BN层处理,则每次特征提取后的数据分布位置会被打乱,模型需要耗费更多资源对新的数据分布进行学习.该操作不利于模型的收敛且容易导致过拟合,因此BN层能够加速网络收敛、防止发生过拟合.
3.4 激活函数
为提高模型的分类效果,引入swish激活函数来替代ReLU激活函数[24],swish激活函数可以有效提升模型准确率,其定义如下:
定理 1 (ⅰ) 若a≤λ1,则系统(3)没有共存解;若a≤λ1且d≤λ1,则系统(3)没有非负非零解。
swishx=x·σ(x)
(8)
但由于swish激活函数计算较为复杂,本文模型使用了hard-swish激活函数[25]替代swish激活函数来提高模型的精度,hard-swish激活函数定义如下:
(9)
为解决sigmoid函数实现swish函数计算复杂的问题,使用了近似的函数来实现,具体操作为:将 ReLU6激活函数改进的hard-sigmoid函数用于构造swish激活函数,该操作可以得到计算简单且精度更高的hard-swish激活函数.随着网络的层数变深,使用非线性激活函数的成本会降低,因此在搭建本文模型时,仅在特征矩阵通道数较少时使用ReLU激活函数,其余激活函数均使用了hard-swish.
4 实验与分析
4.1 实验环境及评价指标
为了验证本文模型效果,现搭建仿真实验环境,实验环境配置如表1所示.

表1 实验环境配置Table 1 Lab environment configuration
本文所使用的实验评价指标为准确率(Accuracy)、精确率(Precision)、召回率(Recall)和假负率(FNR).
(10)
(11)
(12)
(13)
以上指标均由表2混淆矩阵中的4个值计算得出.在数据集中,攻击样本标签为1,正常样本标签为0,则TP、FP、FN、TN表示以下4种情况:

表2 混淆矩阵Table 2 Confusion matrix
TP:实际值为1,预测值为1,结果正确.
FP:实际值为0,预测值为1,结果错误.
TN:实际值为0,预测值为0,结果正确.
4.2 实验数据集
本文采用UNSW-NB15数据集[26],该数据集由澳大利亚网络安全中心(ACCS)于2015年生成.本文实验选用了经处理后可用于入侵检测的数据文件:UNSW-NB15 Training Set.csv和UNSW-NB15 Testing Set.csv,该训练集和测试集均已完成数据去冗余,其样本数分别为175341和82332条,正常数据和异常数据分布较为均衡.在训练集中,正常数据占32%,异常数据占68%;在测试集中,正常数据占45%,异常数据占55%,其数据分布情况如表3所示.

表3 UNSW-NB15数据分布情况Table 3 Data distribution of UNSW-NB15
本文采用二分类思想解决入侵检测问题,将数据集中的数据逐条进行三维图像化处理.每条数据包含标签列,正常数据标签为0,异常数据标签为1.
4.3 实验参数设置
对模型进行训练之前,需要设置模型的超参数.其中比较重要的参数有:激活函数、优化器、批尺寸和学习率等.
本文使用了自适应学习率优化算法中的Adam优化器,由于其计算效率高、参数调节十分简单,默认的参数就可以应对大多数训练情况,故选择Adam优化器作为本模型的优化算法.
实验过程中所有模型的批尺寸(Batch Size)均设置为32,虽然更大的Batch Size可以加快训练速度,但考虑到使用的仿真环境内存只有16GB;而过小的Batch Size会降低模型的收敛速度.在对比了Batch Size设置为16与32的实验结果后,将本实验中的Batch Size统一设置为32.
设置高学习率虽然能够提升模型的训练速度,但高学习率易使模型错过全局最小值或一直在全局最小值附近震荡,模型无法收敛至最优;设置低学习率训练起来更慢,该策略的优点是更容易使模型收敛至全局最小值,但是当神经网络收敛至一个局部极小值时,过小的学习率会使模型困在局部极小值最终导致其错过全局最小值.在保证其他条件不变的前提下,使用了0.1、0.01、0.001、0.0001这4种不同学习率对本文模型进行50轮迭代训练,不同学习率对应的最终轮次准确率如表4所示.
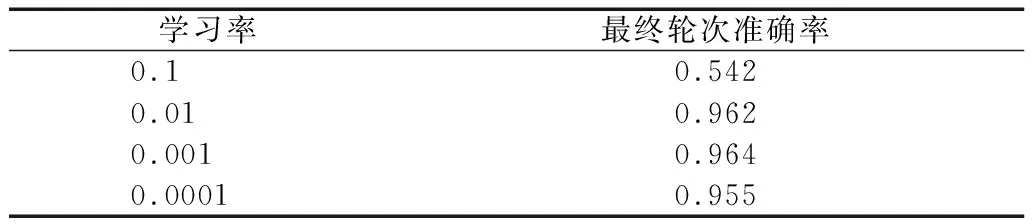
表4 不同学习率下的最终轮次准确率Table 4 Final round accuracy rates of different learning rates
从表中可知,将学习率设为0.001时模型准确率最高,因此本实验使用的学习率为0.001.
实验中使用的倒残差结构详细参数如表5所示.其中SE列包含的属性是True和False,表示是否使用SE模块,NL列表示该层使用的激活函数名称.

表5 倒残差结构参数Table 5 Parameter of inverted residual block
4.4 实验结果分析
本文设置了3组对比实验来验证模型的有效性.第1组实验:将相同的数据分别转化成二维数据和三维数据输入本文模型进行对比,实验结果表明三维数据能够有效提升模型的检测准确率;第2组实验:将本文模型与常用的机器学习模型进行对比,实验结果证明本文模型在准确率、精确率和召回率的综合性能表现均优于用于对比的机器学习模型;第3组实验:将本文模型与CNN以及LSTM进行检测能力与模型复杂度的综合评估,由实验结果可知,本文模型准确率相比CNN提升了0.7%、损失值降低了1.6%,且模型参数数量在3种模型中最少.由上述3组对比可以得出:本文模型能够有效降低模型复杂度并提升检测准确率.
4.4.1 二、三维数据实验效果对比
为验证输入数据维度对模型效果的影响,现将相同数据分别转化成二维数据和三维数据,并输入本文模型进行50轮对比实验,实验结果如图5所示.

图5 二维数据与三维数据实验效果对比Fig.5 Comparison of experimental effects of 2D data and 3D data
由实验结果可知,三维数据信息传递效果明显优于二维数据.在其他条件相同的前提下,模型对三维数据的检测准确率比二维数据提高了17.2%,表明三维数据能够显著提升模型的检测准确率.
4.4.2 融合MS-IRB与CAM模型与机器学习模型对比
现将几种常用的机器学习模型应用到实验数据集并与本文模型进行对比,包括决策树、随机森林、支持向量机、Adaboost,其性能表现如表6所示.

表6 不同模型对比Table 6 Comparison of different models
从表6中数据可以看出,随机森林和Adaboost模型性能明显强于决策树和支持向量机,表明集成学习在进行分类任务时强于单体分类器的.通过评价指标可知,与进行实验的机器学习模型相比,本文模型综合性能表现更优.
如图6所示,随着迭代轮次的增加,3种模型的准确率均有所提升,但LSTM收敛速度明显慢于CNN和本文模型.本文模型在前5轮内准确率提升速度非常快,并在五轮之后准确率趋于平稳、缓步提升,由此可知本文模型结构设置合理,模型收敛速度很快.虽然CNN收敛速度也很快,但是准确率却低于本文模型,通过50轮对比实验可以看出,本文模型准确率和收敛速度均优于CNN和LSTM.
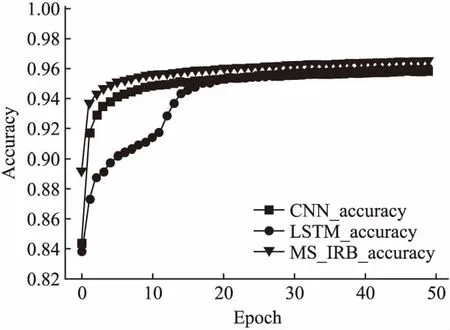
图6 3种模型准确率随迭代轮次变化Fig.6 Variation of the accuracy of the three models with iteration rounds
除准确率之外,损失值也是评判模型优劣的重要指标,3种模型的损失值随迭代轮次变化如图7所示.

图7 3种模型损失值随迭代轮次变化Fig.7 Variation of loss values with iteration rounds for the three models
由图7可知随着迭代轮次的增加,本文模型的损失值快速降低并趋于稳定状态.与另两种模型相比,本文模型的损失值最低,模型收敛速度最快.综上所述,本文模型综合性能优于CNN和LSTM.
在搭建本文模型的过程中使用了深度可分离卷积和H-swish激活函数,替换了传统模型中的普通卷积和ReLU激活函数.此举提升了模型准确率并降低了模型的参数数量和浮点计算量,使模型体积更小,更容易搭建.实验过程中使用Keras的summary方法和get_flops方法对模型的参数量和浮点计算量进行了统计,为更客观地评价模型复杂度,将3组模型的最高特征矩阵通道数均设置为128,结果如表7所示.
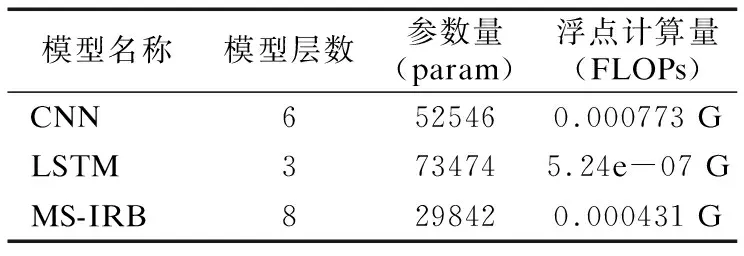
表7 模型复杂度对比Table 7 Model complexity comparison
表7表明MS-IRB模型的层数更深,由于深度倒残差结构对特征矩阵进行了升维降维操作,该操作会加深模型层数,同时增加运算参数数量.在层数更深时,本文模型的参数数量分别比CNN减少了34%,比LSTM减少了60%,同时浮点计算量比CNN减少了45%,显著地降低了模型复杂度.
5 总结与展望
本文提出了一种融合MS-IRB与通道注意力机制的入侵检测方法,有效地解决了深度学习中存在的模型复杂度高、收敛速度慢和准确率低等问题.在公开网络数据集UNSW-NB15上进行测试和验证,结果表明本文模型在进行二分类任务时能够降低模型复杂度并提升分类准确率.
但由于本文并未对数据集进行特征选择,因此数据集质量可能会对模型分类效果产生影响.若处理多分类问题,存在部分类别检测准确率低的可能.但本文模型具有良好的可扩展性,通过调整倒残差结构来优化模型性能,使模型能够在数据维度和数据量大幅增加时保持较低的参数数量和计算量.下一步研究的重心将放在改进本文模型,并解决多分类问题.
